Quick Summary: Fine-tuning an LLM typically costs between under $5 and $10,000 depending on model size, technique, and infrastructure. Smaller models (2-8B parameters) with parameter-efficient methods like LoRA can be fine-tuned for under $10 on cloud GPUs, while full fine-tuning of larger models on premium infrastructure can exceed $10,000. Understanding cost drivers—compute resources, training data volume, model architecture, and technique choice—helps teams budget effectively.
The price tag for fine-tuning large language models catches most teams off guard. Training from scratch can cost millions—Google’s Gemini Ultra reportedly hit $191 million, while GPT-4 came in around $78 million—but fine-tuning existing models tells a completely different story.
Here’s the thing though: fine-tuning costs vary wildly. A research team at Stanford fine-tuned Qwen3-8B-Base for under $5 using LoRA adapters on Together AI’s managed service. Meanwhile, full fine-tuning jobs on enterprise infrastructure routinely cost $3,000 to $10,000.
Understanding where your money goes matters more than the sticker price.
What Drives Fine-Tuning Costs
Four primary factors determine what fine-tuning actually costs.
Compute Infrastructure
GPU choice creates the biggest cost variance. Cloud providers charge by the hour, and rates differ dramatically based on hardware class.
An NVIDIA A10G—mid-range by today’s standards—costs roughly $1.50 to $2.50 per hour on major cloud platforms. The fine-tuning job that cost under $10 mentioned earlier ran for four hours on a single A10G.
But scaling up gets expensive fast. Premium GPUs like A100s or H100s run $4 to $8 per hour on AWS or Google Cloud. Multi-GPU setups for larger models multiply these costs linearly.
Self-hosting presents a different calculation. An RTX 4090 costs about $1,600 upfront but eliminates recurring hourly charges. According to community discussions on LinkedIn, one GPU pays for itself in weeks when compared to $2,500 monthly cloud GPU node subscriptions—if utilization stays consistently high.
Model Size and Architecture
Parameter count directly impacts memory requirements and training duration.
| Model Size | VRAM (Full Fine-tuning) | VRAM (4-bit LoRA) | Typical Cost Range |
|---|---|---|---|
| 2-3B parameters | 6-8 GB | 2-3 GB | $300-$700 |
| 7-8B parameters | 14-16 GB | 6-8 GB | $1,000-$3,000 (LoRA) Up to $12,000 (full) |
| 12-13B parameters | 24-28 GB | 10-12 GB | $5,000-$15,000 |
Phi-2 (2.7B parameters) with LoRA typically costs $300 to $700. Mistral 7B models land between $1,000 and $3,000 using LoRA, but full fine-tuning can push costs to $12,000.
Memory requirements explain why. Full fine-tuning stores gradients for every parameter. A 7B model needs roughly 28GB VRAM just to load weights at 16-bit precision—before accounting for gradients, optimizer states, and activation memory during training.
Training Technique Selection
The method chosen for fine-tuning dramatically alters both cost and resource requirements.
- Full Fine-Tuning updates every model parameter. This approach offers maximum control and customization but demands significant VRAM. Memory usage scales linearly with model size, making full fine-tuning of models beyond 13B parameters impractical without multi-GPU setups.
- Parameter-Efficient Fine-Tuning (PEFT) techniques update only a small subset of weights. LoRA (Low-Rank Adaptation) inserts trainable adapter modules between transformer layers while freezing the base model. According to arXiv research on resource-efficient methods, LoRA reduces training memory substantially while maintaining comparable accuracy to full fine-tuning.
Real-world impact? Stanford researchers achieved 0.78 accuracy fine-tuning Qwen3-8B with LoRA (rank=32) versus 0.41 accuracy on the base model—for under $5 in compute costs. That performance gain at minimal expense demonstrates why PEFT techniques dominate practical applications.
- Quantization further reduces costs. Training with 4-bit quantization via bitsandbytes dropped FLUX.1-dev LoRA fine-tuning from roughly 60GB peak memory to approximately 37GB, according to Hugging Face documentation. Quality degradation remained negligible.

Dataset Size and Training Duration
More training data doesn’t always mean better results, but it definitely means higher costs.
Token count determines compute time. OpenAI’s fine-tuning API—which bills based on training tokens rather than wall-clock time—makes this relationship explicit. Community discussions mention that tracking costs requires monitoring trained tokens since billing shifted away from core training time metrics.
Data quality matters more than volume. Teams often find better results from 500 carefully curated examples than 5,000 noisy samples. Poor data quality extends training duration as the model struggles to find consistent patterns, inflating costs without improving outcomes.

Implement Custom LLM Solutions with AI Superior
Fine tuning a large language model requires the right dataset, training infrastructure, and evaluation process. In many cases, custom model adaptation or retrieval-based systems may also be considered.
AI Superior develops custom LLM solutions for businesses that require domain-specific AI capabilities.
Their expertise includes:
- dataset preparation and annotation
- model fine tuning and evaluation
- RAG and hybrid architectures
- production deployment of LLM systems
If you need a custom LLM solution tailored to your data and workflows, AI Superior can support the development process.
Hidden Costs That Add Up
The invoice from your cloud provider doesn’t tell the whole story.
Data Preparation Labor
Cleaning, formatting, and validating training data consumes substantial engineering time. Dataset inconsistencies directly limit model performance—research on fine-tuning for automated program repair (arXiv:2507.19909) notes that human annotation agreement rates cap achievable accuracy.
If annotators only agree 70% of the time, the model can’t reliably exceed 70% accuracy regardless of training investment.
Experimentation Costs
Fine-tuning rarely succeeds on the first attempt. Hyperparameter tuning—learning rate, batch size, number of epochs—requires multiple training runs.
Budget for 3-5 iterations minimum. Each experimental run costs the same as production training.
Validation and Evaluation
For reinforcement fine-tuning approaches, validation during training incurs additional costs. OpenAI’s guidance on RFT billing explicitly calls out validation frequency as a cost driver—more frequent validation means higher bills.
Grader model selection matters too. Using a larger model to evaluate training checkpoints costs more per validation cycle than using smaller, faster graders.
Storage and Deployment
Model checkpoints consume storage. A 7B parameter model at 16-bit precision requires roughly 14GB disk space per checkpoint. Saving checkpoints every epoch across multiple experiments adds up.
Deployment infrastructure represents an ongoing cost. Self-hosting requires maintaining GPU nodes 24/7. API-based deployment shifts costs to per-token inference pricing.
Cloud vs Self-Hosted Cost Analysis
The build-versus-buy decision depends on utilization patterns and scale.
Cloud Provider Pricing
Major cloud platforms offer managed fine-tuning services and raw GPU compute. Managed services abstract infrastructure complexity but add markup. According to Stanford’s research computing resources documentation, Together AI’s managed training service provided the under $5 fine-tuning example—significantly cheaper than self-managing equivalent infrastructure.
Raw GPU rentals offer more control. AWS g5.xlarge instances (NVIDIA A10G) start around $1.50/hour. Multi-GPU instances for larger models scale proportionally: g5.12xlarge with 4x A10G GPUs costs roughly $6/hour.
Self-Hosting Economics
Consumer GPUs make local fine-tuning viable for smaller models. An RTX 4060 Ti 16GB handles 7B models with LoRA and quantization. Upfront cost hits $1,200-$1,600, but eliminates recurring charges.
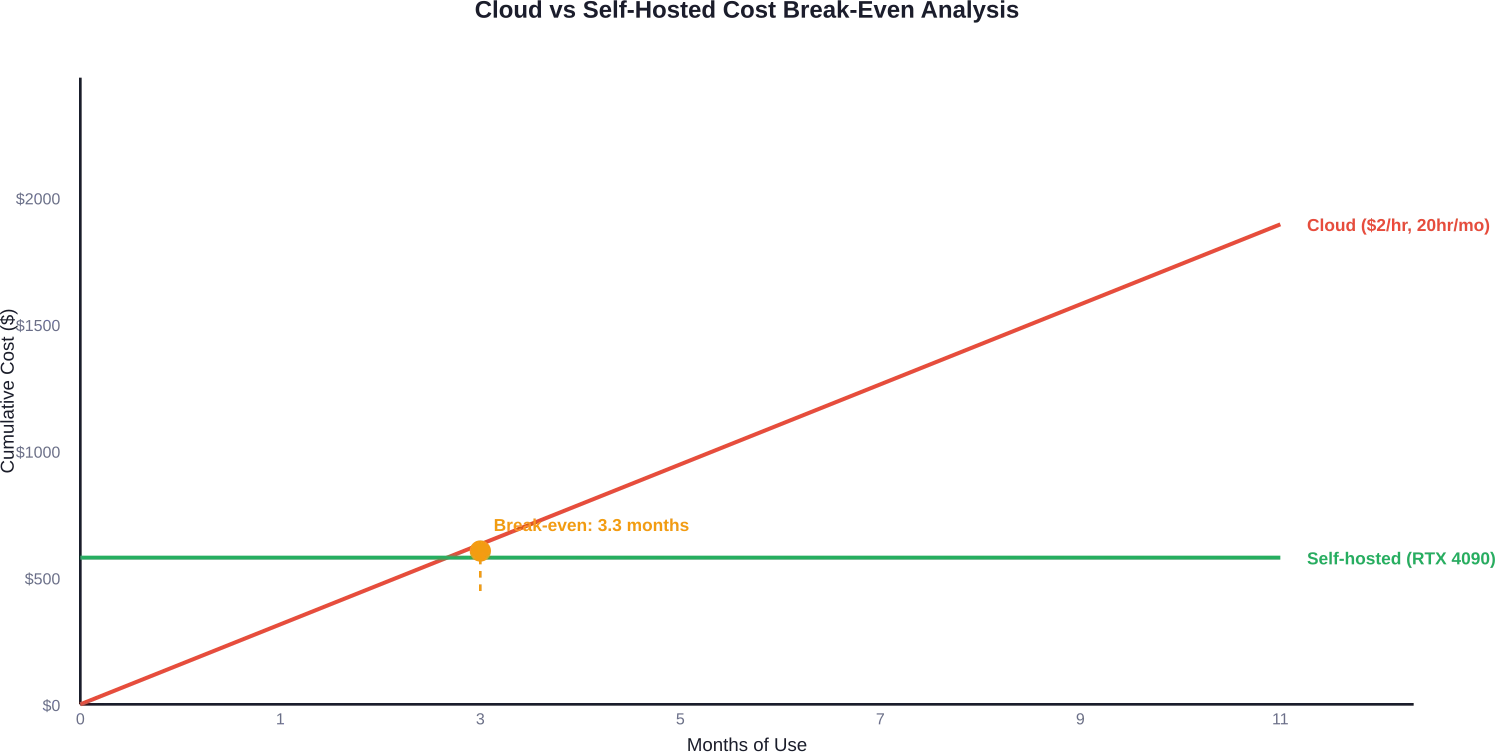
The math favors self-hosting when utilization exceeds 15-20 hours monthly. At $2/hour cloud rates, 20 hours monthly costs $480—meaning a $1,600 GPU pays for itself in under four months of consistent use.
But cloud offers flexibility for sporadic workloads. Running one fine-tuning job monthly for four hours ($8-$10 on cloud) doesn’t justify GPU ownership.
When Fine-Tuning Makes Financial Sense
Not every use case justifies fine-tuning investment.
Calculate Your Baseline
Compare fine-tuning costs against API alternatives. If a task requires 10 million inference tokens monthly, API costs at $0.001 per 1K tokens equal $10,000 annually. A one-time $2,000 fine-tuning investment that enables cheaper inference with smaller models delivers ROI within months.
But if prompt engineering achieves acceptable results with a base model, fine-tuning wastes resources.
Context Windows Change the Calculation
Modern models support 200K to 1M token context windows. Stuffing domain knowledge into prompts eliminates fine-tuning needs for many applications. When new base models release every 4-6 months, maintaining fine-tuned versions becomes a recurring expense.
Community discussions highlight this shift: teams increasingly prefer large context windows with well-engineered prompts over custom fine-tuning because switching to improved base models requires zero retraining.
Fine-Tuning Wins For
Specific scenarios still favor fine-tuning:
- Consistent output formatting that prompting can’t reliably enforce
- Specialized domain knowledge not present in base model training data
- Latency-critical applications where smaller fine-tuned models outperform larger base models
- High-volume inference where per-token API costs exceed one-time training investment
- Privacy requirements preventing external API use
Reducing Fine-Tuning Costs Without Sacrificing Quality
Several strategies cut expenses while preserving performance.
Start Small
Begin with the smallest model that might work. Fine-tune a 3B parameter model before attempting 7B or 13B variants. Performance might suffice—and costs stay under $500.
According to arXiv research on fine-tuning lightweight LLMs for financial sentiment classification (arXiv:2512.00946), 7-8B parameter models including DeepSeek-LLM 7B, Llama3 8B Instruct, and Qwen3 8B are evaluated against FinBERT on financial datasets. Smaller models deliver production-grade results for well-scoped tasks.
Use LoRA by Default
Start every fine-tuning project with LoRA unless compelling reasons dictate full fine-tuning. The 80-95% quality retention versus 70-95% cost reduction makes LoRA the obvious default choice.
Rank parameter tuning offers further optimization. Lower LoRA ranks (8-16) reduce costs versus higher ranks (32-64) with minimal accuracy impact for many tasks.
Optimize Training Duration
More epochs don’t guarantee better results. Monitor validation loss and stop training when improvement plateaus. Early stopping prevents wasted compute on marginal gains.
The MIT-IBM Watson AI Lab’s research on scaling laws indicates that 4 percent ARE is about the best achievable accuracy one could expect due to random seed noise, requiring careful compute budget allocation, but pushing beyond that point yields diminishing returns at exponentially higher cost.
Curate Training Data Aggressively
Five hundred high-quality examples beat 5,000 mediocre ones. Invest time in data quality upfront to reduce required training iterations.
Remove duplicates, fix formatting inconsistencies, and validate labels. Clean data trains faster and achieves better results, cutting both time and cost.
Consider Managed Services
Platform markup sometimes costs less than engineering time. Managed services handle infrastructure provisioning, monitoring, and checkpoint management. For teams without ML infrastructure expertise, managed platforms like Together AI or Hugging Face AutoTrain deliver faster results at lower total cost.
Frequently Asked Questions
How much does it cost to fine-tune GPT-3.5 or GPT-4?
OpenAI charges based on training tokens. GPT-3.5-turbo fine-tuning costs approximately $0.008 per 1K training tokens. A dataset with 100,000 training tokens costs roughly $0.80 to train. GPT-4 fine-tuning pricing is significantly higher—check OpenAI’s official pricing page for current rates as these change periodically.
Can I fine-tune LLMs on a laptop?
Smaller models (2-3B parameters) work on high-end laptops with 16GB+ unified memory or dedicated VRAM using 4-bit quantization and LoRA. Expect very slow training—hours to days depending on dataset size. Cloud GPUs remain more practical for most cases, but laptop fine-tuning is technically feasible for experimentation.
Is fine-tuning cheaper than using API calls long-term?
It depends on inference volume. Calculate monthly API costs at current usage, then compare to one-time fine-tuning investment plus inference costs with your fine-tuned model. For high-volume applications (millions of tokens monthly), fine-tuning often delivers ROI within months. For low-volume or experimental use, APIs cost less.
How often should I re-fine-tune my model?
Re-fine-tune when base models improve significantly or when performance degrades on new data patterns. Many teams skip re-fine-tuning altogether with modern large-context models, instead updating prompts when switching to newer base models. Evaluate whether fine-tuning advantages persist as context windows expand and base model capabilities improve.
What’s the difference between fine-tuning cost and inference cost?
Fine-tuning is a one-time training expense to customize the model. Inference cost refers to ongoing expenses each time the model generates predictions. Self-hosted models shift inference costs to fixed infrastructure, while API-based models charge per token processed. Factor both when calculating total cost of ownership.
Do I need multiple GPUs to fine-tune LLMs?
Not for models under 13B parameters when using LoRA and quantization. A single consumer GPU (RTX 3060 12GB or better) handles 7-8B models with PEFT techniques. Full fine-tuning of larger models or training beyond 13B parameters typically requires multi-GPU setups unless extreme quantization is acceptable.
How do I estimate fine-tuning costs before starting?
Identify model size, choose training technique (full vs LoRA), estimate training duration based on dataset size, and calculate GPU hours needed. Multiply GPU hours by cloud provider rates. Add 30-40% buffer for experimentation. Start with small pilot runs to validate estimates before committing to full training budgets.
Making the Fine-Tuning Decision
Fine-tuning costs span two orders of magnitude based on choices made upfront.
Successful teams start by questioning whether fine-tuning is necessary. Larger context windows and better base models solve problems that required fine-tuning just months ago. When fine-tuning proves necessary, parameter-efficient techniques like LoRA make custom models accessible at budgets under $100 for most use cases.
The expensive failures share common patterns: skipping data quality validation, choosing oversized models, and running full fine-tuning when LoRA would suffice.
Real talk: budget for experimentation. The first training run rarely produces production-ready results. Plan for 3-5 iterations, monitor costs actively, and optimize aggressively.
Ready to start fine-tuning within budget? Begin with the smallest viable model, use LoRA by default, and validate data quality before spending on compute. Your first successful fine-tuning teaches more than any guide.