Quick Summary: Training a large language model costs anywhere from $50,000 to over $500 million depending on model size, infrastructure, and training duration. Smaller models with 20 billion parameters might cost $50,000-$100,000, while massive systems like GPT-4 or Gemini can exceed $100 million. The biggest expenses are GPU compute time, data preparation, and cloud infrastructure.
The economics of training large language models have become a defining factor in AI development. Organizations now face critical decisions about whether to build their own models or subscribe to commercial services.
And the numbers? They’re staggering.
According to Epoch AI research, both GPT-4 and Google’s Gemini have cost hundreds of millions of dollars to train. These aren’t just incremental improvements over earlier models—the financial barrier has jumped dramatically in just the past few years.
Here’s the thing though—not every organization needs a frontier model. Understanding the cost structure helps determine the right approach for specific use cases.
What Drives Training Costs for Large Language Models
Training costs break down into several major categories, each contributing significantly to the total bill.
Compute Infrastructure
GPU hardware dominates the expense sheet. Models with around 100 billion parameters require advanced GPU hardware, such as NVIDIA’s A100 GPUs. For a 20 billion parameter model, the infrastructure typically needs 8-16 A100 80GB GPUs.
The compute cost alone runs $50,000-$100,000 for a smaller model. That baseline calculation—approximately $22,000 (16 A100s × $2.75/hr × 500 hours)—represents just the successful training run.
But wait.
Failed runs and experimentation easily double or triple that figure. Training large language models isn’t a one-shot process. Hyperparameter tuning, architecture experiments, and troubleshooting all consume additional compute time.
Time and Duration
Training duration scales with model size and complexity. A 20 billion parameter model might train in 500-1000 hours. Larger models measuring 120+ billion parameters can take several thousand GPU-hours.
Cloud infrastructure costs accumulate hourly. This means every optimization that reduces training time directly cuts expenses. Efficient hyperparameter selection, better data pipeline design, and reduced idle GPU time all matter financially.
Data Preparation and Management
High-quality training data doesn’t appear magically. Organizations invest heavily in data collection, cleaning, labeling, and curation. The gradual depletion of high-quality publicly available data has made this challenge more acute.
Data storage and transfer costs add up too. Moving massive datasets between storage systems and compute clusters incurs bandwidth and storage fees that many initial budgets underestimate.

Understand the Real Cost of Training an LLM
Training a large language model involves far more than compute resources. Data engineering, model experimentation, evaluation, and deployment infrastructure also affect total costs.
AI Superior helps organizations assess whether training a model from scratch is justified or if alternative approaches such as model adaptation or API integration are more practical.
Their services include:
- training pipeline design
- dataset strategy and validation
- infrastructure planning
- cost-benefit analysis of custom models
If you are exploring custom LLM development, a feasibility analysis can help prevent unnecessary training costs.
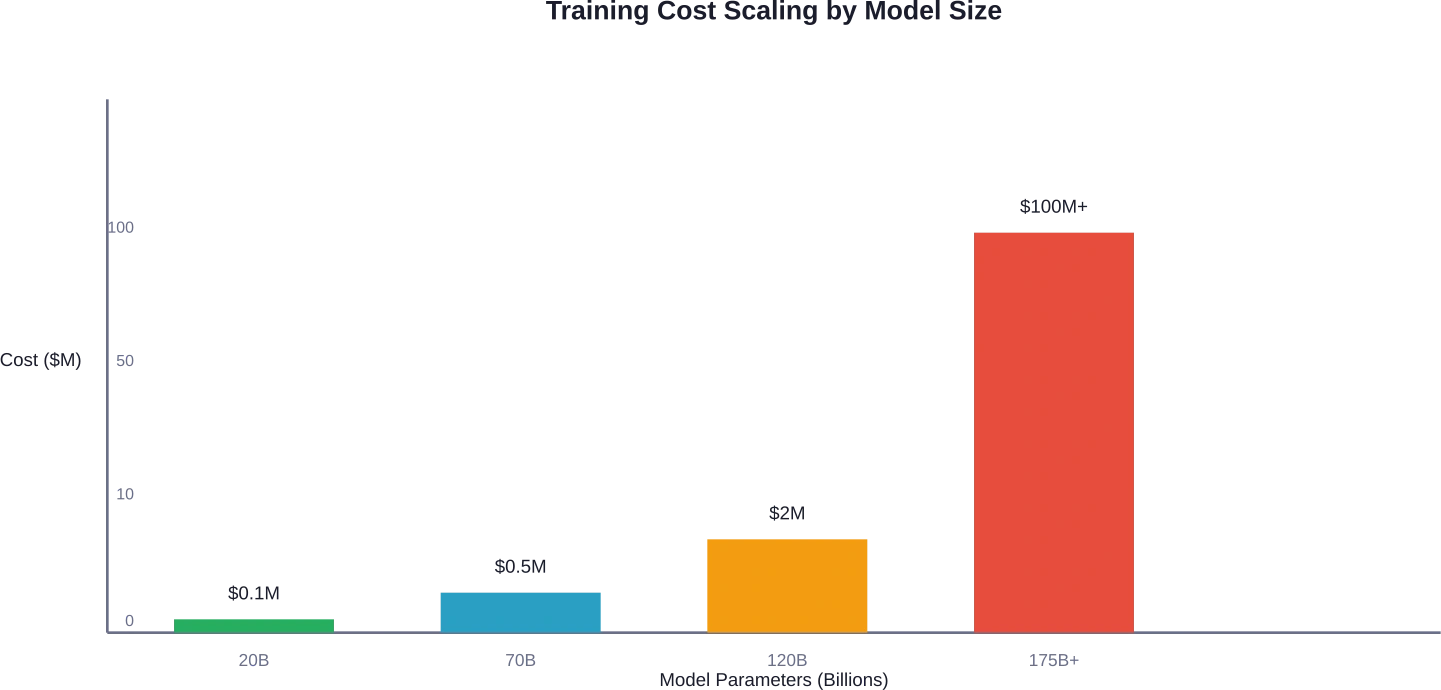
Real-World Cost Comparisons: 20B to 120B Parameters
Let’s break down actual cost ranges for different model scales.
| Model Size | GPU Requirements | Base Compute Cost | Total Estimated Cost |
|---|---|---|---|
| 20B parameters | 8-16 A100 80GB | $22,000-$50,000 | $50,000-$100,000 |
| 70B parameters | 32-64 A100 80GB | $100,000-$250,000 | $200,000-$500,000 |
| 120B+ parameters | 64-128+ A100 80GB | $300,000-$800,000 | $500,000-$2,000,000 |
| Frontier models (175B+) | 1000+ GPUs | $50M-$200M+ | $100M-$500M+ |
The gap between small and large models isn’t linear—it’s exponential. A 120B parameter model costs roughly 5-20 times more than a 20B model, not just because of parameter count but due to training complexity, longer convergence times, and infrastructure overhead.
The Frontier Model Premium
Systems like GPT-4 and Gemini operate in a completely different cost tier. According to Epoch AI data, these models have cost hundreds of millions of dollars to develop.
Why such astronomical figures?
Frontier models require massive GPU clusters running for months. They incorporate extensive experimentation, multiple training runs, safety testing, and alignment work. The infrastructure alone—managing thousands of GPUs simultaneously—demands sophisticated orchestration systems.
Breaking Down Infrastructure Expenses
Infrastructure costs extend beyond raw GPU rental. Organizations need to account for the complete stack.
GPU Hardware Options
NVIDIA’s A100 GPUs remain the standard for LLM training, though newer H100 and H200 variants offer better performance at higher prices. The choice depends on availability, budget, and timeline.
Cloud providers charge different rates. AWS, Google Cloud, and Microsoft Azure each have distinct pricing structures for GPU instances. Specialized providers focusing on AI workloads sometimes offer better rates for sustained usage.
Storage and Networking
Model checkpoints, training data, and logs consume substantial storage. A 120B parameter model generates checkpoint files exceeding 500GB each. Organizations typically save multiple checkpoints throughout training for recovery and analysis.
Network bandwidth matters too. Data transfer between storage and compute, especially for distributed training across multiple nodes, can add thousands of dollars to the monthly bill.
Hosting and Deployment
Training costs are just the beginning. Hosting these models for inference incurs ongoing expenses. For models with around 100 billion parameters, hosting costs range from $50,000 to $500,000 per year depending on model size and usage patterns.
The widely quoted development costs for distilled models like DeepSeek-V3 may exclude expenses of training more powerful teacher models from which they were derived, illustrating how accounting approaches can obscure total development investments.
Optimization Strategies to Reduce Training Costs
Several techniques can dramatically cut training expenses without sacrificing model quality.
Quantization and Mixed Precision
FP4 quantization frameworks for LLMs have demonstrated the potential to achieve accuracy comparable to BF16 and FP8 with minimal degradation on large-scale models. This technology reduces memory requirements and speeds up computation, directly lowering GPU time needed.
Mixed precision training has become standard practice. Using lower precision for certain operations while maintaining higher precision where it matters balances speed and accuracy effectively.
Low-Rank Training Methods
Applying low-rank parametrization to Transformer-based LLMs reduces computational costs and can actually improve performance in some cases. These methods compress the parameter space while maintaining model expressiveness.
Efficient Data Strategies
Research on Chinchilla-optimal scaling laws indicates that an LLM developer training a 13B model expecting 2 trillion tokens of inference demand could potentially reduce total compute by approximately 1.7×10²² FLOPs (17%) by training smaller models longer.
The key insight? Training slightly longer with more data can reduce inference costs later if the model will serve many requests. Total cost of ownership matters more than just training cost.

Spot Instances and Preemptible VMs
Cloud providers offer discounted spot instances that can be interrupted. For fault-tolerant training workflows with regular checkpointing, spot instances cut costs by 40-70% compared to on-demand pricing.
The tradeoff? Training might take longer due to interruptions. But with proper checkpoint management, the savings usually justify the complexity.
The Build vs. Buy Decision
Organizations face a fundamental choice: train their own model or use commercial services.
When Commercial Services Make Sense
For most use cases, subscribing to commercial LLM services proves more economical. APIs from OpenAI, Anthropic, and Google provide access to frontier models without upfront capital investment.
According to cost-benefit analysis research, organizations need significant sustained usage to break even with commercial services. Studies suggest performance parity thresholds around 20% of leading commercial models mark viable breakeven points for infrastructure investment.
When Training Makes Sense
Custom training becomes attractive when:
- Domain-specific requirements demand specialized training data
- Data privacy regulations prevent sending information to third-party APIs
- Expected inference volume exceeds millions of requests monthly
- Fine-tuning commercial models proves insufficient for the use case
Organizations expecting heavy sustained usage over multiple years can achieve better total cost of ownership with self-hosted models. The break-even point depends on model size, request volume, and required performance levels.
Test-Time Compute Considerations
Recent research on test-time compute allocation reveals another cost dimension. Inference expenses can exceed training costs for widely-deployed models.
Adaptive allocation strategies that dynamically assign compute based on query difficulty improve efficiency substantially. Training-free difficulty proxies help distribute fixed compute budgets across test queries, maximizing solved instances while adhering to budget constraints.
Research on efficient agents shows that optimal framework design matters enormously. One study found a framework retaining 96.7% performance of a leading open-source agent while reducing operational costs from 0.398 to 0.228—a 28.4% improvement in cost-of-pass.
Accounting Principles for AI Development Costs
Policymakers increasingly use development cost and compute as proxies for AI capabilities and risks. Recent laws introduce regulatory requirements contingent on specific cost thresholds.
But here’s the problem: technical ambiguities in cost accounting create loopholes. Narrow accounting can obscure a model’s total development costs. The widely quoted development costs for distilled models like DeepSeek-V3 may exclude expenses of training more powerful teacher models from which they were derived.
Organizations should adopt comprehensive accounting that includes:
- All training runs, including failed experiments
- Data acquisition, cleaning, and preparation costs
- Infrastructure overhead and networking
- Engineering time for architecture development
- Safety testing and alignment work
- Costs of teacher models for distillation approaches
| Cost Category | Typical % of Total | Often Overlooked? |
|---|---|---|
| GPU Compute (successful run) | 30-40% | No |
| Failed experiments | 15-25% | Yes |
| Data preparation | 10-15% | Yes |
| Storage & networking | 5-10% | Yes |
| Engineering labor | 20-30% | Sometimes |
| Safety & alignment | 5-10% | Yes |
Future Cost Trends
Several factors will influence training costs in coming years.
GPU hardware continues advancing. NVIDIA’s Blackwell architecture—including B100, B200, and GB200 variants—promises better performance per dollar. But demand keeps prices elevated.
Data costs are rising. As high-quality public data becomes scarcer, organizations invest more in proprietary datasets, synthetic data generation, and data licensing agreements.
That said, algorithmic improvements and training efficiency gains partially offset hardware costs. The research community continually develops better optimization methods, scaling laws, and architecture designs.
Frequently Asked Questions
How much does it cost to train a 70B parameter model?
Training a 70 billion parameter model typically costs between $200,000 and $500,000. This includes base compute costs of $100,000-$250,000 for 32-64 A100 GPUs, plus additional expenses for failed runs, experimentation, data preparation, and infrastructure overhead.
Can smaller organizations afford to train large language models?
Smaller organizations can train modest-sized models (1-20 billion parameters) for $10,000-$100,000 using cloud GPU resources and optimization techniques. However, for most applications, using commercial API services or fine-tuning existing open-source models proves more cost-effective than training from scratch.
What’s the most expensive part of training an LLM?
GPU compute time represents 30-40% of total costs for most projects. However, when accounting for failed experiments and hyperparameter tuning, compute-related expenses often exceed 50% of the total budget. Engineering labor typically accounts for another 20-30%.
How long does it take to train a large language model?
Training duration varies dramatically by model size. A 20B parameter model might train in 500-1000 GPU-hours (roughly 3-6 weeks on a 16-GPU cluster). Larger 120B+ models can require several thousand GPU-hours, extending training to 2-4 months. Frontier models with 175B+ parameters often train for several months on massive clusters.
Is it cheaper to train once or use API calls long-term?
This depends entirely on usage volume. For applications making fewer than 10 million API calls monthly, commercial services typically cost less. Organizations with sustained high-volume usage—especially those needing specialized models or having data privacy requirements—may find self-training more economical over multi-year periods.
What’s the difference between training cost and inference cost?
Training cost is the one-time expense to develop the model, ranging from thousands to hundreds of millions of dollars. Inference cost is the ongoing expense to run the model for predictions, charged per request or token. For widely-deployed models, total inference costs over the model’s lifetime often exceed training costs.
How can I reduce LLM training costs?
Key cost reduction strategies include using quantization (FP4/FP8 training), leveraging spot instances for 40-70% savings, implementing efficient checkpointing to minimize wasted compute, optimizing data pipelines to reduce idle GPU time, and considering model distillation from larger teacher models when appropriate.
Making the Investment Decision
Training large language models remains expensive, but the costs exist on a spectrum. Organizations don’t face a binary choice between frontier models and nothing.
A realistic assessment starts with use case requirements. What performance level actually solves the business problem? Does the application require cutting-edge capabilities, or would a smaller specialized model suffice?
For many applications, models in the 7-20 billion parameter range deliver excellent results at manageable costs. These systems can be trained for $50,000-$200,000, making them accessible to mid-sized organizations with specific domain needs.
The frontier model race—pushing toward 175B+ parameters and beyond—makes sense primarily for companies building general-purpose AI platforms. For everyone else, the sweet spot often lies in smaller, specialized models optimized for particular tasks.
Look at the total cost of ownership. Training represents just the beginning. Factor in hosting, inference costs, ongoing maintenance, and the engineering team needed to support the system.
The economics of LLM development continue evolving. Hardware improves, algorithms become more efficient, and new training techniques emerge regularly. What costs $500,000 today might cost $200,000 in two years—or might deliver 3x better performance for the same price.
Organizations entering this space should start small, measure carefully, and scale based on demonstrated value. The technology has matured enough that experimentation no longer requires massive upfront investment. Prototype with smaller models, validate the approach, then decide whether scaling up or sticking with commercial APIs makes more sense.
The AI revolution continues accelerating, but smart deployment beats pure scale. Understanding these cost structures helps organizations make informed decisions rather than chasing benchmarks that may not matter for their specific applications.