Quick Summary: Monitoring LLM app costs requires tracking token usage, model selection, and request patterns in real-time to prevent budget overruns. Leading tools like Datadog LLM Observability, Langfuse, and cloud-native solutions from AWS Bedrock and OpenAI provide cost attribution, usage analytics, and optimization recommendations. Effective monitoring combines observability platforms with strategic practices like prompt optimization, model selection, and caching.
As generative AI applications move from prototype to production, token costs can spiral out of control. A single unoptimized prompt chain can multiply expenses by 10x, and without real-time visibility into usage patterns, teams often discover budget overruns only when the invoice arrives.
Traditional cloud cost monitoring doesn’t cut it for LLM applications. Token-based pricing models require specialized observability that tracks not just compute time, but input tokens, output tokens, model selection, and request frequency across different providers.
This creates a fundamental challenge: how do teams maintain visibility into LLM costs without sacrificing development velocity or application performance?
Why LLM Cost Monitoring Matters
The token-based pricing model fundamentally changes how application costs scale. Unlike traditional infrastructure where costs correlate with server uptime, LLM expenses depend on the volume and complexity of every single request.
According to AWS documentation published in October 2025 (Build a proactive AI cost management system for Amazon Bedrock), organizations face challenges managing costs associated with token-based pricing that can lead to unexpected bills if usage isn’t carefully monitored. Traditional methods like budget alerts and cost anomaly detection often react too late.
Here’s what makes LLM cost management different:
- Token consumption varies wildly based on prompt length and response complexity
- Different models carry drastically different price points (Amazon Nova Micro costs $0.000035 per 1,000 input tokens and $0.00014 per 1,000 output tokens versus larger models at higher rates)
- Multi-step agent workflows compound costs through multiple LLM calls
- Production usage patterns rarely match development estimates
Real talk: most teams only discover they have a cost problem after running up thousands in charges. Proactive monitoring prevents that scenario entirely.
Understanding Token Economics
Token pricing isn’t uniform across models or providers. The economics depend heavily on which foundation model powers the application and how requests are structured.
OpenAI’s documentation shows that audio tokens in user messages count as 1 token per 100ms of audio, while assistant messages use 1 token per 50ms. These variations matter when building multimodal applications.
Amazon Nova models demonstrate the pricing spectrum clearly. As documented in AWS materials from June 2025:
| Model | Input Tokens (per 1,000) | Output Tokens (per 1,000) |
|---|---|---|
| Amazon Nova Micro | $0.000035 | $0.00014 |
| Larger Nova variants | Higher rates | Proportionally scaled |
The largest model isn’t always necessary for every task. Matching model capability to use case complexity directly impacts costs.
Anthropic provides a Usage and Cost API that enables programmatic access to organizational spending data. This allows teams to build custom dashboards and automated cost controls.

Implement LLM Monitoring Systems
LLM applications require monitoring to track usage, performance, and operational stability.
AI Superior builds monitoring and management tools for production AI systems, helping organizations operate LLM-based applications more efficiently.
Their development work can include:
- usage tracking systems
- prompt and response analytics
- infrastructure monitoring
- AI system optimization tools
AI Superior helps teams move LLM applications from prototype to stable production environments.
Core Components of LLM Cost Monitoring
Effective monitoring systems track multiple dimensions simultaneously. Token usage alone doesn’t tell the complete story.
Token Usage Tracking
Every request generates both input and output tokens. Monitoring systems need to capture both dimensions and attribute them to specific users, features, or workflows.
Input token counts depend on prompt engineering choices. Verbose system prompts or excessive context injection inflate costs per request. Output tokens vary based on model parameters like temperature and max_tokens settings.
Google’s Apigee documentation describes LLM token policies as crucial for cost control, leveraging token usage metrics to enforce limits and provide real-time monitoring. The platform allows setting prompt token limits, such as restricting requests to 1,000 tokens per minute.
Model Selection Attribution
Applications that use multiple models need cost attribution by model type. A routing decision that sends simple queries to an expensive model wastes budget.
Model cascading strategies can optimize costs by attempting cheaper models first and escalating only when necessary. Monitoring must track which model handled each request and the associated cost differential.
Request Pattern Analysis
Temporal patterns reveal optimization opportunities. Batch processing during off-peak hours, request throttling during traffic spikes, and identifying redundant calls all require historical pattern data.
AWS testing documented in October 2025 showed workflow execution times ranging from 6.76 to 32.24 seconds based on output token requirements. Understanding these patterns helps capacity planning.
Top LLM Cost Monitoring Tools
Several platforms have emerged as leaders in LLM observability and cost management. Each brings different strengths depending on deployment architecture and provider ecosystem.
Datadog LLM Observability
Datadog’s platform integrates with major LLM providers including OpenAI, Anthropic, and Amazon Bedrock, as documented in AWS partnership materials. AWS documentation from July 2025 (Monitor agents built on Amazon Bedrock with Datadog LLM Observability) describes how Datadog monitors agents built on Bedrock with full observability capabilities.
The platform tracks token usage, latency, and costs across all LLM calls in a centralized dashboard. Traces capture multi-step agent workflows, showing how costs accumulate through complex chains.
Key capabilities include real-time cost attribution, performance monitoring, and anomaly detection. Teams can set budget alerts and visualize spending trends over time.
Pricing varies based on usage volume, with custom enterprise plans available for large-scale deployments.
Langfuse
Langfuse offers open-source LLM observability with the option to self-host. The platform provides session-based views that tie related LLM requests together, making it easier to understand user journeys.
Strong observability for multi-step chains and agent workflows sets Langfuse apart. Hierarchical tracing shows parent-child relationships between LLM calls, while cost tracking attributes spending to specific traces or sessions.
Community discussions highlight that while the self-hosted option provides full control, the cloud version starts at $29/month with usage-based pricing beyond the base tier, with free self-hosted option available.
Amazon Bedrock Native Tools
AWS built cost management directly into Bedrock. The October 2025 documentation describes a proactive AI cost management system that goes beyond traditional budget alerts.
The workflow maintains consistent execution patterns while processing requests with varying duration (6.76 to 32.24 seconds based on output token requirements). This native integration means no separate observability platform is required for Bedrock workloads.
Cost optimization strategies documented in June 2025 emphasize model selection as a primary lever. Choosing the right Nova model variant can reduce costs dramatically without sacrificing application quality.
OpenAI Cost Management Tools
OpenAI provides native usage tracking through the API dashboard and programmatic access via usage endpoints. The Realtime API documentation explains how costs accrue across different modalities: text, audio, and images.
Audio token calculations differ by message type (1 token per 100ms for user messages, 1 token per 50ms for assistant messages). Understanding these nuances prevents surprise charges in voice-enabled applications.
The platform offers budget limits and notification thresholds configurable at the organization and project level.
Anthropic Usage and Cost API
Anthropic’s approach provides programmatic access to organizational usage data through a dedicated API. This enables custom cost monitoring integrations without relying on third-party platforms.
Claude Code documentation from Anthropic shows the /cost command provides detailed token usage statistics including total cost ($0.55 example), API duration, and code changes. This granular data helps developers understand exactly what drives spending in their applications.
Rate limiting and team spend controls allow administrators to cap usage at the organizational level.
Cloud-Native Monitoring Solutions
Major cloud providers have integrated LLM cost monitoring into their broader observability platforms.
Azure Monitor
Azure’s monitoring extends to Azure OpenAI Service deployments. The platform tracks token consumption, request rates, and costs across all deployed models.
Integration with Azure Cost Management provides unified visibility into both infrastructure and LLM expenses, making it easier to understand total application costs.
Google Cloud and Apigee
Google’s approach uses Apigee LLM token policies for cost control. These policies enforce limits based on token usage metrics and provide real-time monitoring of prompt token consumption.
The documentation describes implementing rate limits like 1,000 tokens per minute using PromptTokenLimit policies. This prevents runaway costs from unexpected traffic spikes.
Hugging Face Infrastructure
Hugging Face pricing published in January 2026 shows a spectrum from free tier to enterprise solutions. Inference Endpoints charge based on compute time multiplied by hardware price.
A request that takes 10 seconds on a GPU costing $0.00012 per second results in a $0.0012 charge, as documented in Hugging Face pricing guides. Understanding this compute-time model differs from token-based pricing and requires different monitoring approaches.
The platform provides usage dashboards showing compute consumption, but community discussions from April 2025 reveal confusion about translating runtime to exact costs. Better documentation of the conversion formula would help.
| Platform | Pricing Model | Monitoring Features | Best For |
|---|---|---|---|
| Datadog | Usage-based | Unified observability, traces, alerts | Multi-provider environments |
| Langfuse | Free self-host, $29+ cloud | Session tracking, hierarchical traces | Open-source preference |
| AWS Bedrock | Included with service | Native integration, request patterns | AWS-native deployments |
| OpenAI Native | Included | Usage dashboard, API access | OpenAI-exclusive apps |
| Anthropic API | Included | Programmatic cost data | Claude-based applications |
Cost Optimization Strategies
Monitoring identifies problems. Optimization fixes them. Several strategies consistently reduce LLM costs without compromising functionality.
Prompt Engineering
Concise prompts reduce input token counts. Research shows that smelly code leads to significantly higher token consumption during inference compared to clean code, with median token consumption of 28.13 for clean code versus 33.30 for smelly code.
Removing unnecessary context, using clear instructions, and structuring prompts efficiently all lower per-request costs. Testing different prompt formulations and measuring token usage identifies the most efficient approaches.
Model Selection
Task-specific models often outperform general-purpose models on cost-effectiveness. AWS documentation emphasizes that the largest model isn’t always necessary for every application.
A cascading approach tries cheaper models first and escalates only when accuracy falls below thresholds. This balances cost and quality dynamically.
Research on cost-benefit analysis defines performance parity as benchmark scores within 20% of top commercial models, reflecting enterprise norms where small accuracy gaps are offset by cost, security, and integration benefits.
Caching Strategies
Response caching for repeated queries eliminates redundant LLM calls entirely. Semantic caching goes further by recognizing similar (not just identical) queries and returning cached responses.
OpenAI’s cost optimization documentation highlights caching as a primary strategy. The Batch API and flex processing provide additional cost reduction mechanisms for non-time-sensitive workloads.
Strategic Throttling
Rate limiting prevents cost spikes during unexpected traffic surges. Apigee’s token policies enforce limits that protect against runaway spending.
Queue-based architectures absorb traffic spikes without immediately scaling LLM usage. This trades some latency for predictable costs.
Implementation Best Practices
Deploying cost monitoring requires both technical integration and organizational process.
Instrumentation Approach
Instrument LLM calls at the SDK level rather than trying to scrape provider dashboards. Direct integration captures request metadata like user IDs, feature flags, and session contexts that enable granular cost attribution.
Most observability platforms provide SDKs or OpenTelemetry integrations that automatically capture traces. Manual instrumentation gives more control but requires more engineering effort.
Alert Configuration
Set tiered alerts based on absolute spending thresholds and percentage increases. A $100 daily budget alert catches gradual creep, while a 200% hour-over-hour increase alert catches sudden spikes.
AWS cost anomaly detection works for infrastructure but often reacts too late for token-based costs. Real-time monitoring from specialized LLM observability platforms catches problems faster.
Team Education
Developers need visibility into the cost implications of their choices. Showing token counts and estimated costs during development helps build cost awareness.
Claude Code documentation shows the /cost command provides session-level statistics including total cost, duration, and code changes. Building similar feedback loops into internal tools drives better decisions.
Regular Audits
Monthly cost reviews identify optimization opportunities and validate that controls work as intended. Tracking cost per user, cost per feature, and cost per transaction reveals where spending concentrates.
Comparing actual costs against initial estimates highlights planning gaps and improves future forecasts.
Measuring ROI and Success
Cost monitoring itself costs time and resources. Teams need clear metrics to justify the investment.
Key performance indicators include:
- Cost per application function or user session
- Percentage reduction in token consumption after optimization
- Mean time to detect cost anomalies
- Variance between budgeted and actual spending
Research on efficient agents achieved 96.7% of the performance of OWL while reducing operational costs from $0.398 to $0.228, resulting in a 28.4% improvement in cost-of-pass (from arXiv: Efficient Agents).
The goal isn’t minimizing costs at any expense. It’s maximizing value delivered per dollar spent. Sometimes higher costs deliver proportionally higher value.
Common Pitfalls to Avoid
Several mistakes consistently undermine cost monitoring efforts.
Monitoring in isolation without optimization action wastes effort. Data without decisions doesn’t reduce spending. Build feedback loops that turn insights into prompt changes, model selections, or architecture improvements.
Over-optimizing too early in development slows iteration velocity. Wait until usage patterns stabilize before aggressive optimization. Premature optimization based on prototype usage rarely reflects production reality.
Ignoring opportunity costs matters too. Developer time spent optimizing a $50/month expense might cost more than just paying the bill. Focus optimization efforts where spending concentrates.
Forgetting about latency trade-offs creates new problems. Aggressive caching or model downselection might reduce costs but increase response times enough to hurt user experience. Monitor both dimensions together.
Future Trends in LLM Cost Management
The cost monitoring landscape continues evolving rapidly as the technology matures.
Probabilistic cost constraints represent an emerging approach. ArXiv research on optimized model cascades describes C3PO, a system that optimizes LLM selection with probabilistic cost constraints for reasoning tasks. This goes beyond simple thresholds to sophisticated cost-quality trade-off optimization.
Multi-provider routing based on real-time pricing will become more common. As model capabilities converge, price competition intensifies. Systems that dynamically route requests to the cheapest provider offering sufficient quality will provide competitive advantages.
Specialized hardware for inference continues improving price-performance ratios. Hugging Face pricing documents Intel Sapphire Rapids x1 instances starting at $0.033/hour (as of source material date). Custom AI accelerators from cloud providers keep pushing costs down.
But wait. Lower base prices don’t eliminate monitoring needs. They shift optimization focus from gross spending to efficiency metrics like cost per successful task completion.
Frequently Asked Questions
How do I calculate the cost of an LLM API request?
Multiply input tokens by the model’s input token price, then add output tokens multiplied by the output token price. For example, with Amazon Nova Micro at $0.000035 per 1,000 input tokens and $0.00014 per 1,000 output tokens, a request with 500 input tokens and 1,500 output tokens costs approximately $0.0000175 + $0.00021 = $0.0002275.
What’s the difference between LLM monitoring and traditional APM?
Traditional application performance monitoring focuses on infrastructure metrics like CPU, memory, and request latency. LLM monitoring adds token consumption, model selection, prompt patterns, and cost attribution specific to generative AI workloads. Many platforms now integrate both capabilities.
Can I monitor costs across multiple LLM providers?
Yes. Platforms like Datadog LLM Observability support multiple providers including OpenAI, Anthropic, and Amazon Bedrock in a unified dashboard. This enables cost comparison and multi-provider routing strategies.
How much can cost optimization realistically save?
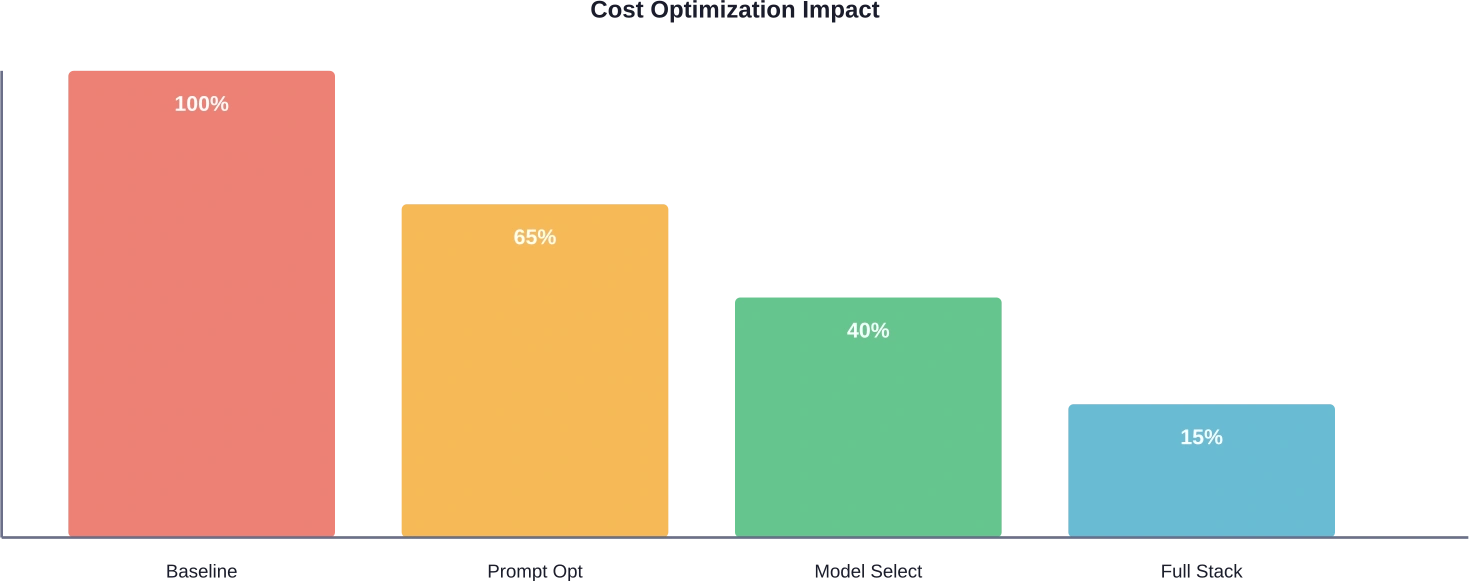
Optimization results vary by application. AWS testing showed potential cost savings of up to 90% for Step Functions Express workflow compared to Standard workflow on the same workload. Prompt engineering typically reduces costs 20-40%, model selection another 30-50%, and caching eliminates redundant calls entirely. The exact savings depend on baseline efficiency and optimization effort.
Should I self-host models to reduce costs?
Self-hosting makes sense at sufficient scale. ArXiv research on cost-benefit analysis shows break-even points depend on usage volume, technical capabilities, and whether performance parity with commercial models is achievable. For many organizations, managed services remain more cost-effective when engineering time is factored in.
How often should I review LLM costs?
Check real-time dashboards daily during initial deployment to catch configuration issues early. Conduct detailed cost reviews weekly during active development and monthly once usage stabilizes. Set automated alerts for anomalies rather than relying solely on scheduled reviews.
What metrics matter most for LLM cost management?
Track cost per user session, cost per successful task completion, token efficiency (output value per token), and cost variance from budget. These metrics connect spending directly to business outcomes rather than treating costs as abstract infrastructure expenses.
Moving Forward with LLM Cost Monitoring
Managing LLM application costs requires continuous visibility, strategic optimization, and organizational discipline. The token-based pricing model fundamentally differs from traditional infrastructure costs, demanding specialized monitoring approaches.
Start with native monitoring tools from providers like OpenAI, Anthropic, or AWS Bedrock. These built-in capabilities provide baseline visibility without additional platform costs. As applications scale, consider dedicated observability platforms like Datadog or Langfuse for advanced features like multi-provider support and sophisticated alerting.
The real value comes from connecting monitoring to action. Track costs, identify optimization opportunities through prompt engineering and model selection, and measure the impact of changes. Build feedback loops that help developers understand cost implications during development rather than discovering problems in production.
Cost optimization isn’t about minimizing spending at any cost. It’s about maximizing the value delivered per dollar spent while maintaining quality and performance standards. The right monitoring foundation makes that balance achievable.
Ready to take control of LLM spending? Start by instrumenting applications with basic token tracking today. Small improvements compound quickly when applied consistently across all LLM calls.