Quick Summary: LLM cost monitoring helps organizations track token usage, prevent budget overruns, and optimize spending across AI workloads. By implementing real-time visibility into model usage patterns, teams can identify costly inefficiencies before they spiral out of control. The right monitoring solution provides granular cost breakdowns, usage analytics, and governance controls essential for production deployments.
Large language models have moved from experimental projects to production systems powering everything from customer support to content generation. But here’s the thing—without proper monitoring, costs can balloon overnight.
A single unoptimized prompt chain can multiply expenses by up to 10x. Teams often discover these budget overruns only after billing cycles close, when the damage is already done.
This isn’t just about saving money. Cost monitoring provides the visibility needed to make informed decisions about model selection, prompt engineering, and infrastructure choices. Organizations deploying AI workloads at scale need comprehensive tracking as a non-negotiable operational requirement.
Why Cost Monitoring Matters for LLM Deployments
Token-based pricing means every API call carries a cost. Unlike traditional software where compute expenses remain relatively predictable, LLM spending varies dramatically based on usage patterns, prompt complexity, and model selection.
The transition from prototype to production amplifies this challenge. What worked fine during testing with a handful of queries becomes financially unsustainable at scale. Without continuous visibility, optimization becomes guesswork.
Real-world deployment scenarios create additional complexity. Multiple teams might use different models across various applications. Some workflows involve chained calls where one LLM output feeds into another. RAG pipelines pull data from vector databases before generating responses, adding layers of compute cost.
Cost monitoring solves three critical problems. First, it prevents surprise bills by tracking spending in real-time rather than retrospectively. Second, it identifies optimization opportunities by revealing which prompts, models, or users consume the most tokens. Third, it enables governance by setting budgets and alerts at the project, team, or organizational level.
Key Metrics for Tracking LLM Costs
Effective monitoring requires tracking the right metrics. Token consumption sits at the foundation—both input tokens (the prompt) and output tokens (the generated response). Different models charge different rates per token, so raw token counts don’t tell the complete story.
Cost per request provides a normalized view. This metric helps compare the financial efficiency of different approaches. A request that uses a more expensive model but generates fewer tokens might cost less than a cheaper model with verbose output.
Usage patterns reveal important trends. Peak usage times, request volume by application, and token consumption by user or team expose where spending concentrates. These patterns often highlight unexpected inefficiencies.
Model selection directly impacts costs. Model selection directly impacts costs. Newer models generally cost more than older ones. Open-source models deployed on-premise carry infrastructure costs instead of per-token charges. Tracking which models handle which workloads exposes optimization opportunities.
Error rates matter more than most teams realize. Failed API calls still consume tokens—and budget. High error rates indicate integration problems, but they also represent wasted spending that could be eliminated through better error handling.
On-Premise Versus Commercial LLM Services
Organizations face a fundamental decision: subscribe to commercial services or deploy models on their own infrastructure. According to research analyzing this trade-off, the choice involves multiple cost factors beyond simple per-token pricing.
Commercial services from providers like OpenAI, Anthropic, and Google offer attractive simplicity. Teams pay for tokens used without worrying about infrastructure, model updates, or operational overhead. This approach scales easily but costs accumulate linearly with usage.
On-premise deployment requires upfront infrastructure investment. Based on cost-benefit analysis research, organizations need to consider hardware acquisition, power consumption, cooling, maintenance, and staffing. The break-even point depends on usage volume—high-volume deployments often benefit from on-premise models while lower volumes favor commercial APIs.
Research on cost-benefit analysis of on-premise LLM deployment establishes criteria for model selection including performance parity within 20% of top commercial models. This threshold reflects enterprise norms where small accuracy gaps get offset by cost savings, security benefits, and integration flexibility.
Hidden Costs in Both Approaches
Commercial services carry hidden costs beyond token pricing. Rate limits might force upgrades to premium tiers. Data egress fees apply when processing large volumes. Multiple team members needing access inflate subscription costs.
On-premise deployments have their own hidden expenses. Model fine-tuning requires data scientists. Infrastructure needs redundancy for reliability. Updates and patches demand ongoing attention. Security and compliance overhead increases with self-hosted solutions.
Monitoring becomes essential regardless of deployment choice. Commercial APIs need tracking to prevent runaway costs. On-premise systems require monitoring to optimize resource utilization and justify infrastructure investments.
Essential Tools and Technologies
Multiple monitoring solutions have emerged to address LLM cost tracking needs. These tools vary in features, complexity, and ideal use cases.
LiteLLM provides a unified interface across multiple LLM providers. It standardizes API calls while tracking tokens and costs centrally. Teams working with several providers benefit from consolidated monitoring rather than checking multiple dashboards.
Langfuse offers open-source observability specifically designed for LLM applications. It tracks costs alongside quality metrics, providing insight into the relationship between spending and output quality. The platform supports complex workflows including RAG pipelines and multi-step agent chains.
Datadog LLM Observability extends existing infrastructure monitoring to AI workloads. Organizations already using Datadog can add LLM tracking without introducing new tools. The integration connects cost data with broader system performance metrics.
| Solution Type | Best For | Key Strength | Consideration |
|---|---|---|---|
| Unified Proxy | Multi-provider setups | Single interface for all LLMs | Adds latency layer |
| Open-Source Platform | Customization needs | Full control and transparency | Requires self-hosting |
| Enterprise Observability | Large organizations | Integrates with existing tools | Higher cost structure |
| Provider Native API | Single vendor usage | Most accurate data | Limited cross-provider view |
Provider-native solutions offer programmatic access to organization API usage and cost data. This approach works well when standardizing on one provider but creates blind spots in multi-vendor environments.

Build LLM Systems with Clear Usage Monitoring
LLM-powered applications require proper monitoring and infrastructure to manage requests, usage, and system performance. AI Superior develops AI platforms where large language models are integrated with backend services, data pipelines, and analytics tools. Their engineers build systems that support reliable model deployment, logging, and performance monitoring inside production environments.
Deploying an LLM System in Production?
Talk with AI Superior to:
- design LLM infrastructure and backend services
- build NLP applications powered by language models
- integrate monitoring and analytics into AI systems
👉 Contact AI Superior to discuss your AI development project.
Implementing Real-Time Cost Tracking
Real-time monitoring provides immediate visibility instead of retrospective analysis. This capability enables proactive cost management rather than reactive damage control.
The implementation typically involves three components. First, instrumentation captures token counts from every LLM call. Second, a central database aggregates this data with associated metadata like user, application, and timestamp. Third, dashboards visualize spending patterns and trigger alerts when thresholds are exceeded.
PostgreSQL databases often serve as the storage layer for cost monitoring systems. The database holds token counts, cost calculations, and usage metadata. This approach provides flexibility for custom queries while handling the write volume from production applications.
Built-in dashboards transform raw data into actionable insight. Effective dashboards show current spending, compare it to budgets, highlight top consumers, and reveal trends over time. The best implementations allow drilling down from organization-level view to individual request details.
Setting Up Alerts and Budgets
Alert configuration prevents budget surprises. Teams should establish multiple alert levels—warning thresholds that indicate elevated spending and critical limits that trigger intervention.
Budget allocation works best hierarchically. Organization-wide budgets set overall limits. Department or project budgets provide granular control. Per-user or per-application caps prevent runaway costs from isolated issues.
Alert channels matter. Email notifications work for non-urgent warnings. Slack or Teams integrations enable team awareness. PagerDuty or similar systems handle critical budget breaches requiring immediate response.
Optimizing Costs Through Monitoring Insights
Cost monitoring generates data. Optimization turns that data into savings.
Prompt engineering emerges as a primary optimization lever. Monitoring reveals which prompts consume excessive tokens. Shorter, more focused prompts reduce input costs. Constraining output length prevents verbose responses that waste budget.
Model selection optimization uses cost data to match workloads with appropriate models. Simple tasks don’t need the most powerful (expensive) models. Monitoring identifies opportunities to route requests to cheaper alternatives without sacrificing quality.
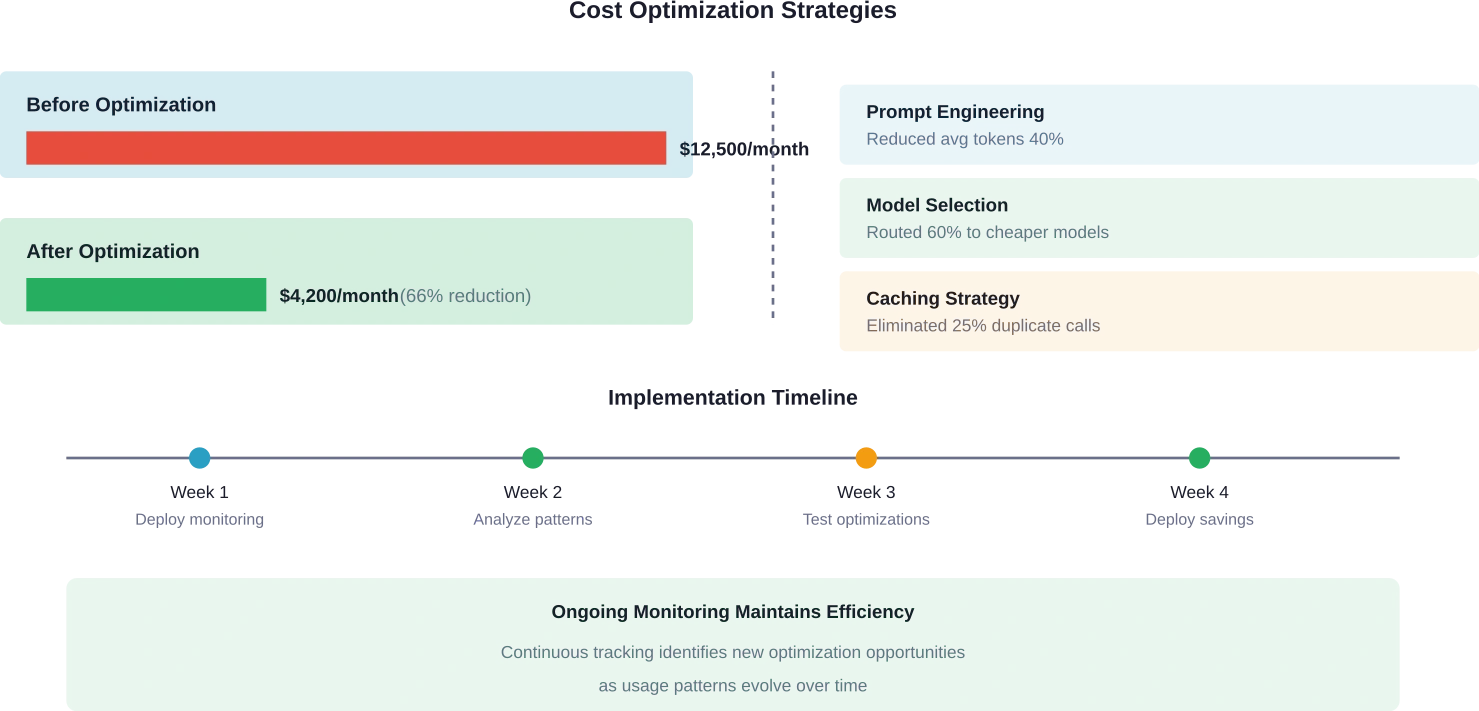
Caching strategies eliminate duplicate processing. If multiple users ask similar questions, caching the first response avoids regenerating identical content. Monitoring identifies high-frequency queries that benefit most from caching.
Request batching combines multiple operations when possible. Some workflows make numerous small API calls that could be consolidated. Monitoring usage patterns reveals batching opportunities that reduce both costs and latency.
Governance and Usage Controls
Cost monitoring enables governance beyond simple tracking. Organizations need controls to enforce policies and prevent unauthorized spending.
Role-based access control determines who can use which models. Development teams might access expensive models for testing while production applications use cost-optimized alternatives. Monitoring tracks compliance with these policies.
Rate limiting prevents abuse or misconfiguration from causing budget disasters. Per-user or per-application rate limits cap maximum token consumption over specified time windows. These controls protect against runaway loops or unexpected usage spikes.
Approval workflows add friction for expensive operations. Research applications exploring new use cases might require explicit approval before accessing premium models. Monitoring provides the usage data needed to evaluate these requests.
Compliance and Audit Requirements
Many industries face regulatory requirements around AI usage. Financial institutions need to demonstrate responsible AI deployment. Healthcare organizations must comply with data privacy regulations.
Cost monitoring generates audit trails showing which users accessed which models with what data. This documentation supports compliance efforts while also enabling forensic analysis when issues arise.
Data retention policies determine how long usage records persist. Longer retention supports trend analysis but increases storage costs. Organizations balance these concerns based on their specific compliance requirements.
Integration With Contact Center Analytics
Contact centers represent high-volume LLM deployment scenarios. According to research on LLM-based insight extraction for contact center analytics, organizations deploy language models for self-service tools, administrative automation, and agent productivity enhancement.
These deployments generate massive token consumption. Monitoring becomes critical for cost-effective operation. The research describes systems that automatically extract insights from customer interactions while managing deployment costs.
Zero-shot baselines using models like GPT-3.5-turbo provide starting points for contact center applications. Fine-tuned models offer better accuracy but require additional infrastructure and maintenance. Cost monitoring helps evaluate these trade-offs by tracking the financial impact of each approach.
The research emphasizes end-to-end topic modeling experiments that determine optimal scaling factors. These experiments rely on comprehensive cost tracking to balance accuracy improvements against increased spending.
Financial Industry Integration Considerations
Financial institutions face unique challenges integrating LLMs. Research on strategic frameworks for financial LLM integration highlights how organizations adopt language models for credit assessments, client advisory services, and language-intensive process automation.
Effective implementation requires responsible innovation that balances capability with risk management. Cost monitoring supports this balance by providing visibility into usage patterns and spending trends.
Financial organizations typically enforce stricter governance than other industries. Monitoring tools must support detailed audit trails, role-based access controls, and compliance reporting. Integration with existing risk management systems becomes essential.
The research notes that financial institutions of all sizes increasingly deploy LLMs. Smaller organizations need cost-effective monitoring solutions. Larger institutions require enterprise-grade governance and scale.
Choosing the Right Monitoring Solution
Selecting a monitoring tool depends on specific organizational needs. Several factors guide this decision.
Multi-provider support matters when using multiple LLM vendors. Organizations standardizing on a single provider might prioritize deeper integration over broad compatibility.
Deployment flexibility affects both costs and control. Cloud-hosted solutions minimize operational overhead. Self-hosted options provide greater customization and data sovereignty.
Integration capabilities determine how monitoring data flows into existing systems. API access enables custom dashboards. Webhooks support event-driven automation. Pre-built connectors simplify integration with popular tools.
| Feature | Startup Need | Enterprise Need |
|---|---|---|
| Cost Tracking | Basic token counting | Multi-dimensional analysis |
| Governance | Simple budgets | Complex approval workflows |
| Integration | Standalone dashboard | Enterprise tool connectivity |
| Support | Community forums | Dedicated assistance |
| Deployment | Cloud-hosted preferred | On-premise option required |
Scalability requirements vary by organization size and growth trajectory. Tools that work fine for dozens of requests per day might struggle with thousands per minute. Understanding expected volume prevents outgrowing monitoring infrastructure.
Budget for the monitoring solution itself creates a meta-challenge. Spending excessive amounts on monitoring defeats the purpose. Cost-effective solutions should represent a minimal portion of overall AI spending.
Future Trends in LLM Cost Management
Cost monitoring continues evolving alongside the broader LLM ecosystem. Several trends are reshaping how organizations approach spending management.
- Predictive cost modeling uses historical data to forecast future spending. Machine learning algorithms identify patterns and project costs under different scenarios. This capability enables proactive budgeting rather than reactive adjustment.
- Automated optimization takes monitoring insights and implements improvements without manual intervention. Systems automatically route requests to cost-optimal models, adjust caching parameters, and compress prompts while maintaining quality.
- Cross-provider cost arbitrage monitors pricing across multiple vendors and routes requests to the most cost-effective option for each workload. This approach requires real-time cost data and sophisticated routing logic.
- Carbon footprint tracking extends monitoring beyond financial costs to environmental impact. As organizations face sustainability pressures, understanding the energy consumption associated with AI workloads becomes increasingly important.
Frequently Asked Questions
How much does LLM cost monitoring typically reduce spending?
Organizations implementing comprehensive monitoring and optimization can significantly reduce LLM costs. The exact savings depend on how optimized the initial deployment was. Teams with no prior monitoring often see the largest reductions. Gains come primarily from prompt engineering, model selection optimization, and eliminating wasteful duplicate calls.
Can monitoring tools work across different LLM providers?
Yes, several monitoring solutions support multi-provider environments. Tools like LiteLLM create a unified interface across OpenAI, Anthropic, Google, and other vendors. These solutions standardize API calls while tracking costs centrally. Single-provider monitoring typically offers more detailed metrics but creates blind spots when using multiple vendors.
What’s the difference between cost monitoring and LLM observability?
Cost monitoring focuses specifically on tracking token usage and spending. LLM observability encompasses a broader set of metrics including quality, latency, error rates, and user satisfaction alongside costs. Observability platforms provide holistic visibility into LLM application health. Cost monitoring is a critical component of observability but not the complete picture.
How do on-premise deployments handle cost monitoring differently?
On-premise deployments track infrastructure costs instead of per-token charges. Monitoring focuses on GPU utilization, power consumption, and throughput. The goal shifts from minimizing token usage to maximizing hardware efficiency. Teams need to calculate internal cost per token based on infrastructure expenses to compare with commercial alternatives.
Should every organization implement real-time monitoring or is batch analysis sufficient?
Real-time monitoring becomes essential at scale or when budgets are tight. Organizations processing thousands of requests daily need immediate visibility to prevent runaway costs. Smaller deployments with predictable usage can rely on batch analysis of daily or weekly spending. The complexity and overhead of real-time systems only makes sense when the risk of budget overruns justifies the investment.
How does caching impact cost monitoring accuracy?
Caching reduces actual LLM API calls but monitoring must track both cached and uncached requests. Effective monitoring distinguishes cache hits from misses to calculate true cost savings. Without this distinction, teams might overestimate actual spending. Cache hit rates become an important optimization metric alongside token consumption.
What role does monitoring play in LLM governance?
Monitoring provides the data foundation for governance policies. Usage tracking enables budget enforcement, rate limiting, and access controls. Audit trails from monitoring systems demonstrate compliance with internal policies and external regulations. Governance policies without monitoring data become unenforceable guidelines rather than actual controls.
Taking Control of LLM Spending
Cost monitoring transforms LLM deployments from unpredictable expense centers into manageable, optimized systems. The visibility it provides enables informed decisions about model selection, prompt engineering, and infrastructure choices.
Organizations moving AI workloads to production can’t afford to skip this step. The tools and techniques exist today to track spending, prevent overruns, and continuously optimize costs. Implementation effort pays for itself through reduced spending within weeks.
Start with basic token tracking if comprehensive monitoring seems overwhelming. Even simple visibility into which applications and users consume the most tokens reveals optimization opportunities. Build toward real-time monitoring, automated alerts, and governance controls as deployments scale.
The competitive advantage goes to teams that deploy AI effectively while managing costs responsibly. Monitoring provides both capabilities—enabling aggressive deployment without reckless spending. Organizations that master cost monitoring can explore new LLM applications confidently, knowing they maintain financial control.