Quick Summary: The fastest LLM inference APIs in 2026 come from providers like Groq, SiliconFlow, and Hugging Face, with latency under 2 seconds and throughput exceeding 100 tokens/second. Pricing varies dramatically—from DeepSeek’s $0.28 per million input tokens to OpenAI’s GPT-5.2 Pro at $21.00. Cost-effective inference requires balancing speed, pricing, and model capability for your specific workload.
Speed matters when deploying large language models at scale. But the fastest inference API isn’t always the cheapest—and the cheapest isn’t always fast enough.
In early 2026, the LLM inference market has fragmented into distinct tiers. Premium providers like OpenAI command top-dollar pricing for cutting-edge models. Meanwhile, aggressive newcomers like DeepSeek undercut established players by 90% or more.
This guide breaks down the real numbers. Pricing per million tokens, actual latency measurements, throughput benchmarks, and the hidden costs that pricing pages don’t advertise.
Understanding LLM Inference Speed Metrics
Before comparing providers, it’s worth understanding what “fast” actually means in the context of LLM APIs.
Three metrics matter most:
- Latency measures time-to-first-token—how quickly the model starts responding after receiving your request. According to Hugging Face’s inference provider metrics, top-performing models achieve latency under 1.5 seconds. Groq is routinely cited as extremely fast in third-party benchmarking and by Groq’s own benchmark writeups (tokens/sec).
- Throughput tracks tokens generated per second once the model starts responding. Hugging Face data shows leading providers hitting 127 tokens/second or higher for models like Qwen3.5-35B-A3B.
- Context window determines how much text the model can process in a single request. Modern models support 128K to 262K tokens, though longer contexts can increase both latency and cost.
- Here’s the thing though—speed varies dramatically based on workload characteristics. Short queries with brief responses complete faster than long-context reasoning tasks. Batch processing trades immediate response time for better throughput and lower costs.
Fastest LLM Inference Providers by Latency
When raw speed is the priority, a handful of providers consistently outperform the competition.
Groq: Purpose-Built for Speed
Groq operates custom Language Processing Unit (LPU) hardware designed specifically for LLM inference. Community discussions and Groq’s own benchmarks position it as “extremely fast” for inference speed, with tokens-per-second measurements that consistently lead the market.
The company released new benchmarks for Llama 3.3 70B showing industry-leading inference performance. For applications where sub-second response time matters—chatbots, real-time assistants, interactive tools—Groq’s architecture delivers measurable advantages.
Pricing isn’t publicly listed for all models, so developers need to check Groq’s official documentation for current rates.
SiliconFlow: Speed Meets Affordability
SiliconFlow delivered up to 2.3× faster inference speeds and 32% lower latency compared to leading AI cloud platforms in recent benchmark tests, while maintaining consistent accuracy. The platform offers both serverless pay-per-use and reserved GPU options.
This combination of speed and cost control makes SiliconFlow compelling for production deployments where both metrics matter. The platform supports multiple open-source models with transparent pricing and flexible infrastructure options.
Hugging Face Inference Providers
Hugging Face aggregates multiple inference providers through a unified API, tracking performance across various model-provider combinations. The interface allows developers to automatically route requests to the fastest or cheapest provider for each model. Because the router supports OpenAI-compatible calls, migration is straightforward for those using existing integrations.

Build LLM Applications Optimized for Fast Inference
Fast LLM responses depend on the right architecture, model setup, and infrastructure. AI Superior develops AI software and NLP systems that integrate large language models into real applications such as chatbots, automation tools, and data analysis platforms. Their team designs model pipelines, backend services, and deployment environments so LLM features run reliably inside production systems.
Building a Product That Uses LLM APIs?
Talk with AI Superior to:
- design and build LLM-powered applications
- develop NLP systems and AI software
- deploy language models within existing platforms
👉 Request an AI consultation with AI Superior to discuss your project.
LLM Inference Pricing: 2026 Market Snapshot
Pricing structures vary wildly across providers. Some charge premium rates for proprietary models. Others compete aggressively on open-source model pricing.
Here’s where the market stands as of early 2026:
Premium Tier: OpenAI and Anthropic
OpenAI launched GPT-5.2 Pro in February 2026 at $21.00 per million input tokens and $168.00 per million output tokens. The standard GPT-5.2 model costs $8.00 input / $32.00 output per million tokens.
Anthropic’s Claude models occupy similar premium pricing territory. These providers justify higher costs with state-of-the-art capabilities, reliability, and extensive safety testing.
Mid-Tier: Google Gemini and Others
Google’s Gemini models offer competitive pricing for high-capability models. The broader mid-tier includes providers like Mistral AI, which balances performance with more accessible pricing than premium providers.
Budget Tier: DeepSeek Disruption
DeepSeek has aggressively undercut competitors with its V3.2-Exp “thinking” models listed at only $0.28 per million input tokens (cache-miss) and $0.42 per million output tokens. This represents a 90%+ discount compared to premium providers.
xAI’s Grok lineup similarly targets cost-conscious developers. Grok 4 Fast and Grok 4.1 Fast both price at $0.20 input / $0.50 output per million tokens.
| Provider | Model Example | Input ($/M tokens) | Output ($/M tokens) | Performance Tier |
|---|---|---|---|---|
| OpenAI | GPT-5.2 Pro | $21.00 | $168.00 | Premium |
| OpenAI | GPT-5.2 | $8.00 | $32.00 | Premium |
| xAI | Grok 4 | $3.00 | $15.00 | Mid-tier |
| xAI | Grok 4 Fast | $0.20 | $0.50 | Budget |
| DeepSeek | V3.2-Exp | $0.28 | $0.42 | Budget |
| Novita (HF) | Qwen3.5-35B-A3B | $0.25 | $2.00 | Budget |
Hidden Costs Beyond Token Pricing
Sticker price per million tokens tells only part of the cost story.
Several hidden factors significantly impact actual spending:
Context Caching and Reuse
Some providers offer discounted rates for cached context that’s reused across requests. DeepSeek’s $0.28 rate applies to cache-miss requests; cache-hit pricing is lower. If your application repeatedly processes similar contexts, caching can cut costs substantially.
Batch vs. Real-Time Pricing
OpenAI and Google offer batch processing APIs with discounted pricing—sometimes 50% off real-time rates. According to Hugging Face community discussions, there’s no direct equivalent of OpenAI’s Batch API with special discounted pricing on Hugging Face serverless endpoints.
Batch inference works for non-time-sensitive workloads: data processing, content generation, analysis tasks. The tradeoff is delayed completion in exchange for lower costs.
Output Token Economics
Output tokens typically cost 4-8× more than input tokens. A model that generates verbose responses burns through budget faster than one that responds concisely.
For cost optimization, constraining maximum output length prevents runaway token usage. Setting limits too low can truncate responses before delivering complete answers, so the configuration requires balancing completeness against cost control.
Infrastructure and Scaling Costs
Serverless APIs charge per token with no infrastructure overhead. Reserved capacity models—like SiliconFlow’s reserved GPU options—require upfront commitments but offer better per-token economics at scale.
Research on heterogeneous GPU deployment shows cost-efficiency varies significantly based on workload characteristics. According to analysis of LLM serving over heterogeneous GPUs, matching request types to appropriate hardware improves resource utilization and reduces effective costs.
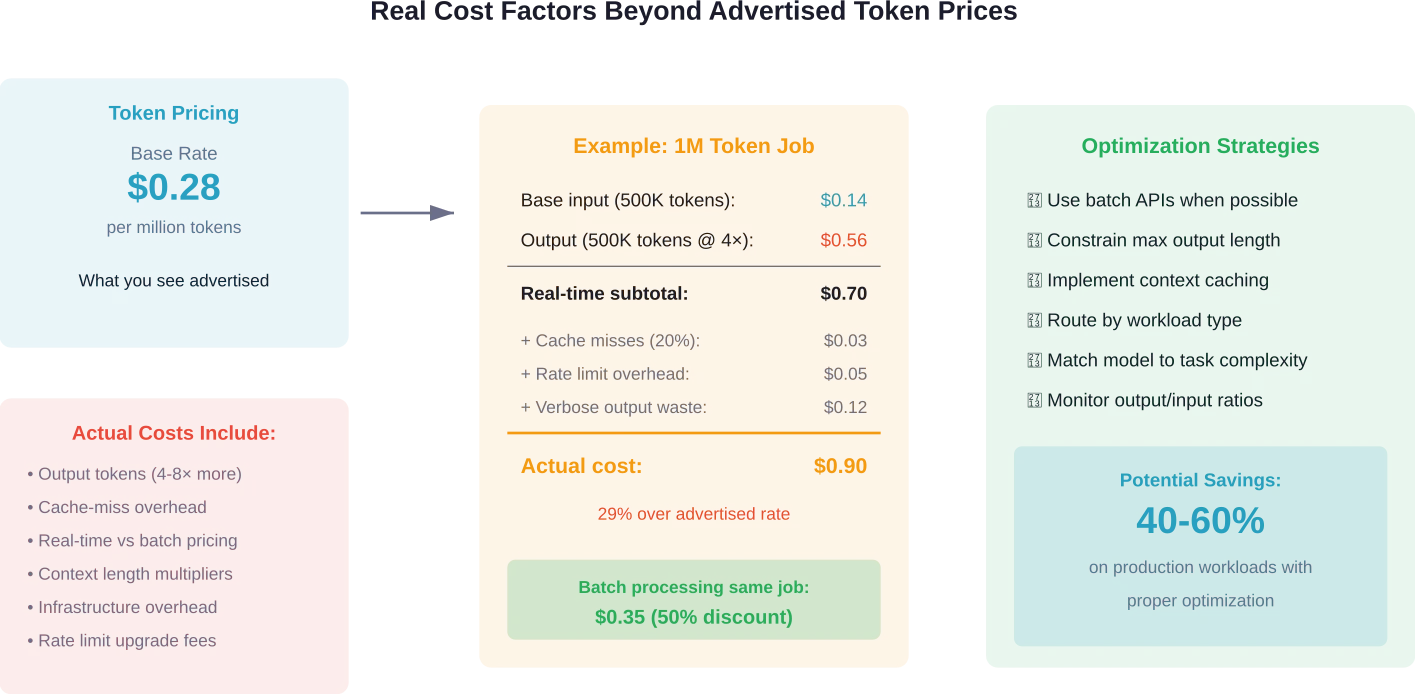
Speed-to-Cost Ratio: Finding the Sweet Spot
The optimal provider depends entirely on workload requirements.
For latency-critical applications—customer-facing chatbots, real-time coding assistants, interactive demos—speed justifies premium pricing. A 2-second response delay drives users away regardless of cost savings.
For high-volume batch processing—content classification, data extraction, analysis pipelines—cost per million tokens dominates the equation. DeepSeek’s $0.28 pricing at acceptable (if not leading) performance makes economic sense.
Research on LLM shepherding suggests hybrid approaches can optimize both metrics. Using smaller, faster models for initial processing and routing complex queries to larger models reduces average costs while maintaining quality. According to the study, even small hints from larger models (10-30% of full response) substantially improve smaller model accuracy.
Model Size Considerations
Model size directly impacts both speed and cost.
According to Hugging Face guidance on choosing open source LLMs, a 7-8B parameter model requires 14-16 GB VRAM at FP16 precision, or 6-8 GB with 4-bit quantization. Cloud options include AWS g5.xlarge instances.
Smaller 1-3B parameter models run on 4-6 GB VRAM (2 GB quantized) and handle basic tasks—text classification, autocomplete, simple chat—on modest hardware like RTX 3060 or laptop GPUs.
Larger models deliver better reasoning but require more compute resources. Deploying a LLaMA-2-70B model requires at least 2 NVIDIA A100 GPUs (each with 80 GB VRAM) for FP16 inference, according to efficiency survey research.
Top Cost-Effective Providers for Fast Inference
Based on performance metrics and pricing data, several providers offer compelling speed-to-cost ratios:
SiliconFlow
SiliconFlow combines competitive speed (2.3× faster than some leading platforms) with flexible pricing. The platform supports both serverless and reserved capacity, allowing cost optimization based on usage patterns.
The service provides an all-in-one AI cloud with industry-leading price-to-performance ratios, targeting both developers and enterprises.
Hugging Face Inference Providers
Hugging Face’s unified router aggregates multiple providers, allowing automatic routing to the fastest or cheapest option for each model. According to their metrics:
- Novita offers Qwen3.5 models at $0.25-$0.60 input with latency under 1.1 seconds
- Together AI provides comparable models with slightly higher latency but similar pricing
- Multiple providers compete for each popular model, driving efficiency
The router supports OpenAI-compatible API calls, simplifying migration from other providers. Developers can specify routing preferences—”:fastest”, “:cheapest”—to optimize for different objectives.
Mistral AI
Mistral AI delivers strong performance at mid-tier pricing. The company focuses on efficient model architectures that reduce inference costs without sacrificing capability.
Mistral models achieve competitive quality benchmarks while maintaining reasonable per-token costs, making them attractive for production deployments balancing multiple constraints.
DeepSeek
For workloads where cost dominates decision-making, DeepSeek’s aggressive pricing ($0.28 input / $0.40 output) represents the current market floor for capable models.
Performance lags behind premium providers but remains acceptable for many applications. The cost savings—up to 90% compared to top-tier models—enables use cases that couldn’t justify premium pricing.
Fireworks AI
Fireworks AI specializes in optimized inference for open-source models. The platform focuses on production-grade reliability with predictable pricing and performance.
The service provides infrastructure specifically tuned for LLM serving, with features designed for developers building applications rather than experimenting with models.
Performance Benchmarking Considerations
Published benchmarks don’t always reflect real-world performance.
Several factors create gaps between advertised metrics and production experience:
Load conditions affect latency. Providers under heavy load slow down. Time-of-day, geographic region, and current demand all influence actual response times.
Request characteristics matter significantly. Short prompts with brief outputs complete faster than long-context reasoning tasks. According to research on LLM inference energy-performance tradeoffs, inference exhibits substantial variability across queries and execution phases.
Cold start latency may affect the first request in serverless architectures.
Rate limits constrain throughput. Even fast APIs throttle requests beyond certain volumes, requiring higher-tier subscriptions or reserved capacity for high-volume applications.
Infrastructure Deployment Options
Beyond managed APIs, infrastructure choices significantly impact cost and performance.
Serverless APIs
Serverless options like those from Hugging Face, OpenAI, and others charge per token with no infrastructure management. This model works well for variable workloads, prototyping, and applications with unpredictable demand.
The tradeoff is higher per-token costs compared to dedicated infrastructure at scale.
Reserved Capacity
Reserved GPU instances or dedicated endpoints provide guaranteed resources at lower per-token rates. Providers like SiliconFlow offer this option alongside serverless pricing.
Reserved capacity makes economic sense once usage reaches consistent thresholds where the commitment cost drops below equivalent serverless spending.
Self-Hosted Inference
Running inference on owned or rented infrastructure provides maximum control and potentially lowest costs at very high volumes.
Research on deploying LLMs on edge devices highlights constraints: a 7-8B parameter model requires significant memory and compute resources. Mobile SoC characterization studies show that even with heterogeneous processing units, memory bandwidth limits throughput, with some configurations achieving only 40-45 GB/s per unit before requiring multiple processors to saturate available bandwidth.
Self-hosting requires expertise in model deployment, optimization, monitoring, and scaling—overhead that serverless APIs eliminate.
Choosing the Right Provider for Your Workload
Decision criteria should prioritize workload characteristics over abstract comparisons.
Ask these questions:
- What’s the usage pattern? Steady high-volume workloads favor reserved capacity or self-hosting. Variable, unpredictable demand suits serverless APIs.
- How latency-sensitive is the application? Real-time user interactions require sub-second response times. Background processing tolerates multi-second latency for cost savings.
- What model capability is actually needed? Many applications over-provision model capability. Smaller, faster models handle straightforward tasks at lower cost.
- Can batch processing work? Non-urgent workloads benefit from 50% batch discounts when providers offer them.
- What’s the output-to-input ratio? Applications generating long responses pay heavily for output tokens. Constraining verbosity reduces costs significantly.
- Does the workload benefit from context caching? Repeated processing of similar contexts with caching support cuts costs per request.
Frequently Asked Questions
What is the cheapest LLM inference API in 2026?
DeepSeek offers the lowest pricing at $0.28 per million input tokens and $0.40 per million output tokens for their V3.2-Exp models as of early 2026. xAI’s Grok 4 Fast at $0.20 input / $0.50 output is comparably priced. However, total cost depends on output verbosity, caching efficiency, and whether batch processing is available. The “cheapest” option varies based on these workload-specific factors.
Which provider has the fastest LLM inference speed?
Groq consistently ranks as the fastest inference provider, using purpose-built LPU hardware optimized for LLM workloads. Third-party benchmarks and community discussions cite Groq as delivering industry-leading tokens-per-second performance. According to Hugging Face metrics, other fast options include Novita (hosting Qwen models with 0.66-1.09 second latency) and SiliconFlow (2.3× faster than some leading platforms). Actual speed depends on model size, context length, and current load conditions.
How much does it cost to run 1 billion tokens through an LLM API?
Cost for 1 billion tokens varies dramatically by provider and input/output mix. At DeepSeek’s rates ($0.28 input / $0.40 output), 1B tokens costs $280 for input-only or $400 for output-only. At OpenAI’s GPT-5.2 Pro rates ($21 input / $168 output), the same volume costs $21,000 input or $168,000 output. A typical workload with 60% input and 40% output would cost roughly $328 on DeepSeek versus $79,800 on GPT-5.2 Pro—a 240× difference.
Do batch processing APIs actually save money?
Yes, when available. OpenAI and Google offer batch APIs with approximately 50% discounts compared to real-time processing. The tradeoff is delayed completion—batch jobs may take hours rather than seconds. According to Hugging Face community discussions, many Hugging Face serverless endpoints don’t offer batch-specific discounted pricing, though dedicated inference endpoints may. Batch processing makes sense for data processing, content generation, and analysis tasks where immediate results aren’t required.
Should I use serverless or reserved GPU capacity?
It depends on usage patterns and volume. Serverless APIs work well for variable demand, prototyping, and low-to-moderate volumes where convenience outweighs per-token costs. Reserved capacity becomes cost-effective when consistent usage reaches the break-even point where commitment costs drop below equivalent serverless spending. SiliconFlow offers both options, allowing optimization based on usage patterns. Calculate your actual sustained token volume and compare against reservation pricing to determine the break-even threshold.
How does model size affect inference speed and cost?
Larger models require more compute resources, increasing both latency and infrastructure costs. According to Hugging Face documentation, a 1-3B model needs just 2-4 GB VRAM and delivers fast inference on modest hardware, suitable for basic tasks. A 7-8B model requires 6-16 GB VRAM depending on quantization and handles more complex workloads. A 70B model demands 140+ GB VRAM (multiple high-end GPUs) and processes requests more slowly. Smaller models optimize speed and cost; larger models improve capability and reasoning quality. Match model size to actual task requirements rather than defaulting to the largest available model.
Can I reduce costs by optimizing prompt length?
Absolutely. Shorter prompts consume fewer input tokens, directly reducing costs. More importantly, constraining maximum output length prevents expensive verbose responses. Since output tokens cost 4-8× more than input tokens, a model generating unnecessarily long responses burns budget rapidly. According to best practices, set max_tokens parameters appropriate to your use case—setting too low truncates responses, while too high allows wasteful verbosity. Monitor actual output lengths and adjust limits accordingly. Context caching for repeated prompt elements further reduces costs when supported by the provider.
Conclusion: Balancing Speed and Cost
The fastest LLM inference API isn’t the best choice for every workload—and the cheapest API isn’t always the most cost-effective when quality and speed matter.
In 2026, the market offers genuine choice. Premium providers like OpenAI deliver cutting-edge capabilities at premium pricing. Aggressive challengers like DeepSeek undercut incumbents by 90% or more. Specialized infrastructure providers like Groq and SiliconFlow optimize for speed or cost-efficiency.
The optimal provider depends entirely on your specific requirements: latency sensitivity, output quality needs, usage volume, output verbosity, caching opportunities, and whether batch processing works for your use case.
Start by understanding your workload characteristics. Measure actual token volumes, input/output ratios, and latency requirements. Then map those requirements to providers that optimize for your specific constraints.
Don’t assume the most expensive option delivers the best results—or that the cheapest option sacrifices too much quality. Test multiple providers with representative workloads before committing to large-scale deployment.
The LLM inference market remains highly competitive in 2026, with pricing and performance improving rapidly. Monitor new entrants and benchmark regularly to ensure you’re getting optimal value as the landscape evolves.
Ready to optimize your LLM inference costs? Benchmark your specific workload across providers using the pricing data and performance metrics in this guide to identify the best speed-to-cost ratio for your application.