Quick Summary: LLM cost optimization strategies help organizations reduce operational expenses while maintaining AI performance. Key approaches include prompt optimization, model routing, caching, quantization, and infrastructure tuning. Research shows these techniques can reduce costs by 10-50% through methods like prompt compression, strategic model selection, and efficient token management.
The operational costs of running large language models in production can spiral quickly. What starts as a promising proof-of-concept becomes a financial burden when scaled to millions of API calls monthly.
Organizations deploying LLMs face a harsh reality: processing costs that grow linearly with usage. For a model with approximately 175 billion parameters, the required memory space would be approximately 350 GB (for FP16) or 700 GB (for FP32). That’s just storage—the actual inference costs pile up with every token processed.
But here’s the thing—cost optimization doesn’t mean sacrificing performance. Strategic approaches can dramatically reduce expenses while maintaining, or even improving, output quality.
Understanding LLM Pricing Models
Most cloud-based LLM services charge per token. Users pay separately for input tokens (the prompt) and output tokens (the generated response). This pay-per-token mechanism creates interesting dynamics.
Research from the MIT-IBM Watson AI Lab (in “A Hitchhiker’s Guide to Scaling Law Estimation”, 2024/2025) shows that ~4% average relative error (ARE) represents approximately the best achievable prediction accuracy when estimating scaling laws (i.e., forecasting large-model loss from smaller models in the same family), largely due to random seed noise—which alone can cause up to ~4% differences in final loss even for identical training configs. Up to 20% ARE remains useful for many practical decision-making tasks in model selection and budget allocation. These considerations matter when evaluating cost-performance tradeoffs across model families or sizes.
Cached input tokens typically cost around 10 percent of normal input tokens. That pricing asymmetry creates opportunities for significant savings through strategic caching approaches.
The pricing structure also means output generation costs more than input processing for most providers. This fundamental truth drives several optimization strategies that shift token consumption from expensive outputs to cheaper inputs.
Prompt Optimization Techniques
Prompt engineering represents the lowest-hanging fruit for cost reduction. Poorly structured prompts waste tokens and generate unnecessary output.
Compress Without Losing Context
Verbose prompts burn through input tokens. A product description request might originally state: “Generate a compelling product description for a smartphone. It should mention the key features and specifications, such as the screen size, camera resolution, battery life, and storage capacity. Try to make it engaging and persuasive.”
The optimized version: “Generate a compelling product description for a smartphone with a 6.5-inch display, 48MP camera, 5000mAh battery, and 256GB storage.”
Same intent, fewer tokens, more specific guidance. This approach reduces input costs while often improving output quality through precision.
Structure Outputs Strategically
Structured outputs minimize token waste. Instead of asking for free-form responses that require parsing, request JSON or specific formats. This technique appears in production systems where E-Agent frameworks employ structured outputs to minimize candidate answer length.
According to OpenAI’s reinforcement fine-tuning documentation, clear task specifications with verifiable answers enable more efficient model behavior. Explicit rubrics and code-based graders measure functional success while reducing unnecessary verbosity.
| Prompt Type | Token Usage | Cost Impact | Best For
|
|---|---|---|---|
| Verbose, unstructured | High | Baseline | Exploration phase |
| Compressed, structured | Medium | 20-30% reduction | Production deployments |
| Cached with structure | Low | 40-50% reduction | Repetitive tasks |
Strategic Model Selection and Routing
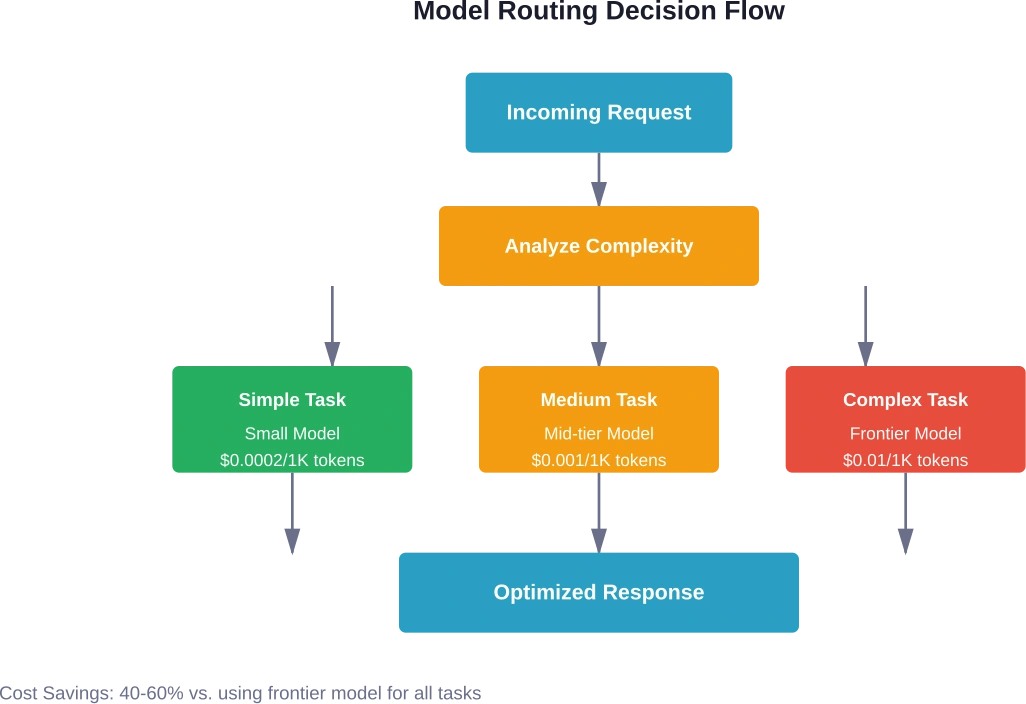
Not every task requires the most powerful model available. Model routing—directing different requests to appropriately-sized models—delivers substantial savings.
Match Model Capability to Task Complexity
Simple classification tasks don’t need frontier models. Sentiment analysis, basic summarization, or category tagging work fine with smaller, cheaper alternatives. Reserve expensive models for complex reasoning, nuanced generation, or specialized knowledge tasks.
Research on model efficiency shows that redesigned architectures can attain comparable performance at different scales. The model’s architecture plays a critical role beyond just parameter count.
Production systems report mixing OpenAI, Anthropic, and local model deployments based on task requirements across 2M+ monthly API calls. This heterogeneous approach optimizes cost-performance ratios across different use cases.
Implement Intelligent Routing Logic
Automated routing systems analyze incoming requests and select appropriate models. AI Enabler platforms provide automated optimization of both LLM selection and underlying infrastructure, removing manual decision overhead.
The routing logic considers factors like query complexity, required accuracy, latency tolerance, and current pricing. Dynamic routing adapts to changing conditions without manual intervention.
Caching Strategies for Repetitive Workloads
Caching delivers immediate, dramatic cost reductions for applications with repetitive patterns. Production systems report 40 percent cache hit rates, with some deployments saving approximately $3,000 monthly in API costs.
Implement Semantic Caching
Basic caching stores exact prompt matches. Semantic caching goes further—it recognizes similar queries even with different wording. “How do I reset my password?” and “What’s the process for password recovery?” trigger the same cached response.
This approach particularly benefits customer support, documentation search, and FAQ systems where users phrase identical questions differently.
Cache System Prompts and Context
System prompts that define model behavior rarely change. Caching these reduces redundant processing. Context that appears in multiple requests—like company information, product catalogs, or style guides—should be cached aggressively.
Context engineering approaches show subagents might explore extensively, using tens of thousands of tokens, but return condensed summaries of 1,000-2,000 tokens. Caching these intermediate results prevents redundant deep dives into the same information.
Early Stopping and Output Control
Models often generate more content than necessary. Early stopping techniques detect when sufficient information has been produced and halt generation.
Research on ES-CoT (Early Stopping Chain-of-Thought) demonstrates methods to detect answer convergence and stop generation early. When consecutive identical step answers indicate convergence, generation terminates, reducing inference token costs while maintaining comparable accuracy.
The technique works by prompting the model to output its current answer at each reasoning step. Run length of consecutive identical answers serves as a convergence measure. Sharp increases in run length that exceed minimum thresholds trigger termination.
Set Maximum Token Limits
Explicitly limit output length through API parameters. This prevents runaway generation that wastes tokens on unnecessary elaboration. Different tasks need different limits—adjust based on use case.
Classification needs 10 tokens. Summarization might need 200. Long-form generation could justify 1,000+. But defaults that allow unlimited output invite waste.
Quantization and Model Compression
Quantization reduces the precision of model weights, decreasing memory requirements and computational costs. LLMs commonly use FP16 precision to reduce memory requirements compared to FP32. Further quantization to INT8 or INT4 provides additional savings.
Post-Training Quantization
Post-training sparsity reduces model cost by removing weights from dense networks. Research on sparsity induction demonstrates post-training sparsity approaches on models tested with single NVIDIA RTX A6000 GPUs (48 GB).
Native dense matrices lack high sparsity, making direct weight removal disruptive. Advanced approaches induce sparsity patterns that preserve model capabilities while reducing computational requirements.
Distillation for Specialized Tasks
Knowledge distillation creates smaller models that mimic larger ones for specific tasks. The student model learns from the teacher’s outputs, capturing task-relevant behavior in fewer parameters.
Autodistill frameworks enable designing specialized models with substantially lower inference costs through knowledge distillation approaches.
| Technique | Complexity | Cost Reduction | Quality Impact
|
|---|---|---|---|
| Prompt optimization | Low | 20-30% | Often improves |
| Model routing | Medium | 40-60% | Minimal |
| Caching | Low | 30-50% | None |
| Early stopping | Medium | 30-40% | Minimal |
| Quantization | High | 50-70% | 5-10% degradation |
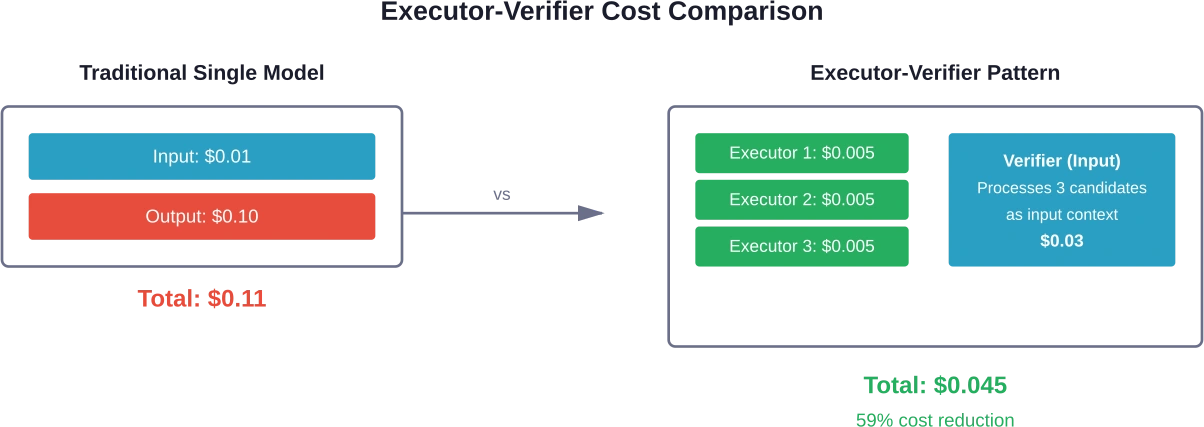
Executor-Verifier Architectures
The executor-verifier paradigm shifts token consumption from expensive outputs to cheaper inputs. Multiple small, locally-deployed models generate candidate answers. A powerful cloud-based model verifies which candidate is correct.
E-Agent frameworks demonstrate this approach reduces token usage by 10-50 percent compared to baseline methods. The pricing asymmetry between input and output tokens makes verification cheaper than generation.
Small executors run locally or on inexpensive infrastructure. They generate multiple diverse candidates in parallel. The verifier processes all candidates as input context—charged at lower input token rates—and selects or synthesizes the best answer.
This architecture particularly suits tasks with clear correctness criteria: mathematical problems, code generation, factual questions, or structured data extraction.
Infrastructure and Deployment Optimization
Beyond model-level optimizations, infrastructure choices significantly impact costs.
Optimize Hardware Selection
GPU selection matters. NVIDIA TensorRT-LLM provides Python APIs to define LLMs with state-of-the-art optimizations for efficient inference on NVIDIA GPUs. Testing shows dramatic performance improvements on appropriate hardware.
Experiments using single NVIDIA RTX A6000 GPUs with 48 GB memory demonstrate viable inference for models requiring careful resource management. Right-sizing hardware prevents over-provisioning while maintaining acceptable latency.
Batch Processing When Possible
Real-time requirements sometimes create artificial constraints. Batch processing multiple requests together improves throughput and reduces per-request costs. Tasks like content moderation, classification, or analysis often tolerate slight delays that enable batching.
Consider Self-Hosting for Scale
At sufficient volume, self-hosting becomes economical. Cloud API pricing includes substantial margins. Organizations processing millions of requests monthly should evaluate dedicated infrastructure.
The breakeven point depends on technical capabilities, maintenance overhead, and usage patterns. Potential savings at scale may justify serious analysis.
Iterative Refinement Systems
Parallel-Distill-Refine (PDR) systems generate diverse drafts in parallel, distill them into bounded workspaces, and refine conditioned on that workspace. This approach often provides better performance than long chain-of-thought while maintaining lower latency and context size.
Sequential Refinement iteratively improves a single candidate answer without persistent workspace. Testing on mathematical tasks shows iterative pipelines surpass single-pass baselines at matched sequential budgets. Shallow PDR delivers the largest gains—approximately 10 percent improvement on challenging problem sets.
These methods view models as improvement operators with continua strategies. Generate four shorter answers and combine their strengths in a single superior answer. This often outperforms single long-form generation while using fewer total tokens.
Continuous Monitoring and Optimization
Cost optimization isn’t one-and-done. Continuous monitoring identifies new opportunities and catches regressions.
Track Key Metrics
Monitor tokens per request, cost per transaction, cache hit rates, and model selection distribution. Establish baselines and alert on anomalies. Usage patterns shift—optimization strategies should adapt.
Implement Feedback Loops
Self-evolving agent frameworks implement retraining loops that capture issues and improve performance. Optimization should continue until quality thresholds are reached—typically targeting >80% of outputs receiving positive feedback—or until diminishing returns appear where new iterations show minimal improvement.
Evaluation-driven system design uses evals as the core process for creating production-grade autonomous systems. Structured evaluation with clear metrics enables systematic improvement without guesswork.
Regular Model Evaluation
New models launch constantly with improved price-performance ratios. Quarterly evaluations ensure deployments leverage the latest options. Yesterday’s frontier model becomes tomorrow’s mid-tier alternative.
Test new releases against existing benchmarks. Switching models requires minimal code changes but can deliver substantial savings or capability improvements.
Common Pitfalls to Avoid
Several mistakes undermine optimization efforts:
- Over-optimizing for cost alone: Quality matters. A 50 percent cost reduction means nothing if output quality drops enough to require human intervention. Always measure accuracy alongside cost metrics.
- Ignoring latency implications: Some optimization techniques trade latency for cost. Batching and model routing add processing time. Ensure performance remains acceptable for use cases.
- Static optimization strategies: What works today may not work tomorrow. Model pricing changes, new capabilities emerge, and usage patterns evolve. Static strategies gradually lose effectiveness.
- Premature optimization: Start with basic techniques like prompt optimization and caching. Complex approaches like custom model distillation require substantial investment. Ensure volume justifies the effort.
Real-World Cost Savings Examples
Production deployments demonstrate meaningful savings from these strategies.
Systems processing 2M+ monthly API calls across multiple applications report 40 percent cache hit rates saving approximately $3,000 monthly. This represents a straightforward implementation with immediate ROI.
E-Agent frameworks reducing token usage by 10-50 percent maintain or improve accuracy on knowledge-intensive tasks. Testing on knowledge-intensive and reasoning tasks demonstrates the executor-verifier approach effectiveness.
Early stopping methods reduce inference tokens by approximately 41 percent on average across five reasoning datasets and three LLMs while maintaining comparable accuracy.
These represent reported results from production systems handling real workloads.

Stop Burning Money on LLMs with AI Superior
Many teams adopt large language models and only later realize how quickly infrastructure costs can spiral. Token usage grows, models run longer than expected, and systems that worked in testing start becoming expensive in production.
AI Superior helps businesses design and optimize LLM systems so they stay efficient at scale. Their teams work on custom model development, fine-tuning, and AI workflow optimization, often reducing unnecessary compute usage and improving how models are deployed inside real business processes.
If your LLM costs keep rising, contact AI Superior to audit your setup and fix the inefficiencies before your next cloud bill hits.
Frequently Asked Questions
What’s the fastest way to reduce LLM costs?
Prompt optimization and caching deliver immediate results with minimal implementation complexity. Start by compressing verbose prompts, requesting structured outputs, and implementing basic caching for repeated queries. These changes can reduce costs 20-40 percent within days.
How much can model routing save?
Model routing typically saves 40-60 percent compared to using frontier models for all tasks. The exact savings depend on task distribution—environments with many simple classification or extraction tasks see higher savings than those requiring primarily complex reasoning.
Does quantization significantly hurt model quality?
Modern quantization techniques maintain quality remarkably well. INT8 quantization typically causes 1-3 percent accuracy degradation while reducing memory requirements approximately 50 percent. INT4 quantization shows 5-10 percent degradation but enables running much larger models on limited hardware.
When should organizations consider self-hosting?
Self-hosting becomes economical around 10-50 million monthly tokens, depending on technical capabilities and cloud API pricing. Organizations with ML engineering expertise and consistent usage patterns hit breakeven sooner. Calculate total cost of ownership including infrastructure, maintenance, and opportunity costs.
How often should cost optimization strategies be reviewed?
Quarterly reviews catch major shifts in pricing, model capabilities, and usage patterns. Monthly monitoring of key metrics identifies anomalies requiring immediate attention. Major changes to application functionality warrant immediate optimization reassessment.
Can smaller companies afford advanced optimization techniques?
Absolutely. Basic techniques like prompt optimization, caching, and model selection require minimal technical investment. Advanced approaches like custom distillation or self-hosting make sense at higher volumes, but initial savings come from low-complexity changes any organization can implement.
What’s the relationship between cost optimization and latency?
Some techniques improve both—early stopping reduces cost and latency simultaneously. Others create tradeoffs—model routing adds slight routing overhead, batching delays individual requests. Design optimization strategies considering latency requirements for specific use cases.
Moving Forward with Cost Optimization
LLM cost optimization represents an ongoing process, not a destination. Start with high-impact, low-complexity techniques. Measure results rigorously. Iterate based on data.
The organizations succeeding with production LLM deployments treat cost optimization as a core competency. They monitor continuously, experiment systematically, and adapt strategies as conditions change.
Research continues advancing optimization techniques. Staying current with developments ensures deployments benefit from the latest innovations. New methods for compression, routing, and efficient inference emerge regularly.
But the fundamentals remain constant: understand pricing models, match resources to requirements, eliminate waste, and measure everything. These principles deliver sustainable cost structures that scale with business growth.
Start implementing one or two strategies this week. Measure the impact. Build from there. The cumulative effect of multiple optimizations compounds—a 20 percent improvement here, 30 percent there, suddenly overall costs drop 60 percent while quality improves.
That’s not theoretical. That’s what production systems achieve when organizations approach cost optimization systematically.