Quick Summary: NLP (Natural Language Processing) uses rule-based and statistical methods for specific language tasks at lower cost, while LLMs (Large Language Models) are neural networks trained on massive datasets that excel at generative tasks but cost significantly more. Combining both approaches—using NLP for classification and routing, LLMs for complex reasoning—can reduce inference costs by 40-90% while maintaining quality.
Everyone loves big models until the bill arrives. What looks like cents per request during testing turns into thousands per month in production.
The reality? Most AI workloads don’t need GPT-level reasoning for every single query. But without proper cost architecture, every request hits the most expensive model anyway.
Here’s the thing though—NLP and LLMs aren’t competing technologies. They’re complementary tools that, when combined strategically, deliver both performance and cost efficiency. Understanding when to use each approach isn’t just about saving money. It’s about building sustainable AI systems that scale.
Understanding the Cost Difference Between NLP and LLMs
Traditional Natural Language Processing and Large Language Models operate on fundamentally different economics. The distinction matters because it directly impacts production budgets.
NLP systems typically involve upfront development costs—building rule sets, training smaller specialized models, creating classification pipelines. Once deployed, inference costs remain minimal. Processing text through regex patterns, named entity recognition, or small classification models requires negligible compute.
LLMs flip this model entirely. Development costs are lower because foundation models come pre-trained. But inference costs become the dominant expense. Every token processed—both input and output—carries a price tag.
The Token Economics Reality
Token-based pricing means costs scale linearly with usage. According to data from Hugging Face Inference Providers, current market rates for competitive models range significantly:
| Model | Provider | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|---|
| GPT-5 Mini | OpenAI | $0.25 | $2.00 | ~400k |
| Qwen3.5-35B-A3B | Novita | $0.25 | $2.00 | 262,144 |
| Qwen3.5-27B | Novita | $0.30 | $2.40 | 262,144 |
| Qwen3.5-397B-A17B | Together | $0.60 | $3.60 | 262,144 |
Output tokens consistently cost 8-10x more than input tokens. This asymmetry punishes verbose responses. A chatbot that generates 500-word answers burns through the budget exponentially faster than one optimized for concise outputs.
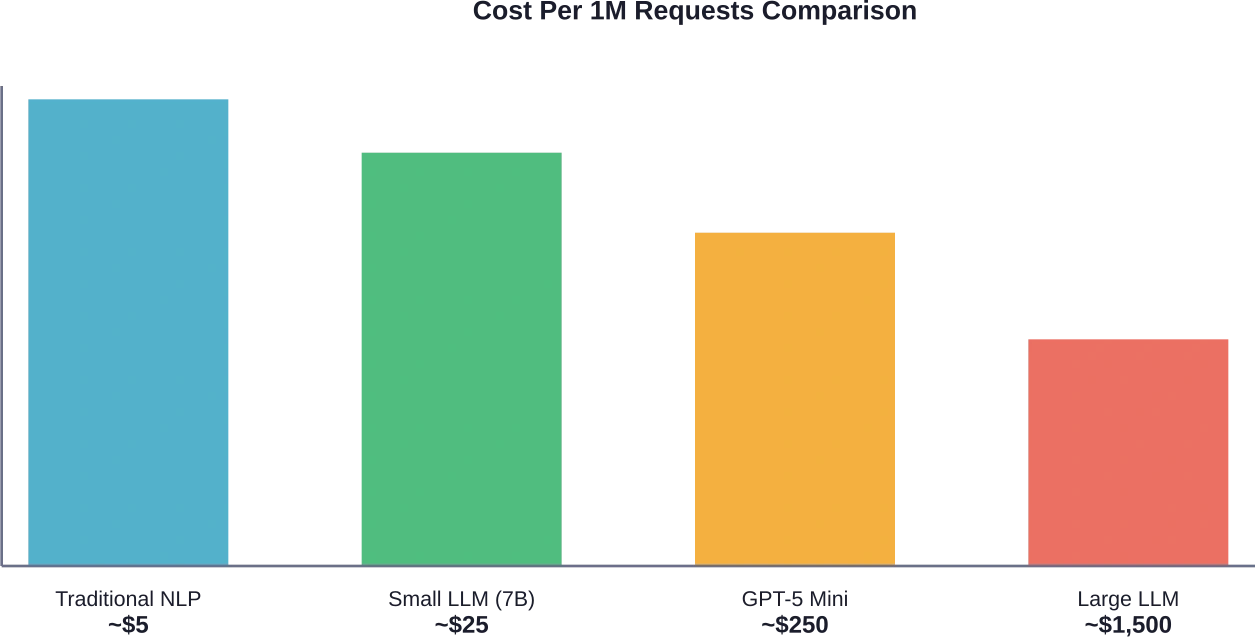
Real talk: that $0.25 per million input tokens sounds cheap until production volume hits. Process 100 million tokens monthly—easily achievable for a mid-sized application—and that’s $25,000 just for inputs. Add outputs and the actual spend multiplies.
Infrastructure Costs Beyond API Calls
Cloud GPU pricing adds another layer. According to analysis from Hugging Face on cloud compute economics, infrastructure costs dominate when self-hosting models.
The capital investment for GPU capacity represents the primary barrier. Physical infrastructure matters less than the upfront hardware expense. For organizations running their own inference, this shifts the cost model from pay-per-token to fixed capacity planning.
But wait. Cloud instances still charge hourly. Based on model size and hardware deployment patterns documented in industry sources, practical constraints emerge around:
| Model Size | VRAM (FP16) | VRAM (4-bit) | Cloud Instance Type | Typical Use Cases |
|---|---|---|---|---|
| 1-3B | 4-6 GB | ~2 GB | AWS g4dn.xlarge | Basic chat, classification, autocomplete |
| 7-8B | 14-16 GB | ~6-8 GB | AWS g5.xlarge | General-purpose inference |
Traditional NLP components run comfortably on CPU instances. No specialized hardware required. The cost differential becomes stark at scale.
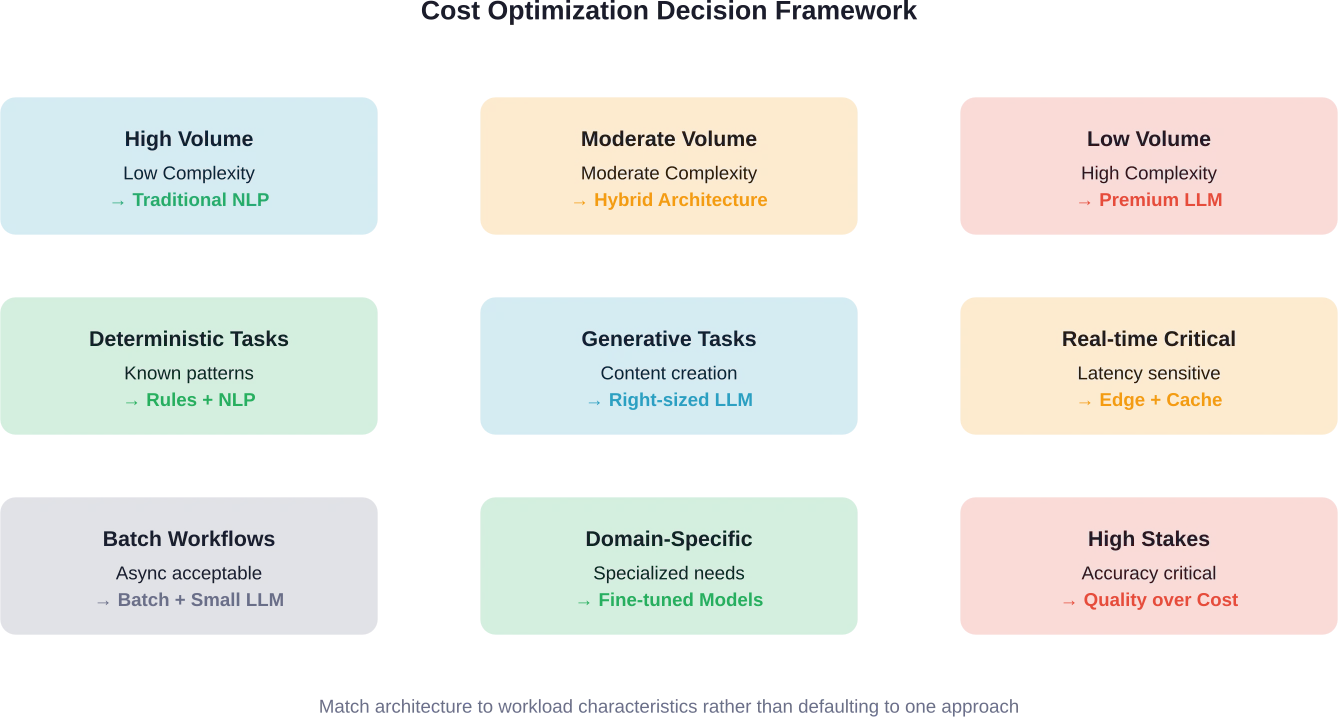
Where Traditional NLP Delivers Cost Advantages
Certain language processing tasks don’t benefit from LLM capabilities. For these workloads, traditional NLP methods deliver equivalent or superior results at a fraction of the cost.
Classification and Routing Tasks
Intent classification, sentiment analysis, topic categorization—these are solved problems. Small specialized models trained for specific classification tasks achieve 95%+ accuracy while processing thousands of requests per second on minimal hardware.
A BERT-based classifier fine-tuned for customer support routing might use 110 million parameters. Compare that to GPT-5 Mini’s billions of parameters. The classification model runs inference in single-digit milliseconds on CPU. An LLM call takes hundreds of milliseconds and costs several orders of magnitude more per request.
Community discussions highlight practical examples. According to a case study from Lumitech, when they analyzed their LLM usage, they found 80% of queries were straightforward. Every request hit their most expensive model unnecessarily.
By implementing an NLP classification layer first, they routed simple tasks to lightweight models and reserved LLMs for complex reasoning. The result: 10× cost reduction – from $200 to $20 per month—with zero quality degradation.
Pattern Matching and Entity Extraction
Regex patterns and rule-based extraction systems cost essentially nothing to operate. When requirements are well-defined, rules perform perfectly.
Email validation, phone number formatting, date parsing, address normalization—these don’t need neural networks. Rule-based systems execute in microseconds without API calls or model inference.
Named entity recognition follows similar economics. SpaCy’s statistical models extract entities with high accuracy across multiple languages. Once loaded in memory, processing is near-instantaneous. No per-request costs. No token counting.
Domain-Specific Language Tasks
Specialized NLP models trained for narrow domains often outperform general-purpose LLMs while costing less.
Medical text processing benefits from BioBERT or similar domain-adapted models. Legal document analysis works better with legal-specific NLP pipelines. Financial sentiment analysis achieves higher accuracy with FinBERT than with generic LLMs.
These models range from 100M to 400M parameters. Self-hosting becomes economically viable. Training costs are one-time expenses. Inference costs approach zero at scale.
When LLM Costs Make Sense
LLMs justify their price tags for specific use cases. The key is matching capability to requirement.
Generative and Creative Tasks
Content generation, creative writing, code synthesis, summarization—these are LLM territory. Traditional NLP can’t generate coherent long-form content. Rule-based systems can’t write marketing copy that sounds human.
For generative workloads, LLM costs become unavoidable. The question shifts from whether to use LLMs to which model tier offers the best value.
OpenAI reports GPT-5 Mini achieves 91.1% on the AIME math contest and 87.8% on an internal “intelligence” measure. Performance rivals much larger models. At $0.25 per million input tokens, it delivers frontier capabilities at accessible pricing.
Complex Reasoning and Multi-Step Problems
Chain-of-thought reasoning, multi-hop question answering, mathematical problem solving—smaller models struggle here. Larger LLMs with billions of parameters show emergent reasoning abilities that justify higher costs.
But this is where it gets interesting. Not every complex task requires the largest model. Research on optimizing LLM usage shows methods that reduce costs by 40-90% while improving quality by 4-7%.
The methodology involves extensive evaluation across different model tiers. Results consistently demonstrate that task-appropriate model selection maintains quality while controlling expenses.
Low-Volume High-Value Workflows
When request volume is low and decision value is high, LLM costs become negligible compared to business impact.
A legal research tool processing 100 queries daily benefits from LLM capabilities. Even at premium pricing, monthly costs might total $50-200. The value of accurate legal analysis far exceeds that expense.
Compare this to a chatbot handling 100,000 daily interactions. Same model, different volume, entirely different cost profile. High-volume scenarios demand optimization. Low-volume workflows can afford premium models.
The Hybrid Architecture Approach
The most cost-effective production systems combine NLP and LLMs strategically. This isn’t an either-or decision.
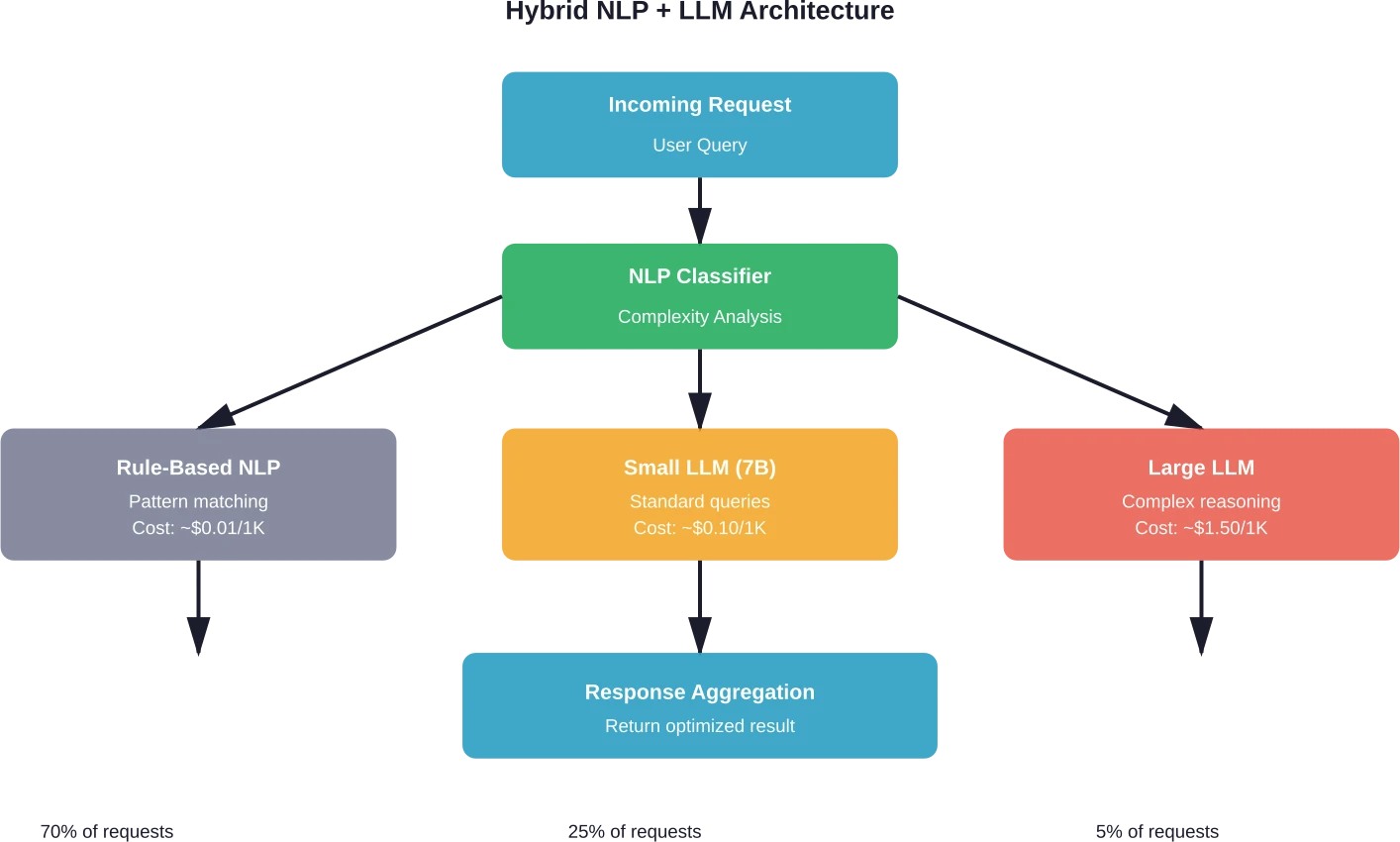
Intelligent Request Routing
Classification layers determine complexity before routing requests to appropriate models. Simple tasks hit fast, cheap models. Complex reasoning gets routed to capable LLMs.
Implementation requires several components. First, a lightweight classifier analyzes incoming requests. This might be a fine-tuned BERT model or even simpler heuristics based on query length, keywords, and structure.
The classifier categorizes requests into tiers: simple factual queries, straightforward tasks, moderate complexity, high complexity reasoning. Each tier maps to a different processing path.
Teams implementing intelligent routing report 30-50% cost reductions without measurable quality degradation when routing strategies align models to task requirements effectively. The key is systematic evaluation that validates routing logic and maintains quality standards across model tiers.
Caching and Response Optimization
Semantic caching prevents redundant LLM calls. When users ask similar questions, cached responses serve immediately without inference costs.
Traditional caching matches exact queries. Semantic caching uses embeddings to identify similar questions with different wording. A vector similarity search determines if cached responses satisfy new queries.
Embedding models are cheap to run. Even with the additional embedding step, serving cached responses reduces costs dramatically compared to full LLM inference.
Response optimization focuses on reducing output tokens. Prompt engineering that encourages concise answers directly cuts costs. Since output tokens cost 8-10x input tokens, verbose responses disproportionately inflate bills.
Progressive Enhancement
Start with the smallest viable model. Escalate to larger models only when necessary.
A multi-agent system might first attempt tasks with a 7B parameter model. If confidence scores fall below threshold, the system automatically retries with a more capable model. Most requests succeed on the first attempt. Only difficult cases incur higher costs.
This approach requires confidence calibration. Models must accurately estimate their own uncertainty. Well-calibrated models know when they’re likely to fail and can request escalation automatically.
Real-World Cost Optimization Strategies
Production systems employ multiple tactics simultaneously. No single optimization solves the cost problem. The combination delivers results.
Prompt Engineering for Efficiency
Prompt length directly impacts costs. Every token in the prompt gets processed and charged.
Excessive context, verbose instructions, redundant examples—these inflate input token counts unnecessarily. Streamlined prompts that convey requirements concisely reduce costs without sacrificing quality.
Few-shot examples demonstrate desired behavior but consume tokens. Testing different example counts identifies optimal trade-offs. Sometimes three examples achieve the same accuracy as ten while using 70% fewer tokens.
Model Right-Sizing
Bigger isn’t always better. Task-appropriate model selection balances capability and cost.
Benchmark suites like MMLU, HumanEval, and domain-specific evaluations reveal which models perform adequately for specific tasks. A model that scores 85% might cost one-tenth of a model that scores 90%. The 5-point accuracy difference might not justify 10x cost for certain applications.
Extensive benchmarking and analysis indicate smaller models often approach the capabilities of much larger models for narrow tasks. DeepSeek V3.2-Exp matches and somewhat outperforms its predecessor V3.1 on public benchmarks while offering better cost efficiency through architectural improvements.
Batch Processing and Async Workflows
Real-time inference costs more than batch processing. When immediacy isn’t required, batching requests reduces expenses.
Document summarization, content moderation, data extraction—these workloads often tolerate latency. Processing in batches allows for better resource utilization and negotiated volume pricing with providers.
Async workflows decouple request submission from result delivery. Users submit tasks, continue other work, and receive results when processing completes. This flexibility enables cost optimization that real-time constraints prevent.
Comparing Current Market Pricing
Provider pricing varies significantly. Shopping around matters.
Based on data from early 2026, competitive pricing clusters around several tiers. Entry-level models like GPT-5 Mini and Qwen3.5-35B-A3B start at $0.25 per million input tokens and $2.00 per million output tokens.
Mid-tier models range from $0.30 to $0.60 input pricing. Premium large models exceed $0.60 for inputs.
Context window sizes affect value calculations. Models offering 256K-400K context windows enable different architectural patterns than those limited to 32K-128K windows. Larger context reduces the need for multiple requests when processing long documents.
| Capability Tier | Typical Input Price | Typical Output Price | Best For |
|---|---|---|---|
| Entry (7-8B) | $0.10-0.25 / 1M | $0.80-2.00 / 1M | Classification, simple chat, basic summarization |
| Mid (30-40B) | $0.25-0.60 / 1M | $2.00-3.60 / 1M | General-purpose tasks, moderate reasoning |
| Premium (100B+) | $0.60-2.00 / 1M | $3.60-10.00 / 1M | Complex reasoning, specialized domains |
Latency and throughput vary independently of price. Cheaper models aren’t necessarily slower. Provider infrastructure and optimization affect performance as much as model size.
Hidden Costs to Consider
API pricing isn’t the only cost factor. Development time, debugging complexity, and maintenance overhead all contribute to total cost of ownership.
Traditional NLP requires more upfront development. Building classification pipelines, tuning models, maintaining rule sets—these tasks demand skilled engineering time.
LLMs reduce development friction. Prompt engineering replaces model training. Iteration cycles shorten. For teams with limited ML expertise, LLM ease-of-use offsets higher inference costs.
But at scale, inference costs dominate. A system processing millions of daily requests will spend more on LLM tokens in a year than on initial NLP development. The calculus flips as volume increases.
Energy and Environmental Cost Considerations
Financial costs parallel energy consumption. Research from arxiv.org on energy costs of LLM inference benchmarks the relationship between compute and power draw.
Large model inference requires substantial energy. While exact figures depend on hardware and optimization, the trend is clear: bigger models consume more power per token.
Traditional NLP models process requests with minimal energy overhead. CPU-based inference draws far less power than GPU-accelerated LLM inference.
Organizations with sustainability commitments face dual pressures: financial optimization and carbon footprint reduction. Fortunately, these goals align. Strategies that reduce LLM costs typically reduce energy consumption simultaneously.
Efficient routing that directs simple queries to lightweight models cuts both expenses and emissions. Right-sizing models to match task requirements delivers environmental benefits alongside cost savings.
Building a Cost-Aware Architecture
Sustainable AI systems monitor and optimize costs continuously. One-time optimization isn’t sufficient. Usage patterns shift. Model pricing changes. Requirements evolve.
Cost Monitoring and Attribution
Tracking expenses by feature, user tier, or workflow reveals optimization opportunities. Aggregate metrics obscure which components drive spending.
Detailed logging captures request metadata: model used, token counts, latency, cost, and business context. This data enables analysis that identifies expensive patterns.
Some features might generate disproportionate costs relative to business value. Usage analysis might reveal 5% of users consume 60% of the LLM budget through inefficient interaction patterns. Targeted optimization or feature redesign addresses these outliers.
Testing and Evaluation Frameworks
Cost optimization requires measurement. Quality metrics validate that cheaper alternatives maintain acceptable performance.
Evaluation frameworks compare model outputs across different tiers. Human evaluation or automated quality scoring determines if smaller models achieve sufficient accuracy for specific tasks.
A/B testing in production measures user satisfaction across different model selections. If users can’t distinguish between responses from a 7B model and a 70B model for certain queries, the expensive model isn’t adding value.
Continuous Optimization Loops
Static architectures become suboptimal as models improve and pricing changes. Regular evaluation identifies better alternatives.
New models launch frequently. A model released next month might offer better performance per dollar than current selections. Continuous benchmarking against new releases ensures systems leverage the best available value.
Pricing adjustments occur without announcement. Monitoring rate changes from multiple providers enables opportunistic switching when competitors offer better economics.
Future Cost Trends
Pricing trajectory matters for long-term planning. Several factors influence future costs.
Model efficiency continues improving. Architectural innovations deliver better performance per parameter. Research from arxiv.org on efficiency of large language models documents algorithmic advances that reduce computational requirements.
Redesigned models attain equivalent capabilities with fewer parameters through architectural optimization. As these techniques mature, costs per unit of capability decrease.
Competition among providers exerts downward pricing pressure. As more players enter the market, rate compression accelerates. The introduction of GPT-5 Mini, Gemini 2.5 Flash, and Claude 3.5 Haiku created a new tier of capable models at significantly lower prices than previous generations.
Hardware improvements continue. New GPU architectures deliver better inference throughput. As hardware efficiency increases, providers can offer lower prices while maintaining margins.
But demand grows simultaneously. As more applications integrate LLMs, aggregate spending increases even if per-token costs decline. Organizations that don’t actively optimize find expenses growing despite falling unit prices.
Implementation Roadmap
Moving from expensive all-LLM architecture to cost-optimized hybrid systems requires planning.
Phase 1: Measurement and Analysis
Instrument existing systems to capture detailed usage metrics. Without data, optimization is guessing.
Log every LLM request with metadata: timestamp, user, feature, prompt tokens, completion tokens, model used, latency, cost. Aggregate this data for analysis.
Identify patterns. Which features generate the most requests? Which users consume the most tokens? What prompt patterns appear frequently?
Calculate cost per feature, per user segment, per business outcome. This reveals where optimization efforts yield highest returns.
Phase 2: Quick Wins
Low-hanging fruit delivers immediate savings while building momentum for larger initiatives.
Implement prompt optimization. Trim unnecessary context, remove verbose instructions, consolidate examples. This requires minimal development effort but immediately reduces token consumption.
Add semantic caching. Libraries exist for most languages that make implementation straightforward. Caching can eliminate 20-40% of requests with minimal code changes.
Right-size obvious cases. Tasks currently using premium models but achieving equivalent results with mid-tier models represent clear optimization opportunities.
Phase 3: Strategic Architecture
Larger initiatives require more planning but deliver substantial ongoing savings.
Build the classification and routing layer. This becomes infrastructure that other optimizations leverage. Start simple—classify requests into two or three tiers initially.
Deploy task-specific NLP models for high-volume deterministic workloads. These replace LLM calls entirely for specific use cases.
Implement progressive enhancement for complex queries. Try cheaper models first, escalate only when necessary.
Phase 4: Continuous Improvement
Optimization isn’t a project with an end date. It’s an ongoing practice.
Schedule quarterly reviews of model performance and pricing. New options emerge constantly. Regular evaluation ensures systems evolve as the landscape changes.
Monitor cost metrics alongside business metrics. Treat cost efficiency as a key performance indicator alongside quality, latency, and user satisfaction.
Experiment with new approaches. Set aside a budget for testing alternative architectures, new models, and different providers. The best optimization for next quarter might not exist yet.

Reduce Your AI Costs Before They Get Out of Control
Choosing between NLP systems and large language models can dramatically affect long term AI spending. AI Superior works with businesses that need AI systems designed for real world efficiency. Their team builds and fine tunes LLMs, develops task specific models, and optimizes AI driven workflows so companies can reduce compute usage while maintaining performance.
If you want to cut AI costs instead of just scaling them, speak with AI Superior and get practical guidance on building more efficient AI systems.
Common Pitfalls to Avoid
Cost optimization can backfire when done carelessly. Several mistakes appear repeatedly.
Premature Optimization
Early-stage projects benefit from rapid iteration enabled by LLMs. Spending weeks building custom NLP pipelines before validating product-market fit wastes resources.
Start with the simplest approach that works. Optimize when scale demands it, not before. Premature optimization distracts from core product development.
Optimizing Without Measurement
Assumptions about what drives costs often prove wrong. Detailed measurement reveals surprising patterns.
Teams sometimes optimize the wrong components. A feature that seems expensive might represent 3% of total costs. Meanwhile, an overlooked workflow quietly consumes 40% of budget.
Measure first. Optimize high-impact areas. Ignore minor contributors until major issues are addressed.
Sacrificing Quality for Cost
Aggressive cost cutting that degrades output quality proves counterproductive. Poor AI experiences damage user trust and undermine product value.
Maintain quality standards. Use evaluation frameworks to validate that cheaper alternatives meet requirements. When they don’t, the more expensive option is the correct choice.
Ignoring Development Velocity
Complex cost optimization architecture can slow development. Trading agility for marginal savings rarely makes sense for early-stage products.
Balance optimization effort against business value. A system processing 1,000 daily requests doesn’t need the same optimization rigor as one processing 1,000,000.
Frequently Asked Questions
How much can hybrid NLP + LLM architecture realistically save?
Research and community reports document cost reductions ranging from 40% to 90% depending on workload characteristics. Systems with high volumes of simple queries see the largest savings. Applications dominated by complex generative tasks see smaller but still significant reductions. The key factor is the percentage of requests that can be handled by cheaper NLP approaches versus those requiring full LLM capabilities.
Do smaller LLMs actually perform well enough for production use?
Modern small LLMs like GPT-5 Mini achieve surprisingly high performance on benchmarks. OpenAI reports 91.1% on AIME math problems and 87.8% on internal intelligence measures. For many production tasks, these models match or exceed the quality of previous-generation large models while costing 5-10x less. Task-specific evaluation is essential—performance varies by use case.
What’s the break-even point for building custom NLP models versus using LLMs?
Generally speaking, high-volume deterministic tasks justify custom NLP development. If a task receives thousands of requests daily and can be handled by classification or extraction, custom models pay for themselves within weeks. Low-volume or highly variable tasks favor LLMs despite higher per-request costs because development effort can’t be amortized across enough requests.
How do I determine which requests need expensive models versus cheap ones?
Start with a lightweight classifier that analyzes request characteristics: length, structure, keywords, domain. Based on these signals, route to appropriate model tiers. Initial classification accuracy doesn’t need to be perfect—build feedback loops that identify misrouted requests and refine classification over time. Many teams report that simple heuristics work surprisingly well as starting points.
What monitoring metrics should I track for LLM cost optimization?
Track token counts separately for input and output since pricing differs significantly. Monitor cost per request, cost per user, cost per feature, and cost per business outcome. Track model selection distribution to understand routing patterns. Measure cache hit rates if using semantic caching. Monitor quality metrics alongside cost to ensure optimization doesn’t degrade performance. Set up alerts when costs exceed expected patterns.
Is it better to use API services or self-host models for cost savings?
The answer depends on scale and technical capability. API services offer convenience and eliminate infrastructure management overhead. For moderate volumes, per-token pricing often proves more economical than maintaining GPU infrastructure. Self-hosting becomes cost-effective at very high volumes where per-request costs exceed amortized infrastructure expenses. Cloud compute analysis from Hugging Face indicates capital investment represents the primary barrier for self-hosting rather than operational complexity.
How often do LLM prices change and should I build for that?
Provider pricing changes occur periodically, sometimes without advance notice. Major releases often introduce new pricing tiers. Building abstraction layers that separate model selection from business logic allows switching providers or models without extensive refactoring. Multi-provider support enables opportunistic routing to whoever offers best economics for specific request types at any given time.
Conclusion
The choice between NLP and LLMs isn’t binary. The most cost-effective production AI systems combine both approaches strategically.
Traditional NLP excels at high-volume deterministic tasks. Rule-based systems and specialized models process simple requests at minimal cost. LLMs deliver capabilities that traditional methods can’t match but at significantly higher expense.
Smart architecture routes requests to appropriate processing tiers. Classification layers identify simple tasks that don’t need expensive models. Complex reasoning gets directed to capable LLMs. This hybrid approach reduces costs by 40-90% while maintaining quality.
Cost optimization requires continuous effort. Measurement reveals patterns. Evaluation validates alternatives. Regular reviews ensure systems evolve as models improve and pricing changes.
Start with measurement. Instrument your current system to understand spending patterns. Identify quick wins through prompt optimization and caching. Build strategic architecture for long-term efficiency. Treat cost management as ongoing practice rather than a one-time project.
The organizations that master this balance will build sustainable AI systems that scale economically. Those that default to expensive models for everything will face budget constraints that limit innovation.
Your move: assess your current costs, identify optimization opportunities, and implement systematic improvements. The tools and techniques exist. The question is whether you’ll use them.