Quick Summary: Open-source LLMs eliminate licensing fees but shift costs to infrastructure, talent, and maintenance. Minimal internal deployments run $125K–$190K annually, while enterprise-scale implementations can exceed $12M. The cost-effectiveness depends on usage volume, technical expertise, and customization needs—proprietary APIs often prove cheaper for low-to-moderate workloads.
The promise sounds compelling: download an open-source large language model, deploy it on your infrastructure, and avoid the recurring API costs of proprietary services. No more per-token billing. No vendor lock-in.
But here’s the thing—that “free” model comes with a price tag that catches most organizations off guard.
Open-source LLMs shift expenses from obvious line items like licensing fees to less visible but equally substantial costs: specialized engineering talent, GPU infrastructure, ongoing maintenance, and operational overhead. These hidden expenses can dwarf the cost of commercial API services, particularly at smaller scales.
The decision between open-source and proprietary LLMs isn’t about free versus paid. It’s about which cost structure aligns with your usage patterns, technical capabilities, and business requirements.
Why Open-Source LLMs Aren’t Actually Free
The term “open-source” creates a dangerous misconception. Yes, you can download model weights without licensing fees. But deploying those weights in production environments requires substantial resources.
Proprietary LLM services like OpenAI’s GPT-5.2, Google Gemini, or Anthropic’s Claude charge per token. As of early 2026, OpenAI’s GPT-5.2 Pro costs $21.00 per million input tokens ($168 output), while budget tiers like GPT-5.2 Mini start at $0.25 per million input tokens. According to verified pricing data, these rates reflect a range of tiers balancing performance and cost. DeepSeek’s V3.2-Exp “thinking” models are listed at $0.28 per million input tokens (cache-miss) and $0.42 per million output tokens, substantially cheaper than Western competitors.
Open-source models flip this equation. Instead of usage-based fees, you’re paying for:
- Hardware acquisition or cloud GPU rentals
- Engineering salaries for deployment and integration
- Infrastructure management and monitoring
- Security hardening and compliance work
- Model optimization and fine-tuning
- Ongoing maintenance and support
These costs remain relatively fixed regardless of usage volume, creating a fundamentally different economic model than pay-per-use APIs.
The Infrastructure Cost Reality
Running LLMs demands serious computational horsepower. Models with billions of parameters require GPUs with substantial VRAM, fast interconnects, and robust cooling systems.
Hardware Investment Requirements
A minimal production deployment typically needs at least one high-end GPU. NVIDIA’s A100 GPUs, commonly used for LLM inference, cost between $10,000 and $15,000 per unit. Larger models or higher throughput requirements multiply that number quickly.
But hardware acquisition represents just the starting point. Physical infrastructure requires rack space, power distribution, cooling systems, and network connectivity. Organizations without existing data center capacity face additional capital expenses for these supporting systems.
Cloud GPU Economics
Cloud GPU instances offer an alternative to hardware ownership, but pricing remains substantial. According to analysis from Hugging Face examining GPU cloud economics, capital costs dominate cloud pricing structures. For example, an NVIDIA Tesla V100 typically costs around $10,000 USD to purchase, while its average rental cost per hour ranges between $2 and $3—meaning hourly cloud rates compound quickly when running continuously.
And here’s what trips up initial cost projections: inference workloads require persistent availability. Unlike training jobs that run once, production deployments run continuously. That 24/7 operation turns hourly cloud costs into steep monthly bills.
The Human Capital Investment
Infrastructure represents just one cost dimension. The specialized talent required to deploy and maintain open-source LLMs often exceeds hardware expenses.
Required Engineering Roles
Production LLM deployments demand multiple specialized roles. MLOps engineers handle deployment pipelines, inference optimization, and scaling infrastructure. Software integration engineers build the connectors between models and existing systems—work that typically consumes roughly 60% of engineering effort in AI projects according to available data.
DevOps specialists manage Kubernetes clusters, container orchestration, and infrastructure monitoring. Security engineers implement access controls, audit logging, and compliance frameworks. Data engineers build pipelines for model fine-tuning and evaluation.
Each role commands substantial salaries in today’s competitive market for AI talent. Senior ML engineers often earn $150K–$250K annually, with total compensation packages reaching higher for top-tier talent.
Ongoing Support Requirements
But here’s what catches organizations off guard: deployment isn’t a one-time project. Production LLM systems require continuous attention.
Models need periodic updates as capabilities improve. Inference stacks like vLLM or NVIDIA Triton require maintenance and optimization. Integration points break when upstream systems change. Performance degrades without ongoing tuning.
This creates a perpetual staffing requirement. Organizations can’t deploy an open-source LLM and walk away—they’re committing to sustained engineering investment.
Real-World Cost Scenarios
Abstract cost categories matter less than concrete scenarios. What does it actually cost to run open-source LLMs at different scales?
Minimal Internal Deployment
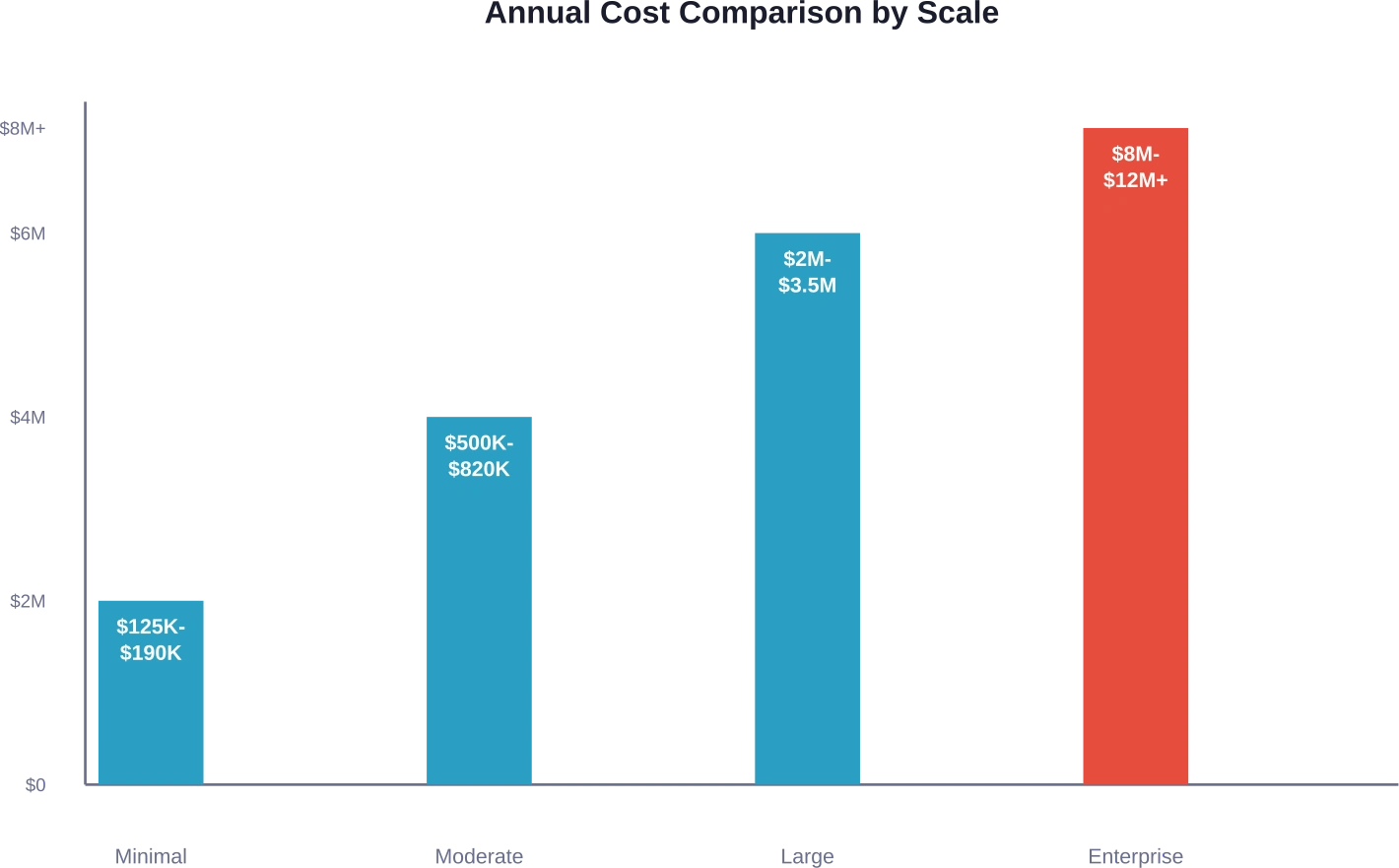
A basic internal chatbot or document analysis tool serving a small team represents the simplest deployment scenario. According to cost breakdowns from industry analysis, even minimal internal deployments run $125K–$190K annually.
This scenario assumes:
- Cloud GPU instances rather than hardware purchase
- Single GPU inference setup
- Part-time engineering support (not dedicated staff)
- Minimal customization beyond basic fine-tuning
- Low query volume (hundreds to low thousands daily)
The costs break down roughly as cloud infrastructure (40%), engineering time (45%), and monitoring/security tools (15%).
Moderate Customer-Facing Features
Customer-facing applications raise the stakes significantly. Higher availability requirements, increased query volumes, and production support demands push costs to $500K–$820K annually for moderate-scale deployments.
This scenario typically involves:
- Multi-GPU setup for redundancy and throughput
- Dedicated engineering team (2-3 full-time roles)
- Custom fine-tuning for domain specificity
- Comprehensive monitoring and alerting
- Security hardening and compliance work
Infrastructure costs rise, but engineering expenses dominate. Building reliable, production-grade systems requires sustained engineering effort far beyond initial deployment.
Enterprise-Scale Core Products
When LLM capabilities become central to product offerings, costs escalate dramatically. Enterprise-scale implementations serving thousands of concurrent users can exceed $8M–$12M annually.
These deployments demand:
- Multi-region GPU clusters for performance and redundancy
- Dedicated engineering teams (8-15+ engineers)
- Extensive model optimization and custom architectures
- Enterprise security and compliance frameworks
- 24/7 operational support
At this scale, engineering headcount becomes the dominant cost driver, easily surpassing infrastructure expenses.
| Deployment Scale | Annual Cost Range | Primary Cost Drivers | Typical Use Cases
|
|---|---|---|---|
| Minimal Internal | $125K–$190K | Cloud GPUs, part-time engineering | Internal chatbots, document analysis |
| Moderate Customer-Facing | $500K–$820K | Dedicated engineering team, multi-GPU | Customer support automation, content generation |
| Large Production | $2M–$3.5M | Large engineering teams, optimized infrastructure | Core product features, high-volume APIs |
| Enterprise Core Product | $8M–$12M+ | Extensive teams, multi-region clusters | Mission-critical AI products, platform offerings |
Proprietary LLM API Pricing in 2026
Comparing open-source costs requires understanding proprietary alternatives. API pricing has evolved significantly, with major providers adjusting rates and introducing new tiers.
Current Pricing Landscape
As of early 2026, proprietary LLM pricing spans a wide range. According to verified pricing data updated through February 2026:
- OpenAI’s GPT-5.2 Pro costs $21.00 per million input tokens and $168.00 per million output tokens, representing their premium flagship tier. Standard GPT-5.2 runs $1.75 and $14.00 respectively, while GPT-5.2 Mini offers budget-friendly rates at $0.25 and $2.00.
- Google’s Gemini pricing varies by model tier. Their latest offerings balance performance and cost across different use cases.
- Anthropic’s Claude models maintain competitive positioning in the mid-to-premium range, emphasizing context length and safety features.
- xAI has launched Grok 4 at $3/$15 per million tokens, Grok 4 Fast at $0.20/$0.50, and Grok 4.1 Fast at $0.20/$0.50 per million tokens.
- DeepSeek’s V3.2-Exp “thinking” models are listed at $0.28 per million input tokens (cache-miss) and $0.42 per million output tokens, substantially cheaper than Western competitors.
Usage-Based Cost Calculations
API costs scale linearly with usage. An application processing 100 million tokens monthly using GPT-5.2 Pro (at $21.00 per million input tokens) would incur approximately $25K annually for input tokens. The same workload on DeepSeek V3.2-Exp runs roughly $336 annually—a 74x difference.
This linear scaling creates clear break-even points. High-volume applications eventually justify open-source infrastructure investments. Low-to-moderate workloads almost always favor APIs.
The crossover point depends on specific pricing tiers and infrastructure costs, but generally falls somewhere between 50M–200M tokens monthly for most organizations.
Hidden Operational Costs
Beyond obvious infrastructure and salary expenses, open-source LLM deployments accumulate less visible operational costs that compound over time.
Monitoring and Observability
Production LLM systems require comprehensive monitoring. Latency tracking, throughput metrics, error rates, and resource utilization all need real-time visibility.
Commercial observability platforms charge based on data volume and retention periods. These costs scale with system complexity and traffic.
Custom monitoring solutions shift costs to engineering time—building dashboards, alerting systems, and diagnostic tools consumes substantial development resources.
Model Updates and Versioning
Open-source LLM ecosystems move quickly. New model versions release regularly, offering improved capabilities, better efficiency, or bug fixes.
Each update requires testing, validation, and deployment planning. Regression testing ensures new versions don’t break existing functionality. Performance benchmarking validates improvements. Rollback procedures prepare for failures.
Organizations can’t simply ignore updates—falling behind on critical security patches or performance improvements creates technical debt and competitive disadvantages.
Security and Compliance
LLM deployments handling sensitive data face stringent security requirements. Access controls, audit logging, data encryption, and network isolation all require implementation and maintenance.
Compliance frameworks like SOC 2, HIPAA, or GDPR impose additional requirements. Regular security audits, penetration testing, and vulnerability management add recurring costs.
Proprietary API providers typically handle compliance certifications and security infrastructure, offloading these burdens from customers. Open-source deployments assume full responsibility.
When Open-Source Makes Financial Sense
Despite substantial costs, open-source LLMs deliver compelling economics in specific scenarios.
High-Volume Production Workloads
The crossover point where open-source becomes cheaper than APIs depends on usage volume. Processing hundreds of millions or billions of tokens monthly creates massive API bills that justify infrastructure investment.
An application processing 500 million tokens monthly on mid-tier proprietary APIs might pay $200K–$400K annually. That same workload on self-hosted infrastructure could run for $300K–$500K total—but with relatively flat scaling beyond that point.
At billion-token scales, the economics shift decisively toward self-hosting.
Specialized Domain Requirements
Some applications require extensive fine-tuning on proprietary domain data. Medical diagnosis, legal document analysis, or specialized technical fields benefit from models trained on domain-specific corpora.
Proprietary API providers offer fine-tuning services, but costs escalate quickly for extensive customization. Open-source models allow unlimited fine-tuning without per-training-token charges.
Organizations with rare languages, specialized vocabularies, or unique formatting requirements may find open-source models more adaptable, though specific cost-benefit varies by use case.
Data Privacy and Sovereignty
Regulatory requirements sometimes prohibit sending sensitive data to external APIs. Healthcare records, financial information, or classified data may require on-premise processing.
Open-source LLMs enable complete data control. Information never leaves organizational infrastructure, simplifying compliance and reducing risk.
The value of this control depends on data sensitivity and regulatory context, but for some organizations it’s non-negotiable regardless of cost.
Long-Term Strategic Independence
Dependence on external API providers creates strategic risks. Providers can increase prices, discontinue models, or change terms of service. Service outages directly impact dependent applications.
Open-source deployments eliminate vendor dependency. Organizations control their own availability, pricing, and roadmap.
An arXiv research paper on cost-benefit analysis of on-premise LLM deployment defines performance parity as benchmark scores within 20% of top commercial models, reflecting enterprise norms where small accuracy gaps are offset by cost, security, and integration benefits.
Performance Considerations
Cost comparisons miss a critical dimension: performance differences between open-source and proprietary models.
Capability Gaps
Top-tier proprietary models generally outperform comparable open-source alternatives on challenging reasoning tasks, complex instructions, and specialized domains.
The gap varies significantly across task types. Simple classification, structured data extraction, or template-based generation show minimal differences. Complex reasoning, nuanced language understanding, or creative tasks favor cutting-edge proprietary models.
Organizations must evaluate whether capability differences matter for their specific use cases. Many applications succeed with mid-tier performance at lower cost.
Optimization Opportunities
Open-source deployments enable extensive optimization unavailable with API services. Quantization reduces model size and memory requirements while maintaining acceptable accuracy. Knowledge distillation transfers capabilities to smaller, faster models.
Research published on Hugging Face examining reasoning efficiency found that shorter reasoning chains can achieve similar or better performance with reduced computational cost. Specifically, basic short-1@k approaches demonstrated up to 40% fewer thinking tokens compared to standard approaches while maintaining output quality.
Custom inference stacks like vLLM or NVIDIA Triton offer performance tuning unavailable through standardized APIs. Batching strategies, caching mechanisms, and hardware-specific optimizations can dramatically improve throughput and latency.
Latency and Throughput
Self-hosted infrastructure enables geographic distribution closer to users, reducing network latency. Dedicated hardware eliminates queueing delays from shared API infrastructure.
But building high-performance inference systems requires significant expertise. Poorly optimized deployments often deliver worse latency than well-engineered API services.
Making the Cost Decision
Choosing between open-source and proprietary LLMs requires evaluating multiple dimensions beyond simple cost comparison.
Calculate Total Cost of Ownership
Accurate cost projections must include all expense categories:
- Infrastructure: GPU hardware or cloud rentals, networking, storage
- Personnel: Engineering salaries, recruiting costs, training
- Operations: Monitoring tools, security software, compliance audits
- Opportunity cost: Engineering time diverted from product development
- Risk premium: Downtime costs, performance issues, security incidents
Organizations consistently underestimate personnel and operational costs while overestimating infrastructure savings.
Evaluate Technical Capabilities
Successful open-source deployments require substantial technical expertise. Teams need skills in distributed systems, GPU programming, ML optimization, and production operations.
Organizations lacking this expertise face two options: build capabilities through hiring and training (expensive and slow) or hire external consultants (expensive and dependency-creating).
API services eliminate most technical requirements, enabling teams to focus on application logic rather than infrastructure.
Consider Hybrid Approaches
The decision isn’t binary. Many organizations successfully combine approaches.
LLM routing strategies dynamically select models based on request characteristics. Simple queries route to fast, cheap models while complex tasks use powerful alternatives. According to research from Hugging Face on batched instruction routing, this optimization balances performance and cost across mixed workloads.
Development and staging environments can use APIs while production runs self-hosted infrastructure. This reduces infrastructure costs during low-volume phases while enabling API-free production.
Task-specific specialization deploys open-source models for high-volume, standardized tasks while using proprietary APIs for complex, variable requests.
| Consideration | Favors Open-Source | Favors Proprietary APIs
|
|---|---|---|
| Usage Volume | Very high (500M+ tokens/month) | Low to moderate (<100M tokens/month) |
| Technical Expertise | Strong ML and infrastructure teams | Limited ML expertise, small teams |
| Customization Needs | Extensive fine-tuning required | Standard models sufficient |
| Data Privacy | Strict regulatory requirements | Standard commercial terms acceptable |
| Time to Market | Long-term strategic investment | Rapid deployment critical |
| Cost Predictability | Prefer fixed infrastructure costs | Variable costs acceptable |
Cost Optimization Strategies
Organizations committed to open-source LLMs can employ several strategies to control costs.
Right-Size Infrastructure
Many deployments over-provision hardware based on peak load rather than typical usage. Autoscaling infrastructure dynamically adjusts capacity based on demand, reducing idle resource costs.
Spot instances and preemptible VMs offer significant cloud discounts—sometimes 60-80% off standard pricing—in exchange for potential interruption. Batch workloads and development environments tolerate interruption well.
Model Selection and Optimization
Smaller models deliver surprising performance on specialized tasks after fine-tuning. Research on optimizing small language models for e-commerce tasks found that a properly fine-tuned 1-billion-parameter Llama 3.2 model achieved 99% accuracy, matching the performance of GPT-5.1 on specialized intent recognition.
Quantization reduces model precision from 16-bit to 8-bit or even 4-bit representations, cutting memory requirements and inference costs by 50-75% with minimal quality impact.
Model distillation trains smaller student models to mimic larger teacher models, achieving better efficiency-performance tradeoffs than training from scratch.
Efficient Inference Techniques
Batching requests processes multiple inputs simultaneously, dramatically improving GPU utilization. Continuous batching techniques enable dynamic batch assembly for real-time applications.
KV-cache optimization reduces redundant computation during autoregressive generation, particularly for long contexts or multi-turn conversations.
Request routing sends simple queries to small, fast models and complex queries to larger models, optimizing cost-performance across workload distributions.

Review Your Open Source LLM Costs With Technical Insight
Open source LLMs can look cheap because the base model is free, but the real expenses often appear in training, fine tuning, data prep, and deployment. Decisions about model size, architecture, and integration vastly impact compute use and ongoing operating costs. AI Superior focuses on the engineering work behind open source LLMs—creating models, optimizing training workflows, and setting up efficient deployment pipelines so you can understand and control where your budget is going. (aisuperior.com/services/llm-model-creation-services)
If you’re tracking hidden expenses in 2026 and want a clearer picture of where costs are coming from, start with the technical setup. Talk to AI Superior to audit your current open source LLM implementation and find practical ways to reduce total cost of ownership.
Future Cost Trends
LLM cost dynamics continue evolving rapidly, with several trends reshaping the economic landscape.
Downward Pressure on API Pricing
Competition intensifies among proprietary providers. DeepSeek’s aggressive pricing at $0.28 per million input tokens forced competitors to evaluate their own rates.
Improved inference efficiency reduces provider costs, enabling lower prices while maintaining margins. Continued hardware improvements and algorithmic optimizations should sustain this trend.
More Capable Open-Source Models
The performance gap between open-source and proprietary models narrows continuously. Models released as open-source today match proprietary alternatives from 12-18 months prior.
This trajectory reduces the performance penalty of choosing open-source options, making them viable for more applications.
Specialized Small Models
Task-specific small models trained for particular domains increasingly compete with general-purpose large models on focused applications.
These specialized models run on cheaper hardware with lower operational overhead, improving open-source economics for targeted use cases.
Common Cost Estimation Mistakes
Organizations consistently make predictable errors when evaluating LLM costs.
Ignoring Personnel Costs
The most frequent mistake: treating existing engineering resources as “free” because salaries are already budgeted.
LLM deployment and maintenance consume substantial engineering time. That time carries opportunity cost—engineers working on infrastructure can’t simultaneously build product features.
Proper cost accounting includes fully loaded personnel costs, not just incremental hires.
Underestimating Operational Overhead
Initial deployment represents perhaps 20-30% of total effort over a multi-year lifecycle. Ongoing maintenance, updates, monitoring, and optimization consume the majority.
Organizations budget for deployment but underestimate sustained operational requirements, creating resource crunches post-launch.
Comparing Peak to Average
API costs calculated using peak usage appear inflated compared to fixed infrastructure costs. But most workloads don’t sustain peak continuously—average usage determines actual expenses.
Infrastructure must provision for peak capacity, creating idle resources during typical operation. APIs only charge for actual usage, naturally scaling with demand.
Overlooking Compliance and Security
Security hardening, compliance audits, and regulatory requirements add substantial costs to self-hosted deployments.
Organizations inexperienced with production ML systems routinely underestimate these expenses by 50-100%.
Frequently Asked Questions
Are open-source LLMs really free?
No. While model weights are available without licensing fees, deployment requires substantial infrastructure, specialized engineering talent, and ongoing maintenance. Total cost of ownership for minimal deployments starts around $125K annually, with enterprise implementations exceeding $12M.
When does open-source become cheaper than proprietary APIs?
The break-even point typically falls between 50M–200M tokens monthly, depending on specific API pricing and infrastructure costs. Very high-volume applications (500M+ tokens monthly) almost always favor self-hosting, while lower volumes usually benefit from pay-per-use APIs.
What are the biggest hidden costs of open-source LLMs?
Engineering salaries represent the largest often-overlooked expense, typically consuming 45-55% of total costs. Organizations consistently underestimate the specialized expertise required for deployment, optimization, and ongoing maintenance. Security hardening and compliance work add another frequently underestimated cost dimension.
How much cheaper are open-source LLMs than proprietary options?
It depends entirely on usage volume. At low volumes, proprietary APIs cost substantially less—potentially 5-10x cheaper when accounting for full TCO. At very high volumes, self-hosted infrastructure can reduce per-token costs by 50-80%. The advantage shifts based on scale, customization needs, and available expertise.
What technical expertise is needed to run open-source LLMs?
Production deployments require ML engineers for model optimization, MLOps specialists for deployment infrastructure, DevOps engineers for system management, and software engineers for integration work. Security expertise becomes critical for production systems handling sensitive data. Minimal deployments might consolidate these roles into 1-2 people, while enterprise scale requires dedicated teams.
Can small companies afford open-source LLM deployment?
Most small companies find proprietary APIs more economical unless they have specific requirements like strict data privacy, extensive customization needs, or exceptionally high usage volumes. The $125K+ annual minimum for self-hosting typically exceeds small-company API costs until usage reaches substantial scale.
What’s the best approach for cost-conscious organizations?
Start with proprietary APIs to validate product-market fit and understand usage patterns. This minimizes upfront investment and technical complexity. Consider open-source deployment only after reaching scale where API costs become prohibitive (typically $200K+ annually), and ensure the technical expertise exists to support self-hosted infrastructure effectively.
Conclusion: Making the Right Economic Choice
Open-source LLMs aren’t free—they’re a fundamentally different cost structure that favors specific organizational contexts.
The “free” model weights translate to substantial investments in infrastructure, personnel, and operations. For low-to-moderate usage scenarios, proprietary APIs deliver better economics with dramatically reduced complexity. Organizations pay only for actual usage while offloading deployment, scaling, and maintenance to providers.
Open-source deployments make economic sense at high volumes where per-token API costs become prohibitive, when extensive customization requires deep model access, or where data privacy mandates on-premise processing. These scenarios justify the substantial fixed costs and technical complexity.
The decision requires honest assessment of actual costs—including often-overlooked personnel expenses—against realistic usage projections. Organizations with strong ML engineering capabilities and clear paths to high-volume usage benefit from open-source approaches. Those with limited expertise, moderate usage, or tight timelines typically find APIs more practical.
Most critically, understand the question isn’t “open-source or proprietary” but “which cost model aligns with our usage, capabilities, and requirements.” Answer that honestly, and the economically optimal choice becomes clear.
Ready to evaluate LLM options for your specific use case? Calculate expected token volume, assess technical capabilities, and model both cost structures with realistic assumptions. The numbers will guide the decision better than any general recommendation.