ملخص سريع: تتراوح تكلفة تدريب نموذج لغوي ضخم بين 1.5 مليار و50,000 مليون دولار أمريكي وأكثر من 1.5 مليار و500 مليون دولار أمريكي، وذلك تبعًا لحجم النموذج والبنية التحتية ومدة التدريب. أما النماذج الأصغر حجمًا التي تحتوي على 20 مليار مُعامل، فقد تتراوح تكلفتها بين 1.5 مليار و50,000 مليون و1.5 مليار و100,000 دولار أمريكي، بينما قد تتجاوز تكلفة الأنظمة الضخمة مثل GPT-4 أو Gemini 1.5 مليار و100 مليون دولار أمريكي. وتتمثل أكبر النفقات في وقت الحوسبة باستخدام وحدات معالجة الرسومات (GPU)، وإعداد البيانات، والبنية التحتية السحابية.
أصبحت الجدوى الاقتصادية لتدريب نماذج اللغة الكبيرة عاملاً حاسماً في تطوير الذكاء الاصطناعي. وتواجه المؤسسات الآن قرارات مصيرية بشأن ما إذا كان ينبغي عليها بناء نماذجها الخاصة أو الاشتراك في خدمات تجارية.
أما الأرقام؟ فهي مذهلة.
بحسب أبحاث شركة Epoch AI، فقد كلّف تدريب كل من GPT-4 وGemini من جوجل مئات الملايين من الدولارات. ولا يقتصر الأمر على تحسينات طفيفة مقارنةً بالنماذج السابقة، بل إنّ التكلفة المالية قد ارتفعت بشكلٍ كبير خلال السنوات القليلة الماضية فقط.
لكن الأمر المهم هو أن ليس كل مؤسسة بحاجة إلى نموذج رائد. ففهم هيكل التكاليف يساعد في تحديد النهج الأمثل لحالات الاستخدام المحددة.
ما الذي يؤثر على تكاليف تدريب نماذج اللغة الكبيرة؟
تنقسم تكاليف التدريب إلى عدة فئات رئيسية، تساهم كل منها بشكل كبير في إجمالي الفاتورة.
البنية التحتية للحوسبة
تُهيمن مكونات وحدة معالجة الرسومات (GPU) على قائمة النفقات. تتطلب النماذج التي تحتوي على حوالي 100 مليار مُعامل مكونات متطورة لوحدة معالجة الرسومات، مثل وحدات A100 من NVIDIA. بالنسبة لنموذج يحتوي على 20 مليار مُعامل، تحتاج البنية التحتية عادةً إلى 8-16 وحدة A100 بسعة 80 جيجابايت.
تبلغ تكلفة الحوسبة وحدها ما بين $50,000 و$100,000 لنموذج أصغر. ويمثل هذا الحساب الأساسي - الذي يبلغ تقريبًا $22,000 (16 A100s × $2.75/ساعة × 500 ساعة) - عملية التدريب الناجحة فقط.
لكن انتظر.
قد تؤدي التجارب الفاشلة إلى مضاعفة هذا الرقم أو حتى زيادته ثلاثة أضعاف. تدريب نماذج اللغة الكبيرة ليس عملية تتم لمرة واحدة، فضبط المعلمات الفائقة، وتجارب البنية، واستكشاف الأخطاء وإصلاحها، كلها تستهلك وقتًا إضافيًا للحوسبة.
الوقت والمدة
تتناسب مدة التدريب طرديًا مع حجم النموذج وتعقيده. قد يستغرق تدريب نموذج يحتوي على 20 مليار مُعامل ما بين 500 و1000 ساعة. أما النماذج الأكبر حجمًا التي تحتوي على أكثر من 120 مليار مُعامل، فقد تستغرق آلاف الساعات من وقت وحدة معالجة الرسومات (GPU).
تتراكم تكاليف البنية التحتية السحابية ساعةً بساعة. وهذا يعني أن أي تحسين يقلل وقت التدريب يُخفض النفقات بشكل مباشر. ويُعدّ اختيار المعلمات الفائقة بكفاءة، وتصميم مسار البيانات بشكل أفضل، وتقليل وقت خمول وحدة معالجة الرسومات، أمورًا بالغة الأهمية من الناحية المالية.
إعداد البيانات وإدارتها
لا تظهر بيانات التدريب عالية الجودة من تلقاء نفسها. تستثمر المؤسسات بكثافة في جمع البيانات وتنظيفها وتصنيفها وتنسيقها. وقد زاد النضوب التدريجي للبيانات العامة عالية الجودة من حدة هذا التحدي.
تتراكم تكاليف تخزين البيانات ونقلها أيضاً. فنقل مجموعات البيانات الضخمة بين أنظمة التخزين ومجموعات الحوسبة يستلزم رسوماً على النطاق الترددي والتخزين، وهو ما يقلل الكثير من الميزانيات الأولية من تقديره.

فهم التكلفة الحقيقية لتدريب ماجستير القانون
إن تدريب نموذج لغوي كبير يتطلب أكثر بكثير من مجرد موارد حاسوبية. فهندسة البيانات، وتجربة النموذج، وتقييمه، وبنية النشر التحتية تؤثر أيضاً على التكاليف الإجمالية.
متفوقة الذكاء الاصطناعي يساعد المؤسسات على تقييم ما إذا كان تدريب نموذج من الصفر مبرراً أم أن الأساليب البديلة مثل تكييف النموذج أو تكامل واجهة برمجة التطبيقات أكثر عملية.
تشمل خدماتهم ما يلي:
- تصميم مسار التدريب
- استراتيجية مجموعة البيانات والتحقق من صحتها
- تخطيط البنية التحتية
- تحليل التكلفة والعائد للنماذج المخصصة
إذا كنت تستكشف تطوير برامج إدارة القانون المخصصة، فإن تحليل الجدوى يمكن أن يساعد في تجنب تكاليف التدريب غير الضرورية.
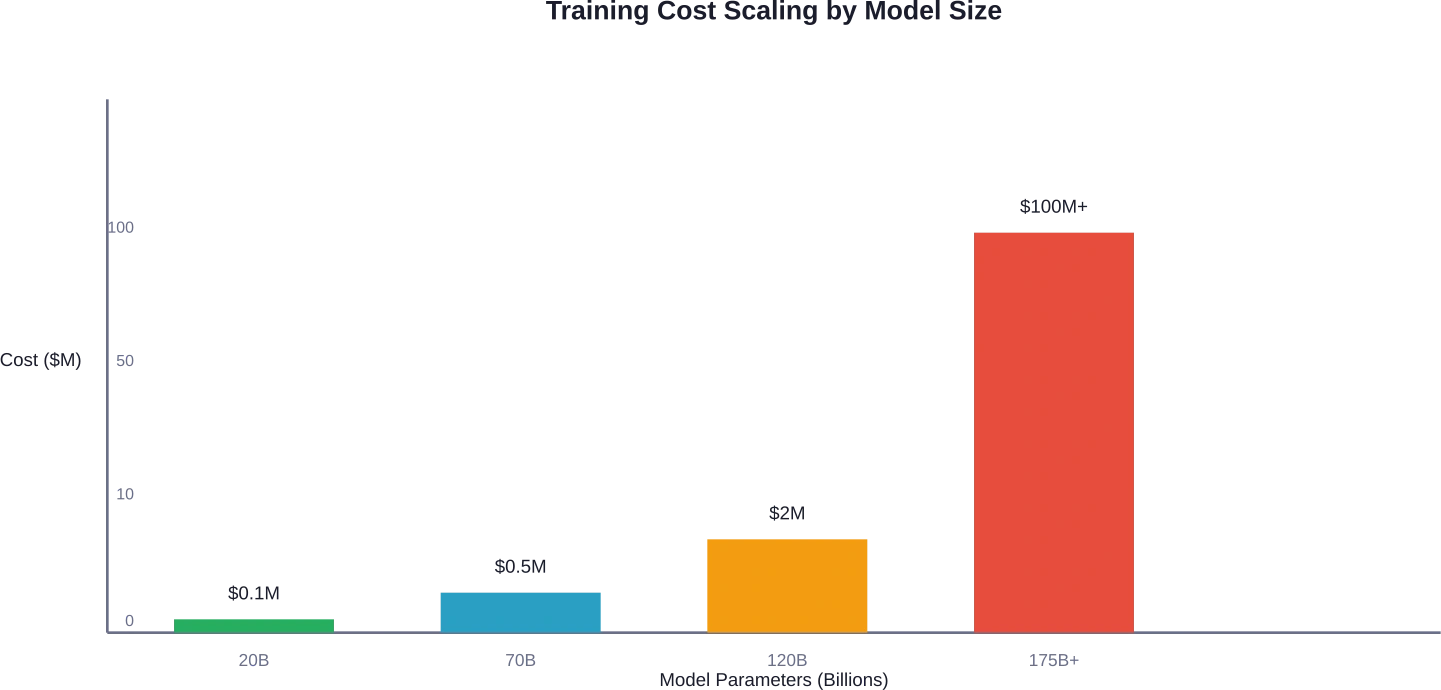
مقارنات التكلفة في الواقع العملي: معايير تتراوح من 20 مليار إلى 120 مليار
دعونا نحلل نطاقات التكلفة الفعلية لأحجام النماذج المختلفة.
| حجم النموذج | متطلبات وحدة معالجة الرسومات | تكلفة الحوسبة الأساسية | التكلفة الإجمالية المقدرة |
|---|---|---|---|
| معلمات 20B | 8-16 A100 80GB | $22,000-$50,000 | $50,000-$100,000 |
| معلمات 70B | 32-64 A100 80GB | $100,000-$250,000 | $200,000-$500,000 |
| أكثر من 120 مليار معلمة | 64-128+ A100 80GB | $300,000-$800,000 | $500,000-$2,000,000 |
| طرازات فرونتير (175B+) | أكثر من 1000 وحدة معالجة رسومية | $50M-$200M+ | $100M-$500M+ |
إن الفجوة بين النماذج الصغيرة والكبيرة ليست خطية، بل هي أسية. فتكلفة نموذج يحتوي على 120 مليار مُعامل تتراوح بين 5 إلى 20 ضعف تكلفة نموذج يحتوي على 20 مليار مُعامل، ليس فقط بسبب عدد المُعاملات، بل أيضاً بسبب تعقيد التدريب، وطول أوقات التقارب، وتكاليف البنية التحتية.
نموذج فرونتير المميز
تعمل أنظمة مثل GPT-4 وGemini ضمن فئة تكلفة مختلفة تمامًا. ووفقًا لبيانات Epoch AI، فقد كلّف تطوير هذه النماذج مئات الملايين من الدولارات.
لماذا هذه الأرقام الفلكية؟
تتطلب النماذج الرائدة مجموعات ضخمة من وحدات معالجة الرسومات (GPU) تعمل لأشهر. وهي تتضمن تجارب مكثفة، وعمليات تدريب متعددة، واختبارات سلامة، وعمليات محاذاة. وتتطلب البنية التحتية وحدها - التي تدير آلاف وحدات معالجة الرسومات في وقت واحد - أنظمة تنسيق متطورة.
تحليل نفقات البنية التحتية
لا تقتصر تكاليف البنية التحتية على استئجار وحدة معالجة الرسومات فحسب، بل يجب على المؤسسات مراعاة جميع جوانب البنية التحتية.
خيارات أجهزة وحدة معالجة الرسومات
لا تزال معالجات الرسوميات A100 من NVIDIA هي المعيار الأمثل لتدريب نماذج التعلم الآلي، على الرغم من أن الإصدارات الأحدث H100 وH200 توفر أداءً أفضل بأسعار أعلى. ويعتمد الاختيار على التوافر والميزانية والجدول الزمني.
تختلف أسعار مزودي الخدمات السحابية. فلكل من AWS وGoogle Cloud وMicrosoft Azure هياكل تسعير خاصة بوحدات معالجة الرسومات (GPU). وقد يقدم المزودون المتخصصون في تطبيقات الذكاء الاصطناعي أسعارًا أفضل للاستخدام المستمر.
التخزين والشبكات
تستهلك نقاط التحقق من النموذج وبيانات التدريب والسجلات مساحة تخزين كبيرة. ينتج عن نموذج ذي 120 بايت من المعلمات ملفات نقاط تحقق يتجاوز حجم كل منها 500 جيجابايت. عادةً ما تحفظ المؤسسات نقاط تحقق متعددة خلال عملية التدريب لأغراض الاستعادة والتحليل.
كما أن عرض النطاق الترددي للشبكة مهم أيضاً. فنقل البيانات بين التخزين والحوسبة، وخاصة للتدريب الموزع عبر عدة عقد، يمكن أن يضيف آلاف الدولارات إلى الفاتورة الشهرية.
الاستضافة والنشر
تكاليف التدريب ليست سوى البداية. فاستضافة هذه النماذج للاستدلال تتطلب نفقات مستمرة. بالنسبة للنماذج التي تحتوي على حوالي 100 مليار مُعامل، تتراوح تكاليف الاستضافة من $50,000 إلى $500,000 دولار أمريكي سنويًا، وذلك حسب حجم النموذج وأنماط استخدامه.
قد تستبعد تكاليف التطوير التي يتم ذكرها على نطاق واسع للنماذج المقطرة مثل DeepSeek-V3 نفقات تدريب نماذج المعلمين الأكثر قوة التي اشتُقت منها، مما يوضح كيف يمكن لأساليب المحاسبة أن تحجب إجمالي استثمارات التطوير.
استراتيجيات التحسين لتقليل تكاليف التدريب
هناك العديد من التقنيات التي يمكن أن تقلل بشكل كبير من نفقات التدريب دون التضحية بجودة النموذج.
التكميم والدقة المختلطة
أثبتت أطر التكميم FP4 لنماذج التعلم المحدود إمكانية تحقيق دقة مماثلة لـ BF16 وFP8 مع أدنى حد من التدهور في النماذج واسعة النطاق. تقلل هذه التقنية من متطلبات الذاكرة وتسرع الحساب، مما يقلل بشكل مباشر من وقت وحدة معالجة الرسومات (GPU) اللازم.
أصبح التدريب المختلط الدقة ممارسة معيارية. فاستخدام دقة أقل في عمليات معينة مع الحفاظ على دقة أعلى في العمليات المهمة يوازن بين السرعة والدقة بشكل فعال.
أساليب التدريب للرتب الدنيا
يؤدي تطبيق معلمات منخفضة الرتبة على نماذج التعلم الخطي القائمة على المحولات إلى تقليل التكاليف الحسابية، بل وقد يحسن الأداء في بعض الحالات. تعمل هذه الطرق على ضغط فضاء المعلمات مع الحفاظ على قدرة النموذج على التعبير.
استراتيجيات البيانات الفعالة
تشير الأبحاث حول قوانين التوسع الأمثل لـ Chinchilla إلى أن مطور LLM الذي يقوم بتدريب نموذج 13B ويتوقع 2 تريليون رمز من طلب الاستدلال يمكنه تقليل إجمالي الحساب بحوالي 1.7 × 10²² FLOPs (17%) عن طريق تدريب نماذج أصغر لفترة أطول.
ما هي الفكرة الأساسية؟ التدريب لفترة أطول قليلاً باستخدام بيانات أكثر يمكن أن يقلل من تكاليف الاستدلال لاحقاً إذا كان النموذج سيخدم العديد من الطلبات. التكلفة الإجمالية للملكية أهم من تكلفة التدريب وحدها.

مثيلات Spot والأجهزة الافتراضية القابلة للمقاطعة
يُقدّم مُزوّدو الخدمات السحابية خصومات على استخدام الخوادم الفورية التي يُمكن إيقافها مؤقتًا. بالنسبة لعمليات التدريب التي تتحمّل الأعطال مع نقاط تفتيش منتظمة، تُخفّض الخوادم الفورية التكاليف بنسبة تتراوح بين 40 و70% مقارنةً بأسعار الخوادم عند الطلب.
المقابل؟ قد يستغرق التدريب وقتاً أطول بسبب الانقطاعات. ولكن مع إدارة نقاط التفتيش بشكل سليم، فإن التوفير عادةً ما يبرر هذا التعقيد.
قرار البناء مقابل الشراء
تواجه المنظمات خياراً أساسياً: إما تدريب نموذجها الخاص أو استخدام الخدمات التجارية.
متى تكون الخدمات التجارية منطقية
في معظم حالات الاستخدام، يُعد الاشتراك في خدمات إدارة التعلم الآلي التجارية أكثر اقتصادية. توفر واجهات برمجة التطبيقات من OpenAI وAnthropic وGoogle إمكانية الوصول إلى نماذج رائدة دون الحاجة إلى استثمار رأسمالي مسبق.
بحسب أبحاث تحليل التكلفة والعائد، تحتاج المؤسسات إلى استخدام مستدام وكبير لتحقيق نقطة التعادل مع الخدمات التجارية. وتشير الدراسات إلى أن عتبات تكافؤ الأداء التي تقارب 20% للنماذج التجارية الرائدة تُمثل نقاط تعادل مجدية للاستثمار في البنية التحتية.
متى يكون التدريب منطقياً
يصبح التدريب المخصص جذابًا عندما:
- تتطلب المتطلبات الخاصة بالمجال بيانات تدريب متخصصة
- تمنع لوائح خصوصية البيانات إرسال المعلومات إلى واجهات برمجة التطبيقات التابعة لجهات خارجية.
- من المتوقع أن يتجاوز حجم الاستدلال ملايين الطلبات شهرياً
- أثبتت عملية الضبط الدقيق للنماذج التجارية عدم كفايتها لحالة الاستخدام.
يمكن للمؤسسات التي تتوقع استخدامًا مكثفًا ومستدامًا على مدى سنوات عديدة تحقيق تكلفة إجمالية أفضل للملكية باستخدام النماذج المستضافة ذاتيًا. وتعتمد نقطة التعادل على حجم النموذج، وحجم الطلبات، ومستويات الأداء المطلوبة.
اعتبارات الحوسبة أثناء الاختبار
تكشف الأبحاث الحديثة حول تخصيص موارد الحوسبة أثناء الاختبار عن بُعد آخر للتكلفة. إذ يمكن أن تتجاوز تكاليف الاستدلال تكاليف التدريب بالنسبة للنماذج واسعة الانتشار.
تُحسّن استراتيجيات التخصيص التكيفية، التي تُخصّص موارد الحوسبة ديناميكيًا بناءً على صعوبة الاستعلام، الكفاءة بشكل كبير. وتساعد مؤشرات الصعوبة التي لا تتطلب تدريبًا على توزيع ميزانيات الحوسبة الثابتة على استعلامات الاختبار، مما يزيد من عدد الحالات التي تم حلها مع الالتزام بقيود الميزانية.
تُظهر الأبحاث المتعلقة بالوكلاء الفعالين أن تصميم الإطار الأمثل له أهمية بالغة. فقد وجدت إحدى الدراسات إطارًا يحافظ على أداء 96.7% لأحد الوكلاء الرائدين مفتوحي المصدر، مع خفض تكاليف التشغيل من 0.398 إلى 0.228، أي بتحسن قدره 28.4% في تكلفة المرور.
مبادئ المحاسبة لتكاليف تطوير الذكاء الاصطناعي
يستخدم صناع السياسات بشكل متزايد تكلفة التطوير والحوسبة كمؤشرات بديلة لقدرات الذكاء الاصطناعي ومخاطره. وقد أدخلت القوانين الحديثة متطلبات تنظيمية مشروطة بعتبات تكلفة محددة.
لكن تكمن المشكلة هنا: فالغموض التقني في محاسبة التكاليف يخلق ثغرات. إذ يمكن للمحاسبة الضيقة أن تحجب التكاليف الإجمالية لتطوير النموذج. وقد لا تشمل تكاليف التطوير المعلنة على نطاق واسع للنماذج المُبسطة مثل DeepSeek-V3 نفقات تدريب نماذج تعليمية أكثر قوة، والتي اشتُقت منها.
ينبغي على المنظمات اعتماد نظام محاسبة شامل يتضمن ما يلي:
- جميع عمليات التدريب، بما في ذلك التجارب الفاشلة
- تكاليف الحصول على البيانات وتنظيفها وإعدادها
- تكاليف البنية التحتية والشبكات
- الوقت اللازم لتطوير البنية الهندسية
- اختبارات السلامة وأعمال المحاذاة
- تكاليف نماذج المعلمين لأساليب التقطير
| فئات التكلفة | نموذجي % من الإجمالي | هل يتم تجاهلها في كثير من الأحيان؟ |
|---|---|---|
| معالجة وحدة معالجة الرسومات (تشغيل ناجح) | 30-40% | لا |
| تجارب فاشلة | 15-25% | نعم |
| إعداد البيانات | 10-15% | نعم |
| التخزين والشبكات | 5-10% | نعم |
| عمالة الهندسة | 20-30% | أحيانا |
| السلامة والمحاذاة | 5-10% | نعم |
اتجاهات التكاليف المستقبلية
ستؤثر عدة عوامل على تكاليف التدريب في السنوات القادمة.
تستمرّ أجهزة معالجة الرسومات في التطور. تعد بنية بلاكويل من إنفيديا - بما في ذلك إصدارات B100 وB200 وGB200 - بأداء أفضل مقابل السعر. لكن الطلب المتزايد يُبقي الأسعار مرتفعة.
تتزايد تكاليف البيانات. ومع تزايد ندرة البيانات العامة عالية الجودة، تستثمر المؤسسات بشكل أكبر في مجموعات البيانات الخاصة، وتوليد البيانات الاصطناعية، واتفاقيات ترخيص البيانات.
مع ذلك، فإن التحسينات الخوارزمية وزيادة كفاءة التدريب تعوض جزئياً تكاليف الأجهزة. ويواصل مجتمع البحث العلمي تطوير أساليب تحسين أفضل، وقوانين التوسع، وتصاميم معمارية متطورة.
الأسئلة الشائعة
كم تبلغ تكلفة تدريب نموذج يحتوي على 70 مليار مُعامل؟
تتراوح تكلفة تدريب نموذج يحتوي على 70 مليار مُعامل عادةً بين $200,000 و$500,000. ويشمل ذلك تكاليف الحوسبة الأساسية التي تتراوح بين $100,000 و$250,000 لـ 32-64 وحدة معالجة رسومية A100، بالإضافة إلى نفقات إضافية لتشغيلات فاشلة، وتجارب، وإعداد البيانات، وتكاليف البنية التحتية.
هل تستطيع المؤسسات الصغيرة تحمل تكاليف تدريب نماذج لغوية كبيرة؟
بإمكان المؤسسات الصغيرة تدريب نماذج متوسطة الحجم (من مليار إلى 20 مليار مُعامل) لنطاق $10,000 إلى $100,000 باستخدام موارد وحدات معالجة الرسومات السحابية وتقنيات التحسين. مع ذلك، في معظم التطبيقات، يُعد استخدام خدمات واجهة برمجة التطبيقات التجارية أو ضبط نماذج المصادر المفتوحة الموجودة أكثر فعالية من حيث التكلفة مقارنةً بالتدريب من الصفر.
ما هو الجزء الأكثر تكلفة في تدريب الحاصلين على درجة الماجستير في القانون؟
يمثل وقت معالجة وحدة معالجة الرسومات (GPU) ما بين 30 و401 تريليون دولار من إجمالي تكاليف معظم المشاريع. ومع ذلك، عند احتساب التجارب الفاشلة وضبط المعلمات الفائقة، غالبًا ما تتجاوز النفقات المتعلقة بالمعالجة 501 تريليون دولار من إجمالي الميزانية. وعادةً ما تمثل أجور المهندسين ما بين 20 و301 تريليون دولار إضافية.
كم من الوقت يستغرق تدريب نموذج لغوي كبير؟
تختلف مدة التدريب اختلافًا كبيرًا باختلاف حجم النموذج. قد يستغرق تدريب نموذج يحتوي على 20 مليار مُعامل ما بين 500 و1000 ساعة من استخدام وحدة معالجة الرسومات (أي ما يقارب 3 إلى 6 أسابيع على مجموعة حاسوبية تضم 16 وحدة معالجة رسومات). أما النماذج الأكبر حجمًا التي تحتوي على 120 مليار مُعامل أو أكثر، فقد تتطلب آلاف الساعات من استخدام وحدة معالجة الرسومات، مما يمدد فترة التدريب إلى ما بين شهرين وأربعة أشهر. غالبًا ما تستغرق نماذج Frontier التي تحتوي على 175 مليار مُعامل أو أكثر عدة أشهر للتدريب على مجموعات حاسوبية ضخمة.
هل التدريب لمرة واحدة أرخص أم استخدام استدعاءات واجهة برمجة التطبيقات على المدى الطويل؟
يعتمد هذا الأمر كلياً على حجم الاستخدام. بالنسبة للتطبيقات التي تُجري أقل من 10 ملايين استدعاء لواجهة برمجة التطبيقات شهرياً، عادةً ما تكون الخدمات التجارية أقل تكلفة. أما المؤسسات التي تشهد استخداماً مستمراً وعالي الحجم - وخاصةً تلك التي تحتاج إلى نماذج متخصصة أو لديها متطلبات خصوصية البيانات - فقد تجد أن التدريب الذاتي أكثر اقتصادية على مدى عدة سنوات.
ما الفرق بين تكلفة التدريب وتكلفة الاستدلال؟
تكلفة التدريب هي التكلفة لمرة واحدة لتطوير النموذج، وتتراوح بين آلاف ومئات الملايين من الدولارات. أما تكلفة الاستدلال فهي التكلفة المستمرة لتشغيل النموذج للتنبؤات، وتُحتسب بناءً على كل طلب أو رمز مميز. بالنسبة للنماذج واسعة الانتشار، غالبًا ما تتجاوز تكاليف الاستدلال الإجمالية طوال عمر النموذج تكاليف التدريب.
كيف يمكنني تقليل تكاليف التدريب في برنامج الماجستير في القانون؟
تشمل استراتيجيات خفض التكاليف الرئيسية استخدام التكميم (تدريب FP4/FP8)، والاستفادة من مثيلات Spot لتحقيق وفورات تتراوح بين 40 و70%، وتنفيذ نقاط التفتيش الفعالة لتقليل الحوسبة المهدرة، وتحسين مسارات البيانات لتقليل وقت وحدة معالجة الرسومات الخاملة، والنظر في تقطير النموذج من نماذج المعلم الأكبر حجمًا عند الاقتضاء.
اتخاذ قرار الاستثمار
لا يزال تدريب نماذج اللغة الكبيرة مكلفاً، لكن التكاليف تتفاوت. لا تواجه المؤسسات خياراً ثنائياً بين النماذج المتقدمة وعدم استخدام أي شيء.
يبدأ التقييم الواقعي بمتطلبات حالة الاستخدام. ما هو مستوى الأداء الذي يحل مشكلة العمل فعلياً؟ هل يتطلب التطبيق إمكانيات متطورة، أم أن نموذجاً متخصصاً أصغر حجماً يكفي؟
في العديد من التطبيقات، تُحقق النماذج التي تتراوح معلماتها بين 7 و20 مليارًا نتائج ممتازة بتكاليف معقولة. ويمكن تدريب هذه الأنظمة على نطاق يتراوح بين $50,000 و$200,000، مما يجعلها في متناول المؤسسات متوسطة الحجم ذات الاحتياجات الخاصة في مجالات محددة.
إنّ سباق تطوير النماذج المتقدمة، الذي يتجه نحو أكثر من 175 مليار مُعامل وما فوق، يُعدّ منطقياً بالدرجة الأولى للشركات التي تُطوّر منصات ذكاء اصطناعي عامة الأغراض. أما بالنسبة للآخرين، فإنّ الخيار الأمثل غالباً ما يكمن في النماذج الأصغر حجماً والمتخصصة والمُحسّنة لمهام مُحدّدة.
انظر إلى التكلفة الإجمالية للملكية. التدريب ليس سوى البداية. ضع في اعتبارك تكاليف الاستضافة والاستدلال والصيانة المستمرة وفريق الهندسة اللازم لدعم النظام.
تتطور اقتصاديات تطوير التعلم الآلي باستمرار. تتحسن الأجهزة، وتصبح الخوارزميات أكثر كفاءة، وتظهر تقنيات تدريب جديدة بانتظام. ما يكلف اليوم $500,000 قد يكلف $200,000 خلال عامين، أو قد يحقق أداءً أفضل بثلاثة أضعاف بنفس السعر.
ينبغي للمؤسسات الراغبة في دخول هذا المجال أن تبدأ على نطاق صغير، وأن تقيس بدقة، ثم تتوسع بناءً على القيمة المُثبتة. لقد نضجت التكنولوجيا بما يكفي بحيث لم يعد التجريب يتطلب استثمارًا ضخمًا مُسبقًا. يُنصح بإنشاء نماذج أولية مصغرة، والتحقق من صحة النهج، ثم تحديد ما إذا كان التوسع أو الاستمرار في استخدام واجهات برمجة التطبيقات التجارية هو الخيار الأنسب.
تتسارع ثورة الذكاء الاصطناعي باستمرار، لكن النشر الذكي يتفوق على مجرد التوسع. يساعد فهم هياكل التكلفة هذه المؤسسات على اتخاذ قرارات مدروسة بدلاً من السعي وراء معايير قد لا تكون ذات أهمية لتطبيقاتها المحددة.