ملخص سريع: تشمل أفضل منصات تحليلات إدارة دورة حياة التطبيقات (LLM) لتتبع التكلفة والجودة في عام 2026 منصة Confident AI للمراقبة التي تركز على التقييم مع تسعير قائم على الاستخدام، ومنصة Langfuse للمراقبة مفتوحة المصدر مع تتبع الجلسات، ومنصة Datadog LLM Observability للتتبع على نطاق المؤسسات. وتتصدر منصة MiniMax M2.5 القائمة كأكثر النماذج فعالية من حيث التكلفة مع جودة تحليلية عالية، بينما تُظهر أطر عمل AgServe كيف يمكن للخدمة الواعية بالجلسات أن تحقق جودة مكافئة لـ GPT-40 بتكلفة أقل بنسبة 16.5%.
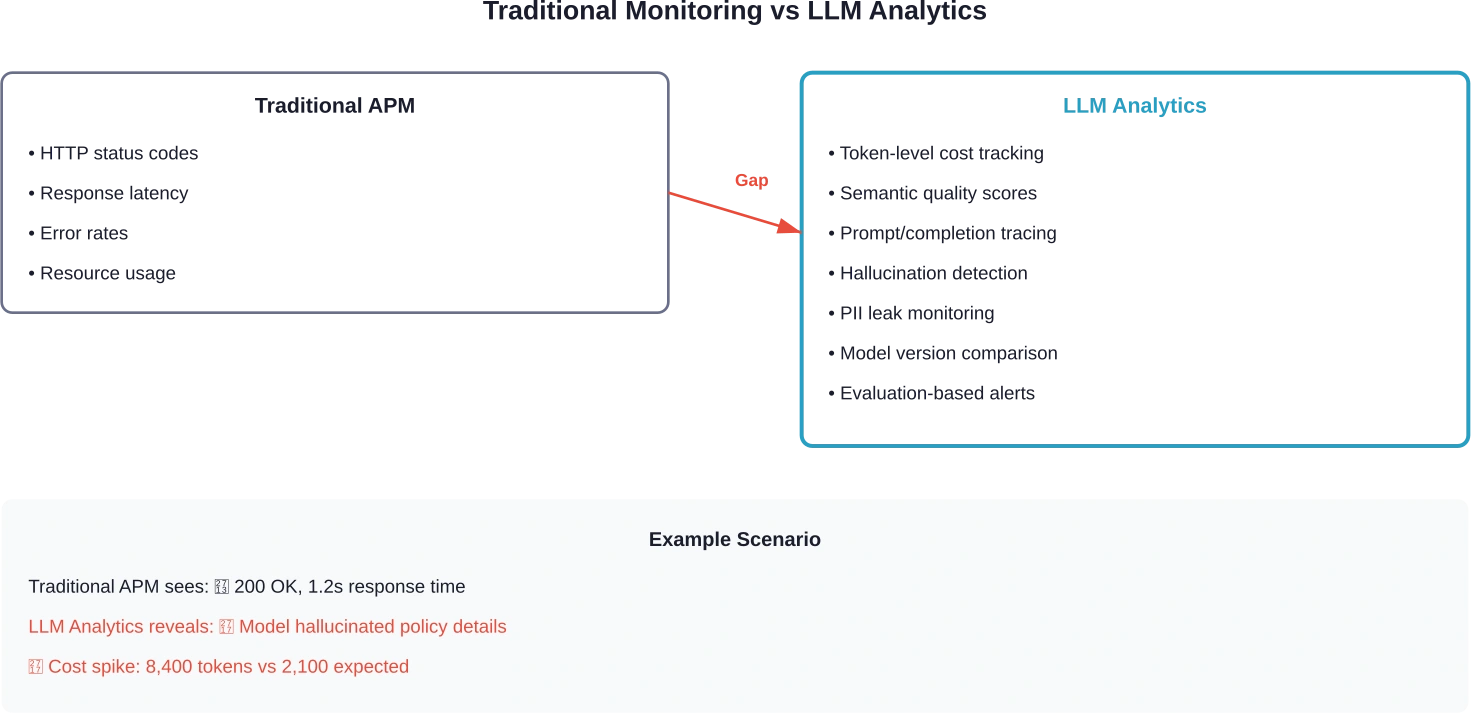
لا تستطيع أنظمة المراقبة التقليدية رصد إخفاقات الذكاء الاصطناعي. قد تُظهر لوحة معلومات إدارة أداء التطبيقات استجابةً برمز 200 في غضون 1.2 ثانية، لكنها لن تكشف أن النموذج قد أخطأ في فهم تفاصيل السياسة، أو سرب معلومات حساسة، أو انحرف عن الموضوع في منتصف المحادثة.
هذا هو الخلل الذي تسدّه أدوات تحليل نماذج التعلم الآلي. فهي تتعقب المطالبات والإكمالات، وتحسب تكاليف الرموز لكل طلب، وتكتشف انحراف الجودة عبر إصدارات النموذج، وتكشف أنماط الفشل التي تغفلها منصات المراقبة القياسية تمامًا.
مع توسع نطاق التطبيقات المدعومة بتقنية إدارة دورة حياة التطبيقات (LLM) من مرحلة النموذج الأولي إلى مرحلة الإنتاج، قد ترتفع تكاليف الرموز بشكل كبير. ويمكن لسلسلة مطالبات واحدة غير مُحسَّنة أن تُضاعف النفقات عشرة أضعاف. وبدون رؤية فورية لأنماط الاستخدام، غالبًا ما تكتشف الفرق تجاوزات الميزانية بعد فوات الأوان.
يُفصّل هذا الدليل أفضل منصات تحليل إدارة دورة حياة المنتج (LLM) لتتبع كلٍ من التكلفة والجودة. سنتناول ما يُميّز كل أداة، وكيف تُقارن الأسعار بين مختلف الموردين، وأي المنصات تُناسب سيناريوهات النشر المُحددة.
لماذا يُعدّ تتبّع تكلفة وجودة برامج الماجستير في القانون أمرًا مهمًا؟
تختلف أنظمة الذكاء الاصطناعي المستخدمة في الإنتاج عن البرامج التقليدية في طريقة فشلها. فخادم الويب إما أن يُعيد البيانات أو يُظهر خطأً. أما نظام إدارة التعلم الآلي (LLM) فيمكنه إعادة بيانات JSON مُنسقة بشكل مثالي تحتوي على معلومات مُختلقة بالكامل.
يمثل التحكم في التكاليف تحديًا آخر. فالتسعير القائم على الرموز يعني أن أي تعديل فوري يُغير من الجدوى الاقتصادية. وقد يؤدي إضافة سياق لتحسين الجودة إلى زيادة تكلفة الطلب الواحد ثلاثة أضعاف. أما التحول من GPT-4 إلى نموذج أصغر فقد يُخفض التكاليف بمقدار 90%، ولكنه يُقلل من دقة المخرجات إلى ما دون المستويات المقبولة.
تشير الأبحاث المتعلقة بأنظمة خدمة الوكلاء إلى أن منصات خدمة النماذج الحالية تفتقر إلى الوعي بالجلسات، مما يؤدي إلى مفاضلات غير ضرورية بين التكلفة والجودة. يُظهر إطار عمل AgServe أن إدارة ذاكرة التخزين المؤقت للقيم والمفاتيح الواعية بالجلسات، بالإضافة إلى تسلسل النماذج القائم على الجودة، يمكن أن يحقق جودة استجابة مماثلة لـ GPT-40 بتكلفة أقل بنسبة 16.5% فقط.
إليك ما تُتيحه تحليلات برامج الماجستير في القانون بشكل صحيح:
- إسناد التكلفة على مستوى الرمز المميز عبر المطالبات والمستخدمين والميزات وإصدارات النماذج
- كشف الانحرافات عالية الجودة من خلال نتائج التقييم الآلي وحلقات التغذية الراجعة البشرية
- تتبع زمن الاستجابة هذا يفصل وقت استجابة واجهة برمجة التطبيقات عن وقت معالجة النموذج
- تحليل أنماط الفشل التي تكشف عن محفزات الهلوسة الشائعة أو أخطاء التنسيق
- مراقبة السلامة فيما يتعلق بتسريب المعلومات الشخصية، ومحاولات الحقن الفوري، وانتهاكات سياسة المحتوى
بدون هذه القدرات، تعمل الفرق بشكل أعمى. لا يمكنها تحسين قرارات الهندسة السريعة، ولا يمكنها إثبات عائد الاستثمار لأصحاب المصلحة، ولا يمكنها اكتشاف تدهور الجودة قبل أن يؤثر على المستخدمين.
ما الذي يميز تحليلات ماجستير القانون عن قابلية المراقبة القياسية؟
تتتبع أدوات إدارة أداء التطبيقات القياسية الطلبات والأخطاء وزمن الاستجابة. هذا ضروري ولكنه غير كافٍ لتطبيقات إدارة دورة حياة التطبيقات.
الفرق الجوهري: يجب أن تُقيّم تحليلات برنامج الماجستير في القانون (LLM) الجودة الدلالية لا يقتصر الأمر على نجاح استدعاء واجهة برمجة التطبيقات، بل يشمل أيضاً مخرجات النظام. فرمز الحالة 200 لا يُخبرك شيئاً عن دقة نصيحة النموذج أو ملاءمتها أو سلامتها.
ثلاث قدرات تميز التحليلات الخاصة بإدارة التعلم عن المراقبة التقليدية:
حساب التكلفة باستخدام الرموز المميزة
يستهلك كل استدعاء لواجهة برمجة التطبيقات رموز إدخال (للمطالبة) ورموز إخراج (للإكمال). تختلف التكاليف باختلاف النموذج ونوع الرمز، وأحيانًا باختلاف وقت اليوم. يتطلب تتبع التكاليف بدقة تحليل بيانات الاستخدام الوصفية من كل استجابة لواجهة برمجة التطبيقات ونسبتها إلى مركز التكلفة الصحيح.
بحسب وثائق أنثروبيك حول إدارة التكاليف، يوفر الأمر /cost إحصائيات مفصلة عن استخدام الرموز، بما في ذلك التكلفة الإجمالية، ومدة واجهة برمجة التطبيقات، والمدة الفعلية، وتغييرات التعليمات البرمجية. يُمكّن هذا التتبع الدقيق الفرق من تحديد العمليات المكلفة قبل توسيع نطاقها.
مقاييس الجودة القائمة على التقييم
لا يمكن استنتاج الجودة من رموز حالة HTTP. تحلّ منصات التحليلات هذه المشكلة من خلال إجراء تقييمات آلية عند كل عملية إكمال. تتحقق هذه التقييمات من عدم وجود أخطاء، وتقيس مدى ملاءمة النتائج للمخرجات المتوقعة، وتتحقق من توافق التنسيق، وتُشير إلى انتهاكات السلامة المحتملة.
تؤكد أبحاث شركة أنثروبيك حول تقييم الوكلاء أن التقييمات الجيدة تساعد الفرق على إطلاق وكلاء الذكاء الاصطناعي بثقة أكبر. فبدونها، تقع الفرق في دوامة ردود الفعل، حيث لا تكتشف المشكلات إلا في بيئة الإنتاج، ما يؤدي إلى ظهور مشكلات أخرى عند إصلاح عطل واحد.
تتبع الإنجاز الفوري
تسجل السجلات القياسية نقاط النهاية ورموز الحالة. أما تتبع LLM فيسجل دورة الاستجابة الكاملة، بما في ذلك رسائل النظام، ومدخلات المستخدم، واستدعاءات الدوال، ومعلمات النموذج، والمخرجات النهائية. يُعد هذا السياق أساسيًا لتصحيح أخطاء الجودة وتحسين الاستجابة.
توضح إرشادات OpenAI بشأن التقييم باستخدام Langfuse كيف أن تتبع الخطوات الداخلية لسير عمل الوكيل يمكّن من وضع استراتيجيات تقييم عبر الإنترنت وغير متصلة بالإنترنت تستخدمها الفرق لإيصال الوكلاء إلى مرحلة الإنتاج بشكل موثوق.
أفضل منصات تحليل بيانات برامج الماجستير في القانون لعام 2026
لقد نضج سوق تحليلات برامج الماجستير في القانون بشكل ملحوظ. وتنقسم المنصات الآن إلى ثلاث فئات: أدوات تركز على التقييم، وأطر مراقبة مفتوحة المصدر، ومجموعات مراقبة المؤسسات.
إليكم مقارنة بين المنصات الرائدة:
الذكاء الاصطناعي الواثق
يركز نظام الذكاء الاصطناعي الموثوق به على مراقبة جودة إدارة دورة حياة البرمجيات (LLM) من خلال التقييمات ومقاييس الجودة المنظمة بدلاً من المراقبة على غرار إدارة أداء التطبيقات (APM). فهو يجمع بين تسجيل التقييم الآلي، وتتبع إدارة دورة حياة البرمجيات، واكتشاف الثغرات الأمنية، والتعليقات البشرية في منصة واحدة.
تتألق هذه الأداة للفرق التي تعطي الأولوية لضمان الجودة على حساب إمكانية المراقبة العامة. يتم تقييم كل سجل تلقائيًا وفقًا لمقاييس قابلة للتكوين مثل الصلة، ومعدل التكرار، والامتثال للتنسيق.
الميزات الرئيسية:
- مكتبة تقييم مدمجة تضم أكثر من 20 مقياسًا للجودة
- دعم مخصص للمقيّمين لإجراء فحوصات الجودة الخاصة بالمجال
- دمج التغذية الراجعة البشرية في سير عمل RLHF
- فحص الثغرات الأمنية لمنع الحقن الفوري وتسريب المعلومات الشخصية الحساسة
- إصدار مجموعة البيانات لاختبار الانحدار
التسعير: يعتمد التسعير على الاستخدام، مما يجعله خيارًا مناسبًا للفرق ذات أحجام التتبع المتوسطة. ينبغي تقييم توقعات التكلفة خلال فترة الإعداد.
الأفضل لـ: فرق تركز على ضمان الجودة ودورات التطوير القائمة على التقييم.
لانغفوس
توفر Langfuse إمكانية مراقبة إدارة دورة حياة اللغة (LLM) مفتوحة المصدر مع تتبع كامل لإتمام التعليمات، وتتبع تكلفة الرموز، ومراقبة الجودة. تدعم المنصة نماذج النشر الذاتي والسحابي.
وفقًا لدليل OpenAI حول تقييم الوكلاء باستخدام Langfuse، فإن المنصة تراقب خطوات الوكيل الداخلية وتتيح مقاييس التقييم عبر الإنترنت وغير المتصلة بالإنترنت التي تستخدمها الفرق لإيصال الوكلاء إلى مرحلة الإنتاج بشكل موثوق.
يتفوق برنامج Langfuse في تتبع الجلسات، حيث يقوم بتجميع الآثار ذات الصلة في جلسات لتسهيل المحادثات متعددة المراحل وتحليل سير العمل الوكيل.
الميزات الرئيسية:
- نطاقات تتبع غير محدودة في الخطة الاحترافية
- تتبع المحادثات على أساس الجلسات
- تقييم النتائج في الوقت الفعلي
- تحديد تكلفة الإسناد لكل مستخدم أو ميزة أو نموذج
- نواة مفتوحة المصدر مع خيار السحابة المؤسسية
التسعير: تقدم Langfuse Cloud ثلاث باقات: باقة الهواة (٥٠ ألف وحدة شهريًا مجانًا)، وباقة الأساسيات (١TP4T29 شهريًا + الاستخدام)، وباقة المحترفين (١TP4T199 شهريًا + الاستخدام). تتضمن كلتا الباقتين المدفوعتين ١٠٠ ألف وحدة، مع إمكانية استخدام إضافية تبدأ من ١TP4T8 لكل ١٠٠ ألف وحدة.
الأفضل لـ: الفرق التي ترغب في مرونة المصادر المفتوحة مع استضافة سحابية اختيارية، وخاصة لتطبيقات المحادثة متعددة الأدوار.
هيليكون
توفر منصة Helicone إمكانية مراقبة خفيفة الوزن لإدارة دورة حياة التطبيقات (LLM) مع التركيز على تحسين التكلفة. تعمل المنصة كطبقة وسيطة بين التطبيقات وواجهات برمجة تطبيقات إدارة دورة حياة التطبيقات، حيث تلتقط كل طلب دون الحاجة إلى تغييرات في التعليمات البرمجية.
تُسهّل بنية الوكيل عملية النشر. بمجرد تغيير نقطة نهاية واجهة برمجة التطبيقات، يبدأ Helicone بتسجيل الطلبات فورًا. لكن هذه البساطة تأتي مع بعض السلبيات: مرونة أقل في التقييمات المخصصة، وعدم وجود مقاييس جودة مدمجة.
الميزات الرئيسية:
- التكامل بدون كتابة أي كود عبر وكيل واجهة برمجة التطبيقات (API).
- تتبع استخدام الرموز المميزة عبر النماذج
- مراقبة التكاليف وتنبيهات الميزانية
- طبقة تحليل زمن الاستجابة والتخزين المؤقت
- دعم لأكثر من 10 جهات تقدم برامج الماجستير في القانون
التسعير: تتضمن الباقة المجانية 10 آلاف طلب شهريًا. أما الباقة الاحترافية فتبدأ من $79 شهريًا مع تسعير يعتمد على الاستخدام.
الأفضل لـ: الفرق التي تحتاج إلى رؤية سريعة للتكاليف دون متطلبات تقييم شاملة.
إمكانية مراقبة Datadog LLM
قامت Datadog بتوسيع منصة مراقبة المؤسسات الخاصة بها لتشمل تطبيقات إدارة دورة حياة التطبيقات (LLM). يتيح هذا التكامل عرض بيانات تتبع LLM في نفس لوحة التحكم التي تعرض مقاييس البنية التحتية وبيانات إدارة أداء التطبيقات (APM) والسجلات.
تساعد هذه الرؤية الموحدة الفرق على ربط أداء إدارة دورة حياة التعلم بسلوك النظام الأساسي. قد يرتبط بطء الإنجاز بزمن استجابة قاعدة البيانات، وقد تتزامن الزيادات المفاجئة في التكلفة مع إصدارات ميزات محددة.
الميزات الرئيسية:
- مراقبة موحدة عبر البنية التحتية وطبقة إدارة دورة حياة المنتج
- تتبع التكاليف في الوقت الفعلي واكتشاف الحالات الشاذة
- تفصيل استخدام الرموز المميزة حسب نقطة النهاية والمستخدم
- دعم المقاييس المخصصة لمؤشرات الأداء الرئيسية الخاصة بالمجال
- ميزات أمان المؤسسة والامتثال
التسعير: متكامل مع اشتراك Datadog الحالي. راجع الموقع الرسمي للاطلاع على الخطط الحالية المصممة خصيصًا لتلبية احتياجات مراقبة LLM.
الأفضل لـ: فرق المؤسسات التي تستخدم Datadog بالفعل والتي ترغب في دمج مراقبة إدارة دورة حياة البرامج (LLM) في مجموعة أدوات المراقبة الحالية الخاصة بها.
أوزان ونسيج مائل
يُوسّع برنامج Weave إمكانيات تتبع التجارب الخاصة ببرنامج W&B لتشمل تطبيقات LLM. فهو يتتبع قوالب المطالبات، ومعلمات النموذج، والمخرجات عبر التجارب، مما يُسهّل مقارنة اختلافات المطالبات وتكوينات النموذج.
تتفوق المنصة في التقييم دون اتصال بالإنترنت. يمكن للفرق تسجيل آثار الإنتاج، وإعادة تشغيلها مقابل نماذج أو مطالبات مختلفة، وقياس اختلافات الجودة قبل نشر التغييرات.
الميزات الرئيسية:
- سير عمل يركز على التجربة لتحقيق التحسين السريع
- التقييم دون اتصال بالإنترنت مع إعادة تشغيل التتبع
- تتبع التكاليف لكل تجربة ونوع النموذج
- التكامل مع أدوات دورة حياة التعلم الآلي الخاصة بشركة W&B
- إدارة مجموعات البيانات لاختبارات القياس المعياري
التسعير: تتوفر باقة مجانية. تتوفر باقات للفرق والمؤسسات بأسعار تعتمد على الاستخدام - راجع الموقع الرسمي للاطلاع على الأسعار الحالية.
الأفضل لـ: فرق التعلم الآلي التي تجري تجارب تحسين سريعة واسعة النطاق والتي تحتاج إلى إمكانيات تقييم غير متصلة بالإنترنت.
| منصة | تتبع التكاليف | مقاييس الجودة | الوعي بالجلسة | السعر المبدئي
|
|---|---|---|---|---|
| الذكاء الاصطناعي الواثق | نعم | أكثر من 20 تقييمًا مدمجًا | أساسي | الاستخدام |
| لانغفوس | نعم | مقيّمون متخصصون | متقدم | مجاني / $249/شهريًا |
| هيليكون | نعم | محدود | لا | مجاني / $79/شهريًا |
| Datadog LLM | نعم | المقاييس المخصصة | أساسي | أسعار المؤسسات |
| نسيج دبليو آند بي | نعم | يركز على التجربة | إعادة التشغيل دون اتصال بالإنترنت | مستوى مجاني متاح |

قم ببناء أنظمة إدارة التعلم القانوني مع مراقبة واضحة للتكلفة والجودة.
تحتاج تطبيقات إدارة التعلم القائم على البيانات إلى رؤية واضحة لكيفية أداء النماذج في بيئة الإنتاج. يساعد تتبع المطالبات والاستجابات واستخدام الرموز وسلوك النظام الفرق على الحفاظ على الجودة وفهم كيفية استخدام أنظمة الذكاء الاصطناعي الخاصة بهم فعليًا. متفوقة الذكاء الاصطناعي تُطوّر الشركة منصات ذكاء اصطناعي تدمج نماذج اللغة مع أنظمة الواجهة الخلفية، وخطوط نقل البيانات، وأدوات التحليل. ويقوم مهندسوها ببناء برمجيات ذكاء اصطناعي تدعم التسجيل والتقييم والمراقبة، مما يُمكّن من إدارة تطبيقات إدارة اللغة الإنجليزية بكفاءة عالية في بيئة الإنتاج.
هل تقوم بنشر تطبيق إدارة التعلم القانوني في بيئة الإنتاج؟
تحدث مع الذكاء الاصطناعي المتفوق على:
- تطوير تطبيقات قائمة على لغة البرمجة اللغوية العصبية وأدوات معالجة اللغة الطبيعية
- دمج عمليات المراقبة والتحليل
- نشر أنظمة الذكاء الاصطناعي ضمن منصات البرمجيات الحالية
👉 تواصل معنا متفوقة الذكاء الاصطناعي لمناقشة مشروع تطوير الذكاء الاصطناعي الخاص بك.
اختيار النموذج المناسب للتحليلات الفعالة من حيث التكلفة
يُعد اختيار المنصة أمراً بالغ الأهمية، لكن اختيار النموذج هو ما يحدد التكلفة الفعلية وجودة النتائج. وتُظهر المقارنات المعيارية الحديثة اختلافات كبيرة في مدى كفاءة النماذج في التعامل مع أعباء العمل التحليلية.
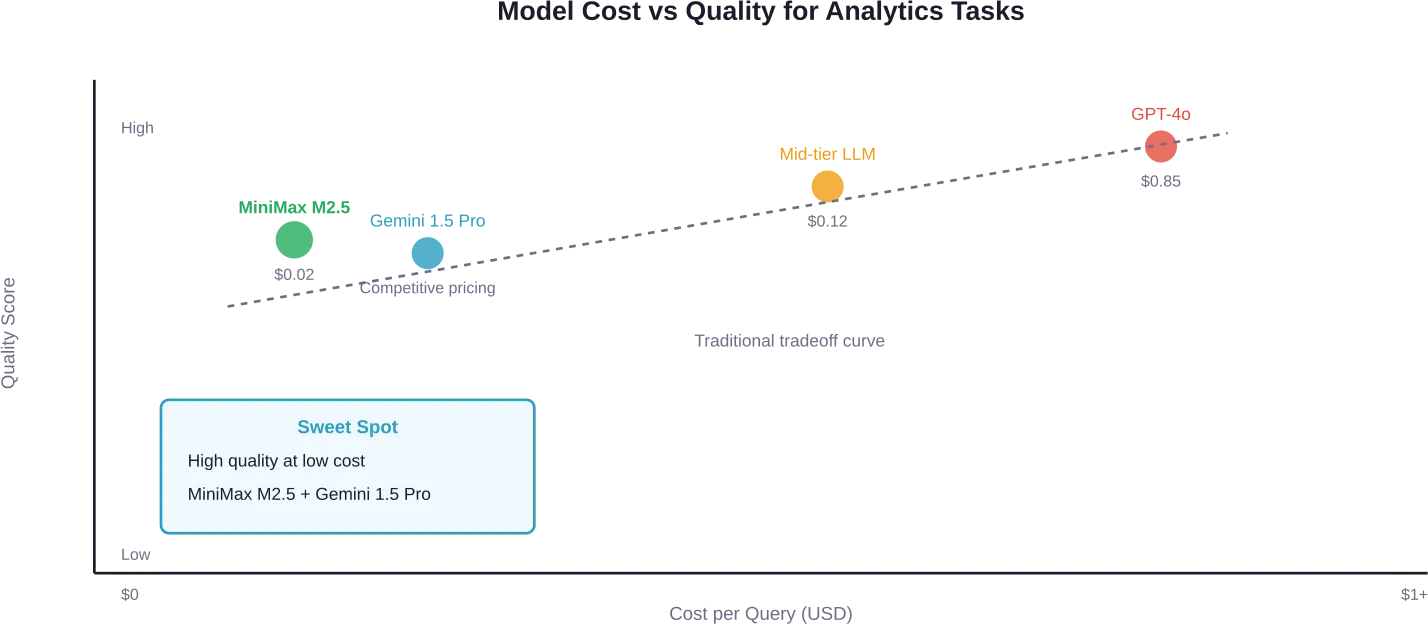
وفقًا للاختبارات التي أجريت على بيانات Google Analytics الحقيقية، قدم MiniMax M2.5 جودة ممتازة عبر عمليات اختبار متعددة، وبلغت تكلفته $0.02 لكل استعلام، وحقق متوسط وقت إكمال يبلغ 70 ثانية.
قام المعيار بتقييم النماذج على عدة أبعاد:
- تقييم الجودة: هل قدم النموذج رؤى قابلة للتنفيذ تتجاوز البيانات الخام؟
- درجة الدقة: ما مدى دقة استخدامها لأبعاد ومقاييس GA4 الحقيقية؟
- تكلفة الاستعلام الواحد: التكلفة الإجمالية للمواد الصيدلانية الفعالة لإنجاز المهمة التحليلية
- كمون: المدة الزمنية من تقديم الطلب الفوري إلى الإنجاز
أظهر برنامج Gemini 1.5 Pro أداءً متميزًا في التحليلات الاستراتيجية التي تتطلب تفكيرًا معمقًا. فقد رصد على الفور خللًا في تتبع الإسناد في بيانات الاختبار، وانتقل مباشرةً إلى تحليل التحويلات القابل للتنفيذ. وبهذه الأسعار، يمكن للفرق تشغيل مئات الاستعلامات يوميًا بأقل تكلفة.
تؤكد الأبحاث المتعلقة باختيار نماذج التعلم الآلي للمهام المعقدة متعددة المراحل هذه النتائج. وقد أظهر إطار عمل MixLLM أنه بالمقارنة مع استخدام نموذج تعلم آلي تجاري قوي واحد، فإن اختيار النموذج التكيفي يحسن جودة النتائج بنسبة 1-16% مع تقليل تكلفة الاستدلال بنسبة 18-92%.
إطار المفاضلة بين التكلفة والجودة
تكشف الأبحاث التي تتناول تجاوز المفاضلات بين التكلفة والجودة في خدمة الوكلاء أن البنى التي تراعي الجلسات قادرة على كسر منحنى المفاضلة التقليدي. يحقق نظام AgServe جودة استجابة مماثلة لـ GPT-40 بتكلفة أقل بنسبة 16.5% من خلال ابتكارين:
- إدارة ذاكرة التخزين المؤقت للمفتاح والقيمة مع مراعاة الجلسة: يستخدم هذا الإطار تقنية الإخلاء القائمة على وقت الوصول المُقدَّر ومعايرة التضمين الموضعي لتعزيز معدلات إعادة استخدام ذاكرة التخزين المؤقت بشكل كبير. وهذا يقلل من العمليات الحسابية الزائدة عبر الجلسات متعددة المراحل.
- التتابع النموذجي الواعي بالجودة: بدلاً من الالتزام بنموذج واحد طوال الجلسة، تُجري AgServe تقييمًا فوريًا للجودة وتُحدّث النماذج أثناء الجلسة عند الحاجة. وهذا يسمح بالبدء بنماذج أقل تكلفة والترقية فقط عندما تتطلب الجودة ذلك.
يُظهر البحث تحسناً بمقدار 1.8 مرة في الجودة مقارنة بمنحنى المفاضلة التقليدي بين التكلفة والجودة، مما يثبت فعلياً أن خيارات الهندسة المعمارية المناسبة يمكن أن تحقق نتائج أفضل بتكاليف أقل في الوقت نفسه.
المؤشرات الرئيسية التي يجب تتبعها
يتطلب التحليل الفعال لإدارة دورة حياة المنتج تتبع المقاييس الصحيحة. تركز العديد من الفرق بشكل حصري على التكلفة أو زمن الاستجابة متجاهلةً مؤشرات الجودة التي تتنبأ برضا المستخدم.
مقاييس التكلفة
- استهلاك الرموز لكل طلب: قم بقياس كل من رموز الإدخال والإخراج بشكل منفصل. تختلف استراتيجيات التحسين؛ فتقليل رموز الإدخال يتطلب هندسة سريعة، بينما يتطلب التحكم في رموز الإخراج تحسين معايير أخذ العينات أو قيود التنسيق.
- تكلفة تفاعل المستخدم الواحد: يتم حساب إجمالي تكاليف الرموز المميزة لجميع استدعاءات واجهة برمجة التطبيقات اللازمة لإنجاز مهمة واحدة للمستخدم. قد يؤدي سؤال واحد من المستخدم إلى استدعاءات متعددة للنموذج (الاسترجاع، والاستدلال، والتنسيق)، وتكون التكلفة الإجمالية أهم من تكاليف الاستدعاءات الفردية.
- التكلفة حسب الميزة أو نقطة النهاية: يُمكّن تحديد المصدر من تحليل عائد الاستثمار. ما هي الميزات التي تُولّد قيمة تُبرّر تكاليفها في إدارة دورة حياة المنتج؟ وما هي الميزات التي تُهدر الرموز دون فائدة مُتناسبة للمستخدم؟
تؤكد وثائق Anthropic حول إدارة التكاليف على تتبع أنماط الاستخدام باستخدام الأمر /stats، والذي يوفر رؤية على مستوى الجلسة لاستخدام الرموز المميزة، ومدة واجهة برمجة التطبيقات، والوقت الفعلي، وتغييرات التعليمات البرمجية.
مقاييس الجودة
- معدل الهلوسة: نسبة عمليات الإكمال التي تحتوي على معلومات ملفقة لا يدعمها السياق المقدم. يتطلب ذلك التحقق الآلي من الحقائق بالرجوع إلى المستندات المصدرية أو قواعد المعرفة.
- درجة الصلة: ما مدى جودة استجابة خاصية الإكمال لاستفسار المستخدم الفعلي؟ يوفر التشابه الدلالي بين السؤال والإجابة مقياسًا تقريبيًا.
- الامتثال للتنسيق: بالنسبة للمخرجات المنظمة (JSON، CSV، SQL)، ما هي نسبة عمليات الإكمال التي تتم بنجاح دون أخطاء؟
- انتهاكات السلامة: تكرار المخرجات التي تحتوي على معلومات شخصية حساسة، أو محتوى مسيء، أو ردود على محاولات حقن الرسائل.
أظهرت الأبحاث التي تناولت تقييم جودة تسلسل الأفكار في توليد الشفرة أن العوامل الخارجية مسؤولة عن 53.60% (وخاصةً عدم وضوح المتطلبات ونقص السياق)، بينما مسؤولة العوامل الداخلية عن 40.10% (وخاصةً التناقضات بين الاستدلال والإرشادات). وهذا يشير إلى أهمية مراقبة جودة المدخلات وأنماط استدلال النموذج للحفاظ على معايير المخرجات.
مقاييس الأداء
- الوقت اللازم للوصول إلى أول رمز مميز (TTFT): زمن الاستجابة قبل أن يبدأ النموذج في بث المخرجات. أمر بالغ الأهمية لسرعة الاستجابة الملحوظة في واجهات الدردشة.
- عدد الرموز المميزة في الثانية: سرعة التحميل بمجرد بدء البث. السرعات البطيئة تُحبط المستخدمين الذين ينتظرون اكتمال التحميل لفترات طويلة.
- زمن الاستجابة من البداية إلى النهاية: إجمالي الوقت من طلب المستخدم إلى الاستجابة الكاملة، بما في ذلك الاسترجاع والمعالجة المسبقة واستنتاج النموذج والمعالجة اللاحقة.
| الفئة المترية | المؤشرات الرئيسية | لماذا يهم ذلك
|
|---|---|---|
| يكلف | استخدام الرموز، تكلفة كل تفاعل، التكلفة حسب الميزة | يتحكم في الإنفاق ويتيح تحليل العائد على الاستثمار |
| جودة | معدل الهلوسة، درجة الصلة، مدى الالتزام بالتنسيق | يضمن دقة المخرجات ورضا المستخدم |
| أداء | زمن الاستجابة من البداية إلى النهاية (TTFT)، عدد الرموز المميزة/ثانية | يحافظ على تجربة مستخدم سريعة الاستجابة |
| أمان | تسريب معلومات التعريف الشخصية، ومحاولات الحقن الفوري، وانتهاكات السياسة | يمنع الحوادث الأمنية ومشاكل الامتثال |
استراتيجيات التنفيذ
إن الحصول على قيمة من تحليلات إدارة التعلم يتطلب أكثر من مجرد تثبيت أداة مراقبة. تحتاج الفرق إلى مناهج منظمة للأجهزة، وتصميم التقييم، والتنبيهات.
ابدأ بالتتبع
قم بتجهيز استدعاءات واجهة برمجة تطبيقات إدارة التعلم (LLM API) لالتقاط بيانات الطلب والاستجابة الكاملة.
كحد أدنى، سجل:
- الطابع الزمني ومعرف الطلب
- اسم النموذج والمعلمات
- أكمل التعليمات (رسالة النظام، إدخال المستخدم، السياق)
- نص الإكمال الكامل
- عدد الرموز (المدخلات، المخرجات، الإجمالي)
- تفاصيل زمن الاستجابة (وقت واجهة برمجة التطبيقات، وقت المعالجة)
- حساب التكلفة
توفر معظم منصات التحليلات حزم تطوير برمجية (SDKs) تتولى هذه المهمة تلقائيًا. ولكن حتى التسجيل المخصص البسيط بتنسيق منظم يُمكّن من إجراء تحليل لاحق.
تحديد معايير الجودة
تؤكد الأبحاث المتعلقة بتبسيط عمليات تقييم أنظمة الذكاء الاصطناعي على ضرورة أن تتناسب استراتيجيات التقييم مع تعقيد النظام. تعمل أدوات التقييم القائمة على الترميز (مثل مطابقة السلاسل النصية، والاختبارات الثنائية، والتحليل الثابت) مع المخرجات المحددة. أما أدوات التقييم القائمة على نماذج التعلم المتوازية فتتعامل مع التقييم الدلالي في الحالات التي تفشل فيها المطابقة التامة.
أنشئ مجموعة بيانات مرجعية تتضمن نماذج تمثيلية ومخرجات متوقعة. شغّل إصدارات جديدة من النموذج أو قوالب النماذج على هذه المجموعة قبل النشر. تتبّع مقاييس الجودة بمرور الوقت لاكتشاف أي تراجع في الأداء.
وفقًا لإرشادات OpenAI بشأن تقييم الوكلاء باستخدام Langfuse، يتضمن التقييم غير المتصل عادةً وجود مجموعة بيانات مرجعية مع أزواج من المطالبات والمخرجات، وتشغيل الوكيل على مجموعة البيانات هذه، ومقارنة المخرجات باستخدام آليات تسجيل إضافية.
إعداد تنبيهات التكلفة
تحدث تجاوزات الميزانية بسرعة مع التسعير القائم على الرموز.
قم بضبط التنبيهات لـ:
- تجاوزت التكلفة اليومية خط الأساس بمقدار 25%+
- الطلبات الفردية تستهلك 10 أضعاف الرموز العادية
- مستخدمون أو ميزات محددة تتسبب في تكاليف غير متناسبة
- تغييرات غير متوقعة في إصدارات الطرازات تزيد من الإنفاق
ينبغي أن تُحفّز التنبيهات على إجراء تحقيق، لا على الذعر. غالبًا ما تشير الزيادات المفاجئة في التكاليف إلى نجاح المنتج (زيادة الاستخدام) وليس إلى وجود مشاكل. لكن الشفافية تُمكّن من التمييز بين النمو وعدم الكفاءة.
تطبيق حلقات التغذية الراجعة
لا تُغطي المقاييس الآلية كل ما يهم المستخدمين. أضف آليات واضحة لتقديم الملاحظات:
- تقييم الإنجازات (بالإبهام لأعلى/لأسفل)
- الإبلاغ المفصل عن المشكلات المتعلقة بضعف المخرجات
- استطلاعات رضا العملاء على مستوى الجلسة
اربط تعليقات المستخدمين بتقييمات الجودة الآلية. إذا كان البشر يقيمون باستمرار عمليات الإكمال ذات الدرجات العالية بشكل سيئ، فإن المقاييس الآلية تحتاج إلى إعادة معايرة.
تقنيات التحسين المتقدمة
بمجرد أن يصبح نظام المراقبة الأساسي جاهزاً للعمل، يمكن للعديد من التقنيات المتقدمة أن تحسن بشكل كبير نسب التكلفة إلى الجودة.
نموذج التتالي الواعي بالجلسة
أظهرت الأبحاث المتعلقة بخدمة العملاء عبر الوكلاء أن اختيار النموذج المناسب للجلسة يُحقق تحسينات ملحوظة. فبدلاً من الالتزام بنموذج واحد طوال المحادثة، يبدأ النظام بنموذج أقل تكلفة ويُحدّثه أثناء الجلسة عندما تتطلب الجودة ذلك.
يحقق إطار عمل AgServe جودة مكافئة لـ GPT-4o بتكلفة 16.5% من خلال اختيار النماذج وترقيتها ديناميكيًا أثناء فترة الجلسة بناءً على تقييم الجودة في الوقت الفعلي.
يتطلب التنفيذ ما يلي:
- تقييم الجودة بعد كل استجابة نموذجية
- العتبات التي تحدد مستويات الجودة المقبولة
- من المنطقي اللجوء إلى نماذج أكثر كفاءة (وأغلى ثمناً) عند الحاجة
- إدارة ذاكرة التخزين المؤقت للقيم والمفاتيح لإعادة استخدام السياق عبر تبديل الطرازات
تحسين فوري قائم على التحليلات
تكشف التحليلات عن أنماط الرسائل التي ترتبط بمشاكل الجودة أو تجاوزات التكاليف. وتشمل المشاكل الشائعة ما يلي:
- حشو السياق المفرط: إضافة المستندات كاملةً إلى المطالبات في حين أن مقتطفات محددة تكفي. تشير التحليلات التي تُظهر ارتفاع عدد الكلمات المدخلة مع انخفاض درجات الصلة إلى هذه المشكلة.
- تعليمات مبهمة: تؤدي التعليمات العامة مثل "حلل هذه البيانات" إلى مخرجات متفرقة وغير مركزة. وتشير التحليلات التي تُظهر انخفاضًا في الالتزام بالتنسيق أو تباينًا كبيرًا في طول المخرجات إلى وجود مشاكل في وضوح التعليمات.
- القيود المفقودة: يؤدي عدم تحديد طول أو تنسيق الإخراج إلى عمليات إكمال طويلة بلا داعٍ. وتكشف تحليلات استخدام الرموز هذا الأمر بسرعة.
استراتيجيات التخزين المؤقت
تُعالج العديد من تطبيقات إدارة التعلم الآلي سياقات متشابهة بشكل متكرر. وتُمكّن التحليلات التي تحدد بادئات المطالبات عالية التردد من وضع استراتيجيات تخزين مؤقت مُستهدفة.
يخزن التخزين المؤقت الدلالي تضمينات الأسئلة الأخيرة. عندما يكون سؤال جديد مشابهًا دلاليًا لسؤال مخزن مؤقتًا، يتم إرجاع الإجابة المخزنة بدلًا من استدعاء واجهة برمجة التطبيقات. يُعد هذا مناسبًا لتطبيقات الأسئلة الشائعة حيث يطرح العديد من المستخدمين أسئلة متطابقة.
يُعيد تخزين بادئة المطالبات استخدام معالجة رسائل النظام وسياقها المشترك. فإذا كانت 80% من المطالبات تشترك في نفس البادئة المكونة من 2000 رمز، فإن تخزين هذه العملية يوفر تكاليف كبيرة.
الأخطاء الشائعة وكيفية تجنبها
حتى الفرق التي تمتلك بنية تحتية للمراقبة ترتكب أخطاء متوقعة تقوض فعالية التحليلات.
تتبع مقاييس التباهي
لا تُعدّ مقاييس مثل إجمالي استدعاءات واجهة برمجة التطبيقات أو إجمالي عدد الرموز المميزة عواملَ أساسية في اتخاذ القرارات، بل ترتفع هذه المقاييس مع نجاح المنتج. لذا، يُنصح بتتبع المقاييس التي تُشير إلى وجود مشاكل، مثل: تكلفة القيمة المُقدّمة، ومعدلات تدهور الجودة، وحالات التأخير الشاذة.
تجاهل الدلالة الإحصائية
تتسم مخرجات برنامج ماجستير القانون بالعشوائية. ولا يشير فشل مهمة واحدة إلى وجود مشاكل هيكلية. لكن الفرق غالباً ما تبالغ في رد فعلها تجاه حالات الفشل الفردية بدلاً من تحليل الاتجاهات.
يتطلب الأمر أحجام عينات كافية قبل استنتاج وجود انحدار ذي جودة. وتركز الأبحاث المتعلقة باختيار نماذج الانحدار الخطي متعددة المراحل على تصميم أنظمة تتحمل تقلبات الأداء الناتجة عن عشوائية هذه النماذج.
التحسين من أجل التكلفة فقط
لا جدوى من خفض التكاليف بمقدار 50% إذا انخفضت الجودة لدرجة تؤثر سلبًا على تجربة المستخدم. الهدف هو تحقيق التوازن الأمثل بين التكلفة والجودة، وليس خفض التكلفة إلى أدنى حد.
ينبغي أن تتتبع التحليلات كلا البُعدين في آنٍ واحد. تُظهر الأبحاث المتعلقة بالخدمة الواعية بالجلسات أن البنية المناسبة يمكن أن تُحسّن الجودة. بينما خفض التكاليف، وتجاوز المقايضة التقليدية.
لا يتم اختباره في بيئة الإنتاج
يُعدّ التقييم غير المتصل بالإنترنت باستخدام مجموعات بيانات مرجعية أمرًا بالغ الأهمية، لكن سلوك الإنتاج يختلف. يصوغ المستخدمون الاستعلامات بشكل مختلف عما يتوقعه مصممو الاختبارات. ولا تظهر الحالات الشاذة في العالم الحقيقي في مجموعات البيانات المُنسقة.
قم بتشغيل نظام مراقبة الإنتاج بشكل مستمر واستخدمه لتحسين معايير الأداء غير المتصلة بالإنترنت. يجب أن يتطور معيار الأداء ليعكس أنماط الاستخدام الفعلية.
الأسئلة الشائعة
ما الفرق بين مراقبة LLM وقابلية ملاحظة LLM؟
تراقب أنظمة المراقبة المقاييس المحددة مسبقًا وتُرسل تنبيهات عند تجاوزها الحدود المسموح بها. وتتيح إمكانية المراقبة استكشاف سلوك النظام من خلال استعلامات مُخصصة على بيانات التتبع التفصيلية. وتجمع معظم المنصات الحديثة بين كلا النهجين: مقاييس مُهيكلة للوحات المعلومات والتنبيهات، وبيانات تتبع تفصيلية لتصحيح أخطاء مُحددة.
كم تبلغ تكلفة تحليلات برنامج ماجستير القانون عادةً؟
تختلف نماذج التسعير اختلافًا كبيرًا. فالمنصات القائمة على الاستخدام تفرض رسومًا بناءً على حجم البيانات المُتتبعة. أما منصات الاشتراك مثل Langfuse Pro فتُكلّف $249 شهريًا مقابل عدد غير محدود من البيانات المُتتبعة. بينما تُدمج حزم البرامج المؤسسية مثل Datadog مراقبة إدارة دورة حياة البيانات (LLM) في العقود القائمة.
هل يمكن لأدوات التحليل أن تقلل من تكاليف دراسة الماجستير في القانون؟
لا تُساهم التحليلات بشكل مباشر في خفض التكاليف، ولكنها تُتيح اتخاذ قرارات تحسينية تُؤدي إلى ذلك. تُشير الأبحاث المتعلقة بخدمة الجلسات إلى إمكانية تحقيق تخفيضات في التكاليف تتجاوز 80% من خلال تحسينات في البنية التحتية.
ما هي معايير الجودة الأكثر أهمية لتطبيقات إدارة التعلم في مجال الإنتاج؟
يُعدّ معدل الهلوسة ودرجة الصلة بالموضوع عاملين حاسمين لضمان دقة المعلومات. كما أن الالتزام بالتنسيق مهمٌّ للمخرجات المنظمة. وتساهم مقاييس الأمان (مثل تسريب المعلومات الشخصية الحساسة، ومقاومة الحقن الفوري) في منع الحوادث الأمنية. وتختلف المقاييس المحددة باختلاف حالة الاستخدام؛ إذ تُعطي تطبيقات دعم العملاء أولويةً لأبعاد جودة مختلفة عن تلك التي تُعطيها أدوات توليد التعليمات البرمجية.
هل ينبغي عليّ استخدام أدوات تحليلية مفتوحة المصدر أم تجارية خاصة ببرامج الماجستير في القانون؟
توفر أدوات المصادر المفتوحة مثل Langfuse مرونة في النشر وعدم التقيد بمورد واحد، لكنها تتطلب إدارة البنية التحتية. أما المنصات التجارية فتُقدم استضافة مُدارة، وتطويرًا أسرع للميزات، ودعمًا مُخصصًا. غالبًا ما تُفضل الفرق التي تمتلك بنية تحتية قوية المصادر المفتوحة. بينما تُفضل الفرق التي تُركز على تطوير التطبيقات بدلًا من العمليات الحلول المُدارة.
كيف يمكنني قياس عائد الاستثمار في تحليلات برامج الماجستير في القانون؟
تتبّع ثلاثة أبعاد: توفير التكاليف من خلال التحسين (تقليل استهلاك الرموز المميزة)، وتحسين الجودة (تقييمات أفضل من المستخدمين، وتقليل طلبات الدعم)، وسرعة التطوير (تصحيح أسرع للأخطاء، ونشر أكثر أمانًا). تحقق معظم الفرق عائدًا إيجابيًا على الاستثمار في غضون شهرين إلى ثلاثة أشهر من خلال تحسين التكاليف فقط، قبل احتساب فوائد الجودة والسرعة.
ما هو الحد الأدنى من إعدادات التحليلات اللازمة لتطبيق ماجستير القانون الجديد؟
ابدأ بتتبع أساسي يسجل كل طلب، وإتمام، وعدد الرموز، والتكلفة. أضف مقياس جودة بسيطًا ذا صلة بالمجال (مثل توافق التنسيق للمخرجات المنظمة، وتقييم مدى الصلة لتطبيقات الدردشة). فعّل تنبيهات التكلفة في حال تجاوز الميزانية. يستغرق هذا الإعداد البسيط من يوم إلى يومين لتنفيذه، ويمنع معظم مشاكل الإنتاج الشائعة.
خاتمة
تطورت تحليلات إدارة دورة حياة المنتج من كونها ميزة إضافية إلى ضرورة إنتاجية. فبدون رؤية واضحة لتكاليف الرموز، ومقاييس الجودة، وخصائص الأداء، تعمل الفرق بشكل أعمى.
توفر بيئة المنصات خيارات قوية تلبي مختلف الاحتياجات. يقود الذكاء الاصطناعي الموثوق به مراقبة الجودة التي تركز على التقييم. يوفر Langfuse مرونة المصادر المفتوحة مع تتبع قوي للجلسات. يوفر Helicone رؤية سريعة للتكاليف من خلال النشر القائم على الوكيل. يوسع Datadog نطاق مراقبة المؤسسة ليشمل أحمال عمل إدارة دورة حياة التعلم.
لكن الأدوات وحدها لا تضمن النجاح. فالتحليلات الفعالة تتطلب تتبع المقاييس الصحيحة، وبناء معايير الجودة، وتنفيذ حلقات التغذية الراجعة، واستخدام الرؤى لتوجيه قرارات التحسين.
تُظهر الأبحاث أن البنى المُدركة للجلسات قادرة على تجاوز المفاضلات التقليدية بين التكلفة والجودة. يحقق نظام AgServe جودةً تُضاهي GPT-40 بتكلفة أقل بنسبة 16.5% من خلال إدارة ذكية لذاكرة التخزين المؤقت للقيم والمفاتيح واختيار النماذج الديناميكي. تنجح هذه التقنيات لأنها تُطابق بنية النظام مع الخصائص الفريدة لأحمال عمل LLM.
تتشارك الفرق التي تحقق أفضل النتائج ممارسات مشتركة. فهي تستخدم أدوات تحليل شاملة منذ البداية، وتحدد معايير الجودة مبكراً، وتتابع أي تراجع في الأداء باستمرار، وتعتمد في تحسينها على البيانات بدلاً من الحدس، وتتعامل مع التحليلات كنظام تغذية راجعة يتحسن بمرور الوقت، وليس مجرد تطبيق لمرة واحدة.
ابدأ بتطبيق نظام تتبع أساسي وتتبع التكاليف. أضف مقاييس جودة مناسبة لحالة الاستخدام. فعّل التنبيهات لاكتشاف المشكلات قبل أن تؤثر على المستخدمين. ثم استخدم هذه الرؤية الناتجة لتحسينات متكررة في المطالبات، واختيار النموذج، وبنية النظام.
غالباً ما يكمن الفرق بين الفرق الناجحة في تطبيقات إدارة دورة حياة المنتج (LLM) وتلك التي تواجه صعوبات في التحليلات. فالقياس يُحفز التحسين، والتحسين يُحقق اقتصاديات مستدامة، والاقتصادات المستدامة تُمكّن من بناء منتجات ذكاء اصطناعي مفيدة حقاً.