ملخص سريع: يرتكز تطوير الذكاء الاصطناعي في عام 2026 على الأنظمة الوكيلة، ونماذج اللغة واسعة النطاق التي تصل إلى 1.6 تريليون مُعامل، والتطبيق العملي في المؤسسات. تشمل الاتجاهات الرئيسية أنظمة الذكاء الاصطناعي الوكيلة ذات معايير الأداء القوية في مهام البرمجة والاستدلال، ومحولات الانتشار التي تدعم أدوات الإبداع من الجيل التالي، والأطر الحكومية التي تُعيد تشكيل معايير الأمن السيبراني. يُمثل هذا العام تحولًا من الذكاء الاصطناعي التجريبي إلى أنظمة جاهزة للاستخدام في مجالات الرعاية الصحية والبرمجة وسير العمل التجاري.
شهد مجال الذكاء الاصطناعي تحولات جذرية منذ أواخر عام 2025. فبعد أن كانت التجارب هي السائدة، أصبحت الأنظمة الجاهزة للاستخدام تُشغّل الآن عمليات بالغة الأهمية. وتعمل نماذج ذات تريليونات المعاملات على أجهزة استهلاكية. كما تقوم الأنظمة المستقلة بجدولة الاجتماعات وتحليل البيانات وإدارة البنية التحتية دون تدخل بشري.
لكن ما الذي يُحدث التغيير فعلاً؟ بعيداً عن ضجة الترويج وإطلاق المنتجات، تُعيد اختراقات تقنية محددة تشكيل كيفية تفاعل الشركات والمطورين مع الذكاء الاصطناعي. إن التوجهات الناشئة في عام 2026 ليست نظرية، بل مدعومة بتحسنات ملموسة في الأداء، وتغيرات في السياسات الحكومية، وبيانات اعتماد المؤسسات.
يتناول هذا التحليل المعمق ثمانية من أهم تطورات الذكاء الاصطناعي التي ستُحدد ملامح عام 2026، بدءًا من الابتكارات المعمارية في نماذج الانتشار وصولًا إلى بيانات المسح العالمي الذي أجراه معهد مهندسي الكهرباء والإلكترونيات (IEEE) حول تبني الذكاء الاصطناعي. وبصراحة، بعض التوقعات التي صدرت عام 2024 لم تكن دقيقة على الإطلاق، بينما تجاوزت توقعات أخرى حتى أكثرها تفاؤلًا.
الذكاء الاصطناعي القائم على الوكلاء يحقق انتشاراً واسعاً في السوق
كشف استطلاع IEEE العالمي الذي نُشر في يناير 2026 عن أمرٍ لافت: يتوقع 521% من التقنيين أن تصل تقنيات الذكاء الاصطناعي للمساعدين الشخصيين وجدولة المواعيد إلى انتشار واسع بحلول نهاية العام. لم تعد هذه التقنية هامشية، بل أصبحت جزءًا أساسيًا من البنية التحتية.
يختلف الذكاء الاصطناعي الوكيل اختلافًا جوهريًا عن برامج الدردشة الآلية أو أدوات البحث. فهذه الأنظمة لا تنتظر الأوامر، بل تراقب السياقات، وتتخذ قرارات مستقلة، وتنفذ عمليات متعددة الخطوات. تخيل برنامج جدولة يقرأ بريدك الإلكتروني، ويتحقق من تقاويم المشاركين، ويتفاوض على مواعيد الاجتماعات، ويحجز قاعات المؤتمرات، ويرسل مواد التحضير - كل ذلك دون أي تدخل يدوي.
ووجد الاستطلاع نفسه أن 91% من المشاركين يتوقعون زيادة استخدام الذكاء الاصطناعي الوكيل لتحليل البيانات في عام 2026. وتعكس هذه القفزة تحولاً أوسع: انتقال الذكاء الاصطناعي من الإجابة على الأسئلة إلى حل المشكلات بشكل استباقي.
ما الذي يدفع هذا التطور؟ تحسين نوافذ السياق، وتعزيز قدرات الاستدلال، وخفض التكاليف. تعالج نماذج مثل DeepSeek-V4-Pro الآن مليون رمز مميز في نافذة سياق واحدة - أي ما يقارب 750 ألف كلمة، وهو ما يكفي لتحليل قواعد بيانات كاملة أو سلاسل رسائل بريد إلكتروني تمتد لعدة أشهر في عملية واحدة.
لكنّ الأمر لا يخلو من أن تبني الشركات لهذه التقنيات يتأخر عن حماس المستهلكين. فالمخاوف الأمنية، ومتطلبات الامتثال، وتعقيد التكامل، كلها عوامل تُبطئ عملية النشر. وتشير تقارير أكسنتشر إلى أن 871% من العملاء سيتجنبون علامة تجارية معينة بعد تجربة سلبية واحدة، مما يزيد من أهمية وكلاء خدمة العملاء المستقلين.
نماذج ذات تريليون معلمات تعيد تعريف المقياس
بلغ حجم النموذج عتبة جديدة في أوائل عام 2026. فقد أُطلق نموذج DeepSeek-V4-Pro بـ 1.6 تريليون مُعامل، مُفعّلاً 49 مليار مُعامل لكل عملية استدلال. وهذا أكبر بعشرة أضعاف من نماذج عام 2023 الرائدة، ومع ذلك انخفضت تكاليف الاستدلال بشكل كبير بفضل بنية مزيج الخبراء (MoE).
ما هو الإنجاز التقني؟ آليات الانتباه الهجينة. يجمع DeepSeek-V4 بين الانتباه الكثيف للرموز المهمة والانتباه المتفرق للسياق، مما يقلل من العبء الحسابي مع الحفاظ على الأداء. في معايير MMLU، حقق DeepSeek-V4-Pro-Base نتيجة 90.1% في تقييم من 5 أمثلة، وهو مستوى قريب من مستوى الخبراء البشريين في مهام المعرفة على مستوى الدراسات العليا.
| نموذج | إجمالي المعايير | المعلمات المُفعّلة | سياق الزمن | الابتكار الرئيسي |
|---|---|---|---|---|
| ديب سيك-في4-برو | 1.6 تيرابايت | 49ب | مليون رمز | الانتباه الهجين |
| ديب سيك-الإصدار 4-فلاش | 284ب | 13ب | مليون رمز | الدقة المختلطة FP4/FP8 |
| ميسترال متوسط 3.5 | 128ب | 128B (كثيف) | 256 ألف رمز | التعليمات/البرمجة الموحدة |
| Qwen3.6-27B | 27ب | 27ب (كثيف) | 128 ألف رمز | التركيز على الفائدة العملية في العالم الحقيقي |
لكن الأمر يصبح أكثر إثارة للاهتمام هنا. فالنماذج الأصغر حجماً تُقلّص الفجوة. يُقدّم جهاز Qwen3.6-27B من شركة علي بابا أداءً تنافسياً في مهام البرمجة والاستدلال، على الرغم من صغر حجمه بمقدار 60 ضعفاً. وقد أولى الفريق الأولوية لـ "الاستقرار والفائدة العملية" على حساب عدد المعاملات، وهذا واضح جلياً، حيث أفاد المطورون بانخفاض حالات عدم الاتساق في النتائج وزيادة اتساقها.
حقق نموذج Mistral Medium 3.5، وهو نموذج كثيف ذو 128 مليار مُعامل، أداءً بلغ 91.4% على منصة τ³-Telecom و77.6% على منصة SWE-Bench Verified. ويُعدّ الرقم الثاني بالغ الأهمية، إذ تختبر منصة SWE-Bench مهام هندسة البرمجيات الواقعية، مثل إصلاح مشكلات GitHub من خلال أوصاف مكتوبة بلغة طبيعية. ويشير الأداء الذي يتجاوز 75% إلى قدرة هذه النماذج على إدارة عمليات برمجة الإنتاج بشكل مستقل.
محولات الانتشار تُحوّل الذكاء الاصطناعي الإبداعي
لقد تطورت تقنية تحويل النصوص إلى صور لتتجاوز مجرد تحويل النصوص إلى صور. تجمع أحدث محولات الانتشار بين التحكم في التخطيط، وتناسق الأنماط، والتكييف متعدد الوسائط في بنى موحدة.
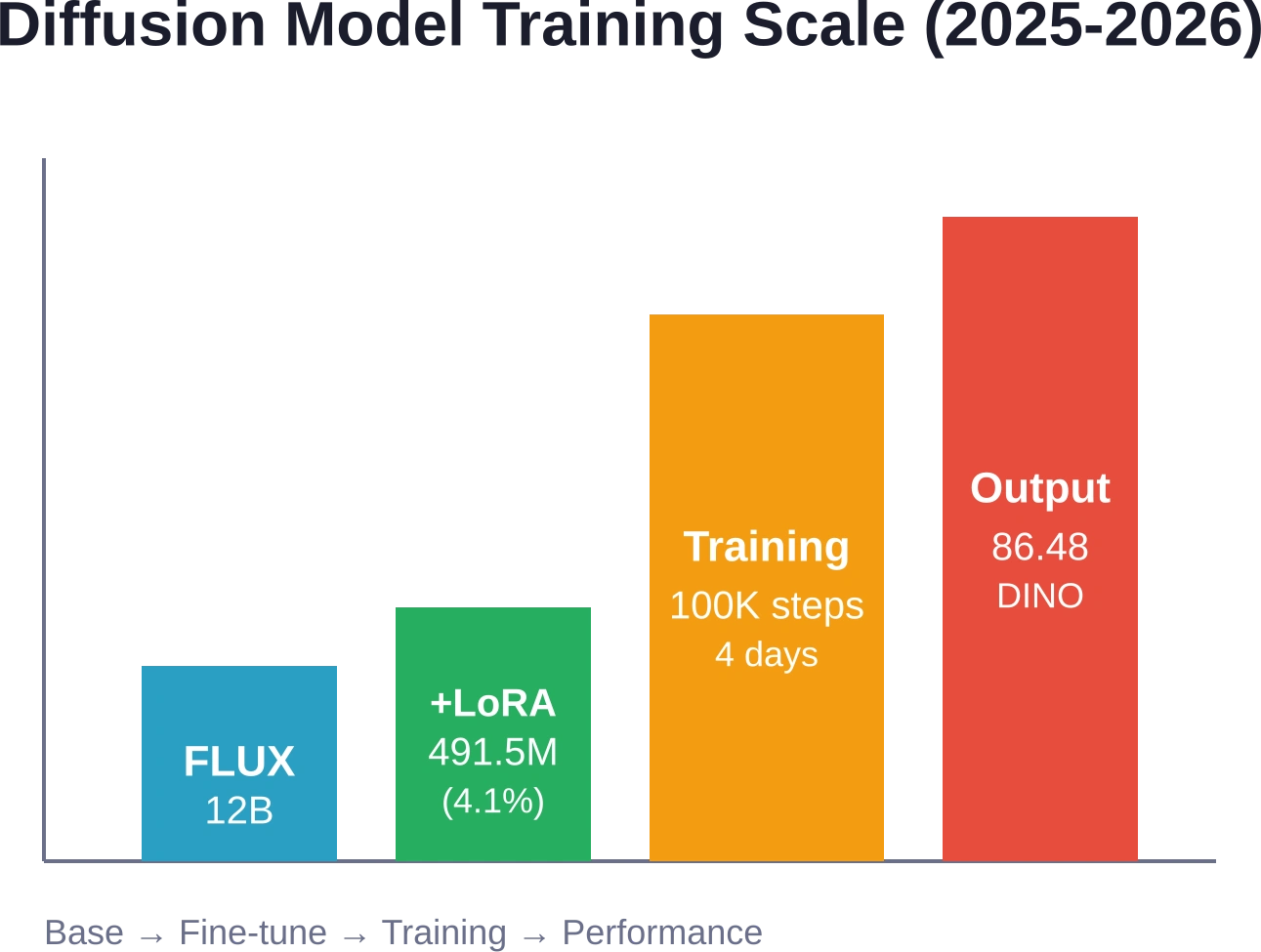
قام مشروع CreatiDesign، وهو مشروع بحثي مشترك بين ByteDance وجامعة فودان، بتحسين نموذج FLUX.1-dev (نموذج أساسي يحتوي على 12 مليار مُعامل) باستخدام LoRA برتبة 256. وقد أدى ذلك إلى إضافة 491.5 مليون مُعامل فقط - أي ما يعادل 4.1% من الحمل الزائد - ولكنه مكّن من التحكم الدقيق في تصميمات الرسومات. يقبل النظام في آنٍ واحدٍ مُطالبات نصية، وتصميمات مكانية، ومراجع أنماط، وقيود اتساق الموضوع.
استغرق التدريب أربعة أيام على ثمانية وحدات معالجة رسومية من طراز H20-96G، حيث تم تنفيذ 100,000 خطوة بمعدل تعلم ثابت قدره 1e-4. ماذا كانت النتائج؟ 86.48 نقطة في مقياس DINO للحفاظ على المحتوى، و78.30 نقطة لدقة دلالات العناصر النصية. بمعنى آخر: تحافظ التصاميم المُولّدة على التناسق البصري عبر مختلف المتغيرات، وتُعرض تخطيطات النصوص المعقدة بدقة - وهما مجالان واجهت فيهما النماذج السابقة صعوبة.
تُمثل مُشفِّرات التمثيل التلقائي (RAEs) نقلة نوعية أخرى في بنية النماذج. تستخدم نماذج الانتشار التقليدية مُشفِّرات VAE من عام 2021، وهي بنى أساسية قديمة تُؤثر سلبًا على الكفاءة. تُدرِّب مُشفِّرات RAEs مُحوِّلات الرؤية خصيصًا للمساحة الكامنة، مُنتجةً 256 رمزًا لصور بحجم 224×224 مع إعادة بناء أفضل. تُظهر نماذج ImageNet خطأ إعادة بناء يبلغ 0.288، وهو أقل بكثير من مُشفِّر FLUX القديم.
تُعدّ بيانات التدريب مهمة أيضاً. فقد أدّى توسيع نطاق البيانات من 1.28 مليون صورة من ImageNet إلى 73 مليون عينة من الويب والبيانات الاصطناعية والنصوص إلى تحسين نتائج GenEval من المستوى الأساسي إلى 76.8 على DPG-Bench. وتُنتج بيانات التدريب الأكثر تنوعاً نماذجَ تُعمّم بشكل أفضل على الحالات الاستثنائية والمطالبات غير المألوفة.
الأطر الحكومية تعيد تشكيل الأمن السيبراني للذكاء الاصطناعي
أرست التحركات السياسية في أواخر عام 2025 وأوائل عام 2026 معايير جديدة لأمن الذكاء الاصطناعي وحوكمته. وقد أصدر المعهد الوطني للمعايير والتكنولوجيا (NIST) مسودة توجيهات في ديسمبر 2025 بعنوان "إعادة التفكير في الأمن السيبراني لعصر الذكاء الاصطناعي".“
تتناول هذه الإرشادات توتراً جوهرياً: فبينما تُؤتمت أنظمة الذكاء الاصطناعي عمليات مراقبة الأمن والاستجابة للتهديدات، فإنها تُضيف أيضاً ثغرات أمنية جديدة. لم تكن المدخلات المُضللة، واستخلاص النماذج، وبيانات التدريب المُلوثة من بين المخاوف في أُطر الأمن السيبراني السابقة للذكاء الاصطناعي. أما نهج المعهد الوطني للمعايير والتكنولوجيا (NIST) المُحدّث فيُعامل نماذج الذكاء الاصطناعي كأصول بنية تحتية حيوية تتطلب حماية مُخصصة.
في الوقت نفسه، أصدر الرئيس ترامب في ديسمبر 2025 أمرًا تنفيذيًا بعنوان "ضمان إطار سياسة وطنية للذكاء الاصطناعي"، وجّه فيه المدعي العام إلى إنشاء فرقة عمل معنية بالتقاضي في قضايا الذكاء الاصطناعي. ما الهدف؟ الطعن في لوائح الذكاء الاصطناعي على مستوى الولايات التي تُعتبر غير دستورية أو متجاوزة بموجب السلطة الفيدرالية. وهذا يخلق بيئة امتثال موحدة، وهو أمر مثير للجدل بين الجهات التنظيمية في الولايات، ولكنه موضع ترحيب من قبل الشركات متعددة الولايات التي تواجه متطلبات متباينة.
ينص أمر منفصل صدر في يوليو 2025 بعنوان "منع الذكاء الاصطناعي المتأثر بالتوجهات التقدمية في الحكومة الفيدرالية" على ضرورة تجنب أنظمة الذكاء الاصطناعي الفيدرالية للتحيز الأيديولوجي. ويتعين على الوكالات توثيق مصادر بيانات التدريب، ومراجعة مخرجات التدريب للتأكد من حيادها من حيث وجهات النظر، ووضع آليات مراجعة قبل نشرها. ولا يزال الجدل قائماً حول ما إذا كان هذا الإجراء يُحسّن موثوقية الذكاء الاصطناعي أم يُضيف أعباءً جديدة على الامتثال.
تُحدد خطة البيت الأبيض "الفوز في سباق الذكاء الاصطناعي: خطة عمل أمريكا للذكاء الاصطناعي" (الصادرة في يوليو 2025) أكثر من 90 إجراءً سياسيًا فيدراليًا ضمن ثلاثة محاور رئيسية: تسريع تطوير البنية التحتية، وإزالة العوائق التنظيمية، وحماية مصالح الأمن القومي. وتشمل التدابير الملموسة تبسيط إجراءات تراخيص مراكز البيانات، وزيادة تمويل أبحاث الذكاء الاصطناعي، وتقييد تصدير نماذج معينة.
الذكاء الاصطناعي في مجال الرعاية الصحية يضيق الفجوة العالمية
تتوقع منظمة الصحة العالمية نقصاً في عدد العاملين الصحيين يصل إلى 11 مليون عامل بحلول عام 2030، مما سيحرم 4.5 مليار شخص من الخدمات الصحية الأساسية. وتقدم أنظمة التشخيص المدعومة بالذكاء الاصطناعي وأنظمة التطبيب عن بُعد حلاً جزئياً، ليس عن طريق الاستغناء عن الأطباء، بل عن طريق توسيع نطاق خدماتهم.
حقق نظام مايكروسوفت لتشخيص الأمراض بالذكاء الاصطناعي (MAI-DxO) دقة بلغت 85.5% في تشخيص الحالات الطبية المعقدة، مقارنةً بمتوسط 20% للأطباء ذوي الخبرة. هذا لا يعني أن الذكاء الاصطناعي يُشخّص بشكل أفضل من الأطباء، بل يعني أن أنظمة الذكاء الاصطناعي التي تُحلل بيانات المرضى الشاملة، والمراجع الطبية، والصور الشعاعية، قادرة على استخلاص معلومات قد يغفل عنها الأطباء بسبب ضيق الوقت أو كثرة المعلومات.
تساعد أنظمة الذكاء الاصطناعي الأطباء في فرز الحالات ودعم اتخاذ القرارات، حيث يقوم الأطباء بمراجعة التوصيات. ويتحقق تحسن الكفاءة من خلال معالجة الذكاء الاصطناعي لتجميع البيانات، ومراجعة الأدبيات الطبية، وتوليد التشخيص التفريقي - وهي مهام تستغرق ساعات طويلة من وقت الطبيب.
تتوسع نماذج الرعاية الهجينة التي تجمع بين الزيارات الشخصية والرعاية عن بُعد المُراقبة بالذكاء الاصطناعي بوتيرة متسارعة. تقوم الأجهزة القابلة للارتداء ببث البيانات الحيوية إلى أنظمة الذكاء الاصطناعي التي تُشير إلى أي خلل، وتتنبأ بالمضاعفات، وتُوصي بالتدخلات العلاجية. بالنسبة للأمراض المزمنة مثل السكري أو أمراض القلب، تُساعد المراقبة المستمرة على رصد أي تدهور مبكرًا، مما يُقلل من الحاجة إلى التدخلات الطارئة.
بحسب استطلاع IEEE العالمي، تتوقع 41% أن يصل استخدام الذكاء الاصطناعي المساعد لمراقبة الصحة إلى مستوى واسع أو شبه واسع بحلول عام 2026. ويتماشى هذا مع قيام شركات مثل آبل وجوجل وسامسونج بتضمين تقنيات متقدمة لتتبع الصحة في الأجهزة الاستهلاكية. البنية التحتية متوفرة بالفعل، حيث تعمل طبقات الذكاء الاصطناعي على تحويل البيانات إلى إجراءات عملية.
أصبح الذكاء الاصطناعي عنصراً أساسياً في سير العمل البحثي
يُنتج البحث العلمي بيانات أسرع من قدرة البشر على تحليلها. فعلم الجينوم يُنتج تيرابايتات لكل تجربة. وتلتقط أجهزة الكشف في فيزياء الجسيمات مليارات من أحداث التصادم. وتعمل نماذج المناخ لأسابيع، مُنتجةً بيتابايتات من عمليات محاكاة الغلاف الجوي.
تندمج أدوات الذكاء الاصطناعي الآن مباشرةً في مسارات البحث. تلخص نماذج اللغة الأدبيات العلمية، وتقترح تصميمات تجريبية، وتحدد الثغرات في الدراسات الحالية. تحلل نماذج رؤية الحاسوب صور المجهر، وبيانات الأقمار الصناعية، وملاحظات التلسكوبات. يعمل التعلم المعزز على تحسين المعايير التجريبية وتخصيص الموارد.
استضاف موقع arXiv، وهو خادم ما قبل النشر للفيزياء والرياضيات وعلوم الحاسوب، أكثر من 200 ألف بحث في عام 2025. ويعترف جزء متزايد من الباحثين بمساعدة الذكاء الاصطناعي في مراجعة الأدبيات، وتوليد الفرضيات، وتحليل البيانات. لا يستعين الباحثون بمصادر خارجية للتفكير، بل يؤتمتون الجوانب الروتينية للمنهج العلمي.
لكن الذكاء الاصطناعي يطرح تحديات جديدة. فالنماذج المدربة على الأبحاث المنشورة ترث تحيز النشر، ما يُفضّل النتائج الإيجابية على النتائج السلبية. ولا تستطيع هذه النماذج التمييز بين الدراسات القوية وتلك التي تعاني من عيوب منهجية دون تدريب مُحدد. ويتعين على الباحثين التحقق من صحة اقتراحات الذكاء الاصطناعي بالاستناد إلى خبرتهم في المجال، وهي مهارة لا تُدرّس عادةً في برامج الدراسات العليا.
يسلط تقرير المعهد الوطني للمعايير والتكنولوجيا (NIST) الصادر في يونيو 2025 بعنوان "تأثير الذكاء الاصطناعي على القوى العاملة في مجال الأمن السيبراني" الضوء على قلق مماثل: فمع أتمتة الذكاء الاصطناعي للمهام الروتينية، يجب أن تتحول مهارات القوى العاملة نحو الإشراف والتحقق ومعالجة الحالات الاستثنائية. وينطبق النمط نفسه على مختلف التخصصات، فالأتمتة لا تلغي الخبرة، بل ترفع مستوى العمل الذي يُعتبر عملاً خبيراً.
البنية التحتية تصبح أكثر ذكاءً وكفاءة
يتطلب تدريب خوارزمية DeepSeek-V4-Pro مراكز بيانات، وليس وحدات معالجة الرسومات فقط. تمثل البنية التحتية للطاقة والتبريد اللازمة لدعم عمليات التدريب التي تضم تريليونات المعلمات على نطاق واسع، عائقًا لا يقل أهمية عن توفر الحوسبة.
تُركز البنية التحتية للذكاء الاصطناعي في عام 2026 على تحسين الكفاءة بقدر التركيز على السعة الخام. وتُقلل أنظمة التبريد السائل استهلاك الطاقة بنسبة تتراوح بين 30 و401 تيرابايت مقارنةً بالتبريد الهوائي. ويُتيح التوزيع الديناميكي لأعباء العمل نقل التدريب إلى ساعات خارج أوقات الذروة أو إلى المناطق التي تتمتع بفائض في الطاقة المتجددة. كما تُقلل تقنيات ضغط النماذج، مثل التدريب متعدد الدقة (FP4 وFP8)، من متطلبات عرض النطاق الترددي للذاكرة، مما يسمح بمعالجة دفعات أكبر لكل وحدة معالجة رسومية.
يُظهر DeepSeek-V4-Flash هذا التوجه بوضوح: ٢٨٤ مليار مُعامل، منها ١٣ مليار مُعامل فقط مُفعّل لكل رمز، باستخدام دقة مختلطة من FP4 وFP8. هذا يُقلل تكلفة الاستدلال بنحو ٧٥١TP3T مُقارنةً بالنماذج ذات الدقة الكاملة، مما يجعل النماذج ذات الحجم التريليوني مُجدية اقتصاديًا للاستخدام في بيئات الإنتاج.
تُعدّ تقنية الذكاء الاصطناعي على الحافة مجالًا جديدًا واعدًا. إذ يُسهم تشغيل النماذج على الأجهزة في التخلص من مخاطر التأخير والخصوصية الناتجة عن عمليات نقل البيانات إلى السحابة. وتعمل النماذج الكمية التي تحتوي على أقل من 10 مليارات مُعامل الآن على الهواتف الذكية وأجهزة إنترنت الأشياء، مما يُتيح رؤية حاسوبية فورية، ومعالجة صوتية، وتحليلات استشعارية دون الحاجة إلى اتصال بالشبكة.
لا تزال تطبيقات الذكاء الاصطناعي الطرفي في مجال الإنتاج محصورة في مجالات محددة: مراقبة جودة التصنيع، وتتبع مخزون التجزئة، والصيانة التنبؤية للمعدات الصناعية، وتحليلات البيانات الأساسية من أجهزة الاستشعار. لا تحتاج هذه التطبيقات إلى قدرات نماذج متطورة، بل تحتاج إلى موثوقية عالية، وزمن استجابة منخفض، وإمكانية التشغيل دون اتصال بالإنترنت.
يتعلم الذكاء الاصطناعي في البرمجة السياق، وليس فقط بناء الجملة.
كانت نماذج توليد الشفرة البرمجية السابقة تتعامل مع البرمجة على أنها مجرد تنبؤ بالنصوص. فبمجرد تزويدها بتوقيع الدالة وسلسلة التوثيق، كانت تُكمل عملية التنفيذ. لكن هندسة البرمجيات الحقيقية تتطلب فهم بنية النظام، وعقود واجهة برمجة التطبيقات، وقيود الأداء، واتفاقيات الفريق.
يعكس أداء Mistral Medium 3.5 على منصة SWE-Bench Verified (77.6%) قدرةً أفضل على الاستدلال السياقي. يعرض هذا المعيار مشكلات من مستودعات GitHub حقيقية: تقارير الأخطاء، وطلبات الميزات، والحالات الاستثنائية. يجب على النماذج قراءة المشكلة، وتحديد موقع الكود ذي الصلة في ملفات متعددة، وتنفيذ الإصلاح، والتأكد من اجتياز الاختبارات. هذا هو هندسة البرمجيات الشاملة، وليس مجرد توليد أجزاء من الكود.
يُقدّم نموذج Kimi K2.6، وهو نموذج وكلاء متعدد الوسائط مفتوح الوزن، تم إصداره في أبريل 2026، قدرات برمجة متقدمة طويلة المدى. يتعامل النموذج مع "مهام البرمجة المعقدة والشاملة" باستخدام لغات Rust وGo وPython، مع إمكانية تعميمه على مجالات تطوير الواجهات الأمامية، وعمليات التطوير والتشغيل، وتحسين الأداء. وقد حقق النموذج 54.0 نقطة على مقياس HLE-Full (مع الأدوات)، وهو معيار لقياس إنجاز المهام متعددة الخطوات التي تتطلب التخطيط واستخدام الأدوات ومعالجة الأخطاء.
يبرز التصميم القائم على البرمجة كقدرة متميزة. يصف المطورون متطلبات المنتج العامة، بينما يقوم الذكاء الاصطناعي بإنشاء نماذج أولية لواجهة المستخدم، ومخططات واجهة برمجة التطبيقات، وعمليات ترحيل قواعد البيانات، والتنفيذات الأولية. يقوم المطورون البشريون بمراجعة البنية وتحسينها ومعالجة الحالات الاستثنائية. يتغير تقسيم العمل: يتولى الذكاء الاصطناعي كتابة التعليمات البرمجية الأساسية وتنفيذ المسودات الأولية، بينما يضمن المطورون البشريون متانة النظام وسهولة صيانته.
لكن تكمن المشكلة في أن جودة الكود متفاوتة. تُنتج النماذج كودًا صحيحًا نحويًا، ولكنه قد يخالف أحيانًا أفضل الممارسات، أو يُدخل ثغرات أمنية، أو يفشل مع مدخلات غير مُختبرة. لذا، تبقى مراجعة الكود ضرورية. تُشير المؤسسات التي تستخدم مساعدي البرمجة بالذكاء الاصطناعي إلى زيادة في الإنتاجية تتراوح بين 20 و401 تيرابايت في المهام الروتينية، لكنها تُؤكد على أن المطورين المبتدئين ما زالوا بحاجة إلى التوجيه والإشراف.
رؤساء أقسام البيانات يرون صلاحيات موسعة
تشير نتائج الأبحاث الاستقصائية إلى تزايد الاعتقاد بأن أدوار مدير البيانات الرئيسي يجب أن تشمل التحليلات والذكاء الاصطناعي، مع تسجيل نمو ملحوظ على أساس سنوي. ويعكس ذلك ترابط الذكاء الاصطناعي الوثيق مع البنية التحتية للبيانات.
يتطلب تدريب النماذج الكبيرة مجموعات بيانات مُنسقة، وضوابط جودة، وأطر حوكمة. ويتطلب نشر أنظمة الذكاء الاصطناعي مراقبة الانحراف والتحيز والامتثال. يندرج كلا هذين الدورين بشكل طبيعي ضمن اختصاص قيادة البيانات، لكن العديد من مديري البيانات الرئيسيين يفتقرون إلى الخبرة في مجال الذكاء الاصطناعي أو السلطة الكافية لقيادة استراتيجية الذكاء الاصطناعي.
أظهر استطلاع أجرته مؤسسة IEEE أن ممارسات الذكاء الاصطناعي الأخلاقية ستشهد نموًا في الطلب عليها خلال عام 2026، بزيادة قدرها 9 نقاط مئوية مقارنة بالعام السابق. وتسعى المؤسسات إلى توظيف متخصصين ذوي خبرة في ممارسات الذكاء الاصطناعي الأخلاقية، وتقييم العدالة، والامتثال، وهي أدوار تجمع بين هندسة البيانات، والشؤون القانونية، والمعرفة المتخصصة.
بصراحة: لا تزال معظم المؤسسات تعمل بمعزل عن بعضها. فرق البيانات تتولى إدارة التخزين وخطوط نقل البيانات، ومهندسو التعلم الآلي يبنون النماذج، والشؤون القانونية تراجع الامتثال، وفرق المنتجات تحدد المتطلبات. يمكن لمديري البيانات التنفيذيين ذوي الصلاحيات المتعددة الوظائف توحيد هذه الجهود، لكن السياسات التنظيمية غالباً ما تحول دون ذلك.

حوّل اتجاهات الذكاء الاصطناعي إلى مشاريع عملية مع AI Superior
لا تكتسب اتجاهات الذكاء الاصطناعي الجديدة أهمية إلا عندما تستطيع الشركة ربطها بمنتج أو عملية أو مشكلة تجارية حقيقية. متفوقة الذكاء الاصطناعي تدعم هذه الخدمة الشركات من خلال الاستشارات في مجال الذكاء الاصطناعي، واكتشاف حالات استخدام الذكاء الاصطناعي، والبحث والتطوير في هذا المجال، وتطوير الذكاء الاصطناعي التوليدي، واستشارات برامج الماجستير في القانون، ورؤية الحاسوب، ومعالجة اللغات الطبيعية، والتعلم الآلي، وتطوير برامج الذكاء الاصطناعي المخصصة. وهذا يناسب الشركات التي ترغب في استكشاف تطورات الذكاء الاصطناعي من منظور عملي قبل الانتقال إلى مرحلة التطوير.
بإمكان شركة AI Superior مساعدة الفرق في:
- تقييم حالات استخدام الذكاء الاصطناعي بناءً على احتياجات العمل
- استكشاف فرص الذكاء الاصطناعي التوليدي، أو التعلم مدى الحياة، أو معالجة اللغات الطبيعية، أو رؤية الحاسوب
- دعم أبحاث وتطوير الذكاء الاصطناعي
- تخطيط برامج الذكاء الاصطناعي المخصصة وفقًا لمتطلبات واقعية
- دمج حلول الذكاء الاصطناعي في المنتجات أو سير العمل الحالية
👉تواصل مع شركة AI Superior لمناقشة التطورات في مجال الذكاء الاصطناعي التي تستحق الاستكشاف لأعمالك أو منتجك أو عملياتك الداخلية.
ماذا يعني عام 2026 لاستراتيجية الذكاء الاصطناعي؟
تتشارك الاتجاهات المتقاربة في عام 2026 في خيط مشترك: انتقال الذكاء الاصطناعي من مرحلة إثبات المفهوم إلى البنية التحتية الإنتاجية. تعمل الأنظمة الذكية على أتمتة سير العمل. تقدم النماذج ذات التريليونات من المعلمات أداءً يقارب أداء الخبراء. تُنتج محولات الانتشار أعمالًا إبداعية جاهزة للنشر. تُرسّخ الأطر الحكومية معايير الامتثال.
بالنسبة للمؤسسات، يعني هذا أمرين. أولاً، تحتاج المشاريع التجريبية إلى خطط انتقالية. لم يعد شعار "نجري تجارب على الذكاء الاصطناعي" استراتيجيةً مجدية، فالمنافسون ينشرون هذه التقنيات على نطاق واسع. ثانياً، تُعدّ البنية التحتية بنفس أهمية الخوارزميات. فأفضل نموذج يصبح عديم الفائدة بدون قنوات بيانات، ومراقبة، وعمليات امتثال.
تعكس نقاشات المجتمع مخاوف عملية. يناقش المطورون المفاضلات بين أجهزة الذكاء الاصطناعي الطرفية، وإمكانية تكرار المعايير، وشروط ترخيص النماذج. لم تختفِ دورة الضجة الإعلامية، لكنها تتعايش مع نقاشات نشر الإنتاج - وهو توازن أكثر صحة.
بحلول عام 2028، من المتوقع أن تصل قيمة برمجيات الذكاء الاصطناعي إلى 1.58 تريليون دولار أمريكي، وفقًا لتوقعات القطاع. هذا النمو لا يُموّل تطوير النماذج فحسب، بل يُموّل أيضًا الأدوات والبنية التحتية والخدمات التي تُمكّن المؤسسات من تطبيق الذكاء الاصطناعي عمليًا. ويتحوّل التحدي من "هل يُمكننا بناءه؟" إلى "هل يُمكننا نشره بشكل مسؤول وعلى نطاق واسع؟"“
الأسئلة الشائعة
ما هو الذكاء الاصطناعي الوكيل وكيف يختلف عن روبوتات الدردشة؟
تعمل أنظمة الذكاء الاصطناعي الوكيلة بشكل مستقل، حيث تراقب السياقات وتنفذ مسارات عمل متعددة الخطوات دون تدخل بشري في كل خطوة. وعلى عكس روبوتات الدردشة التي تستجيب للاستفسارات، تقوم هذه الأنظمة بجدولة الاجتماعات، وتحليل تدفقات البيانات، وإدارة البنية التحتية بشكل استباقي. وقد أظهر استطلاع IEEE العالمي أن 911% من التقنيين يتوقعون زيادة استخدام الذكاء الاصطناعي الوكيل في تحليل البيانات بحلول عام 2026، مما يعكس التحول من الأتمتة التفاعلية إلى الأتمتة الاستباقية.
ما هو حجم أكبر نماذج الذكاء الاصطناعي في عام 2026؟
وصل DeepSeek-V4-Pro إلى 1.6 تريليون مُعامل، مع تفعيل 49 مليار مُعامل لكل استدلال، باستخدام بنية مزيج الخبراء. أما Mistral Medium 3.5 فهو نموذج كثيف يحتوي على 128 مليار مُعامل. تصل نوافذ السياق الآن إلى مليون رمز (DeepSeek-V4) أو 256 ألف رمز (Mistral Medium 3.5)، مما يُتيح تحليل قواعد البيانات البرمجية أو مجموعات المستندات بالكامل في عملية واحدة.
هل نماذج التريليون معلمة عملية للاستخدام الإنتاجي؟
نعم، بفضل ابتكارات الكفاءة. يقلل التدريب ذو الدقة المختلطة (FP4/FP8) تكاليف الاستدلال بنحو 75% مقارنةً بالدقة الكاملة. لا تُفعّل بنية مزيج الخبراء سوى جزء صغير من المعلمات لكل رمز مميز - يستخدم DeepSeek-V4-Pro 49 مليارًا من معلماته البالغ عددها 1.6 تريليون لكل استدلال. تجعل هذه التحسينات النماذج الضخمة مجدية اقتصاديًا للاستخدام المؤسسي على الرغم من حجمها.
ما هي مهارات الذكاء الاصطناعي الأكثر طلباً في عام 2026؟
شهدت الممارسات الأخلاقية للذكاء الاصطناعي نموًا في الطلب بنسبة 9 نقاط مئوية على أساس سنوي في عام 2026، وفقًا لبيانات معهد مهندسي الكهرباء والإلكترونيات (IEEE). تحتاج المؤسسات إلى متخصصين يربطون بين هندسة البيانات والامتثال القانوني وعدالة الذكاء الاصطناعي. ووجد استطلاع أجرته كلية سلون للإدارة بمعهد ماساتشوستس للتكنولوجيا أن 70% من المشاركين يعتقدون أن دور مدير البيانات الرئيسي يجب أن يشمل استراتيجية الذكاء الاصطناعي، مما يشير إلى وجود طلب على قادة يدمجون حوكمة البيانات مع نشر الذكاء الاصطناعي.
كيف يُغيّر الذكاء الاصطناعي تقديم الرعاية الصحية؟
حقق نظام مايكروسوفت التشخيصي المدعوم بالذكاء الاصطناعي دقة بلغت 85.51 نقطة في ثلاث حالات طبية معقدة، مقارنةً بدقة 201 نقطة في ثلاث حالات للأطباء ذوي الخبرة على نفس مجموعة الاختبار. لا يحل الذكاء الاصطناعي محل الأطباء، بل يعزز دورهم من خلال الفرز، ودعم اتخاذ القرارات، والمراقبة المستمرة عن بُعد. تتوقع منظمة الصحة العالمية نقصًا في عدد العاملين في المجال الطبي يصل إلى 11 مليونًا بحلول عام 2030؛ وتساعد الأنظمة المدعومة بالذكاء الاصطناعي في سد هذه الفجوة من خلال أتمتة تحليل البيانات ومراجعة الأدبيات الطبية، مما يتيح للأطباء التفرغ لرعاية المرضى.
ما هي أكبر تحديات البنية التحتية للذكاء الاصطناعي في عام 2026؟
يُحدّ استهلاك الطاقة ومتطلبات التبريد وتوافر موارد الحوسبة من نطاق التدريب. يُقلّل التبريد السائل من استهلاك الطاقة بمقدار 30-40% مقارنةً بالتبريد الهوائي. كما يُوفّر التدريب ذو الدقة المختلطة والتنشيط المتفرق باستخدام MoE ما بين 60-70% من موارد الحوسبة. يجب على المؤسسات الموازنة بين أداء النموذج والتكاليف التشغيلية، وغالبًا ما تختار نماذج أصغر حجمًا وأكثر دقةً بدلًا من أنظمة ضخمة للمهام المحددة التي تُعدّ فيها الكفاءة أهم من القدرة الخام.
هل ستؤدي قوانين الذكاء الاصطناعي الحكومية إلى إبطاء الابتكار؟
تهدف الأطر الفيدرالية إلى توحيد الامتثال، واستبدال اللوائح الحكومية المتضاربة التي تزيد التكاليف. وتُحدد إرشادات الأمن السيبراني الصادرة عن المعهد الوطني للمعايير والتكنولوجيا (NIST) في ديسمبر 2025، وخطة عمل البيت الأبيض "الفوز في سباق الذكاء الاصطناعي"، أكثر من 90 إجراءً سياسيًا لتسريع تطوير البنية التحتية مع وضع معايير أمنية أساسية. ويعتمد ما إذا كانت هذه الإجراءات تُعزز الابتكار أم تُعيقه على كيفية تنفيذها؛ فتبسيط مراكز البيانات يُساعد، لكن التقاضي بشأن أولوية الولايات يُثير حالة من عدم اليقين.
الطريق إلى الأمام
لم يعد الذكاء الاصطناعي في عام 2026 مجرد تكهنات. فمعايير الأداء، وبيانات تبني المؤسسات له، وتغيرات السياسات الحكومية، كلها أدلة ملموسة على مكانة هذه التقنية. تمثل الأنظمة الذكية، والنماذج ذات التريليونات من المعاملات، ومحولات الانتشار، إنجازات تقنية بارزة، وليست مجرد ادعاءات تسويقية.
لكنّ أصعب المشاكل لا تزال تنظيمية. فدمج الذكاء الاصطناعي في الأنظمة القديمة، وتدريب الموظفين على سير العمل الجديد، وضمان النشر المسؤول، كلها أمور تتطلب قيادة واستثماراً يتجاوزان مجرد تطوير الخوارزميات. التكنولوجيا فعّالة، لكن السؤال هو: هل تستطيع المؤسسات التكيّف معها بالسرعة الكافية للاستفادة منها؟.
سيُقدّم مؤشر ستانفورد للذكاء الاصطناعي واستطلاعات معهد مهندسي الكهرباء والإلكترونيات (IEEE) مقاييس مُحدّثة بحلول منتصف عام 2026. تابع هذه المقاييس للحصول على أدلة كمية حول معدلات التبني، واتجاهات الحوسبة، والتحولات في القوى العاملة. في الوقت الراهن، المسار واضح: الذكاء الاصطناعي هو البنية التحتية، وقرارات البنية التحتية تُشكّل الميزة التنافسية لسنوات.
ابقَ على اطلاع. اختبر بعناية. انشر بمسؤولية. إنّ إنجازات الذكاء الاصطناعي لعام 2026 ليست نظرية، بل هي أنظمة جاهزة للإنتاج تُعيد تشكيل الصناعات الآن.