ملخص سريع: تأتي أسرع واجهات برمجة تطبيقات استدلال نماذج التعلم الموجه باللغات (LLM) في عام 2026 من مزودين مثل Groq وSiliconFlow وHugging Face، بزمن استجابة أقل من ثانيتين وإنتاجية تتجاوز 100 رمز مميز/ثانية. وتختلف الأسعار اختلافًا كبيرًا، بدءًا من DeepSeek بسعر $0.28 لكل مليون رمز مميز مُدخل، وصولًا إلى OpenAI GPT-5.2 Pro بسعر $21.00. ويتطلب الاستدلال الفعال من حيث التكلفة تحقيق توازن بين السرعة والسعر وقدرات النموذج بما يتناسب مع حجم العمل المحدد.
تُعدّ السرعة عاملاً مهماً عند نشر نماذج لغوية كبيرة على نطاق واسع. لكن أسرع واجهة برمجة تطبيقات للاستدلال ليست بالضرورة الأرخص، والأرخص ليس بالضرورة الأسرع.
في أوائل عام 2026، انقسم سوق استدلال نماذج التعلم الآلي إلى مستويات متميزة. تفرض شركات رائدة مثل OpenAI أسعارًا باهظة مقابل نماذجها المتطورة. في المقابل، تقدم شركات جديدة طموحة مثل DeepSeek أسعارًا أقل من الشركات الراسخة بمقدار 901 تيرابايت أو أكثر.
يُفصّل هذا الدليل الأرقام الحقيقية. يشمل ذلك التسعير لكل مليون رمز مميز، وقياسات زمن الاستجابة الفعلية، ومعايير الإنتاجية، والتكاليف الخفية التي لا تُعلن عنها صفحات التسعير.
فهم مقاييس سرعة الاستدلال في نماذج اللغة الخطية
قبل مقارنة مقدمي الخدمات، يجدر فهم ما تعنيه كلمة "سريع" فعليًا في سياق واجهات برمجة تطبيقات إدارة التعلم.
ثلاثة مقاييس هي الأكثر أهمية:
- كمون يقيس هذا المقياس زمن الاستجابة لأول رمز مميز، أي مدى سرعة استجابة النموذج بعد تلقي طلبك. ووفقًا لمقاييس موفر الاستدلال لدى Hugging Face، تحقق النماذج الأفضل أداءً زمن استجابة أقل من 1.5 ثانية. ويُشار إلى Groq باستمرار على أنه سريع للغاية في اختبارات الأداء التي تجريها جهات خارجية، وكذلك في تقارير الأداء الخاصة بـ Groq (الرموز المميزة/ثانية).
- الإنتاجية يتتبع النظام عدد الرموز المميزة التي يتم إنشاؤها في الثانية بمجرد بدء النموذج بالاستجابة. تُظهر بيانات Hugging Face أن مزودي الخدمة الرئيسيين يحققون 127 رمزًا مميزًا في الثانية أو أكثر لنماذج مثل Qwen3.5-35B-A3B.
- نافذة السياق يُحدد هذا مقدار النص الذي يمكن للنموذج معالجته في طلب واحد. تدعم النماذج الحديثة ما بين 128 ألفًا و262 ألف رمز، مع العلم أن السياقات الأطول قد تزيد من زمن الاستجابة والتكلفة.
- لكن الأمر المهم هو أن السرعة تختلف اختلافًا كبيرًا بناءً على خصائص عبء العمل. فالاستعلامات القصيرة ذات الاستجابات الموجزة تُنجز أسرع من مهام الاستدلال ذات السياق الطويل. أما المعالجة الدفعية فتُضحي بوقت الاستجابة الفوري مقابل إنتاجية أفضل وتكاليف أقل.
أسرع مزودي استدلال LLM حسب زمن الاستجابة
عندما تكون السرعة القصوى هي الأولوية، فإن حفنة من مقدمي الخدمات يتفوقون باستمرار على المنافسة.
جروك: مصمم خصيصاً للسرعة
تستخدم Groq وحدة معالجة لغوية (LPU) مصممة خصيصًا لاستنتاج نماذج اللغة المحلية (LLM). وتؤكد مناقشات المجتمع ومعايير الأداء الخاصة بـ Groq أنها "سريعة للغاية" من حيث سرعة الاستنتاج، حيث تتصدر قياسات عدد الكلمات في الثانية السوق باستمرار.
أصدرت الشركة معايير أداء جديدة لمنصة Llama 3.3 70B تُظهر أداءً استدلاليًا رائدًا في هذا المجال. بالنسبة للتطبيقات التي يُعد فيها زمن الاستجابة أقل من ثانية أمرًا بالغ الأهمية - مثل برامج الدردشة الآلية، والمساعدين الفوريين، والأدوات التفاعلية - توفر بنية Groq مزايا ملموسة.
لا يتم الإعلان عن الأسعار لجميع الطرازات بشكل علني، لذا يحتاج المطورون إلى مراجعة الوثائق الرسمية لشركة Groq للاطلاع على الأسعار الحالية.
سيليكون فلو: السرعة تلتقي بالتكلفة المعقولة
حققت منصة SiliconFlow سرعات استدلال أسرع بما يصل إلى 2.3 مرة وزمن استجابة أقل بمقدار 32% مقارنةً بمنصات الذكاء الاصطناعي السحابية الرائدة في اختبارات الأداء الحديثة، مع الحفاظ على دقة ثابتة. توفر المنصة خيارات الدفع حسب الاستخدام بدون خوادم وخيارات تخصيص وحدات معالجة الرسومات.
إنّ الجمع بين السرعة والتحكم في التكاليف يجعل SiliconFlow خيارًا جذابًا لعمليات النشر الإنتاجية حيث يُعدّ كلا المعيارين مهمّين. تدعم المنصة نماذج متعددة مفتوحة المصدر مع تسعير شفاف وخيارات بنية تحتية مرنة.
موفرو استنتاج الوجه أثناء العناق
يجمع Hugging Face العديد من مزودي الاستدلال عبر واجهة برمجة تطبيقات موحدة، ويتتبع الأداء عبر مختلف تركيبات النماذج ومزودي الاستدلال. تتيح هذه الواجهة للمطورين توجيه الطلبات تلقائيًا إلى أسرع مزود أو أقل تكلفة لكل نموذج. ولأن الموجه يدعم استدعاءات متوافقة مع OpenAI، فإن عملية الانتقال سهلة للمستخدمين الذين يعتمدون على عمليات التكامل الحالية.

قم ببناء تطبيقات LLM مُحسّنة للاستدلال السريع
تعتمد استجابات نماذج التعلم الخطي السريع على البنية الصحيحة، وإعداد النموذج، والبنية التحتية. متفوقة الذكاء الاصطناعي تُطوّر الشركة برمجيات الذكاء الاصطناعي وأنظمة معالجة اللغة الطبيعية التي تدمج نماذج لغوية ضخمة في تطبيقات عملية مثل روبوتات المحادثة، وأدوات الأتمتة، ومنصات تحليل البيانات. ويقوم فريقها بتصميم مسارات النماذج، وخدمات الواجهة الخلفية، وبيئات النشر لضمان تشغيل ميزات نماذج اللغة الطبيعية بكفاءة عالية داخل أنظمة الإنتاج.
بناء منتج يستخدم واجهات برمجة تطبيقات إدارة دورة حياة المنتج (LLM APIs)؟
تحدث مع الذكاء الاصطناعي المتفوق على:
- تصميم وبناء تطبيقات مدعومة بتقنية LLM
- تطوير أنظمة معالجة اللغة الطبيعية وبرامج الذكاء الاصطناعي
- نشر نماذج اللغة ضمن المنصات الحالية
👈 اطلب استشارة الذكاء الاصطناعي مع متفوقة الذكاء الاصطناعي لمناقشة مشروعك.
تسعير الاستدلال في برامج الماجستير في القانون: لمحة عامة عن السوق لعام 2026
تختلف هياكل التسعير اختلافاً كبيراً بين مقدمي الخدمات. يفرض البعض أسعاراً مرتفعة على النماذج الخاصة بهم، بينما يتنافس آخرون بشدة على تسعير النماذج مفتوحة المصدر.
إليكم وضع السوق اعتباراً من أوائل عام 2026:
المستوى المميز: OpenAI و Anthropic
أطلقت OpenAI نموذج GPT-5.2 Pro في فبراير 2026 بتكلفة $21.00 لكل مليون رمز مُدخل و$168.00 لكل مليون رمز مُخرج. أما نموذج GPT-5.2 القياسي، فتبلغ تكلفته $8.00 لكل مليون رمز مُدخل و$32.00 لكل مليون رمز مُخرج.
تُصنّف طرازات كلود من أنثروبيك ضمن فئة الأسعار المرتفعة المماثلة. ويبرر هؤلاء الموردون ارتفاع التكاليف بفضل الإمكانيات المتطورة والموثوقية العالية واختبارات السلامة الشاملة.
الفئة المتوسطة: جوجل جيميني وغيرها
تُقدّم نماذج Gemini من جوجل أسعارًا تنافسية للنماذج عالية الأداء. أما الفئة المتوسطة الأوسع فتضمّ مزوّدين مثل Mistral AI، الذين يوازنون بين الأداء العالي والأسعار المعقولة مقارنةً بالمزوّدين المتميزين.
الفئة الاقتصادية: ديب سيك ديسبتشن
تفوقت DeepSeek بشكل كبير على منافسيها من خلال نماذجها "التفكيرية" V3.2-Exp، حيث يبلغ سعرها $0.28 فقط لكل مليون رمز مُدخل (في حالة عدم وجود بيانات في ذاكرة التخزين المؤقت) و$0.42 لكل مليون رمز مُخرج. وهذا يمثل خصمًا يزيد عن 90% مقارنةً بمزودي الخدمات المتميزين.
تستهدف مجموعة Grok من xAI المطورين المهتمين بالتكلفة. ويبلغ سعر كل من Grok 4 Fast و Grok 4.1 Fast $0.20 مدخلات / $0.50 مخرجات لكل مليون رمز.
| مزود | مثال نموذجي | المدخلات ($/M رموز) | الناتج ($/M رمز مميز) | مستوى الأداء |
|---|---|---|---|---|
| OpenAI | GPT-5.2 Pro | $21.00 | $168.00 | غالي |
| OpenAI | GPT-5.2 | $8.00 | $32.00 | غالي |
| xAI | جروك 4 | $3.00 | $15.00 | المستوى المتوسط |
| xAI | جروك 4 فاست | $0.20 | $0.50 | ميزانية |
| البحث العميق | الإصدار التجريبي V3.2 | $0.28 | $0.42 | ميزانية |
| نوفيتا (HF) | Qwen3.5-35B-A3B | $0.25 | $2.00 | ميزانية |
التكاليف الخفية التي تتجاوز تسعير الرموز
لا يمثل سعر الملصق لكل مليون رمز سوى جزء من قصة التكلفة.
تؤثر عدة عوامل خفية بشكل كبير على الإنفاق الفعلي:
التخزين المؤقت للسياق وإعادة الاستخدام
تقدم بعض الشركات أسعارًا مخفضة للسياق المخزن مؤقتًا والذي يُعاد استخدامه في الطلبات. ينطبق سعر DeepSeek البالغ $0.28 على الطلبات التي لا يتم العثور فيها على البيانات في ذاكرة التخزين المؤقت؛ أما أسعار الطلبات التي يتم العثور فيها على البيانات فهي أقل. إذا كان تطبيقك يعالج سياقات متشابهة بشكل متكرر، فإن التخزين المؤقت يمكن أن يقلل التكاليف بشكل كبير.
التسعير المجمع مقابل التسعير الفوري
تُقدّم OpenAI وGoogle واجهات برمجة تطبيقات لمعالجة البيانات المجمّعة بأسعار مخفّضة، تصل أحيانًا إلى 50% من أسعار الوقت الفعلي. ووفقًا لمناقشات مجتمع Hugging Face، لا يوجد بديل مباشر لواجهة برمجة تطبيقات المعالجة المجمّعة من OpenAI بأسعار مخفّضة خاصة على نقاط نهاية Hugging Face غير الخادمة.
يُعدّ الاستدلال الدفعي مناسبًا لأعباء العمل غير الحساسة للوقت، مثل معالجة البيانات، وإنشاء المحتوى، ومهام التحليل. ويتمثل المقابل في تأخير الإنجاز مقابل انخفاض التكاليف.
اقتصاديات رموز الإنتاج
عادةً ما تكلف رموز الإخراج من 4 إلى 8 أضعاف رموز الإدخال. النموذج الذي يُنتج ردودًا مطولة يستنزف الميزانية أسرع من النموذج الذي يُقدم ردودًا موجزة.
لتحسين التكلفة، يمنع تحديد الحد الأقصى لطول المخرجات الاستخدام المفرط للرموز. قد يؤدي تحديد حدود منخفضة للغاية إلى اقتطاع الاستجابات قبل تقديم إجابات كاملة، لذا يتطلب التكوين موازنة بين اكتمال البيانات والتحكم في التكلفة.
تكاليف البنية التحتية والتوسع
تُفرض رسوم على واجهات برمجة التطبيقات بدون خوادم لكل رمز مميز دون أي تكاليف إضافية للبنية التحتية. تتطلب نماذج السعة المحجوزة - مثل خيارات وحدة معالجة الرسومات المحجوزة من SiliconFlow - التزامات مسبقة، لكنها توفر اقتصاديات أفضل لكل رمز مميز على نطاق واسع.
تُظهر الأبحاث المتعلقة بنشر وحدات معالجة الرسومات غير المتجانسة أن فعالية التكلفة تختلف اختلافًا كبيرًا بناءً على خصائص عبء العمل. ووفقًا لتحليل خدمة LLM عبر وحدات معالجة الرسومات غير المتجانسة، فإن مطابقة أنواع الطلبات مع الأجهزة المناسبة تُحسّن استخدام الموارد وتُقلل التكاليف الفعلية.
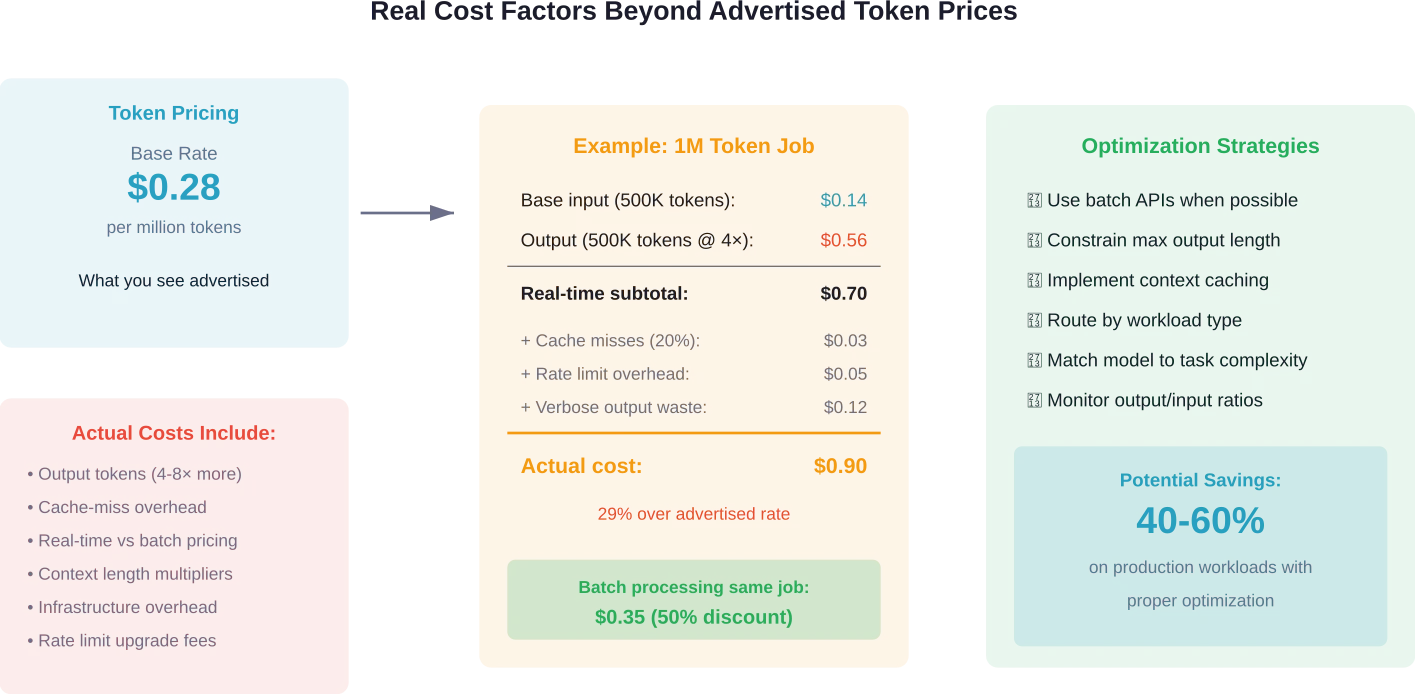
نسبة السرعة إلى التكلفة: إيجاد النقطة المثلى
يعتمد اختيار المزود الأمثل كلياً على متطلبات حجم العمل.
بالنسبة للتطبيقات التي تتطلب استجابة سريعة للغاية - مثل روبوتات الدردشة الموجهة للعملاء، ومساعدي البرمجة الفورية، والعروض التوضيحية التفاعلية - فإن السرعة تبرر السعر المرتفع. فتأخير الاستجابة لمدة ثانيتين يُنفر المستخدمين بغض النظر عن وفورات التكلفة.
في عمليات المعالجة الدفعية ذات الحجم الكبير - تصنيف المحتوى، واستخراج البيانات، وخطوط تحليل البيانات - تُهيمن تكلفة المليون رمز على المعادلة. ويُعدّ تسعير DeepSeek البالغ $0.28، مع أداء مقبول (إن لم يكن متميزًا)، خيارًا اقتصاديًا منطقيًا.
تشير الأبحاث المتعلقة بتوجيه نماذج التعلم الآلي إلى أن الأساليب الهجينة قادرة على تحسين كلا المقياسين. فاستخدام نماذج أصغر وأسرع للمعالجة الأولية وتوجيه الاستعلامات المعقدة إلى نماذج أكبر يقلل من متوسط التكاليف مع الحفاظ على الجودة. ووفقًا للدراسة، فإن حتى التلميحات البسيطة من النماذج الأكبر (10-30% من الاستجابة الكاملة) تُحسّن بشكل كبير من دقة النماذج الأصغر.
اعتبارات حجم النموذج
يؤثر حجم النموذج بشكل مباشر على كل من السرعة والتكلفة.
وفقًا لإرشادات Hugging Face بشأن اختيار نماذج التعلم الآلي مفتوحة المصدر، يتطلب نموذج ذو 7-8 مليارات مُعامل ذاكرة وصول عشوائي للفيديو (VRAM) بسعة 14-16 جيجابايت بدقة FP16، أو 6-8 جيجابايت مع تكميم 4 بت. تشمل خيارات الحوسبة السحابية مثيلات AWS g5.xlarge.
تعمل النماذج الأصغر ذات المعلمات من 1 إلى 3 مليارات على ذاكرة وصول عشوائي للفيديو بسعة 4-6 جيجابايت (2 جيجابايت مُكمّمة) وتتعامل مع المهام الأساسية - تصنيف النصوص، والإكمال التلقائي، والدردشة البسيطة - على أجهزة متواضعة مثل RTX 3060 أو وحدات معالجة الرسومات لأجهزة الكمبيوتر المحمولة.
تُقدّم النماذج الأكبر حجماً استدلالاً أفضل، لكنها تتطلب موارد حاسوبية أكبر. يتطلب نشر نموذج LLaMA-2-70B ما لا يقل عن وحدتي معالجة رسومية NVIDIA A100 (بذاكرة وصول عشوائي للفيديو 80 جيجابايت لكل منهما) لاستنتاج FP16، وفقاً لدراسة استقصائية حول الكفاءة.
أفضل مزودي الخدمات ذوي التكلفة المنخفضة للاستدلال السريع
استنادًا إلى مقاييس الأداء وبيانات التسعير، يقدم العديد من مقدمي الخدمات نسبًا جذابة بين السرعة والتكلفة:
سيليكون فلو
تجمع منصة SiliconFlow بين السرعة التنافسية (أسرع بـ 2.3 مرة من بعض المنصات الرائدة) والتسعير المرن. تدعم المنصة كلاً من السعة غير الخادمة والسعة المحجوزة، مما يسمح بتحسين التكاليف بناءً على أنماط الاستخدام.
توفر الخدمة سحابة ذكاء اصطناعي متكاملة بنسب سعر إلى أداء رائدة في الصناعة، تستهدف كلاً من المطورين والمؤسسات.
موفرو استنتاج الوجه أثناء العناق
يجمع جهاز التوجيه الموحد من Hugging Face بين عدة مزودين، مما يسمح بالتوجيه التلقائي إلى الخيار الأسرع أو الأرخص لكل طراز. وفقًا لمقاييسهم:
- تقدم نوفيتا طرازات Qwen3.5 بمدخلات تتراوح بين $0.25 و$0.60 مع زمن استجابة أقل من 1.1 ثانية
- توفر شركة Together AI نماذج مماثلة مع زمن استجابة أعلى قليلاً ولكن بأسعار مماثلة
- يتنافس العديد من مقدمي الخدمات على كل نموذج شائع، مما يؤدي إلى زيادة الكفاءة.
يدعم جهاز التوجيه استدعاءات واجهة برمجة التطبيقات المتوافقة مع OpenAI، مما يُسهّل عملية الانتقال من مزودين آخرين. ويمكن للمطورين تحديد تفضيلات التوجيه - ":fastest" و ":cheapest" - لتحقيق أهداف مختلفة.
ميسترال للذكاء الاصطناعي
تقدم شركة ميسترال للذكاء الاصطناعي أداءً قوياً بأسعار متوسطة. وتركز الشركة على بنى نماذج فعالة تقلل تكاليف الاستدلال دون المساس بالقدرات.
تحقق نماذج ميسترال معايير جودة تنافسية مع الحفاظ على تكاليف معقولة لكل رمز مميز، مما يجعلها جذابة لعمليات النشر الإنتاجية التي توازن بين القيود المتعددة.
البحث العميق
بالنسبة لأحمال العمل التي تهيمن فيها التكلفة على عملية صنع القرار، فإن التسعير التنافسي لشركة DeepSeek ($0.28 مدخلات / $0.40 مخرجات) يمثل الحد الأدنى الحالي للسوق للنماذج القادرة.
يتخلف الأداء عن مزودي الخدمات المتميزين، ولكنه يظل مقبولاً للعديد من التطبيقات. وتتيح وفورات التكلفة - التي تصل إلى 90% مقارنةً بالطرازات الرائدة - حالات استخدام لم تكن تبرر الأسعار المرتفعة.
ألعاب نارية بتقنية الذكاء الاصطناعي
تتخصص شركة Fireworks AI في الاستدلال الأمثل للنماذج مفتوحة المصدر. وتركز المنصة على موثوقية عالية المستوى مع أسعار وأداء يمكن التنبؤ بهما.
توفر الخدمة بنية تحتية مصممة خصيصًا لخدمة LLM، مع ميزات مصممة للمطورين الذين يقومون ببناء التطبيقات بدلاً من تجربة النماذج.
اعتبارات قياس الأداء
لا تعكس المعايير المنشورة دائمًا الأداء في العالم الحقيقي.
تتسبب عدة عوامل في وجود فجوات بين المقاييس المعلن عنها وتجربة الإنتاج:
تؤثر ظروف التحميل على زمن الاستجابة. فمزودو الخدمة الذين يعانون من ضغط عالٍ يبطئون من سرعة الاستجابة. كما يؤثر وقت اليوم والمنطقة الجغرافية والطلب الحالي على أوقات الاستجابة الفعلية.
تُعدّ خصائص الطلب ذات أهمية بالغة. فالمطالبات القصيرة ذات المخرجات الموجزة تُنجز أسرع من مهام الاستدلال ذات السياق الطويل. ووفقًا للأبحاث المتعلقة بمفاضلات الطاقة والأداء في استدلال نماذج التعلم الخطي، يُظهر الاستدلال تباينًا كبيرًا بين الاستعلامات ومراحل التنفيذ.
قد يؤثر زمن استجابة بدء التشغيل البارد على الطلب الأول في البنى غير الخادمة.
تُقيّد حدود المعدل الإنتاجية. حتى واجهات برمجة التطبيقات السريعة تُخفّض الطلبات عند تجاوز أحجام معينة، مما يتطلب اشتراكات من مستوى أعلى أو سعة محجوزة للتطبيقات ذات الأحجام الكبيرة.
خيارات نشر البنية التحتية
بالإضافة إلى واجهات برمجة التطبيقات المُدارة، تؤثر خيارات البنية التحتية بشكل كبير على التكلفة والأداء.
واجهات برمجة التطبيقات بدون خادم
تعتمد خيارات الحوسبة بلا خوادم، مثل تلك التي تقدمها Hugging Face وOpenAI وغيرها، على نظام الدفع مقابل كل رمز مميز دون الحاجة إلى إدارة البنية التحتية. يُعد هذا النموذج مناسبًا لأحمال العمل المتغيرة، ولإنشاء النماذج الأولية، وللتطبيقات ذات الطلب غير المتوقع.
المقابل هو ارتفاع تكاليف الرمز المميز الواحد مقارنة بالبنية التحتية المخصصة على نطاق واسع.
السعة المحجوزة
توفر وحدات معالجة الرسومات المحجوزة أو نقاط النهاية المخصصة موارد مضمونة بأسعار أقل لكل رمز مميز. يقدم مزودون مثل SiliconFlow هذا الخيار إلى جانب أسعار الحوسبة بلا خوادم.
تصبح السعة المحجوزة منطقية اقتصادياً بمجرد أن يصل الاستخدام إلى عتبات ثابتة حيث تنخفض تكلفة الالتزام إلى ما دون الإنفاق المكافئ بدون خادم.
الاستدلال الذاتي
يوفر تشغيل الاستدلال على البنية التحتية المملوكة أو المستأجرة أقصى قدر من التحكم وأقل التكاليف المحتملة عند الأحجام العالية جدًا.
تُبرز الأبحاث المتعلقة بنشر نماذج الذاكرة منخفضة المستوى (LLMs) على الأجهزة الطرفية بعض القيود: إذ يتطلب نموذج ذو 7-8 مليارات مُعامل موارد ذاكرة وحوسبة كبيرة. وتُظهر دراسات توصيف أنظمة SoC المحمولة أنه حتى مع وحدات المعالجة غير المتجانسة، فإن عرض نطاق الذاكرة يُحد من الإنتاجية، حيث لا تتجاوز بعض التكوينات 40-45 جيجابايت/ثانية لكل وحدة قبل الحاجة إلى معالجات متعددة لاستغلال عرض النطاق المتاح بالكامل.
يتطلب الاستضافة الذاتية خبرة في نشر النماذج وتحسينها ومراقبتها وتوسيع نطاقها - وهي تكاليف إضافية تتخلص منها واجهات برمجة التطبيقات بدون خادم.
اختيار المزود المناسب لحجم عملك
ينبغي أن تعطي معايير اتخاذ القرار الأولوية لخصائص عبء العمل على المقارنات المجردة.
اطرح هذه الأسئلة:
- ما هو نمط الاستخدام؟ تُفضّل أحمال العمل الثابتة ذات الحجم الكبير السعة المحجوزة أو الاستضافة الذاتية. أما الطلب المتغير وغير المتوقع فيناسب واجهات برمجة التطبيقات بدون خوادم.
- ما مدى حساسية التطبيق للتأخير؟ تتطلب تفاعلات المستخدم في الوقت الفعلي أوقات استجابة تقل عن ثانية. أما المعالجة في الخلفية فتتحمل تأخيرًا لعدة ثوانٍ لتوفير التكاليف.
- ما هي إمكانيات النموذج المطلوبة فعلياً؟ تُفرط العديد من التطبيقات في توفير إمكانيات النموذج. بينما تتولى النماذج الأصغر والأسرع المهام البسيطة بتكلفة أقل.
- هل يمكن أن تنجح المعالجة الدفعية؟ تستفيد أحمال العمل غير العاجلة من خصومات الدفعات 50% عندما يقدمها مقدمو الخدمات.
- ما هي نسبة المخرجات إلى المدخلات؟ تُكلّف التطبيقات التي تُنتج استجابات طويلة مبالغ طائلة مقابل رموز الإخراج. ويُقلّل تقييد الإسهاب من التكاليف بشكل كبير.
- هل يستفيد عبء العمل من التخزين المؤقت للسياق؟ يؤدي تكرار معالجة السياقات المتشابهة مع دعم التخزين المؤقت إلى خفض التكاليف لكل طلب.
الأسئلة الشائعة
ما هي أرخص واجهة برمجة تطبيقات للاستدلال في نموذج التعلم الخطي في عام 2026؟
تقدم DeepSeek أقل الأسعار، حيث تبلغ $0.28 لكل مليون رمز إدخال و$0.40 لكل مليون رمز إخراج، وذلك لنماذج V3.2-Exp الخاصة بها اعتبارًا من أوائل عام 2026. ويُعدّ Grok 4 Fast من xAI، بسعر $0.20 للإدخال و$0.50 للإخراج، سعرًا مشابهًا. مع ذلك، يعتمد إجمالي التكلفة على مستوى تفصيل الإخراج، وكفاءة التخزين المؤقت، وتوفر معالجة الدفعات. ويختلف الخيار "الأرخص" بناءً على هذه العوامل الخاصة بعبء العمل.
أي مزود خدمة يتمتع بأسرع سرعة استدلال LLM؟
تُصنّف Groq باستمرار كأسرع مزود لخدمات الاستدلال، مستخدمةً أجهزة معالجة منطقية (LPU) مُصممة خصيصًا ومُحسّنة لأحمال عمل نماذج التعلم العميق (LLM). وتشير معايير الأداء الخارجية ومناقشات المجتمع إلى أن Groq تُقدّم أداءً رائدًا في مجال معالجة الرموز المميزة في الثانية. ووفقًا لمقاييس Hugging Face، تشمل الخيارات السريعة الأخرى Novita (التي تستضيف نماذج Qwen بزمن استجابة يتراوح بين 0.66 و1.09 ثانية) وSiliconFlow (أسرع بمقدار 2.3 مرة من بعض المنصات الرائدة). وتعتمد السرعة الفعلية على حجم النموذج وطول السياق وظروف التحميل الحالية.
كم تبلغ تكلفة تشغيل مليار رمز مميز من خلال واجهة برمجة تطبيقات إدارة الأصول المتعثرة؟
تختلف تكلفة مليار رمز بشكل كبير حسب المزود ومزيج المدخلات والمخرجات. فبحسب أسعار DeepSeek ($0.28 مدخلات / $0.40 مخرجات)، تبلغ تكلفة مليار رمز $280 للمدخلات فقط، أو $400 للمخرجات فقط. أما بحسب أسعار GPT-5.2 Pro من OpenAI ($21 مدخلات / $168 مخرجات)، فتبلغ تكلفة نفس الحجم $21,000 مدخلات أو $168,000 مخرجات. فعلى سبيل المثال، تبلغ تكلفة عبء عمل نموذجي بمدخلات 60% ومخرجات 40% حوالي $328 على DeepSeek، مقابل $79,800 على GPT-5.2 Pro، أي بفارق 240 ضعفًا.
هل توفر واجهات برمجة التطبيقات لمعالجة الدفعات المال فعلاً؟
نعم، عند توفرها. تقدم OpenAI وGoogle واجهات برمجة تطبيقات للمعالجة الدفعية بخصومات تصل إلى 50% مقارنةً بالمعالجة الفورية. لكن يعيبها تأخر الإنجاز، فقد تستغرق مهام المعالجة الدفعية ساعات بدلاً من ثوانٍ. ووفقًا لمناقشات مجتمع Hugging Face، فإن العديد من نقاط نهاية Hugging Face التي لا تعتمد على الخوادم لا تقدم أسعارًا مخفضة خاصة بالمعالجة الدفعية، على الرغم من أن نقاط نهاية الاستدلال المخصصة قد تقدم ذلك. تُعد المعالجة الدفعية خيارًا مناسبًا لمعالجة البيانات، وإنشاء المحتوى، ومهام التحليل التي لا تتطلب نتائج فورية.
هل يجب عليّ استخدام الخوادم غير المتصلة بالخوادم أم سعة وحدة معالجة الرسومات المحجوزة؟
يعتمد ذلك على أنماط الاستخدام وحجمه. تُعدّ واجهات برمجة التطبيقات بدون خوادم مناسبةً للطلب المتغير، ولإنشاء النماذج الأولية، ولأحجام الاستخدام المنخفضة إلى المتوسطة حيث تفوق سهولة الاستخدام تكلفة الرمز المميز. يصبح حجز السعة مُجديًا اقتصاديًا عندما يصل الاستخدام المُستمر إلى نقطة التعادل، حيث تنخفض تكاليف الالتزام إلى ما دون تكلفة الإنفاق المُكافئ على واجهات برمجة التطبيقات بدون خوادم. يُقدّم SiliconFlow كلا الخيارين، مما يسمح بالتحسين بناءً على أنماط الاستخدام. احسب حجم الرمز المميز المُستدام الفعلي لديك وقارنه بأسعار الحجز لتحديد عتبة التعادل.
كيف يؤثر حجم النموذج على سرعة الاستدلال وتكلفته؟
تتطلب النماذج الأكبر حجمًا موارد حاسوبية أكبر، مما يزيد من زمن الاستجابة وتكاليف البنية التحتية. وفقًا لوثائق Hugging Face، يحتاج نموذج بحجم 1-3 مليارات إلى 2-4 جيجابايت فقط من ذاكرة الوصول العشوائي للفيديو (VRAM) ويُوفر استدلالًا سريعًا على أجهزة ذات مواصفات متوسطة، وهو مناسب للمهام الأساسية. بينما يتطلب نموذج بحجم 7-8 مليارات ذاكرة وصول عشوائي للفيديو تتراوح بين 6 و16 جيجابايت، اعتمادًا على التكميم، ويتعامل مع أحمال عمل أكثر تعقيدًا. أما نموذج بحجم 70 مليارًا فيتطلب أكثر من 140 جيجابايت من ذاكرة الوصول العشوائي للفيديو (وحدات معالجة رسومية متعددة عالية الأداء) ويعالج الطلبات ببطء أكبر. تُحسّن النماذج الأصغر حجمًا السرعة والتكلفة، بينما تُحسّن النماذج الأكبر حجمًا القدرة وجودة الاستدلال. لذا، يُنصح بمطابقة حجم النموذج مع متطلبات المهمة الفعلية بدلًا من الاعتماد على أكبر نموذج متاح افتراضيًا.
هل يمكنني تقليل التكاليف عن طريق تحسين مدة الرد الفوري؟
بالتأكيد. تستهلك المطالبات الأقصر عددًا أقل من رموز الإدخال، مما يقلل التكاليف بشكل مباشر. والأهم من ذلك، أن تحديد الحد الأقصى لطول المخرجات يمنع الاستجابات المطولة المكلفة. نظرًا لأن تكلفة رموز الإخراج تزيد من 4 إلى 8 أضعاف تكلفة رموز الإدخال، فإن النموذج الذي يُولّد استجابات طويلة بلا داعٍ يستنزف الميزانية بسرعة. وفقًا لأفضل الممارسات، اضبط معلمات max_tokens بما يتناسب مع حالة الاستخدام الخاصة بك - فالضبط على قيمة منخفضة جدًا يؤدي إلى اقتطاع الاستجابات، بينما يؤدي الضبط على قيمة عالية جدًا إلى إطالة غير ضرورية. راقب أطوال المخرجات الفعلية واضبط الحدود وفقًا لذلك. كما أن التخزين المؤقت للسياق لعناصر المطالبة المتكررة يقلل التكاليف بشكل أكبر عندما يدعمه الموفر.
الخلاصة: الموازنة بين السرعة والتكلفة
إن أسرع واجهة برمجة تطبيقات للاستدلال في نموذج التعلم المحدود ليست الخيار الأفضل لكل عبء عمل - كما أن أرخص واجهة برمجة تطبيقات ليست دائمًا الأكثر فعالية من حيث التكلفة عندما تكون الجودة والسرعة مهمة.
في عام 2026، سيُتيح السوق خياراتٍ حقيقية. فمزودو الخدمات المتميزون مثل OpenAI يقدمون إمكانياتٍ متطورة بأسعارٍ مرتفعة. أما المنافسون الأقوياء مثل DeepSeek، فيقدمون أسعارًا أقل بكثير من الشركات القائمة، تصل إلى 901 تيرابايت أو أكثر. بينما يُركز مزودو البنية التحتية المتخصصة مثل Groq وSiliconFlow على تحسين الأداء من حيث السرعة أو الكفاءة في التكلفة.
يعتمد اختيار المزود الأمثل كلياً على متطلباتك الخاصة: حساسية زمن الاستجابة، واحتياجات جودة الإخراج، وحجم الاستخدام، ومستوى تفصيل الإخراج، وفرص التخزين المؤقت، وما إذا كانت معالجة الدفعات مناسبة لحالة استخدامك.
ابدأ بفهم خصائص عبء العمل لديك. قم بقياس أحجام الرموز الفعلية، ونسب الإدخال/الإخراج، ومتطلبات زمن الاستجابة. ثم قم بربط هذه المتطلبات بمزودي الخدمات الذين يُحسّنون الأداء وفقًا لقيودك المحددة.
لا تفترض أن الخيار الأغلى ثمناً يحقق أفضل النتائج، أو أن الخيار الأرخص ثمناً يضحي بالكثير من الجودة. اختبر عدة مزودين بأحمال عمل نموذجية قبل الالتزام بنشر واسع النطاق.
سيظل سوق الاستدلال في مجال ماجستير القانون شديد التنافسية في عام 2026، مع تحسن سريع في الأسعار والأداء. راقب الوافدين الجدد وقارن الأداء بانتظام لضمان حصولك على أفضل قيمة ممكنة مع تطور السوق.
هل أنت مستعد لتحسين تكاليف استدلال LLM؟ قارن عبء العمل المحدد الخاص بك عبر مقدمي الخدمات باستخدام بيانات التسعير ومقاييس الأداء في هذا الدليل لتحديد أفضل نسبة بين السرعة والتكلفة لتطبيقك.