ملخص سريع: تقيس معايير أداء نماذج التعلم الآلي أداء الاستدلال عبر مقاييس الإنتاجية، وزمن الاستجابة، وكفاءة التكلفة. تساعد أدوات قياس الأداء مثل MLPerf وvLLM وGuideLLM المؤسسات على تقييم خيارات النشر، حيث تُكلّف النماذج الصغيرة ذاتية الاستضافة (7-14 مليار مُعامل) ما بين 95 و991 تريليون دولار أمريكي أقل من واجهات برمجة التطبيقات التجارية، مع الحفاظ على أداء مماثل للعديد من حالات الاستخدام.
قد تؤثر تكاليف نشر نماذج اللغة الكبيرة بشكل كبير على نجاح أو فشل أي مشروع ذكاء اصطناعي. ووفقًا لتقارير AWS وغيرها من التقارير الصناعية، يستهلك الاستدلال أكثر من 901 تيرابايت من إجمالي استهلاك الطاقة لنماذج اللغة في بيئات الإنتاج. وهذا يمثل نفقات تشغيلية ضخمة تتطلب قياسًا دقيقًا.
لم يعد قياس أداء نماذج التعلم الآلي يقتصر على السرعة فحسب، بل أصبحت الكفاءة في التكلفة الشغل الشاغل للمؤسسات التي توسع نطاق تطبيقات الذكاء الاصطناعي. لم يعد السؤال هو ما إذا كان النموذج قادرًا على تلبية الطلبات، بل ما إذا كان قادرًا على القيام بذلك بشكل مربح.
لكن المشكلة تكمن في أن معظم الفرق تفتقر إلى منهجية منظمة لقياس الأداء والتكلفة في آن واحد. فهم يركزون على معيار واحد فقط، ثم يرون النفقات تتصاعد بشكل خارج عن السيطرة.
فهم معايير خدمة ماجستير القانون
تقيس معايير الأداء كيفية تصرف نماذج التعلم الموجه (LLMs) في ظل ظروف محددة. وعلى عكس لوحات صدارة جودة النماذج التي تصنف قدرة الاستدلال، تركز معايير الخدمة على المقاييس التشغيلية: الإنتاجية، وزمن الاستجابة، واستخدام الموارد، وفي النهاية، تكلفة الاستدلال.
تمثل مجموعة معايير MLCommons MLPerf Inference المعيار الصناعي لقياس أداء أحمال العمل في مجال التعلم الآلي والذكاء الاصطناعي. وقد قدم الإصدار 5.1 من MLPerf Inference نموذج Llama3.1-8B كمعيار، موفرًا طول سياق يبلغ 128,000 رمزًا، ما يعكس متطلبات المؤسسات في الواقع العملي.
لكن انتظر لحظة - ما الذي يهم فعلاً عند إجراء المقارنة المعيارية؟
مؤشرات الأداء الرئيسية
يقيس معدل نقل البيانات عدد الطلبات التي تتم معالجتها في الثانية. ويعني ارتفاع معدل نقل البيانات خدمة عدد أكبر من المستخدمين باستخدام نفس الأجهزة. يحسب برنامج GuideLLM النسب المئوية الشاملة، بما في ذلك النسب المئوية 0.1، 1، 5، 10، 25، 75، 90، 95، و99 لمعدل نقل البيانات ومقاييس أخرى.
يقيس زمن الاستجابة وقت الاستجابة. يحدد MLPerf قيودًا محددة لزمن الاستجابة لسيناريوهات مختلفة. تقيس سيناريوهات التدفق الفردي زمن الاستجابة عند النسبة المئوية التسعين، بينما تستهدف سيناريوهات الخادم أوقات استجابة أقل من ثانية للتطبيقات التفاعلية.
يُعدّ وقت ظهور أول رمز (TTFT) عاملاً مهماً في تجربة المستخدم. وبصراحة، يلاحظ المستخدمون عندما يستغرق ظهور الاستجابات أكثر من 200-300 مللي ثانية. ويؤثر هذا المقياس بشكل مباشر على سرعة استجابة التطبيق.
يختلف معدل توليد الرموز عن معدل معالجة الطلبات. فهو يقيس عدد الرموز المنتجة في الثانية، وهو ما يرتبط ارتباطًا مباشرًا بسرعة الإخراج التي يراها المستخدم. وتشير الأبحاث الحديثة في مجال استدلال نماذج لغات الاستدلال إلى وجود تقلبات كبيرة في الذاكرة أثناء توليد الرموز، مما يؤثر على هذا المقياس.
سيناريوهات معيارية قياسية
يُحدد برنامج MLPerf أربعة سيناريوهات رئيسية. كل منها يحاكي أنماط تطبيقات مختلفة بخصائص تحميل محددة.
| سيناريو | توليد الاستعلامات | قيود زمن الاستجابة | مقياس الأداء |
|---|---|---|---|
| تدفق واحد | الاستعلامات المتسلسلة | النسبة المئوية التسعين | زمن استجابة 90%-ile |
| بث متعدد | دفعات ذات فترات زمنية ثابتة | النسبة المئوية 99 | أقصى تدفقات |
| الخادم | توزيع بواسون | النسبة المئوية 99 | عدد الاستعلامات في الثانية |
| غير متصل بالإنترنت | جميع الاستفسارات على | لا أحد | الإنتاجية الإجمالية |
تحاكي سيناريوهات الخادم أحمال واجهة برمجة التطبيقات (API) في بيئة الإنتاج مع طلبات موزعة وفقًا لتوزيع بواسون. يعكس هذا النمط سلوك المستخدم الواقعي حيث تصل الطلبات بشكل عشوائي بدلاً من فترات زمنية ثابتة.
قياس تكاليف الاستدلال في نماذج الانحدار الخطي المختلط
يتطلب تحليل التكاليف فهم كل من النفقات المباشرة وغير المباشرة. يساهم استهلاك الأجهزة، واستهلاك الطاقة، ورسوم الاستضافة، والتكاليف التشغيلية العامة في التكلفة الإجمالية للملكية.
وفقًا لإطار اقتصاديات الاستدلال من فريق WiNGPT، ينبغي التعامل مع استدلال LLM باعتباره إنتاجًا ذكيًا مدفوعًا بالحوسبة. فعلى سبيل المثال، تبلغ التكلفة الأساسية لوحدة معالجة الرسومات A800 80G حوالي $0.79 في الساعة، وتتراوح عادةً بين $0.51 و$0.99 في الساعة في ظل افتراضات التشغيل الشائعة.
مكونات التكلفة الإجمالية للملكية
تبدأ تكاليف الأجهزة من لحظة الشراء. قد تصل تكلفة تكوينات الخوادم المزودة بـ 8 وحدات معالجة رسومية إلى 1.4 مليار دولار أو أكثر، وذلك حسب طراز وحدة المعالجة الرسومية. وعادةً ما يتبع الاستهلاك دورة مدتها أربع سنوات في عمليات النشر المؤسسية.
تشمل تكاليف توفير البنية التحتية رسوم الاستضافة، واستهلاك الطاقة، والتبريد، ومساحة الخوادم. وتتراكم هذه النفقات التشغيلية بمرور الوقت. أما بالنسبة لعمليات النشر السحابية، فتختلف أسعار الخوادم بشكل كبير بناءً على نوع وحدة معالجة الرسومات والمنطقة.
تُضيف رسوم ترخيص البرامج وصيانتها تكاليف متكررة. تُلغي أُطر الخدمة مفتوحة المصدر مثل vLLM رسوم الترخيص، لكن الحلول التجارية تفرض رسومًا على كل عملية نشر أو على كل رمز مميز تتم معالجته.
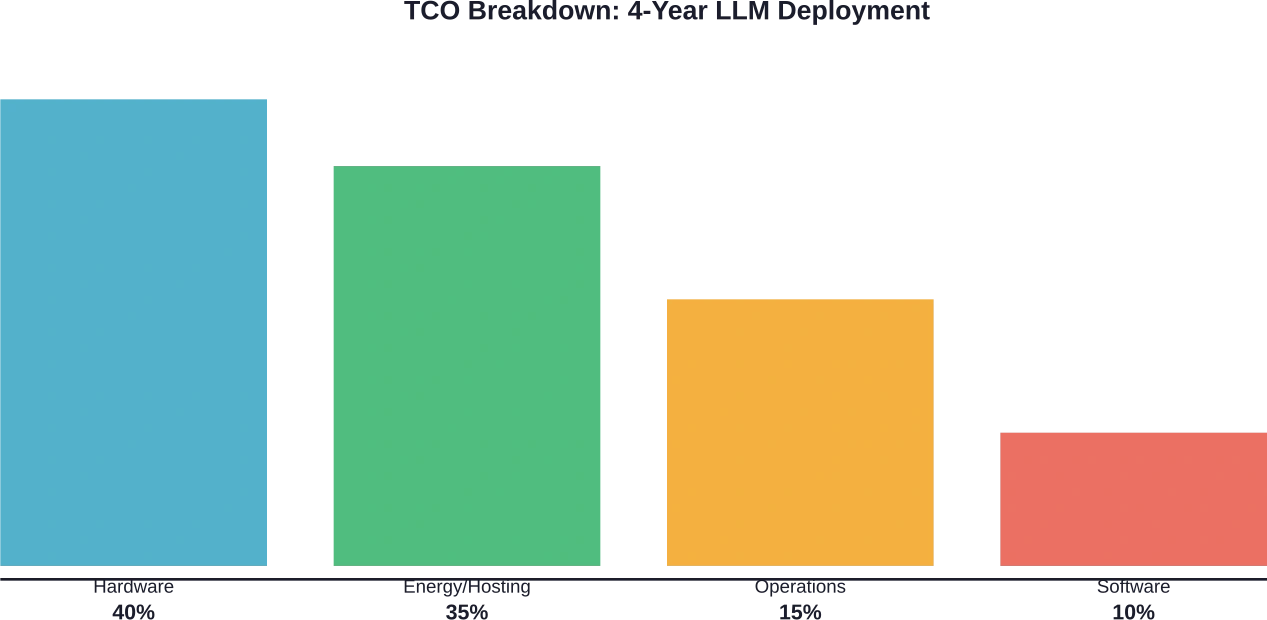
مقارنة تكلفة الاستضافة الذاتية مقابل واجهة برمجة التطبيقات (API)
تكشف نسب التكلفة عن اختلافات كبيرة بين أساليب النشر. وتُظهر الأبحاث التي نشرتها شركة Fin AI أن النماذج الأصغر حجماً تُحقق وفورات كبيرة مقارنةً بواجهات برمجة التطبيقات التجارية.
| نموذج | حدود | التكلفة مقابل GPT-4.1 | مقارنة التكلفة مع GPT-4.1 Mini | التكلفة مقابل السونيت 3.7 |
|---|---|---|---|---|
| جيما 3 4ب | 4ب | 0.04 | 0.20 | 0.01 |
| ديب سيك لاما 8 بي | 8ب | 0.05 | 0.27 | 0.01 |
| كوين 3 14ب | 14ب | 0.05 | 0.27 | 0.01 |
| جيما 3 27ب | 27ب | 0.34 | 1.71 | 0.08 |
| ديب سيك لاما 70 بي | 70ب | 1.70 | 8.49 | 1.10 |
| كوين 3 235ب | 235ب | 2.17 | 10.83 | 1.40 |
تُعدّ النماذج الأصغر حجماً التي تحتوي على أقل من 14 مليار مُعامل أقل تكلفة بكثير من نماذج فئة GPT-4، حيث تُشير الأبحاث إلى أن التكاليف تتراوح بين 0.04 و0.05 ضعف تكلفة GPT-4.1. وهذا يُعدّ تحولاً جذرياً للتطبيقات ذات الحجم الكبير حيث تسمح متطلبات الجودة باستخدام نماذج أصغر.
وثّق فريق هندسة Salesforce توفيرًا يزيد عن 1 تريليون و4 تريليونات و500 ألف دولار سنويًا من خلال استبدال تبعيات LLM الحية بخدمة وهمية لتطوير وقياس أداء سير العمل. وقد أدى ذلك إلى إلغاء استهلاك الرموز المميزة لاختبارات ما قبل الإنتاج، مع الحفاظ على قدرات التحقق عند 16000 طلب في الدقيقة، وسعة قصوى تتجاوز 24000 طلب في الدقيقة.
أدوات وأطر قياس الأداء
تدعم أطر عمل متعددة معايير خدمة إدارة التعلم المنهجية. يقدم كل منها إمكانيات مختلفة لقياس الأداء وكفاءة التكلفة.
مجموعة أدوات قياس أداء vLLM
يوفر مشروع vLLM أدوات قياس أداء مدمجة لقياس الإنتاجية وزمن الاستجابة. يدعم هذا الإطار مجموعات بيانات متنوعة تشمل ShareGPT وBurstGPT وبيانات عشوائية اصطناعية مُولَّدة من مُجزِّئات النماذج.
تشمل معايير الأداء الرئيسية لـ vLLM حدود التزامن القصوى، ومعدلات الطلبات، واختيار مجموعة البيانات. ضبط حد التزامن الأقصى على 10 يعني أن الخادم يعالج ما يصل إلى 10 طلبات في وقت واحد، ويضع الطلبات الإضافية في قائمة الانتظار حتى تتوفر سعة كافية.
أظهرت معايير الأداء لإصدار vLLM-ascend v0.7.3 أداءً متميزًا مع نموذجي Qwen2.5-7B-Instruct و Qwen2.5-VL-7B-Instruct بمعدلات QPS تبلغ 1 و 4 و 16 وما لا نهاية (غير محدود). استُخدم في الاختبار 200 مُدخل مُختار عشوائيًا من مجموعتي بيانات ShareGPT و vision-arena مع بذور عشوائية ثابتة لضمان إمكانية تكرار النتائج.
دليل ماجستير القانون لتقييم أداء الإنتاج
يختص برنامج GuideLLM من مشروع vLLM بتقييم الاستدلال في العالم الحقيقي. وهو يحاكي أنماط حركة مرور مختلفة من خلال ملفات تعريف الحمل القابلة للتكوين.
يدعم اختبار التحميل القائم على معدل الطلبات معدلات طلبات ثابتة. يوفر تشغيل الاختبار بمعدل 10 طلبات في الثانية لمدة 20 ثانية باستخدام بيانات اصطناعية مكونة من 128 رمزًا للاستجابة و256 رمزًا للإخراج قياسات أساسية للإنتاجية. تحسب الأداة توزيعات مئوية شاملة، بما في ذلك النسب المئوية 0.1، 1، 5، 10، 25، 50، 75، 90، 95، 99، و99.9 لكل مقياس.
تُعدّ أنماط الأحمال مهمة لأن التطبيقات المختلفة تُولّد أشكالاً مختلفة من حركة البيانات. يكشف اختبار الانفجار عن سلوك النظام تحت تأثير ارتفاعات مفاجئة في الأحمال، بينما يقيس الاختبار المستمر أداء النظام في حالة الاستقرار.
معايير استدلال MLPerf
يمثل اختبار MLPerf Inference المعيار الصناعي المعتمد. تغطي مجموعة الاختبارات المعيارية سيناريوهات مراكز البيانات والأجهزة المحمولة مع أحمال عمل موحدة عبر مجالات معالجة الرؤية والكلام واللغة.
في سيناريوهات مراكز البيانات، يقيس MLPerf عدد الاستعلامات في الثانية الواحدة ضمن قيود زمن استجابة محددة. أما معايير سيناريوهات الخوادم فتستخدم أنماط استعلام موزعة وفقًا لتوزيع بواسون مع أهداف زمن استجابة عند النسبة المئوية 99. بينما تعمل سيناريوهات عدم الاتصال على زيادة الإنتاجية إلى أقصى حد دون قيود على زمن الاستجابة.
أضاف الإصدار 5.1 من MLPerf Inference معيار Llama3.1-8B الذي يدعم سياق 128,000 رمز. يعكس هذا المعيار متطلبات المؤسسات الحديثة لمهام فهم السياق الطويل وتوليده.
المفاضلات بين تكلفة وحدة معالجة الرسومات وأدائها
يؤثر اختيار المكونات المادية بشكل كبير على كل من الأداء وكفاءة التكلفة. تكشف الأبحاث المتعلقة بكفاءة التكلفة في إدارة دورة حياة البرمجيات باستخدام وحدات معالجة رسومية غير متجانسة أن أنواع وحدات المعالجة الرسومية المختلفة تتوافق مع خصائص أحمال العمل المختلفة.
| نوع وحدة معالجة الرسومات | ذروة FP16 FLOPS | عرض نطاق الذاكرة | حد الذاكرة | السعر بالساعة |
|---|---|---|---|---|
| A6000 | 91 تيرافلوب | 768 جيجابايت/ثانية | 48 جيجابايت | $0.83 |
| A40 | 150 تيرافلوب | 696 جيجابايت/ثانية | 48 جيجابايت | $0.55 |
| L40 | 181 تيرافلوب | 864 جيجابايت/ثانية | 48 جيجابايت | $1.15 |
غالبًا ما يكون عرض نطاق الذاكرة أهم من سعة الحوسبة في استدلال نماذج التعلم الخطي. وتعتمد عملية توليد الرموز على الذاكرة، حيث يتم تحميل أوزان النموذج بشكل متكرر من ذاكرة وحدة معالجة الرسومات. يبلغ عرض نطاق الذاكرة في جهاز A6000 768 جيجابايت/ثانية، وهو أقل من جهاز L40 (864 جيجابايت/ثانية) وأقل بكثير من جهازي H100 أو A100 (2-3 تيرابايت/ثانية).
تعمل عمليات نشر وحدات معالجة الرسومات غير المتجانسة على تحسين كفاءة التكلفة من خلال مطابقة قدرات وحدة معالجة الرسومات مع خصائص الطلب. يتم توجيه الطلبات كثيفة الحساب إلى وحدات معالجة الرسومات ذات القدرة العالية على معالجة البيانات (FLOPS)، بينما تفضل الطلبات كثيفة الذاكرة خيارات النطاق الترددي العالي. يُحسّن هذا النهج استخدام الموارد عبر أنماط الطلبات المتنوعة.
حجم النموذج ومتطلبات الأجهزة
يُحدد عدد المعاملات بشكل مباشر الحد الأدنى لمتطلبات الذاكرة. تتطلب دقة FP16 حوالي 2 بايت لكل معامل، بينما يقلل التكميم ذو 4 بت هذا إلى حوالي 0.5 بايت لكل معامل.

تتفاوت خيارات وحدات معالجة الرسومات السحابية بشكل كبير من حيث الإمكانيات والتكلفة. تدعم مثيلات AWS g4dn.xlarge أحمال العمل الأساسية باستخدام وحدات معالجة رسومات من الفئة الاستهلاكية. بينما توفر مثيلات AWS g5.xlarge أداءً أفضل للنماذج التي تتراوح أحجامها بين 7 و8 مليارات. أما النماذج الأكبر حجمًا فتتطلب تكوينات متعددة لوحدات معالجة الرسومات أو مثيلات متخصصة ذات ذاكرة عالية.
تحسين الكفاءة من حيث التكلفة
يتطلب تحسين التكاليف موازنة عوامل متعددة في آن واحد. وتستلزم المفاضلات بين الأداء والجودة والتكلفة قياسًا وتكرارًا منهجيين.
تأثير الكميات
يقلل التكميم ذو 4 بتات من متطلبات الذاكرة ويزيد من الإنتاجية مع أدنى حد من تدهور الجودة. تتحمل معظم التطبيقات التكميم دون فقدان ملحوظ في الأداء. يقلل التكميم ذو 4 بتات من متطلبات الذاكرة بمقدار 75% تقريبًا مقارنةً بدقة FP16 مع الحفاظ على تحسينات الإنتاجية.
توفر تقنية التكميم 8 بت حلاً وسطاً، إذ تحافظ على جودة أفضل مع توفير معتدل في الذاكرة. بالنسبة للتطبيقات التي تتطلب جودة عالية، تُعدّ تقنية 8 بت خياراً أكثر أماناً من تقنية التكميم 4 بت ذات الأداء العالي.
ضبط حجم الدفعة
يؤدي استخدام دفعات أكبر إلى تحسين استغلال وحدة معالجة الرسومات وزيادة الإنتاجية. فمعالجة 32 طلبًا في وقت واحد تحقق كفاءة أفضل للأجهزة مقارنةً بمعالجتها بالتتابع. مع ذلك، فإن الدفعات الأكبر تزيد من زمن استجابة الطلبات الفردية.
تعمل خاصية التجميع الديناميكي على تحسين هذه المفاضلة من خلال تجميع الطلبات التي تصل خلال فترة زمنية محددة. وعندما تصل الطلبات بشكل متقطع، تحافظ أحجام الدفعات الفعالة الأصغر على زمن استجابة منخفض. أما خلال فترات ذروة التحميل، فتعمل خاصية التجميع التلقائي على زيادة الإنتاجية إلى أقصى حد.
استراتيجيات توجيه الطلبات
يُحسّن التوجيه الذكي للطلبات إلى أنواع وحدات معالجة الرسومات المختلفة من كفاءة التكلفة. تُوجّه الطلبات القصيرة ذات أحجام الدفعات الصغيرة إلى وحدات معالجة الرسومات المُحسّنة للحوسبة. بينما تتطلب الطلبات ذات السياق الطويل وصولاً كبيراً إلى الذاكرة، ما يستدعي استخدام أجهزة مُحسّنة لعرض النطاق الترددي.
يساهم توزيع الأحمال بين النسخ المتماثلة في منع النقاط الساخنة وتحسين الاستخدام العام. يعمل التوجيه بالتناوب الدوري مع أحمال العمل المتجانسة، لكن التوجيه المُراعي للطلبات يُحقق نتائج أفضل مع أنماط الطلبات المتنوعة.
إنشاء حاسبة التكلفة الإجمالية للملكية
يتطلب تقدير التكاليف بدقة محاسبة منهجية لجميع مكونات النفقات. تحتاج المؤسسات إلى معرفة التكاليف الفعلية لكل طلب لاتخاذ قرارات نشر مدروسة.
تنقسم تكاليف الأجهزة إلى تكلفة الشراء وتكلفة الاستهلاك. خادم مزود بـ 8 وحدات معالجة رسومية (GPU) بسعر $320,000 مع فترة استهلاك مدتها 4 سنوات، يكلف $80,000 سنويًا أو ما يقارب $9.13 في الساعة بافتراض التشغيل على مدار الساعة طوال أيام الأسبوع.
تشمل المصاريف التشغيلية رسوم الاستضافة، واستهلاك الطاقة، والصيانة. تُسهّل عمليات النشر السحابية هذه الحسابات، حيث تشمل تكاليف الخوادم بالساعة معظم المصاريف التشغيلية. أما عمليات النشر ذاتية الاستضافة فتتطلب تتبعًا منفصلاً لتكاليف المنشأة، والطاقة بأسعار نموذجية تتراوح بين 0.10 و0.15 لكل كيلوواط ساعة، بالإضافة إلى النفقات الإدارية.
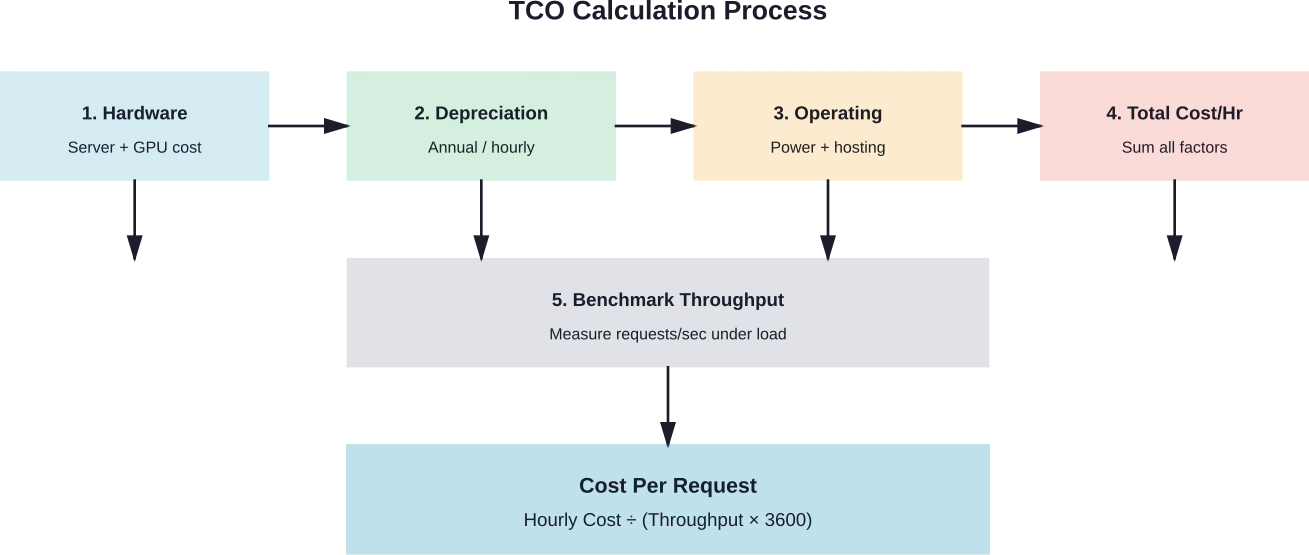
تجمع صيغة حساب تكلفة الطلب الواحد بين التكاليف بالساعة والإنتاجية المقاسة:
تكلفة الطلب الواحد = التكلفة بالساعة ÷ (عدد الطلبات في الثانية × 3600)
بالنسبة لعملية نشر تكلفتها $10 في الساعة وتخدم 50 طلبًا في الثانية، فإن تكلفة الطلب الواحد تساوي $0.0000556 أو ما يقرب من $0.056 لكل 1000 طلب.

خفض تكاليف خدمة ماجستير القانون من خلال هندسة النماذج الأكثر ذكاءً
غالباً ما تركز معايير الأداء على الرموز ووحدات معالجة الرسومات وأسعار البنية التحتية. لكن الفروقات الحقيقية في التكلفة عادةً ما تنشأ من كيفية تصميم النموذج ونشره. متفوقة الذكاء الاصطناعي يعمل على مستوى الهندسة - بناء نماذج التعلم الآلي المخصصة، وتحسين مسارات التدريب، وهيكلة عمليات النشر بحيث تعمل النماذج بكفاءة في بيئة الإنتاج.
إذا أظهرت معايير الأداء لديك تكاليف خدمة عالية، فقد تكون المشكلة في بنية النظام أو إعداد الاستدلال. تواصل مع متفوقة الذكاء الاصطناعي لمراجعة نظام إدارة التعلم الخاص بك وتحديد الطرق العملية لتقليل تكاليف الخدمة.
سير عمل القياس المعياري العملي
تتبع عملية المقارنة المعيارية المنهجية عملية قابلة للتكرار. ويضمن البدء بأحمال عمل تمثيلية أن تعكس القياسات ظروف الإنتاج.
اختيار مجموعة البيانات
يُقدّم ShareGPT أنماط محادثات واقعية مع أطوال مُختلفة للمُطالبات ومتطلبات استجابة مُتنوعة. تحتوي مجموعة البيانات على تفاعلات مُستخدمين حقيقية، مما يجعلها قيّمة للاختبارات المُشابهة للإنتاج. يضمن أخذ عينة عشوائية من 200 إلى 500 مُطالبة باستخدام بذرة عشوائية ثابتة نتائج قابلة للتكرار.
تتيح مجموعات البيانات الاصطناعية إجراء اختبارات مضبوطة لسيناريوهات محددة. ويؤدي توليد الرموز العشوائي إلى إنشاء مطالبات ذات توزيعات أطوال محددة مسبقًا. ويختبر هذا النهج حالات استثنائية مثل أقصى طول للسياق أو أنماط الرموز غير المألوفة.
تحميل تكوين النمط
يقيس اختبار المعدل الثابت الأداء في حالة الاستقرار. ويحدد التشغيل بمعدل 10 استعلامات في الثانية لمدة 60 ثانية خصائص الإنتاجية الأساسية وزمن الاستجابة. ويحدد رفع المعدلات تدريجيًا الحد الأقصى للحمل المستدام قبل تدهور زمن الاستجابة.
يكشف اختبار الاندفاع عن سلوك النظام في ظل ارتفاعات مفاجئة في حركة البيانات. ويُظهر رفع معدل الاستعلامات من استعلام واحد في الثانية إلى 100 استعلام في الثانية خلال 10 ثوانٍ، وقياس زمن الاستعادة، مرونة النظام. وتتعرض أنظمة الإنتاج بشكل متكرر لأنماط الاندفاع خلال ساعات ذروة الاستخدام.
تحليل النتائج
تكشف توزيعات النسب المئوية عن سلوكيات شاذة تخفيها المتوسطات. فبينما قد يكون زمن الاستجابة عند النسبة المئوية الخمسين مقبولاً، تُظهر قيم النسبة المئوية التاسعة والتسعين أسوأ تجربة للمستخدم. يقوم GuideLLM بحساب النسب المئوية تلقائيًا من 0.1% إلى 99.9% لإجراء تحليل شامل.
يشير انخفاض معدل نقل البيانات تحت ضغط مستمر إلى تنازع الموارد. ويُظهر استقرار معدل نقل البيانات طوال مدة الاختبار قابلية التوسع المناسبة. أما انخفاض معدل نقل البيانات فيشير إلى تسربات في الذاكرة، أو انخفاض الأداء بسبب الحرارة، أو مشاكل نظامية أخرى.
اعتبارات الطاقة والقدرة
يؤثر استهلاك الطاقة بشكل مباشر على تكاليف التشغيل والاستدامة البيئية. وتؤكد أبحاث TokenPowerBench أن استهلاك الطاقة في عملية الاستدلال يتجاوز تكاليف التدريب بعشرة أضعاف أو أكثر في أنظمة الإنتاج التي تعالج مليارات الاستعلامات يوميًا.
تُظهر بيانات ML.ENERGY المعيارية أن الطاقة أصبحت مورداً بالغ الأهمية يُمثل عائقاً رئيسياً. فالحصول على بنية تحتية كافية للطاقة لتشغيل أساطيل وحدات معالجة الرسومات (GPU) يكلف أكثر ويستغرق وقتاً أطول من شراء الأجهزة في العديد من المناطق.
يُتيح قياس استهلاك الطاقة أثناء الاختبارات المعيارية معرفة التكاليف. يتراوح استهلاك الطاقة النموذجي لوحدات معالجة الرسومات من 250 واط للبطاقات المُحسّنة لكفاءة الطاقة إلى 700 واط للمُسرّعات عالية الأداء. وبسعر $0.12 لكل كيلوواط ساعة، تُكلّف وحدة معالجة رسومات بقدرة 400 واط حوالي $0.048 في الساعة من الكهرباء فقط.
بضرب تكاليف الطاقة في عدد وحدات معالجة الرسومات (GPU) وإضافة تكاليف التشغيل، نحصل على إجمالي نفقات الطاقة. بالنسبة لخادم مزود بـ 8 وحدات معالجة رسومات يستهلك 3200 واط بالإضافة إلى تكاليف التشغيل، تتراوح تكاليف الطاقة بين 0.40 و0.50 دولارًا أمريكيًا في الساعة، وذلك حسب أسعار الكهرباء المحلية وكفاءة التبريد.
الأسئلة الشائعة
ما هو حجم النموذج الأكثر فعالية من حيث التكلفة لنشره في بيئة الإنتاج؟
تُوفر النماذج التي تتراوح معلماتها بين 7 مليارات و14 مليارًا كفاءة عالية من حيث التكلفة لتطبيقات المؤسسات. تُشير أبحاث شركة Fin AI إلى أن تكلفة هذه النماذج تُعادل 0.05 ضعف تكلفة نماذج GPT-4 تقريبًا، مع الحفاظ على جودة مقبولة لمهام مثل دعم العملاء، وتصنيف المحتوى، واستخراج البيانات المنظمة. تُناسب النماذج الأصغر حجمًا (1-3 مليارات) مهام التصنيف البسيطة، بينما يُنصح باستخدام النماذج التي تزيد معلماتها عن 70 مليارًا للتطبيقات التي تتطلب أقصى قدرة على الاستدلال.
كيف يؤثر حجم الدفعة على تكاليف تقديم برنامج الماجستير في القانون؟
يؤدي زيادة حجم الدُفعات إلى تحسين استخدام وحدة معالجة الرسومات (GPU) وتقليل تكلفة الطلب الواحد من خلال معالجة استعلامات متعددة في وقت واحد. عادةً ما يؤدي مضاعفة حجم الدُفعة من 8 إلى 16 إلى زيادة الإنتاجية بمقدار 40-60% دون زيادة مماثلة في تكلفة الأجهزة. مع ذلك، يؤدي حجم الدُفعة إلى زيادة زمن الاستجابة للطلبات الفردية. تعمل استراتيجيات التجميع الديناميكي على تحقيق التوازن بين هذه المفاضلات من خلال تعديل حجم الدُفعة بناءً على الحمل الحالي، مما يزيد الإنتاجية إلى أقصى حد خلال فترات ذروة الطلب مع الحفاظ على زمن استجابة منخفض خلال فترات انخفاض الطلب.
هل ينبغي للمؤسسات استضافة برامج إدارة التعلم ذاتيًا أم استخدام واجهات برمجة التطبيقات التجارية؟
قد يكون استضافة النماذج الصغيرة ذاتيًا خيارًا فعالًا من حيث التكلفة لعمليات النشر واسعة النطاق، حيث تختلف نقطة التعادل بناءً على حجم النموذج وتكوين الأجهزة. ودون هذا الحد، تظل أسعار واجهات برمجة التطبيقات التجارية تنافسية عند احتساب التكاليف التشغيلية. ويمكن لعمليات النشر المستضافة ذاتيًا أن توفر وفورات كبيرة في التكاليف مقارنةً بواجهات برمجة التطبيقات التجارية، وذلك اعتمادًا على حجم النموذج وتكوين النشر. كما ينبغي على المؤسسات مراعاة متطلبات الخبرة الفنية، إذ تتطلب الاستضافة الذاتية إدارة البنية التحتية ومراقبتها وتحسين أدائها، وهي أمور تتولاها واجهات برمجة التطبيقات التجارية تلقائيًا.
ما هي أدوات قياس الأداء التي تعمل بشكل أفضل لقياس أداء خدمة LLM؟
يتفوق GuideLLM في قياس الأداء في بيئات الإنتاج الواقعية بفضل أنماط التحميل القابلة للتخصيص والمقاييس الشاملة. توفر مجموعة أدوات قياس الأداء vLLM تكاملاً ممتازاً للفرق التي تستخدم vLLM بالفعل في عمليات الخدمة. يقدم MLPerf Inference معايير قياس أداء موحدة وموثوقة للمقارنة بين مختلف تكوينات الأجهزة والبرامج. تخدم أدوات قياس الأداء المتعددة أغراضاً مختلفة: MLPerf للمقارنات الموحدة، وGuideLLM لأنماط الإنتاج الواقعية، وأدوات vLLM للاختبار المتكامل مع إطار العمل.
ما مقدار ذاكرة الوصول العشوائي للفيديو (VRAM) المطلوبة لأحجام النماذج المختلفة؟
تتطلب دقة FP16 حوالي 2 بايت لكل مُعامل: تحتاج طرازات 7B إلى 14-16 جيجابايت، وطرازات 13B إلى 26-28 جيجابايت، وطرازات 70B إلى 140 جيجابايت. يقلل التكميم 4 بت المتطلبات بمقدار 75%: تعمل طرازات 7B بذاكرة 6-8 جيجابايت، وطرازات 13B بذاكرة 10-12 جيجابايت، وطرازات 70B بذاكرة 35-40 جيجابايت. أضف 20-30% كحمل إضافي لذاكرة التخزين المؤقت KV وذاكرة التنشيط. يعمل طراز 7B بتكميم 4 بت بسلاسة على وحدات معالجة الرسومات الاستهلاكية المزودة بذاكرة فيديو 8 جيجابايت، بينما تتطلب طرازات 70B وحدات معالجة رسومات احترافية بذاكرة 40 جيجابايت أو أكثر أو تكوينات متعددة وحدات معالجة الرسومات.
ما الذي يسبب تباين زمن الاستجابة في استدلال نموذج اللغة الخطية؟
تُشكّل قيود عرض نطاق الذاكرة عنق الزجاجة الرئيسي في زمن الاستجابة. يؤدي توليد الرموز إلى تحميل أوزان النموذج بشكل متكرر من ذاكرة وحدة معالجة الرسومات، مما يجعل الاستدلال مُقيّدًا بالذاكرة بدلًا من كونه مُقيّدًا بالحساب. يُضيف تراكم الطلبات أثناء الأحمال العالية وقت انتظار متغير. يزداد حجم ذاكرة التخزين المؤقت للقيم المفتاحية مع طول السياق، مما يزيد الضغط على الذاكرة ويُبطئ الرموز اللاحقة. تُظهر الأبحاث حول استدلال نموذج لغة الاستدلال تقلبات كبيرة في الذاكرة تؤثر على الأداء المتسق. يكشف رصد زمن الاستجابة عند النسبة المئوية 99 هذه الاختلافات بشكل أفضل من المقاييس المتوسطة.
كيف تُحسّن عمليات نشر وحدات معالجة الرسومات غير المتجانسة من كفاءة التكلفة؟
تتفوق أنواع وحدات معالجة الرسومات المختلفة في خصائص أحمال العمل المختلفة. تعمل وحدات معالجة الرسومات ذات النطاق الترددي العالي، مثل A6000 (768 جيجابايت/ثانية)، على تحسين توليد الرموز المميزة المرتبطة بالذاكرة، بينما تتفوق وحدات معالجة الرسومات ذات القدرة الحسابية العالية، مثل A40 (150 تيرافلوب)، في العمليات الحسابية المكثفة. تُظهر الأبحاث المنشورة في مؤتمر ICML 2025 أن توجيه الطلبات بناءً على متطلبات الحوسبة والذاكرة يُحسّن الاستخدام عبر أساطيل وحدات معالجة الرسومات غير المتجانسة. يمكن لعمليات نشر وحدات معالجة الرسومات غير المتجانسة تحسين كفاءة التكلفة بشكل كبير مقارنةً بالأساليب المتجانسة من خلال مطابقة خصائص الطلب مع أنواع وحدات معالجة الرسومات المناسبة، بدلاً من الإفراط في تخصيص وحدات معالجة الرسومات من نوع واحد.
خاتمة
توفر معايير خدمة إدارة دورة حياة التطبيقات (LLM) رؤية أساسية للمفاضلات بين الأداء والتكلفة التي تحدد جدوى النشر. وتتخذ المؤسسات التي تقيس بشكل منهجي الإنتاجية وزمن الاستجابة والتكلفة الإجمالية للملكية قرارات مدروسة بشأن الاستضافة الذاتية مقابل واجهات برمجة التطبيقات التجارية، واختيار حجم النموذج، وتوفير الأجهزة.
تُظهر البيانات أنماطًا واضحة. تُحقق النماذج الأصغر حجمًا، التي تتراوح معلماتها بين 7 و14 مليار، وفورات في التكاليف تتراوح بين 95 و991 تيرابايت لكل 3 تيرابايت مقارنةً بالنماذج التجارية الرائدة، مع الحفاظ على جودة مقبولة للعديد من تطبيقات المؤسسات. وتعتمد فعالية الاستضافة الذاتية من حيث التكلفة على حجم الرموز اليومية، وتكاليف الأجهزة، والنفقات التشغيلية الخاصة بكل مؤسسة. ويُقلل التكميم ذو 4 بتات من متطلبات الذاكرة بمقدار 751 تيرابايت لكل 3 تيرابايت مع تأثير طفيف على الجودة.
لكن الأهم من ذلك كله هو أن قياس الأداء ليس نشاطًا لمرة واحدة. تتغير خصائص الأداء مع تحديثات النماذج، وتحسينات إطار العمل، وتطور أنماط أحمال العمل. تحافظ المؤسسات التي تُنشئ مسارات عمل مستمرة لقياس الأداء على كفاءة التكلفة مع توسع نطاق تطبيقات الذكاء الاصطناعي لديها.
ابدأ بأحمال عمل نموذجية من حركة مرور الإنتاج. قِس الأداء بشكل شامل من حيث الإنتاجية، ونسب زمن الاستجابة، واستخدام الموارد. احسب التكلفة الإجمالية الحقيقية للملكية، بما في ذلك استهلاك الأجهزة، واستهلاك الطاقة، والتكاليف التشغيلية. اختبر تكوينات نشر متعددة لتحديد التوازن الأمثل بين التكلفة والأداء لحالات استخدام محددة.
الأدوات متوفرة - مثل MLPerf وvLLM وGuideLLM وغيرها - التي توفر إمكانيات قياس أداء قوية. وقد أثبتت هذه المنهجيات فعاليتها من خلال اعتمادها في القطاع الصناعي والبحوث الأكاديمية. يبقى فقط تطبيق هذه الأطر بشكل منهجي بما يتناسب مع المتطلبات والقيود الفريدة لكل مؤسسة. قارن الأداء بدقة، وحسّن باستمرار، وشاهد كيف تصبح تكاليف خدمات إدارة التعلم مستدامة على نطاق واسع.