ملخص: تتراوح تكلفة تدريب نموذج لغوي ضخم مثل GPT-4 بين 1.78 و1.92 مليون دولار، حيث تمثل البنية التحتية للحوسبة ما بين 60 و70.3 تريليون دولار من النفقات. وتشمل هذه التكاليف مجموعات وحدات معالجة الرسومات (GPU)، واستهلاك الكهرباء، وإعداد البيانات، والكفاءات الهندسية. ويمكن لضبط النماذج الحالية بدقة أن يقلل النفقات بما يتراوح بين 60 و90.3 تريليون دولار مقارنةً بالتدريب من الصفر.
لقد حوّلت نماذج اللغة الضخمة الذكاء الاصطناعي من مجرد مجال بحثي إلى قوة تجارية هائلة. لكن ما يغيب عن بال معظم الناس هو أن تكلفة إنشاء هذه الأنظمة تضاهي تكلفة إطلاق الأقمار الصناعية إلى الفضاء.
بحسب تقرير مؤشر ستانفورد للذكاء الاصطناعي لعام 2025، بلغت تكلفة تدريب نموذج GPT-4 ما بين $78 و100 مليون دولار. أما مع Gemini Ultra 1.0، فقد ارتفعت التكلفة إلى $192 مليون دولار. وهذا يمثل زيادة قدرها 287 ألف ضعف مقارنةً بتكلفة تدريب نموذج Transformer في عام 2017، والتي بلغت $670 مليون دولار.
لا تقتصر الجوانب الاقتصادية الكامنة وراء هذه الأرقام على مجرد فضول أكاديمي. فالمنظمات التي تُقيّم جدوى بناء نماذج مخصصة أو ترخيص النماذج الحالية تحتاج إلى بيانات ملموسة. كما تحتاج فرق البحث التي تسعى للحصول على التمويل إلى توقعات واقعية للميزانية. ويحتاج مراقبو الصناعة الذين يتابعون تطور الذكاء الاصطناعي إلى سياق لفهم ديناميكيات السوق.
يتناول هذا التحليل بالتفصيل أين يذهب كل دولار عند تدريب نماذج اللغة الرائدة، ولماذا تتصاعد التكاليف بشكل كبير، وما هي الاستراتيجيات التي تقلل النفقات بالفعل دون التضحية بالأداء.
تشريح تكاليف التدريب في برنامج الماجستير في القانون
لا تنحصر تكاليف التدريب في بند واحد، بل تتراكم فئات نفقات متعددة لتصل إلى تلك المبالغ الإجمالية التي تتراوح بين ثمانية وتسعة أرقام.
تستحوذ البنية التحتية للحوسبة على الجزء الأكبر من الميزانية. يتقاضى مزودو الخدمات السحابية رسومًا مقابل استخدام وحدات معالجة الرسومات (GPU) بالساعة، وتمتد عمليات التدريب لأسابيع أو شهور. وتشير التقارير إلى أن شركة OpenAI أنفقت أكثر من 1 تريليون و4 تريليونات دولار على تدريب GPT-4، مع تخصيص جزء كبير منها لتكاليف الحوسبة السحابية.
تتزايد تكاليف الأجهزة مع تعقيد النموذج. تتطلب النماذج الأكبر حجمًا معالجات تسريع أكثر كفاءة، وعددًا أكبر منها. ولا يُعدّ الفرق بين تدريب نموذج يحتوي على 20 مليار مُعامل ونموذج يحتوي على 120 مليار مُعامل فرقًا خطيًا. تزداد متطلبات الحوسبة بشكلٍ كبير مع ازدياد عدد المُعاملات.
لكن انتظر. تكاليف الأجهزة لا تكشف إلا جزءًا من الحقيقة.
المضاعفات الخفية
يُشكّل استهلاك الكهرباء نفقات مستمرة تُقلّل العديد من الميزانيات الأولية من تقديرها. وقد أعلنت شركة أنثروبيك في فبراير 2026 عن التزامها بتغطية ارتفاع أسعار الكهرباء لمراكز بياناتها، ما يُبرز مدى جدية مختبرات الذكاء الاصطناعي الكبرى في التعامل مع هذه المسألة. وأشارت إلى أن تدريب نموذج ذكاء اصطناعي رائد واحد سيتطلب قريباً جيجاوات من الطاقة، وهو ما يُعدّ اعترافاً بالعبء الذي تُشكّله هذه الأنظمة على البنية التحتية.
يُضيف إعداد البيانات وتخزينها طبقةً أخرى من العمل. تحتوي مجموعات بيانات التدريب لنماذج مثل GPT-4 على مئات المليارات من الرموز المُستقاة من الكتب والمواقع الإلكترونية والأوراق الأكاديمية والمجموعات المتخصصة. ويتطلب الحصول على هذه البيانات وتنظيفها وتصفيتها وتخزينها فرقًا متخصصة وبنية تحتية مُجهزة.
تُقدّر الكفاءات الهندسية بأجور مجزية. ويُعاني الباحثون في مجال التعلّم الآلي ومهندسو البنية التحتية القادرون على إدارة عمليات التدريب عبر آلاف وحدات معالجة الرسومات من نقص حاد. وتشكل رواتبهم ومكافآتهم وحصصهم في الشركة جزءاً كبيراً من إجمالي تكاليف المشروع.
تؤدي التكرارات التجريبية إلى زيادة النفقات الأساسية بشكل كبير. ويتطلب إيجاد المعلمات الفائقة المثلى - معدلات التعلم، وأحجام الدفعات، والاختلافات المعمارية - إجراء عمليات تدريب متعددة. كل تجربة فاشلة تستنزف ساعات من موارد وحدة معالجة الرسومات دون إنتاج النموذج النهائي.

البنية التحتية لوحدات معالجة الرسومات: التكلفة المهيمنة
تُشكّل وحدات معالجة الرسومات العمود الفقري لتدريب الذكاء الاصطناعي الحديث. وتتفوق هذه الرقائق المتخصصة في عمليات المصفوفات المتوازية التي تتطلبها الشبكات العصبية.
تهيمن شركة NVIDIA على السوق، حيث تُشغّل معالجاتها H100 وA100 معظم عمليات التدريب واسعة النطاق. ويتقاضى مزودو الخدمات السحابية ما يقارب $2-4 دولارات لكل ساعة تشغيل لوحدة معالجة الرسومات H100. وقد يتطلب تدريب نموذج تجريبي تشغيل ما بين 10000 و25000 وحدة معالجة رسومات لعدة أسابيع.
سرعان ما تصبح الحسابات معقدة للغاية. فبسعر $3 لكل ساعة معالجة رسومية، تبلغ تكلفة تشغيل 15000 وحدة معالجة رسومية لمدة 30 يومًا متواصلة $32.4 مليون - وذلك فقط لوقت المعالجة. هذا قبل احتساب تكاليف التخزين أو الشبكات أو أي مكونات أخرى للبنية التحتية.
يؤدي شراء الأجهزة بشكل مباشر إلى تغيير هيكل التكاليف. فبينما تكون النفقات الرأسمالية الأولية أعلى، فإن تجنب تكاليف الحوسبة السحابية المتكررة يمكن أن يقلل الإنفاق الإجمالي بمرور الوقت. وغالبًا ما تجد المؤسسات التي تخطط لجلسات تدريب متعددة أو عمليات تحسين مستمرة أن التملك أكثر اقتصادية من الاستئجار.
مشكلة وقت الخمول
لكن الأمر هو أن وحدات معالجة الرسومات ليست منتجة في كل لحظة يتم تشغيلها فيها. فاختناقات تحميل البيانات، وحفظ نقاط التحقق، وفترات التوقف لتصحيح الأخطاء تخلق فترات خمول حيث تبقى الأجهزة باهظة الثمن غير مستخدمة ولكنها لا تزال تتكبد تكاليف.
أظهرت دراسة منشورة على موقع arXiv، تناولت أطر تدريب نماذج التعلم الآلي الفعالة، أنه على الرغم من استهلاك وحدات معالجة الرسومات (GPUs) لكامل طاقتها، إلا أنها غالبًا ما تعمل بمعدلات استخدام دون المستوى الأمثل تتراوح بين 30% و50% خلال التدريب المسبق القياسي. ويعود هذا القصور إلى كيفية تفاعل بنية المحولات مع إمكانيات الأجهزة.
توجد حلول. يمكن لأطر التدريب المُحسّنة أن تُحسّن استخدام وحدة معالجة الرسومات (GPU) من خلال تبسيط مسارات البيانات، ودمج العمليات الحسابية مع الاتصالات، وتقليل عبء المزامنة. هذه التحسينات لا تُسرّع التدريب فحسب، بل تُقلّل بشكل مباشر من إجمالي ساعات استخدام وحدة معالجة الرسومات المطلوبة.
| نوع الجهاز | تكلفة الحوسبة السحابية بالساعة | سعر الشراء | نقطة التعادل |
|---|---|---|---|
| إنفيديا إتش 100 | $2.50-$4.00 | $30,000-$40,000 | 10000-16000 ساعة |
| إنفيديا A100 | $1.50-$2.50 | $10,000-$15,000 | 6000-10000 ساعة |
| إنفيديا إتش 200 | $3.50-$5.00 | $40,000-$50,000 | 11000-14000 ساعة |
تكاليف الطاقة: مصدر قلق متزايد
تُضاهي فواتير الكهرباء اللازمة لجلسات التدريب تكاليف الأجهزة نفسها. تستهلك نماذج فرونتير جيجاوات ساعة من الطاقة، وهو ما يكفي لتزويد آلاف المنازل بالكهرباء لأشهر.
أصبحت كفاءة الطاقة محورًا رئيسيًا للبحث العلمي. وقد ركزت دراسة منشورة على موقع arXiv، تتناول تحسين استهلاك الطاقة في التطبيقات القائمة على نموذج التعلم الخطي، على استهلاك الطاقة كمقياس رئيسي للكفاءة إلى جانب مقاييس الأداء التقليدية. وأظهرت التجارب التي أُجريت على أجهزة NVIDIA RTX 8000 أن الأساليب المُحسَّنة تحقق دقة مماثلة للأساليب الأساسية مع تقليل استهلاك الطاقة بمقدار يتراوح بين 23 و50%.
بصراحة، لا تقتصر تكاليف الطاقة على فاتورة الكهرباء المباشرة فقط. فالبنية التحتية اللازمة لتوفير جيجاوات من الطاقة تتطلب محطات فرعية وأنظمة تبريد ومولدات احتياطية. ويأخذ مشغلو مراكز البيانات هذه الاستثمارات الرأسمالية في الحسبان عند تحديد أسعارهم.
مع ازدياد متطلبات التدريب، تصبح البنية التحتية للطاقة عائقاً تنافسياً. وتكتسب المنظمات التي تتمتع بإمكانية الوصول إلى كهرباء موثوقة ومنخفضة التكلفة مزايا كبيرة في اقتصاديات التدريب.
التدريب من الصفر مقابل التحسين التدريجي
لا يتطلب كل مشروع بناء نموذج من الصفر. يوفر ضبط النماذج المدربة مسبقًا بديلاً فعالاً من حيث التكلفة للعديد من التطبيقات.
يتغير الوضع الاقتصادي بشكل جذري. قد تتراوح تكلفة ضبط نموذج مثل Llama 2 أو GPT-3.5 على بيانات خاصة بمجال معين بين 1000 و50000 دولار أمريكي، وذلك حسب حجم مجموعة البيانات ومتطلبات الحوسبة. وهذا أرخص بألف إلى عشرة آلاف مرة من تدريب نموذج مماثل من الصفر.
أظهرت دراسة منشورة على موقع arXiv، تناولت استراتيجيات فعّالة لتحسين نماذج التعلم الخطي، أن الضبط الدقيق باستخدام تقنيات مثل LoRA (التكيف منخفض الرتبة) يُمكن تنفيذه على أجهزة ذات مواصفات متواضعة. في إحدى التجارب، طُبّق تدريب LoRA على نموذج مُكمّم مسبقًا بدقة 4 بت باستخدام وحدة معالجة رسومية NVIDIA T4 واحدة بذاكرة وصول عشوائي للفيديو (VRAM) سعتها 16 جيجابايت، واكتملت العملية في غضون 7 ساعات.
لكن عملية الضبط الدقيق لها قيودها. فالنماذج المدربة مسبقًا تحمل تحيزات وثغرات معرفية متأصلة من بيانات التدريب الأصلية. يُعدّل الضبط الدقيق سلوك النموذج لمهام محددة، لكنه لا يُغيّر جوهريًا المعرفة أو القدرات الأساسية للنموذج.
متى يكون التدريب من الصفر منطقياً؟
تسعى المؤسسات إلى توفير تدريب شامل لعدة أسباب. فمجموعات البيانات الخاصة التي لا يمكن مشاركتها مع مزودي نماذج من جهات خارجية تستلزم تدريبًا داخليًا. كما تستفيد المجالات المتخصصة التي تعاني فيها النماذج الحالية من ضعف الأداء من بنى مخصصة يتم تدريبها على مجموعات بيانات ذات صلة من الصفر.
يدفع التميّز التنافسي بعض القرارات. فالشركات التي تبني منتجات تعتمد على الذكاء الاصطناعي بشكل أساسي تريد نماذج لا يستطيع المنافسون ببساطة تقليدها من خلال تحسين البدائل المتاحة للجمهور.
يُعد التحكم في سلوك النموذج أمرًا بالغ الأهمية. يوفر التدريب من الصفر رؤية كاملة لمصادر البيانات وإجراءات التدريب وخصائص النموذج، وهو أمر بالغ الأهمية للصناعات الخاضعة للتنظيم أو التطبيقات الحساسة للسلامة.


قدّر تكلفة تدريبك في برنامج الماجستير في القانون
يتضمن تدريب نماذج اللغة الكبيرة (LLMs) تنظيم البيانات، والبنية التحتية، وميزانية الحوسبة، والتجريب، والتقييم. متفوقة الذكاء الاصطناعي يُراجع فريق الدعم الفني مجموعة البيانات والأهداف ومعايير الأداء قبل تقدير الموارد والوقت اللازمين. ويشمل تفصيل التكاليف المعالجة المسبقة، ودورات التدريب، والضبط الدقيق، والتحقق. وهذا يُتيح لك التخطيط المسبق للإنفاق على الحوسبة والجهد الهندسي.
هل أنت مستعد لحساب استثمارك في التدريب للحصول على درجة الماجستير في القانون؟
تحدث مع الذكاء الاصطناعي المتفوق على:
- قم بتقييم مجموعة البيانات الخاصة بك وأهدافك
- تحديد استراتيجية التدريب واحتياجات الحوسبة
- الحصول على تقدير منظم لتكاليف التدريب على برنامج الماجستير في القانون
👉 اطلب عرض أسعار تدريب ماجستير القانون من شركة AI Superior.
أمثلة واقعية للتكاليف
توفر النماذج المحددة نقاط مرجعية ملموسة لفهم اقتصاديات التدريب.
بلغت تكلفة تدريب GPT-4 ما يقدر بنحو $78-100 مليون دولار وفقًا لصحيفة وول ستريت جورنال وتقرير مؤشر الذكاء الاصطناعي لجامعة ستانفورد لعام 2025. ويشمل هذا الرقم البنية التحتية للحوسبة والكهرباء واكتساب البيانات والموارد الهندسية طوال فترة التدريب بأكملها.
أدى مشروع Gemini Ultra 1.0 إلى ارتفاع التكاليف إلى ما يقرب من $192 مليون دولار وفقًا لتقرير مؤشر ستانفورد للذكاء الاصطناعي لعام 2025. وتعكس هذه الزيادة في النفقات نطاقًا أوسع، وفترة تدريب أطول، أو تجارب أكثر شمولاً أثناء التطوير.
استغرق تدريب GPT-40 ما يقارب 1 تريليون إلى 100 مليون. تشترك هذه النماذج الرائدة من المختبرات الكبرى في هياكل تكلفة مماثلة - ميزانيات تتراوح بين ثمانية وتسعة أرقام يهيمن عليها حساب وحدة معالجة الرسومات واستهلاك الطاقة.
تواجه المؤسسات الصغيرة تحديات اقتصادية مختلفة. قد تتراوح تكلفة تدريب نموذج يحتوي على 7 مليارات مُعامل بين 1.50 و1.200 ألف دولار، وذلك بحسب توفر الأجهزة وكفاءتها. أما نموذج يحتوي على 20 مليار مُعامل، فقد تتراوح تكلفته بين 1.50 و1.2 مليون دولار. تبقى هذه الأرقام مرتفعة، لكنها في متناول الشركات الناشئة ذات التمويل الجيد أو فرق البحث في المؤسسات الكبرى.
مسار تضخم الأسعار
ارتفعت تكاليف التدريب بشكل هائل. وقد وثّق تقرير مؤشر ستانفورد للذكاء الاصطناعي لعام 2025 زيادة قدرها 287,000 ضعف من عام 2017 حتى الآن - من $670 لنماذج Transformer المبكرة إلى تسعة أرقام للأنظمة الرائدة الحالية.
لا يبدو أن هذا الاتجاه سيتغير. تستمر النماذج في النمو من حيث عدد المعلمات، وحجم بيانات التدريب، وتعقيد البنية. ويتطلب كل جيل قدرة حاسوبية أكبر من الجيل السابق.
مع ذلك، فإن تحسينات الكفاءة تعوض جزئياً الزيادات في الحجم. فالخوارزميات الأفضل، والأجهزة المُحسّنة، وتقنيات التدريب المُطوّرة تُتيح استخلاص المزيد من القدرات مقابل كل دولار يُنفق. وقد انخفضت تكلفة وحدة قدرة النموذج فعلياً، حتى مع ارتفاع تكاليف التدريب المطلقة.
استراتيجيات لخفض تكاليف التدريب
يمكن أن تؤدي الأساليب المتعددة إلى خفض النفقات بشكل كبير دون التضحية بجودة النموذج بشكل متناسب.
تُقلل أُطر التدريب الفعّالة من هدر دورات وحدة معالجة الرسومات. وتُحسّن تقنيات مثل تراكم التدرج، والتدريب متعدد الدقة، ومسارات تحميل البيانات المُحسّنة، من استخدام الأجهزة. ووفقًا لتحليل أنظمة التدريب عالية الإنتاجية، فإن معالجة الاستخدام غير الفعّال للموارد الحاسوبية أثناء تدريب المحوّلات يُمكن أن يُقلل بشكل كبير من وقت التدريب واستهلاك الطاقة.
تُقلل تقنيات ضغط النماذج من متطلبات الحوسبة. يُمثل التكميم الأوزان بعدد أقل من البتات، مما يُقلل من عرض نطاق الذاكرة واحتياجات التخزين. يُزيل التقليم الاتصالات الأقل أهمية، مما يُقلص حجم النموذج. ينقل تقطير المعرفة القدرات من النماذج الكبيرة إلى النماذج الأصغر بكفاءة أكبر من التدريب من الصفر.
يساهم التخصيص الذكي للموارد في تجنب دفع تكاليف الأجهزة غير المستخدمة. ويساهم إيقاف مجموعات وحدات معالجة الرسومات تلقائيًا أثناء مراحل إعداد البيانات، وتحديد حجم البنية التحتية ديناميكيًا لكل مرحلة تدريب، وجدولة عمليات التشغيل خلال فترات انخفاض أسعار الكهرباء، في خفض التكاليف الإجمالية.
يُقلل تحسين المعلمات الفائقة من التجارب الفاشلة. وتُتيح استراتيجيات البحث المنهجية إيجاد إعدادات تدريب فعّالة أسرع من الضبط اليدوي. كما أن تقليل عمليات التدريب الضائعة يعني تقليل ساعات استخدام وحدة معالجة الرسومات (GPU) التي تُهدر دون جدوى.
قرار الحوسبة السحابية مقابل الحوسبة المحلية
توفر البنية التحتية السحابية مرونةً وتكاليف أولية منخفضة. يمكنك تشغيل آلاف وحدات معالجة الرسومات (GPUs) لإجراء تدريب، ثم تحريرها عند الانتهاء. يُعد هذا النهج مناسبًا للمؤسسات التي تُجري تجارب دورية أو التي لا تتضح لديها احتياجات الحوسبة على المدى الطويل.
تتطلب الأجهزة المثبتة محليًا استثمارًا رأسماليًا كبيرًا، لكنها تُغني عن رسوم الإيجار المتكررة. ويُظهر تحليل نقطة التعادل عادةً أن امتلاكها يصبح مُجديًا اقتصاديًا بعد 10,000 إلى 16,000 ساعة من استخدام معالجات H100، أو 6,000 إلى 10,000 ساعة لمعالجات A100.
غالباً ما تجد المنظمات التي تخطط لعمليات تدريب كبيرة متعددة، أو عمليات ضبط دقيقة مستمرة، أو خطوط تطوير نماذج طويلة الأجل، أن شراء الأجهزة أكثر اقتصادية على الرغم من ارتفاع التكاليف الأولية.
| استراتيجية خفض التكاليف | الوفورات المحتملة | تعقيد التنفيذ |
|---|---|---|
| أطر تدريب فعالة | 20-40% | واسطة |
| تكميم النموذج | 30-50% | قليل |
| جدولة الموارد الذكية | 15-30% | واسطة |
| الضبط الدقيق مقابل التدريب من الصفر | 60-90% | منخفض (إذا كان الطراز الأساسي يلبي الاحتياجات) |
| الأجهزة الموجودة في الموقع (على المدى الطويل) | 40-60% | عالي |
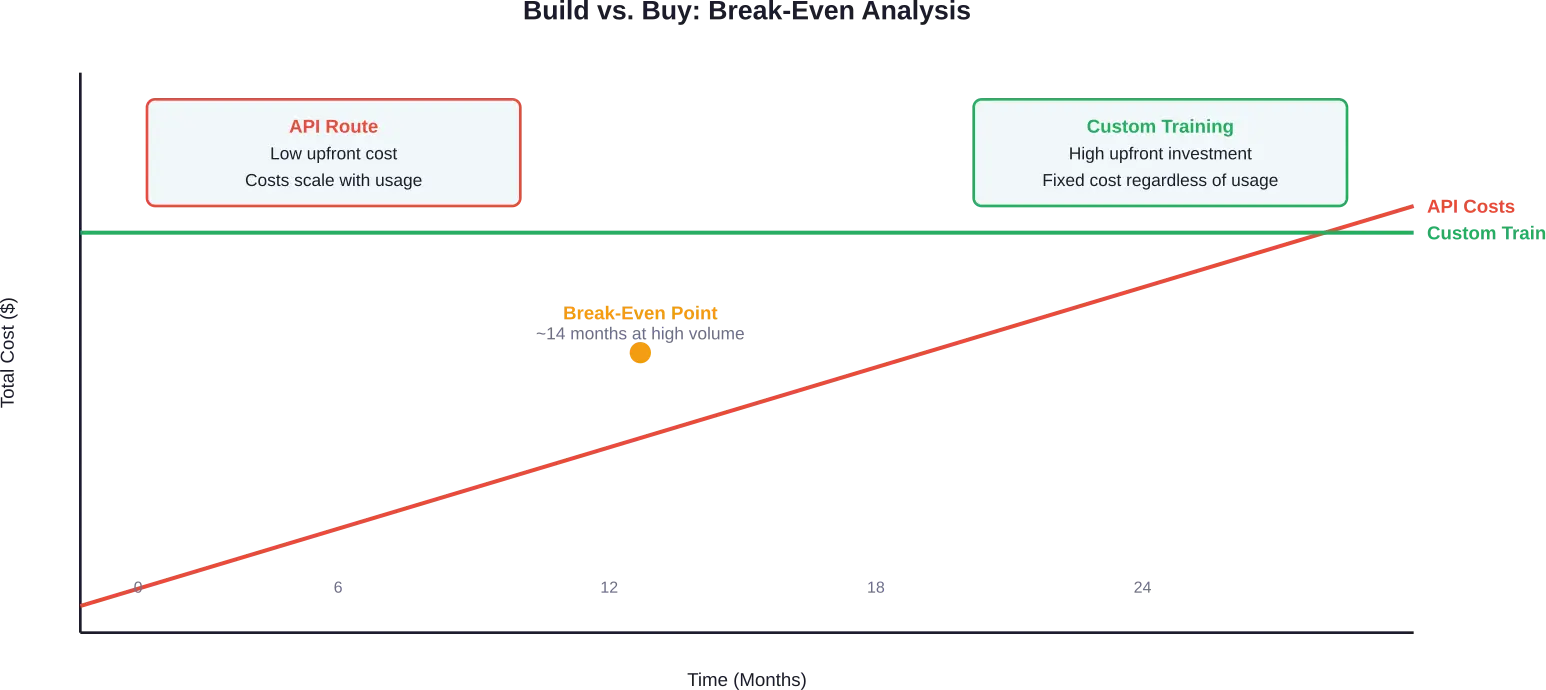
قرار البناء مقابل الشراء
تواجه العديد من المنظمات سؤالاً أساسياً: هل يتم تدريب نموذج مخصص أم ترخيص النماذج الموجودة؟
يبدأ سعر الوصول إلى واجهة برمجة التطبيقات (API) لنماذج مثل GPT-4 من $0.60 لكل مليون رمز إدخال لدى بعض المزودين، بينما يختلف سعر المخرجات باختلاف النموذج. وتقدم منصة Gemini Flash-Lite أسعارًا أقل، حيث تبلغ $0.075 لكل مليون رمز إدخال و$0.30 لكل مليون رمز إخراج، وذلك وفقًا لبيانات التسعير لعام 2025.
يبدو التسعير القائم على الاستخدام اقتصاديًا في البداية، لكن التكاليف تتزايد طرديًا مع حجم البيانات. فالتطبيقات التي تعالج 1.2 مليون رسالة يوميًا بتكلفة 150 رمزًا لكل رسالة، قد تُصدر فواتير شهرية لواجهة برمجة التطبيقات تتراوح بين $15,000 و$60,000، وذلك حسب مستويات التسعير ونسب المدخلات والمخرجات.
عند الأحجام الكبيرة، تصبح البنية التحتية المملوكة أكثر اقتصادية. أظهر تحليل نقطة التعادل لحالة موثقة أن تكاليف واجهة برمجة التطبيقات تصل إلى $60,000 شهريًا وتتجه نحو $500,000+ سنويًا - وهو رقم يبرر استثمارًا كبيرًا في التدريب المسبق.
يعتمد القرار على أنماط الاستخدام، والتخصيص المطلوب، والموقع التنافسي. تميل التطبيقات ذات الاستخدام المتوقع بكميات كبيرة، أو متطلبات المجال المتخصصة، أو الحاجة إلى شفافية النموذج، إلى التدريب المخصص. أما المشاريع ذات الاستخدام المتغير، أو القدرات العامة، أو الجداول الزمنية الضيقة للتطوير، فتميل إلى الوصول عبر واجهة برمجة التطبيقات (API).
اتجاهات التكاليف المستقبلية
ستستمر تكاليف التدريب في التطور مع تغير التكنولوجيا وديناميكيات السوق.
تُساهم التحسينات المستمرة في كفاءة الأجهزة في خفض تكلفة الحساب. وتُظهر أجيال معمارية NVIDIA مكاسب ثابتة في الأداء لكل واط. وسيؤدي دخول المنافسين إلى سوق المعالجات المُسرّعة إلى مزيد من التحسين والمنافسة السعرية.
تُتيح التطورات الخوارزمية استخلاص المزيد من القدرات باستخدام موارد حاسوبية أقل. وتُساهم تقنيات مثل بنى مزيج الخبراء، وآليات الانتباه المتفرق، وخوارزميات التحسين المُحسّنة في تقليل الميزانية الحاسوبية المطلوبة لتحقيق أهداف أداء مُحددة.
من المرجح أن ترتفع تكاليف الطاقة مع ازدياد الضغط الذي تُشكّله البنية التحتية للذكاء الاصطناعي على شبكات الكهرباء. ومع تزايد متطلبات التدريب وازدياد أهمية البنية التحتية للطاقة، ستكتسب المؤسسات التي تتمتع بإمكانية الوصول إلى الطاقة المتجددة منخفضة التكلفة مزايا تنافسية.
قد تؤثر الضغوط التنظيمية على اقتصاديات التدريب. فالحكومات التي تشعر بالقلق إزاء استهلاك الطاقة، أو خصوصية البيانات، أو سلامة الذكاء الاصطناعي، قد تفرض متطلبات تزيد من تكاليف الامتثال أو تقيد ممارسات معينة.
قد تُسهم توجهات الديمقراطية في تقليل العوائق أمام دخول السوق. فنماذج المصادر المفتوحة، ومنصات الحوسبة المشتركة، وتحسين كفاءة التدريب، قد تجعل تطوير النماذج واسعة النطاق في متناول المؤسسات متوسطة الحجم بدلاً من اقتصارها على عمالقة التكنولوجيا.
الأسئلة الشائعة
كم تبلغ تكلفة تدريب GPT-4؟
بلغت تكلفة تدريب GPT-4 ما يقدر بنحو $78-100 مليون دولار وفقًا لصحيفة وول ستريت جورنال وتقرير مؤشر الذكاء الاصطناعي لجامعة ستانفورد لعام 2025. ويشمل هذا الرقم البنية التحتية لوحدة معالجة الرسومات، واستهلاك الكهرباء، وإعداد البيانات، والموارد الهندسية على مدار فترة التدريب التي استمرت عدة أشهر.
لماذا تُعتبر دورات الماجستير في القانون مكلفة للغاية؟
تنشأ تكاليف التدريب بشكل أساسي من البنية التحتية للحوسبة باستخدام وحدات معالجة الرسومات (GPU)، والتي تمثل ما بين 60 و701 تريليون روبية من النفقات. قد يتطلب نموذج رائد ما بين 10000 و25000 وحدة معالجة رسومات متطورة تعمل باستمرار لأسابيع أو شهور. تشمل التكاليف الإضافية استهلاك الكهرباء (جيجاوات-ساعات من الطاقة)، والكفاءات الهندسية، وجمع البيانات وإعدادها، والتكرارات التجريبية لتحسين المعلمات الفائقة.
هل يمكن للتحسين الدقيق أن يقلل من تكاليف تدريب ماجستير القانون؟
عادةً ما تكون تكلفة تحسين النماذج الحالية أقل بمقدار 60-901 تريليون دولار من تكلفة تدريبها من الصفر. وقد تتراوح تكلفة تكييف نموذج مُدرَّب مسبقًا مثل Llama 2 أو GPT-3.5 لمهام محددة بين 1 تريليون دولار و50000 دولار، مقارنةً بتكلفة تتراوح بين 1 تريليون دولار و780000 دولار و192000 دولار لتدريب نموذج جديد. تُمكّن تقنيات مثل LoRA من إجراء التحسين على وحدات معالجة رسومية واحدة، مما يُتيح إنجازه في غضون ساعات بدلاً من أسابيع.
ما الفرق بين تكاليف التدريب السحابي والتدريب المحلي؟
تُفرض رسوم على البنية التحتية السحابية تتراوح بين 1.4 و2.4 تريليون روبية لكل ساعة استخدام لوحدة معالجة الرسومات H100، دون أي استثمار أولي، ولكن مع رسوم تأجير مستمرة. بينما تبلغ تكلفة شراء أجهزة H100 ما بين 30,000 و40,000 روبية للوحدة الواحدة مقدمًا، مع إلغاء رسوم التأجير. ويتحقق التعادل بعد حوالي 10,000 إلى 16,000 ساعة استخدام. غالبًا ما تجد المؤسسات التي تخطط لجلسات تدريب متعددة أن امتلاك هذه الأجهزة أكثر اقتصادية، على الرغم من ارتفاع متطلبات رأس المال الأولية.
ما مقدار الكهرباء التي يستهلكها تدريب طالب ماجستير في القانون؟
تستهلك النماذج الرائدة كميات هائلة من الكهرباء تصل إلى جيجاوات ساعة، تكفي لتزويد آلاف المنازل بالطاقة لأشهر. وسيتطلب تدريب نموذج ذكاء اصطناعي رائد واحد قريبًا قدرة كهربائية هائلة تصل إلى جيجاوات. تمثل تكاليف الكهرباء ما بين 15 و201 تريليون روبية هندية من إجمالي نفقات تدريب النماذج الكبيرة، حيث تساهم فواتير الكهرباء المباشرة والبنية التحتية الداعمة في زيادة هذه التكاليف.
ما هي أرخص طريقة لتدريب نموذج لغوي مخصص؟
يُعدّ تحسين نموذج مفتوح المصدر موجود باستخدام تقنيات فعّالة مثل LoRA الخيار الأمثل من حيث التكلفة. وقد وثّقت الأبحاث تجربة تدريب باستخدام LoRA استغرقت 7 ساعات فقط على وحدة معالجة رسومية NVIDIA T4 واحدة بذاكرة وصول عشوائي للفيديو (VRAM) سعتها 16 جيجابايت، وهي وحدة متوفرة على منصات مثل Google Colab. بالنسبة للتطبيقات التي يوفر فيها التحسين إمكانيات كافية، يُقلّل هذا النهج التكاليف بمقدار 1000 إلى 10000 ضعف مقارنةً بالتدريب من الصفر.
هل ما زالت تكاليف التدريب في ازدياد؟
تستمر تكاليف التدريب المطلقة للنماذج الرائدة في الارتفاع مع تزايد عدد المعلمات وأحجام مجموعات البيانات. وقد وثّق تقرير مؤشر ستانفورد للذكاء الاصطناعي لعام 2025 زيادةً قدرها 287,000 ضعف منذ عام 2017 وحتى الآن. ومع ذلك، فإن تكلفة وحدة قدرة النموذج آخذة في الانخفاض بفضل تحسينات الأجهزة والتطورات الخوارزمية. وتعوض مكاسب الكفاءة جزئيًا الزيادات في الحجم، على الرغم من استمرار ارتفاع الميزانيات الإجمالية للنماذج المتطورة.
فهم الاستثمار
تعكس تكاليف تدريب ماجستير اللغة كثافة الحوسبة اللازمة لإنشاء أنظمة تعالج وتولد اللغة البشرية على نطاق واسع. ولا تُعدّ هذه الأسعار الباهظة، التي تتراوح بين ثمانية وتسعة أرقام، عشوائية، بل تمثل آلاف المعالجات المتخصصة التي تعمل باستمرار، وتستهلك ميغاواط من الطاقة، وتُدار بواسطة فرق من المهندسين المتخصصين الذين يعملون مع مجموعات بيانات ضخمة.
ستستمر الجوانب الاقتصادية في التطور. ستصبح الأجهزة أكثر كفاءة. وستتحسن الخوارزميات. وستحفز المنافسة الابتكار. لكن المقايضة الأساسية تبقى قائمة: القدرة تتطلب الحوسبة، والحوسبة مكلفة.
تحتاج المؤسسات التي تُقيّم جدوى بناء نماذج مخصصة إلى تقديرات واقعية للتكاليف، لا إلى تقديرات طموحة مُنخفضة. ويتعين على الفرق التي تسعى لتأمين التمويل مراعاة جميع فئات النفقات، وليس فقط بنود استئجار وحدات معالجة الرسومات (GPU) الواضحة. كما ينبغي على مراقبي الصناعة الذين يتابعون تطور الذكاء الاصطناعي أن يُدركوا أن تكاليف التدريب تُعد مؤشرًا مفيدًا لحجم النموذج وقدراته.
يعتمد المسار الأمثل على المتطلبات المحددة. فالتطبيقات ذات الأحجام الكبيرة والاحتياجات المتخصصة غالباً ما تبرر التدريب المخصص رغم الاستثمار الأولي الكبير. أما المشاريع ذات الأحجام الأقل أو ذات الأغراض العامة، فتجد أن الوصول إلى واجهة برمجة التطبيقات (API) أكثر اقتصادية. وهناك العديد من حالات الاستخدام التي تقع بين هذين النقيضين، حيث يوفر الضبط الدقيق التوازن الأمثل بين التخصيص وكفاءة التكلفة.
هل أنت مستعد للمضي قدمًا في تطوير النموذج؟ ابدأ بحساب أنماط استخدامك الخاصة، وتحديد القدرات التي تتطلب تدريبًا مخصصًا مقابل القدرات التي تتطلب ضبطًا دقيقًا، وإجراء تحليل نقطة التعادل لحجم النشر المتوقع. ستوضح البيانات المسار الأنسب لحالتك.