Quick Summary: The best LLM analytics platforms for cost and quality tracking in 2026 include Confident AI for evaluation-focused monitoring with usage-based pricing, Langfuse for open-source observability with session tracking, and Datadog LLM Observability for enterprise-scale tracing. MiniMax M2.5 leads as the most cost-efficient model with strong analytical quality, while AgServe frameworks demonstrate how session-aware serving can achieve GPT-4o-equivalent quality at 16.5% of the cost.
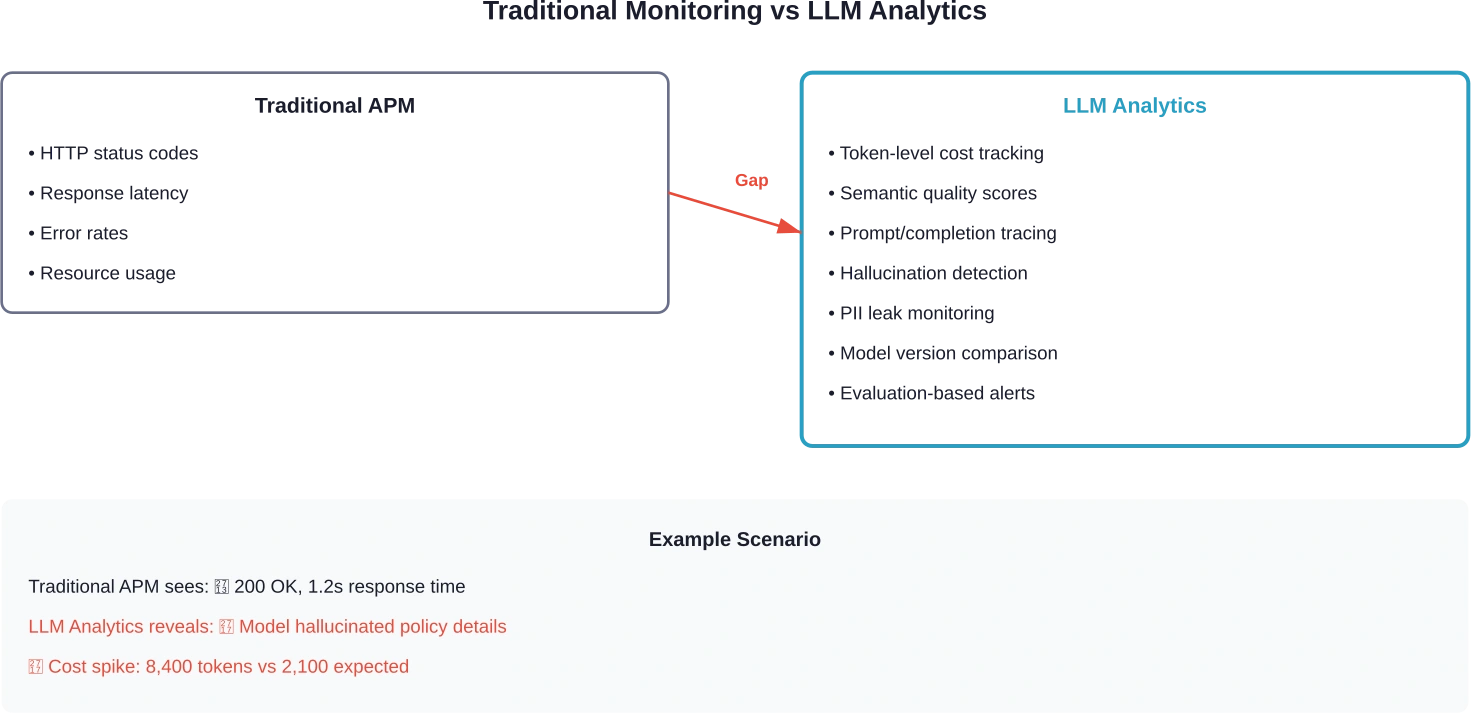
Traditional monitoring doesn’t catch AI failures. An APM dashboard might show a 200 response in 1.2 seconds, but it won’t reveal that the model hallucinated a policy detail, leaked sensitive information, or drifted off-topic halfway through the conversation.
That’s the gap LLM analytics tools fill. They trace prompts and completions, calculate token costs per request, detect quality drift across model versions, and surface failure patterns that standard observability platforms miss entirely.
As LLM-powered applications scale from prototype to production, token costs can spiral quickly. A single unoptimized prompt chain can multiply expenses by 10x. Without real-time visibility into usage patterns, teams often discover budget overruns only after the damage is done.
This guide breaks down the top LLM analytics platforms for tracking both cost and quality. We’ll cover what makes each tool different, how pricing compares across vendors, and which platforms work best for specific deployment scenarios.
Why LLM Cost and Quality Tracking Matters
Production AI systems fail differently than traditional software. A web server either returns data or throws an error. But an LLM can return perfectly formatted JSON that contains completely fabricated information.
Cost control presents another challenge. Token-based pricing means every prompt modification changes the economics. Adding context to improve quality might triple the cost per request. Switching from GPT-4 to a smaller model might cut costs by 90% but degrade output accuracy below acceptable thresholds.
According to research on agent serving systems, existing model serving platforms lack session-awareness, leading to unnecessary cost-quality tradeoffs. The AgServe framework demonstrates that session-aware KV cache management and quality-based model cascading can achieve response quality comparable to GPT-4o at just 16.5% of the cost.
Here’s what proper LLM analytics enables:
- Token-level cost attribution across prompts, users, features, and model versions
- Quality drift detection through automated evaluation scores and human feedback loops
- Latency tracking that separates API response time from model processing time
- Failure pattern analysis that surfaces common hallucination triggers or formatting errors
- Safety monitoring for PII leakage, prompt injection attempts, and content policy violations
Without these capabilities, teams operate blind. They can’t optimize prompt engineering decisions, can’t prove ROI to stakeholders, and can’t catch quality degradation before it impacts users.
What Makes LLM Analytics Different From Standard Observability
Standard APM tools track requests, errors, and latency. That’s necessary but insufficient for LLM applications.
The fundamental difference: LLM analytics must evaluate the semantic quality of outputs, not just whether the API call succeeded. A 200 status code tells you nothing about whether the model’s advice was accurate, relevant, or safe.
Three capabilities separate LLM-specific analytics from traditional monitoring:
Token-Based Cost Calculation
Every API call consumes input tokens (the prompt) and output tokens (the completion). Costs vary by model, by token type, and sometimes by time of day. Proper cost tracking requires parsing usage metadata from each API response and attributing it to the right cost center.
According to Anthropic’s documentation on cost management, the /cost command provides detailed token usage statistics including total cost, API duration, wall-clock duration, and code changes. This granular tracking enables teams to identify expensive operations before they scale.
Evaluation-Based Quality Metrics
Quality can’t be inferred from HTTP status codes. Analytics platforms solve this by running automated evaluations on every completion. These evals check for hallucinations, measure relevance against expected outputs, verify formatting compliance, and flag potential safety violations.
Anthropic’s research on agent evaluation emphasizes that good evaluations help teams ship AI agents more confidently. Without them, teams get stuck in reactive loops, catching issues only in production where fixing one failure creates others.
Prompt and Completion Tracing
Standard logs capture endpoints and status codes. LLM tracing captures the full prompt-completion cycle, including system messages, user inputs, function calls, model parameters, and the final output. This context is essential for debugging quality issues and optimizing prompts.
OpenAI’s guidance on evaluation with Langfuse demonstrates how tracing the internal steps of agent workflows enables both online and offline evaluation strategies that teams use to bring agents to production reliably.
Top LLM Analytics Platforms for 2026
The LLM analytics market has matured significantly. Platforms now fall into three categories: evaluation-focused tools, open-source observability frameworks, and enterprise monitoring suites.
Here’s how the leading platforms compare:
Confident AI
Confident AI centers LLM quality monitoring around evals and structured quality metrics rather than APM-style observability. It brings together automated evaluation scoring, LLM tracing, vulnerability detection, and human feedback into one platform.
The tool shines for teams that prioritize quality assurance over general observability. Every trace gets evaluated automatically against configurable metrics like relevance, hallucination rate, and formatting compliance.
Key features:
- Built-in evaluation library with 20+ quality metrics
- Custom evaluator support for domain-specific quality checks
- Human feedback integration for RLHF workflows
- Vulnerability scanning for prompt injection and PII leakage
- Dataset versioning for regression testing
Pricing: Usage-based with usage-based pricing, making it an accessible option for teams with moderate trace volumes. Cost forecasting should be evaluated during the onboarding period.
Best for: Teams focused on quality assurance and evaluation-driven development cycles.
Langfuse
Langfuse offers open-source LLM observability with full prompt-completion tracing, token-level cost tracking, and quality monitoring. The platform supports both self-hosted and cloud deployment models.
According to OpenAI’s cookbook on evaluating agents with Langfuse, the platform monitors internal agent steps and enables both online and offline evaluation metrics used by teams to bring agents to production reliably.
Langfuse excels at session-aware tracking, grouping related traces into sessions for easier multi-turn conversation and agentic workflow analysis.
Key features:
- Unlimited trace spans on Pro plan
- Session-based conversation tracking
- Real-time evaluation scoring
- Cost attribution per user, feature, or model
- Open-source core with enterprise cloud option
Pricing: Langfuse Cloud offers a Hobby plan (50k units/mo free), a Core plan ($29/mo + usage), and a Pro plan ($199/mo + usage). Both paid plans include 100k units, with additional usage starting at $8/100k units.
Best for: Teams that want open-source flexibility with optional cloud hosting, especially for multi-turn conversational applications.
Helicone
Helicone provides lightweight LLM observability focused on cost optimization. The platform acts as a proxy layer between applications and LLM APIs, capturing every request without requiring code changes.
The proxy architecture makes deployment straightforward. Change the API endpoint, and Helicone starts logging requests immediately. This simplicity comes with tradeoffs: less flexibility for custom evaluations and no built-in quality metrics.
Key features:
- Zero-code integration via API proxy
- Token usage tracking across models
- Cost monitoring and budget alerts
- Latency analysis and caching layer
- Support for 10+ LLM providers
Pricing: Free tier includes 10K requests per month. Pro starts at $79/month with usage-based pricing.
Best for: Teams that need quick cost visibility without extensive evaluation requirements.
Datadog LLM Observability
Datadog extended its enterprise monitoring platform to cover LLM applications. The integration brings LLM traces into the same dashboard as infrastructure metrics, APM data, and logs.
This unified view helps teams correlate LLM performance with underlying system behavior. Slow completions might correlate with database latency. Cost spikes might align with specific feature releases.
Key features:
- Unified monitoring across infrastructure and LLM layer
- Real-time cost tracking and anomaly detection
- Token usage breakdown by endpoint and user
- Custom metric support for domain-specific KPIs
- Enterprise security and compliance features
Pricing: Integrated with Datadog’s existing subscription. Check the official site for current plans tailored to LLM observability needs.
Best for: Enterprise teams already using Datadog who want to consolidate LLM monitoring into their existing observability stack.
Weights & Biases Weave
Weave extends W&B’s experiment tracking capabilities to LLM applications. It traces prompt templates, model parameters, and outputs across experiments, making it easier to compare prompt variations and model configurations.
The platform excels at offline evaluation. Teams can capture production traces, replay them against different models or prompts, and measure quality differences before deploying changes.
Key features:
- Experiment-focused workflow for prompt optimization
- Offline evaluation with trace replay
- Cost tracking per experiment and model variant
- Integration with W&B’s ML lifecycle tools
- Dataset management for benchmark tests
Pricing: Free tier available. Team and enterprise plans with usage-based pricing — see the official site for current rates.
Best for: ML teams running extensive prompt optimization experiments who need offline evaluation capabilities.
| Platform | Cost Tracking | Quality Metrics | Session Awareness | Starting Price
|
|---|---|---|---|---|
| Confident AI | Yes | 20+ built-in evals | Basic | Usage-based |
| Langfuse | Yes | Custom evaluators | Advanced | Free / $249/mo |
| Helicone | Yes | Limited | No | Free / $79/mo |
| Datadog LLM | Yes | Custom metrics | Basic | Enterprise pricing |
| W&B Weave | Yes | Experiment-focused | Offline replay | Free tier available |

Build LLM Systems with Clear Cost and Quality Monitoring
LLM applications need visibility into how models perform in production. Tracking prompts, responses, token usage, and system behavior helps teams maintain quality and understand how their AI systems are actually being used. AI Superior develops AI platforms where language models are integrated with backend systems, data pipelines, and analytics tools. Their engineers build AI software that supports logging, evaluation, and monitoring so LLM applications can be managed reliably in production.
Deploying an LLM Application in Production?
Talk with AI Superior to:
- develop LLM-based applications and NLP tools
- integrate monitoring and analytics workflows
- deploy AI systems within existing software platforms
👉 Contact AI Superior to discuss your AI development project.
Choosing the Right Model for Cost-Efficient Analytics
Platform choice matters, but model selection drives the actual cost and quality outcomes. Recent benchmarks reveal significant differences in how well models handle analytical workloads.
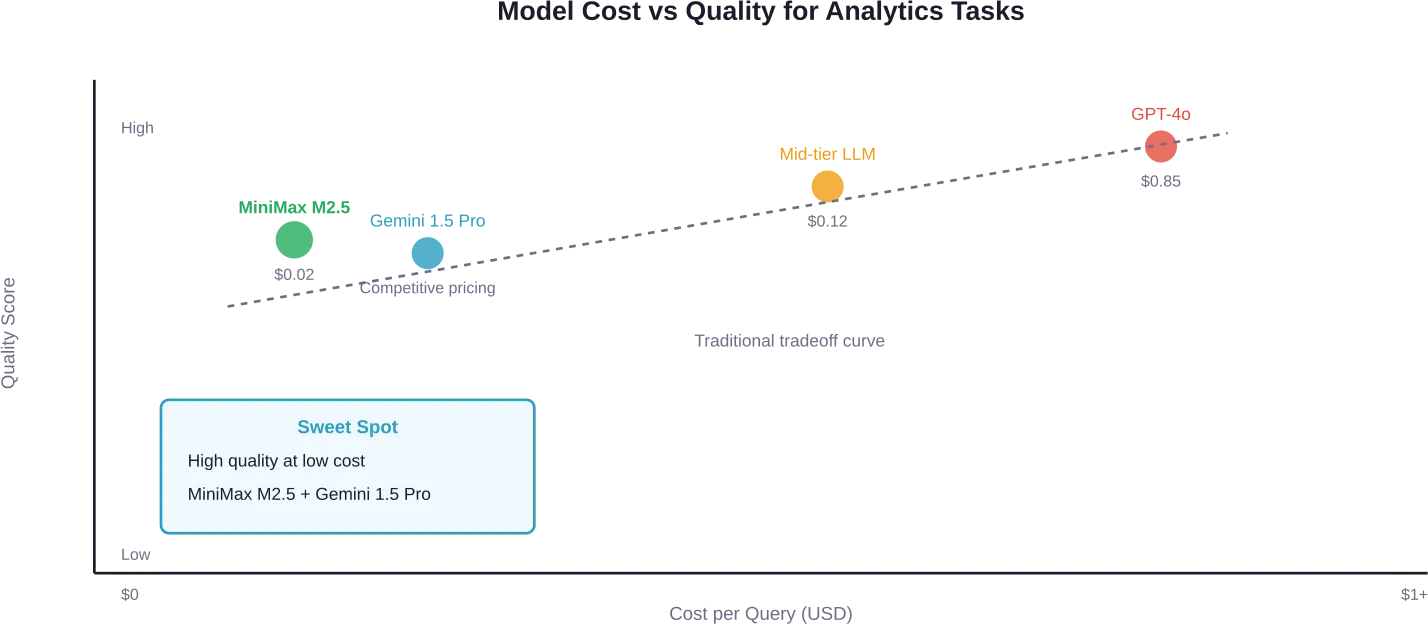
According to testing on real Google Analytics data, MiniMax M2.5 delivered excellent quality across multiple test runs, cost $0.02 per query, and achieved 70 seconds average completion time.
The benchmark evaluated models on several dimensions:
- Quality rating: Did the model deliver actionable insights beyond raw data?
- Accuracy score: How accurately did it use real GA4 dimensions and metrics?
- Cost per query: Total API cost for completing the analytical task
- Latency: Time from prompt submission to completion
For strategic analysis requiring deeper reasoning, Gemini 1.5 Pro showed strong performance. It immediately identified broken attribution tracking in test data and pivoted to actionable conversion analysis. At these price points, teams can run hundreds of queries daily for minimal cost.
Research on selecting LLMs for multi-stage complex tasks confirms these findings. The MixLLM framework demonstrated that compared to using a single powerful commercial LLM, adaptive model selection improves result quality by 1-16% while reducing inference cost by 18-92%.
Cost-Quality Tradeoff Framework
Research on transcending cost-quality tradeoffs in agent serving reveals that session-aware architectures can break the traditional tradeoff curve. AgServe achieves comparable response quality to GPT-4o at 16.5% of the cost through two innovations:
- Session-aware KV cache management: The framework uses Estimated-Time-of-Arrival-based eviction and in-place positional embedding calibration to boost cache reuse rates dramatically. This reduces redundant computation across multi-turn sessions.
- Quality-aware model cascading: Rather than committing to a single model for an entire session, AgServe performs real-time quality assessment and upgrades models mid-session when needed. This allows starting with cheaper models and escalating only when quality demands it.
The research demonstrates 1.8× improvement in quality relative to the traditional cost-quality tradeoff curve, effectively proving that proper architecture choices can deliver better outcomes at lower costs simultaneously.
Key Metrics to Track
Effective LLM analytics requires tracking the right metrics. Too many teams focus exclusively on cost or latency while ignoring quality signals that predict user satisfaction.
Cost Metrics
- Token consumption per request: Measure both input and output tokens separately. Optimization strategies differ — reducing input tokens requires prompt engineering, while controlling output tokens needs better sampling parameters or format constraints.
- Cost per user interaction: Aggregate token costs across all API calls needed to complete one user task. A single user question might trigger multiple model calls (retrieval, reasoning, formatting), and the total cost matters more than individual call costs.
- Cost by feature or endpoint: Attribution enables ROI analysis. Which features generate value that justifies their LLM costs? Which ones hemorrhage tokens without proportional user benefit?
Anthropic’s documentation on managing costs emphasizes tracking usage patterns with the /stats command, which provides session-level visibility into token usage, API duration, wall-clock time, and code changes.
Quality Metrics
- Hallucination rate: Percentage of completions containing fabricated information not supported by provided context. This requires automated fact-checking against source documents or knowledge bases.
- Relevance score: How well does the completion address the actual user query? Semantic similarity between question and answer provides a proxy metric.
- Format compliance: For structured outputs (JSON, CSV, SQL), what percentage of completions parse successfully without errors?
- Safety violations: Frequency of outputs containing PII, offensive content, or responses to prompt injection attempts.
Research on evaluating Chain-of-Thought quality in code generation found that external factors account for 53.60% (primarily unclear requirements and missing context), while internal factors account for 40.10% (mainly inconsistencies between reasoning and prompts). This suggests monitoring both input quality and model reasoning patterns matters for maintaining output standards.
Performance Metrics
- Time to first token (TTFT): Latency before the model begins streaming output. Critical for perceived responsiveness in chat interfaces.
- Tokens per second: Generation speed once streaming begins. Slower speeds frustrate users waiting for long completions.
- End-to-end latency: Total time from user request to complete response, including retrieval, preprocessing, model inference, and postprocessing.
| Metric Category | Key Indicators | Why It Matters
|
|---|---|---|
| Cost | Token usage, cost per interaction, cost by feature | Controls spend and enables ROI analysis |
| Quality | Hallucination rate, relevance score, format compliance | Ensures output accuracy and user satisfaction |
| Performance | TTFT, tokens/second, end-to-end latency | Maintains responsive user experience |
| Safety | PII leakage, prompt injection attempts, policy violations | Prevents security incidents and compliance issues |
Implementation Strategies
Getting value from LLM analytics requires more than installing a monitoring tool. Teams need structured approaches to instrumentation, evaluation design, and alerting.
Start With Tracing
Instrument LLM API calls to capture full request and response data.
At minimum, log:
- Timestamp and request ID
- Model name and parameters
- Complete prompt (system message, user input, context)
- Full completion text
- Token counts (input, output, total)
- Latency breakdown (API time, processing time)
- Cost calculation
Most analytics platforms provide SDKs that handle this automatically. But even simple custom logging to a structured format enables post-hoc analysis.
Define Quality Benchmarks
Research on demystifying evaluations for AI agents emphasizes that evaluation strategies should match system complexity. Code-based graders (string matching, binary tests, static analysis) work for deterministic outputs. LLM-based graders handle semantic evaluation where exact matching fails.
Build a benchmark dataset with representative prompts and expected outputs. Run new model versions or prompt templates against this dataset before deploying. Track quality metrics over time to catch regression.
According to OpenAI’s guidance on agent evaluation with Langfuse, offline evaluation typically involves having a benchmark dataset with prompt-output pairs, running the agent on that dataset, and comparing outputs using additional scoring mechanisms.
Set Up Cost Alerts
Budget overruns happen fast with token-based pricing.
Configure alerts for:
- Daily cost exceeding baseline by 25%+
- Individual requests consuming 10x normal tokens
- Specific users or features driving disproportionate costs
- Unexpected model version changes increasing spend
Alerts should trigger investigation, not panic. Cost spikes often indicate product success (increased usage) rather than problems. But visibility enables distinguishing growth from inefficiency.
Implement Feedback Loops
Automated metrics don’t capture everything users care about. Add explicit feedback mechanisms:
- Thumbs up/down on completions
- Detailed issue reporting for poor outputs
- Session-level satisfaction surveys
Correlate user feedback with automated quality scores. If humans consistently rate high-scoring completions poorly, the automated metrics need recalibration.
Advanced Optimization Techniques
Once basic monitoring is operational, several advanced techniques can significantly improve cost-quality ratios.
Session-Aware Model Cascading
Research on agent serving demonstrates that session-aware model selection delivers dramatic improvements. Instead of committing to one model for an entire conversation, the system starts with a cheaper model and upgrades mid-session when quality demands it.
The AgServe framework achieves GPT-4o-equivalent quality at 16.5% of the cost by dynamically selecting and upgrading models during session lifetime based on real-time quality assessment.
Implementation requires:
- Quality scoring after each model response
- Thresholds defining acceptable quality levels
- Logic to escalate to more capable (expensive) models when needed
- KV cache management to reuse context across model switches
Prompt Optimization Based on Analytics
Analytics reveal which prompt patterns correlate with quality problems or cost overruns. Common issues include:
- Excessive context stuffing: Adding entire documents to prompts when targeted excerpts would suffice. Analytics showing high input token counts with low relevance scores indicate this problem.
- Vague instructions: Generic prompts like “analyze this data” produce rambling, unfocused outputs. Analytics showing low format compliance or high variance in output length suggest instruction clarity problems.
- Missing constraints: Not specifying output length or format leads to unnecessarily long completions. Token usage analytics quickly expose this.
Caching Strategies
Many LLM applications repeatedly process similar contexts. Analytics identifying high-frequency prompt prefixes enable targeted caching strategies.
Semantic caching stores embeddings of recent prompts. When a new prompt is semantically similar to a cached one, return the cached completion instead of calling the API. This works well for FAQ-style applications where many users ask equivalent questions.
Prompt prefix caching reuses processing of common system messages and context. If 80% of prompts share the same 2,000-token prefix, caching that computation saves significant costs.
Common Pitfalls and How to Avoid Them
Even teams with monitoring infrastructure make predictable mistakes that undermine analytics effectiveness.
Tracking Vanity Metrics
Metrics like total API calls or aggregate token counts don’t drive decisions. They go up as the product succeeds. Track metrics that indicate problems: cost per value delivered, quality degradation rates, latency outliers.
Ignoring Statistical Significance
LLM outputs are stochastic. A single bad completion doesn’t indicate systemic problems. But teams often overreact to anecdotal failures instead of analyzing trends.
Require sufficient sample sizes before concluding a quality regression exists. Research on LLM selection for multi-stage tasks emphasizes designing systems that tolerate performance fluctuations caused by LLM stochasticity.
Optimizing for Cost Alone
Cutting costs by 50% means nothing if quality drops enough to degrade user experience. The goal is optimal cost-quality ratio, not minimum cost.
Analytics should track both dimensions simultaneously. Research on session-aware serving demonstrates that proper architecture can improve quality while reducing costs, transcending the traditional tradeoff.
Not Testing in Production
Offline evaluation with benchmark datasets matters, but production behavior differs. Users formulate queries differently than test designers expect. Real-world edge cases don’t appear in curated datasets.
Run ongoing production monitoring and use it to refine offline benchmarks. The benchmark should evolve to reflect actual usage patterns.
Frequently Asked Questions
What’s the difference between LLM monitoring and LLM observability?
Monitoring tracks predefined metrics and alerts when they exceed thresholds. Observability enables exploring system behavior through arbitrary queries on detailed trace data. Most modern platforms blend both approaches — structured metrics for dashboards and alerts, detailed traces for debugging specific issues.
How much does LLM analytics typically cost?
Pricing models vary significantly. Usage-based platforms charge according to trace volume. Subscription platforms like Langfuse Pro cost $249/month for unlimited traces. Enterprise suites like Datadog integrate LLM monitoring into existing contracts.
Can analytics tools reduce my LLM costs?
Analytics don’t directly reduce costs, but they enable optimization decisions that do. Session-aware serving research demonstrates cost reductions exceeding 80% are possible with architectural improvements.
What quality metrics matter most for production LLM applications?
Hallucination rate and relevance score are critical for factual accuracy. Format compliance matters for structured outputs. Safety metrics (PII leakage, prompt injection resistance) prevent security incidents. The specific metrics depend on use case — customer support applications prioritize different quality dimensions than code generation tools.
Should I use open-source or commercial LLM analytics tools?
Open-source tools like Langfuse offer deployment flexibility and no vendor lock-in, but require infrastructure management. Commercial platforms provide managed hosting, faster feature development, and dedicated support. Teams with strong infrastructure capabilities often prefer open-source. Teams focused on application development rather than operations typically choose managed solutions.
How do I measure ROI on LLM analytics investments?
Track three dimensions: cost savings from optimization (reduced token consumption), quality improvements (better user ratings, fewer support tickets), and developer velocity (faster debugging, safer deployments). Most teams see positive ROI within 2-3 months through cost optimization alone, before accounting for quality and velocity benefits.
What’s the minimum viable analytics setup for a new LLM application?
Start with basic tracing that logs every prompt, completion, token count, and cost. Add a simple quality metric relevant to the domain (format compliance for structured outputs, relevance scoring for chat applications). Set up cost alerts for budget overruns. This minimal setup takes 1-2 days to implement and prevents the most common production problems.
Conclusion
LLM analytics has evolved from nice-to-have to production necessity. Without visibility into token costs, quality metrics, and performance characteristics, teams operate blind.
The platform landscape offers strong options across different needs. Confident AI leads for evaluation-focused quality monitoring. Langfuse provides open-source flexibility with robust session tracking. Helicone delivers quick cost visibility through proxy-based deployment. Datadog extends enterprise observability to LLM workloads.
But tooling alone doesn’t guarantee success. Effective analytics requires tracking the right metrics, building quality benchmarks, implementing feedback loops, and using insights to drive optimization decisions.
Research demonstrates that session-aware architectures can transcend traditional cost-quality tradeoffs. AgServe achieves GPT-4o-level quality at 16.5% of the cost through intelligent KV cache management and dynamic model selection. These techniques work because they match system architecture to the unique characteristics of LLM workloads.
The teams seeing best results share common practices. They instrument comprehensively from day one. They define quality benchmarks early and track regression continuously. They optimize based on data rather than intuition. And they treat analytics as a feedback system that improves over time, not a one-time implementation.
Start by implementing basic tracing and cost tracking. Add quality metrics relevant to the use case. Set up alerts that catch problems before they impact users. Then use the resulting visibility to drive iterative improvements in prompts, model selection, and system architecture.
The difference between teams that succeed with production LLM applications and those that struggle often comes down to analytics. Measurement drives optimization. Optimization drives sustainable economics. And sustainable economics enable building genuinely useful AI products.