Quick Summary: Training an LLM from scratch costs between $78 million and $192 million for frontier models like GPT-4 and Gemini Ultra 1.0, driven by massive GPU clusters, electricity, data acquisition, and engineering talent. Smaller models can be trained for $50,000-$500,000 using cloud infrastructure or under $100,000 with efficient optimization techniques, but organizations face ongoing costs for inference, storage, and maintenance that often exceed training expenses.
Large language models have transformed how we interact with technology. But here’s what most people don’t realize: the price tag attached to creating these models is astronomical.
According to the Stanford AI Index Report 2025, training costs for frontier models have escalated dramatically. GPT-4’s training ran somewhere between $78 million and $100 million. Gemini Ultra training cost is estimated at approximately $191 million according to the Stanford AI Index Report 2024. These numbers represent a 287,000x increase from the cost of training a Transformer model back in 2017, which clocked in at just $670.
So what drives these massive expenses? And more importantly, what does it actually cost if you’re considering training your own model from scratch?
Breaking Down the Real Costs of LLM Training
Training a large language model from scratch isn’t just expensive—it’s a multi-dimensional financial commitment that spans hardware, energy, data, and human capital.
Compute Infrastructure: The Biggest Line Item
The compute costs dominate everything else. High-performance GPUs like the NVIDIA H100 can cost $30,000 per unit. But that’s just the beginning.
For context, training frontier models requires thousands of GPUs running continuously for weeks or months. Research from arXiv analyzing GPU economics found that an A800 80G GPU carries a baseline hourly cost of approximately $0.79 per hour, with typical ranges falling between $0.51 and $0.99 per hour depending on configuration and cloud platform pricing.
OpenAI reportedly spent over $100 million on training GPT-4, with a significant portion allocated to cloud computing costs. The scale is hard to wrap your head around.
| Model | Estimated Training Cost | Source |
|---|---|---|
| GPT-4 | $78M-$100M+ | Wall Street Journal, Stanford AI Index 2025 |
| Gemini Ultra 1.0 | $191M | Stanford AI Index Report 2024 |
| GPT-4o | ~$100M | Industry estimates |
| Transformer (2017) | $670 | Stanford AI Index Report 2025 |
Energy Consumption and Environmental Costs
Running thousands of GPUs around the clock consumes enormous amounts of electricity. Research published in Springer’s 2025 study on energy efficiency in large language models highlights that energy consumption dynamics directly correlate with model size and batch configuration.
The environmental impact extends beyond just the training phase. As computational demands grow, so do concerns about sustainability and carbon footprint.
Data Acquisition and Preparation
Here’s something that doesn’t get enough attention: the human labor behind training data is significantly undervalued. A position paper published on Hugging Face in April 2025 argues that data production costs should rival or exceed the computational costs of training.
Quality datasets don’t materialize out of thin air. They require:
- Data collection and licensing fees
- Manual cleaning and annotation
- Copyright compliance and legal review
- Ongoing updates and maintenance
The paper makes a compelling case that training data represents the most expensive—and most undercompensated—part of LLM development.
Engineering Talent and Operational Overhead
Building an LLM requires specialized expertise. Machine learning engineers, data scientists, infrastructure specialists, and research scientists don’t come cheap. Salaries for these roles typically range from $150,000 to $500,000+ annually in major tech hubs.
Beyond salaries, there’s operational overhead: project management, experiment tracking, model versioning, security, and compliance infrastructure.
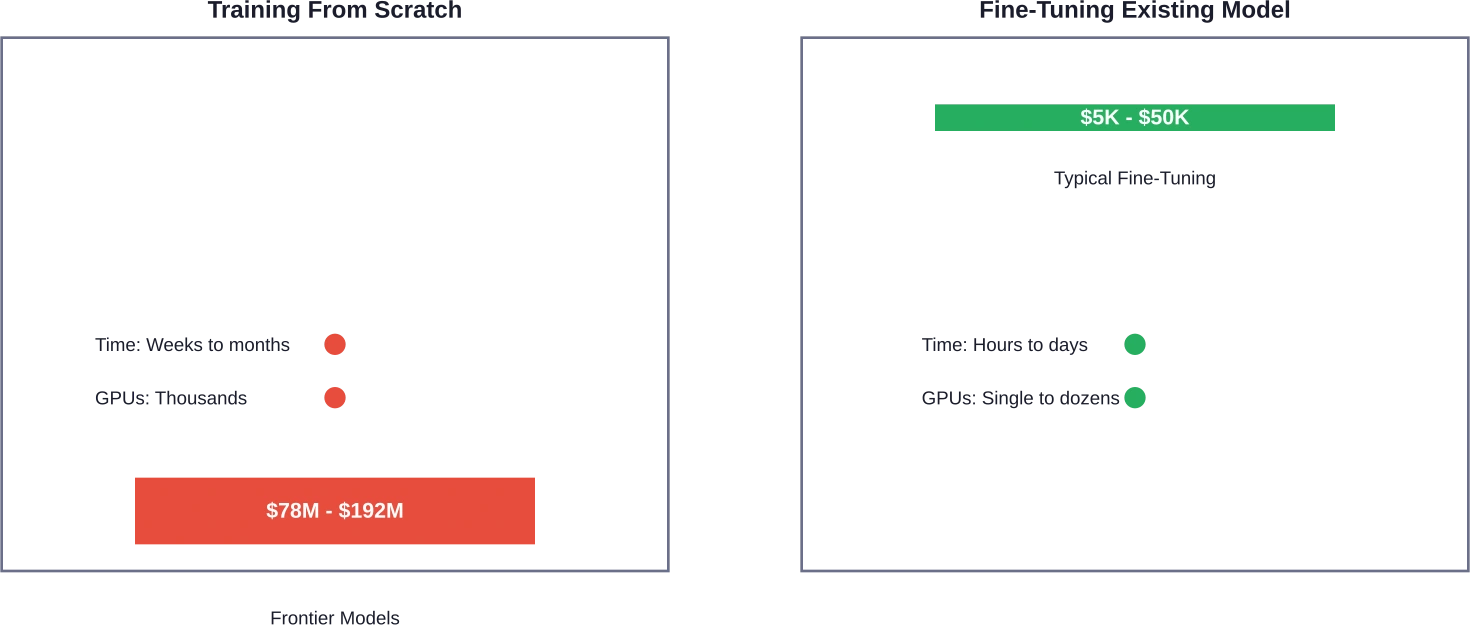
Training From Scratch vs. Fine-Tuning: A Cost Comparison
Not everyone needs to build GPT-5. The decision between training from scratch and fine-tuning an existing model can save organizations 60-90% of their AI budget.
When Training From Scratch Makes Sense
Full pre-training from scratch typically makes sense when:
- Your domain requires fundamentally different language patterns than general models
- Data privacy regulations prohibit using commercial models
- You need complete control over model architecture and behavior
- Your organization has the budget and expertise to support long-term model development
The Fine-Tuning Alternative
Fine-tuning takes a pre-trained model and adapts it to specific tasks or domains. The cost difference is substantial. While GPT-4 cost nearly $100 million to train from scratch, fine-tuning it for specialized applications might cost $5,000 to $50,000.
Research from Universidad Nacional de Colombia demonstrated efficient fine-tuning strategies using LoRA (Low-Rank Adaptation). Their experiments showed that a base model quantized at 8 bits could be fine-tuned in approximately 7 hours on a single NVIDIA T4 GPU with 16GB VRAM—hardware that costs roughly $2-4 per hour on major cloud platforms.
Budget-Friendly Training: Can You Do It for Under $100K?
The answer is yes, but with significant compromises on model size and capabilities.
An arXiv paper titled “FLM-101B: An Open LLM and How to Train It with $100K Budget” demonstrated that smaller-scale LLM training is achievable with careful resource management. The key strategies include:
- Using smaller model architectures (1-20 billion parameters instead of 175+ billion)
- Leveraging open-source frameworks and pre-existing codebases
- Optimizing training runs with efficient hyperparameter selection
- Using mixed-precision training and quantization techniques
Research from Fraunhofer Institute compared three optimizers—AdamW, Lion, and a third variant—for pre-training LLMs on a budget. Their experiments used 2 cluster nodes equipped with multiple GPUs, demonstrating that optimizer choice significantly impacts both training time and final model performance.
The Open-Weight Alternative
OpenAI’s release of gpt-oss-120b and gpt-oss-20b in August 2025 changed the game. These open-weight models, released under the Apache 2.0 license, deliver strong real-world performance at substantially lower costs than training from scratch.
Organizations can now download these models and fine-tune them for specific use cases, bypassing the enormous upfront training costs entirely.
Cloud vs. On-Premise: Which Costs Less Long-Term?
Carnegie Mellon researchers published a cost-benefit analysis examining when on-premise LLM deployment breaks even with commercial cloud services. Their findings challenge conventional wisdom.
Cloud Infrastructure Costs
Cloud platforms offer flexibility but charge premium rates for GPU time. Major providers typically charge:
- $2-8 per hour for high-performance GPU instances
- Data transfer fees (often overlooked but substantial at scale)
- Storage costs for model checkpoints and training data
- API call fees if using managed services
The advantage? Zero upfront capital expenditure and the ability to scale on demand.
On-Premise Infrastructure Investment
Purchasing hardware outright requires significant capital but eliminates recurring cloud costs. A cluster of NVIDIA H100 GPUs might cost $500,000 to $2 million upfront, but that investment amortizes over 3-5 years.
The Carnegie Mellon analysis found that organizations with sustained, predictable AI workloads often break even within 12-18 months when choosing on-premise deployment over cloud services.
But there’s a catch: on-premise infrastructure requires dedicated staff for maintenance, cooling systems, power infrastructure, and security—costs that many budget analyses overlook.
What Drives LLM Training Costs Higher?
Several factors determine whether your training budget lands closer to $50,000 or $50 million.
Model Size and Architecture
The relationship between parameters and cost isn’t linear—it’s exponential. Doubling model size more than doubles training costs due to:
- Increased memory requirements forcing multi-GPU parallelism
- Longer training times as convergence slows with scale
- Greater data requirements to properly train larger architectures
Training Duration and Convergence
Training runs that fail to converge waste enormous resources. Efficient hyperparameter tuning can dramatically affect how fast a model learns. A well-tuned training run might reach target accuracy in half the time of a poorly configured one.
This is where expertise pays dividends. Engineers who understand learning rate schedules, batch size optimization, and regularization techniques save organizations millions in wasted compute.
Data Quality and Quantity
Training on low-quality data produces low-quality models—but acquiring high-quality data costs real money. Some organizations spend more on data curation than on compute infrastructure.
The emerging consensus, articulated in the Hugging Face position paper on training data economics, is that data should be the most expensive component of LLM development. Currently, it’s undervalued.
Hidden Costs Beyond Training
Here’s where many budget projections fall apart: training costs are just the beginning.
Inference Infrastructure
The WiNGPT Team introduced an “economics of inference” framework that treats LLM inference as a compute-driven production activity. Their analysis found that inference costs often exceed training costs over the model’s operational lifetime.
Every query sent to your model consumes computational resources. At scale, inference infrastructure can cost hundreds of thousands per month.
Model Updates and Retraining
Language evolves. Factual information changes. Business requirements shift. Models trained in 2024 become stale by 2026.
Periodic retraining or continuous learning pipelines represent ongoing costs that many organizations underestimate during initial planning.
Storage and Data Management
Model checkpoints, training datasets, experiment logs, and versioning systems all consume storage. For frontier models, we’re talking petabytes of data. Storage costs accumulate quietly but substantially.
Monitoring and Maintenance
Production ML systems require constant monitoring for:
- Performance degradation
- Bias detection and mitigation
- Security vulnerabilities
- API reliability and uptime
These operational costs persist for as long as the model remains in production.
| Cost Category | One-Time | Recurring | Typical Range |
|---|---|---|---|
| Initial Training | ✓ | $50K – $192M | |
| Inference Infrastructure | ✓ | $10K – $500K/month | |
| Model Retraining | ✓ | 20-50% of initial cost/year | |
| Storage | ✓ | $5K – $50K/month | |
| Engineering Team | ✓ | $500K – $5M/year | |
| Data Acquisition | ✓ | ✓ | $100K – $10M+ |
Strategies to Reduce LLM Training Costs
Smart organizations employ multiple tactics to keep expenses under control without sacrificing model performance.
Transfer Learning and Progressive Training
Instead of training from scratch, start with an existing open-weight model and progressively adapt it. This approach, documented in research from Universidad Nacional de Colombia, reduces training time by 80-90%.
Efficient Optimization Techniques
The Fraunhofer Institute research comparing AdamW, Lion, and alternative optimizers showed that optimizer selection meaningfully impacts both training speed and resource consumption. Choosing the right optimizer for your specific use case can shave 20-30% off training costs.
Quantization and Compression
Training with mixed precision (combining 16-bit and 32-bit floating point operations) reduces memory consumption and accelerates computation. Post-training quantization to 8-bit or even 4-bit representations shrinks model size for deployment without catastrophic performance loss.
The Universidad Nacional de Colombia experiments demonstrated successful LoRA training on models quantized to 8 bits, with pre-quantized 4-bit models showing acceptable performance on consumer hardware.
Smart Resource Allocation
Efficiently using and managing computational resources prevents paying for idle time. Strategies include:
- Spot instance bidding on cloud platforms for non-critical training runs
- Pipeline parallelism to maximize GPU utilization
- Gradient accumulation to simulate larger batch sizes on limited hardware
- Checkpoint restart capabilities to recover from interruptions
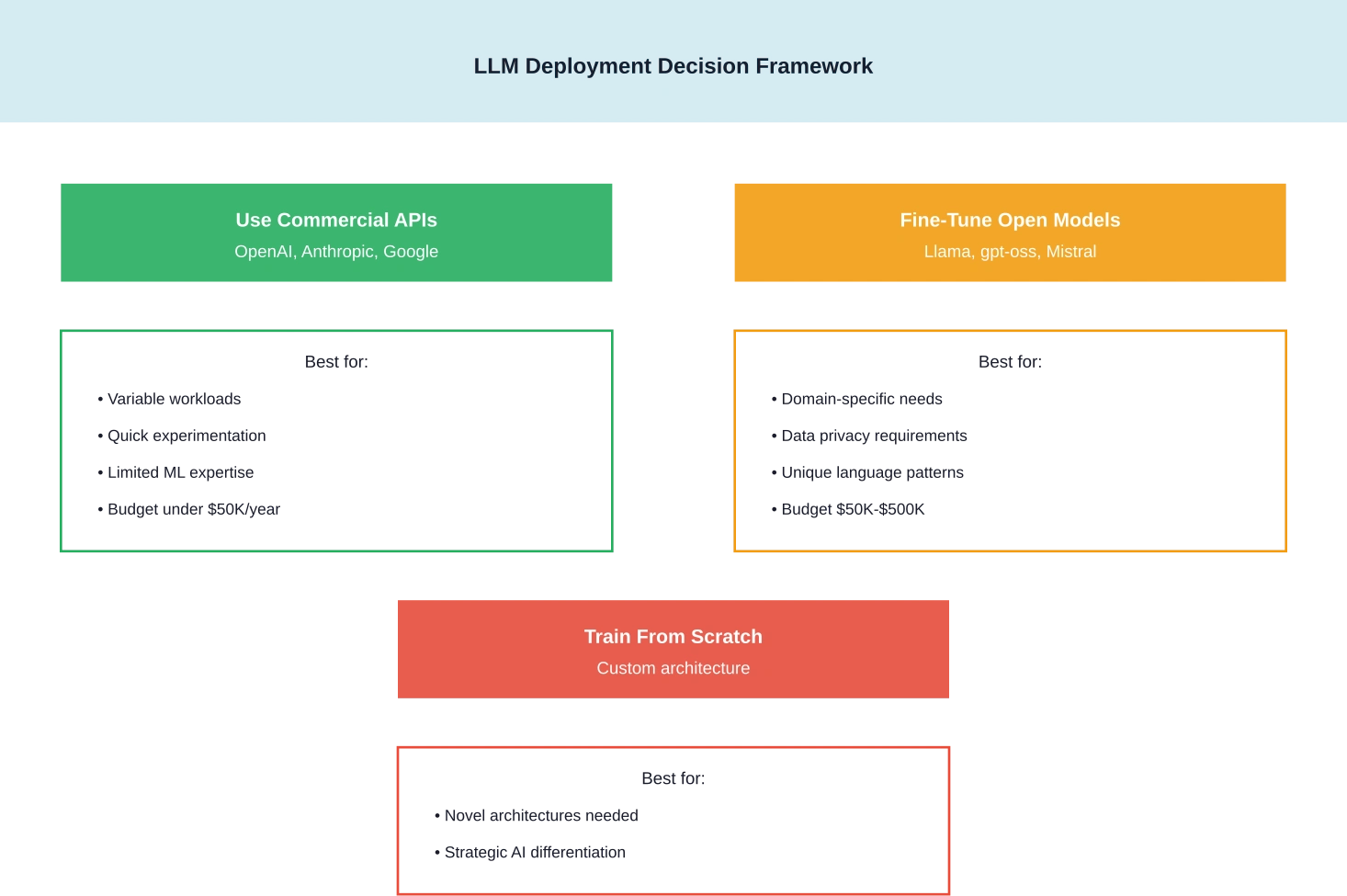
Should You Train Your Own LLM in 2026?
The decision framework has shifted dramatically with the proliferation of capable open-weight models.
For most organizations, the answer is no—at least not from scratch. OpenAI’s gpt-oss models, Meta’s Llama 3 series, and other open-weight alternatives offer performance that would cost tens of millions to replicate.
But fine-tuning? That’s a different story. Organizations with unique domain requirements, specific compliance needs, or proprietary data often benefit from fine-tuning existing models rather than relying solely on general-purpose commercial APIs.
When On-Premise Training Makes Sense
The Carnegie Mellon cost-benefit analysis identified specific scenarios where on-premise LLM deployment and training prove economically viable:
- Sustained workloads exceeding 10,000 GPU hours annually
- Strict data residency requirements prohibiting cloud usage
- Long-term strategic AI initiatives spanning 3+ years
- Availability of in-house ML infrastructure expertise
When Cloud Services Win
For experimental projects, variable workloads, or organizations lacking ML infrastructure expertise, cloud-based solutions and API services offer better economics. The flexibility to scale down—or shut off completely—eliminates the risk of stranded capital investment.

Reduce LLM Training Costs Before You Start
Training an LLM from scratch is expensive not only because of compute, but because of data preparation, model architecture choices, and training strategy. AI Superior works on this engineering layer—helping companies design custom LLMs, prepare training datasets, and optimize training pipelines so models are built efficiently from the start.
If you are estimating the real cost of training an LLM in 2026, it helps to review the technical setup before committing large compute budgets. Contact AI Superior to evaluate your training architecture and identify where costs can be reduced before the training process even begins.
The Future of LLM Training Economics
Several trends are reshaping the cost landscape.
OpenAI’s February 2026 release of GPT-5.3-Codex (announced February 5, 2026) demonstrated 25% greater efficiency than its predecessor. As model architectures improve, the compute required for equivalent performance decreases.
Hardware advances continue as well. NVIDIA’s successive GPU generations deliver meaningful performance-per-watt improvements, reducing both capital and operational expenses.
But perhaps most significantly, the democratization of access through open-weight models is fundamentally changing who can participate in LLM development. What required $100 million in 2023 might be achievable for $100,000 in 2026 through clever use of transfer learning and efficient training techniques.
Frequently Asked Questions
How much does it cost to train GPT-4 from scratch?
According to the Stanford AI Index Report 2024 and reporting from The Wall Street Journal, GPT-4’s training cost between $78 million and $100 million. This includes compute infrastructure, energy costs, data acquisition, and engineering resources over the training period.Gemini Ultra training cost is estimated at approximately $191 million according to the Stanford AI Index Report 2024.
Can you train an LLM for under $100,000?
Yes, but with significant limitations on model size and capabilities. Research documented in the FLM-101B paper demonstrated training smaller models (1-20 billion parameters) within a $100,000 budget by using efficient architectures, optimized training procedures, and careful resource management. Fine-tuning existing open-weight models is far more cost-effective for most use cases.
What’s cheaper: cloud or on-premise LLM training?
It depends on usage patterns. Carnegie Mellon research found that on-premise deployment typically breaks even with cloud costs within 12-18 months for organizations with sustained, predictable workloads exceeding 10,000 GPU hours annually. Cloud services prove more cost-effective for variable workloads, experimental projects, or organizations lacking infrastructure expertise.
How much does LLM inference cost compared to training?
Research from the WiNGPT team suggests that inference costs often exceed training costs over a model’s operational lifetime. While training is a one-time expense (with periodic retraining), inference runs continuously as long as the model serves users. High-traffic applications can incur hundreds of thousands in monthly inference costs.
Is fine-tuning cheaper than training from scratch?
Dramatically cheaper. Fine-tuning can cost 60-90% less than training from scratch. While frontier models like GPT-4 cost $78-100 million to train, fine-tuning those same models for specific applications typically costs $5,000 to $50,000. Universidad Nacional de Colombia research demonstrated effective fine-tuning in as little as 7 hours on a single NVIDIA T4 GPU.
What GPU is best for budget LLM training?
For budget-conscious training, NVIDIA T4 GPUs (16GB VRAM) offer a reasonable entry point at $2-4 per hour on cloud platforms. For more serious projects, A100 or H100 GPUs provide better performance-per-dollar despite higher hourly rates. The A800 80G carries baseline costs around $0.79 per hour according to arXiv research on GPU economics.
How do open-weight models like gpt-oss change the economics?
OpenAI’s March 2026 release of gpt-oss-120b and gpt-oss-20b under the Apache 2.0 license fundamentally shifts the cost equation. Organizations can now download state-of-the-art models and fine-tune them for specific needs, bypassing the tens-of-millions price tag of training from scratch. This democratizes access to frontier model capabilities for organizations with modest budgets.
Making the Training Decision
Training an LLM from scratch represents a massive financial commitment that makes sense only for organizations with unique requirements, substantial budgets, and long-term strategic AI initiatives.
For the vast majority of use cases, fine-tuning open-weight models delivers 80-90% of the value at 5-10% of the cost. The proliferation of high-quality open models from OpenAI, Meta, Mistral, and others has made custom LLM development accessible to organizations that couldn’t have considered it three years ago.
The real question isn’t whether you can afford to train from scratch—it’s whether you can afford not to leverage the billions of dollars already invested in open-weight foundation models.
Ready to explore LLM deployment for your organization? Start by evaluating existing open-weight models against your specific requirements. Calculate your expected inference costs using tools like available LLM training cost calculation tools. And most importantly, begin with small-scale fine-tuning experiments before committing to larger infrastructure investments.