Résumé rapide : L'optimisation fine d'un modèle linéaire généralisé (LLM) coûte généralement entre $5 et $10 000, selon la taille du modèle, la technique utilisée et l'infrastructure. Les modèles plus petits (2 à 8 milliards de paramètres) utilisant des méthodes économes en paramètres comme LoRa peuvent être optimisés pour moins de $10 sur des GPU cloud, tandis que l'optimisation complète des modèles plus grands sur une infrastructure haut de gamme peut dépasser $10 000. Comprendre les facteurs de coût (ressources de calcul, volume de données d'entraînement, architecture du modèle et choix de la technique) permet aux équipes d'établir un budget efficace.
Le coût de l'optimisation des grands modèles de langage surprend la plupart des équipes. L'entraînement à partir de zéro peut coûter des millions — le Gemini Ultra de Google aurait atteint $191 millions, tandis que GPT-4 avoisinait les $78 millions — mais l'optimisation des modèles existants est une toute autre histoire.
Le problème, c'est que les coûts de réglage fin varient énormément. Une équipe de recherche de Stanford a optimisé Qwen3-8B-Base pour moins de $5 en utilisant des adaptateurs LoRa sur le service géré de Together AI. En revanche, un réglage fin complet sur une infrastructure d'entreprise coûte généralement entre $3 000 et $10 000.
Comprendre où va votre argent est plus important que le prix affiché.
Quels sont les facteurs qui déterminent les coûts de mise au point ?
Quatre facteurs principaux déterminent le coût réel du réglage fin.
Infrastructure informatique
Le choix du GPU est le principal facteur de variation des coûts. Les fournisseurs de services cloud facturent à l'heure, et les tarifs varient considérablement selon la catégorie de matériel.
Une carte graphique NVIDIA A10G (milieu de gamme selon les normes actuelles) coûte environ $1,50 à $2,50 par heure sur les principales plateformes cloud. La tâche d'optimisation mentionnée précédemment, dont le coût était inférieur à $10, a duré quatre heures sur une seule A10G.
Mais la montée en charge devient vite onéreuse. Les GPU haut de gamme comme les A100 ou les H100 consomment entre $4 et $8 par heure sur AWS ou Google Cloud. Les configurations multi-GPU pour les modèles plus importants multiplient ces coûts de façon linéaire.
L'auto-hébergement implique un calcul différent. Une RTX 4090 coûte environ 1 600 £ à l'achat, mais élimine les frais horaires récurrents. D'après les discussions sur LinkedIn, un GPU est rentabilisé en quelques semaines, contre 2 500 £ par mois pour un abonnement à un nœud GPU cloud, à condition que son utilisation reste élevée et constante.
Taille et architecture du modèle
Le nombre de paramètres influe directement sur les besoins en mémoire et la durée de l'entraînement.
| Taille du modèle | VRAM (Réglage fin complet) | VRAM (LoRA 4 bits) | Fourchette de coûts typique |
|---|---|---|---|
| Paramètres 2-3B | 6-8 Go | 2-3 Go | $300-$700 |
| Paramètres 7-8B | 14-16 Go | 6-8 Go | $1000-$3000 (LoRA) Jusqu'à $12 000 (plein) |
| Paramètres 12-13B | 24-28 Go | 10-12 Go | $5,000-$15,000 |
Le Phi-2 (2,7 milliards de paramètres) avec LoRA coûte généralement entre $300 et $700. Les modèles Mistral 7B se situent entre $1 000 et $3 000 avec LoRA, mais un réglage fin complet peut faire grimper les coûts jusqu'à $12 000.
Les besoins en mémoire expliquent cela. Le réglage fin complet stocke les gradients pour chaque paramètre. Un modèle 7B nécessite environ 28 Go de VRAM rien que pour charger les poids avec une précision de 16 bits, avant même de prendre en compte les gradients, les états de l'optimiseur et la mémoire d'activation pendant l'entraînement.
Sélection de la technique d'entraînement
La méthode choisie pour le réglage fin modifie considérablement les coûts et les besoins en ressources.
- Réglage fin complet Cette méthode met à jour chaque paramètre du modèle. Elle offre un contrôle et une personnalisation maximum, mais exige une quantité importante de VRAM. La consommation de mémoire étant proportionnelle à la taille du modèle, le réglage fin des modèles dépassant 13 milliards de paramètres est difficilement réalisable sans une configuration multi-GPU.
- Réglage fin efficace des paramètres (PEFT) Ces techniques ne mettent à jour qu'un petit sous-ensemble de poids. LoRA (Low-Rank Adaptation) insère des modules d'adaptation entraînables entre les couches du transformateur tout en figeant le modèle de base. D'après une étude arXiv sur les méthodes économes en ressources, LoRA réduit considérablement la mémoire d'entraînement tout en conservant une précision comparable à celle d'un réglage fin complet.
Impact concret ? Des chercheurs de Stanford ont atteint une précision de 0,78 en affinant le modèle Qwen3-8B avec LoRA (rang = 32) contre 0,41 pour le modèle de base, le tout pour un coût de calcul inférieur à 1 TP4T5. Ce gain de performance à un coût minimal démontre pourquoi les techniques PEFT dominent les applications pratiques.
- Quantification Cela réduit encore les coûts. L'entraînement avec une quantification 4 bits via bitsandbytes a permis de réduire la mémoire nécessaire au réglage fin LoRA de FLUX.1-dev d'environ 60 Go à environ 37 Go, selon la documentation de Hugging Face. La dégradation de la qualité est restée négligeable.

Taille de l'ensemble de données et durée de l'entraînement
Plus de données d'entraînement ne signifient pas toujours de meilleurs résultats, mais cela implique assurément des coûts plus élevés.
Le nombre de jetons détermine le temps de calcul. L'API de réglage fin d'OpenAI, qui facture en fonction des jetons d'entraînement et non du temps réel, explicite cette relation. Les discussions au sein de la communauté indiquent que le suivi des coûts nécessite la surveillance des jetons entraînés, la facturation ne reposant plus sur le temps d'entraînement.
La qualité des données prime sur leur volume. Les équipes obtiennent souvent de meilleurs résultats avec 500 exemples soigneusement sélectionnés qu'avec 5 000 échantillons bruités. Une mauvaise qualité des données allonge la durée d'entraînement, car le modèle peine à identifier des schémas cohérents, ce qui augmente les coûts sans améliorer les résultats.

Mettez en œuvre des solutions LLM personnalisées grâce à l'IA supérieure
L'optimisation d'un modèle de langage complexe nécessite un ensemble de données approprié, une infrastructure d'entraînement adéquate et un processus d'évaluation pertinent. Dans de nombreux cas, l'adaptation personnalisée du modèle ou l'utilisation de systèmes de recherche d'informations peuvent également être envisagées.
IA supérieure développe des solutions LLM personnalisées pour les entreprises qui ont besoin de capacités d'IA spécifiques à un domaine.
Leur expertise comprend :
- préparation et annotation des jeux de données
- Mise au point et évaluation du modèle
- RAG et architectures hybrides
- déploiement en production des systèmes LLM
Si vous avez besoin d'une solution LLM personnalisée adaptée à vos données et à vos flux de travail, IA supérieure peut soutenir le processus de développement.
Des coûts cachés qui s'accumulent
La facture de votre fournisseur de services cloud ne dit pas tout.
Travail de préparation des données
Le nettoyage, la mise en forme et la validation des données d'entraînement sont très chronophages. Les incohérences des ensembles de données limitent directement les performances du modèle ; une étude sur l'ajustement fin pour la réparation automatisée de programmes (arXiv:2507.19909) indique que les taux de concordance des annotations humaines plafonnent la précision atteignable.
Si les annotateurs ne s'accordent que sur 70% du temps, le modèle ne peut pas dépasser de manière fiable la précision de 70% quel que soit l'investissement dans la formation.
Coûts d'expérimentation
Le réglage fin réussit rarement du premier coup. L'optimisation des hyperparamètres (taux d'apprentissage, taille des lots, nombre d'époques) nécessite plusieurs cycles d'entraînement.
Prévoir un budget pour 3 à 5 itérations minimum. Chaque exécution expérimentale coûte autant que l'entraînement en production.
Validation et évaluation
Pour les méthodes d'ajustement fin par renforcement, la validation pendant l'entraînement engendre des coûts supplémentaires. Les recommandations d'OpenAI concernant la facturation des méthodes RFT mentionnent explicitement la fréquence de validation comme facteur de coût : plus la validation est fréquente, plus la facture est élevée.
Le choix du modèle d'évaluation a également son importance. Utiliser un modèle plus volumineux pour évaluer les points de contrôle d'entraînement coûte plus cher par cycle de validation que d'utiliser des modèles plus petits et plus rapides.
Stockage et déploiement
Les points de contrôle des modèles consomment de l'espace de stockage. Un modèle à 7 milliards de paramètres avec une précision de 16 bits nécessite environ 14 Go d'espace disque par point de contrôle. L'enregistrement de ces points de contrôle à chaque époque, sur plusieurs expériences, représente un espace considérable.
L'infrastructure de déploiement représente un coût permanent. L'auto-hébergement exige la maintenance des nœuds GPU 24h/24 et 7j/7. Le déploiement via API transfère les coûts vers une tarification par jeton.
Analyse comparative des coûts : cloud vs auto-hébergement
La décision de construire ou d'acheter dépend des modes d'utilisation et de l'échelle.
Tarification des fournisseurs de cloud
Les principales plateformes cloud proposent des services de réglage fin gérés et de calcul GPU brut. Ces services gérés simplifient l'infrastructure, mais engendrent des surcoûts. Selon la documentation de Stanford sur les ressources de calcul pour la recherche, le service d'entraînement géré de Together AI a fourni l'exemple de réglage fin à moins de $5, à un coût nettement inférieur à celui d'une infrastructure équivalente gérée en interne.
La location de GPU bruts offre un contrôle accru. Les instances AWS g5.xlarge (NVIDIA A10G) sont disponibles à partir d'environ 1 TP4T1,50 $/heure. Le coût des instances multi-GPU pour les modèles plus importants est proportionnel à la charge : une instance g5.12xlarge avec 4 GPU A10G coûte environ 1 TP4T6 $/heure.
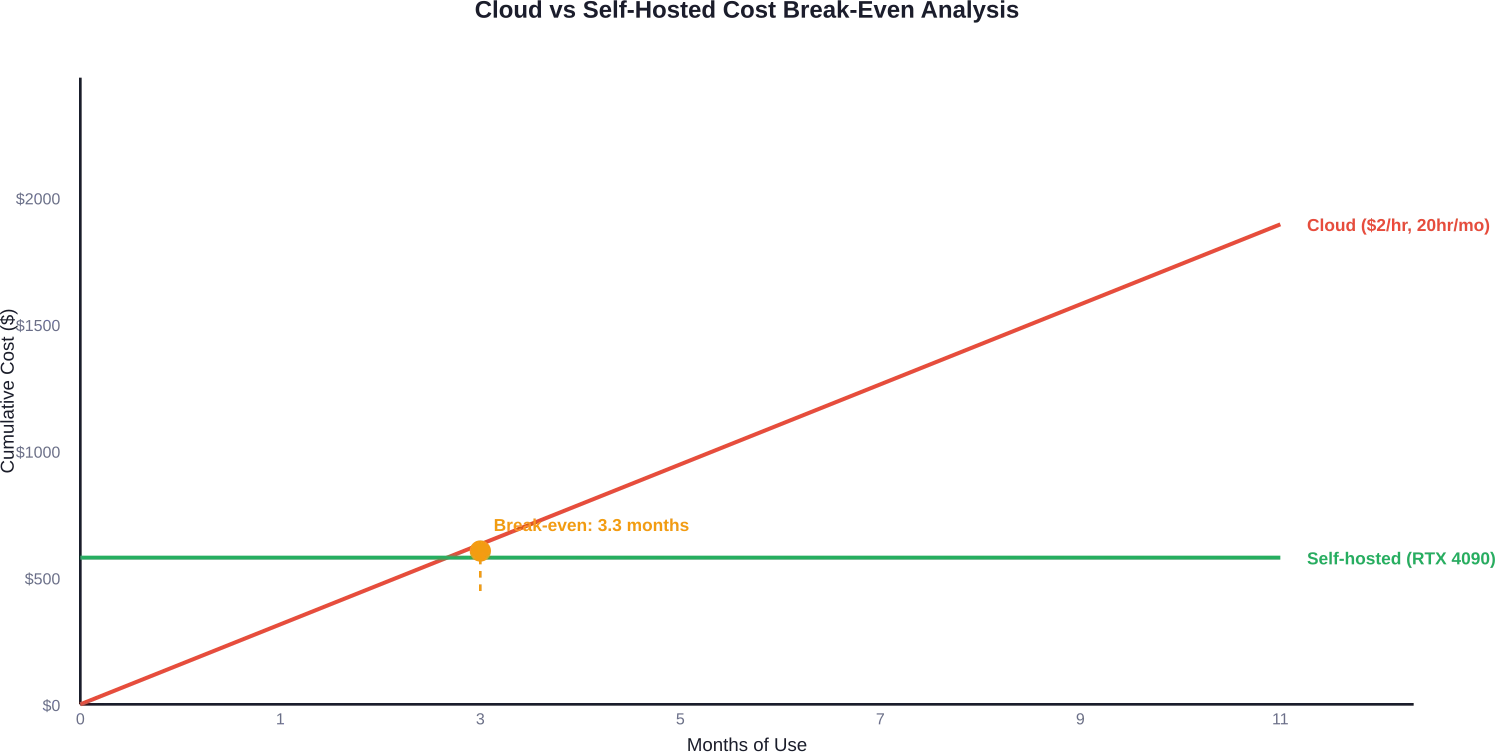
Économie de l'auto-hébergement
Les GPU grand public permettent un réglage fin local pour les modèles plus petits. Une RTX 4060 Ti 16 Go gère 7 milliards de modèles avec LoRa et quantification. Son coût initial atteint 1 200 à 1 600 £, mais il n'y a pas de frais récurrents.
Le calcul est en faveur de l'auto-hébergement lorsque l'utilisation dépasse 15 à 20 heures par mois. Avec un tarif cloud de $2 par heure, 20 heures mensuelles coûtent $480, ce qui signifie qu'un GPU de $1 600 est amorti en moins de quatre mois d'utilisation régulière.
Le cloud offre toutefois une flexibilité pour les charges de travail sporadiques. L'exécution d'une seule tâche de réglage fin mensuelle de quatre heures ($8-$10 sur le cloud) ne justifie pas l'acquisition d'un GPU.
Quand le réglage fin est financièrement judicieux
Tous les cas d'utilisation ne justifient pas un investissement dans un réglage fin.
Calculez votre ligne de base
Comparez les coûts d'optimisation fine avec les alternatives API. Si une tâche nécessite 10 millions de jetons d'inférence par mois, le coût d'une API à $0,001 par tranche de 1 000 jetons s'élève à $10 000 par an. Un investissement unique de $2 000 dans l'optimisation fine, permettant une inférence moins coûteuse avec des modèles plus petits, offre un retour sur investissement en quelques mois.
Mais si une ingénierie rapide permet d'obtenir des résultats acceptables avec un modèle de base, le réglage fin gaspille des ressources.
Fenêtres contextuelles Modifier le calcul
Les modèles modernes prennent en charge des fenêtres de contexte de jetons de 200 000 à 1 million. L’intégration de connaissances du domaine dans les invites élimine le besoin de réglages fins pour de nombreuses applications. Avec la publication de nouveaux modèles de base tous les 4 à 6 mois, la maintenance de versions optimisées représente une dépense récurrente.
Les discussions au sein de la communauté mettent en évidence ce changement : les équipes privilégient de plus en plus les grandes fenêtres de contexte avec des invites bien conçues plutôt que le réglage fin personnalisé, car le passage à des modèles de base améliorés ne nécessite aucun réentraînement.
Les gains de mise au point fine pour
Des scénarios spécifiques privilégient encore un réglage fin :
- Formatage de sortie cohérent que l'invite ne peut pas garantir de manière fiable
- Connaissances spécialisées du domaine non présentes dans les données d'entraînement du modèle de base
- Applications critiques en termes de latence, où des modèles plus petits et finement ajustés surpassent des modèles de base plus grands.
- Inférence à haut volume où les coûts API par jeton dépassent l'investissement initial de formation
- Les exigences de confidentialité empêchent l'utilisation d'API externes
Réduire les coûts de mise au point sans sacrifier la qualité
Plusieurs stratégies permettent de réduire les dépenses tout en préservant les performances.
Commencez petit
Commencez par le plus petit modèle susceptible de convenir. Optimisez un modèle à 3 milliards de paramètres avant d'envisager des variantes à 7 ou 13 milliards de paramètres. Les performances pourraient suffire, et les coûts resteront inférieurs à ceux du $500.
D'après une étude publiée sur arXiv (arXiv:2512.00946) portant sur l'optimisation de modèles linéaires légers pour la classification des sentiments financiers, des modèles à 7-8 milliards de paramètres, dont DeepSeek-LLM 7B, Llama3 8B Instruct et Qwen3 8B, sont comparés à FinBERT sur des jeux de données financières. Les modèles plus petits offrent des résultats exploitables pour des tâches bien définies.
Utiliser LoRa par défaut
Pour tout projet de mise au point, privilégiez LoRA, sauf si des raisons impérieuses exigent une mise au point complète. Le maintien de la qualité du 80-95%, combiné à la réduction des coûts du 70-95%, fait de LoRA le choix par défaut évident.
Le réglage du paramètre de rang permet une optimisation supplémentaire. Les rangs LoRA inférieurs (8 à 16) réduisent les coûts par rapport aux rangs supérieurs (32 à 64) avec un impact minimal sur la précision pour de nombreuses tâches.
Optimiser la durée de l'entraînement
Augmenter le nombre d'époques ne garantit pas de meilleurs résultats. Surveillez la perte de validation et arrêtez l'entraînement dès que l'amélioration stagne. Un arrêt précoce évite un gaspillage de ressources de calcul pour des gains marginaux.
Les recherches du laboratoire d'IA Watson du MIT-IBM sur les lois d'échelle indiquent qu'une précision de 4 % est à peu près la meilleure précision que l'on puisse espérer en raison du bruit aléatoire de la graine, ce qui nécessite une allocation minutieuse du budget de calcul, mais aller au-delà de ce point donne des rendements décroissants à un coût exponentiellement plus élevé.
Organiser les données d'entraînement de manière proactive
Cinq cents exemples de haute qualité valent mieux que cinq mille exemples médiocres. Investissez du temps dans la qualité des données en amont pour réduire le nombre d'itérations d'entraînement nécessaires.
Supprimez les doublons, corrigez les incohérences de formatage et validez les étiquettes. Des données propres permettent un entraînement plus rapide et de meilleurs résultats, réduisant ainsi les délais et les coûts.
Envisagez les services gérés
Le développement de la plateforme coûte parfois moins cher que le temps d'ingénierie. Les services gérés prennent en charge le provisionnement, la surveillance et la gestion des points de contrôle de l'infrastructure. Pour les équipes ne disposant pas d'expertise en infrastructure d'apprentissage automatique, les plateformes gérées comme Together AI ou Hugging Face AutoTrain offrent des résultats plus rapides à moindre coût.
Questions fréquemment posées
Combien coûte le réglage fin de GPT-3.5 ou GPT-4 ?
OpenAI facture en fonction du nombre de jetons d'entraînement. L'optimisation fine de GPT-3.5-turbo coûte environ $0,008 pour 1 000 jetons. Un jeu de données de 100 000 jetons coûte environ $0,80. Le prix de l'optimisation fine de GPT-4 est nettement plus élevé ; consultez la page de tarification officielle d'OpenAI pour connaître les tarifs en vigueur, car ils sont régulièrement mis à jour.
Est-il possible de peaufiner les LLM sur un ordinateur portable ?
Les modèles plus petits (2 à 3 milliards de paramètres) fonctionnent sur des ordinateurs portables haut de gamme dotés de 16 Go ou plus de mémoire unifiée ou de VRAM dédiée, avec une quantification 4 bits et LoRa. L'entraînement est très long : de quelques heures à plusieurs jours selon la taille du jeu de données. Les GPU du cloud restent la solution la plus pratique dans la plupart des cas, mais un réglage fin sur ordinateur portable est techniquement possible à des fins expérimentales.
Le réglage fin est-il moins coûteux que l'utilisation d'appels API à long terme ?
Cela dépend du volume d'inférences. Calculez les coûts mensuels de l'API en fonction de votre utilisation actuelle, puis comparez-les à l'investissement initial pour l'optimisation, auquel s'ajoutent les coûts d'inférence avec votre modèle optimisé. Pour les applications à fort volume (millions de jetons par mois), l'optimisation permet souvent un retour sur investissement en quelques mois. Pour les applications à faible volume ou à des fins expérimentales, les API sont moins coûteuses.
À quelle fréquence dois-je réajuster mon modèle ?
Il est recommandé de procéder à un nouvel ajustement lorsque les modèles de base s'améliorent significativement ou lorsque les performances se dégradent face à de nouveaux types de données. De nombreuses équipes s'abstiennent de tout nouvel ajustement avec les modèles modernes à contexte étendu, préférant mettre à jour les invites lors du passage à des modèles de base plus récents. Il convient d'évaluer si les avantages de l'ajustement fin persistent à mesure que les fenêtres de contexte s'élargissent et que les capacités des modèles de base s'améliorent.
Quelle est la différence entre le coût du réglage fin et le coût de l'inférence ?
Le réglage fin correspond à une dépense ponctuelle d'entraînement permettant de personnaliser le modèle. Les coûts d'inférence désignent les dépenses récurrentes engendrées par chaque prédiction générée par le modèle. Les modèles auto-hébergés imputent ces coûts à une infrastructure fixe, tandis que les modèles basés sur une API facturent par jeton traité. Il convient de prendre en compte ces deux éléments pour calculer le coût total de possession.
Ai-je besoin de plusieurs GPU pour optimiser les LLM ?
Déconseillé pour les modèles de moins de 13 milliards de paramètres avec LoRa et quantification. Une seule carte graphique grand public (RTX 3060 12 Go ou supérieure) prend en charge les modèles de 7 à 8 milliards de paramètres avec les techniques PEFT. L'optimisation complète des modèles plus volumineux ou l'entraînement au-delà de 13 milliards de paramètres nécessitent généralement une configuration multi-GPU, sauf si une quantification extrême est acceptable.
Comment estimer les coûts de mise au point avant de commencer ?
Déterminez la taille du modèle, choisissez la technique d'entraînement (complet ou LoRa), estimez la durée d'entraînement en fonction de la taille du jeu de données et calculez le nombre d'heures GPU nécessaires. Multipliez ce nombre par le tarif de votre fournisseur de cloud. Prévoyez une marge de 30 à 401 Tp3T pour les expérimentations. Commencez par des essais pilotes à petite échelle pour valider les estimations avant d'allouer le budget d'entraînement complet.
Prendre la décision de réglage fin
Les coûts de réglage fin varient sur deux ordres de grandeur en fonction des choix effectués au préalable.
Les équipes performantes commencent par se demander si un réglage fin est nécessaire. Des fenêtres de contexte plus larges et de meilleurs modèles de base permettent de résoudre des problèmes qui exigeaient un réglage fin il y a quelques mois à peine. Lorsque le réglage fin s'avère nécessaire, des techniques économes en paramètres comme LoRa rendent les modèles personnalisés accessibles avec des budgets inférieurs à $100 pour la plupart des cas d'utilisation.
Ces échecs coûteux présentent des caractéristiques communes : omission de la validation de la qualité des données, choix de modèles surdimensionnés et exécution d’un réglage fin complet alors que LoRA suffirait.
Soyons francs : prévoyez un budget pour l’expérimentation. Le premier cycle d’entraînement donne rarement des résultats exploitables en production. Prévoyez 3 à 5 itérations, surveillez attentivement les coûts et optimisez sans relâche.
Prêt à optimiser votre configuration en respectant votre budget ? Commencez par le modèle le plus simple possible, utilisez LoRa par défaut et validez la qualité des données avant d’investir dans la puissance de calcul. Votre premier essai réussi d’optimisation sera plus instructif que n’importe quel guide.