Résumé rapide : Le suivi des coûts des applications LLM nécessite une surveillance en temps réel de l'utilisation des jetons, de la sélection des modèles et des schémas de requêtes afin d'éviter les dépassements budgétaires. Des outils de pointe comme Datadog LLM Observability, Langfuse et les solutions cloud natives d'AWS Bedrock et d'OpenAI permettent l'attribution des coûts, l'analyse de l'utilisation et des recommandations d'optimisation. Un suivi efficace combine les plateformes d'observabilité avec des pratiques stratégiques telles que l'optimisation rapide, la sélection des modèles et la mise en cache.
À mesure que les applications d'IA générative passent du prototype à la production, les coûts des jetons peuvent s'envoler. Une simple chaîne de requêtes non optimisée peut décupler les dépenses, et sans visibilité en temps réel sur les habitudes d'utilisation, les équipes ne découvrent souvent les dépassements budgétaires qu'à la réception de la facture.
Le suivi traditionnel des coûts du cloud ne suffit pas pour les applications LLM. Les modèles de tarification basés sur les jetons nécessitent une observabilité spécialisée qui suit non seulement le temps de calcul, mais aussi les jetons d'entrée, les jetons de sortie, la sélection du modèle et la fréquence des requêtes auprès de différents fournisseurs.
Cela crée un défi fondamental : comment les équipes peuvent-elles maintenir une visibilité sur les coûts LLM sans sacrifier la vitesse de développement ni les performances de l'application ?
Pourquoi le suivi des coûts des LLM est important
Le modèle de tarification par jetons modifie fondamentalement la façon dont les coûts des applications évoluent. Contrairement aux infrastructures traditionnelles où les coûts sont corrélés à la disponibilité du serveur, les dépenses LLM dépendent du volume et de la complexité de chaque requête.
D'après la documentation AWS publiée en octobre 2025 (Créer un système proactif de gestion des coûts liés à l'IA pour Amazon Bedrock), les entreprises rencontrent des difficultés pour maîtriser les coûts associés à la tarification par jetons, ce qui peut entraîner des factures inattendues si l'utilisation n'est pas surveillée de près. Les méthodes traditionnelles, telles que les alertes budgétaires et la détection des anomalies de coûts, réagissent souvent trop tard.
Voici ce qui différencie la gestion des coûts LLM :
- La consommation de jetons varie énormément en fonction de la longueur de l'invite et de la complexité de la réponse.
- Les différents modèles affichent des prix très différents (Amazon Nova Micro coûte $0,000035 pour 1 000 jetons d'entrée et $0,00014 pour 1 000 jetons de sortie, contre des modèles plus grands à des tarifs plus élevés).
- Les flux de travail d'agents en plusieurs étapes augmentent les coûts par le biais de multiples appels LLM
- Les modèles d'utilisation en production correspondent rarement aux estimations de développement
Soyons francs : la plupart des équipes ne découvrent leurs problèmes de coûts qu’après avoir accumulé des milliers d’euros de dépenses. Un suivi proactif permet d’éviter complètement ce scénario.
Comprendre l'économie des jetons
La tarification des jetons n'est pas uniforme selon les modèles ou les fournisseurs. Son fonctionnement économique dépend fortement du modèle de base utilisé par l'application et de la structure des requêtes.
La documentation d'OpenAI indique que les jetons audio dans les messages utilisateur comptent pour 1 jeton toutes les 100 ms, tandis que les messages de l'assistant utilisent 1 jeton toutes les 50 ms. Ces variations sont importantes pour le développement d'applications multimodales.
Les modèles d'Amazon Nova illustrent clairement l'éventail des prix. Comme indiqué dans les documents AWS de juin 2025 :
| Modèle | Jetons d'entrée (pour 1 000) | Jetons de sortie (pour 1 000) |
|---|---|---|
| Amazon Nova Micro | $0.000035 | $0.00014 |
| Variantes Nova plus grandes | taux plus élevés | Échelle proportionnelle |
Le modèle le plus imposant n'est pas toujours nécessaire pour chaque tâche. L'adéquation des capacités du modèle à la complexité du cas d'utilisation a un impact direct sur les coûts.
Anthropic propose une API d'utilisation et de coûts qui permet d'accéder par programmation aux données de dépenses de l'organisation. Cela permet aux équipes de créer des tableaux de bord personnalisés et des systèmes de contrôle des coûts automatisés.

Mettre en œuvre des systèmes de surveillance LLM
Les applications LLM nécessitent une surveillance pour suivre leur utilisation, leurs performances et leur stabilité opérationnelle.
IA supérieure conçoit des outils de surveillance et de gestion pour les systèmes d'IA de production, aidant les organisations à exploiter plus efficacement les applications basées sur LLM.
Leurs travaux de développement peuvent inclure :
- systèmes de suivi de l'utilisation
- analyse rapide et réactive
- surveillance de l'infrastructure
- outils d'optimisation des systèmes d'IA
IA supérieure aide les équipes à faire passer les applications LLM du prototype à des environnements de production stables.
Composantes essentielles du suivi des coûts du LLM
Les systèmes de surveillance efficaces suivent simultanément de multiples dimensions. L'utilisation des jetons à elle seule ne donne pas une image complète.
Suivi de l'utilisation des jetons
Chaque requête génère des jetons d'entrée et de sortie. Les systèmes de surveillance doivent capturer ces deux dimensions et les attribuer à des utilisateurs, des fonctionnalités ou des flux de travail spécifiques.
Le nombre de jetons d'entrée dépend des choix de conception des invites. Des invites système trop verbeuses ou une injection de contexte excessive augmentent le coût par requête. Le nombre de jetons de sortie varie selon les paramètres du modèle, comme la température et le paramètre max_tokens.
La documentation d'Apigee de Google souligne l'importance des politiques de jetons LLM pour la maîtrise des coûts, en s'appuyant sur les indicateurs d'utilisation des jetons afin d'appliquer des limites et d'assurer une surveillance en temps réel. La plateforme permet de définir des limites de jetons immédiates, par exemple en limitant les requêtes à 1 000 jetons par minute.
Attribution de la sélection du modèle
Les applications utilisant plusieurs modèles nécessitent une attribution des coûts par type de modèle. Une décision de routage qui envoie des requêtes simples à un modèle coûteux engendre un gaspillage de budget.
Les stratégies de modélisation en cascade permettent d'optimiser les coûts en privilégiant d'abord les modèles les moins coûteux et en n'utilisant des modèles plus onéreux qu'en cas de nécessité. Le système de surveillance doit permettre de suivre le modèle ayant traité chaque requête et l'écart de coût associé.
Analyse des modèles de requêtes
L'analyse des tendances temporelles révèle des opportunités d'optimisation. Le traitement par lots en dehors des heures de pointe, la limitation du nombre de requêtes lors des pics de trafic et l'identification des appels redondants nécessitent tous des données historiques sur les tendances.
Des tests AWS documentés en octobre 2025 ont montré des temps d'exécution des flux de travail allant de 6,76 à 32,24 secondes en fonction des exigences relatives aux jetons de sortie. La compréhension de ces tendances facilite la planification des capacités.
Meilleurs outils de suivi des coûts des LLM
Plusieurs plateformes se sont imposées comme leaders en matière d'observabilité et de gestion des coûts LLM. Chacune présente des atouts différents selon son architecture de déploiement et son écosystème de fournisseurs.
Observabilité Datadog LLM
La plateforme Datadog s'intègre aux principaux fournisseurs de solutions LLM, notamment OpenAI, Anthropic et Amazon Bedrock, comme indiqué dans la documentation relative aux partenariats AWS. La documentation AWS de juillet 2025 (Surveillance des agents déployés sur Amazon Bedrock avec Datadog LLM Observability) explique comment Datadog assure la surveillance des agents déployés sur Bedrock grâce à des fonctionnalités d'observabilité complètes.
La plateforme centralise le suivi de l'utilisation des jetons, de la latence et des coûts de tous les appels LLM. Les traces permettent de visualiser les flux de travail complexes des agents, illustrant ainsi l'accumulation des coûts au sein de chaînes d'opérations complexes.
Ses principales fonctionnalités incluent l'attribution des coûts en temps réel, le suivi des performances et la détection des anomalies. Les équipes peuvent configurer des alertes budgétaires et visualiser l'évolution des dépenses au fil du temps.
Les tarifs varient en fonction du volume d'utilisation, avec des forfaits entreprise personnalisés disponibles pour les déploiements à grande échelle.
Langfuse
Langfuse propose une solution open source d'observabilité LLM avec possibilité d'auto-hébergement. La plateforme offre des vues basées sur les sessions qui regroupent les requêtes LLM connexes, facilitant ainsi la compréhension des parcours utilisateurs.
Langfuse se distingue par une observabilité renforcée des chaînes d'exécutions et des flux de travail d'agents. Le traçage hiérarchique met en évidence les relations parent-enfant entre les appels LLM, tandis que le suivi des coûts attribue les dépenses à des traces ou sessions spécifiques.
Les discussions au sein de la communauté soulignent que si l'option auto-hébergée offre un contrôle total, la version cloud commence à $29/mois avec une tarification basée sur l'utilisation au-delà du niveau de base, une option auto-hébergée gratuite étant disponible.
Outils natifs Amazon Bedrock
AWS a intégré la gestion des coûts directement dans Bedrock. La documentation d'octobre 2025 décrit un système proactif de gestion des coûts basé sur l'IA, qui va au-delà des alertes budgétaires traditionnelles.
Le flux de travail garantit des schémas d'exécution cohérents lors du traitement de requêtes de durée variable (de 6,76 à 32,24 secondes selon les exigences relatives aux jetons de sortie). Grâce à cette intégration native, aucune plateforme d'observabilité supplémentaire n'est requise pour les charges de travail Bedrock.
Les stratégies d'optimisation des coûts documentées en juin 2025 mettent l'accent sur le choix du modèle comme levier principal. Choisir la bonne variante du modèle Nova permet de réduire considérablement les coûts sans compromettre la qualité de l'application.
Outils de gestion des coûts d'OpenAI
OpenAI propose un suivi natif de l'utilisation via le tableau de bord de l'API et un accès programmatique via des points de terminaison d'utilisation. La documentation de l'API en temps réel explique la répartition des coûts selon les différentes modalités : texte, audio et images.
Le calcul des jetons audio varie selon le type de message (1 jeton toutes les 100 ms pour les messages utilisateur, 1 jeton toutes les 50 ms pour les messages de l'assistant). Comprendre ces différences permet d'éviter les surfacturations dans les applications vocales.
La plateforme propose des limites budgétaires et des seuils de notification configurables au niveau de l'organisation et du projet.
API d'utilisation et de coût anthropique
L'approche d'Anthropic offre un accès programmatique aux données d'utilisation de l'organisation via une API dédiée. Ceci permet des intégrations personnalisées de suivi des coûts sans dépendre de plateformes tierces.
La documentation Claude Code d'Anthropic indique que la commande `/cost` fournit des statistiques détaillées sur l'utilisation des jetons, notamment le coût total (exemple : $0.55), la durée d'utilisation de l'API et les modifications de code. Ces données précises permettent aux développeurs de comprendre exactement ce qui influence les dépenses dans leurs applications.
La limitation du débit et le contrôle des dépenses d'équipe permettent aux administrateurs de plafonner l'utilisation au niveau de l'organisation.
Solutions de surveillance natives du cloud
Les principaux fournisseurs de services cloud ont intégré le suivi des coûts LLM à leurs plateformes d'observabilité plus larges.
Azure Monitor
La surveillance d'Azure s'étend aux déploiements d'Azure OpenAI Service. La plateforme suit la consommation de jetons, les taux de requêtes et les coûts pour tous les modèles déployés.
L'intégration avec Azure Cost Management offre une visibilité unifiée sur les dépenses d'infrastructure et de gestion des licences, facilitant ainsi la compréhension des coûts totaux des applications.
Google Cloud et Apigee
L'approche de Google repose sur les politiques de jetons Apigee LLM pour le contrôle des coûts. Ces politiques imposent des limites basées sur les indicateurs d'utilisation des jetons et permettent une surveillance en temps réel de la consommation des jetons.
La documentation explique comment mettre en œuvre des limites de débit, par exemple 1 000 jetons par minute, à l'aide des politiques PromptTokenLimit. Cela permet d'éviter une explosion des coûts due à des pics de trafic inattendus.
Infrastructure du visage étreint
La grille tarifaire de Hugging Face, publiée en janvier 2026, présente une gamme allant de la version gratuite aux solutions pour entreprises. La facturation des points de terminaison d'inférence est basée sur le temps de calcul multiplié par le prix du matériel.
Une requête exécutée en 10 secondes sur un GPU, dont le coût est de $0,00012 par seconde, entraîne une facturation de $0,0012, conformément aux directives tarifaires de Hugging Face. La compréhension de ce modèle de temps de calcul diffère de la tarification par jetons et requiert des méthodes de surveillance différentes.
La plateforme propose des tableaux de bord d'utilisation affichant la consommation de calcul, mais les discussions de la communauté datant d'avril 2025 révèlent une certaine confusion quant à la conversion du temps d'exécution en coûts exacts. Une meilleure documentation de la formule de conversion serait utile.
| Plate-forme | Modèle de tarification | Fonctionnalités de surveillance | Idéal pour |
|---|---|---|---|
| Datadog | Basé sur l'utilisation | Observabilité unifiée, traces, alertes | Environnements multi-fournisseurs |
| Langfuse | Hébergement gratuit sur soi-même, cloud $29+ | Suivi de session, traces hiérarchiques | préférence pour les logiciels libres |
| AWS Bedrock | Inclus avec le service | Intégration native, modèles de requêtes | Déploiements natifs AWS |
| OpenAI Native | Compris | Tableau de bord d'utilisation, accès à l'API | Applications exclusives à OpenAI |
| API anthropologique | Compris | données sur les coûts programmatiques | Applications basées sur Claude |
Stratégies d'optimisation des coûts
La surveillance permet d'identifier les problèmes. L'optimisation les corrige. Plusieurs stratégies permettent de réduire systématiquement les coûts LLM sans compromettre la fonctionnalité.
Ingénierie rapide
Des invites concises réduisent le nombre de jetons d'entrée. Les recherches montrent qu'un code mal structuré entraîne une consommation de jetons nettement supérieure lors de l'inférence par rapport à un code propre, avec une consommation médiane de 28,13 jetons pour le code propre contre 33,30 pour le code mal structuré.
Supprimer les informations superflues, utiliser des instructions claires et structurer efficacement les invites permettent de réduire le coût par requête. Tester différentes formulations d'invites et mesurer l'utilisation des jetons permet d'identifier les approches les plus efficaces.
Sélection du modèle
Les modèles dédiés à une tâche spécifique sont souvent plus performants que les modèles génériques en termes de rapport coût-efficacité. La documentation AWS souligne que le modèle le plus volumineux n'est pas toujours nécessaire pour chaque application.
Une approche par cascade consiste à tester d'abord des modèles moins coûteux et à passer à des modèles plus performants uniquement lorsque la précision chute en dessous des seuils prédéfinis. Cela permet d'équilibrer dynamiquement le coût et la qualité.
Les recherches sur l'analyse coûts-avantages définissent la parité de performance comme des scores de référence dans 20% des meilleurs modèles commerciaux, reflétant les normes d'entreprise où de petits écarts de précision sont compensés par des avantages en termes de coûts, de sécurité et d'intégration.
Stratégies de mise en cache
La mise en cache des réponses aux requêtes répétées élimine complètement les appels LLM redondants. La mise en cache sémantique va plus loin en reconnaissant les requêtes similaires (et non simplement identiques) et en renvoyant les réponses mises en cache.
La documentation d'OpenAI sur l'optimisation des coûts met en avant la mise en cache comme stratégie principale. L'API Batch et le traitement flexible offrent des mécanismes supplémentaires de réduction des coûts pour les charges de travail non critiques en termes de temps.
Limitation stratégique
La limitation du débit permet d'éviter les pics de coûts lors de pics de trafic imprévus. Les politiques de jetons d'Apigee imposent des limites qui protègent contre les dépenses excessives.
Les architectures à base de files d'attente absorbent les pics de trafic sans augmenter immédiatement l'utilisation de la mémoire LLM. Cela implique une certaine latence en échange de coûts prévisibles.
Meilleures pratiques de mise en œuvre
Le déploiement du suivi des coûts nécessite à la fois une intégration technique et un processus organisationnel.
Approche d'instrumentation
L'instrument LLM effectue des appels au niveau du SDK plutôt que de tenter d'extraire des données des tableaux de bord des fournisseurs. L'intégration directe capture les métadonnées des requêtes, telles que les identifiants utilisateur, les indicateurs de fonctionnalités et les contextes de session, permettant ainsi une attribution précise des coûts.
La plupart des plateformes d'observabilité proposent des kits de développement logiciel (SDK) ou des intégrations OpenTelemetry qui capturent automatiquement les traces. L'instrumentation manuelle offre un contrôle plus précis, mais exige un effort d'ingénierie plus important.
Configuration des alertes
Configurez des alertes à plusieurs niveaux en fonction des seuils de dépenses absolus et des augmentations en pourcentage. Une alerte budgétaire quotidienne de $100 détecte les augmentations progressives, tandis qu'une alerte d'augmentation horaire de 200% détecte les pics soudains.
La détection des anomalies de coûts AWS fonctionne pour l'infrastructure, mais réagit souvent trop tard pour les coûts basés sur les jetons. La surveillance en temps réel assurée par des plateformes d'observabilité LLM spécialisées permet de détecter les problèmes plus rapidement.
Éducation d'équipe
Les développeurs ont besoin de visibilité sur les conséquences financières de leurs choix. Afficher le nombre de jetons et les coûts estimés pendant le développement contribue à une meilleure compréhension des coûts.
La documentation de Claude Code indique que la commande /cost fournit des statistiques au niveau de la session, notamment le coût total, la durée et les modifications de code. L'intégration de boucles de rétroaction similaires dans les outils internes permet de prendre de meilleures décisions.
Audits réguliers
Les analyses mensuelles des coûts permettent d'identifier les pistes d'optimisation et de vérifier le bon fonctionnement des contrôles. Le suivi du coût par utilisateur, par fonctionnalité et par transaction révèle les principaux postes de dépenses.
La comparaison des coûts réels avec les estimations initiales met en évidence les lacunes de la planification et améliore les prévisions futures.
Mesurer le retour sur investissement et le succès
Le suivi des coûts exige du temps et des ressources. Les équipes ont besoin d'indicateurs clairs pour justifier cet investissement.
Les principaux indicateurs de performance comprennent :
- Coût par fonction d'application ou session utilisateur
- Réduction en pourcentage de la consommation de jetons après optimisation
- Délai moyen de détection des anomalies de coûts
- Écart entre les dépenses prévues et les dépenses réelles
Les recherches sur les agents efficaces ont atteint 96,7% de la performance d'OWL tout en réduisant les coûts opérationnels de $0,398 à $0,228, ce qui a permis une amélioration de 28,4% du coût de passage (d'après arXiv : Efficient Agents).
L'objectif n'est pas de minimiser les coûts à tout prix, mais de maximiser la valeur ajoutée pour chaque dollar dépensé. Parfois, des coûts plus élevés engendrent une valeur proportionnellement plus importante.
Pièges courants à éviter
Plusieurs erreurs compromettent systématiquement les efforts de suivi des coûts.
Un suivi isolé, sans optimisation, est un gaspillage d'efforts. Des données sans décisions ne permettent pas de réduire les dépenses. Mettez en place des boucles de rétroaction qui transforment les observations en changements rapides, en choix de modèles ou en améliorations d'architecture.
Une sur-optimisation trop précoce ralentit le rythme des itérations. Attendez que les habitudes d'utilisation se stabilisent avant d'optimiser de manière intensive. Une optimisation prématurée basée sur l'utilisation du prototype reflète rarement la réalité en production.
Négliger les coûts d'opportunité a aussi des conséquences. Le temps que les développeurs consacrent à optimiser une dépense de $50/mois peut coûter plus cher que le simple paiement de la facture. Concentrez vos efforts d'optimisation là où les dépenses sont les plus importantes.
Négliger les compromis liés à la latence engendre de nouveaux problèmes. Un cache trop agressif ou une sélection trop restrictive des modèles peuvent certes réduire les coûts, mais augmenter les temps de réponse au point de nuire à l'expérience utilisateur. Il est donc essentiel de surveiller simultanément ces deux aspects.
Tendances futures en matière de gestion des coûts des LLM
Le paysage du suivi des coûts continue d'évoluer rapidement à mesure que la technologie mûrit.
Les contraintes de coût probabilistes constituent une approche émergente. Les recherches menées sur ArXiv concernant les cascades de modèles optimisées décrivent C3PO, un système qui optimise la sélection des modèles logiques à long terme (LLM) en utilisant des contraintes de coût probabilistes pour les tâches de raisonnement. Cette approche va au-delà des simples seuils et aboutit à une optimisation sophistiquée du compromis coût-qualité.
Le routage multi-fournisseurs basé sur la tarification en temps réel va se généraliser. À mesure que les capacités des modèles convergent, la concurrence par les prix s'intensifie. Les systèmes qui acheminent dynamiquement les requêtes vers le fournisseur le moins cher offrant une qualité suffisante bénéficieront d'un avantage concurrentiel.
Le matériel spécialisé pour l'inférence continue d'améliorer le rapport prix-performances. Selon les documents tarifaires de Hugging Face, les instances Intel Sapphire Rapids x1 sont disponibles à partir de $0,033 €/heure (à la date de publication). Les accélérateurs d'IA personnalisés proposés par les fournisseurs de cloud contribuent à la baisse des coûts.
Mais attention ! Baisser les prix de base ne supprime pas le besoin de suivi. Cela déplace simplement l’attention de l’optimisation des dépenses brutes vers des indicateurs d’efficacité comme le coût par tâche accomplie avec succès.
Questions fréquemment posées
Comment calculer le coût d'une requête API LLM ?
Multipliez le nombre de jetons d'entrée par le prix du jeton d'entrée du modèle, puis ajoutez le nombre de jetons de sortie multiplié par leur prix. Par exemple, avec Amazon Nova Micro ($0,000035 pour 1 000 jetons d'entrée et $0,00014 pour 1 000 jetons de sortie), une requête avec 500 jetons d'entrée et 1 500 jetons de sortie coûte approximativement $0,0000175 + $0,00021 = $0,0002275.
Quelle est la différence entre la surveillance LLM et l'APM traditionnelle ?
La surveillance traditionnelle des performances des applications se concentre sur les indicateurs d'infrastructure tels que le processeur, la mémoire et la latence des requêtes. La surveillance LLM ajoute la consommation de jetons, la sélection du modèle, les schémas d'invite et l'attribution des coûts spécifiques aux charges de travail d'IA générative. De nombreuses plateformes intègrent désormais ces deux fonctionnalités.
Puis-je suivre les coûts auprès de plusieurs fournisseurs de LLM ?
Oui. Des plateformes comme Datadog LLM Observability prennent en charge plusieurs fournisseurs, dont OpenAI, Anthropic et Amazon Bedrock, au sein d'un tableau de bord unifié. Cela permet de comparer les coûts et de mettre en œuvre des stratégies de routage multi-fournisseurs.
Combien d'économies l'optimisation des coûts peut-elle réellement permettre de réaliser ?
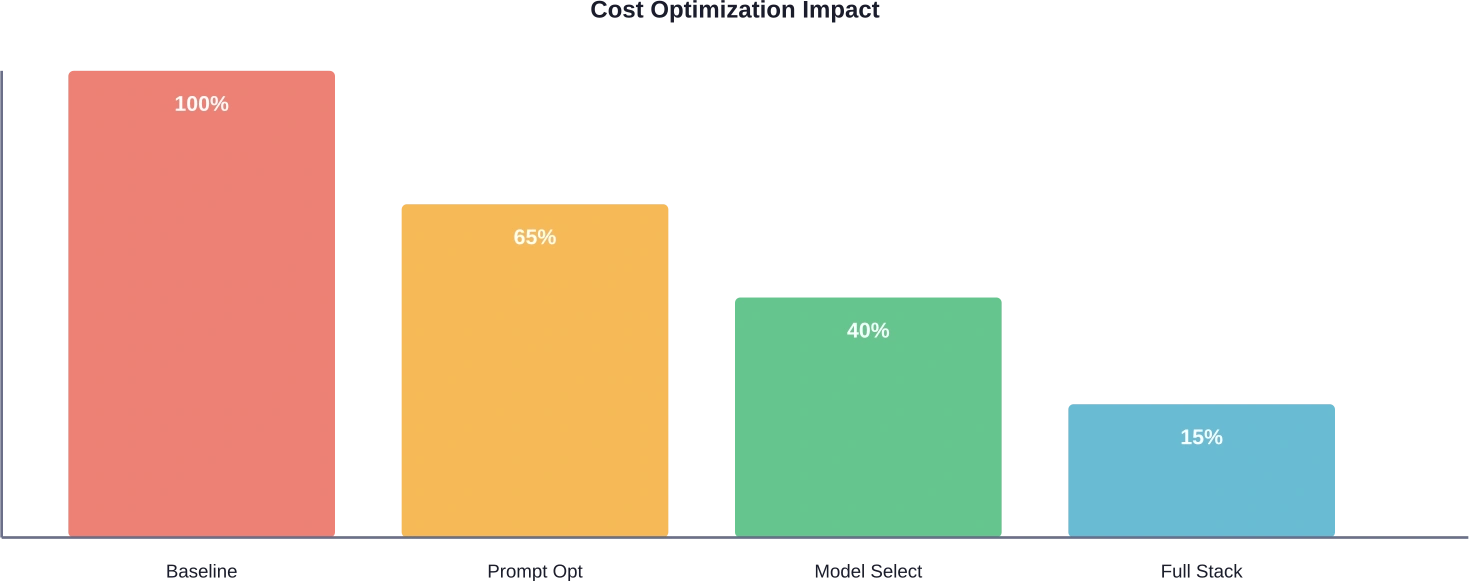
Les résultats d'optimisation varient selon l'application. Les tests AWS ont démontré des économies potentielles allant jusqu'à 901 TP3T pour le workflow Step Functions Express par rapport au workflow Standard, pour une même charge de travail. Une ingénierie rapide permet généralement de réduire les coûts de 20 à 401 TP3T, la sélection du modèle de 30 à 501 TP3T supplémentaires, et la mise en cache élimine totalement les appels redondants. Les économies exactes dépendent de l'efficacité initiale et de l'effort d'optimisation.
Devrais-je héberger moi-même les modèles pour réduire les coûts ?
L'auto-hébergement se justifie à grande échelle. Une étude d'ArXiv sur l'analyse coûts-avantages montre que le seuil de rentabilité dépend du volume d'utilisation, des capacités techniques et de la possibilité d'atteindre des performances équivalentes aux modèles commerciaux. Pour de nombreuses organisations, les services gérés restent plus rentables si l'on tient compte du temps d'ingénierie.
À quelle fréquence dois-je examiner les coûts d'un LLM ?
Consultez quotidiennement les tableaux de bord en temps réel lors du déploiement initial afin de détecter rapidement les problèmes de configuration. Procédez à des analyses de coûts détaillées chaque semaine pendant la phase de développement et chaque mois une fois l'utilisation stabilisée. Configurez des alertes automatisées pour les anomalies plutôt que de vous fier uniquement aux analyses planifiées.
Quels sont les indicateurs les plus importants pour la gestion des coûts des programmes LLM ?
Suivez le coût par session utilisateur, le coût par tâche accomplie avec succès, l'efficacité des jetons (valeur de sortie par jeton) et l'écart de coût par rapport au budget. Ces indicateurs permettent de relier directement les dépenses aux résultats commerciaux, au lieu de considérer les coûts comme de simples frais d'infrastructure abstraits.
Poursuite du suivi des coûts des LLM
La gestion des coûts des applications LLM exige une visibilité continue, une optimisation stratégique et une rigueur organisationnelle. Le modèle de tarification par jetons diffère fondamentalement des coûts d'infrastructure traditionnels et requiert des approches de suivi spécialisées.
Commencez par utiliser les outils de surveillance natifs de fournisseurs comme OpenAI, Anthropic ou AWS Bedrock. Ces fonctionnalités intégrées offrent une visibilité de base sans frais supplémentaires. À mesure que vos applications évoluent, envisagez des plateformes d'observabilité dédiées telles que Datadog ou Langfuse pour bénéficier de fonctionnalités avancées comme la prise en charge de plusieurs fournisseurs et des alertes sophistiquées.
La véritable valeur ajoutée réside dans la mise en œuvre concrète du suivi. Il s'agit de contrôler les coûts, d'identifier les opportunités d'optimisation grâce à une ingénierie et une sélection de modèles rapides, et de mesurer l'impact des modifications. Mettez en place des boucles de rétroaction permettant aux développeurs d'appréhender les implications financières dès la phase de développement, plutôt que de découvrir les problèmes en production.
L'optimisation des coûts ne consiste pas à minimiser les dépenses à tout prix. Il s'agit de maximiser la valeur ajoutée pour chaque euro dépensé, tout en maintenant des normes de qualité et de performance élevées. Une infrastructure de surveillance adéquate permet d'atteindre cet équilibre.
Prêt à maîtriser vos dépenses LLM ? Commencez dès aujourd’hui par instrumenter vos applications avec un suivi basique des jetons. De petites améliorations auront un impact rapide lorsqu’elles seront appliquées systématiquement à tous les appels LLM.