Résumé rapide : Le code asynchrone peut réduire considérablement les coûts LLM lorsqu'il est correctement implémenté, mais des écueils courants, comme le déclenchement de requêtes en amont, peuvent annuler les économies réalisées. Des modèles asynchrones stratégiques, associés à des techniques telles que la mise en cache des requêtes, le traitement par lots et la concurrence contrôlée, peuvent réduire les coûts de 60 à 901 TP3 T tout en maintenant les performances. Le prix du modèle o3 d'OpenAI a chuté de 801 TP3 T à 1 TP4 T2-8 par million de jetons en juin 2025, rendant une implémentation asynchrone appropriée encore plus rentable.
Les coûts liés au LLM peuvent s'envoler plus vite que la plupart des équipes ne le prévoient. Ce qui commence par quelques scripts de validation ou flux de travail automatisés se transforme rapidement en des milliers d'appels API qui font exploser les budgets à une vitesse alarmante.
Le problème, c'est que la programmation asynchrone promet de rendre tout plus rapide et plus efficace. Mais mal implémentée, elle peut en réalité… augmenter vos coûts tout en donnant l'illusion d'une optimisation.
Le problème ? Des schémas subtils dans le code asynchrone qui déclenchent toutes les requêtes d'emblée, même lorsque les processus en aval s'arrêtent prématurément ou n'ont besoin que de résultats partiels. D'après les discussions sur les forums de développeurs OpenAI, ceux qui passent d'implémentations synchrones à des implémentations asynchrones constatent fréquemment des pics de coûts inattendus, malgré des temps d'exécution plus rapides.
Le piège des coûts cachés dans le code LLM asynchrone
Le code asynchrone semble être le choix idéal pour les applications LLM. Envoyez plusieurs requêtes simultanément, traitez les résultats au fur et à mesure de leur arrivée et poursuivez l'exécution. Résultat : une exécution plus rapide et des utilisateurs plus satisfaits.
Mais un piège se cache dans les modèles asynchrones les plus courants.
Lorsque les fonctions asynchrones créent tous leurs appels API en amont (en les encapsulant dans des tâches ou des promesses avant l'exécution de toute logique de traitement), chaque requête atteint les serveurs du fournisseur LLM. Même si votre logique de validation s'arrête après le premier échec. Même si l'utilisateur annule en cours de route. Même si vous n'aviez besoin que de trois résultats, mais que vous en avez mis cinquante en file d'attente.
Les demandes ont déjà été envoyées. Les jetons sont en cours de traitement. La facture s'alourdit.
Comment fonctionne le licenciement par demande préalable
Prenons l'exemple d'un script de validation qui vérifie les réponses LLM par rapport à des critères de qualité. Une implémentation asynchrone simple pourrait ressembler à ceci :
| fonction asynchrone validate_responses(prompts): tâches = [call_llm_api(prompt) pour prompt dans prompts] pour la tâche dans les tâches : résultat = tâche en attente si le résultat ne répond pas aux critères : renvoyer Faux renvoyer Vrai |
Vous avez repéré le problème ? La compréhension de liste à la ligne 2 crée immédiatement toutes les tâches d’appel API, avant même le début de la boucle et avant toute validation.
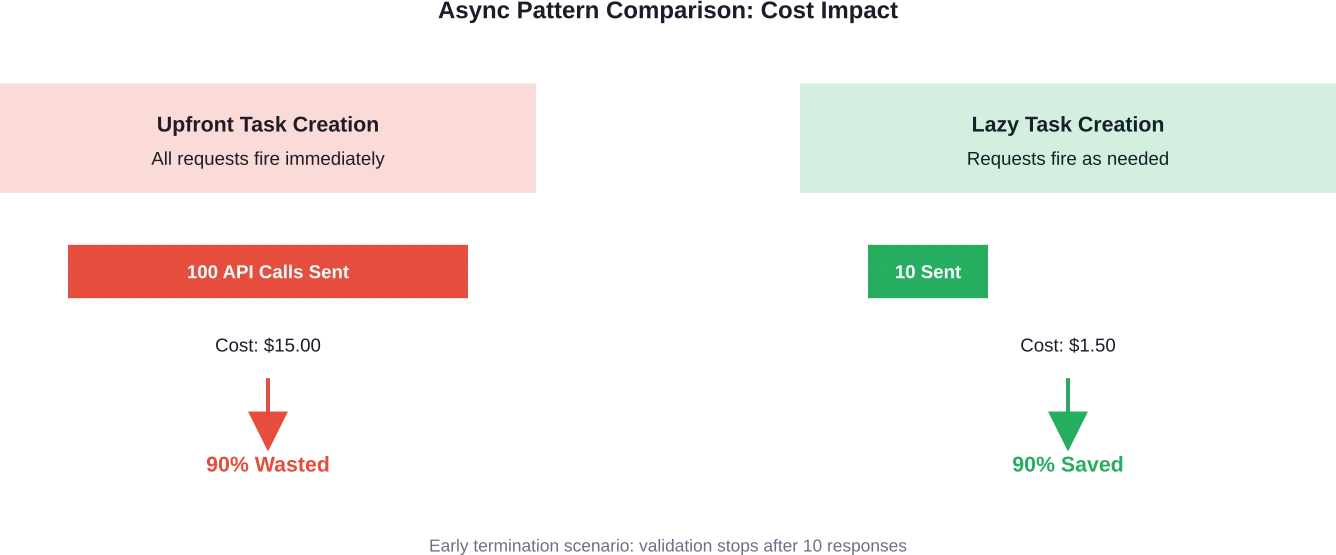
Si le premier résultat ne passe pas la validation, la fonction renvoie False, mais quarante-neuf autres appels API sont déjà en cours, consomment déjà des jetons et génèrent déjà des coûts.
Impact réel sur les coûts
Une équipe de développement a découvert ce problème lorsque son script de validation LLM s'exécutait rapidement mais générait des factures anormalement élevées. Malgré la mise en œuvre d'un code asynchrone apparemment efficace, ils traitaient dix fois plus de jetons que nécessaire.
La solution ? Cinq lignes de code qui ont restructuré la création et l’attente des tâches. Au lieu de créer toutes les tâches en amont, leur création a été déplacée à l’intérieur de la boucle, permettant ainsi une interruption anticipée et évitant les appels API inutiles.
Résultat : Réduction des coûts du 90% sans perte notable de vitesse ni de fonctionnalités.
Concurrence contrôlée : la solution des sémaphores
La correction du déclenchement initial des requêtes est la première étape. Mais il existe un autre modèle asynchrone qui influe à la fois sur les coûts et les performances : la concurrence incontrôlée.
Lorsque des applications envoient des centaines ou des milliers de requêtes LLM simultanées, elles créent plusieurs problèmes :
- Limitation du débit entraînant des tentatives de nouvelle connexion et des délais
- Latence irrégulière due aux difficultés rencontrées par l'infrastructure du fournisseur pour gérer les pics de charge.
- Les demandes ayant échoué et nécessitant un retraitement entraînent un doublement des coûts.
- Pression sur la mémoire due à la gestion d'un trop grand nombre de connexions simultanées
La solution repose sur les sémaphores asyncio, un mécanisme de contrôle de la concurrence qui limite le nombre de requêtes exécutées simultanément.
Mise en œuvre de la limitation de débit basée sur les sémaphores
D'après les discussions au sein de la communauté OpenAI, les développeurs qui implémentent le contrôle de concurrence via un sémaphore asyncio limité à 5 appels simultanés constatent des performances plus stables. Bien que cela ne réduise pas directement la consommation de jetons, cela évite l'enchaînement d'échecs et de tentatives qui font grimper les coûts.
| importer asyncio async def controlled_llm_call(semaphore, prompt): asynchrone avec sémaphore : retourner attendre call_llm_api(prompt) async def process_batch(prompts): sémaphore = asyncio.Sémaphore(5) tâches = [appel_llm_contrôlé(sémaphore, p) pour p dans invites] retourner attendre asyncio.gather(*tasks) |
Ce modèle garantit que seulement cinq requêtes s'exécutent simultanément, réduisant ainsi les dépassements de la limite de débit et stabilisant la latence.
Mais attendez ! Le problème de la création anticipée des tâches persiste. La liste des tâches est créée avant tout traitement. Pour optimiser les coûts, combinez la concurrence contrôlée avec la création différée des tâches.
Mise en cache des prompts : le secret de réduction des coûts du 60%
Parlons maintenant d'un autre type d'optimisation, celle qui fonctionne quelle que soit votre implémentation asynchrone.
La mise en cache des requêtes exploite le fait que de nombreuses applications LLM envoient le même contexte de manière répétée : articles de recherche, documentation, instructions système, exemples de jeux de données – autant de contenus qui restent constants d’une requête à l’autre.
Lorsque la mise en cache est activée, le fournisseur LLM traite et stocke ce contenu répété. Les requêtes suivantes qui réutilisent le contenu mis en cache ne paient que les nouveaux jetons, et non l'intégralité de l'invite.
Comment fonctionne la mise en cache rapide ?
La plupart des principaux fournisseurs de LLM proposent désormais une mise en cache rapide avec des mécanismes similaires :
- Marquez certaines parties de votre invite comme pouvant être mises en cache
- Les processus de première requête et les caches de contenu
- Les requêtes suivantes effectuées dans un intervalle de temps donné réutilisent le cache.
- Vous bénéficiez de tarifs réduits pour les jetons mis en cache.
Le cache (mise en cache des invites) reste généralement valide pendant 5 à 10 minutes d'inactivité. Si le contenu est réutilisé durant cette période, des économies importantes sont réalisées.
Soyons francs : si vous avez un document de recherche de 30 000 jetons et que vous voulez poser dix questions différentes à son sujet, la mise en cache change complètement la donne sur le plan économique.
Sans mise en cache, le LLM traite les 30 000 jetons pour chaque question, soit un total de 300 000 jetons. Avec la mise en cache, vous payez le prix fort pour la première requête, puis un tarif réduit pour la partie mise en cache lors des neuf requêtes suivantes.
| Scénario | Nombre total de jetons traités | Réduction des coûts
|
|---|---|---|
| Aucune mise en cache (10 requêtes) | 300 000 jetons | Ligne de base |
| Avec mise en cache (10 requêtes) | ~120 000 jetons | 60% économies |
| Avec mise en cache (50 requêtes) | ~180 000 jetons | 88% économies |
Combiner la mise en cache avec les modèles asynchrones
C'est là que ça devient intéressant. En combinant une implémentation asynchrone correcte avec une mise en cache des prompts, les économies réalisées se multiplient.
Le code asynchrone regroupe naturellement les requêtes similaires dans le temps, condition essentielle à l'efficacité de la mise en cache. Toutes les requêtes arrivant pendant la période de validité du cache bénéficient ainsi du même contenu mis en cache.
Mais si votre implémentation asynchrone génère des requêtes inutiles, ces appels supplémentaires consomment votre budget de contenu mis en cache sans apporter de valeur ajoutée. Les économies réalisées grâce au cache 60% sont ainsi annulées par la multiplication par 10 des requêtes inutiles.
Si vous réussissez les deux, l'économie se transforme complètement.
API par lots : Gagnez du temps et réalisez d’importantes économies.
L'API Batch d'OpenAI représente une autre stratégie de réduction des coûts adaptée au traitement asynchrone. Comme évoqué au sein de la communauté des développeurs OpenAI, environ 4 200 appels synchrones sont désormais effectués via l'API Batch afin de bénéficier d'une fenêtre de traitement de 24 heures et de réaliser des économies.
Le compromis est simple : accepter des délais de traitement plus longs en échange de coûts considérablement réduits.
Quand le traitement par lots est judicieux
Les API par lots sont particulièrement adaptées aux cas suivants :
- Traitement et analyse des ensembles de données
- pipelines de génération de contenu
- Flux de travail d'évaluation et de test
- Toute charge de travail pour laquelle les résultats immédiats ne sont pas critiques
Le modèle asynchrone est ici différent. Au lieu de gérer des requêtes simultanées, l'application soumet une tâche par lots et interroge son système pour en vérifier la fin. Le fournisseur LLM optimise le traitement en arrière-plan, en acheminant souvent les requêtes vers une infrastructure moins sollicitée ou en les traitant pendant les heures creuses.
| Modèle asynchrone de l'API par lots # async def submit_batch_job(requests): lot = await client.batches.create( fichier_entrée=télécharger_fichier_batch(requêtes), endpoint="/v1/chat/completions"” ) renvoyer batch.id async def poll_batch_status(batch_id): tant que vrai : lot = await client.batches.retrieve(batch_id) si batch.status == “ terminé ” : retourner attendre retrieve_batch_results(batch_id) attendre asyncio.sleep(60) |
Les économies réalisées proviennent de la capacité du prestataire à optimiser l'utilisation des ressources. Lorsque vous n'exigez pas de réponses immédiates, il peut traiter vos demandes plus efficacement.

Réduisez les coûts de votre master en droit grâce à une architecture adaptée.
Les coûts des LLM sont souvent dus à des modes d'utilisation inefficaces, à des requêtes volumineuses et à des pipelines d'inférence mal structurés. Travailler avec une équipe d'ingénierie IA expérimentée comme IA supérieure Elle peut aider à identifier les véritables sources de coûts. L'entreprise développe des systèmes d'IA sur mesure et des applications basées sur le modèle LLM, notamment des outils de traitement automatique du langage naturel (TALN), des chatbots et des plateformes d'analyse de données. Ses ingénieurs conçoivent des pipelines de modélisation, optimisent l'infrastructure et structurent les déploiements afin que les systèmes puissent évoluer sans coûts de calcul superflus.
Vous cherchez à réduire les coûts de votre LLM ?
Dialoguer avec une IA supérieure à :
- Conception des pipelines LLM et de l'architecture backend
- développer des systèmes de traitement automatique du langage naturel et des applications basées sur l'intelligence artificielle
- déployer et intégrer des modèles dans des logiciels existants
👉 Demandez une consultation en IA avec IA supérieure pour discuter de votre projet de maîtrise en droit.
Panorama actuel des prix des LLM en 2026
Pour comprendre l'optimisation des coûts, il est essentiel de connaître les prix actuels. En juin 2025, OpenAI a annoncé des réductions de prix significatives pour son modèle o3 : une baisse de 80% par rapport au prix précédent.
La nouvelle structure tarifaire d'O3 :
- Jetons d'entrée : $2 par million de jetons
- Jetons de sortie : $8 par million de jetons
D'après une étude sur les architectures Mixture-of-Experts, GPT-4.5 facturait $150 pour la génération d'un million de jetons, un coût prohibitif pour de nombreuses applications. La baisse spectaculaire des prix dans les modèles plus récents modifie le rapport coût-bénéfice des techniques d'optimisation.
Cela dit, même avec des coûts par jeton plus faibles, les schémas asynchrones inefficaces peuvent engendrer des dépenses considérables à grande échelle. Un million d'appels API inutiles à $2 par million de jetons entrants représentent tout de même $2 000 jetons gaspillés.
Modèles asynchrones avancés pour le contrôle des coûts LLM
Au-delà des principes de base, plusieurs modèles asynchrones avancés offrent des possibilités supplémentaires d'optimisation des coûts.
Préchargement asynchrone du cache KV
Les recherches sur l'accélération du débit d'inférence des modèles linéaires à longue portée (LLM) via la prélecture asynchrone du cache KV démontrent des gains de performance significatifs. Sur les GPU NVIDIA H2O, cette méthode permet d'atteindre une accélération d'inférence de bout en bout jusqu'à 1,97x sur les LLM open source les plus courants.
Bien que cette technique vise principalement à réduire la latence plutôt qu'à réaliser des économies directes, une inférence plus rapide signifie un débit plus élevé par GPU, ce qui réduit les coûts d'infrastructure par requête.
Formation RLHF asynchrone
Pour les organisations qui entraînent des modèles personnalisés, l'apprentissage par renforcement asynchrone à partir de retours humains (RLHF) offre des gains d'efficacité de calcul. Les recherches démontrent que les approches asynchrones du RLHF permettent d'entraîner les modèles environ 40% plus rapidement que les méthodes synchrones traditionnelles.
Les économies réalisées proviennent d'une réduction du temps d'entraînement et d'une utilisation plus efficace du GPU. Les frameworks d'entraînement asynchrones comme AsyncFlow affichent des gains de débit de 1,76 à 1,82 fois supérieurs aux implémentations de référence à grande échelle.
Réponses en flux continu avec arrêt anticipé
Les réponses des API en flux continu permettent un autre modèle d'optimisation des coûts : l'arrêt anticipé en fonction de la qualité de la réponse.
Au lieu d'attendre la réponse complète, les applications peuvent évaluer les jetons transmis en temps réel et annuler la requête si la réponse ne répond pas aux critères de qualité. Cela évite le gaspillage de jetons pour des réponses qui seront finalement rejetées.
| async def stream_with_quality_check(prompt): flux = attendre client.chat.completions.create( modèle="gpt-4", messages=[{"role": "utilisateur", "content": prompt}], flux=Vrai ) accumulé = ""“ asynchrone pour le segment dans le flux : accumulé += chunk.choices[0].delta.content ou ""“ si should_terminate_early(accumulated): attendre stream.aclose() renvoyer Aucun retour accumulé |
L'essentiel est de définir des contrôles de qualité appropriés qui s'exécutent suffisamment rapidement pour apporter une valeur ajoutée : vérification des contenus interdits, des réponses hors sujet ou des violations de format.
Mesure et suivi de l'efficacité des coûts asynchrones
L'optimisation sans mesure relève de la conjecture. Un contrôle efficace des coûts exige le suivi des indicateurs clés.
Indicateurs clés à surveiller
| Métrique | Ce que cela révèle | Cible
|
|---|---|---|
| Jetons par requête | Rapidité et efficacité des réponses | Minimiser sans perte de qualité |
| Taux de réussite du cache | Fréquence de réutilisation du contenu mis en cache | Au-dessus de 70% pour les charges de travail répétitives |
| Taux d'échec des requêtes | Coûts des nouvelles tentatives dus aux erreurs et à la limitation du débit | En dessous de 2% |
| taux de résiliation anticipée | À quelle fréquence les requêtes s'arrêtent avant d'être terminées | Suivi des économies réalisées |
| Nombre de requêtes simultanées | Charge sur l'infrastructure du fournisseur | Limites de correspondance des sémaphores |
| Coût par résultat réussi | Coût réel incluant les échecs et les nouvelles tentatives | Cible d'optimisation principale |
Mise en œuvre du suivi des coûts
La plupart des fournisseurs de LLM proposent des tableaux de bord d'utilisation, mais ceux-ci présentent généralement des données agrégées. Pour une optimisation plus fine, implémentez un suivi au niveau des requêtes dans votre application.
D'après les discussions de la communauté sur l'utilisation de l'API, le regroupement des frais par ligne révèle des tendances importantes. Certains développeurs ont découvert des variations inexplicables dans l'utilisation des jetons, qui n'ont été visibles qu'après un suivi détaillé.
Enveloppez vos appels d'API avec des instruments qui enregistrent :
- Horodatage et latence de la requête
- Nombre de jetons d'entrée et de sortie
- État de cache (réussite/échec)
- Types d'erreurs et tentatives de nouvelle tentative
- Coût réel basé sur les prix actuels
Ces données permettent d'identifier les anomalies de coûts avant qu'elles ne deviennent des problèmes budgétaires.
Mise en œuvre concrète : une approche étape par étape
D'accord, alors comment mettre en œuvre concrètement ces optimisations de coûts dans une application réelle ?
Commencez par un audit des modèles asynchrones actuels. Recherchez les signaux d'alerte suivants :
- Les compréhensions de liste créent toutes les tâches avant toute instruction await.
- Appels à asyncio.gather() sans limite de concurrence
- Aucune configuration de mise en cache rapide malgré un contenu répétitif
- Tâches par lots synchrones pouvant être migrées vers des API par lots
- Absence de gestion des erreurs entraînant des tentatives de reconnexion coûteuses
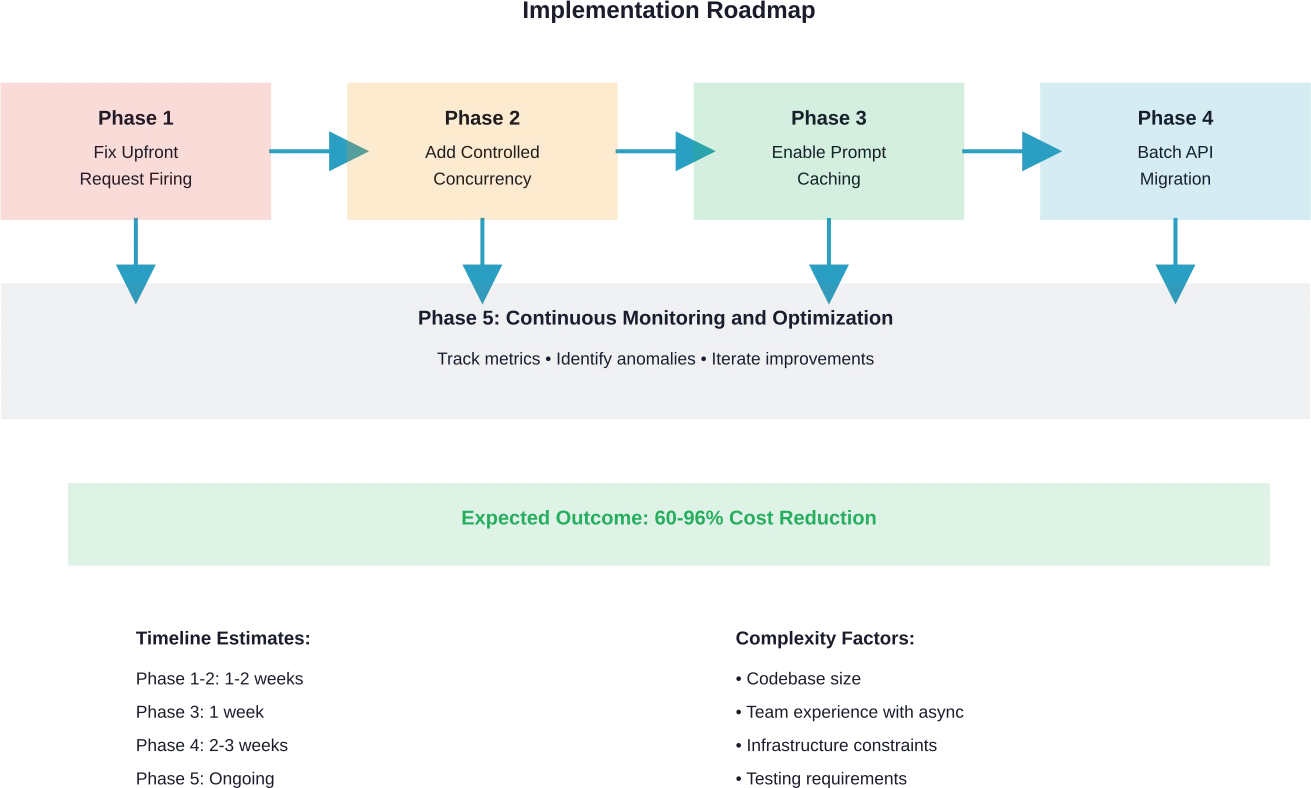
Phase 1 : Correction de la demande de déclenchement en amont
Identifier les fonctions qui créent toutes les tâches avant le début du traitement. Refactoriser pour une création de tâches différée :
| # Avant : Toutes les tâches créées au préalable fonction asynchrone process_items(items): tâches = [traiter_élément(élément) pour élément dans éléments] pour la tâche dans les tâches : résultat = tâche en attente si la validation du résultat n'est pas effectuée : renvoyer Faux # Après : Tâches créées selon les besoins fonction asynchrone process_items(items): pour chaque élément dans les éléments : résultat = attendre process_item(item) si la validation du résultat n'est pas effectuée : renvoyer Faux |
Ce simple changement peut éliminer 50 à 90% requêtes inutiles dans les flux de travail avec une logique de terminaison anticipée.
Phase 2 : Ajouter une concurrence contrôlée
Mettez en œuvre des sémaphores pour éviter les problèmes de limitation de débit :
| classe LLMClient : def __init__(self, max_concurrent=5): self.semaphore = asyncio.Semaphore(max_concurrent) self.client = OpenAI() async def appel(self, prompt): asynchrone avec self.semaphore : retourner attendre self.client.chat.completions.create( modèle="gpt-4", messages=[{“role”: “utilisateur”, “content”: prompt}] ) |
Phase 3 : Activer la mise en cache des invites
Structurez les invites pour optimiser la réutilisation du cache. Placez le contenu statique au début et indiquez qu'il peut être mis en cache conformément à l'API de votre fournisseur.
Phase 4 : Transférer les charges de travail appropriées vers le traitement par lots
Évaluez quels flux de travail peuvent tolérer des réponses différées. Le traitement des ensembles de données, la génération de contenu et les pipelines d'évaluation sont des candidats de choix.
Phase 5 : Mise en œuvre du suivi
Ajoutez un système de suivi des coûts pour mesurer l'impact des optimisations et identifier de nouvelles opportunités.
Pièges courants et comment les éviter
Même avec les meilleures intentions, l'optimisation asynchrone des coûts peut mal tourner. Voici les pièges les plus courants.
Sur-optimisation au détriment de la latence
Réduire trop drastiquement la concurrence permet de résoudre les problèmes de limitation de débit, mais augmente considérablement le temps d'exécution total. Une limite de 1 sémaphore peut éliminer la limitation de débit, mais elle sérialise également toutes les requêtes.
Trouvez le juste milieu par le biais de tests. Commencez par des limites prudentes et augmentez-les progressivement tout en surveillant les taux d'erreur.
Confusion liée à l'invalidation du cache
La mise en cache des invites fonctionne à merveille jusqu'à ce que le contenu mis en cache devienne obsolète. Les applications qui mettent à jour des documents de référence ou des instructions système nécessitent des stratégies d'invalidation du cache.
La plupart des fournisseurs gèrent cela automatiquement grâce à l'expiration du cache, mais tenez compte de ce délai. Si du contenu important est modifié, attendre 10 minutes pour l'expiration du cache peut s'avérer inacceptable.
Ignorer les coûts des requêtes ayant échoué
De nombreuses implémentations asynchrones privilégient les requêtes réussies tout en ignorant le coût des échecs. Les erreurs de limitation de débit, les délais d'attente et les échecs de validation entraînent souvent des tentatives de nouvelle requête qui multiplient les coûts.
Suivre séparément les requêtes ayant échoué et implémenter un mécanisme de temporisation exponentielle avec des limites maximales de tentatives.
Migration prématurée de l'API par lots
Le passage au traitement par lots avant d'avoir cerné les exigences de latence des charges de travail engendre des problèmes d'expérience utilisateur. Toutes les charges de travail “ non critiques ” ne peuvent tolérer des délais de 24 heures.
Commencez par des charges de travail véritablement asynchrones, comme le traitement de jeux de données pendant la nuit, avant de toucher à quoi que ce soit destiné aux utilisateurs.
Questions fréquemment posées
Dans quelle mesure l'optimisation asynchrone peut-elle réellement réduire les coûts LLM ?
La réduction des coûts dépend fortement des modèles d'implémentation actuels. Les applications qui déclenchent des requêtes en amont et interrompent les opérations peuvent réaliser des économies de 60 à 90 TP3T. Celles qui utilisent déjà des modèles asynchrones efficaces peuvent économiser de 20 à 40 TP3T grâce à la mise en cache et au traitement par lots. L'essentiel est d'identifier les requêtes inutiles dans le flux de travail actuel.
La mise en cache des prompts fonctionne-t-elle avec tous les fournisseurs de LLM ?
La plupart des principaux fournisseurs proposent désormais la mise en cache rapide ou des fonctionnalités similaires, mais les modalités d'implémentation varient. Consultez la documentation du fournisseur pour connaître les exigences spécifiques concernant la taille minimale du cache, sa durée et les tarifs. Certains fournisseurs activent la mise en cache automatiquement, tandis que d'autres nécessitent une configuration explicite.
Quelle limite de concurrence dois-je utiliser avec les sémaphores ?
Commencez par 5 à 10 requêtes simultanées et surveillez les erreurs de limitation de débit. Si vous constatez une limitation de débit persistante, réduisez la limite. Si le taux d'erreur est faible et la latence acceptable, augmentez-la progressivement. La limite optimale dépend des limitations de débit de votre fournisseur d'accès, de la taille des requêtes et des exigences de latence de l'application. D'après les discussions au sein de la communauté, une limite comprise entre 5 et 10 convient à la plupart des applications.
Puis-je combiner les réponses en flux continu avec la mise en cache des invites ?
Oui, le streaming et la mise en cache sont complémentaires. La mise en cache du contenu des invites réduit le nombre de jetons à traiter, tandis que le streaming permet un accès rapide aux résultats et une interruption anticipée. Cette combinaison offre des avantages en termes de coûts et de latence.
Comment puis-je mesurer si les optimisations permettent réellement de réaliser des économies ?
Mettez en place un suivi des coûts au niveau des requêtes, enregistrant le nombre de jetons et calculant les coûts en fonction de la tarification actuelle. Comparez les coûts avant et après les modifications d'optimisation sur des périodes de charge de travail équivalentes. Conformément aux recommandations de la communauté, l'affichage de l'utilisation regroupée par poste dans les tableaux de bord des fournisseurs révèle des tendances de coûts détaillées que les vues agrégées ne permettent pas de visualiser.
Dois-je privilégier le coût ou la latence ?
Cela dépend des exigences de l'application. Les fonctionnalités destinées aux utilisateurs privilégient généralement la latence tout en maintenant des coûts acceptables. Le traitement en arrière-plan peut tolérer une latence plus élevée pour réduire les coûts. Commencez par éliminer le gaspillage : les requêtes inutiles qui n'apportent aucune valeur ajoutée, quelle que soit leur vitesse. Ensuite, trouvez le juste équilibre entre coût et latence en fonction des cas d'utilisation spécifiques.
Que se passe-t-il pour les requêtes en cours lorsque mon application plante ?
Les requêtes asynchrones envoyées aux fournisseurs LLM continuent d'être traitées même si votre application s'arrête. Le fournisseur continue de facturer les requêtes terminées. Mettez en œuvre des gestionnaires d'arrêt appropriés qui annulent les requêtes en cours et ferment proprement les boucles d'événements asynchrones afin d'éviter les requêtes orphelines qui génèrent des frais sans résultat.
En conclusion : Optimiser le développement asynchrone pour votre budget
La programmation asynchrone n'est ni intrinsèquement bonne ni mauvaise pour les coûts des masters en droit ; c'est un outil qui nécessite une mise en œuvre soignée.
Les pratiques qui optimisent l'exécution du code peuvent aussi faire exploser les factures si des requêtes inutiles sont envoyées. Cependant, correctement implémentée, la programmation asynchrone permet des stratégies d'optimisation des coûts qu'une programmation synchrone ne peut tout simplement pas égaler.
Commencez par un audit honnête de vos modèles asynchrones actuels. Recherchez la création de tâches en amont, la concurrence incontrôlée et les opportunités de mise en cache manquées. Corrigez d'abord les problèmes les plus importants, généralement le déclenchement de requêtes en amont dans les flux de travail avec une interruption prématurée.
Ajoutez ensuite des optimisations supplémentaires : mise en cache des invites pour le contenu répétitif, traitement par lots pour les charges de travail non urgentes, diffusion en continu avec contrôles de qualité pour les fonctionnalités en temps réel.
Et surtout, mesurez tout. Suivez les jetons, les coûts, la latence et les taux d'erreur au niveau des requêtes. Ces données révéleront des pistes d'optimisation qui ne sont pas évidentes lors de la simple inspection du code.
Le paysage des coûts des modèles LLM continue d'évoluer. La réduction de prix du 80% d'OpenAI pour les modèles o3 en juin 2025 a profondément modifié la situation économique. Mais même avec des coûts par jeton plus bas, l'efficacité reste cruciale à grande échelle.
Prêt à réduire vos coûts LLM ? Commencez dès aujourd’hui par examiner vos modèles d’implémentation asynchrone. Les corrections en cinq lignes qui éliminent les requêtes inutiles sont souvent les plus efficaces et les plus rapides à mettre en œuvre.