Résumé rapide : Le suivi des coûts LLM aide les organisations à contrôler l'utilisation des jetons, à prévenir les dépassements budgétaires et à optimiser les dépenses liées aux charges de travail d'IA. Grâce à une visibilité en temps réel sur les modèles d'utilisation, les équipes peuvent identifier les inefficacités coûteuses avant qu'elles ne deviennent incontrôlables. Une solution de suivi adaptée fournit des analyses de coûts détaillées, des données d'utilisation et des mécanismes de gouvernance essentiels pour les déploiements en production.
Les grands modèles de langage sont passés de projets expérimentaux à des systèmes de production qui alimentent tout, du support client à la génération de contenu. Mais voilà le problème : sans surveillance adéquate, les coûts peuvent exploser du jour au lendemain.
Une seule chaîne de génération de leads non optimisée peut multiplier les dépenses jusqu'à 10 fois. Les équipes ne découvrent souvent ces dépassements budgétaires qu'après la clôture des cycles de facturation, lorsque le mal est déjà fait.
Il ne s'agit pas seulement de réaliser des économies. Le suivi des coûts offre la visibilité nécessaire pour prendre des décisions éclairées concernant le choix des modèles, l'ingénierie rapide et les choix d'infrastructure. Les organisations déployant des charges de travail d'IA à grande échelle ont besoin d'un suivi complet comme exigence opérationnelle incontournable.
Pourquoi le suivi des coûts est important pour les déploiements LLM
La tarification par jetons implique que chaque appel d'API a un coût. Contrairement aux logiciels traditionnels où les dépenses de calcul restent relativement prévisibles, les dépenses liées aux LLM varient considérablement en fonction des habitudes d'utilisation, de la complexité des requêtes et du modèle choisi.
Le passage du prototype à la production accentue ce problème. Ce qui fonctionnait correctement lors des tests avec quelques requêtes devient financièrement insoutenable à grande échelle. Sans visibilité continue, l'optimisation relève de la conjecture.
Les scénarios de déploiement réels ajoutent de la complexité. Plusieurs équipes peuvent utiliser différents modèles dans diverses applications. Certains flux de travail impliquent des appels enchaînés où une sortie LLM alimente une autre. Les pipelines RAG extraient des données de bases de données vectorielles avant de générer des réponses, ce qui augmente les coûts de calcul.
Le suivi des coûts résout trois problèmes essentiels. Premièrement, il évite les factures imprévues en suivant les dépenses en temps réel plutôt qu'a posteriori. Deuxièmement, il identifie les opportunités d'optimisation en révélant les invites, les modèles ou les utilisateurs qui consomment le plus de jetons. Troisièmement, il facilite la gouvernance en définissant des budgets et des alertes au niveau du projet, de l'équipe ou de l'organisation.
Indicateurs clés pour le suivi des coûts des LLM
Un suivi efficace repose sur l'analyse des indicateurs clés. La consommation de jetons en est un élément fondamental : jetons d'entrée (l'invite) et jetons de sortie (la réponse générée). Les tarifs par jeton variant selon les modèles, le nombre brut de jetons ne suffit pas à dresser un tableau complet.
Le coût par requête offre une vue normalisée. Cet indicateur permet de comparer l'efficacité financière de différentes approches. Une requête utilisant un modèle plus coûteux mais générant moins de jetons peut coûter moins cher qu'un modèle moins onéreux avec un affichage détaillé.
Les habitudes d'utilisation révèlent des tendances importantes. Les périodes de pointe, le volume de requêtes par application et la consommation de jetons par utilisateur ou équipe indiquent où se concentrent les dépenses. Ces tendances mettent souvent en évidence des inefficacités inattendues.
Le choix du modèle a un impact direct sur les coûts. Les modèles récents coûtent généralement plus cher que les anciens. Les modèles open source déployés sur site engendrent des coûts d'infrastructure plutôt que des frais par jeton. Le suivi des charges de travail gérées par chaque modèle permet d'identifier les opportunités d'optimisation.
Le taux d'erreur a plus d'importance que la plupart des équipes ne le pensent. Les appels API infructueux consomment des jetons et du budget. Un taux d'erreur élevé indique des problèmes d'intégration, mais aussi des dépenses inutiles qui pourraient être évitées grâce à une meilleure gestion des erreurs.
Services LLM sur site versus services LLM commerciaux
Les organisations sont confrontées à un choix fondamental : souscrire à des services commerciaux ou déployer des modèles sur leur propre infrastructure. Selon une étude analysant ce compromis, ce choix implique de multiples facteurs de coût, au-delà du simple prix par jeton.
Les services commerciaux proposés par des fournisseurs comme OpenAI, Anthropic et Google offrent une simplicité attrayante. Les équipes paient les jetons utilisés sans se soucier de l'infrastructure, des mises à jour des modèles ou des frais d'exploitation. Cette approche est facilement adaptable, mais les coûts augmentent linéairement avec l'utilisation.
Le déploiement sur site nécessite un investissement initial en infrastructure. D'après une analyse coûts-avantages, les entreprises doivent prendre en compte l'acquisition du matériel, la consommation d'énergie, le refroidissement, la maintenance et les effectifs. Le seuil de rentabilité dépend du volume d'utilisation : les déploiements à fort volume sont souvent plus avantageux pour les modèles sur site, tandis que les volumes plus faibles privilégient les API commerciales.
Les recherches sur l'analyse coûts-avantages du déploiement de modèles LLM sur site établissent des critères de sélection, notamment l'équivalence des performances (dans la limite de 20%) des meilleurs modèles commerciaux. Ce seuil reflète les normes d'entreprise où de légers écarts de précision sont compensés par des économies de coûts, des avantages en matière de sécurité et une plus grande flexibilité d'intégration.
Coûts cachés dans les deux approches
Les services commerciaux comportent des coûts cachés, au-delà du prix initial. Les limitations de débit peuvent imposer un passage à une formule supérieure. Des frais de sortie de données s'appliquent lors du traitement de volumes importants. L'accès requis par plusieurs membres de l'équipe fait grimper le coût de l'abonnement.
Les déploiements sur site engendrent des coûts cachés. L'optimisation des modèles requiert l'intervention de data scientists. L'infrastructure doit être redondante pour garantir la fiabilité. Les mises à jour et les correctifs exigent une attention constante. Les contraintes liées à la sécurité et à la conformité augmentent avec les solutions auto-hébergées.
La surveillance est essentielle quel que soit le mode de déploiement. Les API commerciales nécessitent un suivi pour éviter une explosion des coûts. Les systèmes sur site requièrent une surveillance pour optimiser l'utilisation des ressources et justifier les investissements dans l'infrastructure.
Outils et technologies essentiels
De nombreuses solutions de suivi ont vu le jour pour répondre aux besoins de suivi des coûts LLM. Ces outils diffèrent par leurs fonctionnalités, leur complexité et leurs cas d'utilisation idéaux.
LiteLLM offre une interface unifiée pour plusieurs fournisseurs de services de gestion de licences. Elle standardise les appels d'API tout en centralisant le suivi des jetons et des coûts. Les équipes travaillant avec plusieurs fournisseurs bénéficient ainsi d'une surveillance consolidée, évitant la consultation de multiples tableaux de bord.
Langfuse propose une solution d'observabilité open source spécialement conçue pour les applications LLM. Elle assure le suivi des coûts et des indicateurs de qualité, offrant ainsi une vision claire du rapport entre les dépenses et la qualité des livrables. La plateforme prend en charge les flux de travail complexes, notamment les pipelines RAG et les chaînes d'agents multi-étapes.
Datadog LLM Observability étend la surveillance de l'infrastructure existante aux charges de travail d'IA. Les organisations utilisant déjà Datadog peuvent ajouter le suivi LLM sans avoir à déployer de nouveaux outils. Cette intégration relie les données de coûts aux indicateurs de performance système plus généraux.
| Type de solution | Idéal pour | Atout majeur | Considération |
|---|---|---|---|
| Proxy unifié | Configurations multi-fournisseurs | Interface unique pour tous les LLM | Ajoute une couche de latence |
| Plateforme open source | Besoins de personnalisation | Contrôle total et transparence | Nécessite un hébergement auto-géré |
| Observabilité d'entreprise | grandes organisations | S'intègre aux outils existants | Structure de coûts plus élevée |
| API native du fournisseur | Utilisation par un seul fournisseur | Données les plus précises | Vue inter-fournisseurs limitée |
Les solutions natives des fournisseurs offrent un accès programmatique aux données d'utilisation et de coûts des API de l'organisation. Cette approche est efficace lorsqu'on standardise ses processus sur un seul fournisseur, mais elle crée des zones d'ombre dans les environnements multi-fournisseurs.

Créez des systèmes LLM avec un suivi clair de l'utilisation
Les applications utilisant LLM nécessitent une surveillance et une infrastructure adéquates pour gérer les requêtes, l'utilisation et les performances du système. IA supérieure Cette entreprise développe des plateformes d'IA intégrant de vastes modèles de langage à des services backend, des pipelines de données et des outils d'analyse. Ses ingénieurs conçoivent des systèmes permettant un déploiement fiable des modèles, la journalisation et la surveillance des performances en environnement de production.
Déploiement d'un système LLM en production ?
Dialoguer avec une IA supérieure à :
- conception de l'infrastructure LLM et des services backend
- créer des applications NLP basées sur des modèles de langage
- intégrer la surveillance et l'analyse aux systèmes d'IA
👉 Contactez-nous IA supérieure pour discuter de votre projet de développement en IA.
Mise en œuvre du suivi des coûts en temps réel
La surveillance en temps réel offre une visibilité immédiate, contrairement à l'analyse rétrospective. Cette capacité permet une gestion proactive des coûts plutôt qu'une gestion réactive des dommages.
La mise en œuvre comprend généralement trois composantes. Premièrement, l'instrumentation enregistre le nombre de jetons pour chaque appel LLM. Deuxièmement, une base de données centrale agrège ces données avec les métadonnées associées, telles que l'utilisateur, l'application et l'horodatage. Troisièmement, des tableaux de bord visualisent les tendances de dépenses et déclenchent des alertes en cas de dépassement de seuils.
Les bases de données PostgreSQL servent souvent de couche de stockage pour les systèmes de suivi des coûts. Elles contiennent le nombre de jetons, les calculs de coûts et les métadonnées d'utilisation. Cette approche offre une grande flexibilité pour les requêtes personnalisées tout en gérant le volume d'écritures des applications de production.
Les tableaux de bord intégrés transforment les données brutes en informations exploitables. Les tableaux de bord performants affichent les dépenses actuelles, les comparent aux budgets, mettent en évidence les principaux clients et révèlent les tendances au fil du temps. Les meilleures solutions permettent d'explorer les données en détail, de la vue d'ensemble de l'organisation jusqu'aux détails de chaque demande.
Configuration des alertes et des budgets
La configuration des alertes permet d'éviter les mauvaises surprises budgétaires. Les équipes doivent définir plusieurs niveaux d'alerte : des seuils d'avertissement signalant des dépenses élevées et des limites critiques déclenchant une intervention.
L'allocation budgétaire est optimale lorsqu'elle est hiérarchisée. Les budgets globaux de l'organisation fixent des limites générales. Les budgets par département ou par projet offrent un contrôle plus précis. Les plafonds par utilisateur ou par application permettent d'éviter les dépassements de coûts liés à des problèmes isolés.
Les canaux d'alerte sont importants. Les notifications par e-mail conviennent aux avertissements non urgents. Les intégrations Slack ou Teams permettent de sensibiliser l'équipe. PagerDuty ou des systèmes similaires gèrent les dépassements budgétaires critiques nécessitant une intervention immédiate.
Optimisation des coûts grâce aux données de suivi
Le suivi des coûts génère des données. L'optimisation transforme ces données en économies.
L'optimisation des invites s'avère un levier essentiel. Le suivi permet d'identifier les invites qui consomment trop de ressources. Des invites plus courtes et plus ciblées réduisent les coûts d'entrée. Limiter la longueur des réponses évite les messages trop longs et coûteux.
L'optimisation du choix des modèles utilise les données de coût pour associer les charges de travail aux modèles appropriés. Les tâches simples ne nécessitent pas les modèles les plus performants (et les plus coûteux). La surveillance permet d'identifier les possibilités d'orienter les requêtes vers des alternatives moins onéreuses sans compromettre la qualité.
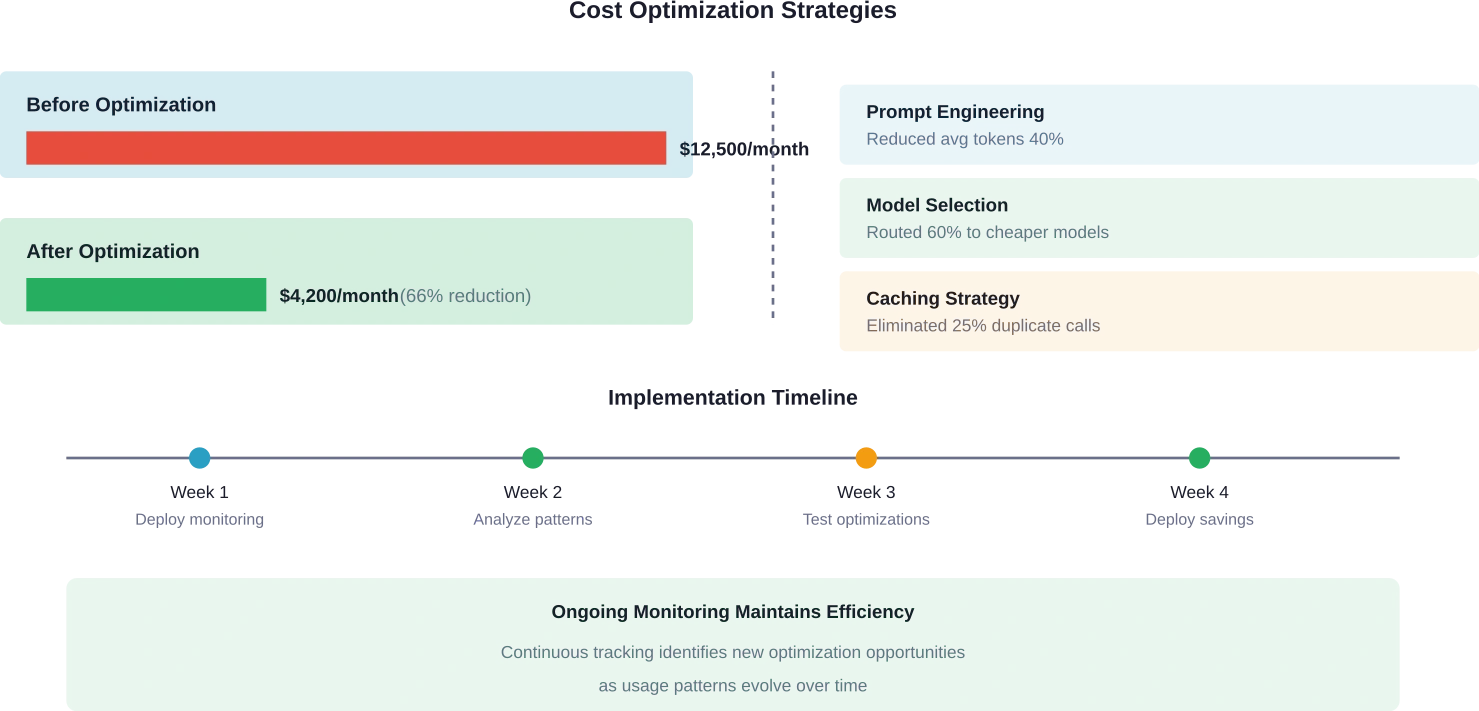
Les stratégies de mise en cache éliminent les traitements redondants. Si plusieurs utilisateurs posent des questions similaires, la mise en cache de la première réponse évite de régénérer un contenu identique. La surveillance permet d'identifier les requêtes fréquentes qui bénéficient le plus de la mise en cache.
Le regroupement des requêtes permet de combiner plusieurs opérations lorsque cela est possible. Certains flux de travail effectuent de nombreux petits appels d'API qui pourraient être consolidés. L'analyse des tendances d'utilisation révèle les opportunités de regroupement permettant de réduire les coûts et la latence.
Gouvernance et contrôles d'utilisation
Le suivi des coûts permet une gouvernance qui va au-delà du simple enregistrement. Les organisations ont besoin de mécanismes de contrôle pour faire respecter leurs politiques et prévenir les dépenses non autorisées.
Le contrôle d'accès basé sur les rôles détermine qui peut utiliser quels modèles. Les équipes de développement peuvent accéder à des modèles coûteux pour les tests, tandis que les applications de production utilisent des alternatives plus économiques. La surveillance permet de garantir le respect de ces politiques.
La limitation du débit empêche les abus ou les erreurs de configuration d'entraîner des pertes budgétaires importantes. Les limites de débit par utilisateur ou par application plafonnent la consommation maximale de jetons sur des périodes définies. Ces mécanismes de contrôle protègent contre les boucles incontrôlées et les pics d'utilisation inattendus.
Les processus d'approbation complexifient les opérations coûteuses. Les applications de recherche explorant de nouveaux cas d'usage peuvent nécessiter une approbation explicite avant d'accéder aux modèles premium. Le suivi fournit les données d'utilisation nécessaires à l'évaluation de ces demandes.
Exigences de conformité et d'audit
De nombreux secteurs sont soumis à des exigences réglementaires concernant l'utilisation de l'IA. Les institutions financières doivent faire preuve d'un déploiement responsable de l'IA. Les organismes de santé doivent se conformer aux réglementations relatives à la protection des données.
Le suivi des coûts génère des journaux d'audit indiquant quels utilisateurs ont accédé à quels modèles et avec quelles données. Cette documentation facilite la mise en conformité et permet également une analyse forensique en cas de problème.
Les politiques de conservation des données déterminent la durée de conservation des enregistrements d'utilisation. Une conservation plus longue facilite l'analyse des tendances, mais augmente les coûts de stockage. Les organisations trouvent un juste équilibre entre ces impératifs en fonction de leurs obligations de conformité spécifiques.
Intégration avec Contact Center Analytics
Les centres de contact représentent des scénarios de déploiement LLM à grande échelle. Selon une étude sur l'extraction d'informations basées sur les modèles de langage pour l'analyse des centres de contact, les entreprises déploient ces modèles pour les outils de libre-service, l'automatisation administrative et l'amélioration de la productivité des agents.
Ces déploiements génèrent une consommation massive de jetons. Un suivi rigoureux devient donc essentiel pour une exploitation rentable. La recherche décrit des systèmes qui extraient automatiquement des informations pertinentes des interactions clients tout en maîtrisant les coûts de déploiement.
Les modèles de base vierges, comme GPT-3.5-turbo, constituent un point de départ pour les applications de centres de contact. Les modèles affinés offrent une meilleure précision, mais nécessitent une infrastructure et une maintenance supplémentaires. Le suivi des coûts permet d'évaluer ces compromis en mesurant l'impact financier de chaque approche.
Cette recherche met l'accent sur des expériences de modélisation thématique de bout en bout visant à déterminer les facteurs d'échelle optimaux. Ces expériences s'appuient sur un suivi exhaustif des coûts afin d'équilibrer les gains de précision et l'augmentation des dépenses.
Considérations relatives à l'intégration du secteur financier
Les institutions financières sont confrontées à des défis uniques en matière d'intégration des modèles linguistiques. Les recherches sur les cadres stratégiques d'intégration des modèles linguistiques dans le secteur financier mettent en lumière la manière dont les organisations adoptent ces modèles pour l'évaluation du crédit, les services de conseil à la clientèle et l'automatisation des processus à forte composante linguistique.
Une mise en œuvre efficace requiert une innovation responsable qui concilie capacités et gestion des risques. Le suivi des coûts contribue à cet équilibre en offrant une visibilité sur les habitudes d'utilisation et les tendances de dépenses.
Les organismes financiers appliquent généralement une gouvernance plus stricte que les autres secteurs. Les outils de surveillance doivent prendre en charge des pistes d'audit détaillées, des contrôles d'accès basés sur les rôles et des rapports de conformité. L'intégration aux systèmes de gestion des risques existants devient essentielle.
L’étude constate que les institutions financières de toutes tailles déploient de plus en plus de solutions de surveillance à long terme. Les petites structures ont besoin de solutions de surveillance économiques, tandis que les grandes institutions exigent une gouvernance et une capacité de déploiement à grande échelle.
Choisir la bonne solution de surveillance
Le choix d'un outil de surveillance dépend des besoins spécifiques de l'organisation. Plusieurs facteurs guident cette décision.
La prise en charge de plusieurs fournisseurs est importante lorsqu'on utilise plusieurs prestataires de services linguistiques. Les organisations qui optent pour un fournisseur unique peuvent privilégier une intégration plus poussée plutôt qu'une large compatibilité.
La flexibilité du déploiement influe sur les coûts et le contrôle. Les solutions hébergées dans le cloud minimisent les frais d'exploitation. Les options auto-hébergées offrent une plus grande personnalisation et une meilleure souveraineté des données.
Les fonctionnalités d'intégration déterminent la manière dont les données de surveillance sont intégrées aux systèmes existants. L'accès API permet la création de tableaux de bord personnalisés. Les webhooks prennent en charge l'automatisation événementielle. Des connecteurs prédéfinis simplifient l'intégration avec les outils les plus courants.
| Fonctionnalité | Besoins de démarrage | Besoins de l'entreprise |
|---|---|---|
| Suivi des coûts | Comptage de jetons de base | Analyse multidimensionnelle |
| Gouvernance | budgets simples | Flux d'approbation complexes |
| Intégration | Tableau de bord autonome | connectivité des outils d'entreprise |
| Soutien | Forums communautaires | Assistance dédiée |
| Déploiement | Hébergement cloud privilégié | Option sur site requise |
Les exigences en matière d'évolutivité varient selon la taille de l'organisation et son rythme de croissance. Les outils qui fonctionnent correctement avec quelques dizaines de requêtes par jour peuvent avoir des difficultés avec des milliers par minute. Anticiper le volume de requêtes prévu permet d'éviter de surcharger l'infrastructure de surveillance.
Le budget alloué à la solution de surveillance constitue un défi majeur. Consacrer des sommes excessives à la surveillance est contre-productif. Les solutions rentables devraient représenter une part minimale des dépenses totales en IA.
Tendances futures en matière de gestion des coûts des LLM
Le suivi des coûts continue d'évoluer au sein de l'écosystème plus large du LLM. Plusieurs tendances redéfinissent la manière dont les organisations abordent la gestion des dépenses.
- La modélisation prédictive des coûts utilise les données historiques pour prévoir les dépenses futures. Les algorithmes d'apprentissage automatique identifient les tendances et projettent les coûts selon différents scénarios. Cette capacité permet une budgétisation proactive plutôt qu'un ajustement réactif.
- L'optimisation automatisée exploite les données de surveillance et met en œuvre des améliorations sans intervention manuelle. Les systèmes acheminent automatiquement les requêtes vers les modèles les plus économiques, ajustent les paramètres de mise en cache et compressent les invites tout en préservant la qualité.
- L'arbitrage des coûts entre fournisseurs surveille les prix de plusieurs fournisseurs et achemine les requêtes vers l'option la plus rentable pour chaque charge de travail. Cette approche nécessite des données de coûts en temps réel et une logique de routage sophistiquée.
- Le suivi de l'empreinte carbone permet d'étendre la surveillance au-delà des coûts financiers pour inclure l'impact environnemental. Face aux enjeux de développement durable, il devient crucial pour les entreprises de comprendre la consommation énergétique liée aux charges de travail d'IA.
Questions fréquemment posées
Dans quelle mesure le suivi des coûts LLM permet-il généralement de réduire les dépenses ?
Les organisations qui mettent en place une surveillance et une optimisation complètes peuvent réduire considérablement leurs coûts LLM. Les économies réalisées dépendent du niveau d'optimisation du déploiement initial. Les équipes n'ayant jamais utilisé de système de surveillance auparavant constatent souvent les réductions les plus importantes. Les gains proviennent principalement d'une ingénierie rapide, d'une optimisation du choix du modèle et de l'élimination des appels redondants inutiles.
Les outils de surveillance peuvent-ils fonctionner avec différents fournisseurs de services LLM ?
Oui, plusieurs solutions de supervision prennent en charge les environnements multi-fournisseurs. Des outils comme LiteLLM créent une interface unifiée pour OpenAI, Anthropic, Google et d'autres fournisseurs. Ces solutions standardisent les appels d'API tout en centralisant le suivi des coûts. La supervision par un seul fournisseur offre généralement des indicateurs plus détaillés, mais crée des zones d'ombre lorsqu'on utilise plusieurs fournisseurs.
Quelle est la différence entre le suivi des coûts et l'observabilité LLM ?
Le suivi des coûts se concentre spécifiquement sur l'utilisation et les dépenses des jetons. L'observabilité LLM englobe un ensemble plus large de métriques, notamment la qualité, la latence, les taux d'erreur et la satisfaction des utilisateurs, en plus des coûts. Les plateformes d'observabilité offrent une visibilité globale sur l'état de santé des applications LLM. Le suivi des coûts est un élément essentiel de l'observabilité, mais ne constitue pas une vision complète.
Comment les déploiements sur site gèrent-ils différemment le suivi des coûts ?
Les déploiements sur site suivent les coûts d'infrastructure plutôt que les frais par jeton. La surveillance porte sur l'utilisation du GPU, la consommation d'énergie et le débit. L'objectif passe de la minimisation de l'utilisation des jetons à l'optimisation de l'efficacité matérielle. Les équipes doivent calculer le coût interne par jeton en fonction des dépenses d'infrastructure afin de le comparer aux solutions commerciales.
Toutes les organisations doivent-elles mettre en place une surveillance en temps réel ou l'analyse par lots est-elle suffisante ?
La surveillance en temps réel devient essentielle à grande échelle ou lorsque les budgets sont serrés. Les organisations traitant des milliers de requêtes par jour ont besoin d'une visibilité immédiate pour éviter une explosion des coûts. Les déploiements plus modestes, avec une utilisation prévisible, peuvent s'appuyer sur une analyse par lots des dépenses quotidiennes ou hebdomadaires. La complexité et les coûts des systèmes en temps réel ne se justifient que si le risque de dépassement budgétaire justifie l'investissement.
Quel est l'impact de la mise en cache sur la précision du suivi des coûts ?
La mise en cache réduit le nombre d'appels à l'API LLM, mais la surveillance doit suivre les requêtes mises en cache et celles qui ne le sont pas. Une surveillance efficace permet de distinguer les accès réussis au cache des échecs afin de calculer les économies réelles. Sans cette distinction, les équipes risquent de surestimer leurs dépenses. Le taux d'accès au cache devient ainsi un indicateur d'optimisation important, au même titre que la consommation de jetons.
Quel rôle joue le suivi dans la gouvernance des LLM ?
La surveillance fournit les données essentielles à l'élaboration des politiques de gouvernance. Le suivi de l'utilisation permet de respecter les budgets, de limiter les débits et de contrôler les accès. Les journaux d'audit des systèmes de surveillance attestent de la conformité aux politiques internes et aux réglementations externes. Sans données de surveillance, les politiques de gouvernance deviennent de simples lignes directrices inapplicables, et non de véritables mécanismes de contrôle.
Maîtriser les dépenses liées au LLM
Le suivi des coûts transforme les déploiements LLM, autrefois centres de dépenses imprévisibles, en systèmes optimisés et maîtrisables. La visibilité qu'il offre permet de prendre des décisions éclairées concernant le choix du modèle, l'ingénierie rapide et les choix d'infrastructure.
Les entreprises qui déploient des charges de travail d'IA en production ne peuvent se permettre de négliger cette étape. Les outils et les techniques existent aujourd'hui pour suivre les dépenses, éviter les dépassements et optimiser les coûts en continu. L'effort de mise en œuvre est rentabilisé en quelques semaines grâce aux économies réalisées.
Commencez par un suivi basique des jetons si une surveillance complète vous semble complexe. Même une simple visibilité sur les applications et les utilisateurs qui consomment le plus de jetons révèle des opportunités d'optimisation. À mesure que vos déploiements s'étendent, évoluez vers une surveillance en temps réel, des alertes automatisées et des contrôles de gouvernance.
L'avantage concurrentiel revient aux équipes qui déploient efficacement l'IA tout en maîtrisant leurs coûts. Le suivi offre ces deux possibilités, permettant un déploiement ambitieux sans dépenses inconsidérées. Les organisations qui maîtrisent le suivi des coûts peuvent explorer de nouvelles applications LLM en toute confiance, sachant qu'elles conservent la maîtrise de leurs finances.