Résumé rapide : En 2026, les meilleures plateformes d'analyse LLM pour le suivi des coûts et de la qualité incluent Confident AI, pour une surveillance axée sur l'évaluation avec une tarification à l'usage ; Langfuse, pour une observabilité open source avec suivi des sessions ; et Datadog LLM Observability, pour le traçage à l'échelle de l'entreprise. MiniMax M2.5 se distingue comme le modèle le plus rentable offrant une excellente qualité analytique, tandis que les frameworks AgServe démontrent comment un service prenant en compte les sessions peut atteindre une qualité équivalente à celle de GPT-4o pour un coût 16,51 TP3 T.
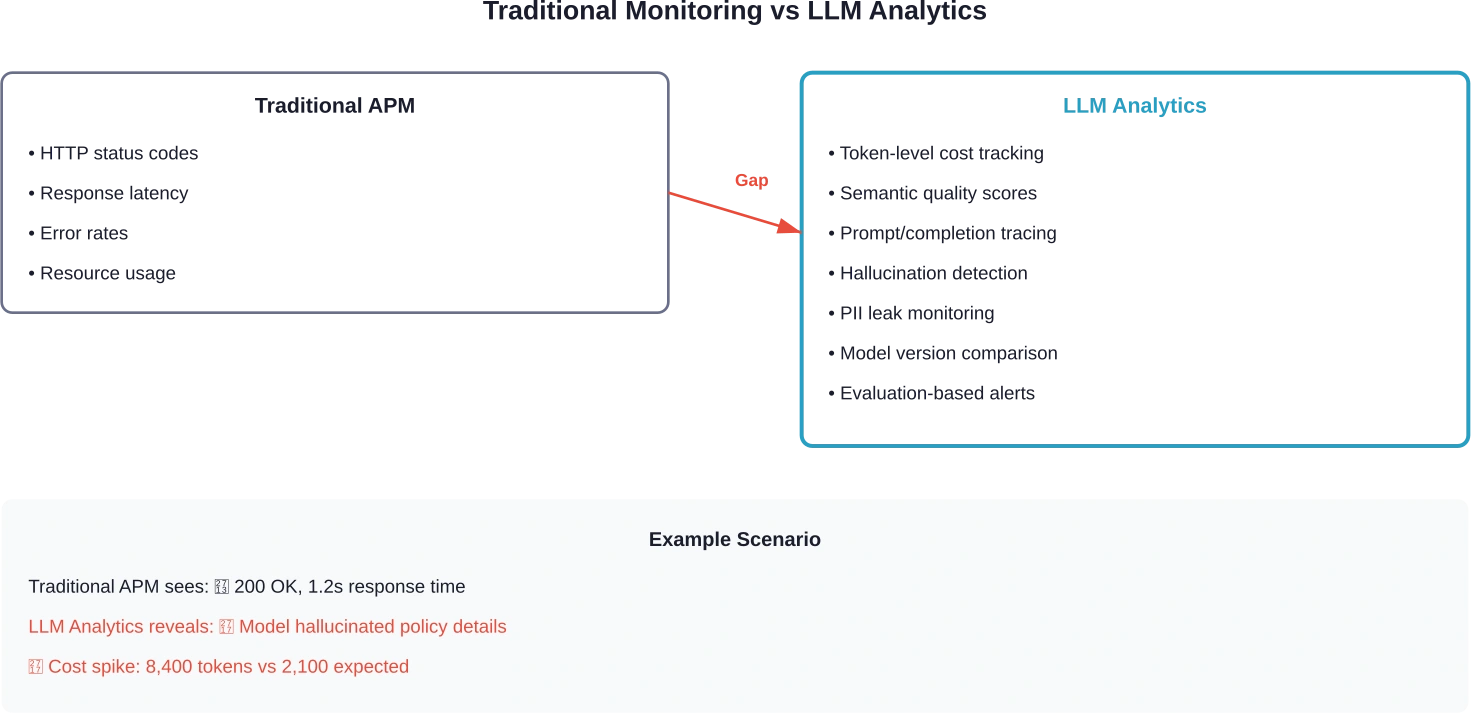
La surveillance traditionnelle ne détecte pas les défaillances de l'IA. Un tableau de bord APM peut afficher une réponse 200 en 1,2 seconde, mais il ne révélera pas que le modèle a mal interprété un détail de politique, divulgué des informations sensibles ou dévié du sujet en cours de conversation.
C’est précisément ce que comblent les outils d’analyse LLM. Ils retracent les invites et les complétions, calculent le coût des jetons par requête, détectent les variations de qualité entre les versions du modèle et mettent en évidence les schémas de défaillance que les plateformes d’observabilité standard ne repèrent pas.
À mesure que les applications basées sur LLM passent du prototype à la production, le coût des jetons peut rapidement exploser. Une seule chaîne d'invites non optimisée peut multiplier les dépenses par dix. Sans visibilité en temps réel sur les habitudes d'utilisation, les équipes ne découvrent souvent les dépassements budgétaires qu'une fois le mal fait.
Ce guide présente les principales plateformes d'analyse LLM pour le suivi des coûts et de la qualité. Nous détaillerons les spécificités de chaque outil, comparerons les prix des différents fournisseurs et identifierons les plateformes les plus adaptées à des scénarios de déploiement spécifiques.
Pourquoi le suivi des coûts et de la qualité des LLM est important
Les systèmes d'IA en production présentent des défaillances différentes de celles des logiciels traditionnels. Un serveur web renvoie des données ou génère une erreur. En revanche, un LLM peut renvoyer du JSON parfaitement formaté contenant des informations entièrement fictives.
La maîtrise des coûts représente un autre défi. La tarification par jetons implique que chaque modification apportée à une requête a un impact sur le rapport économique. L'ajout de contexte pour améliorer la qualité pourrait tripler le coût par requête. Le passage de GPT-4 à un modèle plus petit pourrait réduire les coûts de 90%, mais dégraderait la précision des résultats en dessous des seuils acceptables.
D'après les recherches sur les systèmes de serveurs d'agents, les plateformes de serveurs de modèles existantes ne prennent pas en charge la gestion des sessions, ce qui entraîne des compromis inutiles entre coût et qualité. Le framework AgServe démontre qu'une gestion du cache clé-valeur prenant en compte les sessions et une cascade de modèles basée sur la qualité permettent d'atteindre une qualité de réponse comparable à celle de GPT-4o pour un coût seulement 16,51 T³ T.
Voici ce que permet une analyse LLM appropriée :
- Attribution des coûts au niveau du jeton à travers les invites, les utilisateurs, les fonctionnalités et les versions de modèle
- Détection de dérive de qualité grâce à des scores d'évaluation automatisés et des boucles de rétroaction humaine
- Suivi de la latence qui sépare le temps de réponse de l'API du temps de traitement du modèle
- analyse des modes de défaillance qui font apparaître des déclencheurs d'hallucinations courants ou des erreurs de formatage
- Surveillance de la sécurité pour fuite d'informations personnelles, tentatives d'injection de code et violations de la politique de contenu
Sans ces capacités, les équipes travaillent à l'aveugle. Elles ne peuvent optimiser les décisions d'ingénierie prises rapidement, ni prouver le retour sur investissement aux parties prenantes, ni détecter la dégradation de la qualité avant qu'elle n'affecte les utilisateurs.
Qu'est-ce qui différencie LLM Analytics de l'observabilité standard ?
Les outils APM standard suivent les requêtes, les erreurs et la latence. C'est nécessaire, mais insuffisant pour les applications LLM.
La différence fondamentale : l’analyse LLM doit évaluer qualité sémantique Il s'agit d'obtenir des informations sur les résultats, et pas seulement sur la réussite de l'appel API. Un code d'état 200 ne vous renseigne en rien sur la précision, la pertinence ou la sécurité des recommandations du modèle.
Trois fonctionnalités distinguent l'analyse spécifique au LLM de la surveillance traditionnelle :
Calcul du coût basé sur les jetons
Chaque appel d'API consomme des jetons d'entrée (l'invite) et des jetons de sortie (la réponse). Les coûts varient selon le modèle, le type de jeton et parfois l'heure. Un suivi précis des coûts nécessite l'analyse des métadonnées d'utilisation de chaque réponse d'API et leur affectation au centre de coûts approprié.
D'après la documentation d'Anthropic sur la gestion des coûts, la commande `/cost` fournit des statistiques détaillées sur l'utilisation des jetons, notamment le coût total, la durée d'exécution de l'API, la durée réelle d'exécution et les modifications de code. Ce suivi précis permet aux équipes d'identifier les opérations coûteuses avant leur déploiement à grande échelle.
Mesures de qualité basées sur l'évaluation
La qualité ne peut être déduite des codes d'état HTTP. Les plateformes d'analyse résolvent ce problème en effectuant des évaluations automatisées à chaque exécution. Ces évaluations vérifient l'absence d'anomalies, mesurent la pertinence par rapport aux résultats attendus, contrôlent la conformité du formatage et signalent les éventuelles violations de sécurité.
Les recherches d'Anthropic sur l'évaluation des agents soulignent que des évaluations de qualité permettent aux équipes de déployer des agents d'IA avec plus d'assurance. Sans elles, les équipes s'enlisent dans des cycles de réaction, ne découvrant les problèmes qu'en production, où la correction d'un dysfonctionnement en engendre d'autres.
Suivi des invites et des achèvements
Les journaux standard enregistrent les points de terminaison et les codes d'état. Le traçage LLM capture l'intégralité du cycle d'affichage des invites, y compris les messages système, les entrées utilisateur, les appels de fonction, les paramètres du modèle et le résultat final. Ce contexte est essentiel pour le débogage des problèmes de qualité et l'optimisation des invites.
Les recommandations d'OpenAI concernant l'évaluation avec Langfuse montrent comment le suivi des étapes internes des flux de travail des agents permet de mettre en œuvre des stratégies d'évaluation en ligne et hors ligne que les équipes utilisent pour déployer les agents en production de manière fiable.
Les meilleures plateformes d'analyse LLM pour 2026
Le marché de l'analyse LLM a considérablement mûri. Les plateformes se répartissent désormais en trois catégories : les outils d'évaluation, les frameworks d'observabilité open source et les suites de supervision d'entreprise.
Voici un comparatif des principales plateformes :
IA confiante
Confident AI axe le contrôle qualité des modèles de vie des logiciels (LLM) sur des évaluations et des indicateurs de qualité structurés, plutôt que sur une observabilité de type APM. Sa plateforme unique regroupe la notation automatisée des évaluations, le traçage des LLM, la détection des vulnérabilités et les retours humains.
Cet outil est particulièrement performant pour les équipes qui privilégient l'assurance qualité à l'observabilité générale. Chaque trace est automatiquement évaluée selon des critères configurables tels que la pertinence, le taux d'hallucinations et la conformité au format.
Caractéristiques principales :
- Bibliothèque d'évaluation intégrée avec plus de 20 indicateurs de qualité
- Assistance personnalisée pour les contrôles qualité spécifiques au domaine
- Intégration du retour d'information humain pour les flux de travail RLHF
- Analyse des vulnérabilités pour l'injection rapide et la fuite de données personnelles
- Gestion des versions des jeux de données pour les tests de régression
Tarifs : Tarification à l'usage, ce qui en fait une option accessible aux équipes ayant des volumes de traçage modérés. Il est recommandé d'évaluer les prévisions de coûts lors de la mise en place du service.
Idéal pour : Des équipes axées sur l'assurance qualité et les cycles de développement pilotés par l'évaluation.
Langfuse
Langfuse offre une solution open source d'observabilité LLM avec traçabilité complète des requêtes, suivi des coûts au niveau des jetons et contrôle qualité. La plateforme prend en charge les déploiements sur site et dans le cloud.
Selon le guide d'OpenAI sur l'évaluation des agents avec Langfuse, la plateforme surveille les étapes internes de l'agent et permet des mesures d'évaluation en ligne et hors ligne utilisées par les équipes pour mettre les agents en production de manière fiable.
Langfuse excelle dans le suivi des sessions, regroupant les traces connexes en sessions pour faciliter les conversations à plusieurs tours et l'analyse des flux de travail des agents.
Caractéristiques principales :
- Périodes de suivi illimitées avec le forfait Pro
- Suivi des conversations par session
- Évaluation en temps réel
- Répartition des coûts par utilisateur, fonctionnalité ou modèle
- Noyau open source avec option cloud d'entreprise
Tarifs : Langfuse Cloud propose un forfait Hobby (50 000 unités/mois gratuites), un forfait Core ($29/mois + consommation) et un forfait Pro ($199/mois + consommation). Les deux forfaits payants incluent 100 000 unités, avec une consommation supplémentaire facturée à partir de $8 pour 100 000 unités.
Idéal pour : Les équipes qui souhaitent la flexibilité de l'open source avec un hébergement cloud optionnel, notamment pour les applications conversationnelles multi-tours.
Hélicone
Helicone offre une solution d'observabilité LLM légère axée sur l'optimisation des coûts. La plateforme agit comme une couche intermédiaire entre les applications et les API LLM, capturant chaque requête sans nécessiter de modifications de code.
L'architecture proxy simplifie le déploiement. Modifiez le point de terminaison de l'API et Helicone commence immédiatement à enregistrer les requêtes. Cette simplicité a toutefois un prix : une flexibilité réduite pour les évaluations personnalisées et l'absence de métriques de qualité intégrées.
Caractéristiques principales :
- Intégration sans code via un proxy API
- Suivi de l'utilisation des jetons dans les différents modèles
- Suivi des coûts et alertes budgétaires
- Couche d'analyse de la latence et de mise en cache
- Soutien à plus de 10 fournisseurs de LLM
Tarifs : L'offre gratuite comprend 10 000 requêtes par mois. L'offre Pro est disponible à partir de 1 TP4 T79/mois avec une tarification basée sur l'utilisation.
Idéal pour : Pour les équipes qui ont besoin d'une visibilité rapide des coûts sans exigences d'évaluation approfondies.
Observabilité Datadog LLM
Datadog a étendu sa plateforme de supervision d'entreprise aux applications LLM. Cette intégration permet d'afficher les traces LLM sur le même tableau de bord que les indicateurs d'infrastructure, les données APM et les journaux.
Cette vue unifiée permet aux équipes de corréler les performances de LLM avec le comportement du système sous-jacent. Les lenteurs d'exécution peuvent être liées à la latence de la base de données. Les pics de coûts peuvent correspondre à des mises à jour de fonctionnalités spécifiques.
Caractéristiques principales :
- Surveillance unifiée de l'infrastructure et de la couche LLM
- Suivi des coûts en temps réel et détection des anomalies
- Répartition de l'utilisation des jetons par point de terminaison et utilisateur
- Prise en charge de métriques personnalisées pour les indicateurs clés de performance (KPI) spécifiques au domaine
- fonctionnalités de sécurité et de conformité pour les entreprises
Tarifs : Intégré à votre abonnement Datadog existant. Consultez le site officiel pour découvrir les offres actuelles adaptées aux besoins d'observabilité LLM.
Idéal pour : Les équipes d'entreprise utilisant déjà Datadog et souhaitant intégrer la surveillance LLM à leur infrastructure d'observabilité existante.
Poids et biais du tissage
Weave étend les fonctionnalités de suivi des expériences de W&B aux applications LLM. Il permet de suivre les modèles d'invites, les paramètres du modèle et les résultats d'une expérience à l'autre, facilitant ainsi la comparaison des variations d'invites et des configurations de modèles.
La plateforme excelle dans l'évaluation hors ligne. Les équipes peuvent capturer les traces de production, les rejouer avec différents modèles ou invites et mesurer les différences de qualité avant de déployer des modifications.
Caractéristiques principales :
- Flux de travail axé sur l'expérimentation pour une optimisation rapide
- Évaluation hors ligne avec relecture des traces
- Suivi des coûts par expérience et variante de modèle
- Intégration avec les outils de cycle de vie ML de W&B
- Gestion des jeux de données pour les tests de référence
Tarifs : Offre gratuite disponible. Forfaits Équipe et Entreprise avec tarification à l'usage — consultez le site officiel pour connaître les tarifs en vigueur.
Idéal pour : Équipes d'apprentissage automatique menant des expériences d'optimisation rapide à grande échelle et ayant besoin de capacités d'évaluation hors ligne.
| Plate-forme | Suivi des coûts | Indicateurs de qualité | Sensibilisation à la session | Prix initial
|
|---|---|---|---|---|
| IA confiante | Oui | Plus de 20 évaluations intégrées | Basique | Basé sur l'utilisation |
| Langfuse | Oui | Évaluateurs personnalisés | Avancé | Gratuit / $249/mois |
| Hélicone | Oui | Limité | Non | Gratuit / $79/mois |
| Datadog LLM | Oui | Métriques personnalisées | Basique | Tarifs pour entreprises |
| Tissage W&B | Oui | axé sur l'expérimentation | rediffusion hors ligne | Niveau gratuit disponible |

Concevoir des systèmes LLM avec un suivi clair des coûts et de la qualité
Les applications LLM nécessitent une visibilité sur les performances des modèles en production. Le suivi des invites, des réponses, de l'utilisation des jetons et du comportement du système aide les équipes à maintenir la qualité et à comprendre comment leurs systèmes d'IA sont réellement utilisés. IA supérieure Cette entreprise développe des plateformes d'IA où les modèles de langage sont intégrés aux systèmes backend, aux pipelines de données et aux outils d'analyse. Ses ingénieurs conçoivent des logiciels d'IA qui prennent en charge la journalisation, l'évaluation et la surveillance, permettant ainsi une gestion fiable des applications LLM en production.
Déploiement d'une application LLM en production ?
Dialoguer avec une IA supérieure à :
- développer des applications basées sur LLM et des outils de traitement automatique du langage naturel
- intégrer les flux de travail de surveillance et d'analyse
- déployer des systèmes d'IA au sein de plateformes logicielles existantes
👉 Contactez-nous IA supérieure pour discuter de votre projet de développement en IA.
Choisir le bon modèle pour une analyse rentable
Le choix de la plateforme est important, mais c'est le choix du modèle qui détermine le coût et la qualité des résultats. Des études comparatives récentes révèlent des différences significatives dans la capacité des modèles à gérer les charges de travail analytiques.
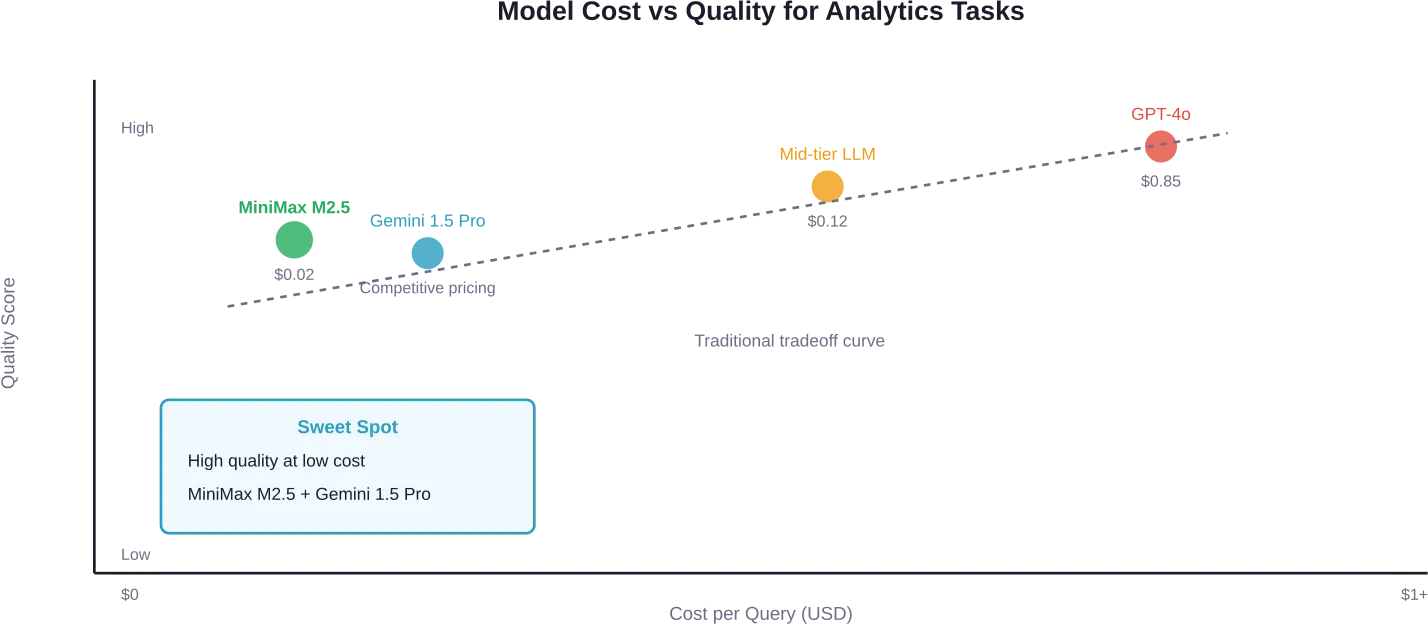
Selon des tests effectués sur de vraies données Google Analytics, MiniMax M2.5 a fourni une excellente qualité sur plusieurs exécutions de tests, a coûté $0.02 par requête et a atteint un temps d'exécution moyen de 70 secondes.
Le modèle de référence a été évalué selon plusieurs dimensions :
- Évaluation de la qualité : Le modèle a-t-il permis d'obtenir des informations exploitables au-delà des données brutes ?
- Score de précision : Dans quelle mesure a-t-il utilisé avec précision les dimensions et les mesures réelles de GA4 ?
- Coût par requête : Coût total de l'API pour la réalisation de la tâche analytique
- Latence: Délai entre la soumission initiale et l'achèvement
Pour les analyses stratégiques exigeant un raisonnement approfondi, Gemini 1.5 Pro a démontré d'excellentes performances. Il a immédiatement identifié les problèmes de suivi d'attribution dans les données de test et s'est orienté vers une analyse des conversions exploitable. À ce prix, les équipes peuvent exécuter des centaines de requêtes par jour à moindre coût.
Les recherches sur la sélection de modèles linéaires pour les tâches complexes à plusieurs étapes confirment ces résultats. Le cadre MixLLM a démontré que, comparativement à l'utilisation d'un seul modèle linéaire commercial performant, la sélection adaptative de modèles améliore la qualité des résultats de 1 à 161 TP3T tout en réduisant le coût d'inférence de 18 à 921 TP3T.
Cadre de compromis coût-qualité
Les recherches sur le dépassement des compromis coût-qualité dans le domaine des agents conversationnels révèlent que les architectures sensibles aux sessions peuvent s'affranchir de la courbe de compromis traditionnelle. AgServe atteint une qualité de réponse comparable à celle de GPT-4o pour un coût 16,51 T³ T grâce à deux innovations :
- Gestion du cache KV prenant en compte la session : Ce système utilise l'éviction basée sur l'estimation du temps d'arrivée et l'étalonnage de l'intégration positionnelle sur place pour optimiser considérablement la réutilisation du cache. Cela réduit les calculs redondants lors des sessions à plusieurs tours.
- Déploiement en cascade de modèles axés sur la qualité : Au lieu de s'engager sur un seul modèle pour toute une session, AgServe effectue une évaluation de la qualité en temps réel et met à niveau les modèles en cours de session si nécessaire. Cela permet de commencer avec des modèles moins coûteux et de passer à un modèle supérieur uniquement lorsque la qualité l'exige.
Cette recherche démontre une amélioration de la qualité de 1,8 fois par rapport à la courbe traditionnelle de compromis coût-qualité, prouvant ainsi que des choix architecturaux appropriés peuvent permettre d'obtenir de meilleurs résultats à moindre coût.
Indicateurs clés à suivre
Une analyse efficace des processus métier (LLM) nécessite le suivi des indicateurs clés de performance (KPI) pertinents. Trop d'équipes se concentrent exclusivement sur les coûts ou la latence, négligeant les signaux de qualité qui prédisent la satisfaction des utilisateurs.
Indicateurs de coûts
- Consommation de jetons par requête : Mesurez séparément les jetons d'entrée et de sortie. Les stratégies d'optimisation diffèrent : réduire le nombre de jetons d'entrée nécessite une ingénierie rapide, tandis que contrôler le nombre de jetons de sortie requiert de meilleurs paramètres d'échantillonnage ou des contraintes de format.
- Coût par interaction utilisateur : Calculer le coût total des jetons pour l'ensemble des appels API nécessaires à la réalisation d'une tâche utilisateur. Une simple question utilisateur peut déclencher plusieurs appels au modèle (extraction, raisonnement, mise en forme), et le coût total est plus pertinent que le coût de chaque appel.
- Coût par fonctionnalité ou point de terminaison : L'attribution permet d'analyser le retour sur investissement. Quelles fonctionnalités génèrent une valeur justifiant leurs coûts LLM ? Lesquelles entraînent une perte de ressources sans bénéfice proportionnel pour l'utilisateur ?
La documentation d'Anthropic sur la gestion des coûts met l'accent sur le suivi des modèles d'utilisation avec la commande /stats, qui offre une visibilité au niveau de la session sur l'utilisation des jetons, la durée de l'API, le temps réel et les modifications du code.
Indicateurs de qualité
- Taux d'hallucinations : Pourcentage de réponses contenant des informations falsifiées non étayées par le contexte fourni. Cela nécessite une vérification automatisée des faits à partir de documents sources ou de bases de connaissances.
- Score de pertinence : Dans quelle mesure la saisie semi-automatique répond-elle à la requête réelle de l'utilisateur ? La similarité sémantique entre la question et la réponse fournit une mesure indirecte.
- Conformité du format : Pour les sorties structurées (JSON, CSV, SQL), quel pourcentage des analyses se déroulent avec succès et sans erreurs ?
- Infractions aux règles de sécurité : Fréquence des sorties contenant des informations personnelles identifiables, du contenu offensant ou des réponses aux tentatives d'injection de requêtes.
Une étude sur l'évaluation de la qualité du raisonnement logique lors de la génération de code a révélé que les facteurs externes expliquent 53,60% (principalement des exigences imprécises et un contexte manquant), tandis que les facteurs internes expliquent 40,10% (principalement des incohérences entre le raisonnement et les instructions). Cela suggère que le suivi de la qualité des données d'entrée et des schémas de raisonnement du modèle est important pour garantir la qualité des résultats.
Indicateurs de performance
- Délai d'obtention du premier jeton (TTFT) : Latence avant que le modèle ne commence à diffuser les données. Essentielle pour la réactivité perçue des interfaces de chat.
- Jetons par seconde : Vitesse de génération une fois le streaming lancé. Les vitesses plus lentes frustrent les utilisateurs qui attendent longtemps la fin du traitement.
- Latence de bout en bout : Temps total entre la requête de l'utilisateur et la réponse complète, y compris la récupération, le prétraitement, l'inférence du modèle et le post-traitement.
| Catégorie métrique | Indicateurs clés | Pourquoi c'est important
|
|---|---|---|
| Coût | Utilisation des jetons, coût par interaction, coût par fonctionnalité | Contrôle les dépenses et permet l'analyse du retour sur investissement |
| Qualité | Taux d'hallucinations, score de pertinence, conformité au format | Garantit la précision des résultats et la satisfaction des utilisateurs |
| Performance | TTFT, jetons/seconde, latence de bout en bout | Maintient une expérience utilisateur réactive |
| Sécurité | Fuites d'informations personnelles, tentatives d'injection de signaux rapides, violations de la politique de confidentialité | Prévient les incidents de sécurité et les problèmes de conformité |
Stratégies de mise en œuvre
Pour tirer pleinement parti de l'analyse LLM, il ne suffit pas d'installer un outil de surveillance. Les équipes ont besoin d'approches structurées en matière d'instrumentation, de conception d'évaluation et d'alerte.
Commencez par le traçage
Les appels d'API Instrument LLM permettent de capturer l'intégralité des données de requête et de réponse.
Au minimum, journaliser :
- Horodatage et identifiant de la requête
- Nom du modèle et paramètres
- Invite complète (message système, saisie utilisateur, contexte)
- Texte intégral
- Nombre de jetons (entrée, sortie, total)
- Répartition de la latence (temps d'API, temps de traitement)
- calcul des coûts
La plupart des plateformes d'analyse proposent des kits de développement logiciel (SDK) qui gèrent cela automatiquement. Mais même une simple journalisation personnalisée dans un format structuré permet une analyse a posteriori.
Définir les critères de qualité
Les recherches visant à simplifier l'évaluation des agents d'IA soulignent que les stratégies d'évaluation doivent être adaptées à la complexité du système. Les évaluateurs basés sur le code (comparaison de chaînes de caractères, tests binaires, analyse statique) fonctionnent pour des résultats déterministes. Les évaluateurs basés sur les modèles linéaires logiques (LLM) prennent en charge l'évaluation sémantique lorsque la correspondance exacte échoue.
Créez un jeu de données de référence avec des invites représentatives et les résultats attendus. Testez les nouvelles versions du modèle ou les modèles d'invite sur ce jeu de données avant le déploiement. Suivez les indicateurs de qualité au fil du temps pour détecter toute régression.
Selon les recommandations d'OpenAI concernant l'évaluation des agents avec Langfuse, l'évaluation hors ligne consiste généralement à disposer d'un ensemble de données de référence avec des paires invite-sortie, à exécuter l'agent sur cet ensemble de données et à comparer les sorties à l'aide de mécanismes de notation supplémentaires.
Configurer les alertes de coûts
Les dépassements de budget sont rapides avec une tarification basée sur les jetons.
Configurer les alertes pour :
- Coût journalier dépassant le niveau de référence de 25%+
- Les requêtes individuelles consomment 10 fois plus de jetons que la normale
- Des utilisateurs ou des fonctionnalités spécifiques engendrant des coûts disproportionnés
- Des changements inattendus de version de modèle augmentent les dépenses
Les alertes doivent inciter à l'investigation, et non à la panique. Les pics de coûts indiquent souvent le succès d'un produit (augmentation de son utilisation) plutôt que des problèmes. Toutefois, la visibilité permet de distinguer la croissance de l'inefficacité.
Mettre en œuvre des boucles de rétroaction
Les indicateurs automatisés ne rendent pas compte de tout ce qui importe aux utilisateurs. Ajoutez des mécanismes de retour d'information explicites :
- Évaluation positive/négative des travaux terminés
- Signalement détaillé des problèmes liés aux résultats médiocres
- Enquêtes de satisfaction au niveau de la session
Mettez en corrélation les commentaires des utilisateurs avec les scores de qualité automatisés. Si les utilisateurs attribuent systématiquement de mauvaises notes à des tâches pourtant bien notées, les indicateurs automatisés doivent être recalibrés.
Techniques d'optimisation avancées
Une fois le système de surveillance de base opérationnel, plusieurs techniques avancées peuvent améliorer considérablement les rapports coût-qualité.
Modèle en cascade prenant en compte la session
Les recherches sur la gestion des agents montrent que la sélection de modèles en fonction de la session apporte des améliorations considérables. Au lieu d'utiliser un seul modèle pour toute la durée d'une conversation, le système commence avec un modèle moins coûteux et passe à un modèle supérieur en cours de session lorsque la qualité l'exige.
Le framework AgServe atteint une qualité équivalente à celle de GPT-4o pour un coût de 16,5% en sélectionnant et en mettant à niveau dynamiquement les modèles pendant la durée de vie de la session sur la base d'une évaluation de la qualité en temps réel.
La mise en œuvre nécessite :
- Évaluation de la qualité après chaque réponse du modèle
- Seuils définissant les niveaux de qualité acceptables
- Logique permettant de passer à des modèles plus performants (et plus coûteux) en cas de besoin.
- Gestion du cache KV pour réutiliser le contexte lors des changements de modèle
Optimisation rapide basée sur l'analyse de données
L'analyse des données révèle les schémas de requêtes qui sont corrélés à des problèmes de qualité ou à des dépassements de coûts. Parmi les problèmes courants, on peut citer :
- Surcharge de contexte excessive : L'ajout de documents entiers aux invites, alors que des extraits ciblés suffiraient, est problématique. Les analyses montrant un nombre élevé de jetons d'entrée avec de faibles scores de pertinence indiquent ce problème.
- Instructions vagues : Les consignes génériques telles que “ analyser ces données ” produisent des résultats confus et décousus. Des analyses révélant une faible conformité au format ou une grande variation dans la longueur des résultats suggèrent des problèmes de clarté des instructions.
- Contraintes manquantes : Ne pas spécifier la longueur ou le format de la sortie entraîne des requêtes inutilement longues. L'analyse de l'utilisation des jetons permet de le constater rapidement.
Stratégies de mise en cache
De nombreuses applications LLM traitent de manière répétée des contextes similaires. L'analyse des préfixes d'invite à haute fréquence permet de mettre en place des stratégies de mise en cache ciblées.
La mise en cache sémantique stocke les représentations des invites récentes. Lorsqu'une nouvelle invite est sémantiquement similaire à une invite en cache, elle renvoie la complétion mise en cache au lieu d'appeler l'API. Cette méthode est particulièrement adaptée aux applications de type FAQ où de nombreux utilisateurs posent des questions similaires.
La mise en cache des préfixes d'invite permet de réutiliser le traitement des messages système et du contexte communs. Si 80% invites partagent le même préfixe de 2 000 jetons, la mise en cache de ce calcul permet de réaliser des économies importantes.
Pièges courants et comment les éviter
Même les équipes disposant d'une infrastructure de surveillance commettent des erreurs prévisibles qui nuisent à l'efficacité des analyses.
Suivi des indicateurs de vanité
Des indicateurs comme le nombre total d'appels API ou le nombre total de jetons ne sont pas déterminants pour les décisions. Ils augmentent au fur et à mesure que le produit rencontre du succès. Il faut plutôt suivre les indicateurs qui signalent les problèmes : coût par valeur ajoutée, taux de dégradation de la qualité, anomalies de latence.
Ignorer la signification statistique
Les résultats des projets LLM sont aléatoires. Un seul échec ne révèle pas de problèmes systémiques. Cependant, les équipes ont souvent tendance à surréagir aux échecs isolés au lieu d'analyser les tendances.
Il est nécessaire de disposer d'échantillons suffisamment grands avant de conclure à l'existence d'une régression de qualité. Les recherches sur la sélection des modèles linéaires linéaires pour les tâches multi-étapes mettent l'accent sur la conception de systèmes capables de tolérer les fluctuations de performance dues à la stochasticité de ces modèles.
Optimisation basée uniquement sur les coûts
Réduire les coûts grâce à 50% n'a aucun sens si la qualité se dégrade au point de nuire à l'expérience utilisateur. L'objectif est d'obtenir un rapport coût-qualité optimal, et non de minimiser les coûts.
Les outils d'analyse doivent suivre les deux dimensions simultanément. Les recherches sur le service prenant en compte les sessions démontrent qu'une architecture appropriée peut améliorer la qualité. alors que réduire les coûts, en dépassant le compromis traditionnel.
Non testé en production
L'évaluation hors ligne avec des jeux de données de référence est importante, mais le comportement en production diffère. Les utilisateurs formulent leurs requêtes différemment de ce qu'anticipent les concepteurs de tests. Les cas limites rencontrés en conditions réelles n'apparaissent pas dans les jeux de données standardisés.
Mettez en place une surveillance continue de la production et utilisez-la pour affiner les benchmarks hors ligne. Ces benchmarks doivent évoluer pour refléter les modèles d'utilisation réels.
Questions fréquemment posées
Quelle est la différence entre la surveillance LLM et l'observabilité LLM ?
La surveillance suit des indicateurs prédéfinis et génère des alertes lorsqu'ils dépassent des seuils. L'observabilité permet d'explorer le comportement du système grâce à des requêtes personnalisées sur des données de traçage détaillées. La plupart des plateformes modernes combinent ces deux approches : des indicateurs structurés pour les tableaux de bord et les alertes, et des traces détaillées pour le débogage de problèmes spécifiques.
Combien coûte généralement l'analyse LLM ?
Les modèles de tarification varient considérablement. Les plateformes à l'usage facturent en fonction du volume de traces. Les plateformes par abonnement comme Langfuse Pro coûtent $249/mois pour un nombre illimité de traces. Les suites d'entreprise comme Datadog intègrent la surveillance LLM aux contrats existants.
Les outils analytiques peuvent-ils réduire les coûts de mon LLM ?
L'analyse des données ne réduit pas directement les coûts, mais elle permet de prendre des décisions d'optimisation qui, elles, les réduisent. Les recherches sur le service prenant en compte les sessions démontrent que des réductions de coûts supérieures à 80% sont possibles grâce à des améliorations architecturales.
Quels sont les indicateurs de qualité les plus importants pour les applications LLM de production ?
Le taux d'hallucination et le score de pertinence sont essentiels à l'exactitude des faits. La conformité au format est importante pour les résultats structurés. Les indicateurs de sécurité (fuite de données personnelles, résistance à l'injection de vulnérabilités) préviennent les incidents de sécurité. Les indicateurs spécifiques dépendent du cas d'utilisation : les applications de support client privilégient des dimensions de qualité différentes de celles des outils de génération de code.
Dois-je utiliser des outils d'analyse LLM open source ou commerciaux ?
Les outils open source comme Langfuse offrent une grande flexibilité de déploiement et une absence de dépendance vis-à-vis d'un fournisseur, mais nécessitent la gestion de l'infrastructure. Les plateformes commerciales proposent un hébergement géré, un développement plus rapide des fonctionnalités et un support dédié. Les équipes disposant de solides compétences en infrastructure privilégient souvent l'open source. Les équipes axées sur le développement applicatif plutôt que sur l'exploitation optent généralement pour des solutions gérées.
Comment mesurer le retour sur investissement des analyses LLM ?
Suivez trois dimensions : les économies réalisées grâce à l’optimisation (réduction de la consommation de jetons), les améliorations de la qualité (meilleures évaluations des utilisateurs, moins de tickets d’assistance) et la productivité des développeurs (débogage plus rapide, déploiements plus sûrs). La plupart des équipes constatent un retour sur investissement positif en 2 à 3 mois grâce à la seule optimisation des coûts, avant même de prendre en compte les gains en termes de qualité et de productivité.
Quelle est la configuration analytique minimale viable pour une nouvelle demande de LLM ?
Commencez par un système de traçage basique qui enregistre chaque invite, chaque exécution, chaque jeton et chaque coût. Ajoutez un indicateur de qualité simple et adapté au domaine (conformité du format pour les sorties structurées, score de pertinence pour les applications de messagerie instantanée). Configurez des alertes de coût pour les dépassements de budget. Cette configuration minimale prend 1 à 2 jours à mettre en œuvre et permet d'éviter les problèmes de production les plus courants.
Conclusion
L'analyse des données LLM est passée d'un atout appréciable à une nécessité en production. Sans visibilité sur les coûts des jetons, les indicateurs de qualité et les caractéristiques de performance, les équipes travaillent à l'aveugle.
L'écosystème des plateformes offre des solutions performantes pour répondre à différents besoins. Confident AI se positionne comme leader en matière de surveillance qualité axée sur l'évaluation. Langfuse propose la flexibilité de l'open source avec un suivi de session robuste. Helicone assure une visibilité rapide des coûts grâce à un déploiement basé sur un proxy. Datadog étend l'observabilité de l'entreprise aux charges de travail LLM.
Mais les outils seuls ne garantissent pas le succès. Une analyse efficace nécessite le suivi des indicateurs clés, l'établissement de référentiels de qualité, la mise en place de boucles de rétroaction et l'utilisation des données pour orienter les décisions d'optimisation.
La recherche démontre que les architectures prenant en compte les sessions peuvent s'affranchir des compromis traditionnels entre coût et qualité. AgServe atteint une qualité équivalente à celle de GPT-4o pour un coût 16,51 TP3T grâce à une gestion intelligente du cache KV et à une sélection dynamique du modèle. Ces techniques sont efficaces car elles adaptent l'architecture système aux caractéristiques uniques des charges de travail LLM.
Les équipes qui obtiennent les meilleurs résultats partagent des pratiques communes. Elles mettent en place un système d'instrumentation complet dès le départ. Elles définissent rapidement des critères de qualité et suivent en continu les régressions. Elles optimisent leurs processus en se basant sur les données plutôt que sur l'intuition. Et elles considèrent l'analyse de données comme un système de rétroaction qui s'améliore avec le temps, et non comme une opération ponctuelle.
Commencez par mettre en place un système de traçabilité et de suivi des coûts de base. Ajoutez des indicateurs de qualité pertinents pour le cas d'utilisation. Configurez des alertes pour détecter les problèmes avant qu'ils n'affectent les utilisateurs. Utilisez ensuite la visibilité ainsi obtenue pour améliorer progressivement les invites, la sélection des modèles et l'architecture du système.
La différence entre les équipes qui réussissent dans le développement d'applications LLM en production et celles qui rencontrent des difficultés réside souvent dans l'analyse des données. La mesure permet l'optimisation. L'optimisation favorise une rentabilité durable. Et une rentabilité durable permet de créer des produits d'IA véritablement utiles.