Résumé rapide : Les stratégies d'optimisation des coûts LLM aident les organisations à réduire leurs dépenses opérationnelles tout en maintenant les performances de l'IA. Les principales approches comprennent l'optimisation rapide, le routage des modèles, la mise en cache, la quantification et l'optimisation de l'infrastructure. Les recherches montrent que ces techniques peuvent réduire les coûts de 10 à 501 Tk grâce à des méthodes telles que la compression rapide, la sélection stratégique des modèles et une gestion efficace des jetons.
Les coûts opérationnels liés à l'exécution de grands modèles de langage en production peuvent rapidement s'envoler. Ce qui commence comme une preuve de concept prometteuse se transforme en fardeau financier lorsqu'il est déployé à l'échelle de millions d'appels API mensuels.
Les organisations qui déploient des modèles linéaires à grande échelle (LLM) sont confrontées à une dure réalité : les coûts de traitement augmentent linéairement avec l’utilisation. Pour un modèle comportant environ 175 milliards de paramètres, l’espace mémoire requis serait d’environ 350 Go (pour FP16) ou 700 Go (pour FP32). Il ne s’agit là que du stockage ; les coûts d’inférence proprement dits s’accumulent à chaque jeton traité.
Mais voilà le point essentiel : optimiser les coûts ne signifie pas sacrifier la performance. Des approches stratégiques permettent de réduire considérablement les dépenses tout en maintenant, voire en améliorant, la qualité de la production.
Comprendre les modèles de tarification des LLM
La plupart des services LLM basés sur le cloud facturent au jeton. Les utilisateurs paient séparément les jetons d'entrée (l'invite) et les jetons de sortie (la réponse générée). Ce mécanisme de paiement au jeton crée une dynamique intéressante.
Les recherches du laboratoire d'IA Watson du MIT et d'IBM (publiées dans “ Guide pratique de l'estimation des lois d'échelle ”, 2024/2025) montrent qu'une erreur relative moyenne (ERM) d'environ 4% représente approximativement la meilleure précision de prédiction atteignable lors de l'estimation des lois d'échelle (c'est-à-dire la prévision de la perte d'un grand modèle à partir de modèles plus petits de la même famille). Cette précision est principalement due au bruit aléatoire des germes d'initialisation, qui peut à lui seul engendrer des différences allant jusqu'à environ 4% dans la perte finale, même pour des configurations d'entraînement identiques. Une ERM allant jusqu'à 20% reste utile pour de nombreuses tâches pratiques de prise de décision, notamment la sélection de modèles et l'allocation budgétaire. Ces considérations sont importantes lors de l'évaluation des compromis coût-performance entre les familles ou les tailles de modèles.
Les jetons d'entrée mis en cache coûtent généralement environ 10 % du prix des jetons d'entrée classiques. Cette asymétrie de prix permet de réaliser des économies substantielles grâce à des approches de mise en cache stratégiques.
La structure tarifaire implique également que, pour la plupart des fournisseurs, la production des livrables coûte plus cher que le traitement des intrants. Ce constat fondamental sous-tend plusieurs stratégies d'optimisation visant à réorienter la consommation de jetons des livrables coûteux vers les intrants moins onéreux.
Techniques d'optimisation rapide
L'optimisation des invites représente la solution la plus simple pour réduire les coûts. Des invites mal structurées gaspillent des ressources et génèrent des résultats inutiles.
Compresser sans perdre le contexte
Les invites trop longues consomment beaucoup de ressources. Une demande de description de produit pourrait initialement indiquer : “ Générez une description de produit attrayante pour un smartphone. Elle doit mentionner les caractéristiques et spécifications clés, telles que la taille de l’écran, la résolution de l’appareil photo, l’autonomie de la batterie et la capacité de stockage. Essayez de la rendre attrayante et persuasive. ”
Version optimisée : “ Générer une description de produit attrayante pour un smartphone doté d’un écran de 6,5 pouces, d’un appareil photo de 48 MP, d’une batterie de 5 000 mAh et d’une capacité de stockage de 256 Go. ”
Même objectif, moins de jetons, instructions plus précises. Cette approche réduit les coûts de production tout en améliorant souvent la qualité du résultat grâce à une plus grande précision.
Structurer les résultats de manière stratégique
Les sorties structurées minimisent le gaspillage de jetons. Au lieu de demander des réponses libres nécessitant un traitement, privilégiez le format JSON ou des formats spécifiques. Cette technique est couramment utilisée dans les systèmes de production où les frameworks d'agents électroniques emploient des sorties structurées afin de réduire la longueur des réponses possibles.
D'après la documentation d'OpenAI sur le réglage fin du renforcement, des spécifications de tâches claires avec des réponses vérifiables permettent un comportement plus efficace du modèle. Des grilles d'évaluation explicites et des correcteurs basés sur le code mesurent la réussite fonctionnelle tout en réduisant la verbosité inutile.
| Type d'invite | Utilisation des jetons | Impact sur les coûts | Idéal pour
|
|---|---|---|---|
| Verbeux, non structuré | Haut | Ligne de base | Phase d'exploration |
| Comprimé, structuré | Moyen | Réduction 20-30% | Déploiements en production |
| En cache avec structure | Faible | Réduction 40-50% | tâches répétitives |
Sélection et routage stratégiques des modèles
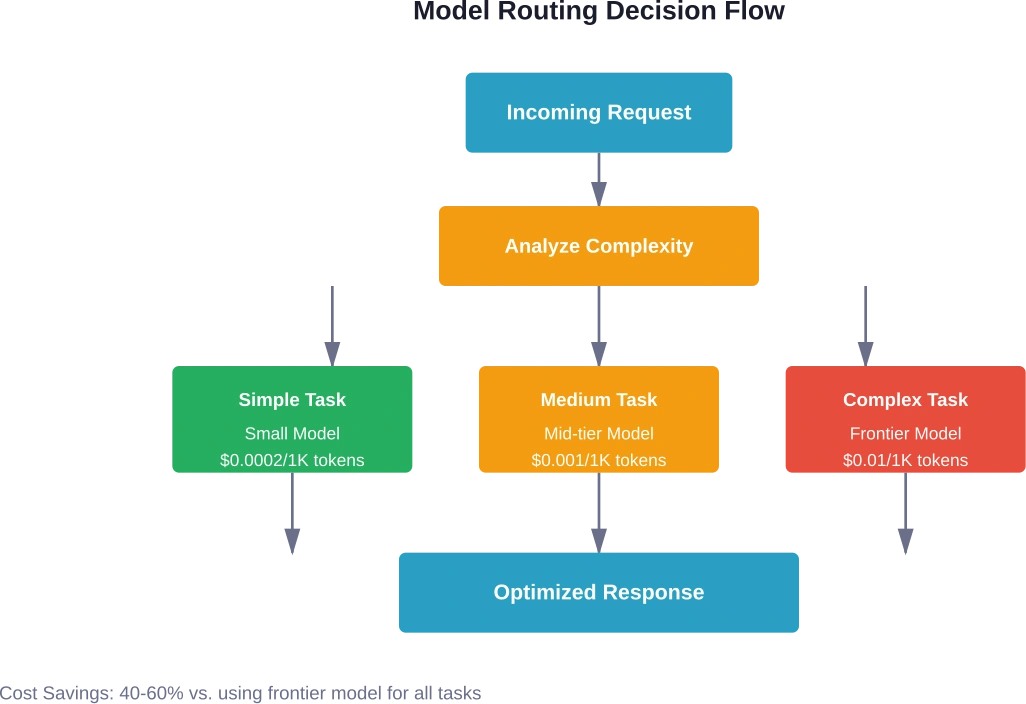
Toutes les tâches ne nécessitent pas le modèle le plus puissant disponible. Le routage des modèles (qui consiste à orienter les différentes requêtes vers les modèles de taille appropriée) permet de réaliser des économies substantielles.
Adapter les capacités du modèle à la complexité de la tâche
Les tâches de classification simples ne nécessitent pas de modèles de pointe. L'analyse des sentiments, la synthèse de données basique ou l'étiquetage catégoriel fonctionnent très bien avec des alternatives plus légères et moins coûteuses. Réservez les modèles onéreux au raisonnement complexe, à la génération nuancée ou aux tâches de connaissances spécialisées.
Les recherches sur l'efficacité des modèles montrent que des architectures repensées peuvent atteindre des performances comparables à différentes échelles. L'architecture du modèle joue un rôle crucial qui dépasse le simple nombre de paramètres.
Les systèmes de production indiquent utiliser une combinaison de déploiements de modèles OpenAI, Anthropic et locaux en fonction des exigences des tâches, pour plus de 2 millions d'appels API mensuels. Cette approche hétérogène optimise le rapport coût-performance pour différents cas d'utilisation.
Mettre en œuvre une logique de routage intelligente
Les systèmes de routage automatisés analysent les requêtes entrantes et sélectionnent les modèles appropriés. Les plateformes d'intelligence artificielle optimisent automatiquement la sélection des modèles logiques et l'infrastructure sous-jacente, éliminant ainsi les tâches de décision manuelle.
La logique de routage prend en compte des facteurs tels que la complexité des requêtes, la précision requise, la tolérance à la latence et le prix en vigueur. Le routage dynamique s'adapte aux conditions changeantes sans intervention manuelle.
Stratégies de mise en cache pour les charges de travail répétitives
La mise en cache permet de réduire considérablement et immédiatement les coûts des applications présentant des schémas répétitifs. Les systèmes de production affichent des taux d'accès au cache de 40 %, certains déploiements permettant d'économiser environ 1 400 000 € par mois sur les coûts d'API.
Mettre en œuvre la mise en cache sémantique
La mise en cache de base conserve les correspondances exactes avec les requêtes. La mise en cache sémantique va plus loin : elle reconnaît les requêtes similaires même avec des formulations différentes. “ Comment réinitialiser mon mot de passe ? ” et “ Quelle est la procédure de récupération de mot de passe ? ” déclenchent la même réponse mise en cache.
Cette approche est particulièrement avantageuse pour le support client, la recherche documentaire et les systèmes de FAQ, où les utilisateurs formulent différemment des questions identiques.
Messages et contexte du système de cache
Les invites système définissant le comportement du modèle changent rarement. Leur mise en cache réduit les traitements redondants. Le contexte apparaissant dans plusieurs requêtes (informations sur l'entreprise, catalogues de produits, guides de style, etc.) doit être mis en cache de manière systématique.
Les approches d'ingénierie du contexte montrent que les sous-agents peuvent explorer en profondeur, en utilisant des dizaines de milliers de jetons, mais ne renvoient que des résumés condensés de 1 000 à 2 000 jetons. La mise en cache de ces résultats intermédiaires évite les explorations approfondies redondantes des mêmes informations.
Arrêt précoce et contrôle de la production
Les modèles génèrent souvent plus de contenu que nécessaire. Les techniques d'arrêt précoce détectent lorsqu'une quantité suffisante d'informations a été produite et interrompent la génération.
Les recherches sur ES-CoT (Early Stopping Chain-of-Thought) présentent des méthodes permettant de détecter la convergence des réponses et d'interrompre la génération prématurément. Lorsque des réponses identiques et consécutives indiquent une convergence, la génération s'arrête, réduisant ainsi le coût des jetons d'inférence tout en maintenant une précision comparable.
Cette technique consiste à demander au modèle de fournir sa réponse actuelle à chaque étape de raisonnement. La longueur des séquences de réponses identiques consécutives sert de mesure de convergence. Une augmentation brutale de cette longueur, dépassant les seuils minimaux, entraîne l'arrêt du modèle.
Définir des limites maximales de jetons
Limitez explicitement la longueur des données de sortie via les paramètres de l'API. Cela évite une génération excessive de données qui gaspille des jetons en traitements inutiles. Les limites varient selon les tâches ; adaptez-les en fonction du cas d'utilisation.
La classification nécessite 10 jetons. La synthèse pourrait en nécessiter 200. La génération de textes longs pourrait justifier plus de 1 000 jetons. Mais les paramètres par défaut autorisant une sortie illimitée entraînent un gaspillage.
Quantification et compression de modèles
La quantification réduit la précision des poids du modèle, diminuant ainsi les besoins en mémoire et les coûts de calcul. Les modèles linéaires à longue portée (LLM) utilisent généralement la précision FP16 pour réduire les besoins en mémoire par rapport à FP32. Une quantification plus poussée à INT8 ou INT4 permet des économies supplémentaires.
Quantification post-entraînement
La sparsité post-entraînement réduit le coût du modèle en supprimant des poids des réseaux denses. Des recherches sur l'induction de la sparsité démontrent l'efficacité de ces approches sur des modèles testés avec des GPU NVIDIA RTX A6000 (48 Go).
Les matrices denses natives présentent une faible sparsité, ce qui rend la suppression directe des poids perturbatrice. Les approches avancées induisent des motifs de sparsité qui préservent les capacités du modèle tout en réduisant les besoins de calcul.
Distillation pour des tâches spécialisées
La distillation des connaissances crée des modèles plus petits qui imitent des modèles plus grands pour des tâches spécifiques. Le modèle de l'élève apprend des résultats de l'enseignant, capturant ainsi le comportement pertinent pour la tâche avec un nombre réduit de paramètres.
Les frameworks d'autodistillation permettent de concevoir des modèles spécialisés avec des coûts d'inférence considérablement réduits grâce à des approches de distillation des connaissances.
| Technique | Complexité | Réduction des coûts | Impact sur la qualité
|
|---|---|---|---|
| Optimisation rapide | Faible | 20-30% | s'améliore souvent |
| Routage du modèle | Moyen | 40-60% | Minimal |
| Mise en cache | Faible | 30-50% | Aucun |
| Arrêt précoce | Moyen | 30-40% | Minimal |
| Quantification | Haut | 50-70% | Dégradation du 5-10% |
Architectures d'exécuteur-vérificateur
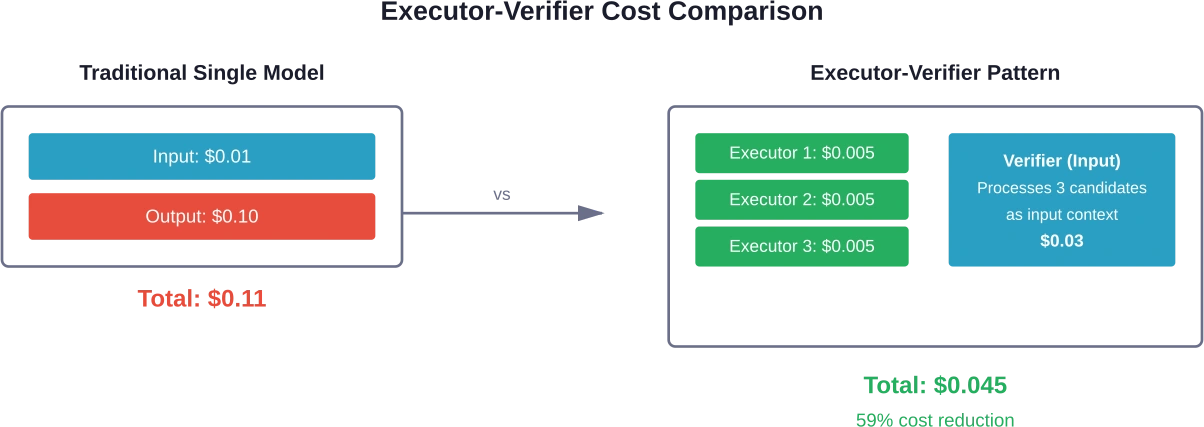
Le paradigme exécuteur-vérificateur déplace la consommation de jetons des sorties coûteuses vers des entrées moins onéreuses. Plusieurs petits modèles déployés localement génèrent des réponses candidates. Un modèle puissant basé sur le cloud vérifie quelle réponse candidate est correcte.
Les plateformes d'agents électroniques démontrent que cette approche réduit l'utilisation des jetons de 10 à 50 % par rapport aux méthodes classiques. L'asymétrie de prix entre les jetons d'entrée et de sortie rend la vérification moins coûteuse que la génération.
De petits exécutants fonctionnent localement ou sur une infrastructure peu coûteuse. Ils génèrent en parallèle de nombreux candidats variés. Le vérificateur traite tous les candidats comme contexte d'entrée (facturé à un tarif réduit de jetons d'entrée) et sélectionne ou synthétise la meilleure réponse.
Cette architecture convient particulièrement aux tâches présentant des critères de correction clairs : problèmes mathématiques, génération de code, questions factuelles ou extraction de données structurées.
Optimisation de l'infrastructure et du déploiement
Au-delà des optimisations au niveau du modèle, les choix d'infrastructure ont un impact significatif sur les coûts.
Optimiser la sélection du matériel
Le choix du GPU est crucial. NVIDIA TensorRT-LLM fournit des API Python permettant de définir des LLM avec des optimisations de pointe pour une inférence efficace sur les GPU NVIDIA. Les tests démontrent des gains de performance spectaculaires sur le matériel compatible.
Des expériences menées avec des cartes graphiques NVIDIA RTX A6000 dotées de 48 Go de mémoire ont démontré la viabilité de l'inférence pour les modèles nécessitant une gestion rigoureuse des ressources. Un dimensionnement matériel adapté permet d'éviter le surdimensionnement tout en maintenant une latence acceptable.
Traitement par lots lorsque possible
Les exigences de temps réel créent parfois des contraintes artificielles. Le traitement par lots de plusieurs requêtes simultanément améliore le débit et réduit le coût par requête. Des tâches comme la modération, la classification ou l'analyse de contenu tolèrent souvent de légers délais, ce qui permet le traitement par lots.
Envisagez l'auto-hébergement pour gagner en envergure.
À partir d'un volume suffisant, l'auto-hébergement devient économique. La tarification des API cloud inclut des marges importantes. Les organisations traitant des millions de requêtes par mois devraient envisager une infrastructure dédiée.
Le seuil de rentabilité dépend des capacités techniques, des coûts de maintenance et des habitudes d'utilisation. Les économies potentielles à grande échelle peuvent justifier une analyse approfondie.
Systèmes de raffinement itératifs
Les systèmes PDR (Parallel-Distill-Refine) génèrent simultanément plusieurs ébauches, les condensent dans des espaces de travail délimités et les affinent en fonction de ces espaces. Cette approche offre souvent de meilleures performances qu'une approche linéaire classique, tout en réduisant la latence et la taille du contexte.
Le raffinement séquentiel améliore itérativement une solution candidate unique sans espace de travail persistant. Les tests sur des tâches mathématiques montrent que les pipelines itératifs surpassent les méthodes de référence à passage unique, à budget séquentiel égal. Le PDR superficiel offre les gains les plus importants : une amélioration d'environ 10 % sur des ensembles de problèmes complexes.
Ces méthodes considèrent les modèles comme des opérateurs d'amélioration dotés de stratégies continues. Elles génèrent quatre réponses plus courtes et combinent leurs points forts en une seule réponse supérieure. Cette approche surpasse souvent la génération d'une seule réponse longue tout en utilisant moins de jetons au total.
Surveillance et optimisation continues
L'optimisation des coûts n'est pas un processus ponctuel. Une surveillance continue permet d'identifier de nouvelles opportunités et de détecter les régressions.
Suivi des indicateurs clés
Surveillez le nombre de jetons par requête, le coût par transaction, le taux d'accès au cache et la distribution des modèles sélectionnés. Établissez des valeurs de référence et signalez les anomalies. Les habitudes d'utilisation évoluent ; les stratégies d'optimisation doivent s'adapter.
Mettre en œuvre des boucles de rétroaction
Les systèmes d'agents auto-évolutifs intègrent des boucles de réentraînement qui permettent de corriger les problèmes et d'améliorer les performances. L'optimisation doit se poursuivre jusqu'à l'atteinte des seuils de qualité (généralement un nombre de sorties positives supérieur à 801 000) ou jusqu'à l'apparition de rendements décroissants, c'est-à-dire lorsque les nouvelles itérations n'apportent qu'une amélioration minime.
La conception de systèmes axée sur l'évaluation utilise les évaluations comme processus central pour la création de systèmes autonomes prêts pour la production. Une évaluation structurée, assortie de métriques claires, permet une amélioration systématique et objective.
Évaluation du modèle régulier
De nouveaux modèles, offrant des rapports qualité-prix améliorés, sont constamment mis sur le marché. Des évaluations trimestrielles garantissent que les déploiements tirent parti des dernières options. Le modèle de pointe d'hier devient l'alternative de milieu de gamme de demain.
Testez les nouvelles versions par rapport aux bancs d'essai existants. Le changement de modèle nécessite des modifications de code minimes, mais peut générer des économies substantielles ou des améliorations de fonctionnalités.
Pièges courants à éviter
Plusieurs erreurs compromettent les efforts d'optimisation :
- Optimisation excessive axée uniquement sur les coûts : La qualité est primordiale. Une réduction des coûts de 50 % ne sert à rien si la qualité de la production chute au point de nécessiter une intervention humaine. Il faut toujours mesurer la précision en parallèle des indicateurs de coûts.
- Ignorer les implications de la latence : Certaines techniques d'optimisation privilégient le coût à la latence. Le traitement par lots et le routage des modèles augmentent le temps de traitement. Veillez à ce que les performances restent acceptables pour les cas d'utilisation.
- Stratégies d'optimisation statique : Ce qui fonctionne aujourd'hui ne fonctionnera peut-être plus demain. La tarification des modèles évolue, de nouvelles fonctionnalités apparaissent et les habitudes d'utilisation se transforment. Les stratégies statiques perdent progressivement de leur efficacité.
- Optimisation prématurée : Commencez par des techniques de base comme l'optimisation rapide et la mise en cache. Les approches complexes, telles que la distillation de modèles personnalisés, nécessitent un investissement conséquent. Assurez-vous que le volume d'activité justifie l'effort.
Exemples concrets d'économies réalisées
Les déploiements en production démontrent des économies significatives grâce à ces stratégies.
Les systèmes traitant plus de 2 millions d'appels API mensuels sur plusieurs applications affichent un taux d'accès au cache de 40 %, ce qui représente une économie d'environ 1 TP4 TP3 000 par mois. Il s'agit d'une solution simple à mettre en œuvre avec un retour sur investissement immédiat.
Les frameworks E-Agent, qui réduisent l'utilisation des jetons de 10 à 50 %, maintiennent, voire améliorent, la précision des tâches nécessitant une connaissance approfondie. Les tests effectués sur des tâches de raisonnement et de traitement de l'information démontrent l'efficacité de l'approche exécuteur-vérificateur.
Les méthodes d'arrêt précoce réduisent les jetons d'inférence d'environ 41 % en moyenne sur cinq ensembles de données de raisonnement et trois LLM tout en maintenant une précision comparable.
Ces résultats représentent les données recueillies sur des systèmes de production gérant des charges de travail réelles.

Arrêtez de gaspiller votre argent dans des LLM avec AI Superior
Nombre d'équipes adoptent des modèles de langage complexes et ne réalisent que plus tard la rapidité avec laquelle les coûts d'infrastructure peuvent exploser. L'utilisation des jetons augmente, les modèles s'exécutent plus longtemps que prévu et les systèmes qui fonctionnaient en phase de test deviennent onéreux en production.
IA supérieure Cette entreprise aide les sociétés à concevoir et optimiser leurs systèmes LLM afin de garantir leur efficacité à grande échelle. Ses équipes travaillent sur le développement de modèles personnalisés, leur mise au point et l'optimisation des flux de travail d'IA, réduisant ainsi souvent la consommation de ressources de calcul inutile et améliorant le déploiement des modèles au sein des processus métiers réels.
Si les frais de votre LLM continuent d'augmenter, contactez IA supérieure pour auditer votre configuration et corriger les inefficacités avant l'arrivée de votre prochaine facture cloud.
Questions fréquemment posées
Quel est le moyen le plus rapide de réduire les coûts d'un LLM ?
L'optimisation des invites et la mise en cache offrent des résultats immédiats avec une complexité de mise en œuvre minimale. Commencez par compresser les invites verbeuses, exiger des résultats structurés et implémenter une mise en cache basique pour les requêtes répétées. Ces modifications peuvent réduire les coûts de 20 à 40 % en quelques jours.
Combien peut-on économiser grâce au routage de modèles ?
Le routage de modèles permet généralement de réaliser des économies de 40 à 60 % par rapport à l'utilisation de modèles frontières pour toutes les tâches. Les économies exactes dépendent de la répartition des tâches : les environnements comportant de nombreuses tâches simples de classification ou d'extraction affichent des économies plus importantes que ceux nécessitant principalement un raisonnement complexe.
La quantification nuit-elle significativement à la qualité du modèle ?
Les techniques de quantification modernes préservent remarquablement bien la qualité. La quantification INT8 entraîne généralement une dégradation de la précision de 1 à 3 % tout en réduisant les besoins en mémoire d'environ 50 %. La quantification INT4 présente une dégradation de 5 à 10 %, mais permet d'exécuter des modèles beaucoup plus volumineux sur du matériel aux ressources limitées.
Quand les organisations devraient-elles envisager l'auto-hébergement ?
L'auto-hébergement devient rentable pour un volume mensuel de jetons compris entre 10 et 50 millions, selon les capacités techniques et le prix des API cloud. Les organisations possédant une expertise en ingénierie du ML et des habitudes d'utilisation régulières atteignent le seuil de rentabilité plus rapidement. Calculez le coût total de possession, incluant l'infrastructure, la maintenance et les coûts d'opportunité.
À quelle fréquence faut-il réévaluer les stratégies d'optimisation des coûts ?
Les analyses trimestrielles permettent de déceler les évolutions majeures en matière de prix, de fonctionnalités des modèles et de modes d'utilisation. Le suivi mensuel des indicateurs clés identifie les anomalies nécessitant une intervention immédiate. Toute modification importante des fonctionnalités de l'application justifie une réévaluation immédiate de son optimisation.
Les petites entreprises peuvent-elles se permettre des techniques d'optimisation avancées ?
Absolument. Des techniques de base comme l'optimisation des prompts, la mise en cache et la sélection de modèles nécessitent un investissement technique minimal. Les approches avancées telles que la distillation personnalisée ou l'auto-hébergement sont pertinentes pour des volumes plus importants, mais les économies initiales proviennent de modifications simples que toute organisation peut mettre en œuvre.
Quel est le lien entre l'optimisation des coûts et la latence ?
Certaines techniques améliorent à la fois les coûts et la latence : l’arrêt précoce réduit simultanément les coûts et la latence. D’autres impliquent des compromis : le routage par modèle engendre une légère surcharge, tandis que le traitement par lots retarde les requêtes individuelles. Concevez des stratégies d’optimisation en tenant compte des exigences de latence propres à chaque cas d’utilisation.
Poursuivre l'optimisation des coûts
L'optimisation des coûts LLM est un processus continu, non un aboutissement. Commencez par des techniques à fort impact et à faible complexité. Mesurez rigoureusement les résultats. Itérez en fonction des données.
Les organisations qui réussissent leurs déploiements LLM en production considèrent l'optimisation des coûts comme une compétence fondamentale. Elles assurent une surveillance continue, mènent des expérimentations systématiques et adaptent leurs stratégies en fonction de l'évolution de la situation.
La recherche continue de perfectionner les techniques d'optimisation. Se tenir au courant des évolutions permet aux déploiements de bénéficier des dernières innovations. De nouvelles méthodes de compression, de routage et d'inférence efficace apparaissent régulièrement.
Les principes fondamentaux restent cependant inchangés : comprendre les modèles de tarification, adapter les ressources aux besoins, éliminer le gaspillage et tout mesurer. Ces principes permettent d’établir des structures de coûts durables qui évoluent avec la croissance de l’entreprise.
Commencez à mettre en œuvre une ou deux stratégies cette semaine. Mesurez l'impact. Procédez ensuite par étapes. L'effet cumulatif de plusieurs optimisations est considérable : une amélioration de 20 % ici, de 30 % là, et soudain, les coûts globaux diminuent de 60 % tandis que la qualité s'améliore.
Ce n'est pas théorique. C'est ce que réalisent les systèmes de production lorsque les organisations abordent l'optimisation des coûts de manière systématique.