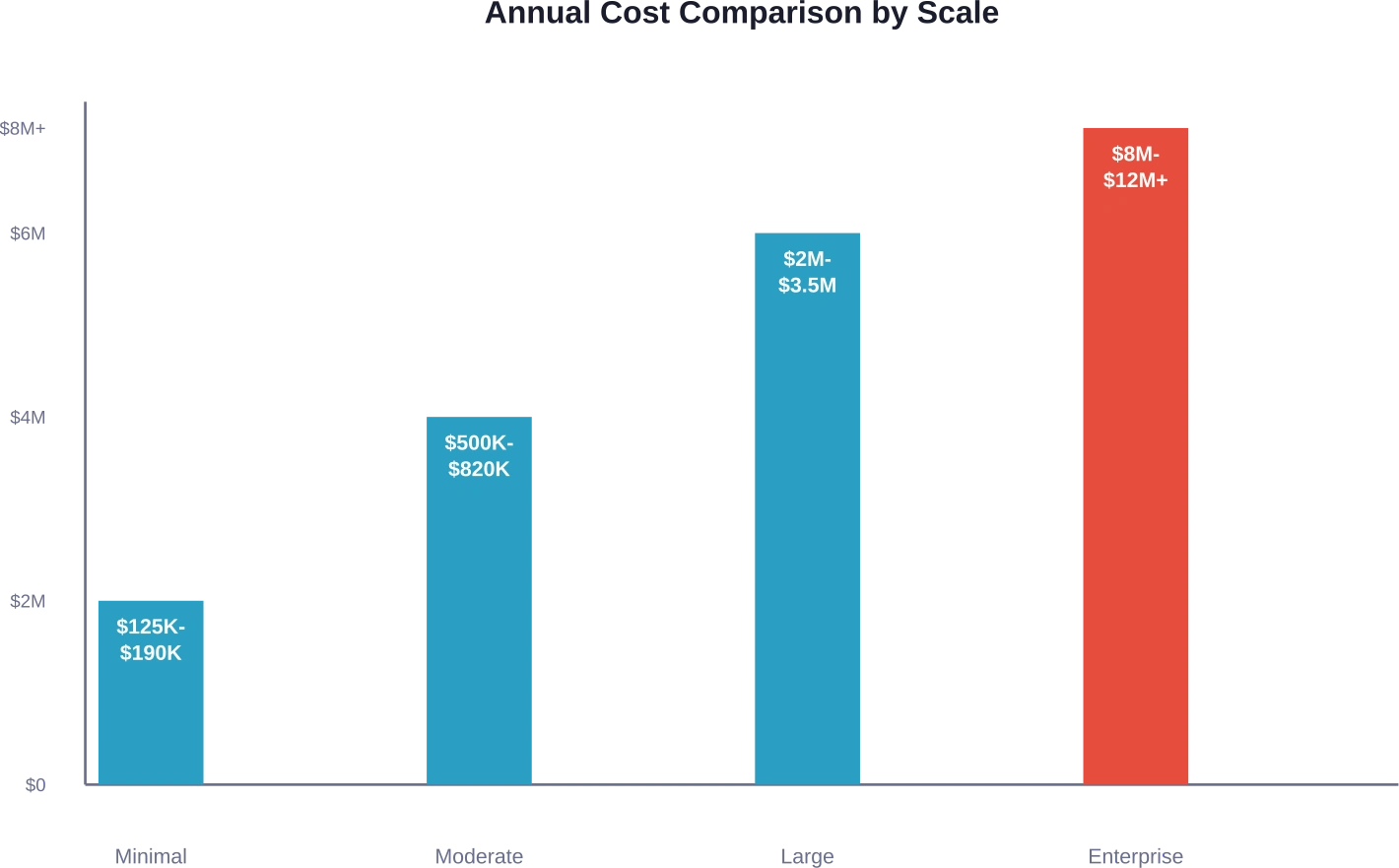
Résumé rapide : Les LLM open source éliminent les frais de licence, mais transfèrent les coûts vers l'infrastructure, les talents et la maintenance. Les déploiements internes minimaux génèrent entre 125 000 et 190 000 THB par an, tandis que les implémentations à l'échelle de l'entreprise peuvent dépasser 12 millions de THB. La rentabilité dépend du volume d'utilisation, de l'expertise technique et des besoins de personnalisation ; les API propriétaires s'avèrent souvent plus économiques pour les charges de travail faibles à modérées.
La promesse est alléchante : télécharger un modèle de langage open source de grande envergure, le déployer sur votre infrastructure et éviter les coûts récurrents des API propriétaires. Fini la facturation à l’unité. Plus de dépendance vis-à-vis d’un fournisseur.
Mais voilà le hic : ce modèle “ gratuit ” a un coût qui prend la plupart des organisations au dépourvu.
Les LLM open source déplacent les dépenses des postes de dépenses évidents, tels que les frais de licence, vers des coûts moins visibles mais tout aussi importants : compétences en ingénierie spécialisée, infrastructure GPU, maintenance continue et frais généraux d’exploitation. Ces dépenses cachées peuvent largement dépasser le coût des services API commerciaux, notamment à petite échelle.
Le choix entre les logiciels libres et les logiciels propriétaires ne se résume pas à une question de gratuité ou de paiement. Il s'agit plutôt de déterminer la structure de coûts la mieux adaptée à vos habitudes d'utilisation, à vos compétences techniques et à vos besoins métiers.
Pourquoi les LLM open source ne sont pas réellement gratuits
Le terme “ open source ” induit une dangereuse méprise. Certes, il est possible de télécharger des poids de modèles sans frais de licence. Cependant, leur déploiement en production exige des ressources considérables.
Les services propriétaires de modélisation de modèles de processus (LLM) comme GPT-5.2 d'OpenAI, Google Gemini ou Claude d'Anthropic facturent au jeton. Début 2026, GPT-5.2 Pro d'OpenAI coûtait $21,00 par million de jetons d'entrée ($168 en sortie), tandis que les offres économiques comme GPT-5.2 Mini étaient disponibles à partir de $0,25 par million de jetons d'entrée. D'après des données tarifaires vérifiées, ces tarifs reflètent différents niveaux d'optimisation des performances et des coûts. Les modèles “ réfléchissants ” V3.2-Exp de DeepSeek sont proposés à $0,28 par million de jetons d'entrée (avec erreurs de cache) et $0,42 par million de jetons de sortie, un prix nettement inférieur à celui des concurrents occidentaux.
Les modèles open source inversent cette équation. Au lieu de frais basés sur l'utilisation, vous payez pour :
- Acquisition de matériel ou location de GPU dans le cloud
- Salaires des ingénieurs en déploiement et intégration
- Gestion et surveillance des infrastructures
- travaux de renforcement de la sécurité et de conformité
- Optimisation et réglage fin du modèle
- Maintenance et support continus
Ces coûts restent relativement fixes quel que soit le volume d'utilisation, créant ainsi un modèle économique fondamentalement différent des API à paiement à l'usage.
La réalité des coûts d'infrastructure
L'exécution de modèles linéaires à grande échelle (LLM) exige une puissance de calcul considérable. Les modèles comportant des milliards de paramètres nécessitent des GPU dotés d'une importante mémoire vidéo (VRAM), d'interconnexions rapides et de systèmes de refroidissement performants.
Exigences d'investissement en matériel
Un déploiement de production minimal nécessite généralement au moins un GPU haut de gamme. Les GPU NVIDIA A100, couramment utilisés pour l'inférence LLM, coûtent entre $10 000 et $15 000 roupies l'unité. Ce prix augmente rapidement avec des modèles plus performants ou des exigences de débit plus élevées.
L'acquisition de matériel ne représente toutefois que le point de départ. L'infrastructure physique nécessite de l'espace en rack, la distribution électrique, des systèmes de refroidissement et une connectivité réseau. Les organisations ne disposant pas de capacité de centre de données existante doivent faire face à des dépenses d'investissement supplémentaires pour ces systèmes de support.
Économie des GPU dans le cloud
Les instances de GPU dans le cloud offrent une alternative à l'achat de matériel, mais leur coût reste élevé. Selon une analyse de Hugging Face portant sur l'économie du cloud GPU, les coûts d'investissement dominent les structures tarifaires. Par exemple, une NVIDIA Tesla V100 coûte généralement environ $10 000 USD à l'achat, tandis que son coût de location horaire moyen se situe entre $2 et $3 — ce qui signifie que les tarifs horaires du cloud augmentent rapidement en cas d'utilisation continue.
Voici ce qui fausse les prévisions de coûts initiales : les charges de travail d’inférence exigent une disponibilité permanente. Contrairement aux tâches d’entraînement qui s’exécutent une seule fois, les déploiements en production fonctionnent en continu. Ce fonctionnement 24 h/24 et 7 j/7 transforme les coûts horaires du cloud en factures mensuelles importantes.
L'investissement dans le capital humain
L'infrastructure ne représente qu'une dimension du coût. Les compétences spécialisées requises pour déployer et maintenir les logiciels libres open source dépassent souvent les dépenses liées au matériel.
Rôles d'ingénierie requis
Le déploiement de modèles LLM en production exige de nombreux rôles spécialisés. Les ingénieurs MLOps gèrent les pipelines de déploiement, l'optimisation de l'inférence et la mise à l'échelle de l'infrastructure. Les ingénieurs d'intégration logicielle conçoivent les connecteurs entre les modèles et les systèmes existants ; un travail qui, selon les données disponibles, représente généralement environ 601 000 000 000 de ressources d'ingénierie dans les projets d'IA.
Les spécialistes DevOps gèrent les clusters Kubernetes, l'orchestration des conteneurs et la surveillance de l'infrastructure. Les ingénieurs en sécurité mettent en œuvre les contrôles d'accès, la journalisation des audits et les cadres de conformité. Les ingénieurs de données conçoivent des pipelines pour l'optimisation et l'évaluation des modèles.
Dans le marché concurrentiel actuel des talents en IA, chaque poste offre des salaires substantiels. Les ingénieurs en apprentissage automatique senior perçoivent souvent entre 150 000 et 250 000 dollars par an, et les rémunérations globales peuvent être encore plus élevées pour les profils les plus performants.
Besoins en matière de soutien continu
Mais voici ce qui surprend les organisations : le déploiement n’est pas un projet ponctuel. Les systèmes LLM en production nécessitent une attention continue.
Les modèles nécessitent des mises à jour régulières à mesure que leurs fonctionnalités s'améliorent. Les piles d'inférence comme vLLM ou NVIDIA Triton requièrent maintenance et optimisation. Les points d'intégration deviennent incompatibles lorsque les systèmes en amont évoluent. Sans réglages continus, les performances se dégradent.
Cela engendre un besoin permanent en personnel. Les organisations ne peuvent pas déployer un LLM open source et s'en désintéresser ; elles s'engagent à réaliser des investissements continus en ingénierie.
Scénarios de coûts réels
Les catégories de coûts abstraites importent moins que les scénarios concrets. Quel est le coût réel de l'exécution de LLM open source à différentes échelles ?
Déploiement interne minimal
Un chatbot interne basique ou un outil d'analyse documentaire destiné à une petite équipe représente le scénario de déploiement le plus simple. D'après les analyses de coûts du secteur, même les déploiements internes les plus modestes coûtent entre 1 400 000 et 1 900 000 dollars par an.
Ce scénario suppose :
- Instances GPU dans le cloud plutôt que l'achat de matériel
- Configuration d'inférence mono-GPU
- Assistance technique à temps partiel (pas de personnel dédié)
- Personnalisation minimale au-delà des réglages de base
- Faible volume de requêtes (quelques centaines à quelques milliers par jour)
Les coûts se décomposent approximativement en infrastructure cloud (40%), temps d'ingénierie (45%) et outils de surveillance/sécurité (15%).
Fonctionnalités modérées destinées aux clients
Les applications destinées aux clients augmentent considérablement les enjeux. Des exigences de disponibilité plus élevées, des volumes de requêtes accrus et des besoins en matière de support à la production font grimper les coûts à $500K–$820K par an pour les déploiements de taille moyenne.
Ce scénario implique généralement :
- Configuration multi-GPU pour la redondance et le débit
- Équipe d'ingénierie dédiée (2 à 3 postes à temps plein)
- Réglage fin personnalisé pour une spécificité de domaine
- Surveillance et alerte complètes
- travaux de renforcement de la sécurité et de conformité
Les coûts d'infrastructure augmentent, mais les dépenses d'ingénierie restent prépondérantes. La construction de systèmes fiables et adaptés à la production exige un effort d'ingénierie soutenu bien au-delà du déploiement initial.
Produits de base à l'échelle de l'entreprise
Lorsque les fonctionnalités LLM deviennent essentielles aux offres de produits, les coûts augmentent considérablement. Les implémentations à l'échelle de l'entreprise, desservant des milliers d'utilisateurs simultanés, peuvent dépasser $8M à $12M par an.
Ces déploiements nécessitent :
- Clusters GPU multirégionaux pour des performances et une redondance accrues
- Équipes d'ingénierie dédiées (8 à 15 ingénieurs et plus)
- Optimisation poussée des modèles et architectures personnalisées
- Cadres de sécurité et de conformité d'entreprise
- assistance opérationnelle 24h/24 et 7j/7
À cette échelle, les effectifs d'ingénierie deviennent le principal facteur de coût, dépassant largement les dépenses d'infrastructure.
| Échelle de déploiement | Gamme de coûts annuels | Principaux facteurs de coûts | Cas d'utilisation typiques
|
|---|---|---|---|
| Interne minimal | $125K–$190K | GPU cloud, ingénierie à temps partiel | Chatbots internes, analyse de documents |
| Relations clients modérées | $500K–$820K | Équipe d'ingénierie dédiée, multi-GPU | Automatisation du support client, génération de contenu |
| Production à grande échelle | $2M–$3,5M | Grandes équipes d'ingénierie, infrastructure optimisée | Fonctionnalités essentielles du produit, API à haut volume |
| Produit de base pour entreprises | $8M–$12M+ | Équipes importantes, clusters multirégionaux | Produits d'IA critiques, offres de plateforme |
Tarification de l'API LLM propriétaire en 2026
Comparer les coûts des solutions open source nécessite de comprendre les alternatives propriétaires. La tarification des API a considérablement évolué, les principaux fournisseurs ajustant leurs tarifs et introduisant de nouveaux niveaux de service.
Contexte actuel des prix
Début 2026, les prix des LLM propriétaires varient considérablement. Selon les données de prix vérifiées et mises à jour jusqu'en février 2026 :
- OpenAI propose GPT-5.2 Pro, son offre haut de gamme, à un tarif de $21 par million de jetons d'entrée et $168 par million de jetons de sortie. La version standard de GPT-5.2 coûte respectivement $1,75 et $14,00, tandis que GPT-5.2 Mini est disponible à des tarifs plus abordables : $0,25 et $2,00.
- Les tarifs des appareils Gemini de Google varient selon le modèle. Leurs dernières offres offrent un équilibre optimal entre performances et coût pour différents cas d'utilisation.
- Les modèles Claude d'Anthropic conservent un positionnement concurrentiel sur le segment moyen à haut de gamme, en mettant l'accent sur la longueur du contexte et les caractéristiques de sécurité.
- xAI a lancé Grok 4 à $3/$15 par million de jetons, Grok 4 Fast à $0.20/$0.50 et Grok 4.1 Fast à $0.20/$0.50 par million de jetons.
- Les modèles “ réfléchissants ” V3.2-Exp de DeepSeek sont listés à $0,28 par million de jetons d'entrée (échec de cache) et $0,42 par million de jetons de sortie, nettement moins chers que les concurrents occidentaux.
Calculs des coûts basés sur l'utilisation
Les coûts des API sont proportionnels à leur utilisation. Une application traitant 100 millions de jetons par mois avec GPT-5.2 Pro (à $21 par million de jetons) engendrerait un coût annuel d'environ $25K pour les jetons d'entrée. La même charge de travail sur DeepSeek V3.2-Exp coûte environ $336 par an, soit une différence de 74 fois.
Cette mise à l'échelle linéaire définit des seuils de rentabilité clairs. Les applications à fort volume justifient à terme les investissements dans une infrastructure open source. Les charges de travail faibles à modérées privilégient presque toujours les API.
Le point de basculement dépend des niveaux de prix spécifiques et des coûts d'infrastructure, mais se situe généralement entre 50 et 200 millions de jetons par mois pour la plupart des organisations.
Coûts opérationnels cachés
Au-delà des dépenses évidentes liées à l'infrastructure et aux salaires, les déploiements LLM open source accumulent des coûts opérationnels moins visibles qui se cumulent au fil du temps.
Surveillance et observabilité
Les systèmes LLM de production nécessitent une surveillance complète. Le suivi de la latence, les indicateurs de débit, les taux d'erreur et l'utilisation des ressources doivent tous être visibles en temps réel.
Les plateformes commerciales d'observabilité facturent en fonction du volume de données et des durées de conservation. Ces coûts augmentent avec la complexité du système et le trafic.
Les solutions de surveillance personnalisées déplacent les coûts vers le temps d'ingénierie : la création de tableaux de bord, de systèmes d'alerte et d'outils de diagnostic consomme des ressources de développement considérables.
Mises à jour et versionnage des modèles
Les écosystèmes LLM open source évoluent rapidement. De nouvelles versions de modèles sont régulièrement publiées, offrant des fonctionnalités améliorées, une meilleure efficacité ou des corrections de bugs.
Chaque mise à jour nécessite des tests, une validation et une planification de déploiement. Les tests de régression garantissent que les nouvelles versions ne perturbent pas les fonctionnalités existantes. L'évaluation des performances valide les améliorations. Les procédures de restauration permettent de gérer les pannes.
Les organisations ne peuvent pas simplement ignorer les mises à jour ; prendre du retard sur les correctifs de sécurité critiques ou les améliorations de performances crée une dette technique et des désavantages concurrentiels.
Sécurité et conformité
Les déploiements LLM traitant des données sensibles sont soumis à des exigences de sécurité strictes. Le contrôle d'accès, la journalisation des audits, le chiffrement des données et l'isolation du réseau nécessitent tous une mise en œuvre et une maintenance.
Les cadres de conformité tels que SOC 2, HIPAA ou RGPD imposent des exigences supplémentaires. Les audits de sécurité réguliers, les tests d'intrusion et la gestion des vulnérabilités engendrent des coûts récurrents.
Les fournisseurs d'API propriétaires gèrent généralement les certifications de conformité et l'infrastructure de sécurité, déchargeant ainsi leurs clients de ces responsabilités. Les déploiements open source, quant à eux, assument l'entière responsabilité.
Quand l'open source devient financièrement judicieux
Malgré des coûts importants, les LLM open source offrent des avantages économiques indéniables dans certains cas spécifiques.
Charges de travail de production à volume élevé
Le seuil à partir duquel les logiciels libres deviennent plus économiques que les API dépend du volume d'utilisation. Le traitement de centaines de millions, voire de milliards de jetons par mois, engendre des factures d'API colossales qui justifient les investissements dans l'infrastructure.
Une application traitant 500 millions de jetons par mois via des API propriétaires de milieu de gamme pourrait engendrer un coût annuel de 1 400 000 à 1 400 000 THB. Sur une infrastructure auto-hébergée, ce même traitement pourrait coûter entre 300 000 et 500 000 THB au total, avec une croissance relativement stable au-delà de ce seuil.
À l'échelle du milliard de jetons, l'économie bascule résolument vers l'auto-hébergement.
Exigences de domaine spécialisé
Certaines applications nécessitent un paramétrage précis sur des données propriétaires du domaine. Le diagnostic médical, l'analyse de documents juridiques ou les domaines techniques spécialisés bénéficient de modèles entraînés sur des corpus spécifiques au domaine.
Les fournisseurs d'API propriétaires proposent des services de paramétrage fin, mais les coûts augmentent rapidement en cas de personnalisation poussée. Les modèles open source permettent un paramétrage fin illimité sans frais par jeton d'entraînement.
Les organisations qui utilisent des langues rares, des vocabulaires spécialisés ou qui ont des exigences de formatage uniques peuvent trouver les modèles open source plus adaptables, bien que le rapport coût-bénéfice spécifique varie selon le cas d'utilisation.
Confidentialité des données et souveraineté
Les exigences réglementaires interdisent parfois l'envoi de données sensibles à des API externes. Les dossiers médicaux, les informations financières ou les données classifiées peuvent nécessiter un traitement sur site.
Les LLM open source permettent un contrôle total des données. Les informations ne quittent jamais l'infrastructure de l'organisation, ce qui simplifie la conformité et réduit les risques.
La valeur de ce contrôle dépend de la sensibilité des données et du contexte réglementaire, mais pour certaines organisations, il est non négociable quel qu'en soit le coût.
Indépendance stratégique à long terme
La dépendance vis-à-vis de fournisseurs d'API externes engendre des risques stratégiques. Ces fournisseurs peuvent augmenter leurs prix, abandonner certains modèles ou modifier leurs conditions d'utilisation. Les interruptions de service ont un impact direct sur les applications qui en dépendent.
Les déploiements open source éliminent la dépendance aux fournisseurs. Les organisations contrôlent elles-mêmes la disponibilité, les prix et leur feuille de route.
Un article de recherche arXiv sur l'analyse coûts-avantages du déploiement LLM sur site définit la parité des performances comme des scores de référence dans 20% des meilleurs modèles commerciaux, reflétant les normes d'entreprise où de petits écarts de précision sont compensés par des avantages en termes de coûts, de sécurité et d'intégration.
Considérations relatives aux performances
Les comparaisons de coûts omettent une dimension essentielle : les différences de performance entre les modèles open source et les modèles propriétaires.
Lacunes en matière de capacités
Les modèles propriétaires haut de gamme surpassent généralement les alternatives open source comparables sur les tâches de raisonnement complexes, les instructions complexes et les domaines spécialisés.
L'écart varie considérablement selon le type de tâche. La simple classification, l'extraction de données structurées ou la génération à partir de modèles présentent des différences minimes. Le raisonnement complexe, la compréhension nuancée du langage ou les tâches créatives privilégient les modèles propriétaires de pointe.
Les organisations doivent évaluer si les différences de capacités ont une incidence sur leurs cas d'utilisation spécifiques. De nombreuses applications fonctionnent de manière optimale avec des performances de milieu de gamme à moindre coût.
Opportunités d'optimisation
Les déploiements open source permettent une optimisation poussée impossible avec les services API. La quantification réduit la taille du modèle et les besoins en mémoire tout en conservant une précision acceptable. La distillation des connaissances transfère les fonctionnalités vers des modèles plus petits et plus rapides.
Une étude publiée sur Hugging Face, portant sur l'efficacité du raisonnement, a démontré que des chaînes de raisonnement plus courtes peuvent atteindre des performances similaires, voire supérieures, à moindre coût de calcul. Plus précisément, les approches courtes de type 1@k ont permis d'utiliser jusqu'à 40% jetons de réflexion en moins par rapport aux approches standard, tout en conservant la qualité du résultat.
Les piles d'inférence personnalisées comme vLLM ou NVIDIA Triton offrent des possibilités d'optimisation des performances inaccessibles via les API standardisées. Les stratégies de traitement par lots, les mécanismes de mise en cache et les optimisations matérielles spécifiques peuvent améliorer considérablement le débit et la latence.
Latence et débit
L'infrastructure auto-hébergée permet une distribution géographique plus proche des utilisateurs, réduisant ainsi la latence du réseau. Le matériel dédié élimine les délais d'attente liés à une infrastructure API partagée.
Cependant, la conception de systèmes d'inférence haute performance exige une expertise considérable. Les déploiements mal optimisés présentent souvent une latence supérieure à celle des services API bien conçus.
Prendre la décision en matière de coûts
Choisir entre les logiciels LLM open source et propriétaires nécessite d'évaluer de multiples dimensions au-delà d'une simple comparaison des coûts.
Calculer le coût total de possession
Des prévisions de coûts précises doivent inclure toutes les catégories de dépenses :
- Infrastructure: Location de matériel GPU ou de cloud, réseau, stockage
- Personnel: Salaires des ingénieurs, coûts de recrutement, formation
- Opérations : Outils de surveillance, logiciels de sécurité, audits de conformité
- Coût d'opportunité: Temps d'ingénierie détourné du développement produit
- Prime de risque : Coûts liés aux temps d'arrêt, problèmes de performance, incidents de sécurité
Les organisations sous-estiment systématiquement les coûts de personnel et d'exploitation tout en surestimant les économies réalisées sur les infrastructures.
Évaluer les capacités techniques
Le succès des déploiements open source exige une expertise technique considérable. Les équipes ont besoin de compétences en systèmes distribués, en programmation GPU, en optimisation du ML et en opérations de production.
Les organisations qui ne possèdent pas cette expertise ont deux options : développer leurs compétences par le recrutement et la formation (coûteux et lent) ou faire appel à des consultants externes (coûteux et créant une dépendance).
Les services API éliminent la plupart des exigences techniques, permettant aux équipes de se concentrer sur la logique applicative plutôt que sur l'infrastructure.
Envisager des approches hybrides
La décision n'est pas binaire. De nombreuses organisations combinent avec succès différentes approches.
Les stratégies de routage LLM sélectionnent dynamiquement les modèles en fonction des caractéristiques des requêtes. Les requêtes simples sont acheminées vers des modèles rapides et économiques, tandis que les tâches complexes utilisent des alternatives plus performantes. Selon une étude de Hugging Face sur le routage par lots d'instructions, cette optimisation permet d'équilibrer performance et coût pour des charges de travail mixtes.
Les environnements de développement et de préproduction peuvent utiliser des API, tandis que la production s'appuie sur une infrastructure auto-hébergée. Cela permet de réduire les coûts d'infrastructure lors des phases de faible activité tout en assurant une production sans API.
La spécialisation par tâche déploie des modèles open source pour les tâches standardisées à volume élevé, tout en utilisant des API propriétaires pour les requêtes complexes et variables.
| Considération | Favorise l'open source | Privilégie les API propriétaires
|
|---|---|---|
| Volume d'utilisation | Très élevé (plus de 500 millions de jetons par mois) | Faible à modéré (<100M de jetons/mois) |
| Expertise technique | Équipes solides en apprentissage automatique et en infrastructure | Expertise limitée en apprentissage automatique, petites équipes |
| Besoins de personnalisation | Un réglage fin et approfondi est nécessaire | Les modèles standard suffisent |
| Protection des données | Exigences réglementaires strictes | conditions commerciales standard acceptables |
| Délai de mise sur le marché | Investissement stratégique à long terme | Déploiement rapide critique |
| Prévisibilité des coûts | Privilégier les coûts d'infrastructure fixes | Les coûts variables sont acceptables |
Stratégies d'optimisation des coûts
Les organisations qui s'engagent en faveur des LLM open source peuvent employer plusieurs stratégies pour maîtriser les coûts.
Infrastructures de taille adaptée
De nombreux déploiements surdimensionnent le matériel en fonction de la charge de pointe plutôt que de l'utilisation typique. L'infrastructure à mise à l'échelle automatique ajuste dynamiquement la capacité en fonction de la demande, réduisant ainsi les coûts liés aux ressources inutilisées.
Les instances Spot et les machines virtuelles préemptibles offrent des remises importantes sur le cloud (parfois de 60 à 801 TPS/3000) en contrepartie d'une possible interruption de service. Les charges de travail par lots et les environnements de développement tolèrent bien les interruptions.
Sélection et optimisation du modèle
Après un réglage fin, les modèles plus petits offrent des performances surprenantes sur des tâches spécialisées. Des recherches sur l'optimisation de petits modèles de langage pour le commerce électronique ont montré qu'un modèle Llama 3.2 d'un milliard de paramètres, correctement réglé, atteignait une précision de 991 TP3T, égalant ainsi les performances de GPT-5.1 en matière de reconnaissance d'intentions spécialisées.
La quantification réduit la précision du modèle de 16 bits à 8 bits ou même 4 bits, réduisant les besoins en mémoire et les coûts d'inférence de 50 à 75% avec un impact minimal sur la qualité.
La distillation de modèles permet d'entraîner des modèles étudiants plus petits à imiter des modèles enseignants plus grands, ce qui permet d'obtenir de meilleurs compromis efficacité-performance qu'avec un entraînement à partir de zéro.
Techniques d'inférence efficaces
Le traitement par lots permet de traiter plusieurs entrées simultanément, ce qui améliore considérablement l'utilisation du GPU. Les techniques de traitement par lots continu permettent un assemblage dynamique des lots pour les applications en temps réel.
L'optimisation du cache KV réduit les calculs redondants lors de la génération autorégressive, en particulier pour les contextes longs ou les conversations à plusieurs tours.
Le routage des requêtes envoie les requêtes simples aux modèles petits et rapides et les requêtes complexes aux modèles plus grands, optimisant ainsi le rapport coût-performance en fonction de la répartition de la charge de travail.

Analysez les coûts de votre LLM open source avec Technical Insight
Les modèles linéaires open source peuvent paraître économiques car le modèle de base est gratuit, mais les coûts réels se situent souvent au niveau de l'entraînement, du paramétrage, de la préparation des données et du déploiement. Les choix concernant la taille du modèle, son architecture et son intégration ont un impact considérable sur la puissance de calcul utilisée et les coûts d'exploitation. IA supérieure Ce service se concentre sur le travail d'ingénierie lié aux modèles de modèles logiques open source : création de modèles, optimisation des flux de travail d'entraînement et mise en place de pipelines de déploiement efficaces, vous permettant ainsi de comprendre et de contrôler l'utilisation de votre budget. (aisuperior.com/services/llm-model-creation-services)
Si vous suivez les dépenses cachées en 2026 et souhaitez une vision plus claire de l'origine des coûts, commencez par la configuration technique. Parlez-en à IA supérieure pour auditer votre implémentation LLM open source actuelle et trouver des moyens pratiques de réduire le coût total de possession.
Tendances futures des coûts
La dynamique des coûts des LLM continue d'évoluer rapidement, plusieurs tendances redessinant le paysage économique.
Pression à la baisse sur les prix des API
La concurrence s'intensifie entre les fournisseurs propriétaires. La tarification agressive de DeepSeek, à $0,28 par million de jetons d'entrée, a contraint ses concurrents à revoir leurs propres tarifs.
L'amélioration de l'efficacité de l'inférence réduit les coûts des fournisseurs, ce qui permet de baisser les prix tout en préservant les marges. Les progrès matériels et les optimisations algorithmiques continus devraient maintenir cette tendance.
Des modèles open source plus performants
L'écart de performance entre les modèles open source et propriétaires se réduit constamment. Les modèles open source disponibles aujourd'hui égalent les performances des alternatives propriétaires d'il y a 12 à 18 mois.
Cette approche réduit la perte de performance liée au choix de solutions open source, les rendant ainsi viables pour un plus grand nombre d'applications.
Modèles spécialisés de petite taille
Les petits modèles spécifiques à une tâche, entraînés pour des domaines particuliers, concurrencent de plus en plus les grands modèles à usage général sur des applications ciblées.
Ces modèles spécialisés fonctionnent sur du matériel moins cher et avec des frais d'exploitation réduits, améliorant ainsi la rentabilité des logiciels libres pour des cas d'utilisation ciblés.
Erreurs courantes dans l'estimation des coûts
Les organisations commettent systématiquement des erreurs prévisibles lorsqu'elles évaluent les coûts des programmes de maîtrise en droit.
Négliger les coûts de personnel
L’erreur la plus fréquente : considérer les ressources d’ingénierie existantes comme “ gratuites ” sous prétexte que les salaires sont déjà budgétisés.
Le déploiement et la maintenance des LLM absorbent une part importante du temps des ingénieurs. Ce temps représente un coût d'opportunité : les ingénieurs travaillant sur l'infrastructure ne peuvent pas développer simultanément les fonctionnalités du produit.
Une comptabilité analytique correcte inclut l'ensemble des coûts de personnel, et non seulement les embauches supplémentaires.
Sous-estimation des frais généraux opérationnels
Le déploiement initial représente un effort total d'environ 20 à 301 TP3 TP sur un cycle de vie pluriannuel. La maintenance, les mises à jour, la surveillance et l'optimisation continues absorbent la majeure partie de cet effort.
Les organisations prévoient un budget pour le déploiement, mais sous-estiment les besoins opérationnels à long terme, ce qui crée des pénuries de ressources après le lancement.
Comparaison des pics et des moyennes
Les coûts des API calculés à partir des pics d'utilisation semblent gonflés par rapport aux coûts fixes d'infrastructure. Or, la plupart des charges de travail ne présentent pas de pics d'utilisation continus ; ce sont les dépenses moyennes qui déterminent les coûts réels.
L'infrastructure doit être dimensionnée pour absorber les pics de capacité, ce qui crée des ressources inactives en fonctionnement normal. Les API, quant à elles, ne facturent que l'usage réel et s'adaptent naturellement à la demande.
Supervision de la conformité et de la sécurité
Le renforcement de la sécurité, les audits de conformité et les exigences réglementaires ajoutent des coûts substantiels aux déploiements auto-hébergés.
Les organisations inexpérimentées en matière de systèmes ML de production sous-estiment systématiquement ces dépenses de 50 à 100%.
Questions fréquemment posées
Les LLM open-source sont-ils vraiment gratuits ?
Non. Bien que les poids des modèles soient disponibles sans frais de licence, leur déploiement exige une infrastructure conséquente, des ingénieurs spécialisés et une maintenance continue. Le coût total de possession pour les déploiements minimaux s'élève à environ 125 000 TP4T par an, et dépasse 12 millions TP4T pour les déploiements en entreprise.
À quel moment les logiciels libres deviennent-ils moins chers que les API propriétaires ?
Le seuil de rentabilité se situe généralement entre 50 et 200 millions de jetons par mois, en fonction de la tarification spécifique des API et des coûts d'infrastructure. Les applications à très fort volume (plus de 500 millions de jetons par mois) privilégient presque toujours l'auto-hébergement, tandis que les volumes plus faibles tirent généralement profit des API à paiement à l'usage.
Quels sont les principaux coûts cachés des LLM open-source ?
Les salaires des ingénieurs représentent le poste de dépense le plus important, souvent négligé, absorbant généralement entre 45 et 551 milliards de dollars des coûts totaux. Les entreprises sous-estiment systématiquement l'expertise spécialisée requise pour le déploiement, l'optimisation et la maintenance continue. Le renforcement de la sécurité et les travaux de mise en conformité constituent un autre poste de dépense fréquemment sous-estimé.
Dans quelle mesure les logiciels LLM open source sont-ils moins chers que les solutions propriétaires ?
Tout dépend du volume d'utilisation. À faible volume, les API propriétaires coûtent nettement moins cher — potentiellement 5 à 10 fois moins cher en tenant compte du coût total de possession (TCO). À très haut volume, une infrastructure auto-hébergée peut réduire le coût par jeton de 50 à 801 000 000 $. L'avantage varie en fonction de l'échelle, des besoins de personnalisation et de l'expertise disponible.
Quelles sont les compétences techniques nécessaires pour gérer des LLM open-source ?
Les déploiements en production nécessitent des ingénieurs en apprentissage automatique pour l'optimisation des modèles, des spécialistes MLOps pour l'infrastructure de déploiement, des ingénieurs DevOps pour la gestion du système et des ingénieurs logiciels pour l'intégration. L'expertise en sécurité est essentielle pour les systèmes de production qui traitent des données sensibles. Pour les déploiements minimaux, ces rôles peuvent être assurés par une ou deux personnes, tandis que pour les déploiements à l'échelle de l'entreprise, des équipes dédiées sont nécessaires.
Les petites entreprises peuvent-elles se permettre le déploiement de solutions LLM open source ?
La plupart des petites entreprises trouvent les API propriétaires plus économiques, sauf si elles ont des exigences spécifiques telles qu'une confidentialité stricte des données, des besoins de personnalisation importants ou des volumes d'utilisation exceptionnellement élevés. Le coût annuel minimum de 1 000 000 $ pour un hébergement autogéré dépasse généralement les dépenses liées aux API pour les petites entreprises, jusqu'à ce que l'utilisation atteigne une échelle significative.
Quelle est la meilleure approche pour les organisations soucieuses de leurs coûts ?
Commencez par des API propriétaires pour valider l'adéquation produit-marché et comprendre les habitudes d'utilisation. Cela minimise les investissements initiaux et la complexité technique. N'envisagez le déploiement open source qu'une fois la taille critique atteinte (généralement 1 000 à 4 000 € par an), lorsque les coûts des API deviennent prohibitifs, et assurez-vous de disposer de l'expertise technique nécessaire pour gérer efficacement une infrastructure auto-hébergée.
Conclusion : Faire le bon choix économique
Les LLM open source ne sont pas gratuits — leur structure de coûts est fondamentalement différente et favorise des contextes organisationnels spécifiques.
Les modèles “ gratuits ” impliquent des investissements considérables en infrastructure, en personnel et en exploitation. Pour les usages faibles à modérés, les API propriétaires offrent une meilleure rentabilité et une complexité nettement réduite. Les entreprises ne paient que pour leur consommation réelle et délèguent le déploiement, la mise à l'échelle et la maintenance aux fournisseurs.
Le déploiement de solutions open source se justifie économiquement pour les volumes importants, lorsque le coût des API par jeton devient prohibitif, lorsqu'une personnalisation poussée exige un accès approfondi au modèle, ou lorsque la confidentialité des données impose un traitement sur site. Ces scénarios justifient les coûts fixes substantiels et la complexité technique.
Cette décision exige une évaluation honnête des coûts réels — y compris les dépenses de personnel souvent négligées — au regard de projections d'utilisation réalistes. Les organisations dotées de solides compétences en ingénierie du ML et d'une stratégie claire pour une utilisation à grande échelle tirent profit des solutions open source. Celles qui ont une expertise limitée, une utilisation modérée ou des délais serrés trouvent généralement les API plus pratiques.
Surtout, il est essentiel de comprendre que la question n'est pas de savoir “ logiciel libre ou propriétaire ”, mais “ quel modèle de coût correspond à notre utilisation, à nos capacités et à nos exigences ”. Répondez honnêtement à cette question, et le choix économiquement optimal deviendra évident.
Prêt à évaluer les options LLM pour votre cas d'utilisation spécifique ? Calculez le volume de jetons attendu, évaluez les capacités techniques et modélisez les deux structures de coûts avec des hypothèses réalistes. Ces données chiffrées vous guideront bien mieux que n'importe quelle recommandation générale.