Résumé rapide : L'entraînement d'un modèle LLM à partir de zéro coûte entre 78 et 192 milliards de pesos pour les modèles de pointe comme GPT-4 et Gemini Ultra 1.0, un coût qui repose sur d'importants clusters de GPU, une forte consommation d'électricité, l'acquisition de données et une main-d'œuvre qualifiée en ingénierie. Des modèles plus petits peuvent être entraînés pour un coût de 50 000 à 500 000 pesos grâce à l'infrastructure cloud, ou pour moins de 100 000 pesos avec des techniques d'optimisation efficaces. Cependant, les entreprises doivent faire face à des coûts récurrents d'inférence, de stockage et de maintenance qui dépassent souvent les dépenses d'entraînement.
Les grands modèles de langage ont transformé notre interaction avec la technologie. Mais voici ce que la plupart des gens ignorent : le coût de création de ces modèles est astronomique.
D'après le rapport Stanford AI Index 2025, les coûts d'entraînement des modèles de pointe ont explosé. L'entraînement de GPT-4 a coûté entre 78 et 100 millions de TPC ($78 et $100 millions de dollars). Le coût d'entraînement de Gemini Ultra est estimé à environ 191 millions de TPC ($191 millions de dollars) selon le rapport Stanford AI Index 2024. Ces chiffres représentent une augmentation de 287 000 fois par rapport au coût d'entraînement d'un modèle Transformer en 2017, qui s'élevait à seulement 670 millions de TPC ($670).
Qu’est-ce qui explique ces dépenses colossales ? Et surtout, quel est le coût réel si vous envisagez de former votre propre modèle à partir de zéro ?
Analyse détaillée des coûts réels d'une formation LLM
Entraîner un modèle de langage complexe à partir de zéro n'est pas seulement coûteux, c'est un engagement financier multidimensionnel qui englobe le matériel, l'énergie, les données et le capital humain.
Infrastructure informatique : le poste de dépense le plus important
Les coûts de calcul représentent la part la plus importante. Les GPU hautes performances comme le NVIDIA H100 peuvent coûter jusqu'à 30 000 £ l'unité. Et ce n'est que le début.
Pour contextualiser, l'entraînement de modèles de pointe nécessite des milliers de GPU fonctionnant en continu pendant des semaines, voire des mois. Une étude d'arXiv analysant l'économie des GPU a révélé qu'un GPU A800 80G a un coût horaire de base d'environ $0,79 €, les coûts typiques se situant entre $0,51 € et $0,99 € selon la configuration et la tarification de la plateforme cloud.
OpenAI aurait dépensé plus de 100 millions de dollars pour l'entraînement de GPT-4, dont une part importante consacrée aux coûts de cloud computing. L'ampleur de ce projet est difficilement concevable.
| Modèle | Coût estimé de la formation | Source |
|---|---|---|
| GPT-4 | $78M-$100M+ | Wall Street Journal, Indice d'IA de Stanford 2025 |
| Gemini Ultra 1.0 | $191M | Rapport sur l'indice d'IA de Stanford 2024 |
| GPT-4o | ~$100M | Estimations de l'industrie |
| Transformer (2017) | $670 | Rapport sur l'indice d'IA de Stanford 2025 |
Consommation d'énergie et coûts environnementaux
Le fonctionnement continu de milliers de GPU consomme d'énormes quantités d'électricité. Une étude publiée par Springer en 2025 sur l'efficacité énergétique des grands modèles de langage souligne que la dynamique de la consommation d'énergie est directement liée à la taille du modèle et à la configuration des lots.
L'impact environnemental ne se limite pas à la phase de formation. À mesure que les besoins en calcul augmentent, les préoccupations liées à la durabilité et à l'empreinte carbone s'accroissent également.
Acquisition et préparation des données
Voici un point souvent négligé : le travail humain nécessaire à la production des données d’entraînement est largement sous-estimé. Un document de position publié sur Hugging Face en avril 2025 soutient que les coûts de production des données devraient égaler, voire dépasser, les coûts de calcul de l’entraînement.
Les jeux de données de qualité ne se créent pas par magie. Ils nécessitent :
- Frais de collecte de données et de licence
- Nettoyage et annotation manuels
- Conformité aux droits d'auteur et examen juridique
- Mises à jour et maintenance continues
L'article démontre de manière convaincante que les données d'entraînement représentent la partie la plus coûteuse — et la moins bien rémunérée — du développement des LLM.
Frais généraux d'ingénierie et de gestion opérationnelle
L'obtention d'un LLM exige une expertise pointue. Les ingénieurs en apprentissage automatique, les data scientists, les spécialistes des infrastructures et les chercheurs sont très recherchés. Dans les principaux pôles technologiques, les salaires pour ces postes varient généralement entre 150 000 et plus de 500 000 dollars par an.
Au-delà des salaires, il y a les frais généraux opérationnels : gestion de projet, suivi des expériences, gestion des versions des modèles, sécurité et infrastructure de conformité.
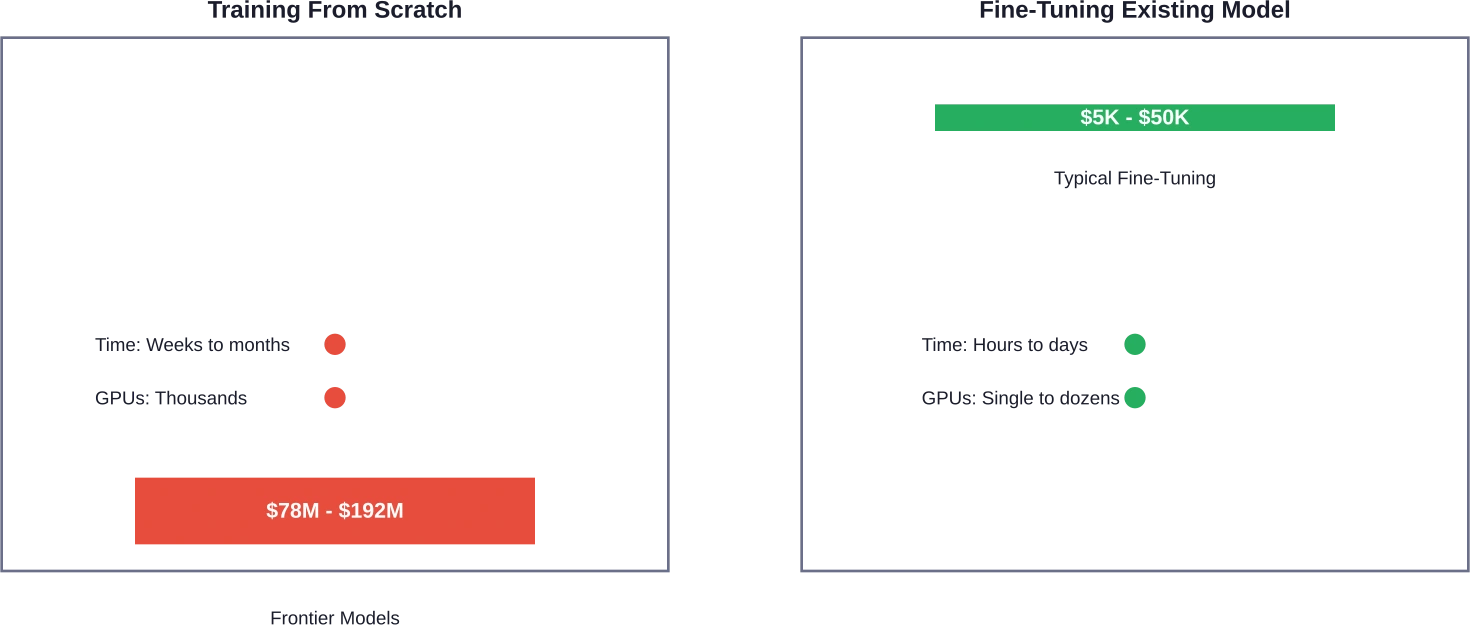
Formation initiale vs. perfectionnement : une comparaison des coûts
Tout le monde n'a pas besoin de construire GPT-5. Le choix entre l'entraînement à partir de zéro et l'optimisation d'un modèle existant peut permettre aux organisations d'économiser entre 60 et 901 TP3T sur leur budget IA.
Quand une formation à partir de zéro est judicieuse
Une formation complète préalable, à partir de zéro, est généralement judicieuse lorsque :
- Votre domaine requiert des modèles de langage fondamentalement différents des modèles généraux.
- Les réglementations relatives à la protection des données interdisent l'utilisation de modèles commerciaux
- Vous devez avoir un contrôle total sur l'architecture et le comportement du modèle.
- Votre organisation dispose du budget et de l'expertise nécessaires pour soutenir le développement de modèles à long terme.
L'alternative de réglage fin
Le fine-tuning consiste à adapter un modèle pré-entraîné à des tâches ou des domaines spécifiques. La différence de coût est considérable. Alors que l'entraînement initial de GPT-4 a coûté près de 100 millions de TP4T, son fine-tuning pour des applications spécialisées peut coûter entre 5 000 et 50 000 TP4T.
Des recherches menées par l'Universidad Nacional de Colombia ont démontré l'efficacité des stratégies d'ajustement fin utilisant LoRA (Low-Rank Adaptation). Leurs expériences ont montré qu'un modèle de base quantifié sur 8 bits pouvait être ajusté en environ 7 heures sur un seul GPU NVIDIA T4 doté de 16 Go de VRAM – un matériel dont le coût horaire est d'environ 1 TP4T2-4 sur les principales plateformes cloud.
Formation à petit budget : est-ce possible pour moins de $100K ?
La réponse est oui, mais au prix de compromis importants sur la taille et les fonctionnalités du modèle.
Un article publié sur arXiv et intitulé “ FLM-101B : Un LLM ouvert et comment l'entraîner avec un budget de $100K ” a démontré qu'un entraînement LLM à plus petite échelle est possible moyennant une gestion rigoureuse des ressources. Les stratégies clés comprennent :
- Utilisation d'architectures de modèles plus petites (1 à 20 milliards de paramètres au lieu de plus de 175 milliards)
- Tirer parti des frameworks open source et des bases de code préexistantes
- Optimisation des séquences d'entraînement grâce à une sélection efficace des hyperparamètres
- Utilisation de techniques d'entraînement et de quantification à précision mixte
Une étude de l'Institut Fraunhofer a comparé trois optimiseurs (AdamW, Lion et une troisième variante) pour le pré-entraînement de modèles linéaires à faible coût. Leurs expériences, menées sur deux nœuds de cluster équipés de plusieurs GPU, ont démontré que le choix de l'optimiseur influe considérablement sur le temps d'entraînement et les performances finales du modèle.
L'alternative Open-Weight
La publication par OpenAI des modèles gpt-oss-120b et gpt-oss-20b en août 2025 a bouleversé la donne. Ces modèles à pondération ouverte, distribués sous licence Apache 2.0, offrent d'excellentes performances en situation réelle à un coût nettement inférieur à celui d'un entraînement à partir de zéro.
Les organisations peuvent désormais télécharger ces modèles et les adapter à des cas d'utilisation spécifiques, évitant ainsi totalement les coûts de formation initiaux exorbitants.
Cloud ou infrastructure sur site : lequel coûte le moins cher à long terme ?
Des chercheurs de l'université Carnegie Mellon ont publié une analyse coûts-avantages examinant à quel moment le déploiement d'une solution LLM sur site devient rentable par rapport aux services cloud commerciaux. Leurs conclusions remettent en question les idées reçues.
Coûts de l'infrastructure cloud
Les plateformes cloud offrent une grande flexibilité, mais facturent des tarifs élevés pour le temps GPU. Les principaux fournisseurs facturent généralement :
- $2-8 par heure pour les instances GPU hautes performances
- Frais de transfert de données (souvent négligés mais substantiels à grande échelle)
- Coûts de stockage des points de contrôle du modèle et des données d'entraînement
- Frais d'appel API si vous utilisez des services gérés
L'avantage ? Aucun investissement initial et la possibilité d'adapter la capacité à la demande.
Investissement dans l'infrastructure sur site
L'achat direct de matériel nécessite un investissement initial important, mais élimine les coûts récurrents liés au cloud. Un cluster de GPU NVIDIA H100 peut coûter entre 500 000 et 2 millions de livres sterling au départ, mais cet investissement est amorti sur 3 à 5 ans.
L'analyse de Carnegie Mellon a révélé que les organisations ayant des charges de travail d'IA soutenues et prévisibles atteignent souvent le seuil de rentabilité en 12 à 18 mois lorsqu'elles optent pour un déploiement sur site plutôt que pour des services cloud.
Mais il y a un hic : l’infrastructure sur site nécessite du personnel dédié à la maintenance, aux systèmes de refroidissement, à l’infrastructure électrique et à la sécurité – des coûts que de nombreuses analyses budgétaires négligent.
Qu’est-ce qui fait augmenter le coût des formations LLM ?
Plusieurs facteurs déterminent si votre budget de formation se rapprochera davantage de $50 000 ou de $50 millions.
Taille et architecture du modèle
La relation entre les paramètres et le coût n'est pas linéaire, mais exponentielle. Doubler la taille du modèle double, voire plus, les coûts d'entraînement, car :
- L'augmentation des besoins en mémoire impose le parallélisme multi-GPU
- Temps d'entraînement plus longs car la convergence ralentit avec l'échelle
- Des besoins en données plus importants sont nécessaires pour entraîner correctement des architectures plus grandes.
Durée et convergence de la formation
Les entraînements qui ne convergent pas gaspillent d'énormes ressources. Un réglage efficace des hyperparamètres peut considérablement accélérer l'apprentissage d'un modèle. Un entraînement bien réglé peut atteindre la précision cible deux fois plus vite qu'un entraînement mal configuré.
C’est là que l’expertise fait toute la différence. Les ingénieurs qui maîtrisent les techniques de planification des taux d’apprentissage, d’optimisation de la taille des lots et de régularisation permettent aux entreprises d’économiser des millions en temps de calcul inutile.
Qualité et quantité des données
S’entraîner sur des données de faible qualité produit des modèles de faible qualité, mais l’acquisition de données de haute qualité a un coût réel. Certaines organisations dépensent davantage pour la curation des données que pour l’infrastructure informatique.
Le consensus qui se dégage, exprimé dans la prise de position de Hugging Face sur l'économie des données de formation, est que les données devraient constituer le poste de dépense le plus important dans le développement des masters en droit. Actuellement, elles sont sous-évaluées.
Coûts cachés au-delà de la formation
C’est là que de nombreuses prévisions budgétaires s’effondrent : les coûts de formation ne sont que le point de départ.
Infrastructure d'inférence
L'équipe WiNGPT a introduit un cadre d'analyse économique de l'inférence qui considère l'inférence LLM comme une activité de production axée sur le calcul. Leur analyse a révélé que les coûts d'inférence dépassent souvent les coûts d'entraînement sur la durée de vie opérationnelle du modèle.
Chaque requête envoyée à votre modèle consomme des ressources de calcul. À grande échelle, l'infrastructure d'inférence peut coûter des centaines de milliers d'euros par mois.
Mises à jour et réentraînement des modèles
Le langage évolue. Les informations factuelles changent. Les besoins des entreprises évoluent. Les modèles entraînés en 2024 seront obsolètes en 2026.
Les formations périodiques ou les programmes d'apprentissage continu représentent des coûts permanents que de nombreuses organisations sous-estiment lors de la planification initiale.
Gestion du stockage et des données
Les points de contrôle des modèles, les jeux de données d'entraînement, les journaux d'expérimentation et les systèmes de gestion de versions consomment tous de l'espace de stockage. Pour les modèles de pointe, on parle de pétaoctets de données. Les coûts de stockage s'accumulent discrètement, mais de façon significative.
Surveillance et maintenance
Les systèmes d'apprentissage automatique en production nécessitent une surveillance constante pour :
- Dégradation des performances
- Détection et atténuation des biais
- vulnérabilités de sécurité
- Fiabilité et disponibilité de l'API
Ces coûts opérationnels persistent tant que le modèle reste en production.
| Catégorie de coût | Une seule fois | Récurrent | Plage typique |
|---|---|---|---|
| Formation initiale | ✓ | $50K – $192M | |
| Infrastructure d'inférence | ✓ | $10K – $500K/mois | |
| Réentraînement du modèle | ✓ | 20-50% de coût initial/an | |
| Stockage | ✓ | $5K – $50K/mois | |
| Équipe d'ingénierie | ✓ | $500K – $5M/an | |
| Acquisition de données | ✓ | ✓ | $100K – $10M+ |
Stratégies pour réduire les coûts de formation LLM
Les organisations performantes emploient de multiples tactiques pour maîtriser leurs dépenses sans sacrifier la performance de leur modèle économique.
Transfert d'apprentissage et formation progressive
Au lieu de partir de zéro, utilisez un modèle d'entraînement à poids ouverts existant et adaptez-le progressivement. Cette approche, documentée par une étude de l'Universidad Nacional de Colombia, réduit le temps d'entraînement de 80 à 90 %.
Techniques d'optimisation efficaces
L'étude de l'Institut Fraunhofer comparant AdamW, Lion et d'autres optimiseurs a démontré que le choix de l'optimiseur a un impact significatif sur la vitesse d'entraînement et la consommation de ressources. Choisir le bon optimiseur pour votre cas d'utilisation spécifique peut permettre de réduire les coûts d'entraînement de 20 à 301 000 Tk.
Quantification et compression
L'entraînement avec une précision mixte (combinant opérations en virgule flottante 16 bits et 32 bits) réduit la consommation de mémoire et accélère les calculs. La quantification post-entraînement à des représentations 8 bits, voire 4 bits, permet de réduire la taille du modèle pour son déploiement sans perte de performance significative.
Les expériences de l'Universidad Nacional de Colombia ont démontré la réussite de l'entraînement LoRA sur des modèles quantifiés à 8 bits, les modèles pré-quantifiés à 4 bits affichant des performances acceptables sur du matériel grand public.
Allocation intelligente des ressources
L’utilisation et la gestion efficaces des ressources informatiques permettent d’éviter de payer pour les temps d’inactivité. Les stratégies comprennent :
- Enchères ponctuelles sur les plateformes cloud pour les sessions d'entraînement non critiques
- Parallélisme du pipeline pour maximiser l'utilisation du GPU
- Accumulation de gradient pour simuler des lots de plus grande taille sur du matériel limité
- Fonctionnalités de redémarrage par point de contrôle pour récupérer après des interruptions
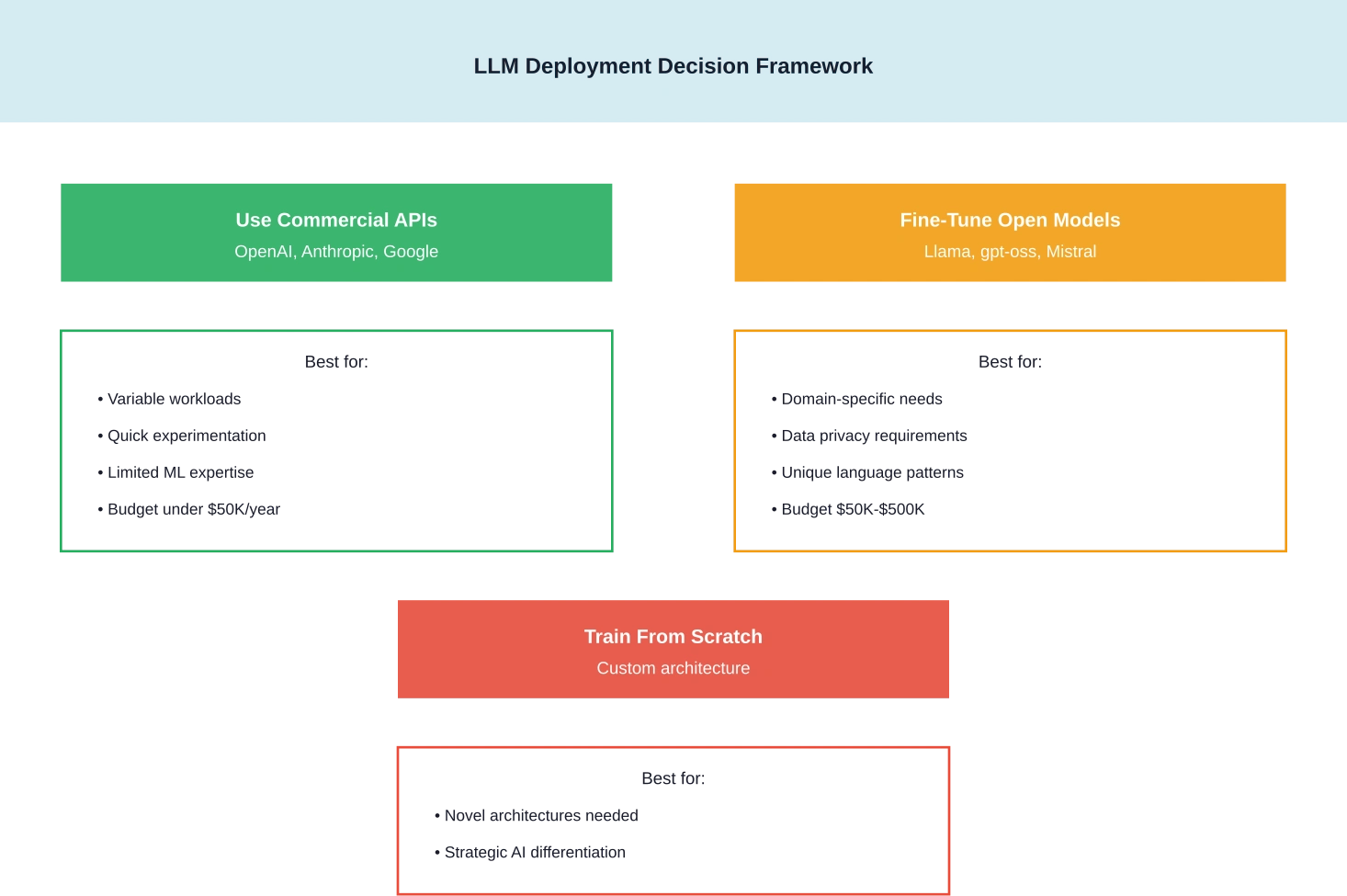
Devriez-vous former vous-même votre LLM en 2026 ?
Le cadre décisionnel a considérablement évolué avec la prolifération de modèles à poids ouvert performants.
Pour la plupart des organisations, la réponse est non, du moins pas en partant de zéro. Les modèles gpt-oss d'OpenAI, la série Llama 3 de Meta et d'autres alternatives à pondération ouverte offrent des performances dont la reproduction coûterait des dizaines de millions.
Mais le réglage fin ? C’est une autre histoire. Les organisations ayant des exigences de domaine uniques, des besoins de conformité spécifiques ou des données propriétaires ont souvent intérêt à régler finement les modèles existants plutôt que de s’appuyer uniquement sur des API commerciales à usage général.
Quand la formation en présentiel est pertinente
L’analyse coûts-avantages de Carnegie Mellon a identifié des scénarios spécifiques dans lesquels le déploiement et la formation LLM sur site s’avèrent économiquement viables :
- Charges de travail soutenues dépassant 10 000 heures GPU par an
- Des exigences strictes en matière de résidence des données interdisent l'utilisation du cloud
- Initiatives stratégiques à long terme en matière d'IA, s'étalant sur plus de 3 ans
- Disponibilité d'une expertise interne en infrastructure ML
Quand les services cloud gagnent
Pour les projets expérimentaux, les charges de travail variables ou les organisations ne disposant pas d'expertise en infrastructure d'apprentissage automatique, les solutions cloud et les services API offrent une meilleure rentabilité. La possibilité de réduire la charge, voire de l'arrêter complètement, élimine le risque d'investissement immobilisé.

Réduisez les coûts de votre formation LLM avant de commencer.
Entraîner un LLM à partir de zéro est coûteux non seulement en raison des ressources de calcul, mais aussi en raison de la préparation des données, des choix d'architecture du modèle et de la stratégie d'entraînement. IA supérieure il travaille sur cette couche d'ingénierie, aidant les entreprises à concevoir des LLM personnalisés, à préparer des ensembles de données d'entraînement et à optimiser les pipelines d'entraînement afin que les modèles soient construits efficacement dès le départ.
Si vous souhaitez estimer le coût réel d'une formation LLM en 2026, il est utile d'examiner l'infrastructure technique avant d'engager d'importants budgets de calcul. Contactez-nous IA supérieure pour évaluer votre architecture de formation et identifier les postes de dépenses à réduire avant même le début du processus de formation.
L'avenir de la formation en économie du LLM
Plusieurs tendances redessinent le paysage des coûts.
La version GPT-5.3-Codex d'OpenAI, publiée en février 2026 (annoncée le 5 février 2026), a démontré une efficacité supérieure de 25% à celle de son prédécesseur. À mesure que les architectures des modèles s'améliorent, la puissance de calcul nécessaire pour des performances équivalentes diminue.
Les progrès matériels se poursuivent également. Les générations successives de GPU de NVIDIA offrent des améliorations significatives en termes de performances par watt, réduisant ainsi les dépenses d'investissement et d'exploitation.
Mais surtout, la démocratisation de l'accès grâce aux modèles à pondération ouverte transforme en profondeur le profil des personnes pouvant participer au développement des masters en droit. Ce qui nécessitait 100 millions de livres sterling en 2023 pourrait être accessible pour 100 000 livres sterling en 2026 grâce à une utilisation judicieuse des transferts d'apprentissage et de techniques de formation efficaces.
Questions fréquemment posées
Combien coûte l'entraînement d'un modèle GPT-4 à partir de zéro ?
D'après le rapport Stanford AI Index 2024 et un article du Wall Street Journal, l'entraînement de GPT-4 coûte entre 78 et 100 millions de dollars (TP4T). Ce montant inclut l'infrastructure de calcul, les coûts énergétiques, l'acquisition de données et les ressources d'ingénierie nécessaires pendant toute la durée de l'entraînement. Le coût d'entraînement de Gemini Ultra est quant à lui estimé à environ 191 millions de dollars (TP4T), toujours selon le rapport Stanford AI Index 2024.
Est-il possible de former un LLM pour moins de 100 000 £ ?
Oui, mais avec des limitations importantes concernant la taille et les capacités des modèles. Les recherches présentées dans l'article FLM-101B ont démontré qu'il était possible d'entraîner des modèles plus petits (1 à 20 milliards de paramètres) avec un budget de $100 000 en utilisant des architectures efficaces, des procédures d'entraînement optimisées et une gestion rigoureuse des ressources. L'ajustement fin de modèles à pondération ouverte existants est bien plus rentable dans la plupart des cas d'utilisation.
Quelle formation LLM est la moins chère : en cloud ou sur site ?
Cela dépend des habitudes d'utilisation. Une étude de Carnegie Mellon a démontré que le déploiement sur site atteint généralement le seuil de rentabilité du cloud en 12 à 18 mois pour les organisations dont la charge de travail annuelle, soutenue et prévisible, dépasse 10 000 heures GPU. Les services cloud s'avèrent plus rentables pour les charges de travail variables, les projets expérimentaux ou les organisations ne disposant pas d'expertise en infrastructure.
Quel est le coût de l'inférence LLM par rapport à l'entraînement ?
Les recherches de l'équipe WiNGPT indiquent que les coûts d'inférence dépassent souvent les coûts d'entraînement sur la durée de vie opérationnelle d'un modèle. Alors que l'entraînement représente une dépense ponctuelle (avec un réentraînement périodique), l'inférence s'exécute en continu tant que le modèle est utilisé. Les applications à fort trafic peuvent engendrer des coûts d'inférence mensuels de plusieurs centaines de milliers d'euros.
Le réglage fin est-il moins cher qu'une formation à partir de zéro ?
Nettement moins cher. L'ajustement fin peut coûter de 60 à 900 milliards de dollars de moins qu'un entraînement à partir de zéro. Alors que l'entraînement de modèles de pointe comme GPT-4 coûte entre 78 et 100 millions de dollars, l'ajustement fin de ces mêmes modèles pour des applications spécifiques coûte généralement entre 5 000 et 50 000 milliards de dollars. Une étude de l'Université nationale de Colombie a démontré qu'un ajustement fin efficace pouvait être réalisé en seulement 7 heures sur un seul GPU NVIDIA T4.
Quelle carte graphique est la meilleure pour une formation LLM à petit budget ?
Pour les formations à budget limité, les GPU NVIDIA T4 (16 Go de VRAM) constituent une option intéressante à $2-4 par heure sur les plateformes cloud. Pour des projets plus ambitieux, les GPU A100 ou H100 offrent un meilleur rapport performances/prix malgré des tarifs horaires plus élevés. Le coût de base du GPU A800 80G est d'environ $0,79 par heure, selon une étude arXiv sur l'économie des GPU.
Comment les modèles à poids ouvert comme gpt-oss modifient-ils l'économie ?
La publication par OpenAI, en mars 2026, des modèles gpt-oss-120b et gpt-oss-20b sous licence Apache 2.0 bouleverse la donne en matière de coûts. Les organisations peuvent désormais télécharger des modèles de pointe et les adapter à leurs besoins spécifiques, évitant ainsi les investissements colossaux (plusieurs dizaines de millions d'euros) liés à un entraînement complet. Cette évolution démocratise l'accès aux capacités des modèles de pointe pour les organisations aux budgets plus modestes.
Prendre la décision en matière de formation
Former un LLM à partir de zéro représente un engagement financier considérable qui n'a de sens que pour les organisations ayant des besoins spécifiques, des budgets importants et des initiatives stratégiques à long terme en matière d'IA.
Dans la grande majorité des cas, l'optimisation des modèles à pondération ouverte permet d'obtenir 80 à 90 000 000 000 de la valeur ajoutée pour un coût 5 à 10 0 ...
La vraie question n'est pas de savoir si vous pouvez vous permettre de vous entraîner à partir de zéro, mais si vous pouvez vous permettre de ne pas tirer parti des milliards de dollars déjà investis dans les modèles de base pour toutes les catégories de poids.
Prêt à explorer le déploiement de modèles LLM au sein de votre organisation ? Commencez par évaluer les modèles à pondération ouverte existants en fonction de vos besoins spécifiques. Calculez vos coûts d'inférence prévus à l'aide d'outils tels que les calculateurs de coûts d'entraînement LLM disponibles. Et surtout, effectuez des tests d'ajustement à petite échelle avant d'investir dans une infrastructure plus importante.