Résumé rapide : L'entraînement d'un modèle de langage complexe coûte entre $50 000 et plus de $500 millions de yuans, selon la taille du modèle, l'infrastructure et la durée de l'entraînement. Les modèles plus petits, avec 20 milliards de paramètres, peuvent coûter entre $50 000 et $100 000 yuans, tandis que les systèmes massifs comme GPT-4 ou Gemini peuvent dépasser $100 millions de yuans. Les principaux postes de dépenses sont le temps de calcul sur GPU, la préparation des données et l'infrastructure cloud.
Le coût de l'entraînement de grands modèles de langage est devenu un facteur déterminant du développement de l'IA. Les organisations doivent désormais faire des choix cruciaux : développer leurs propres modèles ou souscrire à des services commerciaux.
Et les chiffres ? Ils sont stupéfiants.
D'après une étude d'Epoch AI, l'entraînement de GPT-4 et de Gemini de Google a coûté des centaines de millions de dollars. Il ne s'agit pas de simples améliorations par rapport aux modèles précédents : le coût a explosé ces dernières années.
Cependant, il faut savoir que toutes les organisations n'ont pas besoin d'un modèle novateur. Comprendre la structure des coûts permet de déterminer l'approche la plus adaptée à chaque cas d'usage.
Quels sont les facteurs qui influencent les coûts de formation des grands modèles de langage ?
Les coûts de formation se répartissent en plusieurs grandes catégories, chacune contribuant de manière significative à la facture totale.
Infrastructure informatique
Le matériel GPU représente la part prépondérante des dépenses. Les modèles comportant environ 100 milliards de paramètres nécessitent du matériel GPU avancé, comme les GPU A100 de NVIDIA. Pour un modèle de 20 milliards de paramètres, l'infrastructure requiert généralement entre 8 et 16 GPU A100 de 80 Go.
Le coût de calcul à lui seul s'élève à $50 000 à $100 000 pour un modèle plus petit. Ce calcul de base, soit environ $22 000 (16 A100 × $2,75/h × 500 heures), correspond uniquement à une session d'entraînement réussie.
Mais attendez.
Les échecs et les expérimentations peuvent facilement doubler, voire tripler, ce chiffre. L'entraînement de grands modèles de langage n'est pas un processus ponctuel. L'optimisation des hyperparamètres, les expérimentations architecturales et le dépannage consomment tous du temps de calcul supplémentaire.
Durée et temps
La durée de l'entraînement est proportionnelle à la taille et à la complexité du modèle. Un modèle de 20 milliards de paramètres peut nécessiter entre 500 et 1 000 heures d'entraînement. Les modèles plus importants, comportant plus de 120 milliards de paramètres, peuvent nécessiter plusieurs milliers d'heures de calcul sur GPU.
Les coûts d'infrastructure cloud s'accumulent à l'heure. Par conséquent, toute optimisation réduisant le temps d'entraînement diminue directement les dépenses. Le choix judicieux des hyperparamètres, une meilleure conception du pipeline de données et la réduction du temps d'inactivité du GPU sont autant d'éléments qui ont un impact financier significatif.
Préparation et gestion des données
Les données d'entraînement de haute qualité ne surgissent pas par magie. Les organisations investissent massivement dans la collecte, le nettoyage, l'étiquetage et la gestion des données. La raréfaction progressive des données publiques de haute qualité a accentué ce problème.
Les coûts de stockage et de transfert des données s'accumulent également. Le déplacement d'ensembles de données massifs entre les systèmes de stockage et les clusters de calcul engendre des frais de bande passante et de stockage que de nombreux budgets initiaux sous-estiment.

Comprendre le coût réel d'une formation LLM
L'entraînement d'un modèle de langage complexe nécessite bien plus que des ressources de calcul. L'ingénierie des données, l'expérimentation du modèle, son évaluation et l'infrastructure de déploiement influent également sur les coûts totaux.
IA supérieure aide les organisations à évaluer si la formation d'un modèle à partir de zéro est justifiée ou si des approches alternatives telles que l'adaptation du modèle ou l'intégration d'API sont plus pratiques.
Leurs services comprennent :
- conception du parcours de formation
- stratégie et validation de l'ensemble de données
- planification des infrastructures
- Analyse coûts-avantages des modèles personnalisés
Si vous envisagez un développement LLM sur mesure, une analyse de faisabilité peut vous aider à éviter des coûts de formation inutiles.
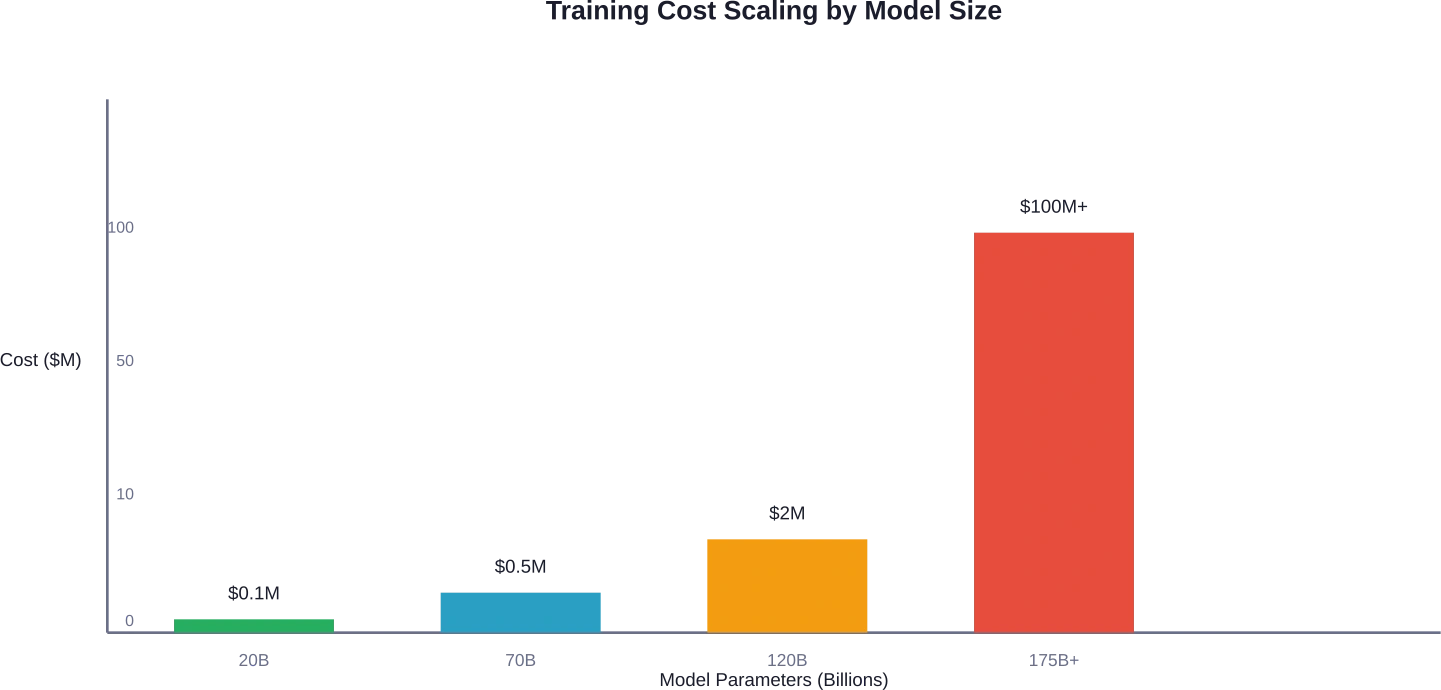
Comparaison des coûts réels : paramètres de 20 à 120 milliards de dollars
Analysons les fourchettes de coûts réelles pour différentes échelles de modèles.
| Taille du modèle | Configuration requise pour le GPU | Coût de calcul de base | Coût total estimé |
|---|---|---|---|
| Paramètres 20B | 8-16 A100 80 Go | $22,000-$50,000 | $50,000-$100,000 |
| Paramètres 70B | 32-64 A100 80 Go | $100,000-$250,000 | $200,000-$500,000 |
| 120B+ paramètres | 64-128+ A100 80 Go | $300,000-$800,000 | $500,000-$2,000,000 |
| Modèles Frontier (175B+) | Plus de 1000 GPU | $50M-$200M+ | $100M-$500M+ |
L'écart entre les petits et les grands modèles n'est pas linéaire, mais exponentiel. Un modèle à 120 milliards de paramètres coûte environ 5 à 20 fois plus cher qu'un modèle à 20 milliards, non seulement à cause du nombre de paramètres, mais aussi en raison de la complexité de l'entraînement, des temps de convergence plus longs et des coûts d'infrastructure supplémentaires.
Le modèle Frontier Premium
Des systèmes comme GPT-4 et Gemini se situent dans une catégorie de coûts totalement différente. D'après les données d'Epoch AI, le développement de ces modèles a coûté des centaines de millions de dollars.
Pourquoi de tels chiffres astronomiques ?
Les modèles de pointe nécessitent d'immenses clusters de GPU fonctionnant pendant des mois. Ils intègrent une expérimentation poussée, de multiples cycles d'entraînement, des tests de sécurité et des travaux d'alignement. L'infrastructure à elle seule — la gestion simultanée de milliers de GPU — exige des systèmes d'orchestration sophistiqués.
Analyse détaillée des dépenses d'infrastructure
Les coûts d'infrastructure ne se limitent pas à la simple location de GPU. Les entreprises doivent prendre en compte l'ensemble de la pile technologique.
Options matérielles GPU
Les GPU NVIDIA A100 restent la référence pour l'entraînement LLM, même si les modèles plus récents H100 et H200 offrent de meilleures performances à un prix plus élevé. Le choix dépendra de la disponibilité, du budget et des délais.
Les fournisseurs de cloud appliquent des tarifs différents. AWS, Google Cloud et Microsoft Azure proposent chacun des structures tarifaires distinctes pour les instances GPU. Les fournisseurs spécialisés dans les charges de travail d'IA offrent parfois des tarifs plus avantageux pour une utilisation prolongée.
Stockage et réseau
Les points de contrôle des modèles, les données d'entraînement et les journaux consomment un espace de stockage considérable. Un modèle de 120 milliards de paramètres génère des fichiers de points de contrôle de plus de 500 Go chacun. Les organisations enregistrent généralement plusieurs points de contrôle tout au long de l'entraînement à des fins de récupération et d'analyse.
La bande passante du réseau est également importante. Les transferts de données entre le stockage et le calcul, notamment pour l'entraînement distribué sur plusieurs nœuds, peuvent alourdir la facture mensuelle de plusieurs milliers de dollars.
Hébergement et déploiement
Les coûts de formation ne sont que le point de départ. L'hébergement de ces modèles pour l'inférence engendre des dépenses continues. Pour les modèles comportant environ 100 milliards de paramètres, les coûts d'hébergement varient de 1 400 000 à 1 400 000 par an, selon la taille du modèle et son utilisation.
Les coûts de développement largement cités pour les modèles simplifiés comme DeepSeek-V3 peuvent exclure les dépenses liées à la formation de modèles enseignants plus puissants dont ils sont issus, illustrant ainsi comment les approches comptables peuvent masquer les investissements totaux en matière de développement.
Stratégies d'optimisation pour réduire les coûts de formation
Plusieurs techniques permettent de réduire considérablement les coûts de formation sans sacrifier la qualité du modèle.
Quantification et précision mixte
Les cadres de quantification FP4 pour les modèles linéaires à grande échelle (LLM) ont démontré leur capacité à atteindre une précision comparable à celle des cadres BF16 et FP8, avec une dégradation minimale sur les modèles à grande échelle. Cette technologie réduit les besoins en mémoire et accélère les calculs, diminuant ainsi directement le temps de calcul GPU nécessaire.
L'entraînement à précision mixte est devenu une pratique courante. Utiliser une précision moindre pour certaines opérations tout en maintenant une précision plus élevée là où c'est nécessaire permet d'équilibrer efficacement vitesse et exactitude.
Méthodes d'entraînement de bas niveau
L'application d'une paramétrisation de faible rang aux modèles linéaires à longue portée (LLM) basés sur Transformer réduit les coûts de calcul et peut même améliorer les performances dans certains cas. Ces méthodes compressent l'espace des paramètres tout en préservant l'expressivité du modèle.
Stratégies de données efficaces
Les recherches sur les lois de mise à l'échelle optimales de Chinchilla indiquent qu'un développeur LLM entraînant un modèle 13B s'attendant à 2 billions de jetons de demande d'inférence pourrait potentiellement réduire le calcul total d'environ 1,7×10²² FLOPs (17%) en entraînant des modèles plus petits plus longtemps.
L'idée clé ? Un entraînement légèrement plus long avec davantage de données peut réduire les coûts d'inférence ultérieurs si le modèle doit traiter de nombreuses requêtes. Le coût total de possession est plus important que le seul coût d'entraînement.

Instances Spot et machines virtuelles préemptibles
Les fournisseurs de cloud proposent des instances spot à prix réduit, pouvant être interrompues. Pour les flux de travail de formation tolérants aux pannes avec des points de contrôle réguliers, les instances spot permettent de réduire les coûts de 40 à 70% par rapport à la tarification à la demande.
Le compromis ? La formation pourrait prendre plus de temps en raison des interruptions. Mais avec une gestion adéquate des points de contrôle, les économies réalisées justifient généralement la complexité.
Le choix entre construire et acheter
Les organisations sont confrontées à un choix fondamental : former leur propre modèle ou utiliser des services commerciaux.
Quand les services commerciaux sont judicieux
Dans la plupart des cas, l'abonnement à des services commerciaux de modélisation de modèles numériques (LLM) s'avère plus économique. Les API d'OpenAI, d'Anthropic et de Google permettent d'accéder à des modèles de pointe sans investissement initial.
D'après les analyses coûts-avantages, les organisations doivent utiliser les services commerciaux de manière intensive et soutenue pour atteindre le seuil de rentabilité. Les études suggèrent que les seuils de performance des principaux modèles commerciaux, autour de 20%, constituent des points d'équilibre viables pour les investissements dans les infrastructures.
Quand la formation a du sens
La formation personnalisée devient intéressante lorsque :
- Les exigences spécifiques au domaine nécessitent des données de formation spécialisées
- Les réglementations relatives à la protection des données empêchent l'envoi d'informations à des API tierces.
- Le volume d'inférences prévu dépasse plusieurs millions de requêtes par mois.
- Le réglage fin des modèles commerciaux s'avère insuffisant pour le cas d'utilisation.
Les organisations qui prévoient une utilisation intensive et soutenue sur plusieurs années peuvent optimiser leur coût total de possession grâce aux modèles auto-hébergés. Le seuil de rentabilité dépend de la taille du modèle, du volume de requêtes et des niveaux de performance requis.
Considérations relatives au calcul lors des tests
Des recherches récentes sur l'allocation des ressources de calcul lors des tests révèlent une autre dimension des coûts : les dépenses d'inférence peuvent dépasser les coûts d'entraînement pour les modèles largement déployés.
Les stratégies d'allocation adaptatives qui attribuent dynamiquement les ressources de calcul en fonction de la difficulté des requêtes améliorent considérablement l'efficacité. Les indicateurs de difficulté sans entraînement permettent de répartir les budgets de calcul fixes entre les requêtes de test, maximisant ainsi le nombre d'instances résolues tout en respectant les contraintes budgétaires.
Les recherches sur les agents performants démontrent l'importance cruciale d'une conception optimale du framework. Une étude a mis en évidence un framework conservant les performances (96,71 TP3T) d'un agent open source de pointe, tout en réduisant les coûts opérationnels de 0,398 à 0,228, soit une amélioration de 28,41 TP3T du coût de passage.
Principes comptables des coûts de développement de l'IA
Les décideurs politiques utilisent de plus en plus les coûts de développement et la puissance de calcul comme indicateurs des capacités et des risques liés à l'IA. Des lois récentes introduisent des exigences réglementaires conditionnées par des seuils de coûts spécifiques.
Le problème est le suivant : les ambiguïtés techniques de la comptabilité analytique créent des failles. Une comptabilité trop restrictive peut masquer le coût total de développement d'un modèle. Les coûts de développement souvent cités pour des modèles simplifiés comme DeepSeek-V3 peuvent exclure les dépenses liées à l'entraînement de modèles enseignants plus performants dont ils sont issus.
Les organisations devraient adopter une comptabilité exhaustive qui comprend :
- Toutes les simulations d'entraînement, y compris les expériences ayant échoué
- coûts d'acquisition, de nettoyage et de préparation des données
- Frais d'infrastructure et de réseau
- Temps d'ingénierie pour le développement de l'architecture
- Travaux d'essais de sécurité et d'alignement
- Coûts des modèles d'enseignants pour les approches de distillation
| Catégorie de coût | % typique du total | Souvent négligé ? |
|---|---|---|
| Calcul GPU (exécution réussie) | 30-40% | Non |
| Expériences ratées | 15-25% | Oui |
| Préparation des données | 10-15% | Oui |
| Stockage et réseau | 5-10% | Oui |
| main-d'œuvre d'ingénierie | 20-30% | Parfois |
| Sécurité et alignement | 5-10% | Oui |
Tendances futures des coûts
Plusieurs facteurs influenceront les coûts de formation dans les années à venir.
Les performances des cartes graphiques continuent de progresser. L'architecture Blackwell de NVIDIA (notamment les variantes B100, B200 et GB200) promet un meilleur rapport performances/prix. Cependant, la forte demande maintient les prix à un niveau élevé.
Le coût des données augmente. Face à la raréfaction des données publiques de haute qualité, les organisations investissent davantage dans des ensembles de données propriétaires, la génération de données synthétiques et les accords de licence de données.
Cela dit, les améliorations algorithmiques et les gains d'efficacité de l'entraînement compensent en partie les coûts matériels. La communauté de recherche développe sans cesse de meilleures méthodes d'optimisation, des lois d'échelle et des architectures plus performantes.
Questions fréquemment posées
Combien coûte l'entraînement d'un modèle à 70 milliards de paramètres ?
L'entraînement d'un modèle de 70 milliards de paramètres coûte généralement entre $200 000 et $500 000. Ce coût inclut les coûts de calcul de base de $100 000 à $250 000 pour 32 à 64 GPU A100, auxquels s'ajoutent les dépenses liées aux exécutions infructueuses, aux expérimentations, à la préparation des données et aux frais d'infrastructure.
Les petites organisations peuvent-elles se permettre de former de grands modèles de langage ?
Les petites structures peuvent entraîner des modèles de taille modeste (1 à 20 milliards de paramètres) avec un T4T de 10 000 à 100 000 en utilisant les ressources GPU du cloud et des techniques d'optimisation. Cependant, pour la plupart des applications, l'utilisation de services API commerciaux ou l'optimisation de modèles open source existants s'avère plus rentable qu'un entraînement à partir de zéro.
Quel est l'aspect le plus coûteux d'une formation LLM ?
Le temps de calcul GPU représente entre 30 et 401 TP3T du coût total de la plupart des projets. Cependant, en tenant compte des expériences infructueuses et du réglage des hyperparamètres, les dépenses liées au calcul dépassent souvent 501 TP3T du budget total. La main-d'œuvre d'ingénierie représente généralement entre 20 et 301 TP3T supplémentaires.
Combien de temps faut-il pour entraîner un modèle de langage de grande taille ?
La durée d'entraînement varie considérablement selon la taille du modèle. Un modèle de 20 milliards de paramètres peut nécessiter entre 500 et 1 000 heures de calcul GPU (soit environ 3 à 6 semaines sur un cluster de 16 GPU). Les modèles plus importants, comportant plus de 120 milliards de paramètres, peuvent exiger plusieurs milliers d'heures de calcul GPU, ce qui porte la durée d'entraînement à 2 à 4 mois. Les modèles de pointe, avec plus de 175 milliards de paramètres, s'entraînent souvent pendant plusieurs mois sur des clusters massifs.
Est-il plus économique de se former une seule fois ou d'utiliser des appels API à long terme ?
Cela dépend entièrement du volume d'utilisation. Pour les applications effectuant moins de 10 millions d'appels API par mois, les services commerciaux sont généralement moins coûteux. Les organisations ayant une utilisation élevée et soutenue, notamment celles nécessitant des modèles spécialisés ou soumises à des exigences de confidentialité des données, peuvent trouver l'autoformation plus économique sur plusieurs années.
Quelle est la différence entre le coût de l'entraînement et le coût de l'inférence ?
Les coûts d'entraînement correspondent aux dépenses initiales liées au développement du modèle et peuvent varier de quelques milliers à plusieurs centaines de millions de dollars. Les coûts d'inférence représentent les dépenses récurrentes nécessaires à l'exécution du modèle pour les prédictions, facturées par requête ou par jeton. Pour les modèles largement déployés, le total des coûts d'inférence sur la durée de vie du modèle dépasse souvent les coûts d'entraînement.
Comment puis-je réduire les coûts de ma formation LLM ?
Les principales stratégies de réduction des coûts comprennent l'utilisation de la quantification (entraînement FP4/FP8), l'exploitation des instances ponctuelles pour des économies de 40 à 70%, la mise en œuvre d'un point de contrôle efficace pour minimiser le gaspillage de calcul, l'optimisation des pipelines de données pour réduire le temps d'inactivité du GPU et la prise en compte de la distillation du modèle à partir de modèles enseignants plus grands lorsque cela est approprié.
Prendre la décision d'investissement
L'entraînement de grands modèles de langage reste coûteux, mais les coûts varient selon les modèles. Les organisations ne sont pas confrontées à un choix binaire entre des modèles de pointe et l'absence de modèle.
Une évaluation réaliste commence par l'analyse des besoins. Quel niveau de performance permet réellement de résoudre le problème métier ? L'application nécessite-t-elle des fonctionnalités de pointe, ou un modèle plus petit et spécialisé suffirait-il ?
Pour de nombreuses applications, les modèles comportant entre 7 et 20 milliards de paramètres offrent d'excellents résultats à un coût raisonnable. Ces systèmes peuvent être entraînés pour $50 000 à $200 000 paramètres, ce qui les rend accessibles aux entreprises de taille moyenne ayant des besoins spécifiques.
La course aux modèles de pointe — visant plus de 175 milliards de paramètres — n'est pertinente que pour les entreprises développant des plateformes d'IA généralistes. Pour les autres, le meilleur compromis réside souvent dans des modèles plus petits et spécialisés, optimisés pour des tâches spécifiques.
Considérez le coût total de possession. La formation n'est que le point de départ. Prenez en compte l'hébergement, les coûts d'inférence, la maintenance continue et l'équipe d'ingénierie nécessaire au support du système.
L'économie du développement des modèles LLM continue d'évoluer. Le matériel s'améliore, les algorithmes gagnent en efficacité et de nouvelles techniques d'entraînement apparaissent régulièrement. Ce qui coûte aujourd'hui $500 000 pourrait coûter $200 000 dans deux ans, ou offrir des performances trois fois supérieures pour le même prix.
Les organisations qui se lancent dans ce domaine devraient commencer modestement, évaluer soigneusement leurs performances et adapter leur stratégie en fonction de la valeur ajoutée démontrée. La technologie est suffisamment mature pour que l'expérimentation ne nécessite plus d'investissements initiaux massifs. Il est conseillé de prototyper avec des modèles réduits, de valider l'approche, puis de décider s'il est plus judicieux de passer à l'échelle supérieure ou de conserver les API commerciales.
La révolution de l'IA continue de s'accélérer, mais un déploiement intelligent prime sur la simple mise à l'échelle. Comprendre ces structures de coûts permet aux organisations de prendre des décisions éclairées plutôt que de courir après des indicateurs de performance qui peuvent ne pas être pertinents pour leurs applications spécifiques.