Résumé rapide : En 2026, les API d'inférence LLM les plus rapides étaient proposées par des fournisseurs comme Groq, SiliconFlow et Hugging Face, avec une latence inférieure à 2 secondes et un débit supérieur à 100 jetons par seconde. Les prix variaient considérablement : de 0,28 TP4T par million de jetons d'entrée pour DeepSeek à 21,00 TP4T pour GPT-5.2 Pro d'OpenAI. Pour une inférence rentable, il est essentiel de trouver un équilibre entre vitesse, prix et capacités du modèle en fonction de votre charge de travail.
La vitesse est cruciale pour le déploiement à grande échelle de modèles de langage complexes. Cependant, l'API d'inférence la plus rapide n'est pas toujours la moins chère, et la moins chère n'est pas toujours suffisamment rapide.
Début 2026, le marché de l'inférence LLM s'est fragmenté en plusieurs segments distincts. Les fournisseurs haut de gamme comme OpenAI pratiquent des prix exorbitants pour leurs modèles de pointe. Parallèlement, de nouveaux acteurs agressifs comme DeepSeek proposent des tarifs inférieurs de 901 000 000 THB, voire plus, à ceux des acteurs établis.
Ce guide détaille les chiffres réels : prix par million de jetons, mesures de latence réelles, benchmarks de débit et coûts cachés que les pages de tarification ne mentionnent pas.
Comprendre les métriques de vitesse d'inférence LLM
Avant de comparer les fournisseurs, il est important de comprendre ce que signifie réellement “ rapide ” dans le contexte des API LLM.
Trois indicateurs sont primordiaux :
- Latence Ce paramètre mesure le temps d'obtention du premier jeton, c'est-à-dire la rapidité avec laquelle le modèle commence à répondre après réception de votre requête. Selon les indicateurs de performance du fournisseur d'inférence Hugging Face, les modèles les plus performants atteignent une latence inférieure à 1,5 seconde. Groq est régulièrement cité comme extrêmement rapide dans les tests comparatifs réalisés par des tiers et dans ses propres rapports de tests comparatifs (jetons/seconde).
- débit Ce système comptabilise les jetons générés par seconde une fois que le modèle commence à répondre. Les données de Hugging Face montrent que les principaux fournisseurs atteignent 127 jetons par seconde, voire plus, pour des modèles comme Qwen3.5-35B-A3B.
- Fenêtre contextuelle Ce paramètre détermine la quantité de texte que le modèle peut traiter en une seule requête. Les modèles modernes prennent en charge de 128 000 à 262 000 jetons, mais des contextes plus longs peuvent augmenter la latence et le coût.
- Le point crucial est que la vitesse varie considérablement en fonction des caractéristiques de la charge de travail. Les requêtes courtes avec des réponses brèves s'exécutent plus rapidement que les tâches de raisonnement contextuel long. Le traitement par lots privilégie un meilleur débit et des coûts moindres au détriment d'un temps de réponse immédiat.
Fournisseurs d'inférence LLM les plus rapides selon la latence
Lorsque la vitesse pure est la priorité, une poignée de fournisseurs surpassent systématiquement la concurrence.
Groq : Conçu pour la vitesse
Groq utilise une unité de traitement du langage (LPU) matérielle personnalisée, conçue spécifiquement pour l'inférence LLM. Les discussions au sein de la communauté et les propres tests de performance de Groq le présentent comme “ extrêmement rapide ” en termes de vitesse d'inférence, avec des mesures de jetons par seconde qui le placent constamment en tête du marché.
L'entreprise a publié de nouveaux benchmarks pour Llama 3.3 70B, démontrant des performances d'inférence exceptionnelles. Pour les applications où un temps de réponse inférieur à la seconde est crucial (chatbots, assistants en temps réel, outils interactifs), l'architecture de Groq offre des avantages concrets.
Les prix ne sont pas affichés publiquement pour tous les modèles ; les développeurs doivent donc consulter la documentation officielle de Groq pour connaître les tarifs en vigueur.
SiliconFlow : La vitesse au service de l'accessibilité
SiliconFlow a affiché des vitesses d'inférence jusqu'à 2,3 fois supérieures et une latence inférieure de 321 TP3T par rapport aux principales plateformes cloud d'IA lors de récents tests de performance, tout en conservant une précision constante. La plateforme propose des options de paiement à l'usage sans serveur et avec GPU réservé.
Cette combinaison de rapidité et de maîtrise des coûts fait de SiliconFlow une solution idéale pour les déploiements en production où ces deux indicateurs sont essentiels. La plateforme prend en charge plusieurs modèles open source avec une tarification transparente et des options d'infrastructure flexibles.
Fournisseurs d'inférences Hugging Face
Hugging Face centralise plusieurs fournisseurs d'inférence via une API unifiée, et suit les performances pour différentes combinaisons modèle-fournisseur. L'interface permet aux développeurs d'acheminer automatiquement les requêtes vers le fournisseur le plus rapide ou le plus économique pour chaque modèle. Le routeur prenant en charge les appels compatibles avec OpenAI, la migration est simple pour les utilisateurs d'intégrations existantes.

Concevoir des applications LLM optimisées pour une inférence rapide
La rapidité des réponses LLM dépend d'une architecture, d'une configuration de modèle et d'une infrastructure appropriées. IA supérieure Cette entreprise développe des logiciels d'IA et des systèmes de traitement automatique du langage naturel (TALN) qui intègrent de vastes modèles de langage dans des applications concrètes telles que les chatbots, les outils d'automatisation et les plateformes d'analyse de données. Son équipe conçoit des pipelines de modélisation, des services backend et des environnements de déploiement afin de garantir le bon fonctionnement des fonctionnalités LLM au sein des systèmes de production.
Vous développez un produit qui utilise les API LLM ?
Dialoguer avec une IA supérieure à :
- concevoir et développer des applications basées sur LLM
- développer des systèmes de traitement automatique du langage naturel (TALN) et des logiciels d'intelligence artificielle (IA)
- déployer des modèles de langage au sein des plateformes existantes
👉 Demandez une consultation en IA avec IA supérieure pour discuter de votre projet.
Tarification de l'inférence LLM : aperçu du marché en 2026
Les structures tarifaires varient énormément d'un fournisseur à l'autre. Certains facturent des prix élevés pour leurs modèles propriétaires, tandis que d'autres pratiquent une concurrence agressive sur les prix des modèles open source.
Voici où en est le marché début 2026 :
Niveau Premium : OpenAI et Anthropic
OpenAI a lancé GPT-5.2 Pro en février 2026 au prix de $21,00 par million de jetons d'entrée et $168,00 par million de jetons de sortie. Le modèle GPT-5.2 standard coûte $8,00 jetons d'entrée et $32,00 jetons de sortie par million de jetons.
Les modèles Claude d'Anthropic se situent dans une gamme de prix similaire, haut de gamme. Ces fournisseurs justifient leurs coûts plus élevés par des fonctionnalités de pointe, une fiabilité à toute épreuve et des tests de sécurité rigoureux.
Niveau intermédiaire : Google Gemini et autres
Les modèles Gemini de Google offrent des prix compétitifs pour des solutions performantes. Le segment intermédiaire, plus large, comprend des fournisseurs comme Mistral AI, qui propose un bon compromis entre performances et prix plus accessibles que les fournisseurs haut de gamme.
Niveau de budget : DeepSeek Disruption
DeepSeek propose des prix nettement inférieurs à ceux de ses concurrents avec ses modèles “ réfléchissants ” V3.2-Exp, affichés à seulement $0,28 par million de jetons d'entrée (erreur de cache) et $0,42 par million de jetons de sortie. Cela représente une réduction de plus de 90% par rapport aux fournisseurs premium.
La gamme Grok de xAI cible également les développeurs soucieux des coûts. Grok 4 Fast et Grok 4.1 Fast sont proposés à $0,20 en entrée et $0,50 en sortie par million de jetons.
| Fournisseur | Exemple de modèle | Entrée (1 jeton TP4T/M) | Sortie (1 jeton TP4T/M) | Niveau de performance |
|---|---|---|---|---|
| OpenAI | GPT-5.2 Pro | $21.00 | $168.00 | Prime |
| OpenAI | GPT-5.2 | $8.00 | $32.00 | Prime |
| xAI | Grok 4 | $3.00 | $15.00 | Niveau intermédiaire |
| xAI | Grok 4 Rapide | $0.20 | $0.50 | Budget |
| DeepSeek | V3.2-Exp | $0.28 | $0.42 | Budget |
| Novita (HF) | Qwen3.5-35B-A3B | $0.25 | $2.00 | Budget |
Coûts cachés au-delà de la tarification des jetons
Le prix affiché par million de jetons ne donne qu'une idée partielle du coût total.
Plusieurs facteurs cachés ont un impact significatif sur les dépenses réelles :
Mise en cache et réutilisation du contexte
Certains fournisseurs proposent des tarifs réduits pour le contexte mis en cache et réutilisé entre les requêtes. Le tarif $0.28 de DeepSeek s'applique aux requêtes sans accès au cache ; le prix est inférieur pour les requêtes avec accès au cache. Si votre application traite régulièrement des contextes similaires, la mise en cache peut réduire considérablement les coûts.
Tarification par lots vs. tarification en temps réel
OpenAI et Google proposent des API de traitement par lots à prix réduits, parfois jusqu'à 501 000 ₹ de réduction par rapport aux tarifs en temps réel. D'après les discussions au sein de la communauté Hugging Face, il n'existe pas d'équivalent direct de l'API Batch d'OpenAI avec un tarif préférentiel sur les points de terminaison serverless de Hugging Face.
L'inférence par lots convient aux charges de travail non critiques en termes de temps : traitement de données, génération de contenu, tâches d'analyse. Le compromis réside dans un délai d'exécution plus long, en contrepartie de coûts réduits.
Économie des jetons de production
Les jetons de sortie coûtent généralement 4 à 8 fois plus cher que les jetons d'entrée. Un modèle qui génère des réponses verbeuses consomme le budget plus rapidement qu'un modèle qui répond de manière concise.
Pour optimiser les coûts, limiter la longueur maximale des résultats évite une utilisation excessive des jetons. Des limites trop basses peuvent tronquer les réponses avant qu'elles ne soient complètes ; la configuration doit donc trouver un équilibre entre exhaustivité et maîtrise des coûts.
Coûts d'infrastructure et de mise à l'échelle
Les API sans serveur facturent au jeton, sans frais d'infrastructure. Les modèles de capacité réservée, comme les options de GPU réservés de SiliconFlow, nécessitent un engagement initial, mais offrent une meilleure rentabilité par jeton à grande échelle.
Les recherches sur le déploiement de GPU hétérogènes montrent que la rentabilité varie considérablement en fonction des caractéristiques de la charge de travail. Selon une analyse du traitement LLM sur des GPU hétérogènes, l'adéquation des types de requêtes au matériel approprié améliore l'utilisation des ressources et réduit les coûts effectifs.
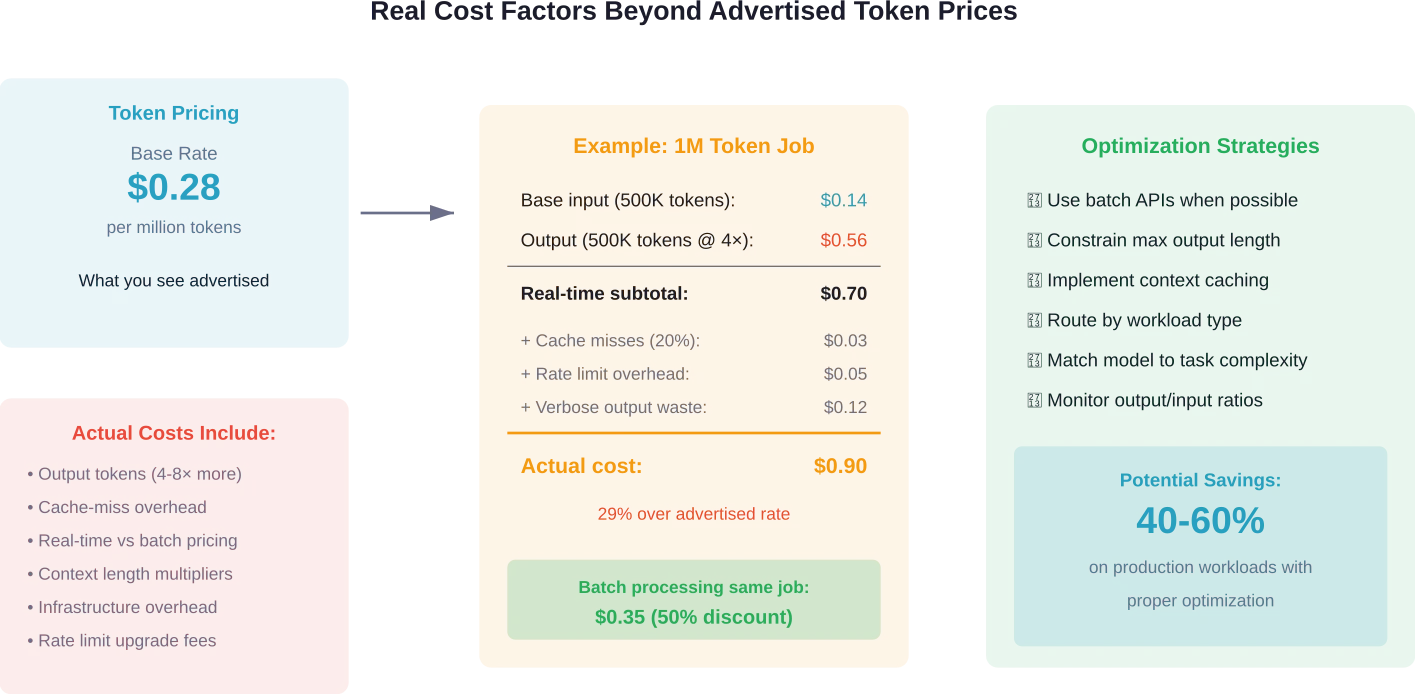
Rapport rapidité/coût : trouver le juste équilibre
Le choix du fournisseur optimal dépend entièrement des exigences en matière de charge de travail.
Pour les applications critiques en termes de latence (chatbots destinés aux clients, assistants de codage en temps réel, démonstrations interactives), la vitesse justifie un prix élevé. Un délai de réponse de deux secondes suffit à faire fuir les utilisateurs, quelles que soient les économies réalisées.
Pour le traitement par lots à haut volume (classification de contenu, extraction de données, pipelines d'analyse), le coût par million de jetons est un facteur déterminant. Le tarif $0,28 de DeepSeek, associé à des performances acceptables (voire excellentes), est économiquement judicieux.
Les recherches sur l'accompagnement des modèles LLM suggèrent que les approches hybrides permettent d'optimiser les deux indicateurs. L'utilisation de modèles plus petits et plus rapides pour le traitement initial et l'acheminement des requêtes complexes vers des modèles plus grands réduisent les coûts moyens tout en préservant la qualité. Selon l'étude, même de faibles indications provenant de modèles plus grands (10 à 30% de réponse complète) améliorent considérablement la précision des modèles plus petits.
Considérations relatives à la taille du modèle
La taille du modèle a un impact direct sur la vitesse et le coût.
D'après les recommandations de Hugging Face concernant le choix des modèles linéaires open source, un modèle de 7 à 8 milliards de paramètres nécessite 14 à 16 Go de VRAM en précision FP16, ou 6 à 8 Go avec une quantification sur 4 bits. Les instances AWS g5.xlarge constituent une option cloud.
Les modèles plus petits, comportant 1 à 3 milliards de paramètres, fonctionnent sur 4 à 6 Go de VRAM (2 Go quantifiés) et gèrent des tâches de base (classification de texte, saisie automatique, chat simple) sur du matériel modeste comme les GPU RTX 3060 ou les GPU d'ordinateurs portables.
Les modèles plus volumineux offrent un meilleur raisonnement, mais nécessitent davantage de ressources de calcul. Selon une étude comparative des performances, le déploiement d'un modèle LLaMA-2-70B requiert au moins deux GPU NVIDIA A100 (avec 80 Go de VRAM chacun) pour l'inférence FP16.
Fournisseurs les plus rentables pour l'inférence rapide
Sur la base des indicateurs de performance et des données tarifaires, plusieurs fournisseurs proposent des rapports rapidité/coût très intéressants :
SiliconFlow
SiliconFlow allie une vitesse compétitive (2,3 fois plus rapide que certaines plateformes leaders) à une tarification flexible. La plateforme prend en charge à la fois le mode sans serveur et la capacité réservée, permettant ainsi une optimisation des coûts en fonction des modèles d'utilisation.
Ce service propose une plateforme cloud d'IA tout-en-un avec des rapports prix/performances parmi les meilleurs du secteur, ciblant à la fois les développeurs et les entreprises.
Fournisseurs d'inférences Hugging Face
Le routeur unifié de Hugging Face regroupe plusieurs fournisseurs, permettant un routage automatique vers l'option la plus rapide ou la moins chère pour chaque modèle. Selon leurs indicateurs :
- Novita propose des modèles Qwen3.5 avec une entrée $0.25-$0.60 et une latence inférieure à 1,1 seconde.
- Together AI propose des modèles comparables avec une latence légèrement supérieure mais un prix similaire.
- Plusieurs fournisseurs se disputent chaque modèle populaire, ce qui stimule l'efficacité.
Le routeur prend en charge les appels d'API compatibles avec OpenAI, simplifiant ainsi la migration depuis d'autres fournisseurs. Les développeurs peuvent spécifier des préférences de routage (” :fastest ”, “ :cheapest ”) afin d'optimiser le trafic en fonction de différents objectifs.
Mistral IA
Mistral AI offre des performances élevées à un prix compétitif. L'entreprise privilégie des architectures de modèles efficaces qui réduisent les coûts d'inférence sans compromettre les fonctionnalités.
Les modèles Mistral atteignent des niveaux de qualité compétitifs tout en maintenant des coûts par jeton raisonnables, ce qui les rend intéressants pour les déploiements en production nécessitant l'équilibre de multiples contraintes.
DeepSeek
Pour les charges de travail où le coût domine la prise de décision, la tarification agressive de DeepSeek ($0.28 en entrée / $0.40 en sortie) représente le plancher actuel du marché pour les modèles performants.
Les performances sont inférieures à celles des fournisseurs haut de gamme, mais restent acceptables pour de nombreuses applications. Les économies réalisées (jusqu'à 90% par rapport aux modèles les plus performants) permettent des usages qui ne justifieraient pas un prix plus élevé.
IA des feux d'artifice
Fireworks AI est spécialisée dans l'inférence optimisée pour les modèles open source. La plateforme privilégie une fiabilité de niveau production, avec des prix et des performances prévisibles.
Ce service fournit une infrastructure spécifiquement optimisée pour le déploiement de LLM, avec des fonctionnalités conçues pour les développeurs qui créent des applications plutôt que pour expérimenter avec des modèles.
Considérations relatives à l'analyse comparative des performances
Les résultats des tests de performance publiés ne reflètent pas toujours les performances réelles.
Plusieurs facteurs créent des écarts entre les indicateurs annoncés et l'expérience de production :
La charge du réseau influe sur la latence. Les fournisseurs d'accès subissent un ralentissement en cas de forte demande. L'heure, la région géographique et la demande actuelle ont toutes une incidence sur les temps de réponse réels.
Les caractéristiques des requêtes ont une importance considérable. Les requêtes courtes avec des réponses brèves s'exécutent plus rapidement que les tâches de raisonnement à contexte long. Selon les recherches sur les compromis énergie-performance de l'inférence LLM, l'inférence présente une variabilité importante selon les requêtes et les phases d'exécution.
La latence au démarrage à froid peut affecter la première requête dans les architectures sans serveur.
Les limitations de débit restreignent la capacité de traitement. Même les API rapides limitent le nombre de requêtes au-delà d'un certain volume, ce qui nécessite des abonnements de niveau supérieur ou une capacité réservée pour les applications à fort trafic.
Options de déploiement d'infrastructure
Au-delà des API gérées, les choix d'infrastructure ont un impact significatif sur les coûts et les performances.
API sans serveur
Les solutions sans serveur, comme celles proposées par Hugging Face, OpenAI et d'autres, facturent par jeton sans gestion d'infrastructure. Ce modèle convient parfaitement aux charges de travail variables, au prototypage et aux applications dont la demande est imprévisible.
Le compromis réside dans des coûts par jeton plus élevés par rapport à une infrastructure dédiée à grande échelle.
Capacité réservée
Les instances GPU réservées ou les points de terminaison dédiés garantissent des ressources à un coût par jeton plus avantageux. Des fournisseurs comme SiliconFlow proposent cette option en complément de leur offre sans serveur.
La capacité réservée devient économiquement judicieuse une fois que l'utilisation atteint des seuils constants où le coût de l'engagement devient inférieur aux dépenses équivalentes sans serveur.
Inférence auto-hébergée
L'exécution des inférences sur une infrastructure détenue ou louée offre un contrôle maximal et des coûts potentiellement plus bas pour des volumes très élevés.
Les recherches sur le déploiement de modèles LLM sur des dispositifs périphériques mettent en évidence des contraintes : un modèle à 7-8 milliards de paramètres exige des ressources de mémoire et de calcul considérables. Les études de caractérisation des SoC mobiles montrent que, même avec des unités de traitement hétérogènes, la bande passante mémoire limite le débit, certaines configurations n'atteignant que 40 à 45 Go/s par unité avant de nécessiter plusieurs processeurs pour saturer la bande passante disponible.
L'auto-hébergement nécessite une expertise en matière de déploiement, d'optimisation, de surveillance et de mise à l'échelle des modèles — des tâches que les API sans serveur éliminent.
Choisir le bon fournisseur pour votre charge de travail
Les critères de décision devraient privilégier les caractéristiques de la charge de travail plutôt que les comparaisons abstraites.
Posez ces questions :
- Quel est le mode d'utilisation ? Les charges de travail importantes et stables privilégient la capacité réservée ou l'auto-hébergement. Une demande variable et imprévisible convient aux API sans serveur.
- Dans quelle mesure l'application est-elle sensible à la latence ? Les interactions utilisateur en temps réel exigent des temps de réponse inférieurs à la seconde. Le traitement en arrière-plan tolère une latence de plusieurs secondes pour réduire les coûts.
- De quelles capacités de modélisation avez-vous réellement besoin ? De nombreuses applications surdimensionnent les modèles. Des modèles plus petits et plus rapides gèrent les tâches simples à moindre coût.
- Le traitement par lots est-il possible ? Les charges de travail non urgentes bénéficient de remises sur les lots 50% lorsque les fournisseurs les proposent.
- Quel est le rapport entre la production et les intrants ? Les applications générant des réponses longues paient cher pour les jetons de sortie. Limiter la verbosité réduit considérablement les coûts.
- La charge de travail bénéficie-t-elle de la mise en cache du contexte ? Le traitement répété de contextes similaires avec prise en charge de la mise en cache permet de réduire les coûts par requête.
Questions fréquemment posées
Quelle est l'API d'inférence LLM la moins chère en 2026 ?
DeepSeek propose le tarif le plus bas pour ses modèles V3.2-Exp (début 2026) : $0,28 par million de jetons d'entrée et $0,40 par million de jetons de sortie. Grok 4 Fast de xAI ($0,20 en entrée / $0,50 en sortie) offre un prix comparable. Toutefois, le coût total dépend de la verbosité des résultats, de l'efficacité de la mise en cache et de la disponibilité du traitement par lots. L'option la plus économique varie donc en fonction de ces facteurs liés à la charge de travail.
Quel fournisseur propose la vitesse d'inférence LLM la plus rapide ?
Groq se classe régulièrement comme le fournisseur d'inférence le plus rapide, grâce à son matériel LPU dédié et optimisé pour les charges de travail LLM. Les benchmarks tiers et les discussions de la communauté confirment que Groq offre des performances de pointe en termes de jetons par seconde. Selon les mesures de Hugging Face, Novita (hébergeant des modèles Qwen avec une latence de 0,66 à 1,09 seconde) et SiliconFlow (2,3 fois plus rapide que certaines plateformes leaders) figurent parmi les autres options rapides. La vitesse réelle dépend de la taille du modèle, de la longueur du contexte et de la charge du système.
Combien coûte le traitement d'un milliard de jetons via une API LLM ?
Le coût pour un milliard de jetons varie considérablement selon le fournisseur et la combinaison entrée/sortie. Avec les tarifs de DeepSeek ($0,28 en entrée / $0,40 en sortie), un milliard de jetons coûte $280 pour une utilisation exclusive en entrée ou $400 pour une utilisation exclusive en sortie. Avec les tarifs de GPT-5.2 Pro d'OpenAI ($21 en entrée / $168 en sortie), le même volume coûte $21 000 en entrée ou $168 000 en sortie. Une charge de travail typique avec 60% en entrée et 40% en sortie coûterait environ $328 sur DeepSeek contre $79 800 sur GPT-5.2 Pro, soit une différence de 240 fois.
Les API de traitement par lots permettent-elles réellement de réaliser des économies ?
Oui, lorsqu'elles sont disponibles. OpenAI et Google proposent des API de traitement par lots avec des réductions d'environ 50% par rapport au traitement en temps réel. En contrepartie, l'exécution est plus lente : les tâches par lots peuvent prendre des heures au lieu de quelques secondes. D'après les discussions de la communauté Hugging Face, de nombreux points d'accès sans serveur Hugging Face n'offrent pas de tarifs réduits spécifiques au traitement par lots, contrairement aux points d'accès dédiés à l'inférence. Le traitement par lots est pertinent pour le traitement de données, la génération de contenu et les tâches d'analyse ne nécessitant pas de résultats immédiats.
Dois-je utiliser une capacité GPU sans serveur ou réservée ?
Cela dépend des habitudes et du volume d'utilisation. Les API sans serveur conviennent parfaitement aux demandes variables, au prototypage et aux volumes faibles à modérés, où la simplicité d'utilisation prime sur le coût par jeton. La capacité réservée devient rentable lorsque l'utilisation régulière atteint le seuil de rentabilité, moment où les coûts d'engagement deviennent inférieurs aux dépenses équivalentes pour une solution sans serveur. SiliconFlow propose les deux options, permettant une optimisation en fonction des habitudes d'utilisation. Calculez votre volume de jetons réel et soutenu et comparez-le au prix de la réservation pour déterminer le seuil de rentabilité.
Comment la taille du modèle affecte-t-elle la vitesse et le coût de l'inférence ?
Les modèles plus volumineux nécessitent davantage de ressources de calcul, ce qui augmente la latence et les coûts d'infrastructure. Selon la documentation Hugging Face, un modèle de 1 à 3 milliards d'octets requiert seulement 2 à 4 Go de VRAM et offre une inférence rapide sur du matériel modeste, convenant aux tâches de base. Un modèle de 7 à 8 milliards d'octets requiert 6 à 16 Go de VRAM selon la quantification et gère des charges de travail plus complexes. Un modèle de 70 milliards d'octets exige plus de 140 Go de VRAM (plusieurs GPU haut de gamme) et traite les requêtes plus lentement. Les modèles plus petits optimisent la vitesse et le coût ; les modèles plus volumineux améliorent les performances et la qualité du raisonnement. Il est recommandé d'adapter la taille du modèle aux exigences réelles de la tâche plutôt que d'opter systématiquement pour le plus grand modèle disponible.
Puis-je réduire les coûts en optimisant la longueur des invites ?
Absolument. Des requêtes plus courtes consomment moins de jetons d'entrée, ce qui réduit directement les coûts. Plus important encore, limiter la longueur maximale des réponses évite les réponses verbeuses et coûteuses. Étant donné que les jetons de sortie coûtent 4 à 8 fois plus cher que les jetons d'entrée, un modèle générant des réponses inutilement longues épuise rapidement le budget. Il est recommandé de définir les paramètres `max_tokens` en fonction de votre cas d'utilisation : une valeur trop faible tronque les réponses, tandis qu'une valeur trop élevée entraîne une verbosité superflue. Surveillez la longueur réelle des réponses et ajustez les limites en conséquence. La mise en cache du contexte pour les éléments de requête répétés réduit encore les coûts si elle est prise en charge par le fournisseur.
Conclusion : Trouver le juste équilibre entre rapidité et coût
L'API d'inférence LLM la plus rapide n'est pas forcément le meilleur choix pour toutes les charges de travail, et l'API la moins chère n'est pas toujours la plus rentable lorsque la qualité et la vitesse sont importantes.
En 2026, le marché offre un véritable choix. Des fournisseurs de premier plan comme OpenAI proposent des fonctionnalités de pointe à des prix élevés. Des concurrents agressifs comme DeepSeek proposent des prix inférieurs de 901 000 milliards de roupies, voire plus, à ceux des acteurs établis. Des fournisseurs d'infrastructures spécialisés comme Groq et SiliconFlow optimisent la vitesse ou la rentabilité.
Le fournisseur optimal dépend entièrement de vos exigences spécifiques : sensibilité à la latence, besoins en matière de qualité de sortie, volume d’utilisation, verbosité de la sortie, possibilités de mise en cache et compatibilité du traitement par lots avec votre cas d’utilisation.
Commencez par analyser les caractéristiques de votre charge de travail. Mesurez les volumes de jetons réels, les ratios entrée/sortie et les exigences de latence. Ensuite, identifiez les fournisseurs qui optimisent ces exigences en fonction de vos contraintes spécifiques.
Ne partez pas du principe que l'option la plus chère offre les meilleurs résultats, ni que l'option la moins chère sacrifie trop la qualité. Testez plusieurs fournisseurs avec des charges de travail représentatives avant de vous engager dans un déploiement à grande échelle.
Le marché de l'inférence LLM reste très concurrentiel en 2026, avec une amélioration rapide des prix et des performances. Surveillez les nouveaux acteurs et comparez régulièrement vos offres pour optimiser vos coûts face à l'évolution du marché.
Prêt à optimiser les coûts d'inférence de votre LLM ? Comparez votre charge de travail spécifique auprès de différents fournisseurs en utilisant les données de tarification et les indicateurs de performance de ce guide afin d'identifier le meilleur rapport vitesse/coût pour votre application.