Résumé rapide : Les outils d'analyse LLM dotés de fonctionnalités d'optimisation des coûts aident les organisations à surveiller l'utilisation des jetons, à suivre les dépenses et à réduire les coûts d'infrastructure d'IA grâce à la mise en cache intelligente, la sélection de modèles et l'allocation automatisée des ressources. Les principales plateformes combinent le suivi des coûts en temps réel et l'observabilité des performances pour identifier les flux de travail coûteux et les optimiser sans compromettre la qualité des réponses. Une gestion efficace des coûts exige un suivi par session, une optimisation rapide et une sélection stratégique des modèles en fonction de la complexité des tâches.
Les organisations qui déploient des modèles de langage complexes sont confrontées à un défi majeur : les coûts peuvent exploser sans que personne ne s’en aperçoive. La tarification par jetons implique que chaque appel d’API s’accumule, et sans analyse adéquate, le chatbot ou l’analyseur de documents d’assistance peut engloutir les budgets à une vitesse alarmante.
L'essor fulgurant de l'adoption des modèles linguistiques a engendré une demande urgente de plateformes d'analyse spécialisées. Ces outils ne se contentent pas de suivre les dépenses : ils identifient activement les opportunités d'optimisation, automatisent les stratégies de réduction des coûts et offrent la visibilité nécessaire pour prendre des décisions éclairées concernant le choix des modèles et l'infrastructure.
Le problème, c'est que toutes les plateformes d'analyse ne se valent pas. Certaines se concentrent uniquement sur l'observabilité, d'autres privilégient le suivi des coûts, et les meilleures combinent les deux avec des fonctionnalités d'optimisation concrètes. Comprendre quelles fonctionnalités sont les plus importantes pour votre cas d'usage est essentiel pour une gestion efficace des coûts, au lieu de gaspiller de l'argent inutilement.
Comprendre les structures de coûts et les modèles de tarification des LLM
La tarification par jetons domine le marché des logiciels de modélisation de données (LLM). Selon les tarifs officiels d'Anthropic, Claude Opus 4.6 coûte $5 par million de jetons d'entrée et $25 par million de jetons de sortie. Cette asymétrie de prix est significative : les jetons de sortie coûtent cinq fois plus cher que les jetons d'entrée.
Règle générale : des invites et des réponses générées plus longues impliquent un nombre de jetons plus élevé et des coûts plus élevés.
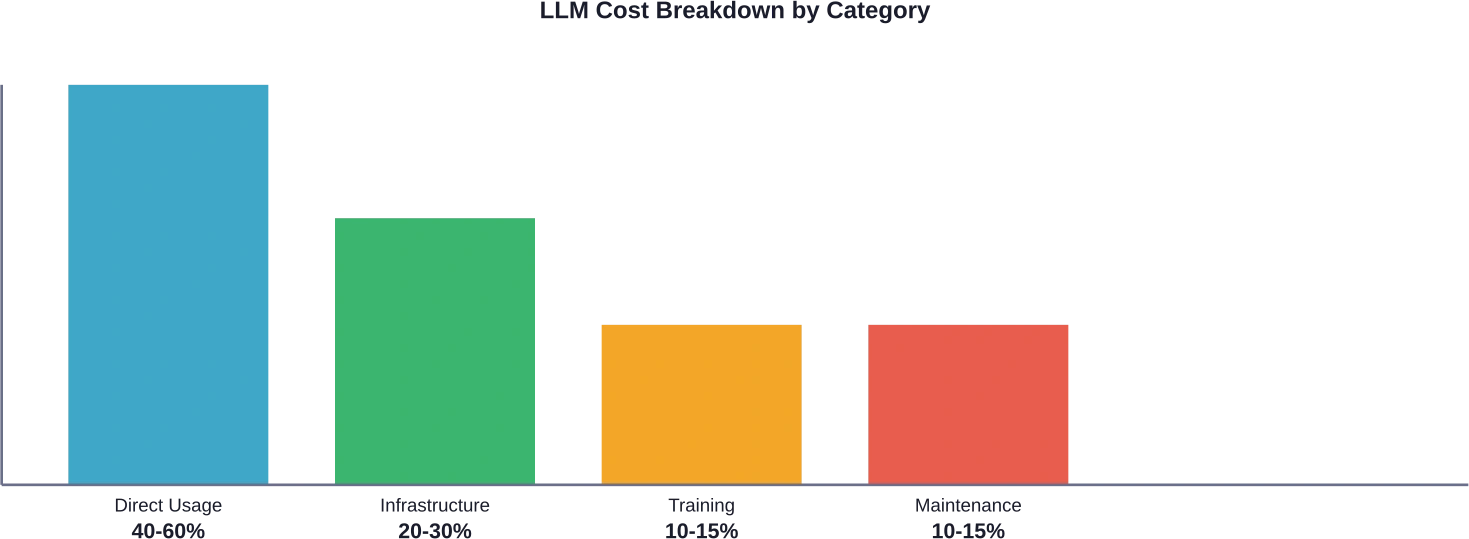
Soyons francs : la plupart des organisations sous-estiment leurs coûts réels liés au marketing digital. Selon une analyse sectorielle, les frais d’utilisation directs peuvent représenter entre 40 et 600 000 milliards de dollars des dépenses totales de marketing digital, l’infrastructure et l’intégration consomment entre 20 et 300 000 milliards de dollars, et la formation et l’optimisation constituent le reste.
Les multiplicateurs de coûts cachés
La documentation AWS indique que la mise en cache des requêtes peut réduire la latence de réponse des inférences jusqu'à 851 TP3T et les coûts des jetons d'entrée jusqu'à 901 TP3T pour les modèles compatibles sur Amazon Bedrock. Cependant, sans analyse permettant d'identifier les modèles pouvant être mis en cache, les entreprises ne bénéficient pas de ces économies.
D'après les études de cas AWS, le temps de traitement des requêtes a varié de 6,76 secondes à 32,24 secondes, cette variation reflétant principalement les exigences différentes en matière de jetons de sortie. Les réponses rapides, inférieures à 10 secondes, concernent généralement les requêtes simples, tandis que les tâches analytiques complexes peuvent dépasser 30 secondes.
La taille des fenêtres de contexte alourdit également les coûts. Claude Opus 4.6 propose en version bêta une fenêtre de contexte de 1 million de jetons : puissante, mais coûteuse si les organisations envoient régulièrement des contextes inutilement volumineux.
Caractéristiques principales des plateformes d'analyse LLM
Les plateformes d'analyse LLM performantes offrent trois fonctionnalités essentielles : un suivi complet des coûts, une visibilité sur les performances et des informations exploitables pour l'optimisation. Chaque composant remplit une fonction spécifique dans la gestion des charges de travail d'IA.
Suivi des coûts par session
Les sessions regroupent les requêtes connexes afin de refléter le coût réel des interactions utilisateur. Au lieu de visualiser les appels API individuellement, les équipes voient les flux de travail complets. D'après des exemples de suivi des coûts, les conversations avec le support coûtent en moyenne environ $0,12 avec 5 appels API, les flux de travail d'analyse de documents coûtent environ $0,45 avec 12 appels API, tandis que les requêtes rapides coûtent environ $0,02 avec un seul appel.
Cette granularité est essentielle. Les organisations peuvent ainsi identifier les types d'interactions qui génèrent des coûts et optimiser leurs opérations en conséquence. L'alternative, qui consiste à traiter chaque appel d'API de manière isolée, masque la véritable rentabilité des fonctionnalités d'IA.
Surveillance de l'utilisation en temps réel
L'analyse des habitudes de consommation de jetons révèle des opportunités d'optimisation. Les plateformes analytiques suivent les ratios jetons entrants/sortants, identifient les requêtes coûteuses et signalent les pics d'utilisation anormaux avant qu'ils n'impactent les budgets.
Mais attention ! La surveillance en temps réel n’est utile que si elle déclenche des actions. Les meilleures plateformes intègrent des alertes automatisées et des seuils budgétaires pour éviter les dépassements de coûts.
Comparaison des performances des modèles
Chaque modèle excelle dans des tâches différentes. Les outils analytiques permettent de réaliser des tests A/B entre les modèles afin de trouver le compromis optimal entre coût et qualité pour chaque cas d'utilisation.
D'après une étude du laboratoire d'intelligence artificielle Watson du MIT et d'IBM, une erreur relative moyenne de 4% représente la meilleure précision atteignable en raison du bruit aléatoire initial, mais une erreur allant jusqu'à 20% reste utile pour la prise de décision. Les organisations doivent définir des seuils de performance acceptables avant d'optimiser leurs coûts.
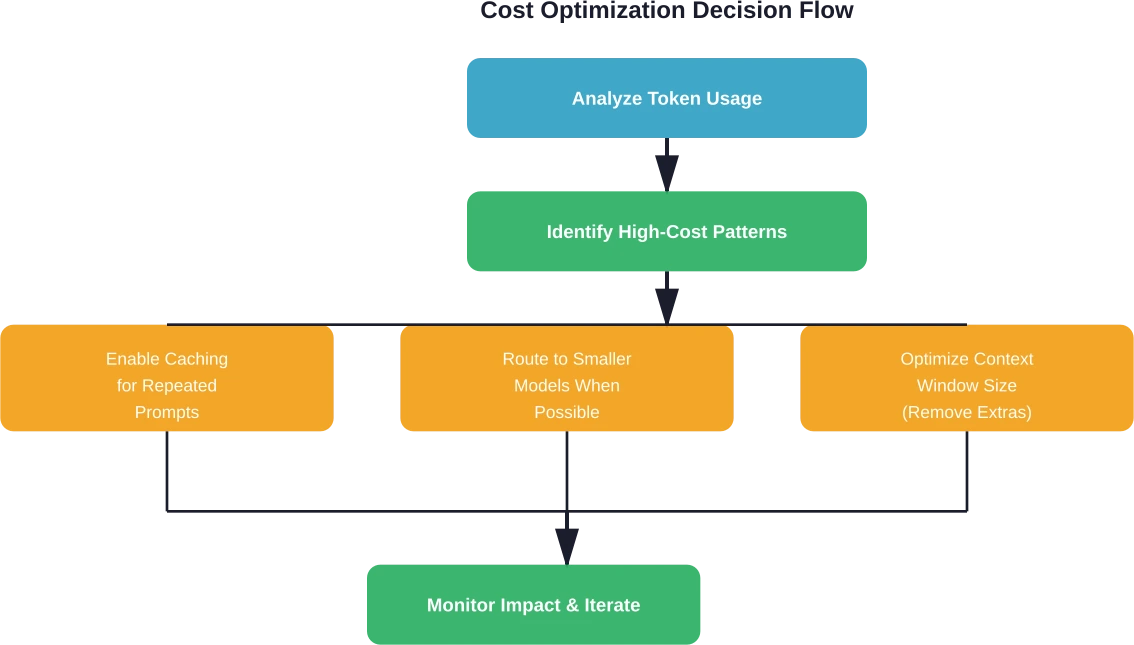
Stratégies d'optimisation des coûts rendues possibles par les outils analytiques
Les plateformes analytiques ne se contentent pas de rendre compte des coûts ; elles permettent des stratégies d’optimisation spécifiques qui réduisent directement les dépenses sans sacrifier les fonctionnalités.
Mise en cache intelligente des invites
La mise en cache des invites stocke les segments d'invite fréquemment utilisés et les réutilise d'une requête à l'autre. Elle permet d'améliorer considérablement la latence, AWS documentant des réductions du temps de réponse allant jusqu'à 851 TP3T pour les requêtes mises en cache. Cependant, sans analyse permettant d'identifier les modèles exploitables, les entreprises ne bénéficient pas pleinement de ces gains.
Deux approches de mise en cache prédominent : la mise en cache au niveau système stocke les préfixes d’invites courants, tandis que la mise en cache des paires requête-réponse stocke des paires requête-réponse complètes pour une réutilisation ultérieure. Les outils d’analyse identifient les invites qui bénéficient le plus de la mise en cache en fonction de leur fréquence de répétition et de la longueur des jetons.
Sélection de modèles stratégiques
Une analyse coûts-avantages du déploiement LLM sur site de Carnegie Mellon établit que les scores de référence dans 20% des principaux modèles commerciaux reflètent la pratique des entreprises, où des écarts de performance modestes restent acceptables pour la réduction des coûts.
Les plateformes analytiques permettent d'identifier les possibilités d'orienter les requêtes vers des modèles moins coûteux lorsque les exigences de qualité le permettent. Les tâches de classification simples ne nécessitent pas de modèles de pointe ; des alternatives plus petites et moins onéreuses sont tout à fait satisfaisantes.
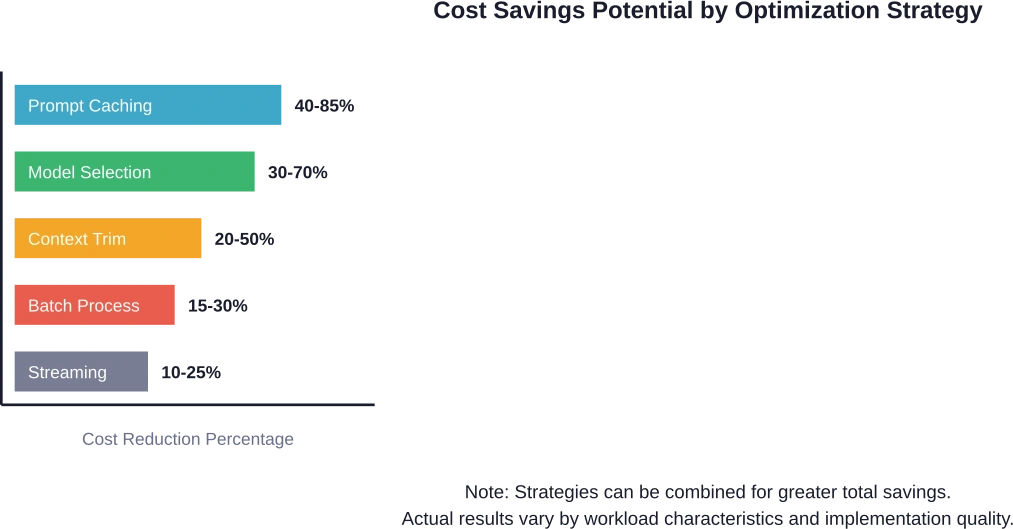
| Stratégie | Réduction des coûts | Complexité de la mise en œuvre | Impact sur la qualité
|
|---|---|---|---|
| Mise en cache rapide | 40-85% | Faible | Aucun |
| Sélection du modèle | 30-70% | Moyen | Dépendant de la tâche |
| Optimisation du contexte | 20-50% | Moyen | Aucun à minimal |
| Traitement par lots | 15-30% | Haut | Ajoute de la latence |
| Flux de réponse | 10-25% | Faible | Aucun |
Optimisation de la fenêtre contextuelle
De nombreuses applications envoient des contextes inutilement volumineux à chaque requête. L'analyse des données révèle la taille moyenne de ces contextes et permet d'identifier les possibilités de supprimer les informations non pertinentes.
Des contextes plus courts impliquent moins d'éléments d'entrée et un traitement plus rapide. Des études de cas industrielles font état de réductions de coûts significatives grâce à une optimisation systématique du contexte.
Seuils de qualité automatisés
Les recherches d'OpenAI sur les agents auto-évolutifs recommandent de poursuivre les cycles d'optimisation jusqu'à ce que les seuils de qualité atteignent plus de 801 000 retours positifs ou que les nouvelles itérations n'apportent qu'une amélioration minime. Les plateformes d'analyse suivent ces indicateurs et signalent lorsque l'optimisation continue n'apporte plus de gains significatifs.

Réduisez les coûts de votre master en droit (LLM) grâce à un partenaire d'ingénierie compétent.
De nombreuses entreprises adoptent des outils d'analyse LLM pour surveiller l'utilisation, la consommation de jetons et les performances des modèles, mais les économies les plus importantes proviennent généralement de la manière dont les modèles sont construits et intégrés dès le départ. C'est là que… IA supérieure L'entreprise intervient souvent. Son équipe travaille sur la couche technique des systèmes LLM : conception de modèles personnalisés, préparation des données d'entraînement, optimisation des architectures et intégration des LLM dans les flux de travail existants afin que les entreprises puissent contrôler plus efficacement leurs performances et leurs coûts d'exploitation.
Si vous cherchez à réduire vos dépenses en modélisation juridique en 2026, il peut être judicieux d'examiner comment vos modèles sont entraînés, déployés et supervisés. Un audit technique ou une analyse d'architecture peut souvent révéler des coûts d'inférence inutiles, des pipelines inefficaces ou des modèles mal optimisés.
Parlez à IA supérieure si vous souhaitez évaluer votre configuration LLM actuelle et identifier des moyens pratiques de réduire les coûts d'exploitation à long terme.
Comparaison des principales plateformes d'analyse LLM
Le paysage des plateformes analytiques comprend des outils d'observabilité spécialisés, des solutions natives des fournisseurs de cloud et des alternatives open source. Chaque catégorie offre des avantages distincts.
Solutions natives des fournisseurs de cloud
AWS, Google Cloud et Azure proposent des analyses intégrées à leurs plateformes d'IA. L'utilisation et les coûts d'Amazon Bedrock sont suivis via les rapports AWS Billing and Cost Management et les API AWS Cost Explorer, permettant un accès automatisé aux données de dépenses de l'ensemble de l'organisation.
Google Conversational Insights propose deux niveaux de tarification : Standard et Entreprise. Les coûts varient selon le type d’interaction. Les conversations par chat sont facturées à la messagerie, tandis que les conversations vocales sont facturées à la minute. Le niveau Entreprise inclut des fonctionnalités d’IA de qualité et prend en charge jusqu’à 50 évaluations personnalisées par conversation.
Les solutions natives s'intègrent parfaitement à l'infrastructure cloud existante, mais peuvent manquer de fonctionnalités d'optimisation avancées présentes sur les plateformes spécialisées.
Plateformes d'observabilité spécialisées
Les plateformes d'observabilité LLM dédiées se concentrent exclusivement sur la surveillance et l'optimisation des charges de travail d'IA. Ces outils offrent généralement des analyses plus approfondies, des fonctionnalités d'optimisation plus sophistiquées et une prise en charge indépendante des fournisseurs LLM.
Les fonctionnalités clés incluent le suivi des requêtes sur les systèmes distribués, l'analyse de la latence, la surveillance du taux d'erreur et l'attribution des coûts par fonctionnalité ou équipe. Les meilleures plateformes fournissent des informations exploitables plutôt que de simples données brutes.
Alternatives open source
Les outils d'analyse open source séduisent les organisations ayant des exigences spécifiques ou des contraintes budgétaires. Ces solutions offrent transparence et personnalisation, mais nécessitent un investissement technique plus important pour leur déploiement et leur maintenance.
Le développement piloté par la communauté signifie que les fonctionnalités évoluent en fonction des besoins réels des utilisateurs, même si le support et la documentation pour les entreprises peuvent être en retard par rapport aux alternatives commerciales.
| Type de plateforme | Idéal pour | Atout clé | Limite principale
|
|---|---|---|---|
| Cloud natif | Déploiements mono-cloud | Intégration profonde | Dépendance au fournisseur |
| Outils spécialisés | Environnements multi-modèles | Optimisation avancée | Coût supplémentaire |
| Source libre | exigences personnalisées | Transparence et contrôle | Charge d'entretien |
Meilleures pratiques de mise en œuvre pour l'analyse des coûts
Le déploiement efficace d'outils analytiques nécessite une planification rigoureuse et des attentes réalistes quant aux délais d'optimisation.
Établissement de mesures de référence
Les organisations ne peuvent optimiser ce qu'elles ne mesurent pas. Commencez par suivre la consommation totale de jetons, le coût moyen par interaction utilisateur et la répartition des dépenses entre les différentes fonctionnalités ou cas d'utilisation.
Il est recommandé d'effectuer les mesures de référence pendant au moins deux semaines afin de recueillir des données représentatives des habitudes d'utilisation. Les variations saisonnières ou les pics d'utilisation faussent les moyennes ; des périodes de mesure plus longues permettent donc d'obtenir des données plus fiables.
Définir des objectifs d'optimisation réalistes
Les recherches du laboratoire d'IA Watson du MIT et d'IBM soulignent l'importance de définir le budget de calcul et la précision cible du modèle avant toute optimisation. Les équipes doivent déterminer si une erreur relative moyenne de 4% ou de 20% répond à leurs besoins décisionnels.
Des objectifs de réduction des coûts trop ambitieux peuvent parfois compromettre la fonctionnalité. L'objectif n'est pas de minimiser les dépenses, mais de les optimiser pour atteindre les niveaux de qualité requis.
Mise en œuvre de déploiements progressifs
N'optimisez pas tout en même temps. Testez d'abord les stratégies de mise en cache sur les points de terminaison à fort trafic, mesurez l'impact, puis étendez-les à d'autres domaines.
Le déploiement progressif permet d'isoler les variables et de mieux attribuer les réductions de coûts à des modifications spécifiques. Il minimise également les risques : si l'optimisation a un impact négatif sur l'expérience utilisateur, les répercussions restent limitées.
Surveillance et itération continues
L'optimisation des coûts n'est pas un projet ponctuel. Les habitudes d'utilisation évoluent, de nouveaux modèles sont lancés avec des prix différents et les exigences des applications changent.
Planifiez des analyses trimestrielles des données pour identifier les tendances émergentes. L'automatisation réduit les tâches manuelles : les plateformes qui signalent automatiquement les opportunités d'optimisation permettent un gain de temps considérable.
Techniques d'optimisation avancées
Au-delà du simple suivi des coûts, les techniques avancées permettent de réaliser des économies supplémentaires pour les déploiements sophistiqués.
Routage de modèle multi-agents
Des recherches sur l'optimisation du traitement automatique du langage naturel à l'aide d'agents basés sur des modèles linéaires latents (LLM) démontrent que la combinaison de différents modèles permet d'améliorer les performances. Un cadre de travail a atteint une précision de 88,11 TP3T sur l'ensemble de données NLP4LP et de 82,31 TP3T sur Optibench, réduisant ainsi les taux d'erreur de 581 TP3T et 521 TP3T respectivement par rapport aux résultats précédents grâce à la collaboration multi-agents.
Les plateformes d'analyse peuvent mettre en œuvre un routage intelligent qui achemine les requêtes vers le modèle le plus rentable capable de traiter chaque tâche. Les requêtes simples sont acheminées vers des modèles rapides et peu coûteux. Les tâches de raisonnement complexes sont traitées par des alternatives plus performantes, mais aussi plus onéreuses.
Optimisation de l'attention par requêtes groupées
Pour les organisations utilisant des modèles auto-hébergés, la configuration du mécanisme d'attention a un impact significatif sur les coûts. Les recherches sur l'attention par requêtes groupées à coût optimal pour la modélisation à contexte long montrent que, dans ce contexte, l'utilisation d'un nombre réduit de nœuds d'attention tout en augmentant la taille du modèle diminue la consommation de mémoire et le nombre d'opérations en virgule flottante (FLOPs) de plus de 501 TP3 T par rapport à la configuration GQA de Llama-3, sans dégradation des performances du modèle.
Cela est important pour les déploiements personnalisés où les coûts d'infrastructure représentent une part importante des dépenses totales.
Boucles de réentraînement automatisées
Les recherches d'OpenAI sur les agents auto-évolutifs introduisent des boucles de réentraînement reproductibles qui permettent de gérer les cas limites et de corriger les erreurs sans intervention humaine constante. Les systèmes qui identifient les résultats de faible qualité et se réentraînent automatiquement en fonction des retours d'information réduisent à la fois les taux d'erreur et le gaspillage de ressources lié à la régénération des réponses erronées.
Les plateformes analytiques qui suivent les indicateurs de qualité de la production permettent ces cycles d'amélioration automatisés, générant ainsi des économies cumulatives au fil du temps.
Évaluation du retour sur investissement des investissements analytiques
Les plateformes analytiques engendrent des coûts supplémentaires : abonnements, efforts d’intégration, maintenance continue. Les organisations ont besoin de cadres d’analyse pour évaluer la rentabilité de leurs investissements.
Calcul du seuil de rentabilité
Les études sur l'analyse coûts-avantages du déploiement de solutions LLM sur site examinent le seuil de rentabilité des entreprises par rapport aux services commerciaux. La même méthodologie s'applique aux outils analytiques : calculer les dépenses mensuelles liées au LLM, estimer le pourcentage de réduction des coûts réalisable grâce aux fonctionnalités d'optimisation et comparer ce pourcentage aux coûts d'abonnement à la plateforme.
Par exemple, si les coûts mensuels de LLM atteignent $50 000 et que l'analyse permet une réduction de 30% grâce à la mise en cache et à la sélection de modèles, cela représente une économie mensuelle de $15 000. Une plateforme d'analyse coûtant $2 000 par mois est immédiatement rentabilisée et génère un bénéfice net mensuel de $13 000.
Quantification des gains d'efficacité opérationnelle
La réduction des coûts ne représente qu'une partie de la valeur ajoutée. Les plateformes analytiques permettent aux ingénieurs de réduire le temps qu'ils consacrent à l'analyse manuelle des problèmes de performance, au débogage des requêtes coûteuses et à la génération de rapports d'utilisation.
D'après les rapports du secteur, les équipes ont constaté des gains de productivité significatifs lorsque des analyses pertinentes permettent d'éliminer les goulots d'étranglement liés au débogage. Les gains de temps se traduisent directement par une réduction des coûts de main-d'œuvre ou une accélération du développement.
Valeur d'atténuation des risques liés aux facteurs
Les alertes budgétaires et la détection des anomalies permettent d'éviter les dépassements de coûts catastrophiques. Les organisations qui ne disposent pas d'un système de surveillance adéquat ne découvrent les dérives budgétaires que des jours, voire des semaines après qu'elles se soient produites, à la réception des factures.
L'avantage d'éviter une facture surprise de 100 000 $ justifie un investissement important en analyses de données. Les bénéfices liés à la réduction des risques sont plus difficiles à quantifier, mais ils ont un impact significatif sur le coût total de possession.
Analyse sur site vs analyse dans le cloud
Les organisations qui déploient des LLM auto-hébergés sont confrontées à des exigences analytiques différentes de celles qui utilisent exclusivement des API commerciales.
Avantages de l'analyse dans le cloud
Les plateformes d'analyse basées sur le cloud nécessitent une configuration minimale, s'adaptent automatiquement et bénéficient de mises à jour continues de leurs fonctionnalités sans intervention manuelle. Elles conviennent parfaitement aux organisations utilisant des services LLM commerciaux où le suivi au niveau de l'API offre une visibilité suffisante.
L'intégration consiste généralement à ajouter des appels SDK ou à acheminer les requêtes via des services de passerelle, ce qui est simple pour la plupart des équipes de développement.
Considérations relatives au déploiement sur site
L'analyse auto-hébergée convient aux organisations ayant des exigences strictes en matière de gouvernance des données ou à celles qui utilisent des modèles propriétaires en interne. Selon une étude de Stanford sur l'intelligence par watt, les LLM locaux peuvent répondre avec précision à 88,71 Tbit/s³ de tâches de conversation et de raisonnement en un seul tour, ce qui rend l'auto-hébergement viable pour de nombreux cas d'utilisation.
Cependant, les déploiements sur site présentent une complexité accrue. Les organisations ont besoin d'une infrastructure pour la plateforme analytique elle-même, doivent gérer les mises à jour manuellement et requièrent une expertise spécialisée pour la maintenance des systèmes.
Approches hybrides
De nombreuses organisations adoptent des stratégies hybrides : l’analyse dans le cloud pour l’utilisation commerciale des modèles de modélisation des données (LLM) combinée à une surveillance sur site pour les modèles auto-hébergés. Cette approche offre un équilibre entre simplicité d’utilisation et contrôle, tout en garantissant une visibilité complète sur l’ensemble de la pile d’IA.
Tendances futures de l'analyse des coûts des LLM
Le paysage analytique continue d'évoluer rapidement à mesure que les organisations exigent des capacités plus sophistiquées.
Modélisation prédictive des coûts
Les plateformes de nouvelle génération prédiront les coûts futurs en fonction des tendances d'utilisation, des modifications apportées aux applications et des fluctuations de prix des modèles. Des alertes proactives avertiront les équipes avant que les coûts ne flambent, au lieu de signaler les problèmes a posteriori.
Les modèles d'apprentissage automatique entraînés sur les tendances d'utilisation historiques peuvent prévoir les dépenses mensuelles avec une précision croissante, permettant ainsi une meilleure planification budgétaire.
Agents d'optimisation automatisés
Les recherches sur l'optimisation automatisée des agents basés sur LLM (ARTEMIS) démontrent des systèmes qui expérimentent en continu des changements de configuration, mesurent l'impact et mettent en œuvre automatiquement des améliorations sans intervention humaine.
Ces systèmes d'auto-optimisation pourraient révolutionner la gestion des coûts en éliminant totalement le travail d'optimisation manuelle. Les premières implémentations présentent des résultats prometteurs, mais restent expérimentales.
Analyse unifiée inter-fournisseurs
Les organisations font de plus en plus appel à plusieurs fournisseurs de modèles d'apprentissage automatique (LLM) : OpenAI pour certaines tâches, Anthropic pour d'autres, et des modèles open source pour des cas d'usage spécifiques. L'unification des analyses entre tous ces fournisseurs demeure un défi.
Les plateformes futures offriront un suivi multi-fournisseurs transparent, permettant des comparaisons de coûts véritablement équitables et un routage intelligent entre les fournisseurs basé sur des données de prix et de performance en temps réel.
Défis courants de mise en œuvre
Les organisations rencontrent des obstacles prévisibles lors du déploiement de plateformes analytiques. Anticiper ces difficultés accélère la réussite de la mise en œuvre.
Attribution d'utilisation incomplète
Le suivi des coûts spécifiques générés par une équipe, une fonctionnalité ou un utilisateur nécessite une instrumentation à l'échelle des applications. De nombreuses organisations enregistrent initialement l'utilisation globale, mais manquent d'une attribution granulaire.
Solution : mettre en œuvre des normes d’étiquetage cohérentes dès le départ. Ajouter des métadonnées à chaque requête LLM identifiant l’application source, le type d’utilisateur et la catégorie de fonctionnalité.
Alerte Fatigue
Des alertes de coûts trop sensibles incitent les équipes à ignorer les notifications. Si chaque petite augmentation de consommation déclenche une alarme, les avertissements importants finissent par être noyés dans le bruit.
Solution : définir des seuils d’alerte basés sur la signification statistique plutôt que sur les variations absolues. Une augmentation du coût 10% pourrait justifier une enquête si elle se maintient pendant plusieurs jours, mais pas si elle ne dure qu’une heure.
Paralysie de l'analyse d'optimisation
Certaines équipes consacrent plus de temps à analyser les opportunités d'optimisation qu'à les mettre en œuvre. Un examen approfondi de chaque amélioration potentielle devient contre-productif.
Solution : appliquez la règle des 80/20. Concentrez-vous d’abord sur les optimisations à fort impact, généralement la mise en cache pour les tâches répétitives et la sélection de modèles pour les points de terminaison à fort volume. Les optimisations mineures peuvent attendre.
Questions fréquemment posées
Dans quelle mesure les organisations peuvent-elles concrètement réduire leurs coûts LLM grâce aux outils d'analyse ?
La réduction des coûts varie considérablement en fonction de l'efficacité initiale et des caractéristiques de la charge de travail. Les organisations effectuant des requêtes répétitives et ne disposant d'aucun système de cache existant peuvent réaliser des économies de 50 à 70 TP3T grâce à la mise en cache rapide. Celles qui appliquent déjà des optimisations de base constatent généralement des économies supplémentaires de 20 à 40 TP3T grâce à une sélection stratégique des modèles et à l'optimisation du contexte. L'essentiel est d'identifier les gaspillages de ressources au sein de votre déploiement spécifique ; les plateformes analytiques excellent dans la mise en évidence de ces opportunités.
Les plateformes d'analyse fonctionnent-elles avec tous les fournisseurs de LLM ?
La plupart des plateformes d'analyse spécialisées prennent en charge les principaux fournisseurs commerciaux, tels qu'OpenAI, Anthropic, Google et AWS Bedrock, via des intégrations API standard. Les solutions natives du cloud fonctionnent généralement uniquement au sein de leurs écosystèmes respectifs : les outils AWS pour Bedrock et les outils Google pour Vertex AI. Pour les modèles auto-hébergés ou les fournisseurs plus petits, la compatibilité dépend des capacités d'intégration personnalisées offertes par la plateforme et de la nécessité d'une instrumentation spécifique.
Quel est le calendrier de mise en œuvre typique pour l'analyse LLM ?
L'intégration analytique de base prend 1 à 2 semaines pour les plateformes cloud utilisant les SDK standard. Cela inclut la configuration initiale, l'implémentation du balisage de base et la configuration du tableau de bord. Un déploiement complet avec suivi des sessions, attribution personnalisée et automatisation de l'optimisation nécessite 4 à 8 semaines selon la complexité de l'application. Les organisations disposant de systèmes distribués ou d'implémentations LLM personnalisées doivent prévoir 2 à 3 mois pour un déploiement complet, incluant les tests et les améliorations.
Les petites équipes devraient-elles investir dans des plateformes d'analyse dédiées ?
Les équipes dont les dépenses mensuelles en LLM sont inférieures à $5 000 peuvent souvent gérer leurs coûts de manière satisfaisante grâce aux outils natifs de base des fournisseurs de cloud et à une surveillance manuelle. À cette échelle, la complexité et le coût des plateformes dédiées peuvent s'avérer disproportionnés par rapport aux avantages. Dès que les dépenses mensuelles en LLM dépassent $10 000 à $15 000, les analyses spécialisées offrent généralement un retour sur investissement positif grâce à l'optimisation automatisée et à une visibilité détaillée. Calculez vos économies potentielles : si les réductions de coûts réalistes dépassent d'au moins trois fois le coût de l'abonnement à la plateforme, l'investissement est justifié.
Comment les outils d'analyse gèrent-ils la limitation du débit et la gestion des quotas ?
Les plateformes avancées intègrent des fonctionnalités de limitation de débit personnalisées qui empêchent les applications de dépasser les seuils d'utilisation configurés. Ces systèmes interceptent les requêtes avant qu'elles n'atteignent les fournisseurs LLM, en rejetant ou en mettant en file d'attente le trafic excédentaire selon des politiques définies. La limitation de débit permet d'éviter les dépassements de coûts et l'épuisement des quotas d'API des fournisseurs. Certaines plateformes mettent en œuvre une gestion intelligente des files d'attente qui priorise les requêtes à forte valeur ajoutée en période de capacité réduite.
Les plateformes analytiques peuvent-elles réduire la latence tout en réduisant les coûts ?
Oui, de nombreuses optimisations de coûts améliorent simultanément les temps de réponse. La mise en cache offre les gains de latence les plus spectaculaires, réduisant le temps de réponse jusqu'à 851 TP3T pour les requêtes mises en cache, selon une étude AWS. Des modèles plus petits et plus rapides, sélectionnés pour les tâches appropriées, répondent souvent plus vite que des modèles de pointe surdimensionnés, tout en étant moins coûteux. L'optimisation du contexte réduit à la fois les coûts de traitement des jetons et le temps nécessaire au traitement des entrées inutilement volumineuses. Les meilleures plateformes analytiques mettent en évidence les opportunités où les gains de coûts et de performances convergent.
Quels sont les indicateurs les plus importants pour la gestion des coûts des programmes LLM ?
Quatre indicateurs clés constituent le socle d'une gestion efficace des coûts : les dépenses mensuelles totales permettent de suivre l'impact budgétaire global ; le coût par interaction utilisateur révèle la rentabilité unitaire des différentes fonctionnalités ; le ratio jetons d'entrée/sortie identifie les schémas de réponse coûteux ; et le taux d'accès au cache mesure l'efficacité de la mise en cache pour réduire les traitements redondants. Ensemble, ces indicateurs permettent aux équipes de comprendre à la fois les coûts globaux et les opportunités d'optimisation spécifiques. Les équipes les plus avancées ajoutent la précision de la sélection des modèles, en surveillant la fréquence à laquelle les modèles les moins coûteux maintiennent les seuils de qualité.
Conclusion
Les outils d'analyse LLM dotés de fonctionnalités robustes d'optimisation des coûts sont passés du statut de solutions de surveillance appréciables à celui d'infrastructures essentielles pour toute organisation déployant l'IA à grande échelle. L'association du suivi des coûts en temps réel, de l'observabilité des performances et des capacités d'optimisation automatisées offre un retour sur investissement immédiat aux équipes investissant des sommes importantes dans les API de modèles de langage.
En résumé ? Les organisations peuvent réduire leurs coûts LLM de 20 % grâce à une optimisation systématique facilitée par des analyses pertinentes, sans compromettre la qualité des réponses ni la fonctionnalité. Cependant, la réussite ne se limite pas à l’installation d’un tableau de bord. Une gestion efficace des coûts exige des indicateurs de référence clairs, des objectifs d’optimisation réalistes, une mise en œuvre progressive et un suivi continu.
Les recherches menées par le MIT, Carnegie Mellon et des entreprises leaders en IA démontrent systématiquement que la combinaison d'une sélection stratégique des modèles, d'une mise en cache intelligente, d'une optimisation du contexte et d'un routage automatisé génère des avantages cumulatifs. Les équipes qui considèrent l'optimisation des coûts comme une démarche continue plutôt que comme un projet ponctuel parviennent à des réductions durables tout en conservant la flexibilité nécessaire pour adopter de nouveaux modèles et fonctionnalités à mesure qu'ils émergent.
L'écosystème des plateformes analytiques propose des solutions pour chaque scénario de déploiement : des outils natifs du cloud intégrés aux principaux fournisseurs aux plateformes d'observabilité spécialisées prenant en charge les environnements multi-fournisseurs, en passant par les alternatives open source pour les besoins spécifiques. Le choix de la plateforme adéquate dépend de l'architecture de déploiement, des contraintes budgétaires et du niveau d'optimisation souhaité.
Commencez par établir vos coûts et habitudes d'utilisation actuels. Identifiez les opportunités d'optimisation les plus pertinentes pour votre charge de travail. Choisissez des outils d'analyse qui fournissent des informations exploitables plutôt que de submerger les équipes de données brutes. Mettez en œuvre les optimisations progressivement, mesurez les résultats et itérez en vous basant sur les données plutôt que sur des suppositions.
Les organisations qui excellent dans la gestion des coûts des modèles de langage partagent un point commun : elles instrumentent de manière exhaustive, analysent en continu et optimisent systématiquement. À mesure que les modèles de langage gagnent en performance et se généralisent, cette discipline permet de distinguer les déploiements d’IA durables des expérimentations coûteuses qui n’atteignent jamais une échelle de production.
Prêt à optimiser vos coûts LLM ? Commencez par la mesure : on ne peut améliorer ce qu’on ne suit pas. Choisissez une plateforme analytique adaptée à votre infrastructure, mettez en place un suivi basique et laissez les données révéler les gaspillages de ressources au sein de votre déploiement. Les enseignements tirés vous surprendront et les économies réalisées justifieront vos efforts.