Points clés : Le coût du réglage fin des modèles linéaires à longue portée (LLM) varie généralement de $300 à plus de $12 000, selon la taille du modèle, la technique utilisée et l'infrastructure. Les petits modèles (2 à 3 milliards de paramètres) avec LoRA coûtent entre $300 et $700, tandis que les modèles plus importants (7 milliards de paramètres) coûtent entre $1 000 et $3 000 avec LoRA, voire jusqu'à $12 000 pour un réglage fin complet. Les coûts cachés, tels que la préparation des données, le stockage, la surcharge de calcul et la maintenance continue, peuvent doubler les estimations initiales.
Le coût se fait sentir différemment lorsqu'il s'agit d'optimiser des modèles de langage complexes. Ce qui commence comme un projet d'IA prometteur se transforme rapidement en un sujet de discussion budgétaire qui inquiète les directeurs financiers.
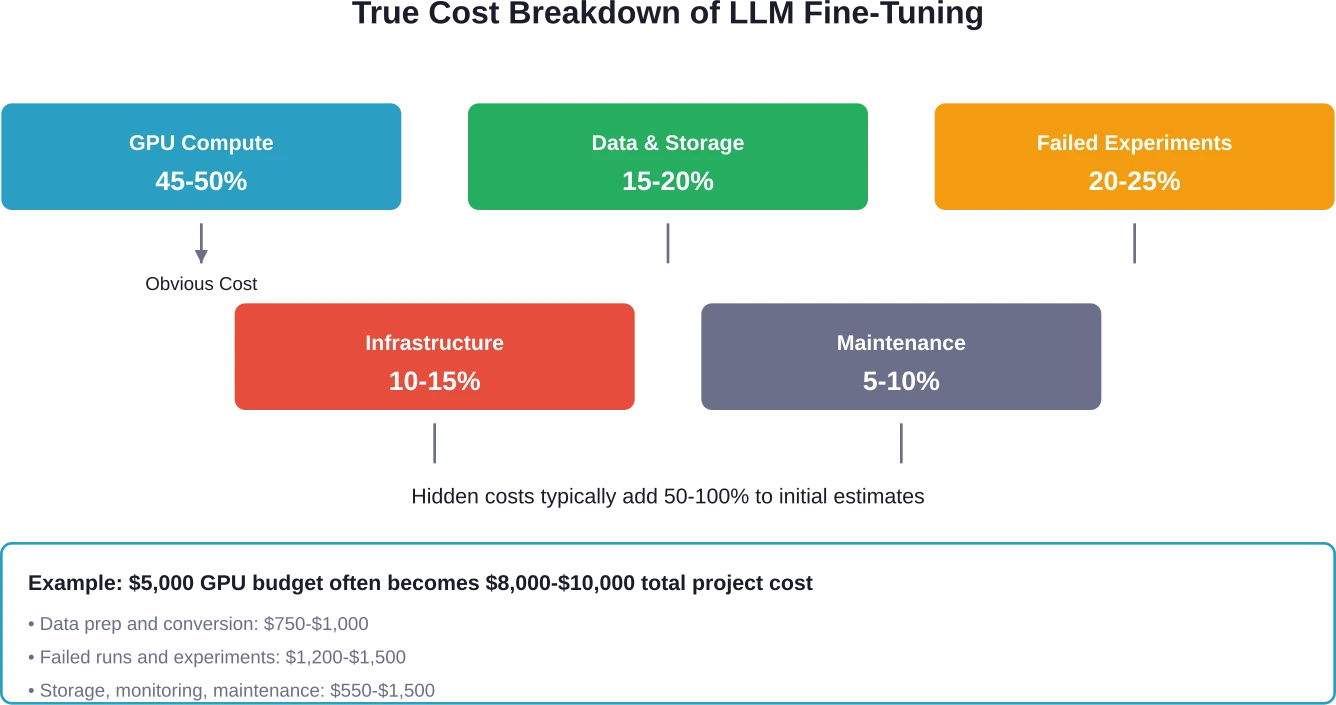
Les coûts de réglage fin ne se limitent pas aux heures de calcul GPU. Les dépenses réelles incluent la préparation des données, leur stockage, les expériences infructueuses et les frais d'infrastructure souvent imprévus. Les discussions au sein de la communauté révèlent que des tâches de réglage fin simples peuvent coûter entre $3 000 et $10 000, sans compter les coûts cachés.
Voici les principaux facteurs qui engendrent ces coûts et comment les maîtriser.
Analyse détaillée des coûts réels de mise au point
La taille du modèle a une importance plus grande que la plupart des équipes ne le pensent. Le nombre de paramètres influe directement sur les besoins de calcul et, en fin de compte, sur la facture.
D'après les données disponibles, voici le coût réel des différents modèles :
| Taille du modèle | Méthode de réglage fin | Fourchette de coûts typique | Temps d'entraînement |
|---|---|---|---|
| Phi-2 (paramètres 2,7B) | LoRA | $300 – $700 | Plusieurs heures |
| Mistral 7B | LoRA | $1 000 – $3 000 | 6 à 12 heures |
| Mistral 7B | Réglage fin complet | Jusqu'à $12 000 | 24 à 48 heures |
| Lama 2 7B | LoRA | $1 200 – $3 500 | 8 à 16 heures |
La technique employée est tout aussi importante que la taille du modèle. L'adaptation de faible rang (LoRA) réduit considérablement les coûts en mettant à jour uniquement un petit sous-ensemble de paramètres au lieu du modèle entier. Les méthodes LoRA ont permis d'obtenir un gain de précision moyen de 361 TP3T par rapport aux modèles de référence, selon des tests comparatifs sur des jeux de données financières, tout en maintenant des coûts maîtrisables.
Mais ces chiffres ne racontent qu'une partie de l'histoire.

Obtenez une ventilation claire des coûts de mise au point de votre LLM auprès d'AI Superior
Les coûts de mise au point du LLM varient en fonction de la taille de l'ensemble de données, du choix du modèle, de l'infrastructure et des exigences d'évaluation. IA supérieure aide les organisations à évaluer si un réglage fin est nécessaire ou si des solutions d'ingénierie rapide ou basées sur la récupération sont plus rentables.
Leur approche comprend :
- stratégie d'évaluation et de préparation des données
- Configuration du pipeline de sélection et d'entraînement des modèles
- Évaluation et analyse comparative des performances
- Configuration du déploiement et de la surveillance
Si vous envisagez de perfectionner votre LLM, consultez IA supérieure pour une analyse coûts-avantages alignée sur votre retour sur investissement attendu.
Les dépenses cachées dont personne ne vous avertit
Le prix affiché pour le temps GPU ne représente peut-être que la moitié du coût réel. Le reste apparaît à des postes non prévus au budget initial par les équipes.
Préparation et stockage des données
Les données brutes ne permettent pas un réglage fin. La conversion des jeux de données au format approprié (généralement JSONL pour la plupart des plateformes) exige du temps de développement. Les membres de la communauté travaillant avec 400 000 exemples d'entraînement et 2 000 exemples de test signalent une surcharge de prétraitement importante.
Les coûts de stockage s'accumulent rapidement. Les jeux de données d'entraînement, les jeux de validation, les points de contrôle du modèle et les multiples versions expérimentales nécessitent tous de l'espace de stockage. AWS et les fournisseurs de cloud facturent cela séparément, et le coût total s'accumule au fil des mois.
Expériences infructueuses et itération
La première phase de mise au point donne rarement des résultats exploitables en production. Les équipes itèrent sur les hyperparamètres, la qualité des données et les méthodes d'entraînement. Chaque itération a un coût.
Les recherches sur l'efficacité des données montrent qu'un réglage fin tenant compte de la complexité permet d'obtenir la même précision avec seulement 111 TP3T de données originales et surpasse les autres méthodes de 4,71 TP3T en moyenne. Cependant, la découverte de cette approche optimale nécessite des expérimentations, et les essais infructueux sont tout aussi coûteux que les essais réussis.
Frais généraux d'infrastructure
L'auto-hébergement engendre des coûts supplémentaires au-delà de la simple puissance de calcul. Les clusters multi-GPU, le réseau, la surveillance et la maintenance nécessitent tous des ressources. Les nœuds GPU de base coûtent au minimum $2 500 par mois, et la sous-utilisation représente un gaspillage d'argent lié à du matériel inutilisé.
Optimisation d'OpenAI : Tarification basée sur les API
OpenAI propose un paramétrage fin sous forme de service géré, facturé au jeton plutôt qu'à l'infrastructure. Ce modèle de facturation diffère sensiblement des approches auto-hébergées.
Le coût de l'entraînement est calculé en multipliant le nombre de jetons par le nombre d'époques. Pour GPT-3.5-turbo, un ensemble d'entraînement classique contenant environ 90 000 à 100 000 jetons coûte plusieurs centaines de dollars pour un réglage fin complet. L'utilisation d'ensembles de validation entraîne des frais supplémentaires.
Mais c'est là que ça se complique. L'API estime à l'avance la consommation maximale de jetons, y compris les jetons d'image et la surcharge liée aux appels de fonction. Les images peuvent consommer jusqu'à 1 105 jetons pour une résolution standard et 36 835 jetons pour les entrées haute résolution par époque — des coûts qui surprennent les développeurs qui ne lisent pas les détails.
L'optimisation par renforcement (RFT) pour les modèles de raisonnement utilise une approche de facturation totalement différente. Au lieu d'une tarification au jeton, la RFT facture en fonction du temps passé à effectuer les tâches d'apprentissage automatique essentielles. La facturation dépend des paramètres de `compute_multiplier`, de la fréquence de validation et du modèle de notation sélectionné.
Coûts d'AWS et des plateformes cloud
Amazon Bedrock et SageMaker proposent un paramétrage fin géré avec une tarification à l'usage. Les coûts varient selon le fournisseur du modèle, la modalité et le type d'instance.
Le prix de SageMaker dépend de l'instance choisie. L'instance ml.g5.12xlarge, couramment utilisée pour l'optimisation de 7 milliards de modèles, consomme environ $7 à $8 unités de ressources par heure. Une tâche d'optimisation classique d'une durée de 8 à 12 heures coûte entre $60 et $100 unités de ressources de calcul.
Le prix d'Amazon Bedrock varie considérablement selon le modèle. Les modèles Titan, les variantes Claude et les modèles Llama ont chacun leurs propres grilles tarifaires. L'optimisation des modèles intégrant des fonctionnalités coûte généralement moins cher que celle des modèles génératifs.
Le stockage sur AWS engendre des coûts supplémentaires. Le stockage S3 pour les ensembles de données, les artefacts de modèles et les points de contrôle, ainsi que les volumes EBS pour les instances, accumulent des frais. Pour un projet comptant 1 000 utilisateurs effectuant 10 requêtes par jour avec 2 000 jetons d'entrée et 1 000 jetons de sortie, les coûts de stockage et de transfert de données peuvent, à terme, dépasser les coûts de calcul.
Le choix entre l'auto-hébergement et le cloud
L'auto-hébergement semble coûteux au départ, mais peut s'avérer plus économique à grande échelle. Le cloud paraît bon marché initialement, mais les coûts s'accumulent avec le temps.
| Facteur | Auto-hébergé | Cloud/API |
|---|---|---|
| Investissement initial | Élevé ($5 000-$15 000) | Aucun |
| Coût d'exploitation mensuel | Électricité uniquement (~$100-$300) | $500-$5,000+ |
| Évolutivité | Limité par le matériel | Essentiellement illimité |
| Charge d'entretien | Haut (équipe interne) | Aucun |
| Protection des données | Contrôle total | Dépend du fournisseur |
| Seuil de rentabilité | 3 à 6 mois | N / A |
Une RTX 4090 coûte 1 600 TP4T à l'achat, contre 2 500 TP4T par mois pour les GPU en mode cloud. Le matériel est rentabilisé en quelques semaines pour les équipes ayant une charge de travail constante.
Mais le cloud est pertinent pour l'expérimentation et les charges de travail variables. Lancer une tâche d'ajustement rapide à la demande est plus avantageux que de maintenir du matériel inactif.
Stratégies de réduction des coûts qui fonctionnent réellement
Réduire les coûts de mise au point ne signifie pas sacrifier les résultats. Plusieurs techniques éprouvées permettent de réduire considérablement les dépenses.
Utilisez LoRA au lieu d'un réglage fin complet
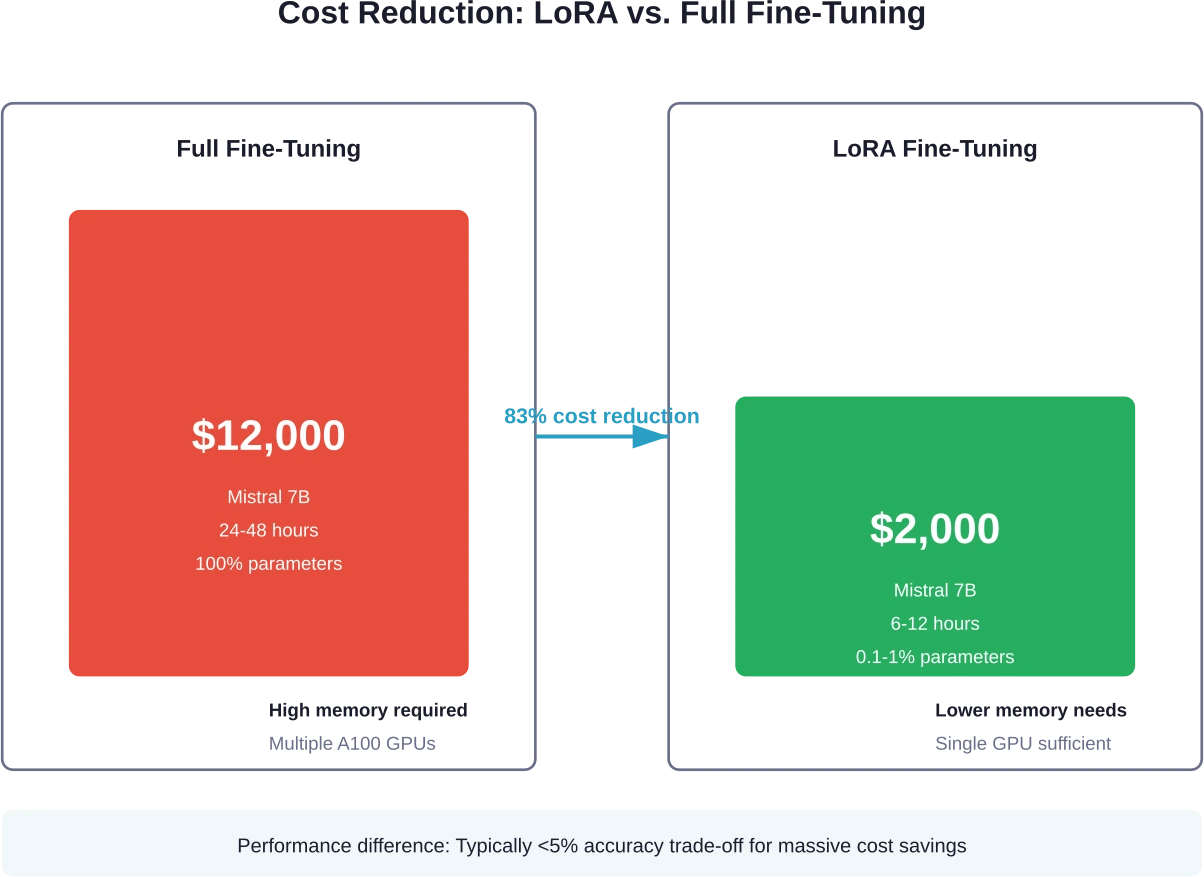
LoRA obtient des résultats comparables en ne mettant à jour que 0,1 à 11 TP3T des paramètres du modèle. La réduction du nombre de paramètres entraînables se traduit directement par des besoins de calcul moindres et des temps d'entraînement plus rapides.
Les méthodes LoRA coûtent environ 4 à 10 fois moins cher qu'un réglage fin complet pour un même modèle. Un Mistral 7B équipé de LoRA effectue entre $1 000 et $3 000 opérations contre $12 000 pour un réglage fin complet : même modèle, coût radicalement différent.
Exploiter la puissance de calcul hors pointe
Certains fournisseurs proposent des instances ponctuelles ou des tarifs hors pointe. Les discussions au sein de la communauté font état d'un intérêt pour des options de réglage plus économiques, certains évoquant des réductions potentielles du coût du 70% grâce à diverses approches d'optimisation.
Privilégier la qualité des données à la quantité
Plus de données d'entraînement ne signifient pas toujours de meilleurs résultats. Les recherches sur l'ajustement fin tenant compte de la complexité démontrent qu'une sélection ciblée des données permet d'obtenir la même précision avec 111 000 téléchargements de données originales.
La sélection d'exemples de haute qualité permet de réduire le nombre de jetons et le temps d'entraînement. Au lieu d'utiliser un million de jetons, 100 000 jetons soigneusement sélectionnés donnent souvent d'aussi bons résultats, pour un coût 10% inférieur.
Choix judicieux des hyperparamètres
Des taux d'apprentissage élevés et un nombre réduit d'époques diminuent le temps d'entraînement sans nécessairement nuire aux performances. Trouver le juste équilibre demande quelques essais, mais les gains sont rapidement significatifs.
La fréquence de validation est également importante. La réduire (par exemple, toutes les 100 étapes au lieu de toutes les 10) diminue proportionnellement les coûts de calcul. Pour l'optimisation du renforcement, choisir des modèles de correction efficaces et éviter les validations excessives permet de réduire directement les coûts.
Quand le réglage fin est financièrement judicieux
Tous les cas d'utilisation ne justifient pas un ajustement précis des coûts. La rentabilité doit être assurée.
Un réglage fin est judicieux lorsque :
- La précision spécifique au domaine importe plus que le coût. Les applications médicales, juridiques ou financières où les erreurs ont des conséquences réelles justifient l'investissement.
- Le volume d'appels API les rend coûteux. Les applications à haut débit traitant des millions de jetons par mois trouvent souvent qu'un réglage fin est moins coûteux que des appels API répétés.
- La protection des données nécessite un contrôle local. Les données sensibles qui ne peuvent pas sortir des limites de l'infrastructure nécessitent des modèles auto-hébergés et finement paramétrés.
- Des formats ou des sorties spécifiques sont requis. Lorsque les incitations seules ne permettent pas d'obtenir la structure de sortie souhaitée ou la cohérence du comportement.
Le réglage fin n'a pas de sens lorsque :
- Une ingénierie rapide permet d'obtenir des résultats similaires. Les fenêtres contextuelles prennent désormais en charge de 200 000 à 1 million de jetons. De nombreuses tâches fonctionnent correctement grâce à des invites système complètes.
- Les modèles évoluent plus vite que les cycles de déploiement. Des modèles améliorés sortent tous les 4 à 6 mois. Les réglages du Mistral 4B deviennent obsolètes dès la sortie du Qwen ou du Llama 3 quelques semaines plus tard.
- Le volume ne justifie pas le coût initial. Les applications à faible trafic qui paient $100/mois en frais d'API ne peuvent pas justifier $5 000 en coûts de réglage fin.
Le calcul se résume à une analyse du seuil de rentabilité. Si l'optimisation coûte $8 000 et permet d'économiser $500 par mois en frais d'API, le retour sur investissement est de 16 mois. C'est acceptable pour les applications stables et pérennes. En revanche, c'est catastrophique pour les projets expérimentaux ou les cas d'utilisation en constante évolution.
L'économie du réglage fin du renforcement
Le réglage fin de l'apprentissage par renforcement introduit une dynamique de coûts différente. Contrairement au réglage fin supervisé facturé par jetons, le réglage fin par renforcement (RFT) facture le temps de calcul consacré aux tâches d'entraînement principales.
L'API RFT d'OpenAI facture en fonction de la durée d'entraînement, et non de la taille de l'ensemble de données. Les principaux facteurs de coût sont les suivants :
- Paramètres du multiplicateur de calcul qui contrôlent la vitesse d'entraînement
- Fréquence de validation et sélection du modèle d'évaluateur
- Durée de l'épisode et complexité de la tâche
Optimiser les coûts RFT signifie choisir le modèle de correcteur le plus petit répondant aux exigences de qualité, éviter les exécutions de validation excessives et maintenir l'efficacité du code d'évaluation personnalisé.
Les recherches sur l'optimisation des données pour l'apprentissage par renforcement montrent que la sélection ciblée des données en ligne et la réutilisation progressive permettent de réduire le temps d'entraînement de 231 à 621 itérations (TP3T) tout en maintenant les performances. Cela se traduit directement par des économies proportionnelles à la réduction du temps d'entraînement.
Suivi et gestion des coûts courants
Le réglage fin n'est pas une dépense ponctuelle. Les modèles dérivent, les données changent et un réentraînement devient nécessaire.
Le suivi des coûts par client ou projet permet une répartition transparente des dépenses. Pour les équipes gérant plusieurs clients via un compte unique, la récupération des détails des projets via l'API et le calcul des coûts à partir des jetons d'apprentissage et du type de modèle offrent un suivi approximatif.
L'établissement de limites strictes empêche les dépenses excessives. OpenAI et les fournisseurs de services cloud prennent en charge des plafonds de dépenses qui interrompent les tâches d'entraînement lorsque certains seuils sont atteints. Cela protège contre les tâches mal configurées qui consomment des milliers d'unités de temps GPU.
Le suivi des tableaux de bord est essentiel. Observer la progression de la formation permet de suspendre ou d'annuler les tâches peu performantes avant d'engendrer un gaspillage de ressources. La plupart des plateformes affichent des indicateurs en temps réel et les coûts cumulés.
Questions fréquemment posées
Combien coûte le réglage fin d'un modèle à 7 milliards de paramètres ?
L'optimisation d'un modèle 7B comme Mistral ou Llama coûte généralement entre $1 000 et $3 000 avec les techniques LoRA, et jusqu'à $12 000 pour une optimisation complète. Le coût exact dépend de la taille de l'ensemble de données, de la durée d'entraînement et du choix de l'infrastructure (cloud ou hébergement sur site).
LoRA est-il aussi efficace qu'un réglage fin complet ?
LoRA offre des performances comparables à un réglage fin complet pour la plupart des applications, avec une différence de précision généralement inférieure à 5%. LoRA met à jour seulement 0,1 à 1% de paramètres tout en fournissant des résultats similaires à un coût 4 à 10 fois inférieur et avec des temps d'apprentissage plus rapides.
Quels sont les coûts cachés du réglage fin du LLM ?
Les coûts cachés comprennent la préparation et la conversion des données (10 à 151 000 milliards de dollars du budget), les expériences et itérations infructueuses (20 à 251 000 milliards de dollars), le stockage des jeux de données et des points de contrôle (5 à 101 000 milliards de dollars), les frais d'infrastructure pour les configurations auto-hébergées (10 à 151 000 milliards de dollars) et la maintenance et le réentraînement continus (5 à 101 000 milliards de dollars). Ces coûts peuvent doubler les estimations initiales du coût du GPU.
Quand dois-je privilégier le réglage fin de l'API plutôt que l'auto-hébergement ?
L'optimisation des API est pertinente pour les charges de travail variables, l'expérimentation et les équipes sans infrastructure de ML. L'auto-hébergement devient rentable pour les charges de travail importantes et constantes, où un investissement matériel unique ($5 000 à $15 000) est amorti en 3 à 6 mois par rapport aux coûts continus du cloud.
Comment puis-je réduire les coûts de mise au point fine du 70% ?
Utilisez LoRa plutôt qu'un réglage fin complet, tirez parti des instances spot ou des tarifs de calcul hors pointe, optimisez la qualité des données pour réduire la taille de l'ensemble de données de 80 à 900 Tk, réduisez la fréquence de validation et choisissez des hyperparamètres efficaces pour raccourcir le temps d'entraînement. La combinaison de ces stratégies peut permettre de réduire les coûts de 700 Tk ou plus.
Le réglage fin est-il pertinent avec de grandes fenêtres de contexte ?
Les fenêtres de contexte étendues (200 000 à 1 million de jetons) réduisent souvent le besoin de réglages fins. Si une invite complète donne des résultats acceptables, elle est souvent moins coûteuse qu'un réglage fin. Ce dernier reste pertinent pour garantir un comportement cohérent, des formats de sortie spécifiques ou lorsque le nombre d'appels API répétés dépasse son coût.
À quelle fréquence les modèles finement réglés nécessitent-ils un réentraînement ?
La fréquence de réentraînement dépend de la dérive des données et du cycle de vie du modèle. Les modèles de production nécessitent généralement des mises à jour tous les 3 à 6 mois en raison des modifications des données sous-jacentes ou de la publication de modèles de base plus performants. Les applications critiques peuvent exiger un réentraînement mensuel, tandis que les domaines stables peuvent se contenter d'un cycle annuel.
Prendre la décision d'investissement
Les réglages précis ont un coût. La décision de procéder ne doit pas être prise à la légère.
Commencez par vérifier si un paramétrage fin est nécessaire. Testez d'abord un système d'invites étendu avec le modèle de base. De nombreuses équipes constatent que la configuration 90% de leur cas d'utilisation fonctionne sans paramétrage fin.
Calculez le coût total de possession, et pas seulement le coût horaire du GPU. Incluez la préparation des données, le budget d'expérimentation, le stockage et la maintenance. Ajoutez 50 à 100% aux estimations initiales pour tenir compte des coûts cachés.
Comparez cela aux coûts de l'API pour le volume prévu. Si les dépenses actuelles s'élèvent à $200 par mois et que les coûts d'optimisation sont de $8 000, le seuil de rentabilité est atteint en 40 mois. Ce calcul n'est pas valable pour la plupart des projets.
Tenez compte de la durée de vie des modèles. Optimiser un modèle qui sera obsolète dans quatre mois représente un gaspillage de ressources. L'évolution rapide des familles de modèles rend l'optimisation moins intéressante qu'il n'y paraît.
Mais lorsque l'expertise métier, la confidentialité des données ou les économies d'échelle le justifient, un paramétrage précis apporte une valeur ajoutée que les modèles génériques ne peuvent égaler. L'essentiel est d'effectuer une analyse rigoureuse des chiffres avant d'engager un budget.
Les équipes qui réussissent l'optimisation LLM la considèrent comme un investissement, et non comme un choix technique. Elles évaluent les coûts, définissent des objectifs de performance clairs et connaissent leur seuil de rentabilité avant même la mise en service du premier GPU.
Prêt à optimiser vos coûts de développement d'IA ? Commencez par mesurer précisément vos dépenses actuelles en API et projetez la croissance de ce volume. Cette base de référence déterminera si un ajustement fin est financièrement judicieux dans votre situation.