Résumé rapide : Les benchmarks de LLM mesurent les performances d'inférence selon des critères de débit, de latence et de rentabilité. Des outils comme MLPerf, vLLM et GuideLLM aident les organisations à évaluer les options de déploiement ; les petits modèles auto-hébergés (7 à 14 milliards de paramètres) coûtent de 95 à 991 TP3T de moins que les API commerciales, tout en conservant des performances comparables pour de nombreux cas d'utilisation.
Le coût du déploiement de modèles de langage complexes peut être déterminant pour la réussite d'un projet d'IA. Selon AWS et d'autres rapports du secteur, l'inférence consomme plus de 901 TP3 Tbps de la consommation électrique totale des modèles de langage en environnement de production. Il s'agit d'une dépense opérationnelle considérable qui exige une mesure précise.
L'évaluation des performances des services LLM ne se limite plus à la vitesse. La rentabilité est devenue la principale préoccupation des organisations qui déploient des applications d'IA à grande échelle. La question n'est plus de savoir si un modèle peut traiter les requêtes, mais s'il peut le faire de manière rentable.
Le problème, c'est que la plupart des équipes n'ont pas d'approche systématique pour mesurer simultanément la performance et les coûts. Elles optimisent un seul indicateur et voient leurs dépenses s'envoler.
Comprendre les critères de référence pour les LLM
Les benchmarks de performance mesurent le comportement des modèles linéaires logiques (LLM) dans des conditions spécifiques. Contrairement aux classements de qualité des modèles qui évaluent leur capacité de raisonnement, les benchmarks de déploiement se concentrent sur des indicateurs opérationnels : débit, latence, utilisation des ressources et, en fin de compte, coût par inférence.
La suite de benchmarks MLCommons MLPerf Inference constitue la norme du secteur pour la mesure des performances des charges de travail d'apprentissage automatique et d'intelligence artificielle. La version 5.1 de MLPerf Inference a introduit Llama3.1-8B comme modèle de référence, offrant une longueur de contexte de 128 000 jetons, reflétant les exigences réelles des entreprises.
Mais attendez… qu’est-ce qui compte réellement lors de l’analyse comparative ?
Indicateurs clés de performance
Le débit mesure le nombre de requêtes traitées par seconde. Un débit plus élevé signifie qu'un plus grand nombre d'utilisateurs peuvent être servis avec le même matériel. GuideLLM calcule des percentiles complets, incluant les percentiles 0,1, 1, 5, 10, 25, 75, 90, 95 et 99, pour le débit et d'autres indicateurs.
La latence mesure le temps de réponse. MLPerf définit des contraintes de latence spécifiques pour différents scénarios. Les scénarios à flux unique mesurent la latence au 90e percentile, tandis que les scénarios serveur visent des temps de réponse inférieurs à la seconde pour les applications interactives.
Le temps d'affichage du premier jeton (TTFT) est crucial pour l'expérience utilisateur. En clair : les utilisateurs remarquent lorsque les réponses mettent plus de 200 à 300 ms à apparaître. Cette métrique influe directement sur la réactivité perçue de l'application.
Le débit de génération de jetons diffère du débit de requêtes. Il mesure le nombre de jetons produits par seconde, ce qui est directement corrélé à la vitesse d'affichage pour l'utilisateur. Des recherches récentes sur l'inférence des modèles de langage de raisonnement montrent d'importantes fluctuations de mémoire lors de la génération de jetons, ce qui a un impact sur cette métrique.
Scénarios de référence standard
MLPerf définit quatre scénarios principaux. Chacun simule différents modèles d'application avec des caractéristiques de charge spécifiques.
| Scénario | Génération de requêtes | Contrainte de latence | Indicateur de performance |
|---|---|---|---|
| Flux unique | Requêtes séquentielles | 90e percentile | Latence de l'ile 90% |
| Flux multiples | lots à intervalle fixe | 99e percentile | Flux maximum |
| Serveur | distribution de Poisson | 99e percentile | Requêtes par seconde |
| Hors ligne | Toutes les requêtes simultanément | Aucun | débit total |
Les scénarios serveur simulent les charges de l'API en production avec des requêtes distribuées selon une loi de Poisson. Ce modèle reflète le comportement réaliste des utilisateurs, où les requêtes arrivent de manière aléatoire plutôt qu'à intervalles fixes.
Mesure des coûts d'inférence LLM
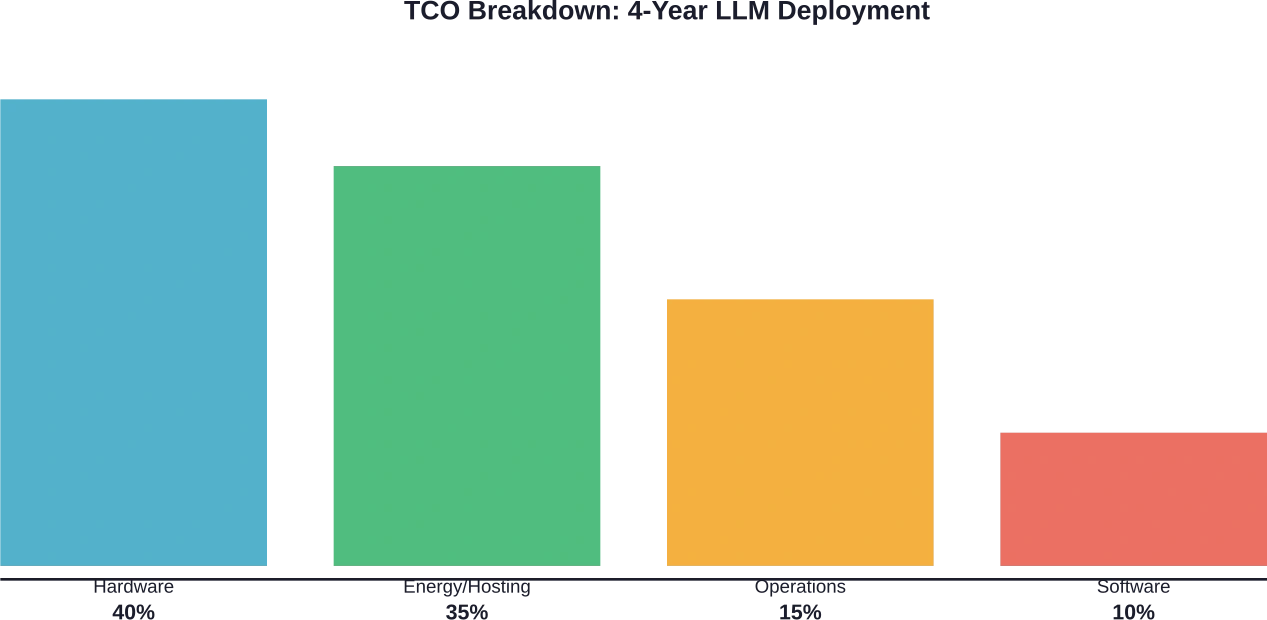
L'analyse des coûts nécessite la prise en compte des dépenses directes et indirectes. L'amortissement du matériel, la consommation d'énergie, les frais d'hébergement et les frais généraux d'exploitation contribuent tous au coût total de possession.
D'après le cadre d'analyse économique de l'inférence de l'équipe WiNGPT, l'inférence LLM doit être considérée comme une production intelligente pilotée par le calcul. Le GPU A800 80G, par exemple, a un coût horaire de base d'environ $0,79, généralement compris entre $0,51 et $0,99 dans des conditions d'utilisation courantes.
Composantes du coût total de possession
Les coûts matériels commencent dès l'acquisition. Une configuration serveur avec 8 GPU peut coûter 1 400 000 € ou plus, selon le modèle de GPU. L'amortissement suit généralement un cycle de quatre ans pour les déploiements en entreprise.
Les coûts liés à la mise en service de l'infrastructure comprennent les frais d'hébergement, la consommation électrique, le refroidissement et l'espace rack. Ces dépenses opérationnelles s'accumulent avec le temps. Pour les déploiements cloud, le prix des instances varie considérablement selon le type de GPU et la région.
Les licences logicielles et la maintenance engendrent des coûts récurrents. Les frameworks open source comme vLLM suppriment les frais de licence, mais les solutions commerciales facturent par déploiement ou par jeton traité.
Comparaison des coûts : hébergement auto-hébergé vs. API
Les ratios de coûts révèlent des différences considérables entre les approches de déploiement. Une étude publiée par Fin AI démontre que les modèles plus petits permettent de réaliser des économies substantielles par rapport aux API commerciales.
| Modèle | Paramètres | Coût par rapport à GPT-4.1 | Coût par rapport à GPT-4.1 Mini | Coût par rapport au Sonnet 3.7 |
|---|---|---|---|---|
| Gemma 3 4B | 4B | 0.04 | 0.20 | 0.01 |
| DeepSeek Llama 8B | 8B | 0.05 | 0.27 | 0.01 |
| Qwen 3 14B | 14B | 0.05 | 0.27 | 0.01 |
| Gemma 3 27B | 27B | 0.34 | 1.71 | 0.08 |
| DeepSeek Llama 70B | 70B | 1.70 | 8.49 | 1.10 |
| Qwen 3 235B | 235B | 2.17 | 10.83 | 1.40 |
Les modèles plus petits, comportant moins de 14 milliards de paramètres, coûtent nettement moins cher que les modèles de type GPT-4, les recherches montrant des coûts de 0,04 à 0,05 fois inférieurs à ceux de GPT-4.1. C'est une révolution pour les applications à grand volume où les exigences de qualité permettent l'utilisation de modèles plus petits.
L'équipe d'ingénierie de Salesforce a constaté des économies annuelles de plus de 1 000 000 $ (TP4T500K) grâce au remplacement des dépendances LLM en production par un service de test pour les flux de travail de développement et d'évaluation des performances. Cette approche a permis d'éliminer la consommation de jetons pour les tests hors production tout en maintenant des capacités de validation de 16 000 requêtes par minute, avec une capacité de pointe dépassant les 24 000 requêtes par minute.
Outils et cadres d'analyse comparative
Plusieurs cadres de référence permettent d'établir des indicateurs de performance systématiques pour les services LLM. Chacun offre des fonctionnalités différentes pour mesurer la performance et l'efficacité des coûts.
Suite d'analyse comparative vLLM
Le projet vLLM intègre des outils d'analyse comparative pour la mesure du débit et de la latence. Il prend en charge divers jeux de données, notamment ShareGPT, BurstGPT et des données aléatoires synthétiques générées par des tokeniseurs de modèles.
Les principaux paramètres de référence de vLLM incluent les limites de concurrence maximales, les débits de requêtes et la sélection des jeux de données. Une concurrence maximale de 10 signifie que le serveur traite jusqu'à 10 requêtes simultanément, les requêtes supplémentaires étant mises en file d'attente jusqu'à ce que de la capacité se libère.
Les tests de performance de la version 0.7.3 de vLLM-ascend ont démontré les performances des modèles Qwen2.5-7B-Instruct et Qwen2.5-VL-7B-Instruct à des fréquences d'exécution (QPS) de 1, 4, 16 et infinies (illimitées). Les tests ont utilisé 200 invites échantillonnées aléatoirement à partir des jeux de données ShareGPT et vision-arena, avec des initialisations aléatoires fixes pour garantir la reproductibilité.
GuideLLM pour l'analyse comparative de la production
GuideLLM, du projet vLLM, est spécialisé dans l'évaluation des inférences en conditions réelles. Il simule différents modèles de trafic grâce à des profils de charge configurables.
Les tests de charge basés sur le débit prennent en charge des taux de requêtes constants. Un test à 10 requêtes par seconde pendant 20 secondes avec des données synthétiques (128 jetons d'invite et 256 jetons de sortie) fournit des mesures de débit de référence. L'outil calcule des distributions de percentiles complètes, incluant les percentiles 0,1, 1, 5, 10, 25, 50, 75, 90, 95, 99 et 99,9 pour chaque métrique.
Les profils de charge sont importants car différentes applications génèrent des profils de trafic différents. Les tests de charge en rafale révèlent le comportement du système lors de pics de charge soudains, tandis que les tests de charge soutenue mesurent les performances en régime permanent.
Points de référence pour l'inférence MLPerf
MLPerf Inference constitue la norme de référence du secteur. La suite de tests de performance couvre les environnements de centres de données et mobiles avec des charges de travail standardisées dans les domaines de la vision, de la parole et du traitement du langage.
Pour les environnements de centre de données, MLPerf mesure le nombre de requêtes par seconde en respectant des contraintes de latence spécifiques. Les tests de performance côté serveur utilisent des modèles de requêtes distribués selon une loi de Poisson, avec une latence cible au 99e percentile. Les environnements hors ligne optimisent le débit sans contrainte de latence.
La version 5.1 de MLPerf Inference a introduit Llama3.1-8B, prenant en charge 128 000 contextes de jetons. Ce benchmark reflète les exigences modernes des entreprises en matière de compréhension et de génération de contextes longs.
Compromis entre coût et performances des GPU
Le choix du matériel a un impact considérable sur les performances et la rentabilité. Les recherches sur la rentabilité du service LLM sur des GPU hétérogènes révèlent que différents types de GPU correspondent à différentes caractéristiques de charge de travail.
| Type de GPU | FLOPS FP16 de pointe | Bande passante de la mémoire | Limite de mémoire | Prix par heure |
|---|---|---|---|---|
| A6000 | 91 TFLOPS | 768 Go/s | 48 Go | $0.83 |
| A40 | 150 TFLOPS | 696 Go/s | 48 Go | $0.55 |
| L40 | 181 TFLOPS | 864 Go/s | 48 Go | $1.15 |
Pour l'inférence LLM, la bande passante mémoire est souvent plus importante que la capacité de calcul. La génération de jetons est limitée par la mémoire, car elle implique le chargement répété des poids du modèle depuis la mémoire du GPU. Le processeur A6000 possède une bande passante mémoire de 768 Go/s, inférieure à celle du L40 (864 Go/s) et nettement inférieure à celle des processeurs H100 ou A100 (2 à 3 To/s).
Le déploiement hétérogène de GPU optimise le rapport coût-efficacité en adaptant les capacités des GPU aux caractéristiques des requêtes. Les requêtes gourmandes en calcul sont dirigées vers les GPU à haut rendement (FLOPS), tandis que les requêtes gourmandes en mémoire privilégient les options à large bande passante. Cette approche améliore l'utilisation des ressources pour différents types de requêtes.
Dimensions du modèle et exigences matérielles
Le nombre de paramètres détermine directement les besoins minimaux en mémoire. La précision FP16 nécessite environ 2 octets par paramètre, tandis que la quantification sur 4 bits réduit ce besoin à environ 0,5 octet par paramètre.

Les options de GPU dans le cloud varient considérablement en termes de capacités et de coûts. Les instances AWS g4dn.xlarge prennent en charge les charges de travail de base avec des GPU grand public. Les instances AWS g5.xlarge offrent de meilleures performances pour les modèles de 7 à 8 milliards de bits. Les modèles plus volumineux nécessitent des configurations multi-GPU ou des instances spécialisées à haute capacité de mémoire.
Optimisation de l'efficacité des coûts
L'optimisation des coûts exige un équilibre simultané de multiples facteurs. Les compromis entre performance, qualité et dépenses nécessitent une mesure et une itération systématiques.
Impact de la quantification
La quantification sur 4 bits réduit les besoins en mémoire et augmente le débit avec une dégradation minimale de la qualité. La plupart des applications tolèrent la quantification sans perte de performance notable. La quantification sur 4 bits réduit les besoins en mémoire d'environ 751 TPP3T par rapport à la précision FP16 tout en maintenant les gains de débit.
La quantification sur 8 bits offre un compromis, préservant mieux la qualité tout en réalisant des économies de mémoire modérées. Pour les applications exigeantes en termes de qualité, la quantification sur 8 bits représente un choix plus sûr que la quantification sur 4 bits, plus agressive.
Réglage de la taille des lots
Des lots plus importants améliorent l'utilisation et le débit du GPU. Le traitement simultané de 32 requêtes offre une meilleure efficacité matérielle que leur traitement séquentiel. Cependant, des lots plus importants augmentent la latence pour chaque requête.
Le traitement par lots dynamique optimise ce compromis en regroupant les requêtes arrivant dans un intervalle de temps donné. Lorsque les requêtes arrivent de manière sporadique, des lots plus petits permettent de maintenir une faible latence. En période de forte charge, le traitement par lots automatique maximise le débit.
Stratégies de routage des requêtes
L'acheminement intelligent des requêtes vers différents types de GPU améliore le rapport coût-efficacité. Les requêtes courtes avec des lots de petite taille sont acheminées vers des GPU optimisés pour le calcul. Les requêtes à contexte long nécessitent un accès mémoire important au matériel optimisé pour la bande passante.
L'équilibrage de charge entre les répliques évite les points chauds et améliore l'utilisation globale. Le routage à tour de rôle convient aux charges de travail homogènes, mais le routage prenant en compte les requêtes offre de meilleurs résultats pour les modèles de requêtes diversifiés.
Création d'un calculateur de coût total de possession (TCO)
Une estimation précise des coûts exige une comptabilisation systématique de tous les éléments de dépense. Les organisations ont besoin de visibilité sur les coûts réels par demande pour prendre des décisions éclairées en matière de déploiement.
Les coûts du matériel se divisent en acquisition et en amortissement. Un serveur à 8 GPU d'une valeur de $320 000 avec une période d'amortissement de 4 ans coûte $80 000 par an, soit environ $9,13 par heure en supposant un fonctionnement 24h/24 et 7j/7.
Les frais d'exploitation comprennent les coûts d'hébergement, la consommation d'énergie et la maintenance. Les déploiements dans le cloud simplifient ce calcul : le coût horaire de l'instance inclut la plupart des dépenses opérationnelles. Les déploiements auto-hébergés nécessitent un suivi distinct des coûts d'infrastructure, de la consommation d'énergie (généralement de 0,10 à 0,15 € par kWh) et des frais administratifs.
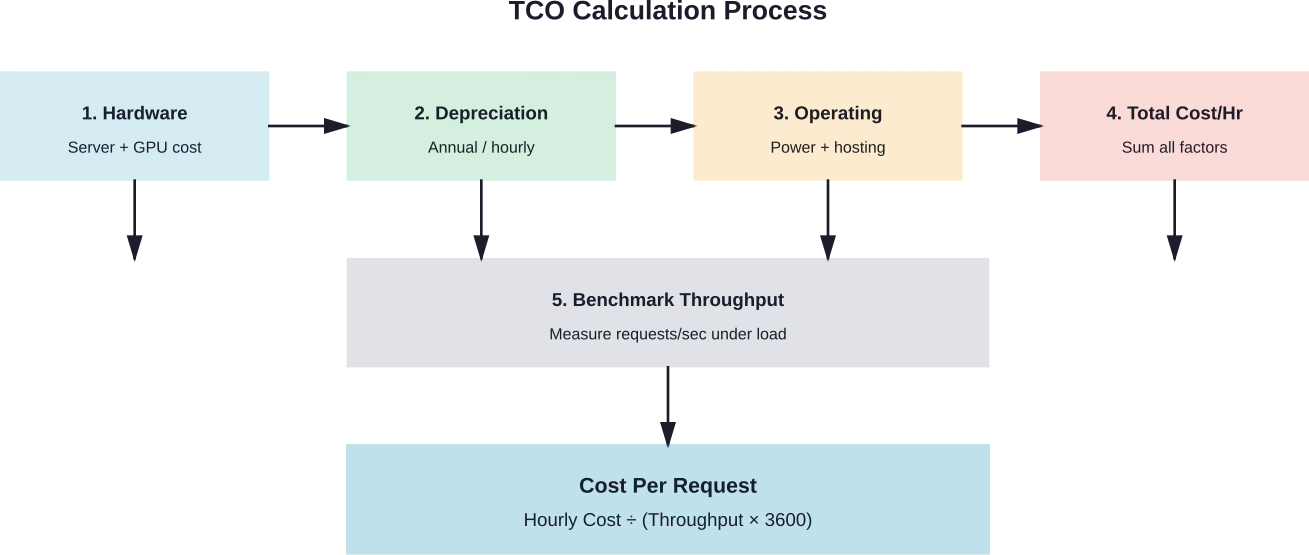
La formule du coût par requête combine les coûts horaires avec le débit mesuré :
Coût par requête = Coût horaire ÷ (Requêtes par seconde × 3 600)
Pour un déploiement coûtant $10 par heure qui traite 50 requêtes par seconde, le coût par requête est égal à $0,0000556 ou environ $0,056 pour 1 000 requêtes.

Réduisez les coûts de service des LLM grâce à une modélisation plus intelligente
Les tests de performance se concentrent souvent sur les jetons, les GPU et le prix de l'infrastructure. Mais les véritables différences de coûts proviennent généralement de la conception et du déploiement du modèle. IA supérieure Il travaille au niveau de l'ingénierie : création de LLM personnalisés, optimisation des pipelines d'entraînement et structuration des déploiements pour que les modèles fonctionnent efficacement en production.
Si vos tests de performance révèlent des coûts de service élevés, le problème peut provenir de l'architecture ou de la configuration d'inférence. Contactez-nous. IA supérieure pour examiner votre système LLM et identifier des moyens pratiques de réduire les coûts de service.
Flux de travail pratique d'analyse comparative
L'évaluation comparative systématique suit un processus reproductible. Le fait de commencer par des charges de travail représentatives garantit que les mesures reflètent les conditions de production.
Sélection de l'ensemble de données
ShareGPT propose des scénarios de conversation réalistes avec des messages de longueur et des exigences de réponse variées. L'ensemble de données contient des interactions utilisateur réelles, ce qui le rend précieux pour des tests en conditions de production. Un échantillonnage aléatoire de 200 à 500 messages avec une graine aléatoire fixe garantit des résultats reproductibles.
Les jeux de données synthétiques permettent de tester de manière contrôlée des scénarios spécifiques. La génération aléatoire de jetons crée des invites avec des distributions de longueur prédéterminées. Cette approche permet de tester des cas limites comme la longueur maximale du contexte ou des modèles de jetons inhabituels.
Configuration du modèle de charge
Les tests à débit constant mesurent les performances en régime permanent. Un fonctionnement à 10 requêtes par seconde pendant 60 secondes établit les caractéristiques de débit et de latence de référence. L'augmentation progressive du débit permet d'identifier la charge maximale admissible avant dégradation de la latence.
Les tests de charge révèlent le comportement du système face à des pics de trafic soudains. Le passage de 1 QPS à 100 QPS en 10 secondes, suivi de la mesure du temps de récupération, démontre la résilience du système. Les systèmes de production subissent fréquemment des pics de trafic lors des heures de pointe.
Analyse des résultats
Les distributions en percentiles révèlent les comportements aberrants que les moyennes masquent. Si une latence au 50e percentile peut être acceptable, les valeurs au 99e percentile indiquent une expérience utilisateur dans le pire des cas. GuideLLM calcule automatiquement les percentiles de 0,1% à 99,9% pour une analyse complète.
Une dégradation du débit sous charge soutenue indique une contention des ressources. Un débit stable pendant toute la durée du test démontre une mise à l'échelle correcte. Une baisse du débit suggère des fuites de mémoire, une limitation thermique ou d'autres problèmes systémiques.
Considérations relatives à l'énergie et à la puissance
La consommation d'énergie a un impact direct sur les coûts opérationnels et la durabilité environnementale. Une étude de TokenPowerBench souligne que, pour les systèmes de production traitant des milliards de requêtes par jour, la consommation d'énergie liée à l'inférence dépasse d'au moins dix fois les coûts d'entraînement.
Les données de référence de ML.ENERGY montrent que l'énergie est devenue une ressource critique et limitante. Dans de nombreuses régions, l'accès à une infrastructure électrique suffisante pour les parcs de GPU coûte plus cher et prend plus de temps que l'acquisition de matériel.
La mesure de la consommation électrique lors des tests de performance permet de visualiser les coûts. La consommation typique d'un GPU varie de 250 W pour les cartes optimisées en termes d'efficacité énergétique à 700 W pour les accélérateurs hautes performances. À $0,12 par kWh, un GPU de 400 W coûte environ $0,048 par heure rien que pour l'électricité.
En multipliant le coût de l'électricité par le nombre de GPU et en ajoutant les frais généraux d'exploitation, on obtient les dépenses énergétiques totales. Pour un serveur à 8 GPU consommant 3 200 W, plus les frais généraux, le coût énergétique s'élève à environ 1 TP4T0,40-0,50 par heure, selon les tarifs d'électricité locaux et l'efficacité du refroidissement.
Questions fréquemment posées
Quelle est la taille de modèle la plus rentable pour un déploiement en production ?
Les modèles comportant entre 7 et 14 milliards de paramètres offrent un excellent rapport coût-efficacité pour les applications d'entreprise. Une étude de Fin AI montre que ces modèles coûtent environ 0,05 fois moins cher que les modèles de la classe GPT-4, tout en conservant une qualité acceptable pour des tâches telles que le support client, la classification de contenu et l'extraction de données structurées. Les modèles plus petits, de 1 à 3 milliards de paramètres, conviennent aux tâches de classification simples, tandis que les modèles de plus de 70 milliards de paramètres sont à réserver aux applications exigeant une capacité de raisonnement maximale.
Comment la taille des lots influence-t-elle les coûts de service des LLM ?
Des lots plus importants optimisent l'utilisation du GPU et réduisent le coût par requête en traitant plusieurs requêtes simultanément. Doubler la taille des lots, de 8 à 16, augmente généralement le débit de 40 à 60 TP3T sans augmentation proportionnelle du coût du matériel. Cependant, la taille des lots accroît la latence des requêtes individuelles. Les stratégies de traitement par lots dynamiques permettent d'équilibrer ces compromis en ajustant la taille des lots en fonction de la charge, maximisant ainsi le débit lors des pics de demande tout en maintenant une faible latence en dehors de ces périodes.
Les organisations doivent-elles héberger elles-mêmes leurs programmes LLM ou utiliser des API commerciales ?
L'auto-hébergement des modèles de petite taille peut s'avérer rentable pour les déploiements à grande échelle, le seuil de rentabilité variant selon la taille du modèle et la configuration matérielle. En deçà de ce seuil, les prix des API commerciales restent compétitifs, compte tenu des coûts opérationnels. Les déploiements auto-hébergés peuvent générer des économies substantielles par rapport aux API commerciales, selon la taille du modèle et la configuration du déploiement. Les entreprises doivent également prendre en compte les compétences techniques requises, car l'auto-hébergement exige des capacités de gestion, de surveillance et d'optimisation des performances de l'infrastructure, des fonctions que les API commerciales prennent en charge automatiquement.
Quels sont les outils d'analyse comparative les plus performants pour mesurer les performances des services LLM ?
GuideLLM excelle dans l'évaluation comparative des performances en production réelle grâce à ses modèles de charge configurables et ses indicateurs complets. La suite d'évaluation comparative vLLM offre une excellente intégration pour les équipes utilisant déjà vLLM. MLPerf Inference propose des benchmarks standardisés et reconnus pour comparer différentes configurations matérielles et logicielles. Plusieurs outils d'évaluation comparative répondent à des besoins spécifiques : MLPerf pour les comparaisons standardisées, GuideLLM pour les modèles de production réels et les outils vLLM pour les tests intégrés au framework.
Quelle quantité de VRAM est nécessaire pour les différentes tailles de modèle ?
La précision FP16 requiert environ 2 octets par paramètre : les modèles 7 bits nécessitent 14 à 16 Go, les modèles 13 bits 26 à 28 Go et les modèles 70 bits 140 Go. La quantification sur 4 bits réduit les besoins de 751 TP3T : les modèles 7 bits fonctionnent sur 6 à 8 Go, les modèles 13 bits sur 10 à 12 Go et les modèles 70 bits sur 35 à 40 Go. Il faut ajouter 20 à 301 TP3T pour la surcharge liée au cache KV et à la mémoire d’activation. Un modèle 7 bits en quantification sur 4 bits fonctionne sans problème sur des GPU grand public dotés de 8 Go de VRAM, tandis que les modèles 70 bits requièrent des GPU professionnels avec plus de 40 Go de VRAM ou des configurations multi-GPU.
Qu’est-ce qui provoque la variabilité de la latence dans l’inférence LLM ?
Les limitations de la bande passante mémoire constituent le principal goulot d'étranglement en termes de latence. La génération de jetons sollicite constamment les poids du modèle depuis la mémoire GPU, ce qui rend l'inférence limitée par la mémoire plutôt que par la puissance de calcul. La mise en file d'attente des requêtes lors des pics de charge engendre des temps d'attente variables. La taille du cache clé-valeur augmente avec la longueur du contexte, accroissant la pression sur la mémoire et ralentissant le traitement des jetons suivants. Les recherches sur l'inférence de modèles de langages de raisonnement mettent en évidence d'importantes fluctuations de mémoire qui affectent la constance des performances. Le suivi de la latence au 99e percentile révèle ces variations avec une meilleure précision que les métriques moyennes.
Comment les déploiements hétérogènes de GPU améliorent-ils le rapport coût-efficacité ?
Les différents types de GPU excellent dans des domaines de charge de travail spécifiques. Les GPU à large bande passante, comme l'A6000 (768 Go/s), optimisent la génération de jetons nécessitant une grande quantité de mémoire, tandis que les GPU à haute puissance de calcul, comme l'A40 (150 TFLOPS), excellent dans les opérations gourmandes en calcul. Une étude publiée lors de la conférence ICML 2025 démontre que le routage des requêtes en fonction des besoins en calcul et en mémoire améliore l'utilisation des ressources au sein de parcs de GPU hétérogènes. Les déploiements de GPU hétérogènes permettent d'optimiser considérablement le rapport coût-efficacité par rapport aux approches homogènes, en adaptant les caractéristiques des requêtes aux types de GPU appropriés, plutôt qu'en surdimensionnant un seul type de GPU.
Conclusion
Les benchmarks LLM offrent une visibilité essentielle sur les compromis entre performance et coût qui déterminent la viabilité du déploiement. Les organisations qui mesurent systématiquement le débit, la latence et le coût total de possession prennent des décisions éclairées concernant l'auto-hébergement par rapport aux API commerciales, le choix de la taille du modèle et l'approvisionnement en matériel.
Les données révèlent des tendances claires. Les modèles plus petits, avec 7 à 14 milliards de paramètres, permettent de réaliser des économies de 95 à 991 TPE/3 par rapport aux modèles commerciaux de pointe, tout en maintenant une qualité acceptable pour de nombreuses applications d'entreprise. La rentabilité de l'auto-hébergement dépend du volume quotidien de jetons, des coûts matériels et des frais généraux d'exploitation propres à chaque organisation. La quantification sur 4 bits réduit les besoins en mémoire de 751 TPE/3 avec un impact minimal sur la qualité.
Mais voici le point essentiel : l’analyse comparative n’est pas une action ponctuelle. Les performances évoluent en fonction des mises à jour des modèles, des améliorations apportées aux infrastructures de diffusion et de l’évolution des charges de travail. Les organisations qui mettent en place des processus d’analyse comparative continue optimisent leurs coûts à mesure que leurs déploiements d’IA se développent.
Commencez par des charges de travail représentatives du trafic de production. Mesurez de manière exhaustive le débit, les percentiles de latence et l'utilisation des ressources. Calculez le coût total de possession (TCO) réel, incluant l'amortissement du matériel, la consommation d'énergie et les frais d'exploitation. Testez plusieurs configurations de déploiement afin d'identifier le compromis coût-performance optimal pour des cas d'utilisation spécifiques.
Les outils existent : MLPerf, vLLM, GuideLLM et d’autres offrent des capacités d’analyse comparative robustes. Leur efficacité est éprouvée par l’adoption dans l’industrie et la recherche universitaire. Il reste à appliquer systématiquement ces cadres aux exigences et contraintes spécifiques de chaque organisation. Analysez rigoureusement vos performances, optimisez en continu et constatez une maîtrise durable des coûts liés à la gestion du cycle de vie des services juridiques (LLM) à grande échelle.