Aperçu: L'entraînement d'un modèle de langage complexe comme GPT-4 coûte entre 1 400 000 et 192 000 milliards de dollars, dont 60 000 à 700 000 milliards de dollars en infrastructure de calcul. Ces coûts sont liés aux clusters de GPU, à la consommation d'électricité, à la préparation des données et aux compétences des ingénieurs. L'optimisation des modèles existants permet de réduire les dépenses de 60 000 à 900 000 milliards de dollars par rapport à un entraînement à partir de zéro.
Les grands modèles de langage ont transformé l'intelligence artificielle, passant du statut de curiosité de recherche à celui de puissance commerciale. Mais voici ce que la plupart des gens ignorent : le coût de création de ces systèmes rivalise avec celui du lancement de satellites dans l'espace.
D'après le rapport Stanford AI Index 2025, l'entraînement de GPT-4 était estimé entre $78 et 100 millions de dollars. Gemini Ultra 1.0 a fait grimper ce chiffre à $192 millions de dollars. Cela représente une augmentation de 287 000 fois par rapport aux $670 nécessaires pour entraîner un modèle Transformer en 2017.
Les enjeux économiques de ces chiffres ne se limitent pas à de simples curiosités académiques. Les organisations qui envisagent de développer des modèles sur mesure ou d'acquérir des licences pour des modèles existants ont besoin de données concrètes. Les équipes de recherche qui sollicitent des financements ont besoin de projections budgétaires réalistes. Et les observateurs du secteur qui suivent l'évolution de l'IA ont besoin de contexte pour comprendre la dynamique du marché.
Cette analyse examine où va chaque dollar dépensé lors de l'entraînement de modèles de langage de pointe, pourquoi les coûts augmentent si considérablement et quelles stratégies permettent réellement de réduire les dépenses sans sacrifier les performances.
Anatomie des coûts de formation LLM
Les coûts de formation ne se résument pas à un seul poste de dépense. De multiples catégories de dépenses s'accumulent pour atteindre ces totaux à huit et neuf chiffres.
L'infrastructure de calcul représente la part prépondérante du budget. Les fournisseurs de cloud facturent l'accès aux GPU à l'heure, et les entraînements s'étalent sur des semaines, voire des mois. OpenAI aurait dépensé plus de 100 millions de dollars pour l'entraînement de GPT-4, dont une part importante est consacrée aux coûts du cloud computing.
Les coûts matériels augmentent proportionnellement à la complexité du modèle. Les modèles plus volumineux requièrent des accélérateurs plus performants et en plus grand nombre. La différence entre l'entraînement d'un modèle à 20 milliards de paramètres et celui d'un modèle à 120 milliards de paramètres n'est pas linéaire. Les besoins en calcul croissent de façon exponentielle avec le nombre de paramètres.
Mais attendez. Le coût du matériel ne dit qu'une partie de l'histoire.
Les multiplicateurs cachés
La consommation d'électricité engendre des dépenses récurrentes souvent sous-estimées dans les budgets initiaux. En février 2026, Anthropic a annoncé son engagement à prendre en charge les hausses du prix de l'électricité pour ses centres de données, soulignant ainsi l'importance que les grands laboratoires d'IA accordent à cette problématique. L'entreprise a également indiqué que l'entraînement d'un seul modèle d'IA de pointe nécessitera bientôt des gigawatts, reconnaissant ainsi la charge que ces systèmes représentent pour l'infrastructure.
La préparation et le stockage des données ajoutent une étape supplémentaire. Les ensembles de données d'entraînement pour des modèles comme GPT-4 contiennent des centaines de milliards de jetons provenant de livres, de sites web, d'articles universitaires et de corpus spécialisés. L'acquisition, le nettoyage, le filtrage et le stockage de ces données nécessitent des équipes et une infrastructure dédiées.
Les ingénieurs de talent bénéficient de rémunérations exceptionnelles. Les chercheurs en apprentissage automatique et les ingénieurs d'infrastructure capables de gérer des entraînements sur des milliers de GPU sont très rares. Leurs salaires, primes et participations au capital représentent une part importante du coût total d'un projet.
Les itérations expérimentales multiplient les coûts initiaux. La recherche des hyperparamètres optimaux (taux d'apprentissage, tailles de lots, variations architecturales) nécessite de multiples entraînements. Chaque expérience infructueuse consomme des heures de calcul GPU sans produire le modèle final.

Infrastructure GPU : la dépense dominante
Les unités de traitement graphique (GPU) constituent l'épine dorsale de l'entraînement des IA modernes. Ces puces spécialisées excellent dans les opérations matricielles parallèles requises par les réseaux neuronaux.
NVIDIA domine le marché. Ses accélérateurs H100 et A100 alimentent la plupart des opérations d'entraînement à grande échelle. Les fournisseurs de cloud facturent environ $2-4 par heure de GPU H100. L'entraînement d'un modèle de pointe peut nécessiter entre 10 000 et 25 000 GPU fonctionnant pendant plusieurs semaines.
Le calcul devient vite impitoyable. À raison de $3 par heure de GPU, faire fonctionner 15 000 GPU pendant 30 jours consécutifs coûte $32,4 millions de dollars, rien que pour le temps de calcul. Et ce, sans compter le stockage, le réseau ni aucun autre composant d'infrastructure.
L'achat direct de matériel modifie la structure des coûts. Bien que les dépenses initiales soient plus élevées, éviter les coûts récurrents du cloud permet de réduire les dépenses globales à long terme. Les organisations qui prévoient plusieurs sessions de formation ou des opérations d'optimisation continue trouvent souvent l'achat plus économique que la location.
Le problème du temps d'inactivité
Le problème, c'est que les GPU ne sont pas productifs en permanence. Les goulots d'étranglement liés au chargement des données, la sauvegarde des points de contrôle et les pauses de débogage créent des périodes d'inactivité pendant lesquelles du matériel coûteux reste inutilisé, tout en générant des frais.
Une étude publiée sur arXiv et portant sur des frameworks d'entraînement LLM efficaces a révélé que, malgré une consommation énergétique maximale, les GPU fonctionnent souvent à des taux d'utilisation sous-optimaux (30%-50%) lors du pré-entraînement standard. Cette inefficacité provient de l'interaction entre les architectures de transformateurs et les capacités matérielles.
Des solutions existent. Des frameworks d'entraînement optimisés permettent d'améliorer l'utilisation du GPU en rationalisant les pipelines de données, en associant calculs et communications et en minimisant la surcharge de synchronisation. Ces améliorations ne se contentent pas d'accélérer l'entraînement ; elles réduisent directement le nombre total d'heures de calcul GPU nécessaires.
| Type de matériel | Coût horaire du cloud | Prix d'achat | Seuil de rentabilité |
|---|---|---|---|
| NVIDIA H100 | $2.50-$4.00 | $30,000-$40,000 | 10 000 à 16 000 heures |
| NVIDIA A100 | $1.50-$2.50 | $10,000-$15,000 | 6 000 à 10 000 heures |
| NVIDIA H200 | $3.50-$5.00 | $40,000-$50,000 | 11 000 à 14 000 heures |
Coûts de l'énergie : une préoccupation croissante
Les factures d'électricité pour les entraînements rivalisent avec le coût du matériel lui-même. Les modèles Frontier consomment des gigawattheures d'électricité, soit suffisamment pour alimenter des milliers de foyers pendant des mois.
L'efficacité énergétique est devenue un axe de recherche majeur. Les travaux publiés sur arXiv, portant sur l'optimisation énergétique des applications basées sur la technologie LLM, mettent l'accent sur la consommation d'énergie comme indicateur clé d'efficacité, au même titre que les mesures de performance traditionnelles. Des expériences menées sur une carte graphique NVIDIA RTX 8000 ont démontré que les approches optimisées atteignent une précision comparable aux performances de référence tout en réduisant la consommation d'énergie de 23 à 501 Tbit/s.
Soyons francs : les coûts énergétiques ne se limitent pas à la facture d’électricité immédiate. L’infrastructure nécessaire pour fournir des gigawatts d’électricité comprend des sous-stations, des systèmes de refroidissement et des générateurs de secours. Les exploitants de centres de données intègrent ces investissements dans leurs modèles de tarification.
Face à l'augmentation des besoins en formation, l'infrastructure énergétique devient un facteur de compétitivité majeur. Les organisations ayant accès à une électricité fiable et bon marché bénéficient d'avantages économiques considérables en matière de formation.
Formation à partir de zéro vs. perfectionnement
Tous les projets ne nécessitent pas la création d'un modèle à partir de zéro. L'optimisation de modèles pré-entraînés offre une alternative économique pour de nombreuses applications.
La situation économique change radicalement. L'optimisation d'un modèle comme Llama 2 ou GPT-3.5 sur des données spécifiques à un domaine peut coûter entre $50 000 et $50 000, selon la taille de l'ensemble de données et les besoins en calcul. C'est 1 000 à 10 000 fois moins cher que d'entraîner un modèle comparable à partir de zéro.
Des recherches publiées sur arXiv, portant sur des stratégies d'amélioration efficaces des modèles linéaires à faible rang (LLM), ont démontré que l'optimisation fine par des techniques telles que LoRA (Low-Rank Adaptation) peut être réalisée sur du matériel modeste. Une expérience a appliqué l'entraînement LoRA à un modèle pré-quantifié à 4 bits à l'aide d'un seul GPU NVIDIA T4 doté de 16 Go de VRAM, le processus s'achevant en 7 heures.
Cependant, le réglage fin présente des limites. Les modèles pré-entraînés comportent des biais et des lacunes de connaissances inhérents à leurs données d'entraînement initiales. Le réglage fin ajuste le comportement du modèle pour des tâches spécifiques, mais ne modifie pas fondamentalement ses connaissances ni ses capacités essentielles.
Quand une formation à partir de zéro est-elle judicieuse ?
Les organisations optent pour une formation complète pour plusieurs raisons. Les jeux de données propriétaires, non partageables avec les fournisseurs de modèles tiers, nécessitent une formation interne. Les domaines spécialisés où les modèles existants sont peu performants tirent profit d'architectures personnalisées, entraînées de A à Z sur des corpus pertinents.
La différenciation concurrentielle influence certaines décisions. Les entreprises qui développent des produits axés sur l'IA recherchent des modèles que leurs concurrents ne peuvent pas simplement reproduire en peaufinant des alternatives disponibles publiquement.
La maîtrise du comportement du modèle est essentielle. Un entraînement à partir de zéro offre une visibilité complète sur les sources de données, les procédures d'entraînement et les caractéristiques du modèle — un point crucial pour les industries réglementées ou les applications critiques pour la sécurité.


Estimez le coût de votre formation LLM
L'entraînement de grands modèles de langage (LLM) implique la curation des données, l'infrastructure, la budgétisation des calculs, l'expérimentation et l'évaluation. IA supérieure L'entreprise analyse vos données, vos objectifs et vos cibles de performance avant d'estimer les ressources et le temps nécessaires. Le détail des coûts inclut le prétraitement, les cycles d'entraînement, l'ajustement et la validation. Vous pouvez ainsi planifier vos dépenses de calcul et vos efforts d'ingénierie en amont.
Prêt à calculer votre investissement pour une formation LLM ?
Dialoguer avec une IA supérieure à :
- Évaluez votre ensemble de données et vos objectifs
- définir la stratégie de formation et les besoins informatiques
- recevoir une estimation structurée des coûts de formation LLM
👉 Demander un devis pour une formation LLM De l'IA supérieure.
Exemples de coûts concrets
Des modèles spécifiques fournissent des points de référence concrets pour comprendre l'économie de la formation.
Le coût de l'entraînement de GPT-4 est estimé entre $78 et 100 millions de dollars, selon le Wall Street Journal et le rapport Stanford AI Index 2025. Ce chiffre englobe l'infrastructure informatique, l'électricité, l'acquisition de données et les ressources d'ingénierie sur toute la période d'entraînement.
Gemini Ultra 1.0 a fait grimper les coûts à environ $192 millions selon le rapport Stanford AI Index 2025. Cette augmentation des dépenses reflète une plus grande échelle, une durée d'entraînement plus longue ou une expérimentation plus poussée pendant le développement.
L'entraînement de GPT-40 a nécessité environ 100 millions d'itérations. Ces modèles de pointe issus de grands laboratoires présentent des structures de coûts similaires : des budgets à huit ou neuf chiffres dominés par la puissance de calcul et la consommation d'énergie des GPU.
Les petites structures sont confrontées à des contraintes économiques différentes. L'entraînement d'un modèle à 7 milliards de paramètres peut coûter entre 1 400 000 et 2 400 000 £, selon l'accès au matériel et son efficacité. Un modèle à 20 milliards de paramètres pourrait coûter entre 1 400 000 et 2 400 000 £. Ces chiffres restent conséquents, mais sont à la portée des jeunes entreprises bien financées ou des équipes de recherche en entreprise.
La trajectoire de l'inflation des prix
Les coûts de formation ont connu une augmentation exponentielle. Le rapport Stanford AI Index 2025 a documenté une augmentation de 287 000 fois entre 2017 et aujourd’hui, passant de $670 pour les premiers modèles Transformer à neuf chiffres pour les systèmes de pointe actuels.
Cette tendance ne montre aucun signe d'inversion. Les modèles continuent de croître en nombre de paramètres, en volume de données d'entraînement et en complexité architecturale. Chaque génération exige plus de puissance de calcul que la précédente.
Cela dit, les gains d'efficacité compensent en partie les augmentations d'échelle. De meilleurs algorithmes, du matériel optimisé et des techniques d'entraînement améliorées permettent d'obtenir davantage de capacités pour chaque dollar investi. Le coût par unité de capacité du modèle a en réalité diminué, même si les coûts absolus d'entraînement ont augmenté.
Stratégies pour réduire les coûts de formation
Plusieurs approches peuvent permettre de réduire considérablement les dépenses sans sacrifier proportionnellement la qualité du modèle.
Les frameworks d'entraînement efficaces minimisent le gaspillage de cycles GPU. Des techniques comme l'accumulation de gradients, l'entraînement en précision mixte et l'optimisation des pipelines de chargement de données améliorent l'utilisation du matériel. D'après l'analyse des systèmes d'entraînement à haut débit, corriger l'utilisation inefficace des ressources de calcul lors de l'entraînement des transformeurs peut réduire considérablement le temps d'entraînement et la consommation d'énergie.
Les techniques de compression de modèles réduisent les besoins de calcul. La quantification représente les poids avec moins de bits, diminuant ainsi la bande passante mémoire et les besoins de stockage. L'élagage supprime les connexions les moins importantes, réduisant la taille du modèle. La distillation des connaissances permet de transférer plus efficacement les capacités des grands modèles vers des modèles plus petits qu'un entraînement à partir de zéro.
L'allocation intelligente des ressources permet d'éviter de payer pour du matériel inactif. La mise en pause automatique des clusters GPU pendant les phases de préparation des données, le dimensionnement dynamique de l'infrastructure pour chaque étape d'entraînement et la planification des exécutions pendant les heures creuses contribuent tous à réduire les coûts totaux.
L'optimisation des hyperparamètres réduit le nombre d'expériences infructueuses. Les stratégies de recherche systématique permettent de trouver plus rapidement des configurations d'entraînement efficaces qu'un réglage manuel. Moins d'entraînements inutiles signifient moins de temps de calcul GPU gaspillé en impasse.
Le choix entre le cloud et l'infrastructure sur site
L'infrastructure cloud offre flexibilité et faibles coûts initiaux. Déployez des milliers de GPU pour une session d'entraînement, puis libérez-les une fois celle-ci terminée. Cette approche convient parfaitement aux organisations menant des expériences ponctuelles ou dont les besoins de calcul à long terme sont incertains.
L'installation de matériel sur site nécessite un investissement initial important, mais élimine les frais de location récurrents. L'analyse du seuil de rentabilité montre généralement que l'acquisition devient économique après 10 000 à 16 000 heures d'utilisation pour les puces H100 ou 6 000 à 10 000 heures pour les puces A100.
Les organisations qui prévoient plusieurs campagnes de formation à grande échelle, des opérations de mise au point continues ou des processus de développement de modèles à long terme constatent souvent que l'achat de matériel est plus économique malgré des coûts initiaux plus élevés.
| Stratégie de réduction des coûts | Économies potentielles | Complexité de la mise en œuvre |
|---|---|---|
| Cadres de formation efficaces | 20-40% | Moyen |
| quantification du modèle | 30-50% | Faible |
| Planification intelligente des ressources | 15-30% | Moyen |
| Réglage fin vs. formation à partir de zéro | 60-90% | Faible (si le modèle de base répond aux besoins) |
| Matériel sur site (à long terme) | 40-60% | Haut |
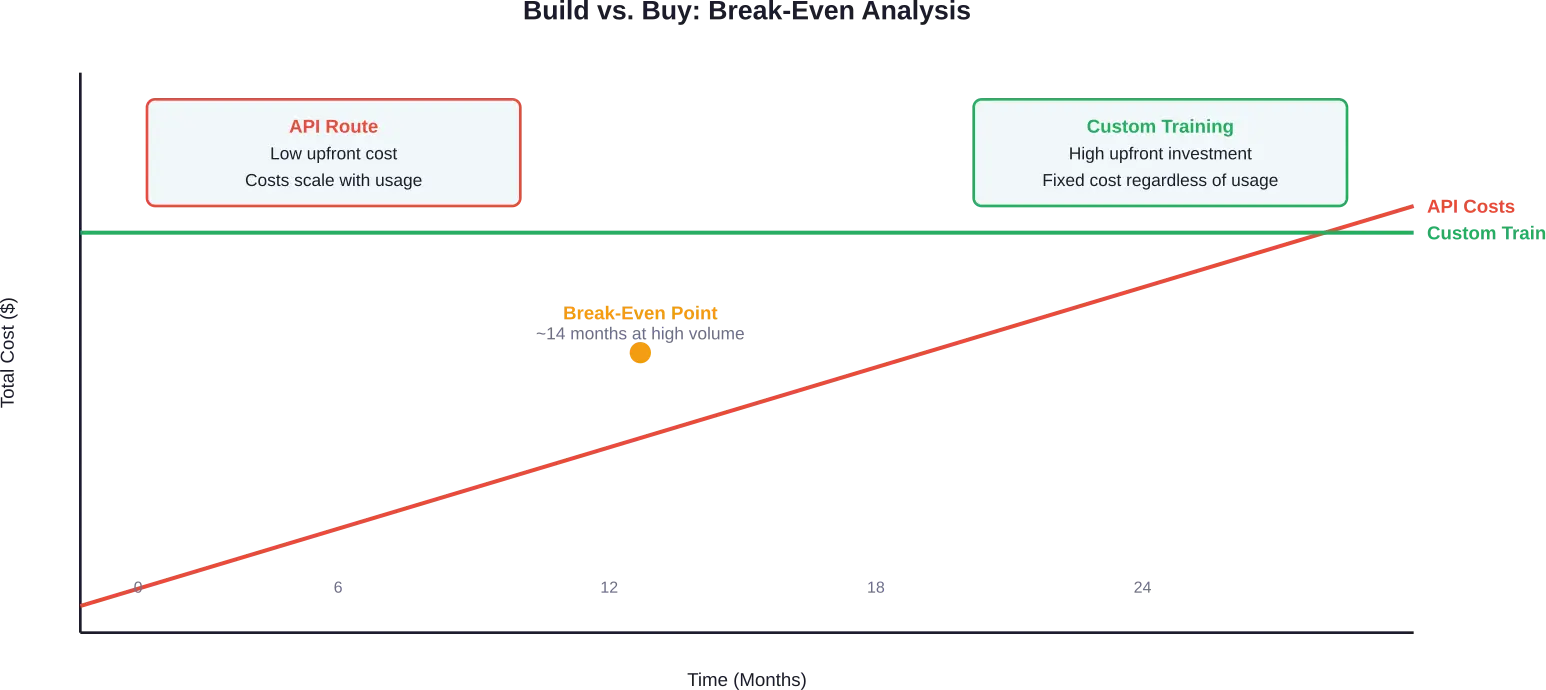
Le choix entre construire et acheter
De nombreuses organisations sont confrontées à une question fondamentale : faut-il former un modèle personnalisé ou acquérir une licence pour des modèles existants ?
L'accès API à des modèles comme GPT-4 est proposé à partir de $0,60 par million de jetons d'entrée chez certains fournisseurs, le prix des jetons de sortie variant selon le modèle. Gemini Flash-Lite offre des tarifs encore plus avantageux : $0,075 par million de jetons d'entrée et $0,30 par million de jetons de sortie (données tarifaires de 2025).
La tarification à l'usage semble économique au premier abord. Cependant, les coûts augmentent proportionnellement au trafic. Les applications traitant 1,2 million de messages par jour, chacun consommant 150 jetons, peuvent générer des factures API mensuelles de $15 000 à $60 000, selon les niveaux de tarification et les ratios entrée/sortie.
À volume élevé, l'infrastructure détenue en propre devient plus économique. L'analyse du seuil de rentabilité d'un cas documenté a montré que les coûts des API atteignaient $60 000 par mois et tendaient vers $500 000 par an, un chiffre qui justifie un investissement initial important en formation.
Le choix dépend des habitudes d'utilisation, des besoins de personnalisation et du positionnement concurrentiel. Les applications à forte utilisation prévisible, aux exigences spécifiques à un domaine ou nécessitant une transparence du modèle privilégient généralement un entraînement personnalisé. Les projets à utilisation variable, aux fonctionnalités générales ou aux délais de développement serrés optent plutôt pour un accès API.
Tendances futures des coûts
Les coûts de formation continueront d'évoluer au gré des changements technologiques et de la dynamique du marché.
Les améliorations en matière d'efficacité matérielle réduisent constamment le coût par calcul. Les différentes générations d'architectures NVIDIA affichent des gains de performance par watt constants. L'arrivée de concurrents sur le marché des accélérateurs stimulera l'optimisation et la concurrence sur les prix.
Les progrès algorithmiques permettent d'obtenir de meilleures performances avec moins de ressources de calcul. Des techniques comme les architectures de type « mix of experts », les mécanismes d'attention parcimonieuse et les algorithmes d'optimisation améliorés réduisent le budget de calcul nécessaire pour atteindre des objectifs de performance spécifiques.
Les coûts énergétiques devraient augmenter à mesure que l'infrastructure d'IA sollicitera davantage les réseaux électriques. Face à l'accroissement des besoins en formation et à l'importance croissante des infrastructures énergétiques, les organisations ayant accès à une énergie renouvelable à bas coût bénéficieront d'un avantage concurrentiel.
Les pressions réglementaires peuvent avoir une incidence sur le coût de la formation. Les gouvernements soucieux de la consommation d'énergie, de la confidentialité des données ou de la sécurité de l'IA pourraient imposer des exigences qui augmenteraient les coûts de mise en conformité ou restreindraient certaines pratiques.
Les tendances à la démocratisation pourraient réduire les barrières à l'entrée. Les modèles open source, les plateformes de calcul partagées et une meilleure efficacité de l'entraînement pourraient rendre le développement de modèles à grande échelle accessible aux entreprises de taille moyenne plutôt qu'aux seuls géants de la tech.
Questions fréquemment posées
Combien coûte l'entraînement de GPT-4 ?
Selon le Wall Street Journal et le rapport Stanford AI Index 2025, l'entraînement de GPT-4 coûterait entre $78 et 100 millions de dollars. Ce chiffre inclut l'infrastructure GPU, la consommation d'électricité, la préparation des données et les ressources d'ingénierie sur une période d'entraînement de plusieurs mois.
Pourquoi la formation LLM est-elle si chère ?
Les coûts de formation proviennent principalement de l'infrastructure de calcul GPU, qui représente entre 60 et 701 TP3T de dépenses. Un modèle de pointe peut nécessiter entre 10 000 et 25 000 GPU haut de gamme fonctionnant en continu pendant des semaines, voire des mois. Les coûts supplémentaires comprennent la consommation d'électricité (en gigawattheures), les ressources d'ingénierie, l'acquisition et la préparation des données, ainsi que les itérations expérimentales visant à optimiser les hyperparamètres.
Le réglage fin peut-il réduire les coûts de formation LLM ?
L'optimisation de modèles existants coûte généralement entre 60 et 900 millions de roupies de moins qu'un entraînement à partir de zéro. Adapter un modèle pré-entraîné comme Llama 2 ou GPT-3.5 à des tâches spécifiques peut coûter entre 5 000 et 50 000 roupies, contre 78 à 192 millions de roupies pour l'entraînement d'un modèle de pointe. Des techniques comme LoRa permettent d'effectuer cette optimisation sur un seul GPU, en quelques heures au lieu de plusieurs semaines.
Quelle est la différence entre les coûts de formation dans le cloud et sur site ?
L'infrastructure cloud facture $2-4 par heure d'utilisation d'un GPU H100, sans investissement initial mais avec des frais de location récurrents. L'achat de matériel H100 coûte $30 000 à $40 000 unités par unité, mais élimine les frais de location. Le seuil de rentabilité est atteint après environ 10 000 à 16 000 heures d'utilisation. Les organisations prévoyant plusieurs sessions de formation trouvent souvent l'acquisition plus économique malgré des besoins en capital initiaux plus importants.
Quelle est la consommation électrique de la formation d'un LLM ?
Les modèles de pointe consomment des gigawattheures d'électricité, soit l'équivalent de la consommation de milliers de foyers pendant des mois. L'entraînement d'un seul modèle d'IA de pointe nécessitera bientôt une capacité de production d'électricité de l'ordre du gigawatt. Les coûts d'électricité représentent entre 15 et 201 000 milliards de dollars des dépenses totales d'entraînement pour les grands modèles, ces coûts étant principalement dus aux factures d'électricité directes et aux infrastructures nécessaires.
Quelle est la méthode la plus économique pour entraîner un modèle de langage personnalisé ?
L'optimisation d'un modèle open source existant à l'aide de techniques efficaces comme LoRa constitue la solution la plus économique. Une étude a démontré qu'une expérience d'entraînement LoRa pouvait être menée à bien en 7 heures sur un seul GPU NVIDIA T4 doté de 16 Go de VRAM, un matériel disponible sur des plateformes telles que Google Colab. Pour les applications où l'optimisation offre des performances suffisantes, cette approche permet de réduire les coûts d'un facteur 1 000 à 10 000 par rapport à un entraînement à partir de zéro.
Les coûts de formation continuent-ils d'augmenter ?
Les coûts d'entraînement absolus des modèles de pointe continuent d'augmenter avec la croissance du nombre de paramètres et de la taille des ensembles de données. Le rapport Stanford AI Index 2025 a constaté une multiplication par 287 000 entre 2017 et aujourd'hui. Cependant, le coût par unité de capacité du modèle diminue grâce aux améliorations matérielles et aux progrès algorithmiques. Les gains d'efficacité compensent partiellement l'augmentation de l'échelle, même si les budgets totaux des modèles les plus performants restent en constante progression.
Comprendre l'investissement
Le coût des formations LLM reflète l'intensité de calcul nécessaire à la création de systèmes capables de traiter et de générer le langage humain à grande échelle. Ces prix à huit ou neuf chiffres ne sont pas arbitraires : ils représentent des milliers de processeurs spécialisés fonctionnant en continu, consommant des mégawatts d'énergie, sous la direction d'équipes d'ingénieurs spécialisés travaillant avec d'immenses ensembles de données.
L'économie continuera d'évoluer. Le matériel informatique gagne en efficacité. Les algorithmes s'améliorent. La concurrence stimule l'innovation. Mais le compromis fondamental demeure : la performance exige de la puissance de calcul, et la puissance de calcul a un coût.
Les organisations qui envisagent de développer des modèles personnalisés ont besoin de projections de coûts réalistes, et non d'estimations trop optimistes. Les équipes en quête de financement doivent prendre en compte toutes les catégories de dépenses, et pas seulement les coûts évidents de location de GPU. Enfin, les observateurs du secteur qui suivent l'évolution de l'IA doivent comprendre que les coûts d'entraînement constituent un indicateur pertinent de la taille et des capacités du modèle.
La marche à suivre dépend des besoins spécifiques. Les applications à fort volume et aux exigences particulières justifient souvent une formation personnalisée malgré un investissement initial conséquent. Pour les projets à plus faible volume ou à usage général, l'accès à l'API s'avère plus économique. De nombreux cas d'utilisation se situent entre ces deux extrêmes, où un paramétrage précis permet d'obtenir le juste équilibre entre personnalisation et rentabilité.
Prêt à passer au développement de votre modèle ? Commencez par calculer vos habitudes d’utilisation, identifier les fonctionnalités nécessitant un entraînement personnalisé et celles nécessitant un réglage fin, et réaliser une analyse de rentabilité pour l’échelle de déploiement prévue. Les données vous permettront de déterminer la voie la plus adaptée à votre situation.