Résumé rapide : Le traitement automatique du langage naturel (TALN) utilise des méthodes statistiques et basées sur des règles pour des tâches linguistiques spécifiques à moindre coût, tandis que les modèles de langage à grande échelle (MLGE) sont des réseaux neuronaux entraînés sur des ensembles de données massifs, performants pour les tâches génératives mais beaucoup plus coûteux. Combiner ces deux approches – TALN pour la classification et le routage, et MLGE pour le raisonnement complexe – permet de réduire les coûts d'inférence de 40 à 900 Tk tout en préservant la qualité.
Tout le monde adore les maquettes sophistiquées jusqu'à ce que la facture arrive. Ce qui semble être quelques centimes par requête lors des tests se transforme en milliers par mois en production.
La réalité ? La plupart des charges de travail d’IA n’ont pas besoin d’un raisonnement de niveau GPT pour chaque requête. Mais sans une architecture de coûts appropriée, chaque requête sollicite de toute façon le modèle le plus coûteux.
En réalité, le traitement automatique du langage naturel (TALN) et les modèles linguistiques (MLM) ne sont pas des technologies concurrentes. Ce sont des outils complémentaires qui, combinés de manière stratégique, permettent d'obtenir à la fois performance et rentabilité. Savoir quand utiliser chaque approche ne se résume pas à faire des économies. Il s'agit de construire des systèmes d'IA durables et évolutifs.
Comprendre la différence de coût entre les programmes de maîtrise en programmation neurolinguistique (NLP) et les programmes de maîtrise en droit (LLM)
Le traitement automatique du langage naturel et les modèles de langage de grande taille fonctionnent selon des principes économiques fondamentalement différents. Cette distinction est importante car elle a un impact direct sur les budgets de production.
Les systèmes de traitement automatique du langage naturel (TALN) impliquent généralement des coûts de développement initiaux : élaboration d’ensembles de règles, entraînement de petits modèles spécialisés et création de pipelines de classification. Une fois déployés, les coûts d’inférence restent minimes. Le traitement de texte par expressions régulières, reconnaissance d’entités nommées ou petits modèles de classification requiert une puissance de calcul négligeable.
Les LLM bouleversent complètement ce modèle. Les coûts de développement sont moindres car les modèles de base sont pré-entraînés. En revanche, les coûts d'inférence deviennent le poste de dépense prédominant. Chaque jeton traité, en entrée comme en sortie, a un coût.
La réalité de l'économie symbolique
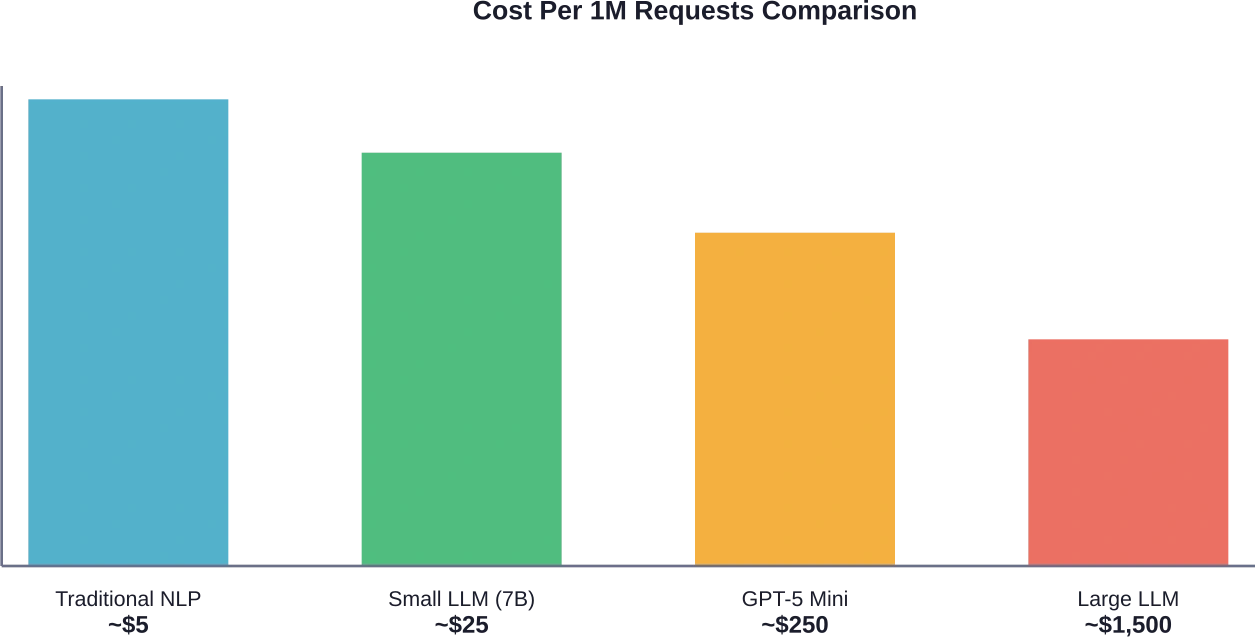
La tarification par jetons implique que les coûts augmentent linéairement avec l'utilisation. Selon les données de Hugging Face Inference Providers, les tarifs actuels du marché pour les modèles concurrents varient considérablement :
| Modèle | Fournisseur | Entrée (par million de jetons) | Sortie (pour 1 million de jetons) | Fenêtre contextuelle |
|---|---|---|---|---|
| GPT-5 Mini | OpenAI | $0.25 | $2.00 | ~400k |
| Qwen3.5-35B-A3B | Novita | $0.25 | $2.00 | 262,144 |
| Qwen3.5-27B | Novita | $0.30 | $2.40 | 262,144 |
| Qwen3.5-397B-A17B | Ensemble | $0.60 | $3.60 | 262,144 |
Les jetons de sortie coûtent systématiquement 8 à 10 fois plus cher que les jetons d'entrée. Cette asymétrie pénalise les réponses trop longues. Un chatbot qui génère des réponses de 500 mots consomme son budget beaucoup plus rapidement qu'un chatbot optimisé pour des réponses concises.
Soyons francs : $0,25 par million de jetons entrants semble bon marché jusqu’à ce que le volume de production atteigne ses objectifs. Traitez 100 millions de jetons par mois (ce qui est facilement réalisable pour une application de taille moyenne), et cela représente $25 000 rien que pour les entrées. Ajoutez les sorties, et les dépenses réelles augmentent considérablement.
Coûts d'infrastructure au-delà des appels d'API
La tarification des GPU dans le cloud complexifie la situation. Selon une analyse de Hugging Face sur l'économie du cloud computing, les coûts d'infrastructure sont prépondérants dans les modèles d'auto-hébergement.
L'investissement initial en capacité GPU représente le principal obstacle. L'infrastructure physique importe moins que le coût du matériel. Pour les organisations qui gèrent elles-mêmes l'inférence, cela modifie le modèle de coût, passant d'un paiement à l'utilisation à une planification de capacité fixe.
Mais attention ! Les instances cloud sont toujours facturées à l’heure. En fonction de la taille des modèles et des schémas de déploiement matériel documentés dans les sources du secteur, des contraintes pratiques apparaissent autour de :
| Taille du modèle | VRAM (FP16) | VRAM (4 bits) | Type d'instance cloud | Cas d'utilisation typiques |
|---|---|---|---|---|
| 1-3B | 4-6 Go | ~2 Go | AWS g4dn.xlarge | Chat basique, classification, saisie semi-automatique |
| 7-8B | 14-16 Go | ~6-8 Go | AWS g5.xlarge | Inférence à usage général |
Les composants NLP traditionnels fonctionnent parfaitement sur des instances CPU. Aucun matériel spécialisé n'est requis. L'écart de coût devient considérable à grande échelle.
Où le NLP traditionnel offre des avantages en termes de coûts
Certaines tâches de traitement du langage naturel ne tirent pas profit des capacités des modèles de langage naturel (LLM). Pour ces charges de travail, les méthodes traditionnelles de traitement automatique du langage naturel (TALN) offrent des résultats équivalents, voire supérieurs, à un coût bien moindre.
Tâches de classification et de routage
Classification des intentions, analyse des sentiments, catégorisation thématique : ces problèmes sont résolus. De petits modèles spécialisés, entraînés pour des tâches de classification spécifiques, atteignent une précision de 95%+ tout en traitant des milliers de requêtes par seconde avec un matériel minimal.
Un classificateur basé sur BERT, optimisé pour le routage du support client, peut utiliser jusqu'à 110 millions de paramètres. À titre de comparaison, GPT-5 Mini en utilise des milliards. Le modèle de classification effectue l'inférence en quelques millisecondes sur le processeur. Un appel LLM prend plusieurs centaines de millisecondes et coûte plusieurs ordres de grandeur de plus par requête.
Les discussions au sein de la communauté mettent en lumière des exemples concrets. Selon une étude de cas de Lumitech, l'analyse de leur utilisation de LLM a révélé que 801 000 requêtes étaient simples. Chaque requête sollicitait inutilement leur modèle le plus coûteux.
En implémentant d'abord une couche de classification NLP, ils ont confié les tâches simples à des modèles légers et réservé les modèles LLM aux raisonnements complexes. Résultat : une réduction des coûts d'un facteur 10 – de $200 à $20 par mois – sans aucune dégradation de la qualité.
Appariement de modèles et extraction d'entités
Les expressions régulières et les systèmes d'extraction basés sur des règles ne coûtent pratiquement rien à exploiter. Lorsque les exigences sont bien définies, les règles fonctionnent parfaitement.
La validation des adresses e-mail, le formatage des numéros de téléphone, l'analyse des dates, la normalisation des adresses : ces opérations ne nécessitent pas de réseaux neuronaux. Les systèmes à base de règles s'exécutent en quelques microsecondes, sans appels d'API ni inférence de modèle.
La reconnaissance d'entités nommées suit un modèle économique similaire. Les modèles statistiques de SpaCy extraient les entités avec une grande précision dans plusieurs langues. Une fois chargées en mémoire, les données sont traitées quasi instantanément. Aucun coût par requête. Aucun comptage de jetons.
Tâches linguistiques spécifiques au domaine
Les modèles NLP spécialisés, entraînés pour des domaines restreints, surpassent souvent les modèles LLM à usage général tout en coûtant moins cher.
Le traitement des textes médicaux bénéficie de l'utilisation de BioBERT ou de modèles similaires adaptés au domaine. L'analyse des documents juridiques est plus performante avec des pipelines de traitement automatique du langage naturel (TALN) spécifiques au domaine juridique. L'analyse des sentiments financiers atteint une précision supérieure avec FinBERT qu'avec des modèles linéaires génériques.
Ces modèles comportent entre 100 et 400 millions de paramètres. L'auto-hébergement devient économiquement viable. Les coûts d'entraînement sont ponctuels. Les coûts d'inférence tendent vers zéro à grande échelle.
Quand les coûts d'un LLM sont justifiés
Les LLM justifient leurs tarifs par des cas d'utilisation spécifiques. L'essentiel est d'adapter les compétences aux besoins.
Tâches génératives et créatives
Génération de contenu, rédaction créative, synthèse de code, résumé : autant de domaines relevant du LLM. Le traitement automatique du langage naturel (TALN) traditionnel ne peut générer de contenu long et cohérent. Les systèmes à base de règles ne peuvent rédiger des textes marketing au ton naturel.
Pour les charges de travail génératives, les coûts liés aux modèles de bas niveau (LLM) deviennent inévitables. La question n'est plus de savoir s'il faut utiliser des LLM, mais plutôt quel niveau de modèle offre le meilleur rapport qualité-prix.
OpenAI annonce que GPT-5 Mini atteint 91,11 TPP3T au concours mathématique AIME et 87,81 TPP3T sur une mesure d'“ intelligence ” interne. Ses performances rivalisent avec celles de modèles bien plus imposants. À 1 TPP4T0,25 par million de jetons d'entrée, il offre des capacités de pointe à un prix abordable.
Raisonnement complexe et problèmes à plusieurs étapes
Le raisonnement par enchaînement, la réponse à des questions complexes, la résolution de problèmes mathématiques : les modèles de petite taille peinent dans ces domaines. Les modèles linéaires à grands réseaux (LLM), avec leurs milliards de paramètres, font preuve de capacités de raisonnement émergentes qui justifient leur coût plus élevé.
Mais c'est là que ça devient intéressant. Toutes les tâches complexes ne nécessitent pas le modèle le plus volumineux. Les recherches sur l'optimisation de l'utilisation des modèles linéaires à grande échelle (LLM) montrent des méthodes permettant de réduire les coûts de 40 à 90 TP3T tout en améliorant la qualité de 4 à 71 TP3T.
La méthodologie repose sur une évaluation approfondie à différents niveaux de modélisation. Les résultats démontrent systématiquement que le choix d'un modèle adapté à la tâche permet de maintenir la qualité tout en maîtrisant les coûts.
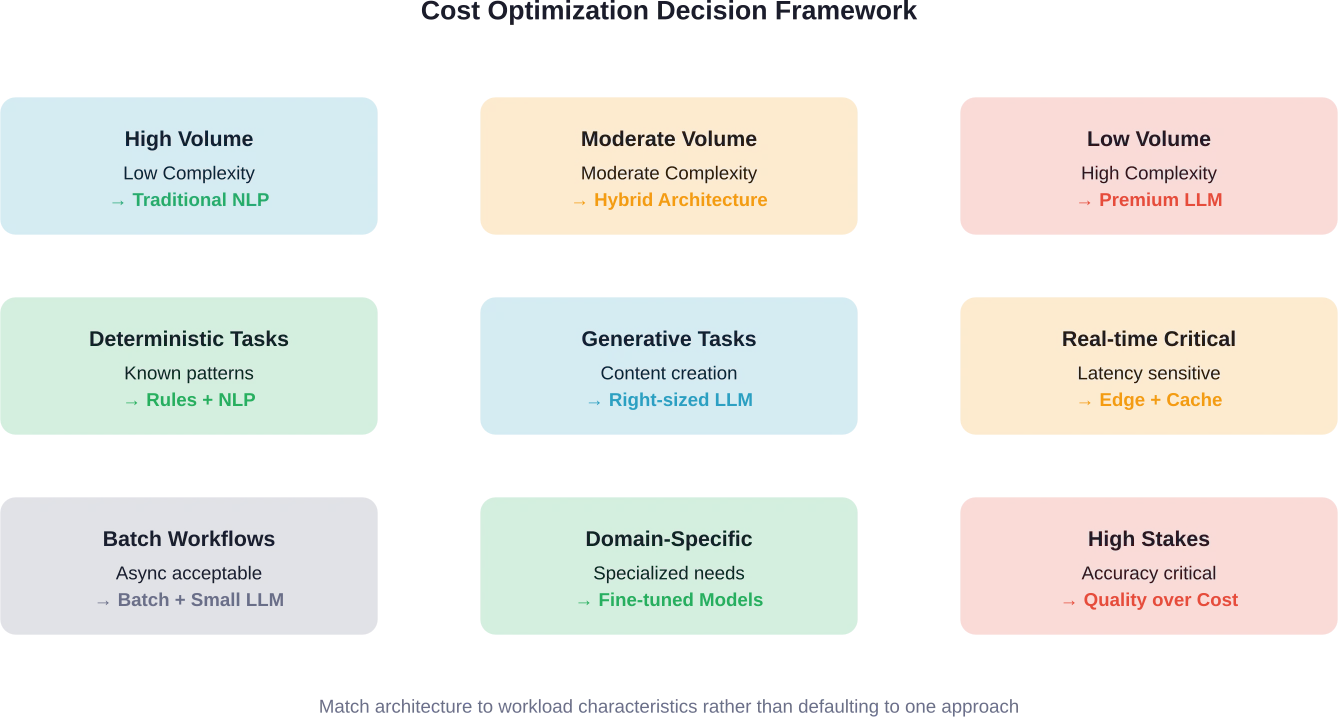
Flux de travail à faible volume et à forte valeur ajoutée
Lorsque le volume de demandes est faible et la valeur de la décision élevée, les coûts LLM deviennent négligeables par rapport à l'impact sur l'activité.
Un outil de recherche juridique traitant 100 requêtes par jour tire pleinement parti des fonctionnalités d'un LLM. Même avec un abonnement premium, les coûts mensuels pourraient atteindre $50-200. La valeur d'une analyse juridique précise dépasse largement cette dépense.
Comparons cela à un chatbot gérant 100 000 interactions quotidiennes. Même modèle, volume différent, profil de coûts totalement différent. Les scénarios à fort volume exigent une optimisation. Les flux de travail à faible volume peuvent se permettre des modèles haut de gamme.
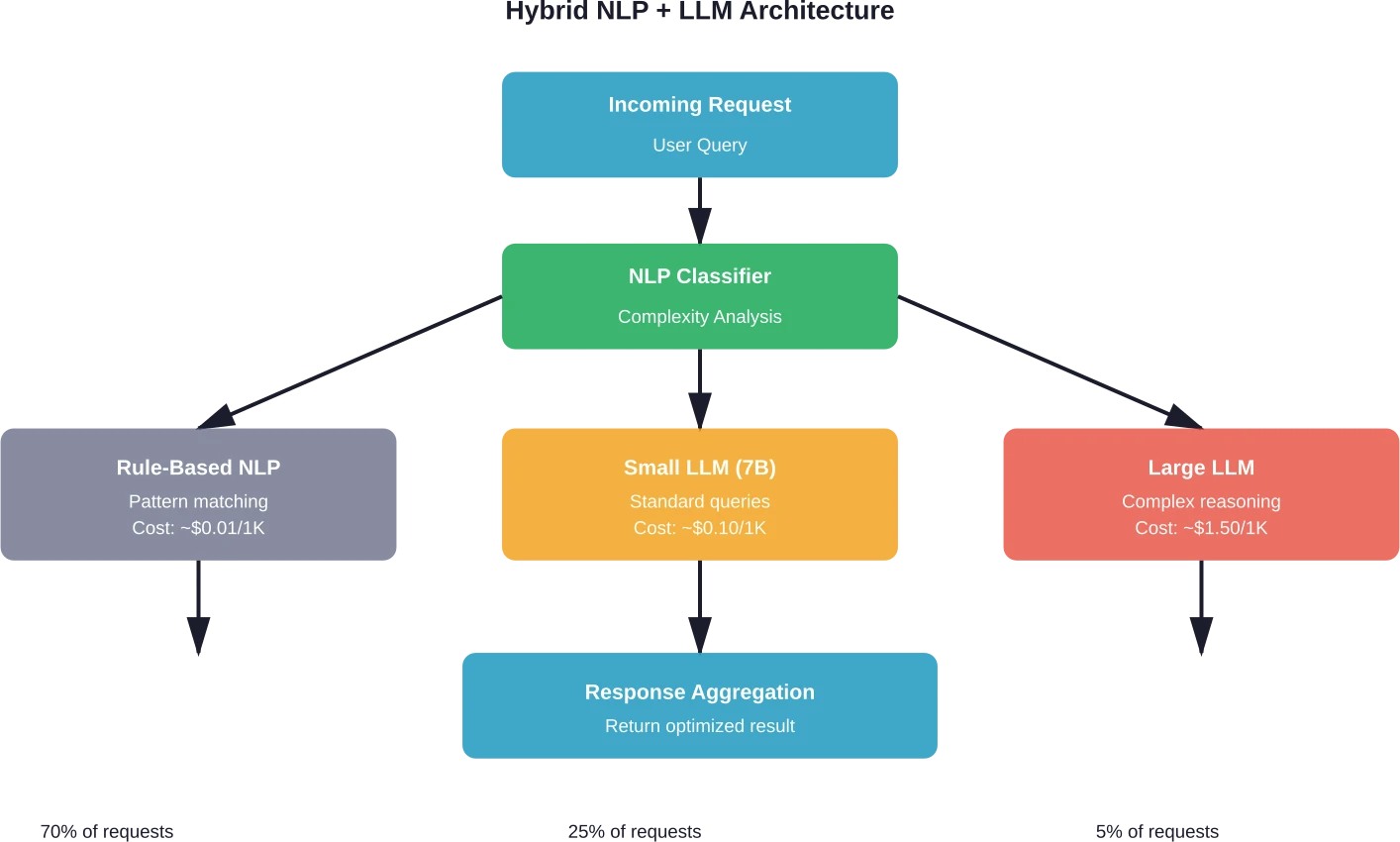
L'approche de l'architecture hybride
Les systèmes de production les plus rentables combinent stratégiquement le traitement automatique du langage naturel (TALN) et les méthodes d'apprentissage automatique (MLA). Il ne s'agit pas d'un choix exclusif.
Routage intelligent des requêtes
Les couches de classification déterminent la complexité avant d'acheminer les requêtes vers les modèles appropriés. Les tâches simples sont confiées à des modèles rapides et peu coûteux. Les raisonnements complexes sont acheminés vers des modèles LLM performants.
La mise en œuvre nécessite plusieurs composants. Tout d'abord, un classificateur léger analyse les requêtes entrantes. Il peut s'agir d'un modèle BERT affiné ou même d'heuristiques plus simples basées sur la longueur de la requête, les mots-clés et la structure.
Le classificateur catégorise les requêtes en différents niveaux : requêtes factuelles simples, tâches directes, complexité modérée et raisonnement complexe. Chaque niveau correspond à un chemin de traitement différent.
Les équipes qui mettent en œuvre le routage intelligent constatent des réductions de coûts (norme 30-50%) sans dégradation mesurable de la qualité, grâce à des stratégies de routage qui alignent efficacement les modèles sur les exigences des tâches. La clé du succès réside dans une évaluation systématique qui valide la logique de routage et garantit le maintien des normes de qualité à tous les niveaux de modélisation.
Optimisation de la mise en cache et de la réponse
La mise en cache sémantique évite les appels LLM redondants. Lorsque des utilisateurs posent des questions similaires, les réponses mises en cache sont servies immédiatement, sans coût d'inférence.
La mise en cache traditionnelle correspond aux requêtes exactes. La mise en cache sémantique utilise des représentations vectorielles pour identifier les questions similaires formulées différemment. Une recherche de similarité vectorielle détermine si les réponses mises en cache satisfont les nouvelles requêtes.
L'exécution de modèles d'intégration est peu coûteuse. Même avec l'étape d'intégration supplémentaire, la mise en cache des réponses réduit considérablement les coûts par rapport à une inférence LLM complète.
L'optimisation des réponses vise à réduire le nombre de messages produits. Une conception incitant à des réponses concises permet de réduire directement les coûts. Étant donné que les messages produits coûtent 8 à 10 fois plus cher que les messages saisis, les réponses trop longues font grimper les factures de manière disproportionnée.
Amélioration progressive
Commencez par le plus petit modèle viable. Ne passez à des modèles plus grands qu'en cas de nécessité.
Un système multi-agents peut commencer par exécuter les tâches avec un modèle à 7 milliards de paramètres. Si le score de confiance est inférieur au seuil requis, le système réessaie automatiquement avec un modèle plus performant. La plupart des requêtes réussissent du premier coup. Seuls les cas complexes engendrent des coûts plus élevés.
Cette approche nécessite un étalonnage de la confiance. Les modèles doivent estimer avec précision leur propre incertitude. Les modèles bien étalonnés savent quand ils risquent d'échouer et peuvent demander automatiquement une remontée d'information.
Stratégies concrètes d'optimisation des coûts
Les systèmes de production mettent en œuvre simultanément plusieurs tactiques. Aucune optimisation isolée ne résout le problème des coûts ; c’est leur combinaison qui donne des résultats.
Ingénierie rapide pour une efficacité accrue
La longueur de l'invite a un impact direct sur les coûts. Chaque jeton de l'invite est traité et facturé.
Un contexte excessif, des instructions verbeuses et des exemples redondants augmentent inutilement le nombre d'éléments à saisir. Des invites simplifiées, communiquant les exigences de manière concise, permettent de réduire les coûts sans compromettre la qualité.
Les exemples à nombre réduit d'occurrences démontrent le comportement souhaité, mais consomment des jetons. Tester différents nombres d'exemples permet d'identifier les compromis optimaux. Parfois, trois exemples permettent d'atteindre la même précision que dix, tout en utilisant 70% jetons de moins.
Adaptation du modèle
Plus grand n'est pas toujours synonyme de meilleur. Le choix d'un modèle adapté à la tâche permet d'équilibrer les performances et le coût.
Les suites de tests de performance comme MMLU, HumanEval et les évaluations spécifiques au domaine permettent d'identifier les modèles les plus performants pour des tâches données. Un modèle obtenant un score de 85% peut coûter dix fois moins cher qu'un modèle obtenant un score de 90%. Dans certaines applications, une différence de précision de 5 points ne justifie pas un surcoût décuplé.
Des tests et analyses approfondis indiquent que, pour des tâches spécifiques, les modèles plus petits atteignent souvent les performances de modèles beaucoup plus volumineux. DeepSeek V3.2-Exp égale et surpasse légèrement son prédécesseur V3.1 sur les benchmarks publics, tout en offrant un meilleur rapport coût-efficacité grâce à des améliorations architecturales.
Traitement par lots et flux de travail asynchrones
L'inférence en temps réel coûte plus cher que le traitement par lots. Lorsque l'immédiateté n'est pas requise, le traitement par lots des requêtes permet de réduire les coûts.
La synthèse de documents, la modération de contenu et l'extraction de données tolèrent généralement une certaine latence. Le traitement par lots permet une meilleure utilisation des ressources et des tarifs négociés avec les fournisseurs en fonction du volume.
Les flux de travail asynchrones dissocient la soumission des requêtes de la réception des résultats. Les utilisateurs soumettent des tâches, poursuivent leurs autres activités et reçoivent les résultats une fois le traitement terminé. Cette flexibilité permet une optimisation des coûts que les contraintes de temps réel empêchent.
Comparaison des prix actuels du marché
Les prix pratiqués par les fournisseurs varient considérablement. Il est important de comparer les offres.
D'après les données du début de l'année 2026, les prix concurrentiels se répartissent en plusieurs paliers. Les modèles d'entrée de gamme comme GPT-5 Mini et Qwen3.5-35B-A3B sont proposés à partir de $0,25 par million de jetons d'entrée et $2,00 par million de jetons de sortie.
Les modèles de milieu de gamme ont un prix d'entrée compris entre $0.30 et $0.60. Les grands modèles haut de gamme dépassent $0.60 pour les entrées.
La taille de la fenêtre de contexte influe sur les calculs de valeurs. Les modèles offrant des fenêtres de contexte de 256 000 à 400 000 éléments permettent des architectures différentes de celles des modèles limités à des fenêtres de 32 000 à 128 000 éléments. Un contexte plus large réduit le nombre de requêtes nécessaires lors du traitement de documents longs.
| Niveau de capacité | Prix typique des intrants | Prix de production typique | Idéal pour |
|---|---|---|---|
| Entrée (7-8B) | $0,10-0,25 / 1M | $0.80-2.00 / 1M | Classification, conversation simple, résumé basique |
| Moyen (30-40B) | $0,25-0,60 / 1M | $2.00-3.60 / 1M | Tâches générales, raisonnement modéré |
| Premium (100B+) | $0,60-2,00 / 1M | $3.60-10.00 / 1M | Raisonnement complexe, domaines spécialisés |
La latence et le débit varient indépendamment du prix. Les modèles moins chers ne sont pas forcément plus lents. L'infrastructure et l'optimisation du fournisseur influent autant sur les performances que la taille du modèle.
Coûts cachés à prendre en compte
Le prix de l'API n'est pas le seul facteur de coût. Le temps de développement, la complexité du débogage et les frais de maintenance contribuent également au coût total de possession.
Le traitement automatique du langage naturel (TALN) traditionnel exige un développement initial plus important. La construction de pipelines de classification, l'optimisation des modèles, la maintenance des ensembles de règles : ces tâches requièrent du temps d'ingénierie spécialisée.
Les LLM réduisent les obstacles au développement. L'ingénierie rapide remplace l'entraînement des modèles. Les cycles d'itération sont raccourcis. Pour les équipes ayant une expertise limitée en apprentissage automatique, la facilité d'utilisation des LLM compense les coûts d'inférence plus élevés.
Mais à grande échelle, les coûts d'inférence deviennent prépondérants. Un système traitant des millions de requêtes quotidiennes dépensera davantage en jetons LLM sur une année qu'en développement initial du traitement automatique du langage naturel (TALN). La situation s'inverse à mesure que le volume augmente.
Considérations relatives aux coûts énergétiques et environnementaux
Les coûts financiers sont directement liés à la consommation d'énergie. Une étude publiée sur arxiv.org concernant les coûts énergétiques de l'inférence LLM établit un lien entre la puissance de calcul et la consommation électrique.
L'inférence de modèles complexes requiert une énergie considérable. Bien que les chiffres exacts dépendent du matériel et de l'optimisation, la tendance est claire : les modèles plus volumineux consomment davantage d'énergie par unité de temps.
Les modèles NLP traditionnels traitent les requêtes avec une consommation d'énergie minimale. L'inférence basée sur le CPU consomme beaucoup moins d'énergie que l'inférence LLM accélérée par GPU.
Les organisations engagées en faveur du développement durable sont confrontées à une double pression : l’optimisation financière et la réduction de leur empreinte carbone. Heureusement, ces objectifs convergent. Les stratégies visant à réduire les coûts de gestion de la demande permettent généralement de réduire simultanément la consommation d’énergie.
Un routage efficace qui oriente les requêtes simples vers des modèles légers permet de réduire les coûts et les émissions. Le dimensionnement adapté des modèles aux exigences des tâches offre des avantages environnementaux tout en générant des économies.
Construire une architecture soucieuse des coûts
Les systèmes d'IA durables surveillent et optimisent les coûts en continu. Une optimisation ponctuelle ne suffit pas. Les habitudes d'utilisation évoluent. La tarification des modèles change. Les exigences évoluent.
Suivi et attribution des coûts
Le suivi des dépenses par fonctionnalité, niveau d'utilisateur ou flux de travail révèle des opportunités d'optimisation. Les indicateurs agrégés, quant à eux, masquent les composants qui génèrent les dépenses.
La journalisation détaillée enregistre les métadonnées des requêtes : modèle utilisé, nombre de jetons, latence, coût et contexte métier. Ces données permettent une analyse qui identifie les schémas coûteux.
Certaines fonctionnalités peuvent engendrer des coûts disproportionnés par rapport à leur valeur ajoutée. L'analyse de l'utilisation pourrait révéler que 51 000 milliards de dollars d'utilisateurs consomment 601 000 milliards de dollars du budget LLM en raison de comportements d'interaction inefficaces. Une optimisation ciblée ou une refonte des fonctionnalités permet de corriger ces anomalies.
Cadres de test et d'évaluation
L'optimisation des coûts nécessite une mesure. Les indicateurs de qualité permettent de vérifier que des alternatives moins coûteuses offrent des performances acceptables.
Les cadres d'évaluation comparent les résultats des modèles à différents niveaux. L'évaluation humaine ou la notation automatisée de la qualité déterminent si les modèles plus petits atteignent une précision suffisante pour des tâches spécifiques.
Les tests A/B en production permettent de mesurer la satisfaction des utilisateurs en fonction des différents modèles utilisés. Si les utilisateurs ne perçoivent pas de différence entre les réponses d'un modèle à 7 milliards de dollars et celles d'un modèle à 70 milliards de dollars pour certaines requêtes, le modèle le plus coûteux n'apporte aucune valeur ajoutée.
Boucles d'optimisation continue
Les architectures statiques deviennent sous-optimales à mesure que les modèles s'améliorent et que les prix évoluent. Une évaluation régulière permet d'identifier de meilleures alternatives.
De nouveaux modèles sont régulièrement mis sur le marché. Un modèle qui sortira le mois prochain pourrait offrir un meilleur rapport performance/prix que les modèles actuellement disponibles. Une évaluation comparative continue avec les nouveautés permet de garantir que les systèmes tirent le meilleur parti des options disponibles.
Les tarifs sont ajustés sans préavis. Le suivi des variations de prix de plusieurs fournisseurs permet de changer de fournisseur au moment opportun lorsque la concurrence propose des offres plus avantageuses.
Tendances futures des coûts
L'évolution des prix est importante pour la planification à long terme. Plusieurs facteurs influencent les coûts futurs.
L'efficacité des modèles continue de s'améliorer. Les innovations architecturales permettent d'obtenir de meilleures performances par paramètre. Les recherches publiées sur arxiv.org concernant l'efficacité des grands modèles de langage documentent les avancées algorithmiques qui réduisent les besoins en calcul.
Les modèles repensés atteignent des performances équivalentes avec moins de paramètres grâce à l'optimisation architecturale. À mesure que ces techniques se perfectionnent, le coût par unité de performance diminue.
La concurrence entre les fournisseurs exerce une pression à la baisse sur les prix. L'arrivée de nouveaux acteurs sur le marché accélère la compression des tarifs. Le lancement des GPT-5 Mini, Gemini 2.5 Flash et Claude 3.5 Haiku a créé une nouvelle gamme de modèles performants à des prix nettement inférieurs à ceux des générations précédentes.
Les améliorations matérielles se poursuivent. Les nouvelles architectures GPU offrent un meilleur débit d'inférence. Grâce à l'augmentation de l'efficacité du matériel, les fournisseurs peuvent proposer des prix plus bas tout en préservant leurs marges.
Mais la demande augmente simultanément. À mesure que davantage d'applications intègrent des LLM, les dépenses globales augmentent, même si le coût par jeton diminue. Les organisations qui n'optimisent pas activement leurs dépenses constatent une hausse de celles-ci malgré la baisse des prix unitaires.
Feuille de route de mise en œuvre
Passer d'une architecture LLM entièrement coûteuse à des systèmes hybrides optimisés en termes de coûts nécessite une planification.
Phase 1 : Mesure et analyse
Instrumentez les systèmes existants pour recueillir des indicateurs d'utilisation détaillés. Sans données, l'optimisation relève de la conjecture.
Consignez chaque requête LLM avec les métadonnées suivantes : horodatage, utilisateur, fonctionnalité, jetons d’invite, jetons de fin, modèle utilisé, latence et coût. Regroupez ces données pour analyse.
Identifiez les tendances. Quelles fonctionnalités génèrent le plus de requêtes ? Quels utilisateurs consomment le plus de jetons ? Quels types de requêtes apparaissent fréquemment ?
Calculez le coût par fonctionnalité, par segment d'utilisateurs et par résultat commercial. Cela permet d'identifier les domaines où les efforts d'optimisation sont les plus rentables.
Phase 2 : Victoires rapides
Les actions les plus faciles à mettre en œuvre permettent de réaliser des économies immédiates tout en créant une dynamique pour des initiatives plus importantes.
Optimisez les invites. Supprimez le contexte inutile, les instructions verbeuses et regroupez les exemples. Cela ne nécessite qu'un effort de développement minimal, mais réduit immédiatement la consommation de jetons.
Ajoutez une mise en cache sémantique. Des bibliothèques existent pour la plupart des langages, simplifiant ainsi son implémentation. La mise en cache peut réduire de 20 à 401 000 le nombre de requêtes avec des modifications de code minimes.
Adaptez la taille aux cas évidents. Les tâches utilisant actuellement des modèles haut de gamme mais obtenant des résultats équivalents avec des modèles de milieu de gamme représentent des opportunités d'optimisation claires.
Phase 3 : Architecture stratégique
Les initiatives de plus grande envergure nécessitent une planification plus poussée, mais génèrent des économies substantielles et continues.
Mettez en place la couche de classification et de routage. Celle-ci constituera l'infrastructure sur laquelle s'appuieront d'autres optimisations. Commencez simplement : classez initialement les requêtes en deux ou trois niveaux.
Déployez des modèles NLP dédiés aux tâches pour les charges de travail déterministes à volume élevé. Ceux-ci remplacent intégralement les appels LLM pour des cas d'utilisation spécifiques.
Mettez en œuvre une approche d'amélioration progressive pour les requêtes complexes. Commencez par des modèles moins coûteux et n'utilisez des modèles plus complexes qu'en cas de nécessité.
Phase 4 : Amélioration continue
L'optimisation n'est pas un projet avec une date de fin. C'est une pratique continue.
Planifiez des analyses trimestrielles des performances et des prix des modèles. De nouvelles options apparaissent constamment. Une évaluation régulière permet d'adapter les systèmes à l'évolution du marché.
Surveillez les indicateurs de coûts parallèlement aux indicateurs de performance de l'entreprise. Considérez l'efficience des coûts comme un indicateur clé de performance au même titre que la qualité, la latence et la satisfaction des utilisateurs.
Expérimentez de nouvelles approches. Prévoyez un budget pour tester des architectures alternatives, de nouveaux modèles et différents fournisseurs. L'optimisation optimale pour le prochain trimestre n'existe peut-être pas encore.

Réduisez vos coûts liés à l'IA avant qu'ils ne deviennent incontrôlables.
Le choix entre les systèmes de traitement automatique du langage naturel (TALN) et les grands modèles de langage peut avoir un impact considérable sur les dépenses à long terme en IA. IA supérieure Cette entreprise collabore avec des sociétés qui ont besoin de systèmes d'IA conçus pour une efficacité optimale. Son équipe conçoit et optimise des modèles de bas niveau (LLM), développe des modèles spécifiques à chaque tâche et optimise les flux de travail pilotés par l'IA afin que les entreprises puissent réduire leur consommation de ressources de calcul tout en maintenant leurs performances.
Si vous souhaitez réduire les coûts de l'IA au lieu de simplement les augmenter, parlez-en à IA supérieure et obtenir des conseils pratiques pour construire des systèmes d'IA plus efficaces.
Pièges courants à éviter
L'optimisation des coûts peut se révéler contre-productive si elle est menée avec négligence. Plusieurs erreurs se répètent.
Optimisation prématurée
Les projets en phase de démarrage bénéficient d'une itération rapide permise par les LLM. Consacrer des semaines à la création de pipelines NLP personnalisés avant de valider l'adéquation produit-marché représente un gaspillage de ressources.
Commencez par l'approche la plus simple et efficace. Optimisez uniquement lorsque la taille du produit l'exige, et non avant. Une optimisation prématurée nuit au développement du produit principal.
Optimisation sans mesure
Les hypothèses concernant les facteurs influençant les coûts s'avèrent souvent erronées. Une mesure détaillée révèle des tendances surprenantes.
Il arrive que les équipes optimisent les mauvais composants. Une fonctionnalité qui semble coûteuse peut représenter 31 TP3 000 $ du coût total. Parallèlement, un flux de travail négligé engloutit discrètement 401 TP3 000 $ du budget.
Mesurez d'abord. Optimisez les domaines à fort impact. Ignorez les facteurs mineurs jusqu'à ce que les problèmes majeurs soient résolus.
Sacrifier la qualité au profit du coût
Les réductions de coûts agressives qui dégradent la qualité de la production s'avèrent contre-productives. Une mauvaise expérience avec l'IA nuit à la confiance des utilisateurs et compromet la valeur du produit.
Maintenez des normes de qualité élevées. Utilisez des cadres d'évaluation pour vérifier que les solutions de rechange moins coûteuses répondent aux exigences. Dans le cas contraire, privilégiez l'option plus onéreuse.
Ignorer la vitesse de développement
Une architecture d'optimisation des coûts complexe peut ralentir le développement. Pour les produits en phase de démarrage, il est rarement judicieux de sacrifier l'agilité au profit d'économies marginales.
Il convient d'équilibrer les efforts d'optimisation et la valeur ajoutée pour l'entreprise. Un système traitant 1 000 requêtes par jour n'a pas besoin d'être optimisé avec la même rigueur qu'un système en traitant 1 000 000.
Questions fréquemment posées
Combien d'économies une architecture hybride NLP + LLM peut-elle raisonnablement permettre ?
Les études et les rapports de la communauté font état de réductions de coûts allant de 40% à 90% selon les caractéristiques de la charge de travail. Les systèmes traitant un volume important de requêtes simples enregistrent les économies les plus importantes. Les applications dominées par des tâches génératives complexes bénéficient de réductions plus modestes, mais néanmoins significatives. Le facteur clé réside dans le pourcentage de requêtes pouvant être traitées par des approches NLP moins coûteuses, par rapport à celles nécessitant des capacités LLM complètes.
Les LLM de plus petite taille sont-ils réellement suffisamment performants pour une utilisation en production ?
Les petits modèles LLM modernes, comme GPT-5 Mini, atteignent des performances étonnamment élevées sur les benchmarks. OpenAI annonce un score de 91,11 TP3T sur les problèmes mathématiques AIME et de 87,81 TP3T sur ses propres mesures d'intelligence. Pour de nombreuses tâches de production, ces modèles égalent, voire surpassent, la qualité des grands modèles de génération précédente, tout en coûtant 5 à 10 fois moins cher. Une évaluation spécifique à la tâche est essentielle : les performances varient selon le cas d'utilisation.
Quel est le seuil de rentabilité pour la création de modèles NLP personnalisés par rapport à l'utilisation de modèles LLM ?
De manière générale, les tâches déterministes à volume élevé justifient le développement de modèles NLP personnalisés. Si une tâche reçoit des milliers de requêtes par jour et peut être traitée par classification ou extraction, les modèles personnalisés sont rentabilisés en quelques semaines. Les tâches à faible volume ou très variables privilégient les modèles linéaires à grande échelle (LLM), malgré des coûts par requête plus élevés, car l'effort de développement ne peut être amorti sur un nombre suffisant de requêtes.
Comment puis-je déterminer quelles demandes nécessitent des modèles coûteux et lesquelles nécessitent des modèles bon marché ?
Commencez par un classificateur léger qui analyse les caractéristiques des requêtes : longueur, structure, mots-clés, domaine. En fonction de ces signaux, acheminez-les vers les niveaux de modélisation appropriés. La précision initiale de la classification n'a pas besoin d'être parfaite ; mettez en place des boucles de rétroaction pour identifier les requêtes mal acheminées et affiner la classification au fil du temps. De nombreuses équipes constatent que de simples heuristiques fonctionnent étonnamment bien comme point de départ.
Quels indicateurs de suivi dois-je surveiller pour optimiser les coûts LLM ?
Suivez séparément le nombre de jetons utilisés en entrée et en sortie, car les prix diffèrent considérablement. Surveillez le coût par requête, par utilisateur, par fonctionnalité et par résultat commercial. Analysez la distribution des modèles de sélection pour comprendre les schémas de routage. Mesurez le taux d'accès au cache si vous utilisez la mise en cache sémantique. Surveillez les indicateurs de qualité parallèlement aux coûts afin de garantir que l'optimisation n'affecte pas les performances. Configurez des alertes lorsque les coûts dépassent les prévisions.
Est-il préférable d'utiliser des services API ou des modèles d'auto-hébergement pour réaliser des économies ?
La réponse dépend de l'échelle et des capacités techniques. Les services API offrent une grande facilité d'utilisation et éliminent les coûts liés à la gestion de l'infrastructure. Pour des volumes modérés, la tarification au jeton s'avère souvent plus économique que la maintenance d'une infrastructure GPU. L'auto-hébergement devient rentable pour des volumes très élevés, lorsque le coût par requête dépasse les dépenses d'infrastructure amorties. L'analyse du cloud computing réalisée par Hugging Face indique que l'investissement initial, et non la complexité opérationnelle, constitue le principal obstacle à l'auto-hébergement.
À quelle fréquence les prix des masters en droit (LLM) changent-ils et dois-je prévoir en conséquence ?
Les tarifs des fournisseurs évoluent régulièrement, parfois sans préavis. Les mises à jour majeures introduisent souvent de nouveaux niveaux de tarification. La création de couches d'abstraction dissociant la sélection du modèle de la logique métier permet de changer de fournisseur ou de modèle sans refactorisation importante. La prise en charge de plusieurs fournisseurs permet un routage opportuniste vers celui qui offre le meilleur rapport qualité-prix pour des types de requêtes spécifiques à un instant donné.
Conclusion
Le choix entre le traitement automatique du langage naturel (TALN) et les modèles linguistiques (MLM) n'est pas binaire. Les systèmes d'IA de production les plus rentables combinent stratégiquement les deux approches.
Le traitement automatique du langage naturel (TALN) traditionnel excelle dans les tâches déterministes à grand volume. Les systèmes à base de règles et les modèles spécialisés traitent les requêtes simples à moindre coût. Les modèles linguistiques offrent des capacités que les méthodes traditionnelles ne peuvent égaler, mais à un coût nettement supérieur.
L'architecture intelligente achemine les requêtes vers les niveaux de traitement appropriés. Des couches de classification identifient les tâches simples ne nécessitant pas de modèles coûteux. Les raisonnements complexes sont dirigés vers des LLM performants. Cette approche hybride permet de réduire les coûts de 40 à 90% tout en préservant la qualité.
L'optimisation des coûts exige un effort constant. La mesure révèle des tendances. L'évaluation valide les alternatives. Des examens réguliers garantissent l'évolution des systèmes au gré des améliorations des modèles et des variations de prix.
Commencez par mesurer les dépenses. Instrumentez votre système actuel pour comprendre les habitudes de consommation. Identifiez les gains rapides grâce à une optimisation et une mise en cache immédiates. Élaborez une architecture stratégique pour une efficacité à long terme. Considérez la gestion des coûts comme une pratique continue plutôt que comme un projet ponctuel.
Les organisations qui sauront trouver cet équilibre construiront des systèmes d'IA durables et évolutifs à moindre coût. Celles qui privilégient systématiquement des modèles onéreux se heurteront à des contraintes budgétaires qui freineront l'innovation.
À vous de jouer : évaluez vos coûts actuels, identifiez les pistes d’optimisation et mettez en œuvre des améliorations systématiques. Les outils et les techniques existent. Reste à savoir si vous les utiliserez.