Résumé rapide : Le déploiement d'un logiciel LLM open source coûte entre 125 000 et plus de 820 000 $ par an pour la plupart des organisations, un coût bien supérieur à celui des API pour les charges de travail classiques. Si les pondérations des modèles sont gratuites, l'infrastructure, les compétences d'ingénierie, les frais d'exploitation et la maintenance engendrent des dépenses cachées considérables, rendant les services LLM commerciaux plus rentables jusqu'à l'atteinte de certains seuils de rentabilité.
L'argumentaire est irrésistible : téléchargez un modèle de langage open source de grande envergure, déployez-le sur votre infrastructure et dites adieu aux factures d'API pour toujours.
Mais voilà le hic : ce modèle “ gratuit ” vous coûtera entre $125 000 et plus de $12 millions par an, selon votre échelle.
Les modèles d'apprentissage automatique open source déplacent les coûts des frais d'API transparents vers des dépenses opérationnelles cachées. Selon une étude présentée dans le cadre d'une analyse coûts-avantages, les organisations sont confrontées à un choix crucial : souscrire à des services commerciaux de modèles d'apprentissage automatique auprès de fournisseurs tels qu'OpenAI, Anthropic et Google, ou déployer des modèles sur leur propre infrastructure. L'analyse révèle que la plupart des hypothèses concernant les économies potentielles sont fondamentalement erronées.
Cette analyse examine la réalité économique du déploiement de logiciels LLM open source en 2026, en s'appuyant sur des données issues de mises en production et d'analyses coûts-avantages académiques.
Le mythe du modèle gratuit : ce que vous payez réellement
Les poids des modèles open source sont téléchargeables gratuitement. Tout le reste est payant.
Lorsque les entreprises comparent le coût d'un téléchargement de $0 à la tarification d'une API facturée au jeton, le calcul semble évident. Pourtant, cette comparaison est trompeuse. Les poids des modèles téléchargés représentent environ 2 à 5TP3T du coût total de déploiement.
Le reste du 95-98% provient de :
- Infrastructure matérielle (GPU, serveurs, réseau)
- talents en ingénierie (ingénieurs en apprentissage automatique, spécialistes MLOps, équipes d'infrastructure)
- Frais généraux opérationnels (surveillance, mise à l'échelle, fiabilité)
- Maintenance et mises à jour (correctifs de sécurité, réentraînement des modèles, optimisation des performances)
- Travaux d'intégration (connexion des modèles aux systèmes existants)
Des recherches analysant les déploiements sur site ont révélé que les entreprises doivent atteindre certains seuils d'utilisation avant que les modèles auto-hébergés ne deviennent compétitifs en termes de coûts par rapport aux services commerciaux. Pour la plupart des charges de travail classiques, ce seuil n'est jamais atteint.
Coûts d'infrastructure : la réalité des GPU
L'exécution de LLM exige des ressources de calcul considérables. Pas celles d'un ordinateur portable, mais une infrastructure GPU à l'échelle industrielle.
Configuration matérielle requise selon la taille du modèle
Un modèle à 7 milliards de paramètres peut s'exécuter à haute vitesse d'inférence sur un seul GPU NVIDIA L4 (24 Go) ou même sur des GPU RTX 4090/5090 grand public, consommant nettement moins d'énergie qu'un A100. Les modèles à 13 milliards de paramètres nécessitent plusieurs GPU. Les modèles de plus de 70 milliards de paramètres requièrent des clusters de GPU complets.
Ce ne sont pas des cartes graphiques d'entrée de gamme. Selon les prix du marché, un GPU NVIDIA A100 de 80 Go coûte environ 10 000 à 15 000 TP4T. Le modèle H100, plus récent, coûte environ 25 000 à 40 000 TP4T l'unité. La plupart des entreprises ont besoin de plusieurs unités pour leurs charges de travail en production.
| Taille du modèle | Mémoire GPU minimale | Matériel typique | Coût approximatif
|
|---|---|---|---|
| Paramètres 7B | 16-24 Go | 1x A100 40 Go | $10,000-$15,000 |
| Paramètres 13B | 32-48 Go | 1 carte A100 de 80 Go ou 2 cartes A100 de 40 Go | $20,000-$30,000 |
| Paramètres 70B | 140-280 Go | 4x A100 80 Go ou 2x H100 | $50,000-$80,000 |
| 175B+ paramètres | 350 Go+ | 8x A100 80 Go ou cluster GPU | $100,000+ |
Compromis entre le cloud et les solutions sur site
Les organisations sont confrontées à deux options en matière d'infrastructure : construire des centres de données sur site ou louer des instances GPU dans le cloud.
L'infrastructure sur site nécessite un investissement initial important. Les budgets varient de 1 040 000 à plus de 50 000 € pour les déploiements minimaux, jusqu'à plus de 1 040 000 à plus de 500 000 € pour les clusters de production. Mais les coûts d'investissement ne représentent que le point de départ. L'alimentation électrique, le refroidissement, l'espace physique et la maintenance ajoutent entre 20 et 400 000 € par an.
Les instances GPU dans le cloud permettent d'éliminer les coûts initiaux, mais engendrent des frais d'exploitation récurrents. Chez des fournisseurs comme AWS, le coût horaire d'une instance GPU dans le cloud pour une configuration à 8 GPU peut varier entre $20 et $35, soit entre $14 000 et $25 000 par mois en fonctionnement continu. Google Cloud et Azure proposent des structures tarifaires similaires.
Des innovations récentes, comme les techniques de quantification, permettent à certains modèles de fonctionner sur du matériel grand public. D'après la documentation Hugging Face sur les modèles SmallThinker, avec la quantification Q4_0, ces modèles peuvent traiter plus de 20 jetons par seconde sur des processeurs grand public classiques. Cependant, le compromis entre performances et précision limite cette approche à des cas d'utilisation spécifiques.
Les dépenses liées au capital humain : les équipes d’ingénierie dont vous aurez besoin
L'infrastructure est tangible. Ce sont les coûts liés au personnel qui font véritablement exploser les budgets.
Le déploiement et la maintenance de logiciels libres ne constituent pas un projet individuel. Les déploiements en production nécessitent des équipes d'ingénieurs spécialisées dont les salaires dépassent largement les dépenses d'infrastructure.
Exigences de l'équipe principale
- Ingénieurs en apprentissage automatique : Concevoir des pipelines d'inférence, optimiser les performances des modèles, implémenter des techniques telles que la quantification et le traitement par lots. Salaire : 150 000 à 250 000 £ par an. La plupart des organisations ont besoin d'au moins deux personnes pour assurer une couverture complète et une expertise approfondie.
- Ingénieurs MLOps : Gestion de l'infrastructure de déploiement, administration des clusters Kubernetes, maintenance des conteneurs Docker, configuration des quotas GPU et implémentation de solutions d'inférence telles que vLLM ou NVIDIA Triton. Salaire : 140 000 à 230 000 £ par an. Expérience essentielle pour le passage à l'échelle supérieure.
- Ingénieurs en intégration logicielle : D'après les discussions au sein de la communauté, environ 601 000 milliards de dollars d'efforts d'ingénierie dans les projets d'IA sont consacrés au “ code d'interface ” — reliant les modèles aux bases de données, aux systèmes d'authentification et aux interfaces utilisateur. Fourchette de salaire : 130 000 à 200 000 milliards de dollars par an.
- Ingénieurs DevOps/infrastructure : Maintenance des serveurs, gestion du réseau, conformité aux normes de sécurité et gestion de la reprise après sinistre. Salaire : 120 000 à 190 000 £ par an.
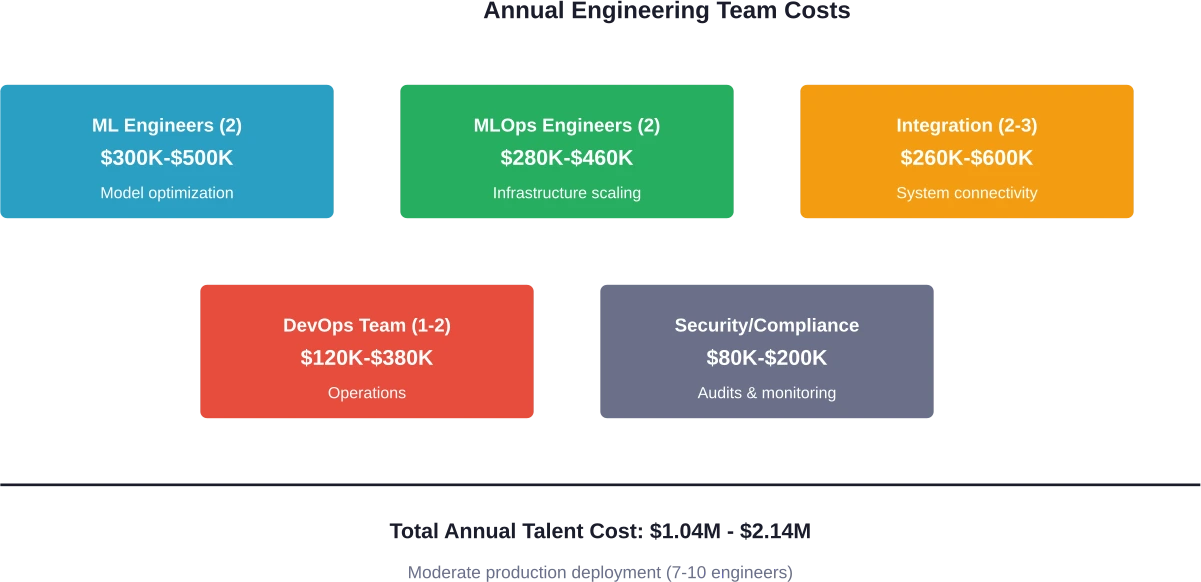
Les déploiements internes de base nécessitent au moins 3 à 4 ingénieurs. Les fonctionnalités destinées aux clients requièrent 7 à 10 ingénieurs. Les déploiements à l'échelle de l'entreprise nécessitent plus de 15 spécialistes.
D'après les tarifs API actuels (2026), les modèles de classe GPT-4 (et leurs successeurs comme GPT-5) coûtent environ $0,0025 à $0,01 par tranche de 1 000 jetons. Un ingénieur en apprentissage automatique coûte $200 000 par an. Cet ingénieur doit vous faire économiser l'équivalent de 6,6 milliards de jetons en appels API rien que pour couvrir son salaire.
Frais généraux opérationnels : La perte mensuelle
Les infrastructures et les salaires constituent des postes de dépenses prévisibles. C'est au niveau des frais généraux d'exploitation que les budgets se heurtent à la réalité.
Surveillance et observabilité
Les applications de production nécessitent une surveillance complète : suivi de la latence, métriques de débit, taux d’erreur, utilisation du GPU, consommation de mémoire et détection de la dégradation de la qualité. Des outils comme Prometheus, Grafana et les plateformes d’observabilité spécialisées en apprentissage automatique représentent un surcoût mensuel de 1 TP4T2 000 à 1 TP4T10 000.
Stockage et transfert de données
Les poids d'un modèle à 70 milliards de paramètres occupent plus de 140 Go d'espace de stockage. Les données d'entraînement, les jeux de données d'ajustement fin et les journaux d'inférence ajoutent des téraoctets. Le stockage cloud coûte entre $0,02 et $0,05 par Go et par mois. Les frais de transfert de données constituent une couche supplémentaire : les frais de sortie des principaux fournisseurs de cloud s'élèvent à $0,08 à $0,12 par Go.
Mise à l'échelle et équilibrage de charge
Les déploiements en production nécessitent une mise à l'échelle automatique pour gérer les variations de charge. Une étude sur le déploiement LLM multi-étapes (simulateur MIST) révèle que des déploiements optimisés peuvent générer jusqu'à 2,8 fois plus de jetons par dollar grâce à des choix architecturaux judicieux. Cependant, la mise en œuvre de ces optimisations requiert une infrastructure sophistiquée.
Les équilibreurs de charge, l'orchestration de conteneurs et les systèmes de redondance ajoutent $5 000 à $25 000 par mois pour les déploiements de moyenne envergure.
Sécurité et conformité
Les modèles auto-hébergés nécessitent des audits de sécurité, des certifications de conformité et une gestion des vulnérabilités. Pour les secteurs réglementés, ces coûts explosent. Les audits de conformité HIPAA coûtent généralement entre 20 000 et 50 000 £ par an pour une infrastructure existante, tandis que la certification SOC 2 Type II coûte entre 30 000 et 60 000 £, frais d'audit inclus.
Scénarios de déploiement : ventilation des coûts réels
Les chiffres abstraits ne veulent rien dire. Voici le coût réel des scénarios de déploiement en 2026.
Scénario 1 : Outil interne minimal
Cas d'utilisation : Chatbot interne pour les questions des employés, 100 à 500 employés, faible volume d'utilisation
Installation:
- Modèle à paramètre unique 7B (Llama 3 ou Mistral)
- 1 carte graphique A100 de 40 Go (hébergée dans le cloud)
- 2 ingénieurs en apprentissage automatique (affectation à temps partiel)
- surveillance et infrastructure de base
Coûts annuels :
- Infrastructure GPU : $15,000-$20,000
- talents en ingénierie (partiel) : $80,000-$120,000
- Surveillance et outils : $10,000-$15,000
- Stockage et mise en réseau : $5,000-$10,000
- Sécurité et conformité : $15,000-$25,000
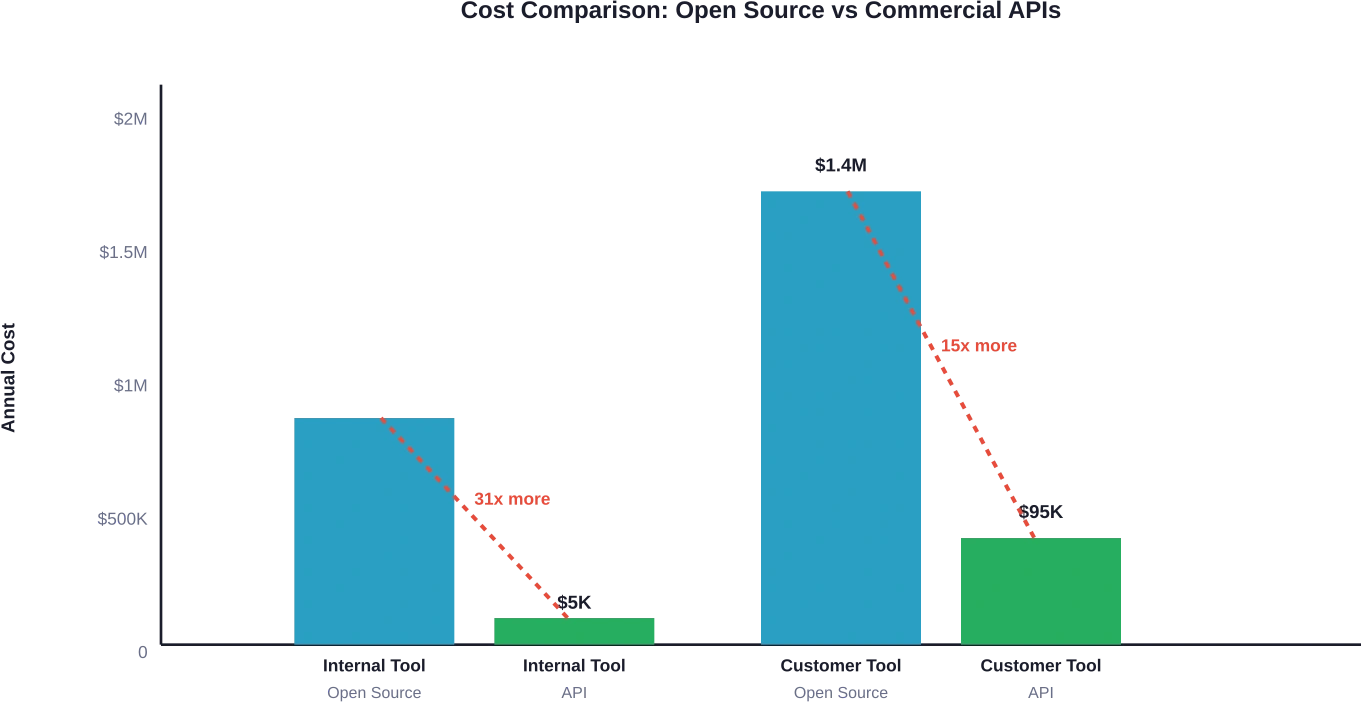
Total : $125 000 à $190 000 par an
À titre de comparaison : une utilisation équivalente via des API commerciales coûterait nettement moins cher par an (généralement entre $3 000 et $15 000 pour des volumes de jetons similaires). Le seuil de rentabilité n’est jamais atteint.
Scénario 2 : Fonctionnalité destinée aux clients
Cas d'utilisation : Chatbot ou génération de contenu pour plus de 10 000 utilisateurs actifs mensuels, utilisation modérée
Installation:
- Modèle paramétrique 13B-70B avec réglage fin
- 4 GPU A100 de 80 Go avec mise à l'échelle automatique
- 7 à 10 membres de l'équipe d'ingénierie
- Surveillance et fiabilité de niveau production
- Assistance téléphonique 24h/24 et 7j/7
Coûts annuels :
- Infrastructure GPU : $120,000-$200,000
- Équipe d'ingénierie : $700,000-$1,400,000
- Surveillance et observabilité : $30,000-$60,000
- Stockage, réseau, CDN : $25,000-$50,000
- Sécurité, conformité, audits : $50,000-$80,000
- Intervention d'urgence et réponse aux incidents : $25,000-$30,000
Total : $950 000 à $1 820 000 par an
Équivalent d'une API commerciale : environ 1 TP4 T40 000 à 1 TP4 T150 000 par an pour des usages similaires, selon le modèle choisi. L'auto-hébergement n'est rentable qu'au-delà de 500 millions à 1 milliard de jetons par mois.
Scénario 3 : Produit de base de l’entreprise
Cas d'utilisation : LLM comme moteur de produit principal, millions d'utilisateurs, exigences de haute disponibilité
Installation:
- Plusieurs modèles à plus de 70 milliards de paramètres avec tests A/B
- Cluster GPU (16 à 32 unités) réparti sur plusieurs régions
- 15 à 25 ingénieurs spécialistes
- Infrastructure de niveau entreprise avec redondance
- Équipes dédiées à la sécurité et à la conformité
Coûts annuels :
- Infrastructure GPU : $1,500,000-$3,000,000
- Équipes d'ingénierie : $2,500,000-$5,000,000
- Suivi et analyse : $200,000-$400,000
- Stockage et mise en réseau : $300,000-$600,000
- Sécurité et conformité : $400,000-$800,000
- Formation et R&D : $500,000-$1,000,000
Total : $5 400 000 à $10 800 000 par an
Cette échelle représente le seuil à partir duquel l'auto-hébergement devient potentiellement compétitif en termes de coûts avec les API commerciales pour des modèles d'utilisation mensuels compris entre 500 millions et plus d'un milliard de jetons.
Quand l'open source devient réellement rentable
Le déploiement de solutions open source n'est pas systématiquement une erreur. Dans certains cas spécifiques, cet investissement se justifie.
Analyse du seuil de rentabilité
Les recherches analysant les aspects économiques du déploiement sur site identifient des seuils de rentabilité critiques où les modèles auto-hébergés deviennent compétitifs en termes de coûts par rapport aux services commerciaux.
Le seuil dépend du volume de jetons. Pour les charges de travail d'entreprise typiques :
- Moins de 100 millions de jetons par mois : Les API commerciales l'emportent de façon décisive
- 100 à 500 millions de jetons par mois : Les coûts tendent vers la parité, mais les API restent souvent moins chères une fois les frais généraux d'ingénierie pris en compte.
- 500 millions à 1 milliard de jetons par mois : Zone de rentabilité où l'auto-hébergement peut justifier les coûts
- Plus d'un milliard de jetons par mois : L'auto-hébergement présente des avantages de coûts évidents.
Mais le volume brut de jetons n'est pas le seul facteur.
Facteurs non financiers
- Confidentialité et souveraineté des données : Les secteurs réglementés qui traitent des données sensibles (santé, finance, administration publique) sont soumis à des exigences de conformité qui interdisent l'utilisation d'API externes. L'auto-hébergement devient alors obligatoire, quel qu'en soit le coût.
- Exigences de latence : Les applications exigeant un temps de réponse inférieur à 100 ms ne tolèrent pas les allers-retours réseau vers les API externes. Selon une analyse de Hugging Face comparant l'inférence en périphérie et dans le cloud, la distance et la congestion du réseau ont un impact significatif sur la latence p95. Pour les applications critiques en termes de latence, le déploiement local est indispensable.
- Niveau de personnalisation : Les modèles hautement personnalisés, nécessitant un réglage fin poussé, un entraînement spécifique au domaine et des architectures spécialisées, justifient l'investissement dans un hébergement dédié. À titre d'exemple, citons le modèle DeepSeek R1 qui, selon les rapports sur l'évolution du paysage informatique, a nécessité moins de $300 000 unités de calcul après l'entraînement.
- Indépendance stratégique : Les organisations qui développent des produits axés sur l'IA peuvent privilégier l'indépendance vis-à-vis des fournisseurs et le contrôle plutôt que l'optimisation des coûts à court terme.
| Facteur de décision | Privilégier l'open source lorsque | Privilégiez les API commerciales lorsque
|
|---|---|---|
| Volume de jetons | Plus de 500 millions par mois | Moins de 500 millions par mois |
| Exigence de latence | Moins de 100 ms p95 | 200 ms et plus acceptable |
| Sensibilité des données | Données réglementées/classifiées | Charges de travail non sensibles |
| Besoins de personnalisation | Réglage fin poussé | Fonctionnalités standard |
| Expertise de l'équipe | Équipes ML/infrastructure existantes | Ressources techniques limitées |
| Disponibilité des capitaux | Possibilité d'investir $500K+ immédiatement | Privilégier les dépenses opérationnelles |
Les coûts cachés qui font capoter les projets
Au-delà des dépenses évidentes, plusieurs coûts cachés font dérailler les déploiements open source.
Mises à jour des modèles et dérive
Les modèles se dégradent avec le temps. La distribution des données évolue. Les attentes des utilisateurs changent. Les API commerciales gèrent les mises à jour automatiquement. Les déploiements auto-hébergés nécessitent une intervention manuelle.
La mise à jour ou le réentraînement des modèles nécessitent davantage de temps de calcul GPU, d'efforts d'ingénierie et de cycles de test. Prévoyez un budget annuel de $50 000 à $200 000 pour la maintenance continue des modèles.
Coût d'opportunité
Les équipes d'ingénierie qui développent l'infrastructure LLM ne créent pas de fonctionnalités produit. Le coût d'opportunité pour sept ingénieurs de consacrer six mois à l'infrastructure de déploiement représente entre $350 000 et $700 000 en salaires, auquel s'ajoute la valeur non réalisée des fonctionnalités qu'ils n'ont pas développées.
Expériences ratées
Tous les déploiements ne sont pas couronnés de succès. Tester plusieurs modèles, architectures et stratégies d'optimisation est gourmand en ressources. Chaque preuve de concept infructueuse coûte entre $25 000 et $100 000 en temps d'ingénierie et en infrastructure.
Dette technique
Les déploiements précipités engendrent une dette technique qui s'accumule avec le temps. Des pipelines d'inférence mal conçus, une surveillance insuffisante et des intégrations fragiles nécessitent des refactorisations coûteuses. Remédier à cette dette technique coûte 3 à 5 fois plus cher qu'une conception correcte dès le départ.
Stratégies d'optimisation qui fonctionnent réellement
Les organisations qui optent pour l'auto-hébergement peuvent mettre en œuvre des stratégies pour réduire les coûts.
Quantification et compression
La quantification des modèles réduit les besoins en mémoire et accélère l'inférence. Des études montrent que la quantification Q4_0 permet aux modèles de dépasser 20 tokens par seconde sur du matériel grand public. Cette technique réduit les coûts d'infrastructure de 50 à 751 Tk3 avec un impact minimal sur la précision pour de nombreuses tâches.
Cadres d'optimisation de l'inférence
Les serveurs d'inférence spécialisés tels que vLLM, NVIDIA Triton et Text Generation Inference améliorent considérablement le débit. Ces frameworks peuvent multiplier par 2 à 5 le nombre de jetons traités par seconde par rapport aux implémentations classiques.
Les gains de performance se traduisent directement par des économies de coûts : moins de GPU pour un débit équivalent.
Approches hybrides
Les organisations intelligentes ne choisissent pas “ tout open-source ” ou “ toutes les API ”. Les stratégies hybrides utilisent des API commerciales pour les charges de travail variables et les pics de trafic, tout en conservant une infrastructure auto-hébergée pour la charge de base.
Cette approche permet d'optimiser les coûts : les API gèrent les pics de trafic sans surdimensionner l'infrastructure, tandis que les modèles auto-hébergés traitent les charges de travail prévisibles de manière rentable.
Modèles spécialisés plus petits
Les modèles plus grands ne sont pas toujours meilleurs. La gamme SmallThinker démontre que des modèles plus petits et conçus pour un usage spécifique peuvent surpasser les modèles LLM plus grands et généralistes sur des tâches particulières. Un modèle 7B bien optimisé coûte 90% de moins à exécuter qu'un modèle 70B tout en offrant potentiellement de meilleures performances pour des tâches spécifiques.

Cadre de calcul du coût total de possession (TCO)
Les organisations ont besoin d'une approche systématique pour calculer le coût total de possession avant de prendre des décisions de déploiement.
- Étape 1 : Estimer le volume de jetons. Calculer la consommation mensuelle prévue de jetons en fonction du nombre d'utilisateurs, des habitudes d'utilisation et des besoins fonctionnels. Inclure les jetons d'entrée et de sortie.
- Étape 2 : Calculez le volume de jetons de référence de l'API commerciale. Multipliez ce volume par le prix de l'API commerciale. Tenez compte des différents niveaux de modèles si vous utilisez plusieurs tailles de modèles.
- Étape 3 : Définir les besoins en infrastructure. Déterminer le nombre et les spécifications des GPU en fonction de la taille du modèle, des exigences de latence et des besoins de redondance. Inclure le réseau, le stockage et la puissance de calcul.
- Étape 4 : Estimer les ressources d'ingénierie nécessaires. Dénombrer les ETP requis pour l'ingénierie ML, le MLOps, l'intégration, l'infrastructure et la sécurité. Inclure la phase de développement initial et la maintenance continue.
- Étape 5 : Ajouter les frais généraux d'exploitation. Inclure les coûts de surveillance, de sécurité, de conformité, de stockage des données, de bande passante et de réponse aux incidents.
- Étape 6 : Tenez compte des coûts cachés. Intégrez le coût d'opportunité, les échecs expérimentaux, la dette technique et les cycles de maintenance des modèles.
- Étape 7 : Calculez le seuil de rentabilité. Déterminez le volume de jetons à partir duquel les coûts totaux d'une API auto-hébergée égalent les coûts d'une API commerciale. La plupart des organisations constatent que ce seuil se situe entre 500 millions et 1 milliard de jetons par mois.

Réduisez les coûts de déploiement des logiciels LLM open source avant qu'ils ne prennent de l'ampleur.
Les solutions LLM open source semblent peu coûteuses au premier abord, mais les coûts de déploiement augmentent souvent rapidement dès lors que l'infrastructure, la surveillance, la mise à l'échelle et l'intégration sont prises en compte. IA supérieure Il travaille sur les aspects techniques des systèmes LLM : conception des architectures de modèles, mise en place de l’infrastructure et intégration des modèles dans les environnements existants afin qu’ils fonctionnent efficacement en production.
Si vous déployez des LLM open source en 2026, il est utile de revoir l'architecture et le pipeline de déploiement au plus tôt. Contactez-nous IA supérieure pour évaluer votre configuration de déploiement et identifier les points où les coûts d'infrastructure et d'inférence peuvent être réduits.
La réalité de 2026
Les coûts de déploiement des modèles LLM open source diminuent, mais pas aussi fortement que les capacités des modèles ne s'améliorent.
Les prix des GPU restent obstinément élevés en raison d'une demande soutenue. Les salaires des ingénieurs spécialisés en IA continuent de progresser ; les ingénieurs en apprentissage automatique possédant une expérience en master sont très recherchés et bénéficient d'une croissance salariale compétitive.
Parallèlement, les prix des API commerciales sont en baisse. Selon une analyse de Hugging Face sur les tendances du marché du calcul, les prix des API commerciales ont considérablement diminué par rapport aux tarifs de 2024. Claude et Gemini affichent des trajectoires similaires. L'économie est de plus en plus favorable aux API pour la plupart des cas d'utilisation.
L'open source dominera certains créneaux spécifiques : les secteurs réglementés, les applications critiques en termes de latence, les organisations traitant des milliards de jetons par mois et les entreprises développant des produits différenciés axés sur l'IA. Pour tous les autres ? Les API sont plus avantageuses financièrement.
Le modèle open source “ gratuit ” coûte au minimum $125 000 et probablement plus de $500 000 pour une production à grande échelle. Ce n'est pas une critique de l'open source, c'est simplement un constat mathématique.
Questions fréquemment posées
Quel est le budget minimum réaliste pour déployer un LLM open-source ?
Le déploiement minimal d'outils internes nécessite un budget annuel de $125 000 à $190 000, couvrant l'infrastructure GPU de base, une partie des ressources d'ingénierie, la surveillance et les frais d'exploitation. Un budget inférieur à ce seuil indique un projet sous-financé et susceptible d'échouer.
Combien de jetons par mois rendent l'auto-hébergement rentable ?
Les études montrent que le seuil de rentabilité pour l'auto-hébergement se situe entre 500 millions et 1 milliard de jetons par mois, moment où les coûts se rapprochent de ceux des API commerciales. En dessous de 500 millions de jetons par mois, les API sont presque toujours moins coûteuses une fois les frais d'ingénierie et d'exploitation correctement pris en compte.
Les modèles plus petits peuvent-ils réduire considérablement les coûts de déploiement ?
Oui. Un modèle à 7 milliards de paramètres bien optimisé coûte 85 à 900 TP3T de moins à exploiter qu'un modèle à 70 milliards de paramètres. Associés à un réglage fin adapté à la tâche, les modèles plus petits atteignent souvent des performances égales, voire supérieures, à celles des modèles plus grands pour des applications spécifiques, réduisant ainsi considérablement les besoins en infrastructure.
Quel est le coût caché le plus important dans le déploiement de solutions LLM open source ?
Les compétences en ingénierie représentent généralement une part importante du coût total de déploiement, soit le principal poste de dépenses caché dans la plupart des déploiements organisationnels. Les ingénieurs en apprentissage automatique, les spécialistes MLOps et les développeurs d'intégration perçoivent des salaires annuels de 140 000 à 250 000 £. Un déploiement de taille moyenne requiert 7 à 10 spécialistes, ce qui engendre des coûts de main-d'œuvre annuels de 1 à 2 millions de £.
Les techniques de quantification permettent-elles réellement de réaliser des économies sans nuire à la qualité ?
Les techniques de quantification comme Q4_0 peuvent réduire les coûts d'infrastructure de 50 à 751 TP3T avec une dégradation minimale de la précision pour de nombreuses tâches. Des recherches démontrent que les modèles quantifiés atteignent plus de 20 jetons par seconde sur du matériel grand public. Cependant, l'impact sur la précision varie selon la tâche ; des tests approfondis sont donc essentiels avant le déploiement en production.
Les startups devraient-elles utiliser des LLM open source ou des API commerciales ?
La plupart des startups devraient privilégier les API commerciales. Leur flexibilité, leurs coûts prévisibles et l'absence de frais d'exploitation permettent d'accélérer l'itération et le développement produit. L'auto-hébergement n'est pertinent que pour les projets à très grande échelle, la gestion de données réglementées ou le développement de capacités d'IA hautement différenciées, essentielles à un avantage concurrentiel.
Combien coûte l'optimisation d'un modèle open source ?
Le coût du réglage fin varie considérablement selon la taille du modèle et l'ensemble de données. Un réglage fin minimal d'un modèle de 7 milliards d'éléments coûte entre 1 400 000 et 1 400 000 ¥, temps de calcul GPU et efforts d'ingénierie inclus. Un réglage fin poussé de modèles de 70 milliards d'éléments avec de grands ensembles de données peut dépasser 1 400 000 à 300 000 ¥. Des exemples remarquables ont permis d'obtenir des résultats impressionnants avec un investissement réduit : des modèles plus petits ont démontré des performances comparables pour un coût bien moindre.
Conclusion : Faites vos calculs avant de vous engager.
Le déploiement open source de LLM n'est pas gratuit. Il représente un investissement conséquent en ingénierie et en infrastructure, qui n'est rentable qu'à certaines échelles et pour des cas d'utilisation spécifiques.
Les API commerciales constituent le choix économiquement rationnel pour la majorité des applications traitant moins de 500 millions de jetons par mois. Elles sont nettement moins coûteuses pour les outils internes, les applications destinées aux employés et les fonctionnalités client de taille moyenne.
L'auto-hébergement justifie l'investissement lors du traitement de volumes massifs de jetons (plus d'un milliard par mois), de la gestion de données réglementées ou sensibles nécessitant un déploiement sur site, du respect d'exigences de latence extrêmes ou de la construction de modèles hautement personnalisés essentiels à la différenciation des produits.
Calculez honnêtement votre coût total de possession. Incluez l'infrastructure, les ressources d'ingénierie, les frais généraux d'exploitation, les coûts cachés et les coûts d'opportunité. Comparez ce chiffre aux prix des API commerciales pour une utilisation équivalente. Les chiffres sont généralement fiables.
Et si les chiffres penchent toujours en faveur de l'auto-hébergement pour votre cas particulier ? Prévoyez un budget deux fois supérieur à votre estimation initiale. Les déploiements en production coûtent toujours plus cher que prévu.
Prêt à calculer précisément les coûts de déploiement de votre solution LLM ? Commencez par estimer le volume de jetons et remontez jusqu'aux besoins en infrastructure et en talents. L'analyse du seuil de rentabilité vous indiquera si les API open source ou commerciales sont financièrement adaptées aux besoins spécifiques de votre organisation.