Quick Summary: LLM analytics tools with cost optimization features help organizations monitor token usage, track spending patterns, and reduce AI infrastructure expenses through intelligent caching, model selection, and automated resource allocation. Leading platforms combine real-time cost tracking with performance observability to identify expensive workflows and optimize without sacrificing response quality. Effective cost management requires session-based tracking, prompt optimization, and strategic model selection based on task complexity.
Organizations deploying large language models face a fundamental challenge: costs can spiral out of control before anyone notices. Token-based pricing means every API call adds up, and without proper analytics, that support chatbot or document analyzer might be burning through budgets at an alarming rate.
The explosion of LLM adoption has created urgent demand for specialized analytics platforms. These tools don’t just track spending—they actively identify optimization opportunities, automate cost reduction strategies, and provide the visibility needed to make informed decisions about model selection and infrastructure.
Here’s the thing though—not all analytics platforms are created equal. Some focus purely on observability, others prioritize cost tracking, and the best combine both with actionable optimization features. Understanding which capabilities matter most for your use case makes the difference between managing costs effectively and throwing money at a problem.
Understanding LLM Cost Structures and Pricing Models
Token-based pricing dominates the LLM landscape. According to Anthropic’s official pricing, Claude Opus 4.6 costs $5 per million input tokens and $25 per million output tokens. That pricing asymmetry matters—output tokens cost five times more than input tokens.
The general rule: longer prompts and longer generated responses mean higher token counts and higher costs.
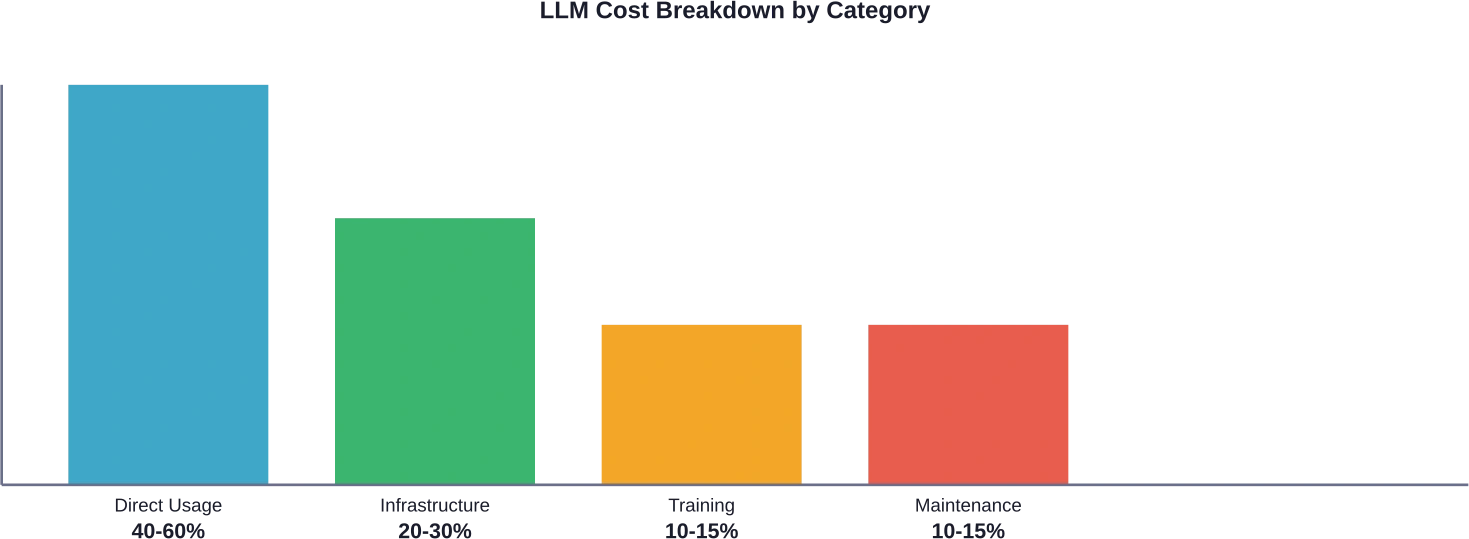
Real talk: most organizations underestimate their true LLM costs. According to industry analysis, direct usage fees can represent 40-60% of total LLM expenses, with infrastructure and integration consuming 20-30%, and training and optimization making up the remainder.
The Hidden Cost Multipliers
AWS documentation indicates that prompt caching can reduce inference response latency by up to 85% and input token costs by up to 90% for supported models on Amazon Bedrock. But without analytics to identify cacheable patterns, organizations miss these savings entirely.
According to AWS case studies, processing requests have ranged from 6.76 seconds to 32.24 seconds in total duration, with variation primarily reflecting different output token requirements. Quick responses under 10 seconds typically handle simple queries, while complex analytical tasks push beyond 30 seconds.
Context window sizes compound costs too. Claude Opus 4.6 features a 1M token context window in beta—powerful, but expensive if organizations routinely send unnecessarily large contexts.
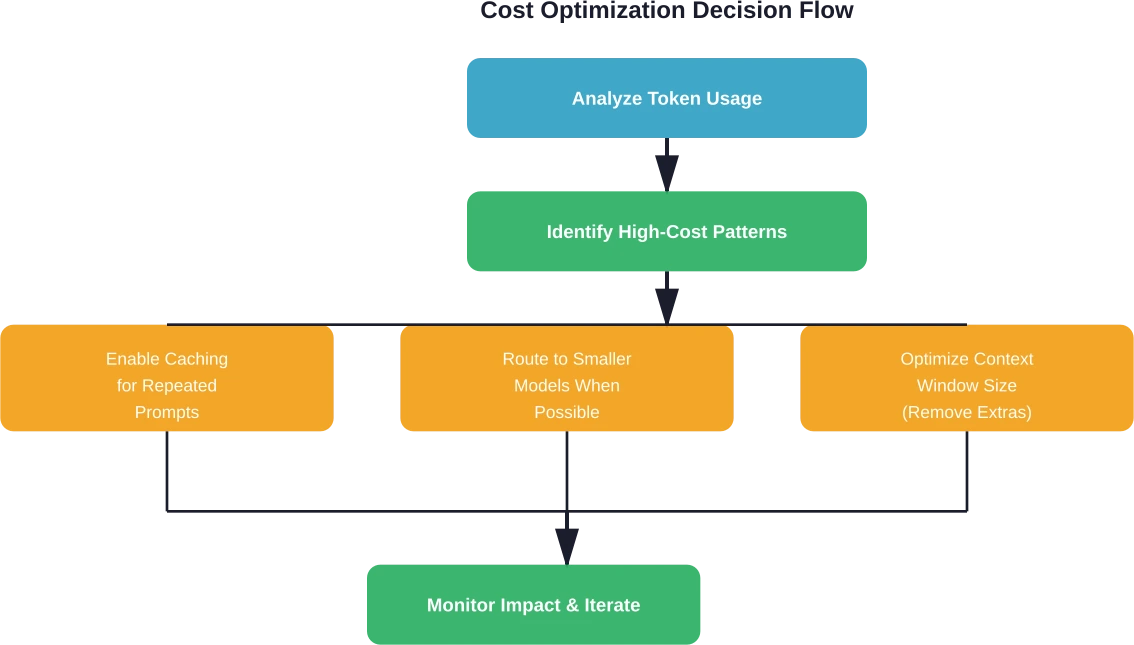
Core Features of LLM Analytics Platforms
Effective LLM analytics platforms deliver three fundamental capabilities: comprehensive cost tracking, performance observability, and actionable optimization insights. Each component serves a distinct purpose in managing AI workloads.
Session-Based Cost Tracking
Sessions group related requests to show the true cost of user interactions. Instead of seeing individual API calls, teams see complete workflows. According to cost tracking examples, support chats cost approximately $0.12 on average with 5 API calls, document analysis workflows cost around $0.45 with 12 API calls, while quick queries cost approximately $0.02 with a single call.
This granularity matters. Organizations can identify which interaction types drive costs and optimize accordingly. The alternative—treating every API call as isolated—obscures the real unit economics of AI features.
Real-Time Usage Monitoring
Token consumption patterns reveal optimization opportunities. Analytics platforms track input versus output token ratios, identify expensive prompts, and flag anomalous usage spikes before they impact budgets.
But wait. Real-time monitoring only helps if it triggers action. The best platforms integrate automated alerting and budget thresholds that prevent runaway costs.
Model Performance Comparison
Different models excel at different tasks. Analytics tools enable A/B testing across models to find the optimal balance between cost and quality for each use case.
According to MIT-IBM Watson AI Lab research, 4% average relative error represents the best achievable accuracy due to random seed noise, but up to 20% error remains useful for decision-making. Organizations must define acceptable performance thresholds before optimizing costs.
Cost Optimization Strategies Enabled by Analytics Tools
Analytics platforms don’t just report costs—they enable specific optimization strategies that directly reduce spending without sacrificing functionality.
Intelligent Prompt Caching
Prompt caching stores frequently used prompt segments and reuses them across requests. Caching delivers substantial latency improvements, with AWS documenting response time reductions of up to 85% for cached queries. But without analytics to identify cacheable patterns, organizations miss these savings entirely.
Two caching approaches dominate: system-level caching stores common prompt prefixes, while request-response caching stores complete query-answer pairs for reuse. Analytics tools identify which prompts benefit most from caching based on repetition frequency and token length.
Strategic Model Selection
A cost-benefit analysis of on-premise LLM deployment from Carnegie Mellon establishes that benchmark scores within 20% of leading commercial models reflect enterprise practice, where modest performance gaps remain acceptable for cost reduction.
Analytics platforms surface opportunities to route requests to less expensive models when quality requirements permit. Simple classification tasks don’t need frontier models—smaller, cheaper alternatives perform adequately.
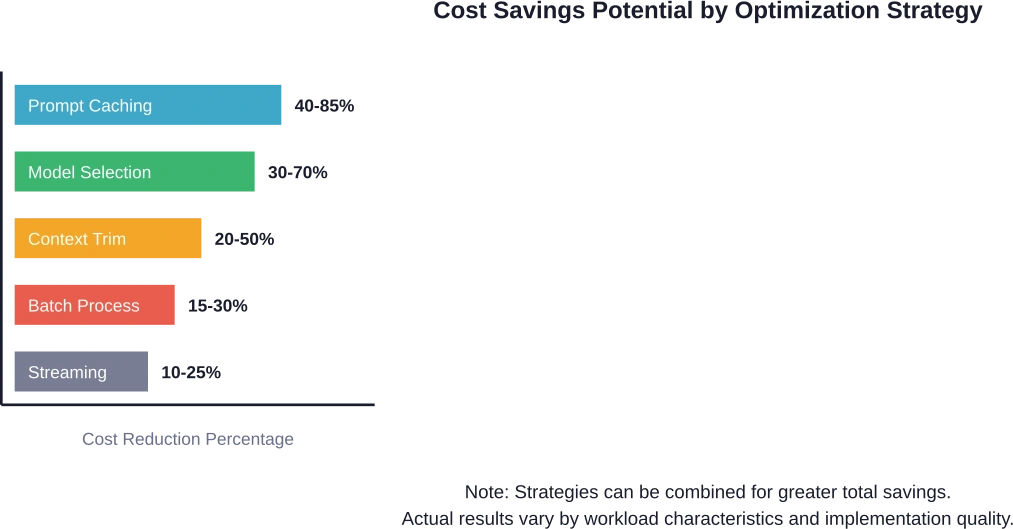
| Strategy | Cost Reduction | Implementation Complexity | Quality Impact
|
|---|---|---|---|
| Prompt caching | 40-85% | Low | None |
| Model selection | 30-70% | Medium | Task-dependent |
| Context optimization | 20-50% | Medium | None to minimal |
| Batch processing | 15-30% | High | Adds latency |
| Response streaming | 10-25% | Low | None |
Context Window Optimization
Many applications send unnecessarily large contexts with every request. Analytics reveal average context sizes and identify opportunities to trim irrelevant information.
Shorter contexts mean fewer input tokens and faster processing. Industry case studies report significant cost reductions through systematic context optimization.
Automated Quality Thresholds
OpenAI research on self-evolving agents recommends continuing optimization cycles until quality thresholds reach >80% positive feedback or new iterations show minimal improvement. Analytics platforms track these metrics and signal when further optimization delivers diminishing returns.

Reduce LLM Costs With the Right Engineering Partner
Many companies adopt LLM analytics tools to monitor usage, token consumption, and model performance, but the biggest cost savings usually come from how the models are built and integrated in the first place. This is where AI Superior often gets involved. Their team works on the technical layer behind LLM systems—designing custom models, preparing training data, fine tuning architectures, and integrating LLMs into existing workflows so companies can control performance and operating costs more effectively.
If you are trying to reduce LLM spending in 2026, it may be worth reviewing how your models are trained, deployed, and monitored. A technical audit or architecture review can often reveal unnecessary inference costs, inefficient pipelines, or poorly optimized models.
Talk to AI Superior if you want to evaluate your current LLM setup and identify practical ways to reduce long term operating costs.
Comparing Leading LLM Analytics Platforms
The analytics platform landscape includes specialized observability tools, cloud provider native solutions, and open-source alternatives. Each category offers distinct advantages.
Cloud Provider Native Solutions
AWS, Google Cloud, and Azure offer integrated analytics within their broader AI platforms. Amazon Bedrock usage and costs are monitored through AWS Billing and Cost Management reports and AWS Cost Explorer APIs, allowing programmatic access to organization-wide spending data.
Google’s Conversational Insights provides two pricing tiers—Standard and Enterprise—with costs varying based on interaction type. Chat conversations charge per message, while voice conversations charge per minute. Enterprise tier adds Quality AI capabilities with support for up to 50 custom evaluations per conversation.
Native solutions integrate seamlessly with existing cloud infrastructure but may lack advanced optimization features found in specialized platforms.
Specialized Observability Platforms
Dedicated LLM observability platforms focus exclusively on monitoring and optimizing AI workloads. These tools typically offer deeper analytics, more sophisticated optimization features, and vendor-agnostic support across multiple LLM providers.
Key capabilities include request tracing across distributed systems, latency analysis, error rate monitoring, and cost attribution by feature or team. The best platforms surface actionable insights rather than just raw metrics.
Open Source Alternatives
Open source analytics tools appeal to organizations with specific requirements or budget constraints. These solutions offer transparency and customization but require more technical investment to deploy and maintain.
Community-driven development means features evolve based on real user needs, though enterprise support and documentation may lag commercial alternatives.
| Platform Type | Best For | Key Advantage | Primary Limitation
|
|---|---|---|---|
| Cloud Native | Single-cloud deployments | Deep integration | Vendor lock-in |
| Specialized Tools | Multi-model environments | Advanced optimization | Additional cost |
| Open Source | Custom requirements | Transparency & control | Maintenance burden |
Implementation Best Practices for Cost Analytics
Deploying analytics tools effectively requires careful planning and realistic expectations about optimization timelines.
Establishing Baseline Metrics
Organizations can’t optimize what they don’t measure. Start by tracking total token consumption, average cost per user interaction, and distribution of expenses across different features or use cases.
Baseline measurement should run for at least two weeks to capture representative usage patterns. Seasonal variations or usage spikes impact averages, so longer measurement periods provide more reliable data.
Setting Realistic Optimization Goals
Research from MIT-IBM Watson AI Lab emphasizes deciding on compute budget and target model accuracy before optimization begins. Teams should define whether 4% average relative error or 20% error meets their decision-making needs.
Aggressive cost reduction targets sometimes compromise functionality. The goal isn’t minimum spending—it’s optimal spending for required quality levels.
Implementing Gradual Rollouts
Don’t optimize everything simultaneously. Test caching strategies on high-volume endpoints first, measure impact, then expand to other areas.
Gradual rollouts isolate variables and make it easier to attribute cost reductions to specific changes. They also minimize risk—if optimization negatively impacts user experience, the blast radius remains small.
Continuous Monitoring and Iteration
Cost optimization isn’t a one-time project. Usage patterns evolve, new models launch with different pricing, and application requirements change.
Schedule quarterly reviews of analytics data to identify emerging patterns. Automation reduces manual overhead—platforms that automatically flag optimization opportunities save significant time.
Advanced Optimization Techniques
Beyond basic cost tracking, advanced techniques deliver additional savings for sophisticated deployments.
Multi-Agent Model Routing
Research on optimization from natural language using LLM-powered agents demonstrates that combining diverse models leads to performance gains. A framework achieved 88.1% accuracy on the NLP4LP dataset and 82.3% on Optibench, reducing error rates by 58% and 52% respectively over prior results through multi-agent collaboration.
Analytics platforms can implement intelligent routing that sends requests to the most cost-effective model capable of handling each task. Simple queries route to fast, inexpensive models. Complex reasoning tasks escalate to more capable—and expensive—alternatives.
Grouped-Query Attention Optimization
For organizations running self-hosted models, attention mechanism configuration impacts costs significantly. Research on cost-optimal grouped-query attention for long-context modeling shows that for long-context scenarios, using fewer attention heads while scaling up model size reduces both memory usage and FLOPs by more than 50% compared to Llama-3’s GQA configuration, with no degradation in model capabilities.
This matters for custom deployments where infrastructure costs factor heavily into total expenses.
Automated Retraining Loops
OpenAI research on self-evolving agents introduces repeatable retraining loops that capture edge cases and correct failures without constant human intervention. Systems that identify low-quality outputs and automatically retrain based on feedback reduce both error rates and the token waste from regenerating failed responses.
Analytics platforms tracking output quality metrics enable these automated improvement cycles, creating compounding cost benefits over time.
Evaluating ROI from Analytics Investments
Analytics platforms represent additional costs—subscriptions, integration effort, ongoing maintenance. Organizations need frameworks to evaluate whether investments deliver positive returns.
Calculating Breakeven Points
Research on cost-benefit analysis of on-premise LLM deployment examines when organizations break even versus commercial services. The same methodology applies to analytics tools: calculate monthly LLM spending, estimate achievable cost reduction percentage based on optimization features, and compare against platform subscription costs.
For example, if monthly LLM costs reach $50,000 and analytics enable 30% reduction through caching and model selection, that represents $15,000 monthly savings. An analytics platform costing $2,000 per month breaks even immediately and delivers $13,000 net monthly benefit.
Quantifying Operational Efficiency Gains
Cost reduction represents only part of the value equation. Analytics platforms reduce time engineers spend manually investigating performance issues, debugging expensive queries, and generating usage reports.
Based on industry reports, teams have achieved significant productivity increases when proper analytics remove debugging bottlenecks. Time savings translate directly to labor cost reductions or increased development velocity.
Factoring Risk Mitigation Value
Budget alerts and anomaly detection prevent cost disasters. Organizations without proper monitoring discover runaway costs days or weeks after they occur—when bills arrive.
The value of avoiding a single $100,000 surprise bill justifies significant analytics investment. Risk mitigation benefits are harder to quantify but materially impact total cost of ownership.
On-Premise vs Cloud-Based Analytics
Organizations deploying self-hosted LLMs face different analytics requirements than those using commercial APIs exclusively.
Cloud Analytics Advantages
Cloud-based analytics platforms require minimal setup, scale automatically, and receive continuous feature updates without manual intervention. They work well for organizations using commercial LLM services where API-level tracking provides sufficient visibility.
Integration typically involves adding SDK calls or routing requests through gateway services—straightforward for most development teams.
On-Premise Deployment Considerations
Self-hosted analytics suit organizations with strict data governance requirements or those running proprietary models internally. According to research on intelligence per watt from Stanford, local LLMs can accurately respond to 88.7% of single-turn chat and reasoning tasks, making self-hosting viable for many use cases.
But on-premise deployments carry higher complexity. Organizations need infrastructure for the analytics platform itself, must handle updates manually, and require specialized expertise to maintain systems.
Hybrid Approaches
Many organizations adopt hybrid strategies: cloud analytics for commercial LLM usage combined with on-premise monitoring for self-hosted models. This balances convenience with control while maintaining comprehensive visibility across the entire AI stack.
Future Trends in LLM Cost Analytics
The analytics landscape continues evolving rapidly as organizations demand more sophisticated capabilities.
Predictive Cost Modeling
Next-generation platforms will predict future costs based on usage trends, application changes, and model pricing shifts. Proactive alerts warn teams before costs spike rather than reporting problems retroactively.
Machine learning models trained on historical usage patterns can forecast monthly spending with increasing accuracy, enabling better budget planning.
Automated Optimization Agents
Research on automated optimization of LLM-based agents (ARTEMIS) demonstrates systems that continuously experiment with configuration changes, measure impact, and automatically implement improvements without human involvement.
These self-optimizing systems could revolutionize cost management by removing manual optimization work entirely. Early implementations show promising results but remain experimental.
Cross-Provider Unified Analytics
Organizations increasingly use multiple LLM providers—OpenAI for some tasks, Anthropic for others, open source models for specific use cases. Unified analytics across all providers remain challenging.
Future platforms will offer seamless multi-provider tracking, enabling true apples-to-apples cost comparisons and intelligent routing across vendors based on real-time pricing and performance data.
Common Implementation Challenges
Organizations encounter predictable obstacles when deploying analytics platforms. Anticipating these challenges accelerates successful implementation.
Incomplete Usage Attribution
Tracking which team, feature, or user generated specific costs requires instrumentation throughout applications. Many organizations initially capture overall usage but lack granular attribution.
Solution: implement consistent tagging standards from the start. Add metadata to every LLM request identifying source application, user type, and feature category.
Alert Fatigue
Overly sensitive cost alerts train teams to ignore notifications. If every minor usage spike triggers alarms, important warnings get dismissed along with noise.
Solution: set alert thresholds based on statistical significance rather than absolute changes. A 10% cost increase might warrant investigation if sustained over several days but not if it occurs for a single hour.
Optimization Analysis Paralysis
Some teams spend more time analyzing optimization opportunities than implementing them. Detailed investigation of every potential improvement becomes counterproductive.
Solution: apply the 80/20 rule. Focus on the highest-impact optimizations first—typically caching for repetitive workloads and model selection for high-volume endpoints. Smaller optimizations can wait.
Frequently Asked Questions
How much can organizations realistically reduce LLM costs with analytics tools?
Cost reduction varies significantly based on initial efficiency and workload characteristics. Organizations with repetitive queries and no existing caching can achieve 50-70% reductions through prompt caching alone. Those already implementing basic optimizations typically see 20-40% additional savings through strategic model selection and context optimization. The key is identifying where your specific deployment wastes resources—analytics platforms excel at surfacing these opportunities.
Do analytics platforms work with all LLM providers?
Most specialized analytics platforms support major commercial providers including OpenAI, Anthropic, Google, and AWS Bedrock through standard API integrations. Cloud-native solutions typically work only within their respective ecosystems—AWS tools for Bedrock, Google tools for Vertex AI. For self-hosted models or smaller providers, compatibility depends on whether the platform offers custom integration capabilities or requires specific instrumentation.
What’s the typical implementation timeline for LLM analytics?
Basic analytics integration takes 1-2 weeks for cloud-based platforms using standard SDKs. This includes setup, basic tagging implementation, and initial dashboard configuration. Comprehensive deployment with session tracking, custom attribution, and optimization automation requires 4-8 weeks depending on application complexity. Organizations with distributed systems or custom LLM implementations should expect 2-3 months for full rollout including testing and refinement.
Should small teams invest in dedicated analytics platforms?
Teams spending under $5,000 monthly on LLM usage can often manage costs adequately with basic cloud provider native tools and manual monitoring. The complexity and expense of dedicated platforms may outweigh benefits at this scale. Once monthly LLM costs exceed $10,000-$15,000, specialized analytics typically deliver positive ROI through automated optimization and detailed visibility. Calculate your potential savings—if realistic cost reductions exceed platform subscription costs by 3x or more, investment makes sense.
How do analytics tools handle rate limiting and quota management?
Advanced platforms include custom rate limiting features that prevent applications from exceeding configured usage thresholds. These systems intercept requests before they reach LLM providers, rejecting or queuing excess traffic based on defined policies. Rate limiting prevents both cost overruns and provider API quota exhaustion. Some platforms implement intelligent queuing that prioritizes high-value requests during periods of constrained capacity.
Can analytics platforms reduce latency alongside costs?
Yes—many cost optimizations simultaneously improve response times. Caching delivers the most dramatic latency improvements, reducing response time by up to 85% for cached queries according to AWS research. Smaller, faster models selected for appropriate tasks often respond more quickly than overqualified frontier models while costing less. Context optimization reduces both token processing costs and the time required to process unnecessarily large inputs. The best analytics platforms surface opportunities where cost and performance improvements align.
What metrics matter most for LLM cost management?
Four metrics provide the foundation for effective cost management: total monthly spending tracks overall budget impact; cost per user interaction reveals unit economics for different features; input/output token ratio identifies expensive response patterns; and cache hit rate measures how effectively caching reduces redundant processing. Together, these metrics enable teams to understand both aggregate costs and specific optimization opportunities. Advanced teams add model selection accuracy—tracking how often cheaper models maintain quality thresholds.
Conclusion
LLM analytics tools with robust cost optimization features have evolved from nice-to-have monitoring solutions to essential infrastructure for any organization deploying AI at scale. The combination of real-time cost tracking, performance observability, and automated optimization capabilities delivers immediate ROI for teams spending significant amounts on language model APIs.
The short answer? Organizations can reduce LLM costs by 20-70% through systematic optimization enabled by proper analytics—without sacrificing response quality or functionality. But success requires more than installing a dashboard. Effective cost management demands clear baseline metrics, realistic optimization goals, gradual implementation, and continuous monitoring.
Research from MIT, Carnegie Mellon, and leading AI companies consistently demonstrates that combining strategic model selection, intelligent caching, context optimization, and automated routing delivers compounding benefits. Teams that treat cost optimization as an ongoing discipline rather than a one-time project achieve sustainable reductions while maintaining the flexibility to adopt new models and capabilities as they emerge.
The analytics platform landscape offers solutions for every deployment scenario—from cloud-native tools integrated with major providers to specialized observability platforms supporting multi-vendor environments to open source alternatives for custom requirements. Choosing the right platform depends on deployment architecture, budget constraints, and optimization sophistication.
Start by establishing current baseline costs and usage patterns. Identify the highest-impact optimization opportunities specific to your workload. Select analytics tools that surface actionable insights rather than overwhelming teams with raw metrics. Implement optimizations gradually, measure results, and iterate based on data rather than assumptions.
The organizations winning at LLM cost management share a common trait: they instrument comprehensively, analyze continuously, and optimize systematically. As language models become more capable and widespread, this discipline separates sustainable AI deployments from expensive experiments that never reach production scale.
Ready to optimize your LLM costs? Begin with measurement—you can’t improve what you don’t track. Choose an analytics platform aligned with your infrastructure, implement basic tracking, and let the data reveal where your specific deployment wastes resources. The insights will surprise you, and the savings will justify the effort.