Key Points: LLM fine-tuning costs typically range from $300 to $12,000+ depending on model size, technique, and infrastructure. Small models (2-3B parameters) with LoRA cost $300-$700, while larger 7B models run $1,000-$3,000 with LoRA or up to $12,000 for full fine-tuning. Hidden costs include data preparation, storage, compute overhead, and ongoing maintenance that can double initial estimates.
The bill hits different when fine-tuning large language models. What starts as a promising AI project quickly becomes a budget conversation that makes CFOs nervous.
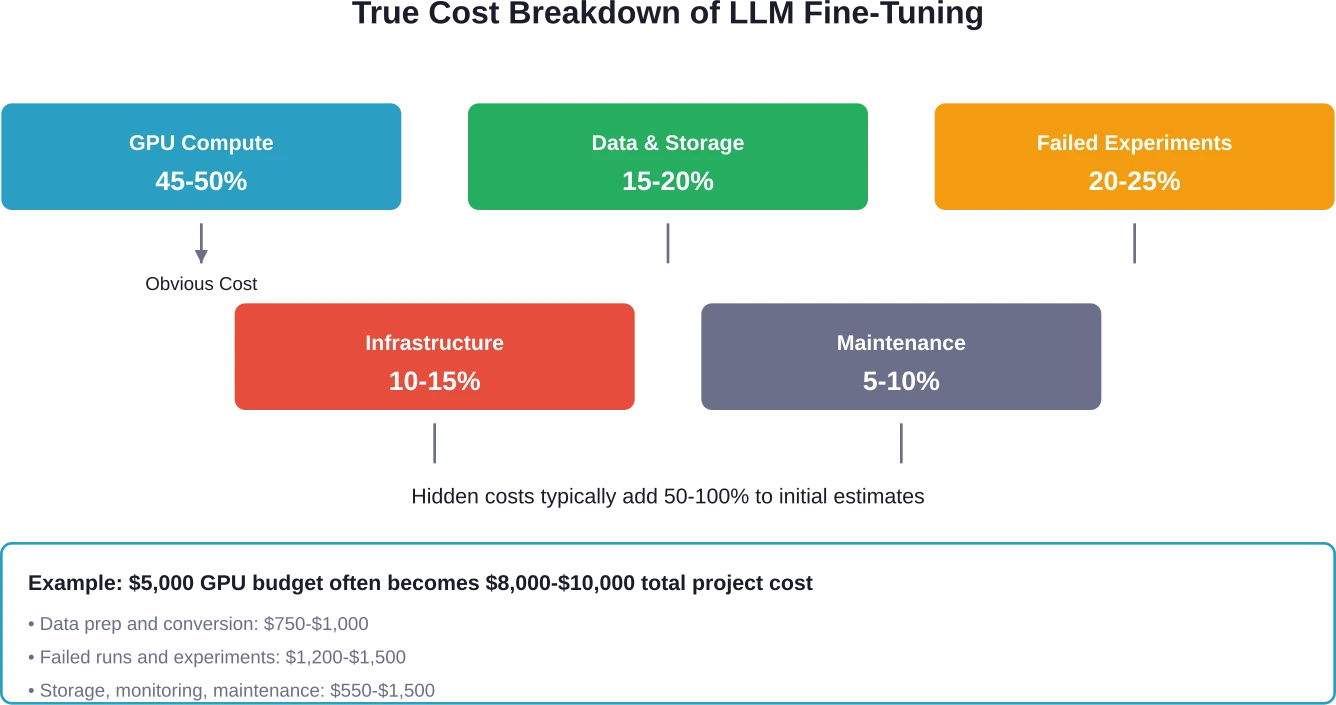
Fine-tuning costs aren’t just about GPU hours. The real expense includes data preparation, storage, failed experiments, and infrastructure overhead that catches teams off guard. Community discussions reveal simple fine-tuning jobs costing $3,000 to $10,000—and that’s before accounting for the hidden expenses.
Here’s what actually drives those costs and how to keep them manageable.
Breaking Down Real Fine-Tuning Costs
Model size matters more than most teams expect. The parameter count directly impacts compute requirements and ultimately, the invoice.
Based on available data, here’s what different model sizes actually cost:
| Model Size | Fine-Tuning Method | Typical Cost Range | Training Time |
|---|---|---|---|
| Phi-2 (2.7B parameters) | LoRA | $300 – $700 | Several hours |
| Mistral 7B | LoRA | $1,000 – $3,000 | 6-12 hours |
| Mistral 7B | Full Fine-Tuning | Up to $12,000 | 24-48 hours |
| Llama 2 7B | LoRA | $1,200 – $3,500 | 8-16 hours |
The technique matters just as much as model size. Low-Rank Adaptation (LoRA) dramatically cuts costs by updating only a small subset of parameters instead of the entire model. LoRA methods achieved an average 36% accuracy increase over baseline models according to benchmarks on financial datasets, while keeping costs manageable.
But those numbers tell only part of the story.

Get a Clear LLM Fine-Tuning Cost Breakdown from AI Superior
LLM fine-tuning costs vary depending on dataset size, model choice, infrastructure, and evaluation requirements. AI Superior helps organizations assess whether fine-tuning is necessary or if prompt engineering or retrieval-based solutions are more cost-effective.
Their approach includes:
- Data assessment and preparation strategy
- Model selection and training pipeline setup
- Performance evaluation and benchmarking
- Deployment and monitoring setup
If you are considering LLM fine-tuning, consult AI Superior for a cost-benefit analysis aligned with your expected ROI.
The Hidden Expenses No One Warns You About
The sticker price for GPU time represents maybe half the actual cost. The rest shows up in places teams don’t budget for initially.
Data Preparation and Storage
Raw data doesn’t work for fine-tuning. Converting datasets into the right format—typically JSONL for most platforms—takes engineering time. Community members working with 400,000 training samples and 2,000 test samples report significant preprocessing overhead.
Storage costs accumulate fast. Training datasets, validation sets, model checkpoints, and multiple experimental versions all need storage. AWS and cloud providers charge separately for this, and it adds up over months.
Failed Experiments and Iteration
The first fine-tuning run rarely produces production-ready results. Teams iterate on hyperparameters, data quality, and training approaches. Each iteration costs money.
Research on data efficiency shows that complexity-aware fine-tuning achieved the same accuracy using only 11% of original data and outperformed other methods by 4.7% on average. But discovering that optimal approach requires experimentation—and failed runs cost just as much as successful ones.
Infrastructure Overhead
Self-hosting adds layers of expense beyond compute. Multi-GPU clusters, networking, monitoring, and maintenance all require resources. Basic GPU nodes start at $2,500 per month, and underutilization means wasting money on idle hardware.
OpenAI Fine-Tuning: API-Based Pricing
OpenAI offers fine-tuning as a managed service, charging per token rather than infrastructure. The billing model differs significantly from self-hosted approaches.
Training costs are calculated by token count multiplied by epochs. For GPT-3.5-turbo, typical training datasets with around 90,000-100,000 tokens cost several hundred dollars for a complete fine-tuning job. Validation sets add additional token charges.
But here’s where it gets tricky. The API estimates maximum possible token consumption upfront, including image tokens and function call overhead. Images can consume up to 1,105 tokens for standard resolution or 36,835 tokens for high-resolution inputs per epoch—costs that surprise developers not reading the fine print.
Reinforcement Fine-Tuning (RFT) for reasoning models uses a completely different billing approach. Rather than token-based pricing, RFT charges based on time spent performing core machine learning work. The billing depends on compute_multiplier settings, validation frequency, and grader model selection.
AWS and Cloud Platform Costs
Amazon Bedrock and SageMaker offer managed fine-tuning with pay-as-you-go pricing. The costs vary by model provider, modality, and instance type.
SageMaker pricing depends on instance selection. The ml.g5.12xlarge instance commonly used for fine-tuning 7B models runs approximately $7-$8 per hour. A typical fine-tuning job taking 8-12 hours costs $60-$100 in compute alone.
Amazon Bedrock pricing varies significantly by model. Titan models, Claude variants, and Llama models each have different rate cards. Embedding model fine-tuning typically costs less than generative model fine-tuning.
Storage on AWS adds incremental costs. S3 storage for datasets, model artifacts, and checkpoints, plus EBS volumes for instances, accumulate charges. For a project with 1,000 users conducting 10 requests daily with 2,000 input tokens and 1,000 output tokens, storage and data transfer costs can exceed compute costs over time.
The Self-Hosting vs. Cloud Decision
Self-hosting looks expensive upfront but can be cheaper at scale. Cloud looks cheap initially but costs compound over time.
| Factor | Self-Hosted | Cloud/API |
|---|---|---|
| Initial Investment | High ($5,000-$15,000) | None |
| Monthly Operating Cost | Electricity only (~$100-$300) | $500-$5,000+ |
| Scalability | Limited by hardware | Essentially unlimited |
| Maintenance Burden | High (internal team) | None |
| Data Privacy | Full control | Dependent on provider |
| Break-Even Point | 3-6 months | N/A |
An RTX 4090 costs $1,600 as a one-time purchase versus cloud GPUs at $2,500 per month. The hardware pays for itself in weeks for teams with consistent workloads.
But cloud makes sense for experimentation and variable workloads. Spinning up a fine-tuning job when needed beats maintaining idle hardware.
Cost-Reduction Strategies That Actually Work
Cutting fine-tuning costs doesn’t mean sacrificing results. Several proven techniques reduce expenses significantly.
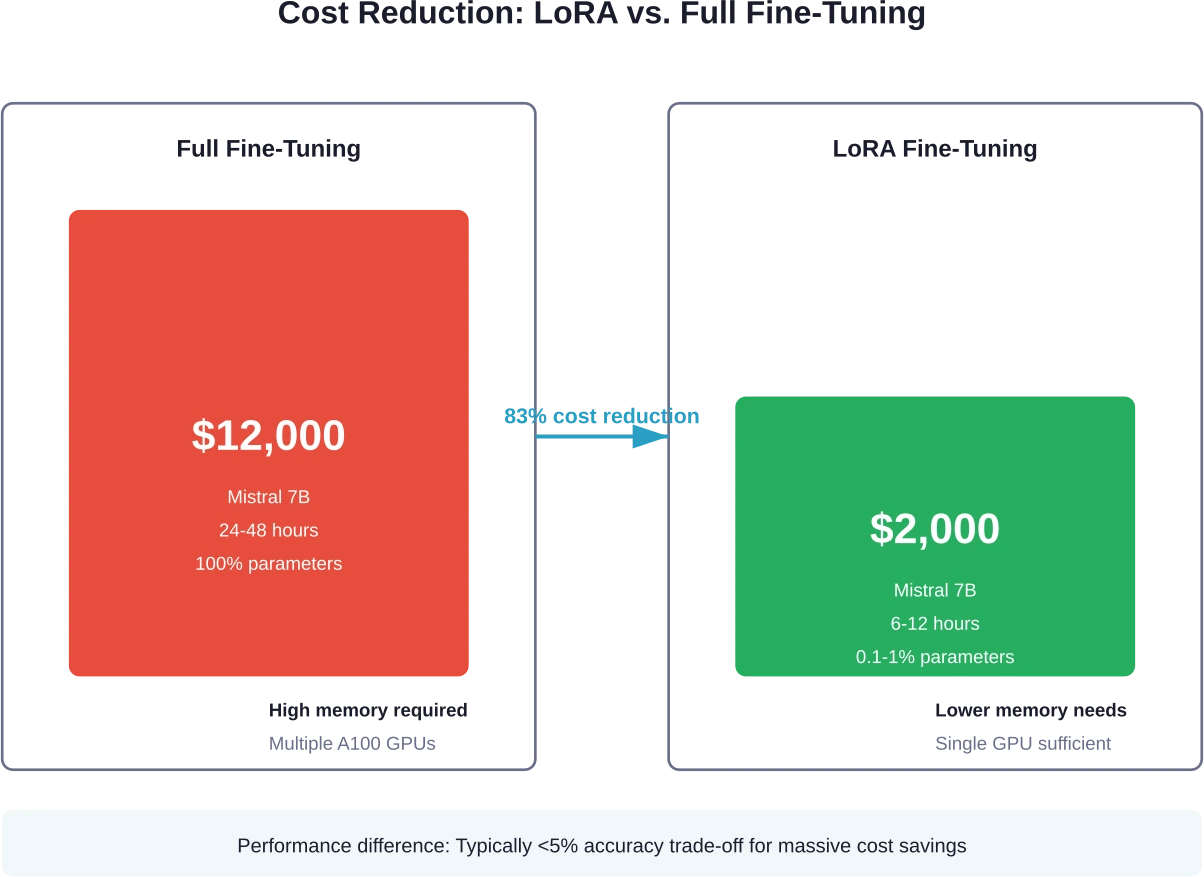
Use LoRA Instead of Full Fine-Tuning
LoRA achieves comparable results while updating only 0.1-1% of model parameters. The reduction in trainable parameters directly translates to lower compute requirements and faster training times.
LoRA methods cost roughly 4-10x less than full fine-tuning for the same model. Mistral 7B with LoRA runs $1,000-$3,000 versus $12,000 for full fine-tuning—same model, dramatically different cost.
Leverage Off-Peak Compute
Some providers offer spot instances or off-peak pricing. Community discussions suggest interest in cheaper fine-tuning options, with some mentioning potential 70% cost reductions through various optimization approaches.
Optimize Data Quality Over Quantity
More training data doesn’t always mean better results. Research on complexity-aware fine-tuning demonstrates that targeted data selection achieves the same accuracy with 11% of original data.
Curating high-quality examples reduces token counts and training time. Instead of throwing 1 million tokens at the model, 100,000 carefully selected tokens often perform just as well—at 10% of the cost.
Smart Hyperparameter Choices
Aggressive learning rates and fewer epochs reduce training time without necessarily hurting performance. Finding the optimal balance requires some experimentation, but the savings compound quickly.
Validation frequency matters too. Reducing validation frequency (e.g., every 100 steps versus every 10 steps) reduces validation compute costs proportionally. For reinforcement fine-tuning, choosing efficient grader models and avoiding excessive validation runs directly reduces bills.
When Fine-Tuning Makes Financial Sense
Not every use case justifies fine-tuning costs. The economics need to work.
Fine-tuning makes sense when:
- Domain-specific accuracy matters more than cost. Medical, legal, or financial applications where errors have real consequences justify the investment.
- Volume makes API calls expensive. High-throughput applications processing millions of tokens monthly often find fine-tuning cheaper than repeated API calls.
- Data privacy requires local control. Sensitive data that cannot leave infrastructure boundaries necessitates self-hosted fine-tuned models.
- Specialized formats or outputs are required. When prompting alone can’t achieve the desired output structure or behavior consistency.
Fine-tuning doesn’t make sense when:
- Prompt engineering achieves similar results. Context windows now support 200K-1M tokens. Many tasks work fine with comprehensive system prompts.
- Models change faster than deployment cycles. Better models release every 4-6 months. Fine-tuning Mistral 4B becomes obsolete when Qwen or Llama 3 launches weeks later.
- Volume doesn’t justify the upfront cost. Low-traffic applications paying $100/month in API fees can’t justify $5,000 in fine-tuning costs.
The calculation comes down to break-even analysis. If fine-tuning costs $8,000 and saves $500/month in API fees, the payback period is 16 months. That’s reasonable for stable, long-term applications. It’s terrible for experimental projects or rapidly evolving use cases.
The Economics of Reinforcement Fine-Tuning
Reinforcement learning fine-tuning introduces different cost dynamics. Unlike supervised fine-tuning billed by tokens, RFT charges for compute time spent on core training work.
OpenAI’s RFT API bills based on training duration, not dataset size. The cost drivers include:
- Compute multiplier settings that control training speed
- Validation frequency and grader model selection
- Episode length and complexity of the task
Optimizing RFT costs means choosing the smallest grader model meeting quality requirements, avoiding excessive validation runs, and keeping custom evaluation code efficient.
Research on RL fine-tuning data efficiency shows that targeted online data selection and rollout replay reduces training time by 23% to 62% while maintaining performance. That directly translates to cost savings proportional to time reduction.
Monitoring and Managing Ongoing Costs
Fine-tuning isn’t a one-time expense. Models drift, data changes, and retraining becomes necessary.
Tracking costs per customer or project enables transparent cost allocation. For teams serving multiple clients through a single account, fetching job details via API and calculating costs from trained tokens and model type provides approximate tracking.
Setting hard limits prevents runaway spending. OpenAI and cloud providers support spending caps that halt training jobs when thresholds are reached. This protects against misconfigured jobs consuming thousands in GPU time.
Dashboard monitoring matters. Watching training progress allows pausing or canceling underperforming jobs before wasting more resources. Most platforms show real-time metrics and accumulated costs.
Frequently Asked Questions
How much does it cost to fine-tune a 7B parameter model?
Fine-tuning a 7B model like Mistral or Llama typically costs $1,000 to $3,000 using LoRA techniques, or up to $12,000 for full fine-tuning. The exact cost depends on dataset size, training duration, and infrastructure choice (cloud vs. self-hosted).
Is LoRA as effective as full fine-tuning?
LoRA achieves comparable performance to full fine-tuning for most applications, with typically less than 5% accuracy difference. LoRA updates only 0.1-1% of parameters while delivering similar results at 4-10x lower cost and faster training times.
What are the hidden costs of LLM fine-tuning?
Hidden costs include data preparation and conversion (10-15% of budget), failed experiments and iteration (20-25%), storage for datasets and checkpoints (5-10%), infrastructure overhead for self-hosted setups (10-15%), and ongoing maintenance and retraining (5-10%). These can double initial GPU cost estimates.
When should I use API fine-tuning versus self-hosting?
API fine-tuning makes sense for variable workloads, experimentation, and teams without ML infrastructure. Self-hosting becomes cost-effective for consistent, high-volume workloads where a one-time hardware investment ($5,000-$15,000) pays back within 3-6 months compared to ongoing cloud costs.
How can I reduce fine-tuning costs by 70%?
Use LoRA instead of full fine-tuning, leverage spot instances or off-peak compute pricing, optimize data quality to reduce dataset size by 80-90%, reduce validation frequency, and choose efficient hyperparameters that shorten training time. Combining these strategies can cut costs by 70% or more.
Does fine-tuning make sense with large context windows?
Large context windows (200K-1M tokens) reduce the need for fine-tuning in many cases. If comprehensive prompting achieves acceptable results, it’s often cheaper than fine-tuning. Fine-tuning still makes sense for consistent behavior, specific output formats, or when repeated API calls exceed fine-tuning costs.
How often do fine-tuned models need retraining?
Retraining frequency depends on data drift and model lifecycle. Production models typically need updates every 3-6 months as underlying data changes or better base models release. High-stakes applications may require monthly retraining, while stable domains might extend to annual cycles.
Making the Investment Decision
Fine-tuning costs real money. The decision to proceed shouldn’t be casual.
Start by validating whether fine-tuning is necessary. Test extensive prompting with the base model first. Many teams discover that 90% of their use case works without fine-tuning.
Calculate the total cost of ownership—not just GPU hours. Include data preparation, experimentation budget, storage, and maintenance. Add 50-100% to initial estimates for hidden costs.
Compare against API costs at expected volume. If current spending is $200/month and fine-tuning costs $8,000, the break-even point is 40 months. That math doesn’t work for most projects.
Consider model longevity. Fine-tuning a model that will be obsolete in 4 months wastes resources. Rapidly evolving model families make fine-tuning less attractive than it appears.
But when domain expertise, data privacy, or volume economics justify it, fine-tuning delivers value that generic models can’t match. The key is running the numbers honestly before committing budget.
The teams that succeed with LLM fine-tuning treat it as an investment decision, not a technical choice. They measure costs, set clear performance targets, and know their break-even point before the first GPU spins up.
Ready to optimize your AI development costs? Start by accurately measuring your current API spending and projecting volume growth. That baseline determines whether fine-tuning makes financial sense for your specific situation.