Quick Summary: LLM inference costs have dropped by 10x annually since 2021, with GPT-4-level performance now costing $0.40 per million tokens versus $30 per million input tokens and $60 per million output tokens in March 2023. However, reasoning models can consume 100x more tokens internally than they output, creating a cost paradox where cheaper per-token pricing leads to higher total bills. Understanding true infrastructure costs, optimization techniques, and the choice between API services and self-hosted deployments is essential for sustainable AI economics.
The economics of artificial intelligence have entered a phase that defies conventional logic. While headlines celebrate plummeting token prices, AI companies are discovering an uncomfortable truth: their bills keep climbing.
What cost $60 per million tokens in November 2021 now costs $0.06-0.40 per million tokens for equivalent GPT-4 performance, representing a 150-1000x reduction depending on model. Yet many startups that build on large language models report infrastructure costs that consume 40-60% of their revenue.
The culprit? A fundamental shift in how modern AI models generate responses—and a token consumption pattern that nobody saw coming.
The Dramatic Decline in LLM Inference Pricing
LLM inference costs have fallen faster than nearly any computing commodity in history. According to research analyzing pricing trends, the rate of cost decline varies dramatically depending on the performance milestone, ranging from 9x to 900x per year.
The rate of decline varies dramatically depending on the task. For some benchmarks, prices dropped by 9x annually. For others, the decrease reached 900x per year—though these extreme drops occurred primarily in 2024 and may not sustain.
Here’s what that looks like in real terms. When GPT-3 became publicly accessible in November 2021, it was the only model achieving an MMLU score of 42. Cost? $60 per million tokens. By March 2026, multiple models exceed that benchmark at $0.06 per million tokens or less.
Google’s Gemini Flash-Lite 3.1 leads budget-tier pricing at $0.25 per million input tokens and $1.50 per million output tokens. Open-source models through providers like Together.ai push even lower—Llama 3.2 3B runs at $0.06 per million tokens for input.
Why Prices Fell So Fast
Several factors drive these cost reductions. Models are becoming smaller while maintaining performance, thanks to improved training techniques. A 13B parameter model can now achieve 95% of GPT-3’s MMLU score with a dramatically smaller inference footprint.
Hardware costs per compute unit continue declining. Cloud H100 prices stabilized at $2.85-$3.50 per hour after declining from 2023 peaks. According to arXiv research, the baseline hourly cost per A800 80G card is approximately $0.79/hour, generally falling within $0.51–$0.99/hour range.
Optimization techniques like quantization, continuous batching, and PagedAttention have transformed throughput capabilities. Systems in the MLPerf Inference v5.1 benchmark improved by as much as 50% over the best system in the 5.0 release six months prior (September 2025).
But there’s a catch.
The Token Consumption Paradox
Lower per-token pricing tells only half the story. The other half involves how many tokens modern models actually consume.
Traditional language models generate responses linearly. Ask a question, get an answer. Token consumption roughly matches output length. A 200-word response consumes approximately 250-300 tokens.
Reasoning models work differently. They “think” through problems internally before producing output. This internal reasoning process consumes tokens—lots of them.
Real-world examples reveal the scale of this shift. A simple question might use 10,000 reasoning tokens internally while returning only a 200-token answer. That’s 50x more tokens than the visible output suggests.
In extreme cases documented by users, some reasoning models consumed over 600 tokens to generate just two words of output. A basic query that would use 50 tokens with a standard model can balloon to 30,000+ tokens with aggressive reasoning enabled.
The Business Impact
This creates what some call the “LLM Cost Paradox.” Per-token pricing dropped 10x, but token consumption increased 100x for certain workloads. The math doesn’t favor AI companies.
Startups that built pricing models around traditional token economics face margin compression. A customer paying $20 per month might generate $18-25 in inference costs during heavy reasoning tasks. The unit economics simply don’t work.
Some providers responded by capping reasoning tokens, limiting how much internal thinking a model can perform. Others implemented tiered pricing where reasoning-heavy requests cost more. But these solutions create friction and complexity.
Understanding True Infrastructure Costs
Beyond API pricing, teams considering self-hosted deployments need to understand the complete cost structure. The numbers reveal when self-hosting makes economic sense—and when it doesn’t.
GPU Infrastructure Economics
According to NVIDIA’s benchmarking guidance published in June 2025, calculating true inference costs requires accounting for hardware acquisition, power consumption, cooling, network bandwidth, and operational overhead.
Cloud H100 instances cost $2.85-$3.50 per hour depending on provider and commitment length. Self-hosted H100s require capital expenditure plus ongoing costs. The breakeven calculation hinges on utilization rates.
Research shows that self-hosted infrastructure becomes viable when GPU utilization exceeds 50% sustainably. Below that threshold, API services typically offer better economics.
| Cost Component | Cloud Provider | Self-Hosted |
|---|---|---|
| GPU Cost | $2.85-3.50/hour | $30,000-40,000 (H100) |
| Power (per GPU) | Included | $0.40-0.60/hour |
| Cooling | Included | $0.15-0.25/hour |
| Network | $0.08-0.12/GB egress | Fixed monthly |
| Operations | Minimal | 1-2 FTE engineers |
| Breakeven Point | — | 50%+ utilization |
The Utilization Equation
Utilization determines everything. A GPU running at 30% utilization costs 3.3x more per inference than one running at 100%. But achieving high utilization requires consistent workload volume and sophisticated batching strategies.
Batch processing can reduce cost per output token by up to 30% compared to single-request processing. Techniques like continuous batching, where the inference engine dynamically combines requests as they arrive, maximize throughput.
Model efficiency gains through quantization, Mixture of Experts architectures, and data pruning can improve economics by 2-5x without sacrificing quality. According to Together.ai provider information, DeepSeek’s MoE architecture is positioned to deliver GPT-4 class performance cost-effectively.
Cost Structure Across Model Sizes
Model size directly impacts inference costs, but the relationship isn’t linear. Smaller models don’t always mean proportionally lower costs, and larger models sometimes offer better value for complex tasks.
Small Models (3B-7B Parameters)
Models in this range excel at cost efficiency for straightforward tasks. Llama 3.2 3B costs roughly $0.06 per million tokens. These models handle classification, simple question answering, and structured data extraction effectively.
The tradeoff comes in capability. Small models struggle with complex reasoning, nuanced language understanding, and tasks requiring extensive world knowledge. For many production workloads, that’s acceptable.
Medium Models (13B-70B Parameters)
This range represents the sweet spot for many applications. A 13B model achieving 95% of GPT-3’s MMLU score might cost $0.25 per million tokens—higher than tiny models but with substantially better reasoning capabilities.
The 70B class models like Llama 3.1 70B offer near-frontier performance at around $0.80 per million tokens. For applications requiring strong reasoning without needing absolute cutting-edge capability, these models deliver excellent unit economics.
Large Models (175B+ Parameters)
Frontier models like GPT-4, Claude, and Gemini Ultra cost $2-15 per million tokens depending on the specific model and provider. They excel at complex reasoning, creative tasks, and problems requiring deep domain knowledge.
The higher cost per token becomes economical when the model completes tasks in fewer iterations, provides more accurate responses, or enables use cases that smaller models simply can’t handle.

Need Help Designing and Deploying an LLM System?
If you are planning to run a large language model in production, it helps to work with a team that builds and deploys AI systems every day. AI Superior develops custom AI applications based on machine learning and LLM models, from early feasibility analysis to deployment and integration. Their team of data scientists and engineers works on model development, NLP systems, data pipelines, and production deployment. They also help evaluate whether a use case actually requires an LLM and how to structure the system so it runs efficiently.
Ready to Plan Your LLM Implementation?
Talk with AI Superior to:
- evaluate your LLM use case and technical requirements
- design and build custom AI or NLP systems
- deploy models and integrate them into existing software
👉 Request an AI consultation with AI Superior to discuss your LLM project.
API Services vs Self-Hosted Economics
The choice between API services and self-hosted infrastructure depends on scale, usage patterns, and technical capabilities. Neither option universally dominates.
When API Services Win
API services from OpenAI, Anthropic, Google, and providers like Together.ai offer compelling economics for many scenarios. Zero infrastructure management means teams focus on application logic rather than GPU orchestration.
Costs scale linearly with usage. Light usage months cost proportionally less than heavy months. There’s no capital expenditure, no stranded capacity during low-demand periods, and no operational overhead for model serving infrastructure.
For applications with variable traffic patterns, seasonal demand, or unpredictable growth trajectories, APIs typically offer better economics unless sustained throughput exceeds a fairly high threshold.
When Self-Hosting Makes Sense
Self-hosting becomes economically viable when GPU utilization can sustainably exceed 50%. According to benchmarking data, that requires consistent workload volume—roughly 10+ million tokens daily for a single GPU setup.
Beyond pure economics, some organizations self-host for data privacy, customization requirements, or specific latency needs. Financial services, healthcare, and government applications often can’t send data to third-party APIs regardless of cost advantages.
Open-source inference engines like vLLM enable high-performance self-hosted deployments. vLLM’s PagedAttention and continuous batching techniques maximize GPU utilization, making self-hosting more economically competitive.
| Factor | Favors APIs | Favors Self-Hosting |
|---|---|---|
| Volume | <10M tokens/day | >50M tokens/day |
| Traffic Pattern | Variable/spiky | Consistent/predictable |
| Latency Needs | Flexible | Ultra-low required |
| Data Sensitivity | Standard | Highly sensitive |
| Customization | Standard models OK | Need custom models |
| Technical Capacity | Limited ML ops | Strong ML ops team |
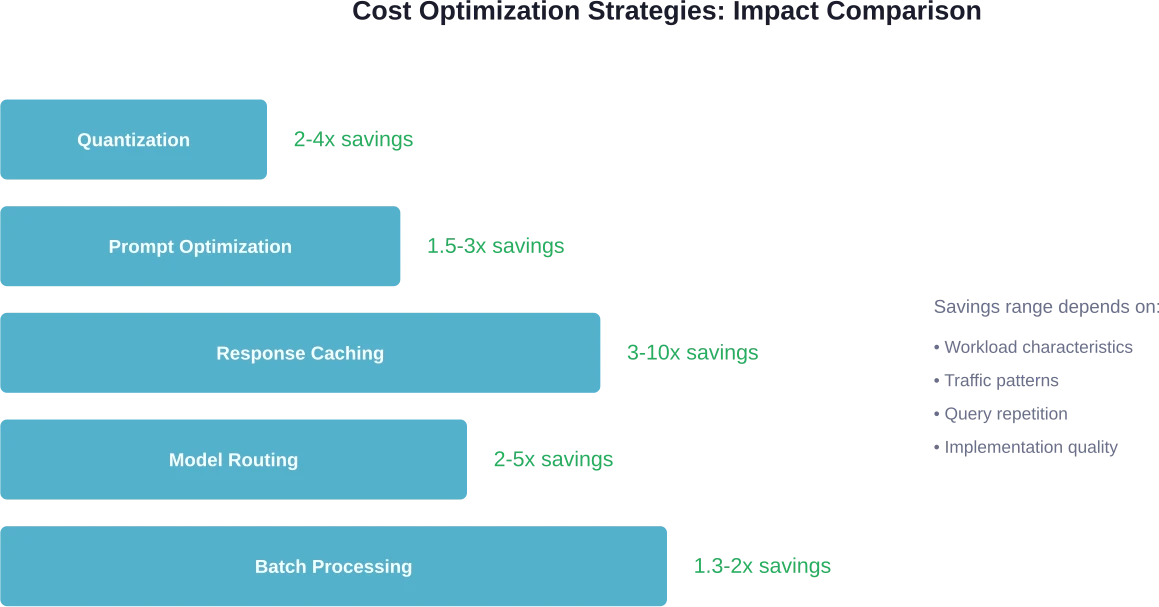
Optimization Techniques That Transform Economics
Several techniques can reduce inference costs by 2-10x without sacrificing quality. These optimizations work whether using APIs or self-hosting.
Quantization
Quantization reduces model precision from 16-bit or 32-bit floating point to 8-bit or even 4-bit integers. This shrinks memory footprint and accelerates inference.
Modern quantization methods maintain quality remarkably well. According to research on FP8 training, most variables in LLM training and inference can employ low-precision formats without compromising accuracy. Providers like Together.ai offer quantized models with reduced pricing and claim to maintain quality.
Prompt Optimization
Prompt length directly impacts costs. A 5,000-token prompt processed 1,000 times costs the same as 5 million tokens of inference. Optimizing prompts to be concise while maintaining effectiveness yields immediate cost reductions.
Research shows that prompt optimization can improve task accuracy while simultaneously reducing token consumption. Well-structured prompts guide models more efficiently, reducing the reasoning tokens needed to reach correct answers.
Response Caching
Many applications make similar or identical requests repeatedly. Caching responses for common queries eliminates redundant inference costs entirely.
Smart caching strategies consider prompt similarity, not just exact matches. Semantic caching compares the meaning of requests and returns cached responses for sufficiently similar queries, even when wording differs.
Model Routing
Not every request requires the most powerful model. Routing simple queries to small, fast models and complex queries to larger models optimizes the cost-quality tradeoff.
This requires upfront logic to classify request complexity, but the economics often justify the investment. Routing 70% of traffic to a $0.10/million token model and 30% to a $3/million token model yields a blended cost of $0.97/million—dramatically lower than using the expensive model for everything.
Provider Landscape in 2026
The inference provider market has evolved considerably. Several categories of providers now serve different needs.
Frontier Model APIs
OpenAI, Anthropic, and Google offer state-of-the-art capabilities with premium pricing. GPT-4 class models cost $2-15 per million tokens depending on specific model variants. These providers invest heavily in safety, reliability, and cutting-edge capabilities.
OpenAI’s o3 and o4-mini models, released in 2025, represent advances in reasoning capability. According to OpenAI evaluations, o3 makes 20% fewer major errors than o1 on difficult real-world tasks, particularly excelling in programming and business consulting applications.
Open-Source Model Platforms
Providers like Together.ai, Fireworks, and Replicate offer open-source models with significantly lower pricing. DeepSeek models on Together.ai provide 70-90% cost savings versus closed-source alternatives while delivering frontier-class performance.
These platforms combine commodity open-source models with proprietary serving infrastructure. The result: excellent performance at dramatically lower prices, though sometimes with less extensive safety filtering and content moderation.
Cloud Provider AI Services
AWS, Azure, and Google Cloud offer both their own models and third-party models through unified APIs. Pricing varies, but cloud providers typically add margin over direct API access while providing enterprise features like SLAs, compliance certifications, and integration with existing cloud infrastructure.
Specialized Inference Providers
Companies like Groq focus specifically on inference optimization. Groq focuses on inference optimization through custom silicon for low-latency performance.
Future Cost Trajectory
Where do inference costs go from here? Several trends shape expectations.
Cost reduction rates of 10x annually seen from 2021-2025 likely won’t sustain at the same pace. Low-hanging optimization fruit has been picked. Hardware improvements continue but at more modest rates. Model architecture innovations still occur but less frequently than during the explosive 2022-2024 period.
A more realistic expectation involves 3-5x annual reductions through 2027, then tapering to 1.5-2x annually. This still represents dramatic improvement—just not the extraordinary pace of recent years.
The reasoning token consumption challenge will drive architectural innovations. Models that achieve strong reasoning with lower token overhead will command market share. Expect continued research into efficient reasoning mechanisms.
Competition remains fierce. DeepSeek’s entry disrupted pricing across the market, forcing incumbents to reduce prices or differentiate on other dimensions. More disruption likely comes from unexpected sources—startups with novel architectures or regional players with different economic structures.
Building Sustainable AI Economics
Organizations building on LLMs need strategies that work regardless of specific pricing fluctuations. Several principles enable sustainable economics.
- First, architect for model flexibility. Don’t hard-code dependencies on specific providers or models. Abstract inference behind interfaces that allow swapping providers as economics shift.
- Second, instrument everything. Measure token consumption, cost per request, and cost per business outcome. Many organizations discover that 20% of use cases consume 80% of costs—and some high-cost use cases deliver minimal value.
- Third, invest in optimization. The techniques discussed earlier—quantization, caching, routing, prompt optimization—compound over time. A 2x improvement seems modest until you realize it means 50% cost reduction every month thereafter.
- Fourth, match model capability to task requirements. Using frontier models for every task wastes money. Building classification logic that routes requests appropriately pays dividends.
- Finally, plan for token consumption visibility. The reasoning token problem catches teams off-guard when they don’t monitor internal token consumption. Providers increasingly offer telemetry showing hidden token usage—use it.
Frequently Asked Questions
How much does LLM inference cost per request?
LLM inference costs vary dramatically based on model size and request complexity. Simple requests to small models (3B-7B parameters) cost fractions of a cent—roughly $0.01-0.05 per 1,000 requests. Medium models (13B-70B) cost $0.10-0.80 per 1,000 requests. Large frontier models (175B+) cost $2-15 per 1,000 requests. However, reasoning models can consume 50-100x more tokens than output length suggests, dramatically increasing actual costs.
Is self-hosting cheaper than using API services?
Self-hosting becomes cheaper than APIs when GPU utilization exceeds approximately 50% consistently. This typically requires processing 10+ million tokens daily per GPU. Below that threshold, APIs usually offer better economics because you avoid capital expenditure and don’t pay for idle capacity. Self-hosting also requires ML operations expertise and infrastructure management overhead.
Why are reasoning models so expensive?
Reasoning models generate extensive internal “thinking” tokens before producing output. A response with 200 visible tokens might consume 10,000-30,000 total tokens during reasoning. This internal token consumption gets billed but remains invisible in the output, creating situations where per-token pricing appears low but total costs are high. Some reasoning queries consume over 600 tokens to generate two-word answers.
How can I reduce LLM inference costs?
Five primary strategies reduce inference costs: quantization (2-4x savings), response caching for repeated queries (3-10x savings), prompt optimization to reduce token usage (1.5-3x savings), model routing to use smaller models for simple tasks (2-5x savings), and batch processing for throughput-oriented workloads (1.3-2x savings). These techniques compound when combined effectively.
What’s the current cost for GPT-4 level performance?
As of March 2026, achieving GPT-4 level performance costs approximately $0.40-0.80 per million tokens using competitive alternatives like DeepSeek V3 or mid-tier models from major providers. OpenAI’s actual GPT-4 costs $2-15 per million tokens depending on the specific variant. This represents massive deflation from late 2022 when equivalent performance cost $20+ per million tokens.
How do cloud GPU costs compare across providers?
Cloud H100 GPU pricing has stabilized at $2.85-3.50 per hour across major providers as of early 2026. Regional cloud providers sometimes offer lower rates ($2.20-2.60 per hour) with reduced SLAs. A800 cards, common in certain regions, cost approximately $0.79 per hour based on infrastructure economics. Multi-GPU configurations typically offer volume discounts of 10-20%.
Will LLM inference costs continue dropping?
Inference costs will likely continue declining but at slower rates than the 10x annual reductions seen from 2021-2025. Realistic expectations involve 3-5x annual reductions through 2027, then tapering to 1.5-2x annually as optimization opportunities become scarcer. Hardware improvements and architectural innovations will drive continued deflation, but the extraordinary pace of recent years probably won’t sustain indefinitely.
Strategic Takeaways for AI-Powered Applications
Understanding LLM inference economics matters more now than ever. The gap between naive implementation and optimized deployment can represent 5-10x cost differences—enough to determine whether unit economics work at all.
Token pricing tells only part of the story. Total token consumption, including hidden reasoning tokens, determines actual costs. Monitoring and controlling this consumption is essential for sustainable operations.
The choice between API services and self-hosting depends on scale, usage patterns, and organizational capabilities. Neither option universally dominates. Analyze your specific situation rather than following industry trends blindly.
Optimization techniques compound. Quantization, caching, prompt engineering, and model routing together can reduce costs by 10x or more compared to baseline implementations. Investing in these optimizations pays sustained dividends.
The market continues evolving rapidly. New providers, models, and pricing structures emerge regularly. Building flexible architectures that can adapt to changing economics protects against both cost inflation and missed opportunities from better alternatives.
Real talk: LLM inference costs have dropped dramatically, but that doesn’t mean AI infrastructure is cheap. It means the economics have shifted from “prohibitively expensive” to “manageable with careful optimization.” The teams that understand these economics and architect accordingly will build sustainable AI businesses. Those that treat inference as a commodity without understanding the underlying cost drivers will struggle.
Ready to optimize your LLM inference costs? Start by measuring your current token consumption patterns, including any hidden reasoning tokens. Identify your highest-cost use cases and evaluate whether model routing or prompt optimization could reduce expenses. Compare your current volume against the self-hosting breakeven threshold to determine if infrastructure ownership makes sense. The insights you gain will directly impact your bottom line.