Overview: Training a large language model like GPT-4 costs between $78-192 million, with compute infrastructure representing 60-70% of expenses. Costs stem from GPU clusters, electricity consumption, data preparation, and engineering talent. Fine-tuning existing models can reduce expenses by 60-90% compared to training from scratch.
Large language models have transformed artificial intelligence from research curiosity to commercial powerhouse. But here’s what most people don’t realize: the price tag attached to creating these systems rivals the cost of launching satellites into space.
According to the Stanford AI Index Report 2025, GPT-4’s training carried an estimated price tag of $78-100 million. Gemini Ultra 1.0 pushed that figure to $192 million. That’s a 287,000x increase from the $670 it cost to train a Transformer model back in 2017.
The economics behind these numbers aren’t just academic curiosities. Organizations evaluating whether to build custom models or license existing ones need concrete data. Research teams securing funding need realistic budget projections. And industry observers tracking AI development need context for understanding market dynamics.
This breakdown examines where every dollar goes when training frontier language models, why costs escalate so dramatically, and which strategies actually reduce expenses without sacrificing performance.
The Anatomy of LLM Training Costs
Training costs don’t come from a single line item. Multiple expense categories compound into those eight- and nine-figure totals.
Compute infrastructure dominates the budget. Cloud providers charge for GPU access by the hour, and training runs stretch across weeks or months. OpenAI reportedly spent over $100 million on GPT-4 training, with a significant portion allocated to cloud computing costs.
Hardware expenses scale with model complexity. Larger models demand more capable accelerators—and more of them. The difference between training a 20-billion-parameter model versus a 120-billion-parameter model isn’t linear. Computational requirements increase exponentially as parameter counts rise.
But wait. Hardware costs tell only part of the story.
The Hidden Multipliers
Electricity consumption creates ongoing expenses that many initial budgets underestimate. Anthropic announced in February 2026 a commitment to cover electricity price increases from their data centers, highlighting how seriously major AI labs take this issue. They noted that training a single frontier AI model will soon require gigawatts of power, an acknowledgment of the infrastructure burden these systems create.
Data preparation and storage add another layer. Training datasets for models like GPT-4 contain hundreds of billions of tokens sourced from books, websites, academic papers, and specialized corpora. Acquiring, cleaning, filtering, and storing that data requires dedicated teams and infrastructure.
Engineering talent commands premium compensation. Machine learning researchers and infrastructure engineers who can orchestrate training runs across thousands of GPUs are in short supply. Their salaries, bonuses, and equity packages form a substantial portion of total project costs.
Experimental iterations multiply baseline expenses. Finding optimal hyperparameters—learning rates, batch sizes, architectural variations—requires multiple training runs. Each failed experiment burns through GPU hours without producing the final model.

GPU Infrastructure: The Dominant Expense
Graphics processing units form the backbone of modern AI training. These specialized chips excel at the parallel matrix operations that neural networks require.
NVIDIA dominates the market. Their H100 and A100 accelerators power most large-scale training operations. Cloud providers charge approximately $2-4 per H100 GPU hour. Training a frontier model might require 10,000-25,000 GPUs running for several weeks.
The math gets brutal quickly. At $3 per GPU hour, running 15,000 GPUs for 30 days straight costs $32.4 million—just for the compute time. That’s before accounting for storage, networking, or any other infrastructure component.
Purchasing hardware outright shifts the cost structure. While upfront capital expenditure runs higher, avoiding recurring cloud costs can reduce overall spend over time. Organizations planning multiple training runs or ongoing fine-tuning operations often find ownership more economical than rental.
The Idle Time Problem
Here’s the thing though—GPUs aren’t productive every moment they’re powered on. Data loading bottlenecks, checkpoint saving, and debugging pauses create idle periods where expensive hardware sits unused but still incurs costs.
Research from arXiv examining efficient LLM training frameworks found that despite consuming full power, GPUs during standard pre-training often operate at suboptimal utilization rates of 30%-50%. This inefficiency stems from how transformer architectures interact with hardware capabilities.
Solutions exist. Optimized training frameworks can improve GPU utilization by streamlining data pipelines, overlapping computation with communication, and minimizing synchronization overhead. These improvements don’t just speed up training—they directly reduce the total GPU hours required.
| Hardware Type | Hourly Cloud Cost | Purchase Price | Break-Even Point |
|---|---|---|---|
| NVIDIA H100 | $2.50-$4.00 | $30,000-$40,000 | 10,000-16,000 hours |
| NVIDIA A100 | $1.50-$2.50 | $10,000-$15,000 | 6,000-10,000 hours |
| NVIDIA H200 | $3.50-$5.00 | $40,000-$50,000 | 11,000-14,000 hours |
Energy Costs: The Growing Concern
Electricity bills for training runs rival the hardware expenses themselves. Frontier models consume gigawatt-hours of power—enough to supply thousands of homes for months.
Energy efficiency has become a primary research focus. Work published on arXiv examining energy optimization in LLM-based applications prioritizes energy consumption as a key efficiency metric alongside traditional performance measures. Experiments on NVIDIA RTX 8000 hardware showed that optimized approaches achieve comparable accuracy to baselines while reducing energy consumption between 23-50%.
Real talk: energy costs aren’t just about the immediate utility bill. Infrastructure to deliver gigawatts of power requires substations, cooling systems, and backup generators. Data center operators factor these capital investments into their pricing models.
As training demands scale, power infrastructure becomes a competitive bottleneck. Organizations with access to low-cost, reliable electricity gain significant advantages in training economics.
Training From Scratch vs. Fine-Tuning
Not every project requires building a model from the ground up. Fine-tuning pre-trained models offers a cost-effective alternative for many applications.
The economics shift dramatically. Fine-tuning a model like Llama 2 or GPT-3.5 on domain-specific data might cost $5,000-$50,000 depending on dataset size and compute requirements. That’s 1,000-10,000x cheaper than training a comparable model from scratch.
Research documented on arXiv examining efficient LLM improvement strategies found that fine-tuning with techniques like LoRA (Low-Rank Adaptation) can be executed on modest hardware. One experiment applied LoRA training to a pre-quantized model at 4 bits using a single NVIDIA T4 GPU with 16GB VRAM, completing the process in 7 hours.
But fine-tuning comes with constraints. Pre-trained models carry embedded biases and knowledge gaps from their original training data. Fine-tuning adjusts model behavior for specific tasks but doesn’t fundamentally alter the model’s core knowledge or capabilities.
When Does Training From Scratch Make Sense?
Organizations pursue full training for several reasons. Proprietary datasets that can’t be shared with third-party model providers necessitate in-house training. Specialized domains where existing models perform poorly benefit from custom architectures trained on relevant corpora from scratch.
Competitive differentiation drives some decisions. Companies building AI-first products want models that competitors can’t simply replicate by fine-tuning publicly available alternatives.
Control over model behavior matters. Training from scratch provides complete visibility into data sources, training procedures, and model characteristics—crucial for regulated industries or safety-critical applications.


Estimate Your LLM Training Cost
Training large language models (LLMs) involves data curation, infrastructure, compute budgeting, experimentation, and evaluation. AI Superior reviews your dataset, objectives, and performance targets before estimating the resources and time required. Their cost breakdown includes preprocessing, training cycles, fine-tuning, and validation. This lets you plan compute spend and engineering effort up front.
Ready to Calculate Your LLM Training Investment?
Talk with AI Superior to:
- evaluate your dataset and goals
- define training strategy and compute needs
- receive a structured LLM training cost estimate
👉 Request an LLM training quote from AI Superior.
Real-World Cost Examples
Specific models provide concrete reference points for understanding training economics.
GPT-4’s training cost an estimated $78-100 million according to The Wall Street Journal and Stanford AI Index Report 2025. That figure encompasses compute infrastructure, electricity, data acquisition, and engineering resources across the entire training period.
Gemini Ultra 1.0 pushed costs higher at approximately $192 million per the Stanford AI Index Report 2025. The increased expense reflects larger scale, longer training duration, or more extensive experimentation during development.
GPT-4o training ran roughly $100 million. These frontier models from major labs share similar cost structures—eight- or nine-figure budgets dominated by GPU compute and power consumption.
Smaller organizations face different economics. Training a 7-billion-parameter model might cost $50,000-$200,000 depending on hardware access and efficiency. A 20-billion-parameter model could run $500,000-$2 million. These figures remain substantial but fall within reach of well-funded startups or enterprise research teams.
The Price Inflation Trajectory
Training costs have escalated exponentially. The Stanford AI Index Report 2025 documented a 287,000x increase from 2017 to present—from $670 for early Transformer models to nine figures for current frontier systems.
This trend shows no signs of reversing. Models continue growing in parameter count, training data volume, and architectural complexity. Each generation demands more compute than the last.
That said, efficiency improvements partially offset scale increases. Better algorithms, optimized hardware, and improved training techniques extract more capability per dollar spent. The cost per unit of model capability has actually decreased even as absolute training costs climbed.
Strategies to Reduce Training Costs
Multiple approaches can substantially reduce expenses without proportionally sacrificing model quality.
Efficient training frameworks minimize wasted GPU cycles. Techniques like gradient accumulation, mixed-precision training, and optimized data loading pipelines improve hardware utilization. According to analysis of high-throughput training systems, addressing inefficient utilization of computational resources during transformer training can dramatically reduce both training time and energy consumption.
Model compression techniques reduce computational requirements. Quantization represents weights with fewer bits, decreasing memory bandwidth and storage needs. Pruning removes less important connections, shrinking model size. Knowledge distillation transfers capabilities from large models to smaller ones more efficiently than training from scratch.
Smart resource allocation prevents paying for idle hardware. Auto-pausing GPU clusters during data preparation phases, dynamically right-sizing infrastructure for each training stage, and scheduling runs during off-peak electricity pricing all contribute to lower total costs.
Hyperparameter optimization reduces failed experiments. Systematic search strategies find effective training configurations faster than manual tuning. Fewer wasted training runs mean fewer GPU hours burned on dead ends.
The Cloud vs. On-Premise Decision
Cloud infrastructure offers flexibility and low upfront costs. Spin up thousands of GPUs for a training run, then release them when finished. This approach works well for organizations running occasional experiments or uncertain about long-term compute needs.
On-premise hardware requires significant capital expenditure but eliminates recurring rental fees. Break-even analysis typically shows ownership becoming economical after 10,000-16,000 hours of H100 usage or 6,000-10,000 hours for A100 chips.
Organizations planning multiple large training runs, continuous fine-tuning operations, or long-term model development pipelines often find purchasing hardware more economical despite higher initial costs.
| Cost Reduction Strategy | Potential Savings | Implementation Complexity |
|---|---|---|
| Efficient training frameworks | 20-40% | Medium |
| Model quantization | 30-50% | Low |
| Smart resource scheduling | 15-30% | Medium |
| Fine-tuning vs. training from scratch | 60-90% | Low (if base model fits needs) |
| On-premise hardware (long-term) | 40-60% | High |
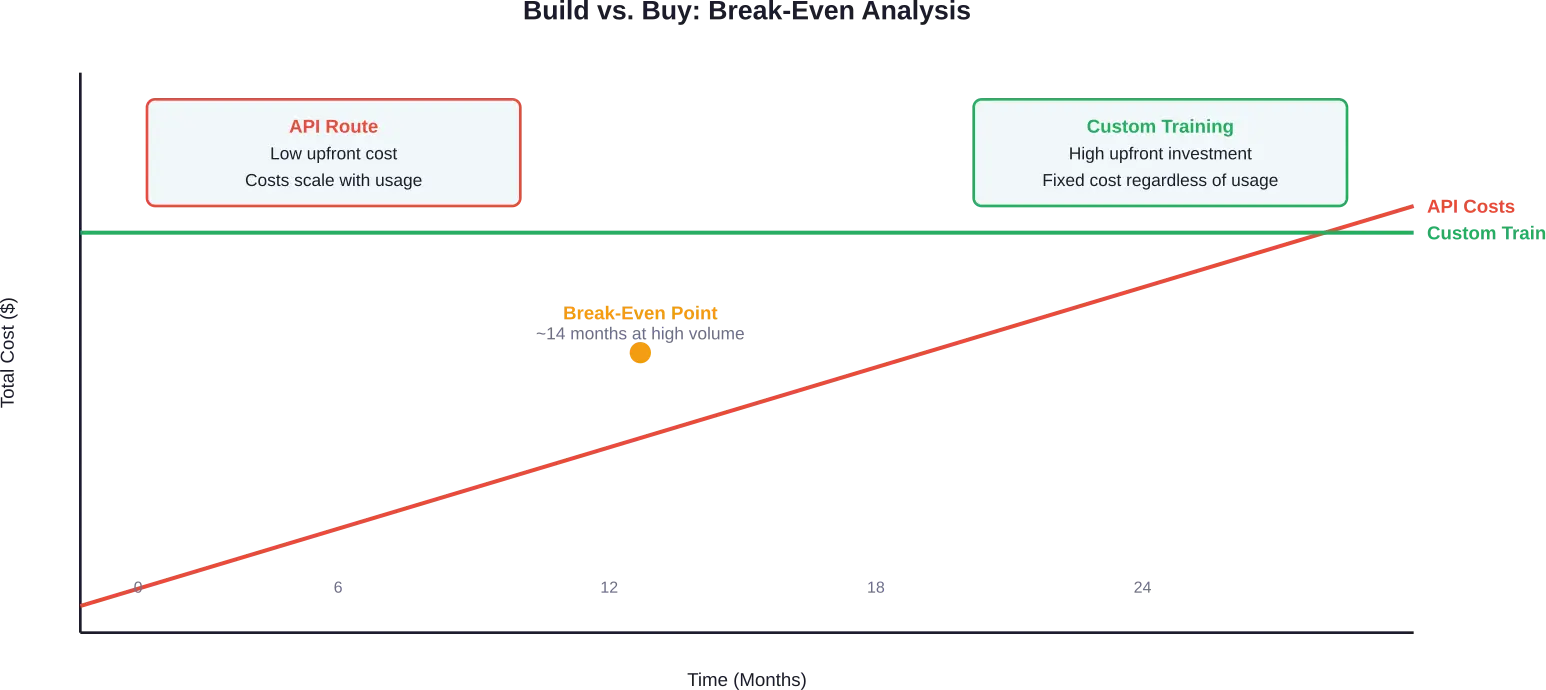
The Build vs. Buy Decision
Many organizations face a fundamental question: train a custom model or license existing ones?
API access to models like GPT-4 starts at $0.60 per million input tokens for some providers, with output pricing varying by model. Gemini Flash-Lite offers even lower rates at $0.075 per million input tokens and $0.30 per million output tokens according to 2025 pricing data.
Usage-based pricing seems economical initially. But costs scale linearly with traffic. Applications processing 1.2 million messages daily at 150 tokens each can generate monthly API bills of $15,000-$60,000 depending on pricing tiers and input/output ratios.
At high volumes, owned infrastructure becomes more economical. Break-even analysis for one documented case showed API costs reaching $60,000 monthly and trending toward $500,000+ annually—a figure that justifies significant upfront training investment.
The decision depends on usage patterns, required customization, and competitive positioning. Applications with predictable high-volume usage, specialized domain requirements, or needs for model transparency tend toward custom training. Projects with variable usage, general capabilities, or tight development timelines lean toward API access.
Future Cost Trends
Training costs will continue evolving as technology and market dynamics shift.
Hardware efficiency improvements steadily reduce cost per computation. NVIDIA’s architecture generations show consistent performance-per-watt gains. Competitors entering the accelerator market will drive further optimization and price competition.
Algorithmic advances extract more capability from less compute. Techniques like mixture-of-experts architectures, sparse attention mechanisms, and improved optimization algorithms reduce the computational budget required to achieve specific performance targets.
Energy costs will likely increase as AI infrastructure places greater strain on electrical grids. As training demands scale and power infrastructure becomes increasingly critical, organizations with access to low-cost renewable energy will gain competitive advantages.
Regulatory pressures may affect training economics. Governments concerned about energy consumption, data privacy, or AI safety could implement requirements that increase compliance costs or restrict certain practices.
Democratization trends could reduce barriers to entry. Open-source models, shared compute platforms, and improved training efficiency might bring large-scale model development within reach of mid-sized organizations rather than exclusively tech giants.
Frequently Asked Questions
How much does it cost to train GPT-4?
GPT-4 training cost an estimated $78-100 million according to The Wall Street Journal and Stanford AI Index Report 2025. This figure includes GPU infrastructure, electricity consumption, data preparation, and engineering resources across the multi-month training period.
Why is LLM training so expensive?
Training costs stem primarily from GPU compute infrastructure, which represents 60-70% of expenses. A frontier model might require 10,000-25,000 high-end GPUs running continuously for weeks or months. Additional costs include electricity consumption (gigawatt-hours of power), engineering talent, data acquisition and preparation, and experimental iterations to optimize hyperparameters.
Can fine-tuning reduce LLM training costs?
Fine-tuning existing models typically costs 60-90% less than training from scratch. Adapting a pre-trained model like Llama 2 or GPT-3.5 for specific tasks might cost $5,000-$50,000 compared to $78-192 million for frontier model training. Techniques like LoRA enable fine-tuning on single GPUs, completing in hours rather than weeks.
What’s the difference between cloud and on-premise training costs?
Cloud infrastructure charges $2-4 per H100 GPU hour with no upfront investment but ongoing rental fees. Purchasing H100 hardware costs $30,000-$40,000 per unit upfront but eliminates rental fees. Break-even occurs around 10,000-16,000 usage hours. Organizations planning multiple training runs often find ownership more economical despite higher initial capital requirements.
How much electricity does training an LLM consume?
Frontier models consume gigawatt-hours of electricity—enough to power thousands of homes for months. Training a single frontier AI model will soon require gigawatts of power capacity. Electricity costs represent 15-20% of total training expenses for large models, with both direct utility bills and supporting infrastructure driving costs.
What’s the cheapest way to train a custom language model?
Fine-tuning an existing open-source model using efficient techniques like LoRA provides the lowest-cost entry point. Research documented a LoRA training experiment completing in 7 hours on a single NVIDIA T4 GPU with 16GB VRAM—hardware available on platforms like Google Colab. For applications where fine-tuning provides sufficient capabilities, this approach reduces costs by 1,000-10,000x compared to training from scratch.
Are training costs still increasing?
Absolute training costs for frontier models continue rising as parameter counts and dataset sizes grow. The Stanford AI Index Report 2025 documented a 287,000x increase from 2017 to present. However, cost per unit of model capability is declining due to hardware improvements and algorithmic advances. Efficiency gains partially offset scale increases, though total budgets for state-of-the-art models keep climbing.
Understanding the Investment
LLM training costs reflect the computational intensity of creating systems that process and generate human language at scale. Those eight- and nine-figure price tags aren’t arbitrary—they represent thousands of specialized processors running continuously, consuming megawatts of power, orchestrated by teams of specialized engineers working with massive datasets.
The economics will continue evolving. Hardware gets more efficient. Algorithms improve. Competition drives innovation. But the fundamental tradeoff remains: capability requires computation, and computation costs money.
Organizations evaluating whether to build custom models need realistic cost projections, not aspirational underestimates. Teams securing funding need to account for all expense categories, not just the obvious GPU rental line items. And industry observers tracking AI development should understand that training costs serve as a useful proxy for model scale and capability.
The path forward depends on specific requirements. High-volume applications with specialized needs often justify custom training despite substantial upfront investment. Lower-volume or general-purpose projects find API access more economical. And many use cases sit somewhere between, where fine-tuning provides the right balance of customization and cost efficiency.
Ready to move forward with model development? Start by calculating your specific usage patterns, identifying which capabilities require custom training versus fine-tuning, and running break-even analysis for your expected deployment scale. The data will clarify which path makes sense for your particular situation.