Quick Summary: Open-source LLM deployment costs between $125K-$820K+ annually for most organizations, far exceeding API pricing for typical workloads. While model weights are free, infrastructure, engineering talent, operational overhead, and maintenance create substantial hidden expenses that make commercial LLM services more cost-effective until reaching specific break-even thresholds.
The pitch sounds irresistible: download an open-source large language model, deploy it on your infrastructure, and wave goodbye to API bills forever.
But here’s the thing—that “free” model will cost you anywhere from $125,000 to over $12 million per year, depending on your scale.
Open-source LLMs shift costs from transparent API fees to hidden operational expenses. According to research presented in a cost-benefit analysis framework, organizations face a critical decision: subscribe to commercial LLM services from providers like OpenAI, Anthropic, and Google, or deploy models on their own infrastructure. The analysis reveals that most assumptions about cost savings are fundamentally flawed.
This breakdown examines the real economics of open-source LLM deployment in 2026, backed by data from production implementations and academic cost-benefit analyses.
The Free Model Myth: What You’re Actually Paying For
Open-source model weights are free to download. Everything else costs money.
When organizations compare a $0 download to API pricing that charges per token, the math seems obvious. But the comparison is deceptive. Downloaded model weights represent roughly 2-5% of total deployment costs.
The remaining 95-98% comes from:
- Hardware infrastructure (GPUs, servers, networking)
- Engineering talent (ML engineers, MLOps specialists, infrastructure teams)
- Operational overhead (monitoring, scaling, reliability)
- Maintenance and updates (security patches, model retraining, performance optimization)
- Integration work (connecting models to existing systems)
Research analyzing on-premise deployments found that organizations need to achieve specific usage thresholds before self-hosted models become cost-competitive with commercial services. For most typical workloads, that threshold is never reached.
Infrastructure Costs: The GPU Reality
Running LLMs demands serious compute resources. Not laptop-level resources. Industrial-scale GPU infrastructure.
Hardware Requirements by Model Size
A 7-billion parameter model can run with high inference speeds on a single NVIDIA L4 (24GB) or even consumer-grade RTX 4090/5090 GPUs, requiring significantly less power than an A100. The 13B models need multiple GPUs. Models in the 70B+ range demand entire GPU clusters.
And these aren’t budget graphics cards. According to market pricing, a single NVIDIA A100 80GB GPU costs approximately $10,000-$15,000. The newer H100 runs approximately $25,000-$40,000 per unit. Most organizations need multiple units for production workloads.
| Model Size | Minimum GPU Memory | Typical Hardware | Approximate Cost
|
|---|---|---|---|
| 7B parameters | 16-24GB | 1x A100 40GB | $10,000-$15,000 |
| 13B parameters | 32-48GB | 1x A100 80GB or 2x A100 40GB | $20,000-$30,000 |
| 70B parameters | 140-280GB | 4x A100 80GB or 2x H100 | $50,000-$80,000 |
| 175B+ parameters | 350GB+ | 8x A100 80GB or GPU cluster | $100,000+ |
Cloud vs On-Premise Trade-offs
Organizations face two infrastructure paths: build on-premise data centers or rent cloud GPU instances.
On-premise infrastructure requires upfront capital expenditure. Budgets range from $50,000 for minimal deployments to $500,000+ for production-scale clusters. But capital costs are just the starting gate. Power, cooling, physical space, and maintenance add 20-40% annually.
Cloud GPU instances eliminate upfront costs but introduce ongoing operational expenses. Cloud GPU instances from providers like AWS can cost approximately $20-$35 per hour for 8x GPU configurations, translating to $14,000-$25,000 monthly for continuous operation. Google Cloud and Azure offer similar pricing structures.
Recent innovations like quantization techniques allow some models to run on consumer hardware. According to Hugging Face documentation on SmallThinker models, with Q4_0 quantization, models can exceed 20 tokens per second on ordinary consumer CPUs. But performance and accuracy trade-offs make this approach suitable only for specific use cases.
The Human Capital Expense: Engineering Teams You’ll Need
Infrastructure is tangible. Talent costs are where budgets truly hemorrhage.
Deploying and maintaining open-source LLMs isn’t a one-person side project. Production deployments require specialized engineering teams with salaries that dwarf infrastructure expenses.
Core Team Requirements
- Machine learning engineers: Build inference pipelines, optimize model performance, implement techniques like quantization and batching. Salary range: $150,000-$250,000 annually. Most organizations need at least two for coverage and expertise depth.
- MLOps engineers: Manage deployment infrastructure, handle Kubernetes clusters, maintain Docker containers, configure GPU quotas, and implement inference stacks like vLLM or NVIDIA Triton. Salary range: $140,000-$230,000 annually. Critical for scaling beyond proof-of-concept.
- Software integration engineers: According to community discussions, roughly 60% of engineering effort in AI projects goes into “glue code”—connecting models to databases, authentication systems, and user interfaces. Salary range: $130,000-$200,000 annually.
- DevOps/infrastructure engineers: Maintain servers, handle networking, ensure security compliance, and manage disaster recovery. Salary range: $120,000-$190,000 annually.
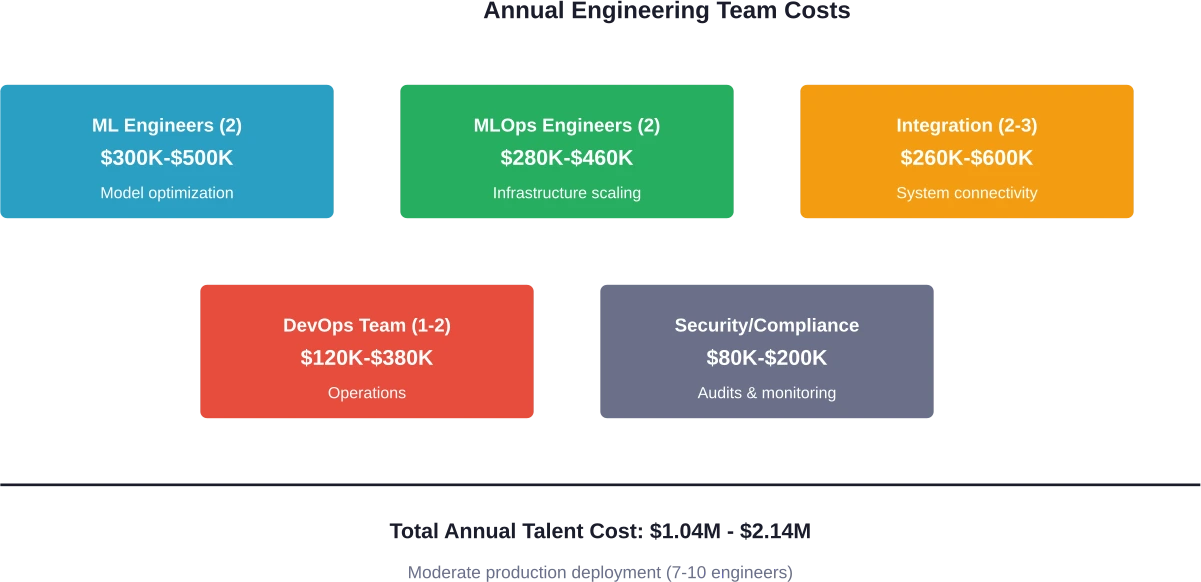
Minimal internal deployments require at least 3-4 engineers. Customer-facing features demand 7-10. Enterprise-scale deployments need 15+ specialized personnel.
According to current 2026 API pricing, GPT-4 class models (and their successors like GPT-5) cost approximately $0.0025-$0.01 per 1,000 tokens input. An ML engineer costs $200,000 annually. That engineer needs to save you 6.6 billion tokens worth of API calls just to break even on their salary alone.
Operational Overhead: The Monthly Bleed
Infrastructure and salaries are predictable line items. Operational overhead is where budgets encounter reality.
Monitoring and Observability
Production LLMs require comprehensive monitoring: latency tracking, throughput metrics, error rates, GPU utilization, memory consumption, and quality degradation detection. Tools like Prometheus, Grafana, and specialized ML observability platforms add $2,000-$10,000 monthly.
Data Storage and Transfer
Model weights for a 70B parameter model occupy 140GB+ of storage. Training data, fine-tuning datasets, and inference logs add terabytes. Cloud storage costs $0.02-$0.05 per GB monthly. Data transfer fees add another layer—egress charges from major cloud providers run $0.08-$0.12 per GB.
Scaling and Load Balancing
Production deployments need auto-scaling to handle variable load. Research on multi-stage LLM serving (MIST simulator study) reveals that optimized deployments can achieve up to 2.8× tokens-per-dollar gains through careful architectural choices. But implementing these optimizations requires sophisticated infrastructure.
Load balancers, container orchestration, and redundancy systems add $5,000-$25,000 monthly for mid-scale deployments.
Security and Compliance
Self-hosted models require security audits, compliance certifications, and vulnerability management. For regulated industries, these costs balloon. HIPAA compliance audits typically cost $20,000-$50,000 annually for existing infrastructure, while SOC 2 Type II certification costs between $30,000-$60,000 including audit fees.
Deployment Scenarios: Real Cost Breakdowns
Abstract numbers are meaningless. Here’s what actual deployment scenarios cost in 2026.
Scenario 1: Minimal Internal Tool
Use case: Internal chatbot for employee questions, 100-500 employees, low usage volume
Setup:
- Single 7B parameter model (Llama 3 or Mistral)
- 1x A100 40GB GPU (cloud hosted)
- 2 ML engineers (part-time allocation)
- Basic monitoring and infrastructure
Annual costs:
- GPU infrastructure: $15,000-$20,000
- Engineering talent (partial): $80,000-$120,000
- Monitoring and tools: $10,000-$15,000
- Storage and networking: $5,000-$10,000
- Security and compliance: $15,000-$25,000
Total: $125,000-$190,000 annually
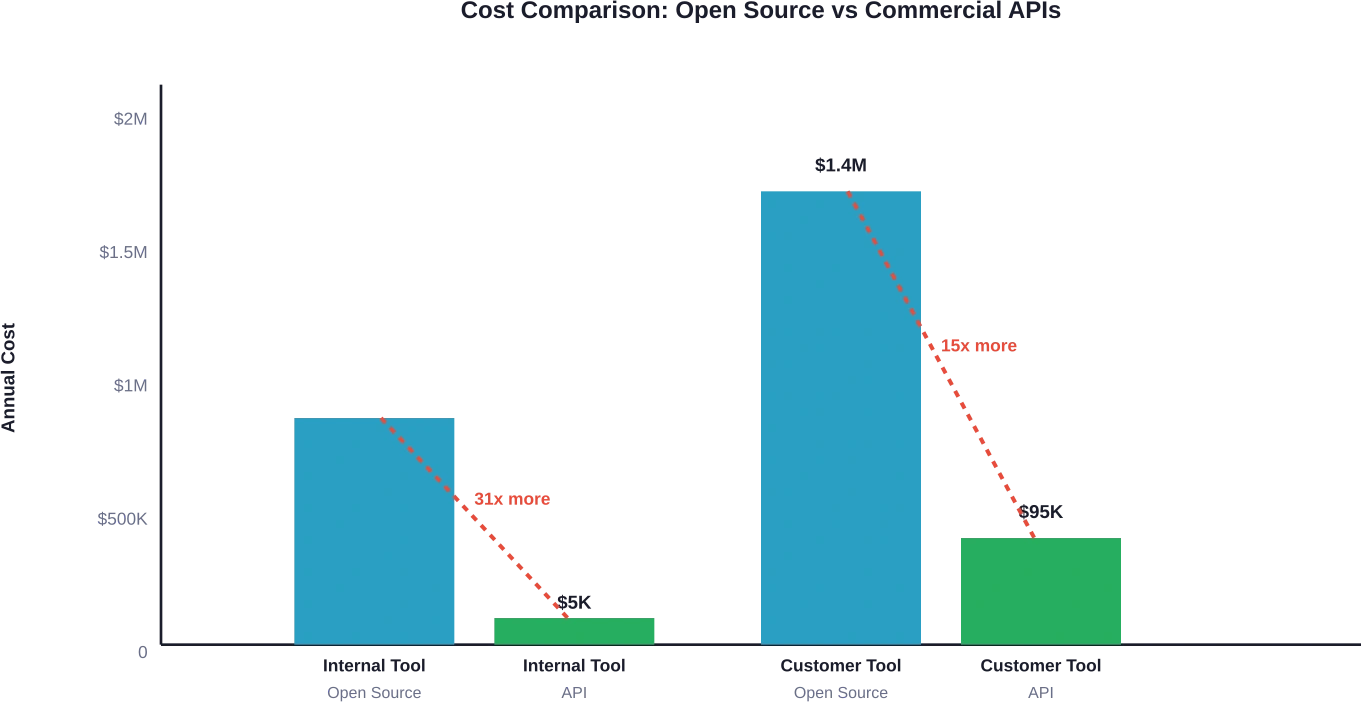
For comparison: equivalent usage via commercial APIs would cost significantly less annually—typically $3,000-$15,000 for similar token volumes. The break-even point never arrives.
Scenario 2: Customer-Facing Feature
Use case: Chatbot or content generation for 10,000+ monthly active users, moderate usage
Setup:
- 13B-70B parameter model with fine-tuning
- 4x A100 80GB GPUs with auto-scaling
- 7-10 engineering team members
- Production-grade monitoring and reliability
- 24/7 on-call support
Annual costs:
- GPU infrastructure: $120,000-$200,000
- Engineering team: $700,000-$1,400,000
- Monitoring and observability: $30,000-$60,000
- Storage, networking, CDN: $25,000-$50,000
- Security, compliance, audits: $50,000-$80,000
- On-call and incident response: $25,000-$30,000
Total: $950,000-$1,820,000 annually
Commercial API equivalent: estimated $40,000-$150,000 annually for similar usage patterns depending on model choice. Self-hosting makes financial sense only above 500M-1B tokens monthly.
Scenario 3: Enterprise Core Product
Use case: LLM as primary product engine, millions of users, high availability requirements
Setup:
- Multiple 70B+ parameter models with A/B testing
- GPU cluster (16-32 units) across multiple regions
- 15-25 engineering specialists
- Enterprise-grade infrastructure with redundancy
- Dedicated security and compliance teams
Annual costs:
- GPU infrastructure: $1,500,000-$3,000,000
- Engineering teams: $2,500,000-$5,000,000
- Monitoring and analytics: $200,000-$400,000
- Storage and networking: $300,000-$600,000
- Security and compliance: $400,000-$800,000
- Training and R&D: $500,000-$1,000,000
Total: $5,400,000-$10,800,000 annually
This scale represents the threshold where self-hosting potentially becomes cost-competitive with commercial APIs for usage patterns in the 500M-1B+ tokens monthly range.
When Open Source Actually Makes Financial Sense
Open-source deployment isn’t universally wrong. Specific scenarios justify the investment.
Break-Even Threshold Analysis
Research analyzing on-premise deployment economics identifies critical break-even points where self-hosted models become cost-competitive with commercial services.
The threshold depends on token volume. For typical enterprise workloads:
- Below 100M tokens monthly: Commercial APIs win decisively
- 100M-500M tokens monthly: Costs approach parity, but APIs often remain cheaper when engineering overhead is factored
- 500M-1B tokens monthly: Break-even zone where self-hosting may justify costs
- Above 1B tokens monthly: Self-hosting demonstrates clear cost advantages
But raw token volume isn’t the only factor.
Non-Financial Drivers
- Data privacy and sovereignty: Regulated industries handling sensitive data (healthcare, finance, government) face compliance requirements that prohibit external API usage. Self-hosting becomes mandatory regardless of cost.
- Latency requirements: Applications demanding sub-100ms response times can’t tolerate network round-trips to external APIs. According to Hugging Face analysis of edge versus cloud inference, network distance and congestion significantly impact p95 latency. For latency-critical applications, local deployment is non-negotiable.
- Customization depth: Heavily customized models with extensive fine-tuning, domain-specific training, and specialized architectures justify self-hosting investment. Notable examples include models like the DeepSeek R1 model, which according to reports on compute landscape shifts required less than $300,000 for post-training.
- Strategic independence: Organizations building AI-first products may prioritize vendor independence and control over short-term cost optimization.
| Decision Factor | Favor Open Source When | Favor Commercial APIs When
|
|---|---|---|
| Token Volume | Above 500M monthly | Below 500M monthly |
| Latency Requirement | Under 100ms p95 | 200ms+ acceptable |
| Data Sensitivity | Regulated/classified data | Non-sensitive workloads |
| Customization Needs | Extensive fine-tuning | Standard capabilities |
| Team Expertise | Existing ML/infrastructure teams | Limited technical resources |
| Capital Availability | Can invest $500K+ upfront | Prefer operational expenses |
Hidden Costs That Kill Projects
Beyond obvious expenses, several hidden costs derail open-source deployments.
Model Updates and Drift
Models degrade over time. Data distributions shift. User expectations evolve. Commercial APIs handle updates automatically. Self-hosted deployments require manual intervention.
Retraining or updating models demands additional GPU time, engineering effort, and testing cycles. Budget $50,000-$200,000 annually for ongoing model maintenance.
Opportunity Cost
Engineering teams building LLM infrastructure aren’t building product features. The opportunity cost of seven engineers spending six months on deployment infrastructure represents $350,000-$700,000 in salary costs plus the unrealized value of features they didn’t build.
Failed Experiments
Not every deployment succeeds. Testing multiple models, architectures, and optimization strategies burns resources. Failed proofs-of-concept cost $25,000-$100,000 each in engineering time and infrastructure.
Technical Debt
Rushed deployments create technical debt that compounds over time. Poorly architected inference pipelines, inadequate monitoring, and brittle integrations require expensive refactoring. Technical debt remediation costs 3-5× more than building correctly initially.
Optimization Strategies That Actually Work
Organizations committed to self-hosting can employ strategies to reduce costs.
Quantization and Compression
Model quantization reduces memory requirements and increases inference speed. Research shows that Q4_0 quantization allows models to exceed 20 tokens per second on consumer-grade hardware. This technique cuts infrastructure costs by 50-75% with minimal accuracy impact for many tasks.
Inference Optimization Frameworks
Specialized inference servers like vLLM, NVIDIA Triton, and Text Generation Inference dramatically improve throughput. These frameworks can increase tokens-per-second by 2-5× compared to naive implementations.
The performance gains translate directly to cost savings—fewer GPUs for equivalent throughput.
Hybrid Approaches
Smart organizations don’t choose “all open-source” or “all APIs.” Hybrid strategies use commercial APIs for variable workloads and peak traffic while maintaining self-hosted infrastructure for baseline load.
This approach optimizes costs: APIs handle burst traffic without over-provisioning infrastructure, while self-hosted models process predictable workloads cost-effectively.
Smaller Specialized Models
Bigger models aren’t always better. The SmallThinker family demonstrates that smaller, purpose-built models can outperform larger general-purpose LLMs on specific tasks. A well-optimized 7B model costs 90% less to run than a 70B model while potentially delivering better task-specific performance.

The TCO Calculation Framework
Organizations need a systematic approach to calculate total cost of ownership before making deployment decisions.
- Step 1: Estimate token volume. Calculate expected monthly token consumption based on user count, usage patterns, and feature requirements. Include both input and output tokens.
- Step 2: Calculate commercial API baseline. Multiply token volume by commercial API pricing. Account for different model tiers if using multiple model sizes.
- Step 3: Size infrastructure requirements. Determine GPU count and specifications based on model size, latency requirements, and redundancy needs. Include networking, storage, and compute.
- Step 4: Estimate engineering resources. Count FTEs needed across ML engineering, MLOps, integration, infrastructure, and security. Include both initial build and ongoing maintenance.
- Step 5: Add operational overhead. Include monitoring, security, compliance, data storage, bandwidth, and incident response costs.
- Step 6: Account for hidden costs. Factor in opportunity cost, failed experiments, technical debt, and model maintenance cycles.
- Step 7: Calculate break-even point. Determine the token volume where self-hosted total costs equal commercial API costs. Most organizations find this threshold at 500M-1B tokens monthly.

Cut Open Source LLM Deployment Costs Before They Scale
Open source LLMs look inexpensive at first, but deployment costs often grow quickly once infrastructure, monitoring, scaling, and integration are involved. AI Superior works on the technical side of LLM systems—designing model architectures, setting up infrastructure, and integrating models into existing environments so they run efficiently in production.
If you are deploying open source LLMs in 2026, it helps to review the architecture and deployment pipeline early. Contact AI Superior to evaluate your deployment setup and identify where infrastructure and inference costs can be reduced.
The 2026 Reality
Open-source LLM deployment costs are declining, but not as dramatically as model capabilities are improving.
GPU prices remain stubbornly high due to sustained demand. Engineering salaries for AI specialists continue climbing—ML engineers with LLM experience are in high demand with competitive salary growth.
Meanwhile, commercial API pricing is dropping. According to Hugging Face analysis of compute landscape trends, commercial API pricing has dropped significantly from 2024 rates. Claude and Gemini show similar trajectories. The economics increasingly favor APIs for most use cases.
Look, open source will dominate specific niches: regulated industries, latency-critical applications, organizations processing billions of tokens monthly, and companies building differentiated AI-first products. For everyone else? APIs make more financial sense.
The “free” open-source model costs $125,000 minimum and likely $500,000+ for anything resembling production scale. That’s not a criticism of open source—it’s just mathematics.
Frequently Asked Questions
What’s the minimum realistic budget for deploying an open-source LLM?
Minimal deployments for internal tools require $125,000-$190,000 annually, covering basic GPU infrastructure, partial engineering allocation, monitoring, and operational overhead. Anything below this threshold indicates an underfunded project likely to fail.
How many tokens per month make self-hosting cost-effective?
Research suggests 500M-1B tokens monthly represents the break-even threshold where self-hosting costs approach parity with commercial APIs. Below 500M tokens monthly, APIs almost always cost less when engineering and operational expenses are properly accounted for.
Can smaller models reduce deployment costs significantly?
Yes. A well-optimized 7B parameter model costs 85-90% less to operate than a 70B model. When combined with task-specific fine-tuning, smaller models often match or exceed larger model performance for specific applications, dramatically reducing infrastructure requirements.
What’s the largest hidden cost in open-source LLM deployment?
Engineering talent typically represents a significant portion of total deployment costs—the largest hidden cost in most organizational deployments. ML engineers, MLOps specialists, and integration developers command $140,000-$250,000 annual salaries. A moderate deployment requires 7-10 specialists, creating $1M-$2M in annual labor costs alone.
Do quantization techniques really save money without hurting quality?
Quantization techniques like Q4_0 can reduce infrastructure costs by 50-75% with minimal accuracy degradation for many tasks. Research demonstrates quantized models achieving 20+ tokens per second on consumer hardware. However, accuracy impacts vary by task—thorough testing is essential before production deployment.
Should startups use open-source LLMs or commercial APIs?
Most startups should start with commercial APIs. The flexibility, predictable costs, and zero operational overhead allow faster iteration and product development. Self-hosting makes sense only when reaching massive scale, handling regulated data, or building highly differentiated AI capabilities central to competitive advantage.
How much does it cost to fine-tune an open-source model?
Fine-tuning costs vary dramatically by model size and dataset. Minimal fine-tuning of a 7B model costs $5,000-$15,000 including GPU time and engineering effort. Extensive fine-tuning of 70B models with large datasets can exceed $100,000-$300,000. Notable examples achieved impressive results with reduced investment—smaller models have demonstrated comparable performance at a fraction of the cost.
Conclusion: Do the Math Before You Commit
Open-source LLM deployment isn’t free. It’s a substantial engineering and infrastructure investment that makes financial sense only at specific scales and for particular use cases.
Commercial APIs are the economically rational choice for the majority of applications processing under 500M tokens monthly. They’re definitely cheaper for internal tools, employee-facing applications, and moderate-scale customer features.
Self-hosting justifies the investment when processing massive token volumes (1B+ monthly), handling regulated or sensitive data requiring on-premise deployment, meeting extreme latency requirements, or building highly customized models central to product differentiation.
Calculate your total cost of ownership honestly. Include infrastructure, engineering talent, operational overhead, hidden costs, and opportunity costs. Compare that figure to commercial API pricing for equivalent usage. The math rarely lies.
And if the numbers still favor self-hosting for your specific scenario? Budget 2× your initial estimate. Production deployments always cost more than planned.
Ready to calculate your LLM deployment costs accurately? Start with token volume projections and work backward to infrastructure and talent requirements. The break-even analysis will reveal whether open source or commercial APIs make financial sense for your organization’s specific needs.