Overview: LLM hosting costs vary dramatically based on deployment model, ranging from $0.025 per million tokens for API services like OpenAI’s GPT-5-nano to $1,500-$5,000 monthly for self-hosted infrastructure. Organizations with over 50,000 daily requests often achieve cost savings of 25-50% by self-hosting, while smaller operations benefit from pay-per-use API pricing. Hardware requirements scale with model size—7B parameter models need roughly 3.5GB VRAM with 4-bit quantization, while 70B models require 35GB or multi-GPU setups.
Enterprise spending on large language models has exploded. Model API costs alone doubled to $8.4 billion in 2025, and most companies plan to increase their AI budgets further this year.
But here’s the thing—not every organization should pay the same way. The economics of LLM hosting depend entirely on scale, usage patterns, and technical requirements. API services offer incredible convenience, but self-hosting can slash costs by 50% or more at sufficient scale.
This guide breaks down the real costs across every major hosting option, from commercial APIs to fully self-managed infrastructure.
API-Based LLM Costs: Pay-Per-Token Pricing
Commercial API services operate on pay-per-use models, charging based on input and output tokens processed. According to OpenAI’s pricing documentation as of 2026, costs vary dramatically between models.
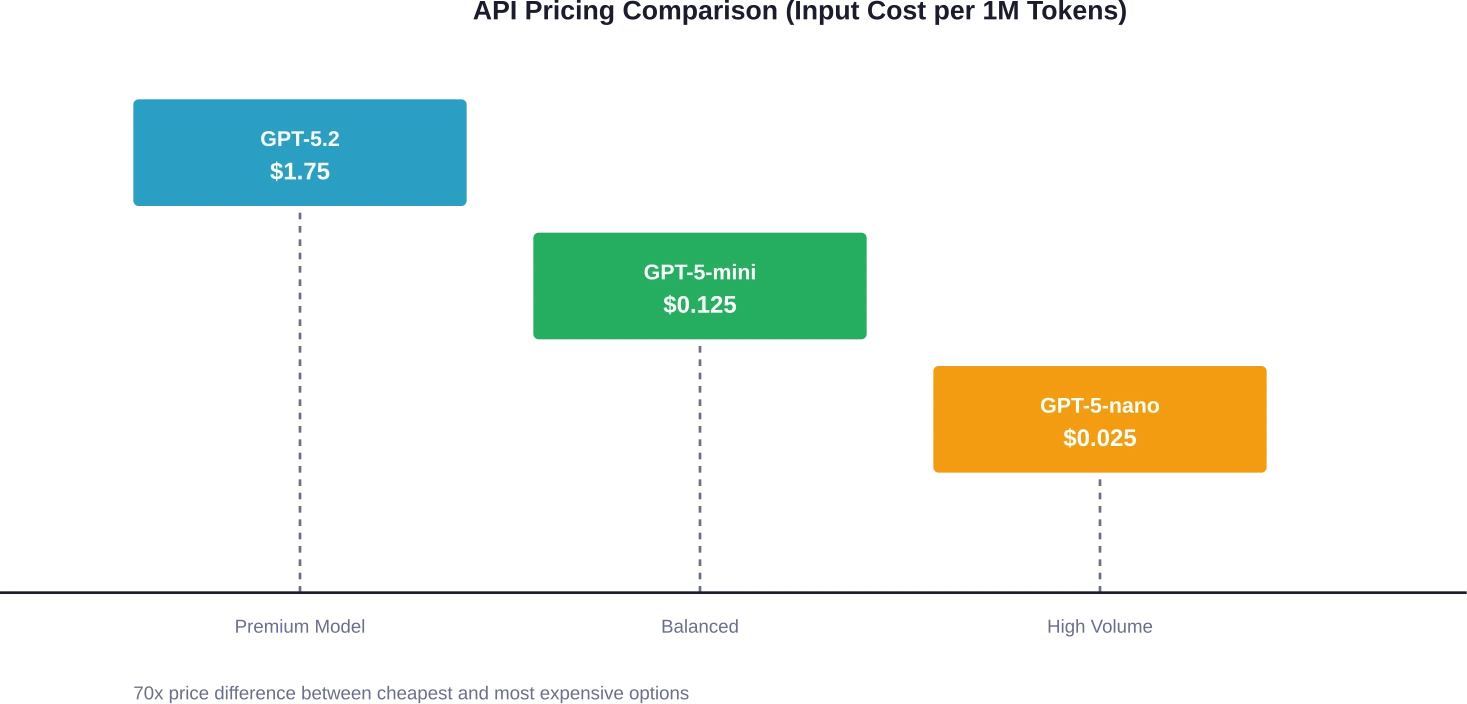
GPT-5.2 runs $1.75 per million input tokens and $14.00 per million output tokens. That’s the flagship model designed for complex reasoning and coding tasks. For comparison, GPT-5-mini costs just $0.125 per million input tokens and $1.00 per million output tokens—14x cheaper on inputs and 14x cheaper on outputs.
The newest addition, GPT-5-nano, dropped pricing even further to $0.025 per million input tokens and $0.20 per million output tokens. For teams running high-volume, straightforward tasks, this represents an 80% cost reduction compared to GPT-5-mini.
Cached Input Savings
OpenAI introduced cached input pricing that charges just 10% of standard rates for repeated content. GPT-5.2 cached inputs cost $0.175 per million tokens instead of $1.75. For applications with consistent system prompts or reference documents, this optimization matters.
The Batch API cuts costs by 50% for non-real-time workloads processed asynchronously within 24 hours.
Anthropic and Google Pricing
Google’s Vertex AI pricing for Gemini 3 models (as of February 2026) shows similar token-based structures. Standard pricing applies for requests under 200K input tokens, with separate rates for larger contexts and cached inputs.
These commercial services charge only for successful requests returning 200 response codes. Failed requests don’t incur costs, which protects against billing for errors.
Cloud Platform Hosting Costs
AWS SageMaker, Google Vertex AI, and Azure Foundry offer managed LLM hosting with more control than pure API services. These platforms charge for compute resources rather than tokens.
AWS SageMaker Pricing Structure
According to AWS documentation updated in February 2026, SageMaker charges for instance hours, storage, and data transfer. The AWS Free Tier includes 250 hours of ml.t3.medium instances for the first two months, plus 4,000 free API requests monthly.
For production workloads, instance pricing scales with GPU power. Organizations running inference on ml.g5.xlarge instances (NVIDIA A10G GPUs) pay different rates depending on region and commitment level.
AWS reserved instances show significant savings compared to on-demand pricing. One-year reserved commitments can reduce costs substantially for predictable workloads.
Google Vertex AI Economics
Google’s Vertex AI pricing documentation shows charges based on compute hours, model deployment time, and prediction requests. Models that fail to deploy don’t incur charges, and training failures (except user-initiated cancellations) aren’t billed.
This consumption-based model protects against paying for failed operations, which matters when experimenting with model configurations.
Self-Hosted LLM Infrastructure Costs
Self-hosting shifts costs from variable usage fees to fixed infrastructure investment. For organizations with over 50,000 daily requests, this often makes economic sense.
The hardware requirements depend entirely on model size. The rule of thumb: roughly 0.5GB of VRAM per billion parameters when using 4-bit quantization. Full precision (FP16) doubles that requirement.
| Model Size | Parameters | VRAM (4-bit) | VRAM (FP16) | Typical Hardware |
|---|---|---|---|---|
| Small | 7B-13B | 3.5-6.5GB | 14-26GB | Single A100/H100 |
| Medium | 30B-40B | 15-20GB | 60-80GB | A100 80GB |
| Large | 70B+ | 35GB+ | 140GB+ | Multi-GPU setup |
If the model doesn’t fit in VRAM, the system falls back to CPU processing, which runs 10-100x slower. That’s not viable for production.
Monthly Infrastructure Costs by Tier
Research analyzing on-premise LLM deployment economics from Carnegie Mellon University shows clear cost tiers emerging:
| Tier | Model Size | Hardware Config | Monthly Cost Range | Best For |
|---|---|---|---|---|
| Entry | 7B-13B | 1x A100/H100 | $1,500-$5,000 | Prototypes, internal tools |
| Mid | 30B-70B | 4-8 GPU cluster | $8,000-$20,000 | Production apps, moderate scale |
| Enterprise | 70B+ | 8+ GPU cluster | $20,000-$50,000+ | High-volume production |
These figures include hardware amortization, power, cooling, and basic maintenance. The arxiv.org research paper on cost-benefit analysis notes that GPU hourly costs for A800 80G cards run approximately $0.79/hour under common assumptions, generally falling within the $0.51-$0.99/hour range.
AWS EC2 Reserved Instance Savings
Analysis from LinkedIn’s comprehensive LLM hosting cost breakdown shows AWS EC2 reserved instances offer significant savings compared to on-demand pricing. For g5.xlarge instances (suitable for 8B parameter models), one-year reserved commitments can reduce monthly costs from approximately $530 to much lower rates.
The cheapest option identified for 8B models was Deep Infra at $5.40/month, while AWS SageMaker represented the most expensive at $529.92/month. The median cost sits around $237/month.

Know Your LLM Hosting Cost
Hosting LLMs involves choices around latency, scale, security, and budget. AI Superior helps you choose an appropriate hosting model (cloud, edge, or hybrid), estimate resource usage, and calculate recurring costs tied to traffic and performance. Their evaluation includes storage, monitoring, scaling, and ongoing maintenance considerations. This gives you a reliable forecast of hosting expenses.
Ready to Plan Your LLM Hosting Budget?
Talk with AI Superior to:
- select the right hosting architecture
- estimate resource and operational costs
- receive a clear hosting cost breakdown
👉 Request an LLM hosting cost estimate from AI Superior.
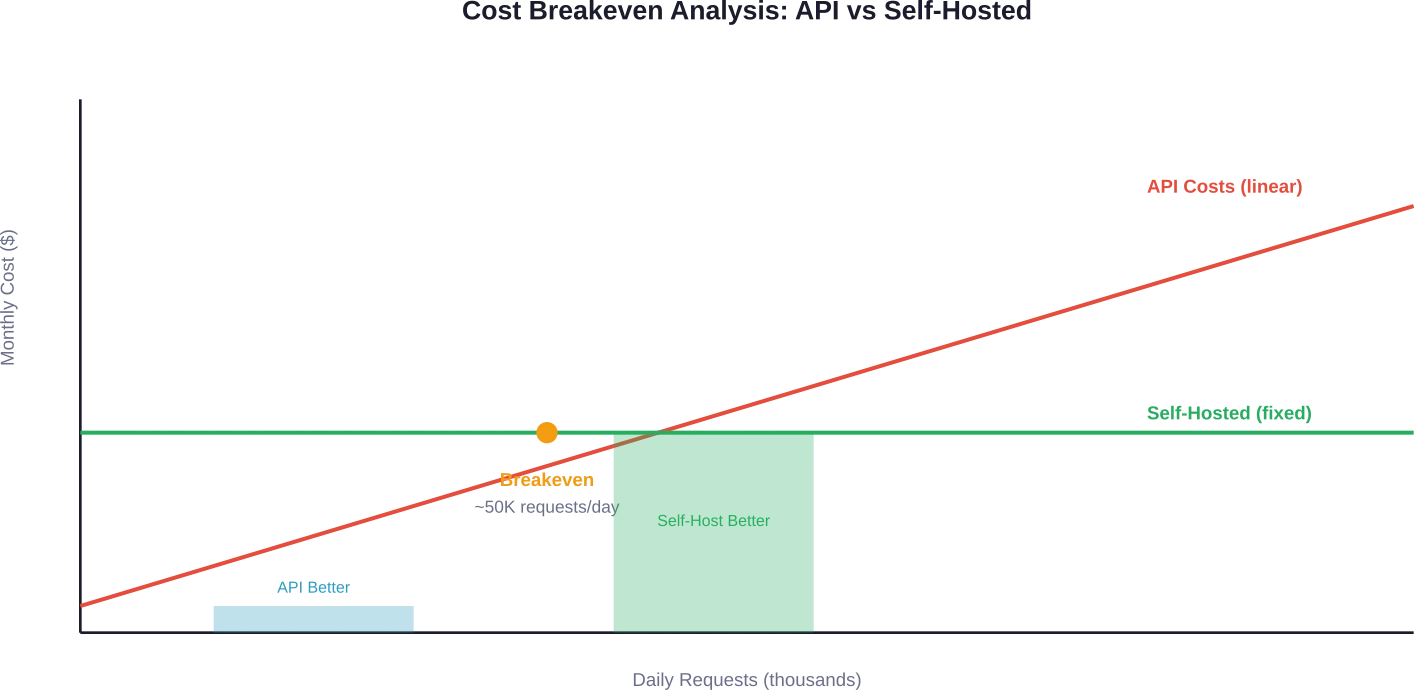
Breaking Even: When Self-Hosting Makes Sense
The breakeven point depends on request volume. Community discussions and cost analyses consistently point to 50,000+ daily requests as the threshold where self-hosting becomes economically attractive.
Here’s why: API costs scale linearly with usage. Fixed infrastructure costs stay constant regardless of request volume (within capacity limits).
An organization processing 50,000 requests daily with 500 input tokens and 500 output tokens per request using GPT-5-mini would spend approximately $3,125 monthly just on API calls. That’s before considering application infrastructure, caching layers, or monitoring.
A self-hosted 7B model on entry-tier hardware ($1,500-$5,000/month) handles similar volumes while offering complete data control. The economics improve dramatically at 100,000+ daily requests.
Hidden Costs Nobody Talks About
The sticker price tells only part of the story. Both API and self-hosted approaches carry hidden expenses that impact total cost of ownership.
API Services Hidden Costs
Rate limits force architecture decisions. When hitting throughput caps, applications need queuing systems, retry logic, and fallback mechanisms. That’s engineering time and infrastructure cost.
Data egress fees add up for high-volume applications. While the token processing itself costs $X, moving large datasets to and from API providers incurs separate charges.
Vendor lock-in creates switching costs. Applications built around specific API response formats, tool integrations, or prompt engineering techniques can’t easily migrate providers.
Self-Hosted Hidden Costs
DevOps overhead matters. Someone needs to handle model updates, security patches, monitoring, and incident response. According to Kong’s 2025 Enterprise AI report, 44% of organizations cite data privacy and security as top barriers—self-hosting requires dedicated resources to address these concerns properly.
Power and cooling exceed raw compute costs. Data centers report that actual power consumption runs 1.5-2x the rated GPU power draw when accounting for cooling and power supply inefficiencies.
Scaling isn’t automatic. Adding capacity means hardware procurement lead times, rack space considerations, and network infrastructure planning. API services scale instantly.
Optimization Strategies That Actually Work
Regardless of hosting choice, several techniques consistently reduce LLM costs without sacrificing performance.
Model Selection and Quantization
Smaller models often perform better than expected on domain-specific tasks. According to Together AI’s research, fine-tuning a 27B open-source model on specialized tasks can outperform Claude Sonnet 4 by 60% while running 10-100x cheaper.
4-bit quantization cuts memory requirements in half with minimal quality impact for most applications. This technique allows running larger models on the same hardware or running the same model on cheaper hardware.
Batch Processing
OpenAI’s Batch API saves 50% on inputs and outputs with asynchronous processing over 24 hours. Together AI’s Batch API documentation shows similar savings—tasks that don’t require real-time responses should always use batch endpoints.
AWS research on SageMaker optimization demonstrates that batching inference requests improves GPU utilization dramatically, reducing cost per prediction.
Caching and Request Deduplication
System prompts, reference documents, and repeated queries waste money. Implementing prompt caching at the application layer eliminates redundant token processing.
For self-hosted deployments, request deduplication middleware can catch identical queries before they hit the model, serving cached responses instead.
Traffic Forecasting and Auto-Scaling
Research from Microsoft on LLM serving efficiency (SageServe) achieved up to 25% savings in GPU-hours through forecast-aware auto-scaling, with potential monthly cost savings of up to $2.5 million. The system analyzes historical request patterns and preemptively adjusts capacity.
This reduces GPU-hour wastage due to inefficient auto-scaling by up to 80% compared to reactive scaling approaches.
Regional Cost Variations
LLM hosting costs vary significantly by geographic region. AWS, Google Cloud, and Azure all implement regional pricing that reflects local infrastructure costs, energy prices, and market conditions.
Real production data analyzing 10 million requests across multiple regions shows regional cost variation. For API services, these differences are usually abstracted away. But for self-hosted infrastructure, choosing the right region impacts monthly costs substantially.
For API services, these differences are usually abstracted away. But for self-hosted infrastructure, choosing the right region impacts monthly costs substantially.
2026 Cost Trends
Several factors are pushing LLM hosting costs down this year.
Algorithmic efficiency improvements matter more than hardware advances. According to research from MIT FutureTech on algorithmic efficiency, improvements in space complexity for large problems (n=1 billion) have outpaced DRAM improvements in 20% of cases analyzed.
New model architectures like Mixture-of-Experts (MoE) create different cost profiles. Research analyzing MoE tax shows these models have unique inefficiencies—load imbalance during prefill and increased memory transfers during decode. But optimized MoE implementations can deliver better cost-performance than dense models.
AWS announced new Large Model Inference containers in 2023 that reduced latency by 33% for Llama-2 70B workloads. Updated versions continue improving efficiency. For Llama-2 70B at concurrency of 16, latency was reduced by 28% and throughput increased by 44% with TensorRT-LLM containers.
FAQ
What’s the cheapest way to host an LLM in 2026?
For low-volume use (under 10,000 requests daily), OpenAI’s GPT-5-nano at $0.025 per million input tokens offers the lowest barrier to entry with zero infrastructure overhead. For high-volume production (50,000+ daily requests), self-hosting 7B-13B parameter models on entry-tier hardware ($1,500-$5,000/month) typically costs less than equivalent API usage.
How much VRAM do I need to run a 70B parameter model?
A 70B parameter model requires approximately 35GB VRAM with 4-bit quantization or 140GB with full FP16 precision. This typically means either an A100 80GB GPU (tight fit with quantization) or a multi-GPU setup for comfortable operation. Without sufficient VRAM, the model falls back to CPU processing at 10-100x slower speeds.
Are AWS reserved instances worth it for LLM hosting?
Reserved instances make sense for predictable, sustained workloads running 24/7. AWS EC2 one-year reserved commitments show significant savings compared to on-demand pricing for GPU instances. However, the commitment locks in capacity—organizations with variable usage patterns might overpay during low-demand periods.
Can small organizations afford self-hosted LLMs?
Entry-tier self-hosting starts around $1,500-$5,000 monthly for 7B-13B parameter models. Organizations processing 50,000+ daily requests often break even compared to API costs at this scale. Below that threshold, API services typically cost less when factoring in DevOps overhead, maintenance, and management burden.
What’s the real cost difference between GPT-5.2 and GPT-5-mini?
According to OpenAI’s 2026 pricing, GPT-5.2 costs $1.75 per million input tokens and $14.00 per million output tokens, while GPT-5-mini costs $0.125 input and $1.00 output—a 14x difference on both input and output. For a typical application processing 1 million tokens daily (500K in, 500K out), GPT-5.2 costs approximately $7,875 monthly versus $562.50 for GPT-5-mini.
Does caching really save money on LLM costs?
Yes, dramatically. OpenAI’s cached input pricing charges just 10% of standard rates for repeated content. For applications with consistent system prompts or reference documents, this means GPT-5.2 cached inputs cost $0.175 per million tokens instead of $1.75. Applications with 50% cacheable content can reduce API costs by roughly 45%.
How do I know when to switch from API to self-hosted?
Calculate current monthly API costs and project growth. Compare against entry-tier self-hosting infrastructure ($1,500-$5,000/month) plus DevOps overhead (typically 0.25-0.5 FTE engineering time). If API costs exceed $5,000 monthly and usage is predictable, self-hosting usually makes economic sense. Data privacy requirements, compliance needs, and customization requirements also drive the decision beyond pure cost.
Final Thoughts
LLM hosting costs aren’t one-size-fits-all. The right choice depends on request volume, performance requirements, data sensitivity, and technical capabilities.
API services excel for getting started quickly, handling variable workloads, and avoiding infrastructure management. They’re almost always cheaper below 50,000 daily requests.
Self-hosting makes economic sense at scale, especially when data privacy matters or when domain-specific fine-tuning delivers better results than general-purpose models. But it requires DevOps commitment and upfront infrastructure investment.
The best approach? Start with APIs to validate product-market fit, then evaluate self-hosting once usage patterns stabilize and costs justify the infrastructure investment. Many organizations run hybrid deployments—APIs for experimentation and overflow capacity, self-hosted infrastructure for core production workloads.
Whatever path makes sense for current needs, build with flexibility. The economics and capabilities of LLM hosting continue evolving rapidly.