Quick Summary: LLM API pricing varies dramatically across providers in 2026, ranging from DeepSeek’s budget-friendly $0.28 per million tokens to OpenAI’s GPT-5.2 Pro at $21 per million input tokens. Understanding token-based pricing models, hidden costs like caching and embeddings, and optimization strategies can reduce expenses by 30-90% while maintaining performance.
The large language model API market has exploded. Over 300 models now compete for developer attention, each with wildly different pricing structures.
Choosing the wrong provider can mean overspending by thousands monthly. Some sources suggest organizations may overpay on LLM APIs, though precise overpayment percentages vary by use case simply because they haven’t optimized their model selection and usage patterns.
This comparison breaks down current pricing across major providers, reveals hidden costs that catch teams off guard, and shows exactly where your money goes when you call an LLM API.
Understanding LLM API Pricing Models
Most LLM APIs charge per token. But what does that actually mean for your budget?
A token represents roughly four characters of text. The word “understanding” contains about three tokens. Your API calls get billed separately for input tokens (what you send) and output tokens (what the model generates).
Output tokens typically cost 3-6 times more than input tokens. That asymmetry matters when you’re generating long responses.
The Three Main Pricing Tiers
Providers structure their pricing around three consumption models:
- On-Demand (Standard): Pay-per-token with no commitments. Highest per-token cost but maximum flexibility. Good for prototyping or unpredictable workloads.
- Batch Processing: Submit requests that process asynchronously within 24 hours. Amazon Bedrock and OpenAI both offer 50% discounts for batch requests compared to on-demand pricing. Perfect for non-urgent tasks like data analysis or content generation.
- Provisioned Throughput: Reserve dedicated capacity with guaranteed response times. Billed hourly or monthly. Makes sense when you’re processing consistent high volumes and need predictable latency.
OpenAI introduced additional tiers in their latest pricing structure. Their “Flex” tier offers moderate discounts, while “Priority” guarantees faster processing during peak usage periods.
Major Provider Pricing Breakdown
Let’s cut through the marketing and look at actual numbers from official pricing pages.
OpenAI API Pricing (2026)
OpenAI’s lineup has expanded significantly. According to OpenAI’s official pricing page, here’s what they charge per million tokens:
| Model | Input Cost | Cached Input | Output Cost |
|---|---|---|---|
| GPT-5.2 Pro | $21.00 | N/A | $168.00 |
| GPT-5.2 | $1.75 | $0.175 | $14.00 |
| GPT-5 Mini | $0.25 | $0.025 | $2.00 |
| GPT-5 Nano | $0.025 | $0.0025 | $0.20 |
| GPT-4.1 | $1.00 | N/A | $4.00 |
| GPT-4o | $1.25 | N/A | $5.00 |
The flagship GPT-5.2 is positioned for complex reasoning and agentic workflows. GPT-5 Nano offers the cheapest entry point in OpenAI’s current lineup, suitable for simple classification or extraction tasks.
Their batch API cuts these prices in half. GPT-5.2 batch pricing costs $0.875 input and $7.00 output per million tokens, representing a 50% discount from standard pricing.
Anthropic Claude Pricing
Anthropic’s Claude models follow a different architecture with prominent context caching capabilities. From their official documentation:
| Model | Base Input | Cache Hits | Output |
|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.5 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.1 | $15.00 | $1.50 | $75.00 |
Claude’s caching system offers a 90% discount when you reuse context. If you’re building a chatbot that references the same knowledge base repeatedly, cache hits at $0.50 per million tokens versus $5.00 for fresh input represents massive savings.
Anthropic also provides batch processing at 50% off standard rates, matching OpenAI’s discount structure.
Google Vertex AI (Gemini Models)
Google’s Vertex AI platform hosts their Gemini family plus third-party models. Pricing from their official Vertex AI page shows:
| Model | Input ≤200K Tokens | Input >200K | Output |
|---|---|---|---|
| Gemini 3.1 Pro Preview | $2.00 | $4.00 | $12.00 |
| Gemini 3.1 Flash | Lower tier pricing | See official docs | See official docs |
Google implements long-context pricing thresholds. Queries exceeding 200K tokens get charged at higher rates across all tokens in that request. Gemini 2.5 Pro includes 10,000 grounded prompts (web search integration) daily at no cost, then charges $35 per 1,000 additional grounded prompts.
Their enterprise web grounding costs $45 per 1,000 grounded prompts. These search-augmented features add up quickly if you’re not monitoring usage.
Amazon Bedrock Multi-Model Platform
AWS Bedrock aggregates models from multiple providers under unified billing. According to their February 2026 pricing update:
- Claude 3.5 Sonnet starts at $3 input / $15 output per million tokens
- Gemma 3 4B costs $0.04 input / $0.08 output
- Gemma 3 12B runs $0.09 input / $0.18 output
Bedrock includes batch inference at 50% off on-demand rates. Their provisioned throughput model charges per model unit hour rather than tokens, with commitment terms offering discounts for 1-month or 6-month contracts.
Amazon also offers their Nova models with competitive pricing, though specific rates vary by region.
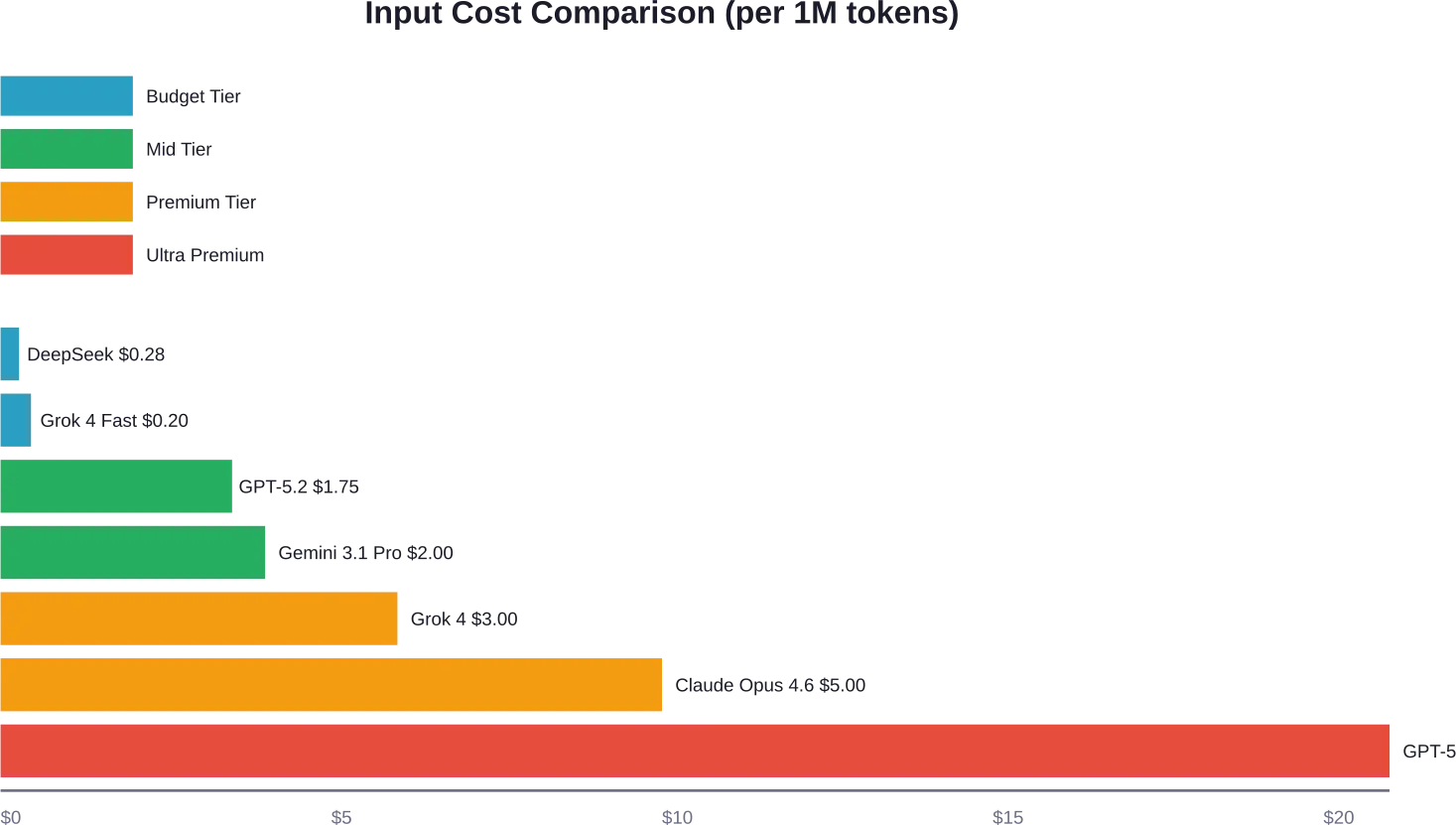
Budget Options: DeepSeek and xAI
China-based DeepSeek has disrupted the market with aggressive pricing on their V3.2-Exp models. DeepSeek’s V3.2-Exp models are listed at $0.60 per million input tokens (cache-miss) and $0.40 for reasoning output tokens according to available pricing data with cache misses, and $0.40 for reasoning output tokens.
xAI launched Grok 4 at $3 input / $15 output per million tokens. Their faster Grok 4.1 Fast variant costs $0.20 input / $0.50 output, targeting developers who need speed over maximum capability.
Hidden Costs That Inflate Your Bill
Token costs grab headlines. But several less-obvious charges can double your actual spend.
Prompt Caching and Context Windows
Large context windows sound great until you realize you’re paying for every token each time. OpenAI and Anthropic both offer prompt caching to reduce repeated context costs.
According to OpenAI’s documentation, cached input tokens cost 90% less than standard input. For GPT-5.2, cached tokens run $0.175 versus $1.75 for uncached.
The catch? Cache writes themselves cost money. Anthropic’s pricing shows cache write rates varying by duration: 5-minute cache writes at $6.25 per million tokens and 1-hour writes at $10 per million for Claude Opus 4.6.
If you’re not reusing context frequently enough, caching costs more than it saves.
Embeddings and Vector Search
Building a RAG (retrieval-augmented generation) system requires generating embeddings. These costs operate separately from main inference pricing.
Amazon Titan Text Embeddings V2 costs $0.00002 per 1,000 input tokens according to AWS documentation. Sounds cheap until you’re embedding millions of documents.
You also pay for vector storage. Google’s Vertex AI RAG Engine includes fees for data ingestion, LLM parsing for chunking, and vector search operations beyond the model inference costs.
Grounding and Tool Use
Google charges $35 per 1,000 grounded prompts (web search) on Gemini after the free daily quota. Claude web search costs $10 per 1,000 searches according to official Anthropic pricing documentation for Vertex AI.
These features dramatically improve accuracy for real-time information. But they also add 10-15% to typical costs if used liberally.
Rate Limits and Throttling
Free tiers and lower usage tiers impose strict rate limits. OpenAI’s tier system shows Tier 1 users get 500 requests per minute with 500,000 tokens per minute on GPT-5.2. Tier 5 users access 40 million TPM.
Hitting rate limits means failed requests and retry logic, which wastes both tokens and developer time. Upgrading tiers requires minimum monthly spending but eliminates bottlenecks.

Build the Right LLM Architecture with AI Superior
Choosing between different LLM APIs is not only about token pricing. Performance requirements, prompt design, system architecture, and scaling strategy all affect the total cost of an application.
AI Superior helps companies design production-ready LLM systems and choose the most suitable architecture for their use case.
Their team can help with:
- selecting the right LLM providers
- designing scalable LLM architectures
- optimizing prompts and token usage
- integrating LLMs into existing systems
If you are planning an LLM-powered product, AI Superior can help design the technical architecture and implement the solution.
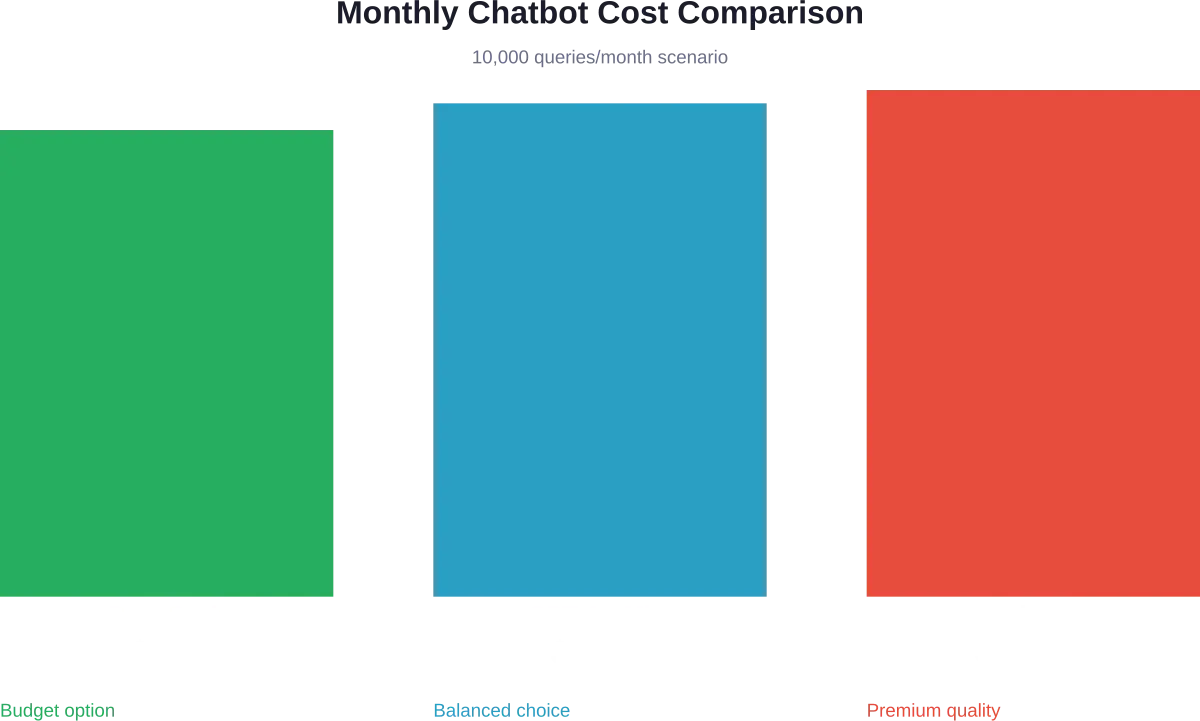
Real-World Cost Analysis: Chatbot Example
Let’s model actual costs for a customer service chatbot handling 10,000 queries monthly.
Assumptions based on typical call center patterns from AWS documentation:
- 5 million tokens for knowledge base (one-time + updates)
- 50,000 embeddings for semantic search
- Average 100 tokens per user query
- Average 100 tokens per response
- Total: 2 million tokens monthly (1M input, 1M output)
OpenAI GPT-4.1 Mini
- Input: 1M tokens × $0.20 = $200
- Output: 1M tokens × $0.80 = $800
- Embeddings: 50K × $0.00002 = $1
- Monthly total: ~$1,001
Claude Opus 4.6 with Caching
- Knowledge base cached: 90% cache hits
- Cached input: 900K × $0.50 = $450
- Fresh input: 100K × $5.00 = $500
- Output: 1M × $25.00 = $25,000
- Monthly total: ~$25,950
Wait, that’s 26x more expensive. Here’s the thing though — Claude Opus delivers significantly higher quality on complex reasoning tasks. The price premium makes sense for mission-critical applications where accuracy matters more than cost.
DeepSeek V3.2 Budget Option
- Input: 1M × $0.28 = $280
- Output: 1M × $0.40 = $400
- Embeddings: $1
- Monthly total: ~$681
DeepSeek offers the cheapest option but with less proven reliability for enterprise use cases. Performance benchmarks show it scores within 20% of top commercial models on standard tests, making it viable for cost-sensitive applications.
Cost Optimization Strategies That Actually Work
Teams that manage LLM costs effectively follow several proven patterns.
Intelligent Prompt Routing
Not every query needs your most powerful model. Route simple questions to smaller models, complex reasoning to flagship options.
AWS documentation indicates intelligent prompt routing can reduce costs by up to 30% without compromising accuracy without accuracy degradation. Implement classification logic that assigns queries to appropriate models based on complexity.
Amazon Bedrock supports this through their intelligent prompt routing feature, which automatically selects optimal models per request.
Aggressive Prompt Caching
Structure your prompts to maximize cache reuse. Place stable context (system instructions, knowledge base excerpts) at the beginning where it can be cached.
Anthropic’s caching system offers up to 90% cost reduction on cached tokens compared to standard input pricing. For applications that reference consistent context, this single optimization can cut spending in half.
Batch Processing for Non-Urgent Tasks
Both OpenAI and Amazon Bedrock offer 50% discounts for batch API requests. Any work that can tolerate 24-hour turnaround should route through batch endpoints.
Content generation, data analysis, and training data creation all work perfectly as batch operations. Organizations can potentially achieve significant cost savings through batch processing, which typically offers 50% discounts compared to on-demand pricing.
Output Token Management
Output tokens cost 4-6x more than input. Control response length aggressively through max_tokens parameters and prompt engineering.
Requesting 500-token responses when 200 tokens suffice wastes money on every call. Set conservative output limits and only expand for queries that genuinely need longer responses.
Model Selection by Task Type
Match model capabilities to requirements:
- Simple classification/extraction: Use nano/mini models (GPT-5 Nano at $0.025 input, $0.20 output)
- General chatbot responses: Mid-tier models (GPT-4.1 Mini, Claude Sonnet variants)
- Complex reasoning/coding: Flagship models (GPT-5.2, Claude Opus)
- Bulk processing: Always use batch APIs for 50% savings
A cost-benefit analysis framework suggests organizations may achieve breakeven points on on-premise LLM deployment depending on usage levels and performance needs depending on usage volume and infrastructure costs. But for most teams, optimizing cloud API usage delivers better ROI than self-hosting.
Monitoring and Cost Management Tools
You can’t optimize what you don’t measure. Several approaches help track LLM spending:
Provider-Native Dashboards
OpenAI, Anthropic, and Google all offer usage dashboards showing token consumption by model, project, and time period. These work but lack cross-provider comparison.
Anthropic’s Usage & Cost API lets you programmatically access consumption data with 1-minute to 1-day granularity. All costs report in USD as decimal strings in cents.
Third-Party Monitoring Platforms
Helicone and similar services aggregate usage across multiple LLM providers. They track per-request costs, identify expensive queries, and alert on budget thresholds.
These platforms typically charge 1-2% of LLM spend or flat monthly fees. Worth it for teams using multiple providers or needing detailed attribution by user/project.
Setting Up Budget Alerts
Most providers support spending limits and alerts. Configure these before production deployment:
- Set hard caps for development/testing environments
- Configure alerts at 50%, 75%, and 90% of budget thresholds
- Implement circuit breakers that pause requests when limits hit
AWS Cost Explorer provides budget tracking for Bedrock usage. Google Cloud offers similar functionality for Vertex AI spending.
Emerging Trends in LLM Pricing
The competitive landscape continues evolving rapidly.
Race to the Bottom on Commodity Tasks
Basic text generation and classification pricing has dropped 80-90% since 2023. Models like GPT-5 Nano ($0.025 input) and DeepSeek ($0.28 input) push prices toward near-zero for simple tasks.
This commoditization means differentiation happens on specialized capabilities — reasoning, multimodal understanding, tool use — rather than basic text generation.
Premium Pricing for Reasoning Models
The opposite trend holds for advanced reasoning. GPT-5.2 Pro at $21 input / $168 output commands massive premiums over standard models.
These “slow thinking” models spend more compute time reasoning before responding, justifying higher prices for complex problems where accuracy matters more than speed.
Context Window Economics
Providers charge premium rates for long-context queries. Google’s >200K token threshold triggers higher pricing across all tokens in that request.
As context windows expand (OpenAI’s GPT-5.2 supports 400K tokens), expect tiered pricing based on context usage to become standard. Efficient context management through summarization and caching will matter more.
Specialized Model Pricing
Domain-specific models (medical, legal, financial) command premium pricing due to specialized training. Expect continued expansion of niche models with pricing 2-3x general-purpose equivalents.
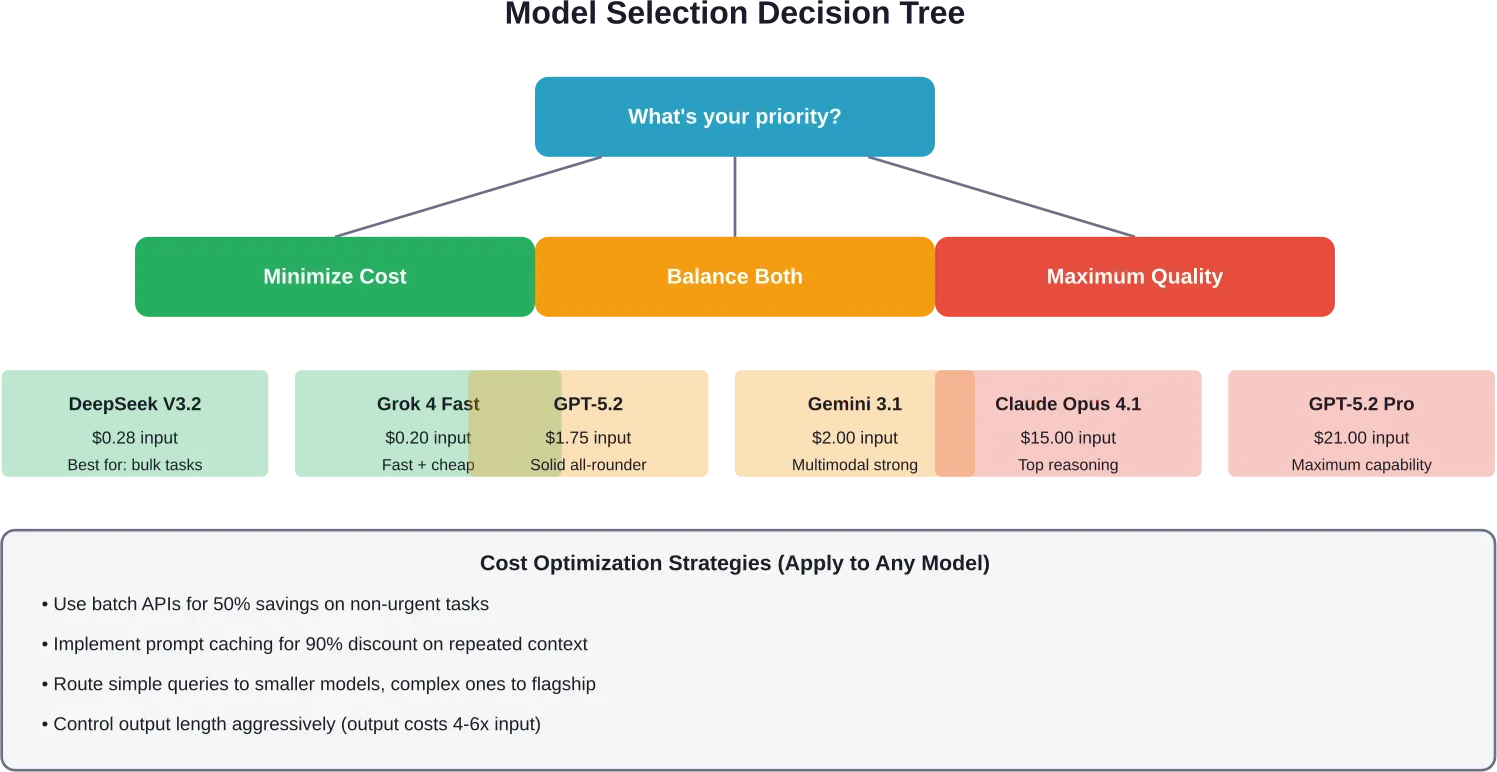
Which Provider Should You Choose?
No universal answer exists, but here’s decision framework based on priorities:
For Tight Budgets
DeepSeek V3.2 offers the lowest per-token costs while maintaining reasonable quality. Grok 4 Fast provides another budget-friendly option with better support infrastructure.
Combine budget models for simple tasks with strategic use of premium models for critical queries. Route 80% of traffic to cheap models, 20% to expensive ones.
For Maximum Quality
OpenAI’s GPT-5.2 Pro and Claude Opus 4.1 represent the current quality ceiling. Expect to pay 10-30x more than mid-tier options.
Only justified when accuracy directly impacts revenue or risk (legal analysis, medical applications, critical infrastructure).
For Balanced Performance
GPT-5.2 ($1.75 input) and Claude Opus 4.6 ($5.00 input) hit the sweet spot for most production applications. Strong performance without extreme costs.
Google’s Gemini 3.1 Pro at $2.00 input offers competitive pricing with excellent multimodal capabilities.
For Google Cloud Users
Vertex AI provides unified access to Gemini plus third-party models. The integrated ecosystem simplifies deployment if you’re already on GCP infrastructure.
Take advantage of Gemini 2.5 Pro’s 10,000 free grounded prompts daily for search-augmented applications.
For AWS Environments
Bedrock offers the widest model selection with unified billing. Good choice for organizations standardized on AWS who want access to Anthropic, Meta, and other providers through one interface.
Frequently Asked Questions
What’s the cheapest LLM API in 2026?
DeepSeek V3.2 currently offers the lowest per-token pricing at approximately $0.28 per million input tokens and $0.40 for reasoning output. Grok 4 Fast from xAI runs $0.20 input / $0.50 output. For OpenAI users, GPT-5 Nano costs $0.025 input / $0.20 output per million tokens.
How much does GPT-5 cost compared to GPT-4?
According to OpenAI’s official pricing, GPT-5.2 costs $1.75 input / $14.00 output per million tokens. Legacy GPT-4 runs $30.00 input / $60.00 output. GPT-5.2 is dramatically cheaper (94% reduction on input, 77% reduction on output) while offering better performance.
Are batch APIs really 50% cheaper?
Yes. Both OpenAI and Amazon Bedrock offer 50% discounts for batch processing with 24-hour turnaround. OpenAI’s batch pricing shows GPT-5.2 drops to $0.875 input / $7.00 output compared to $1.75 / $14.00 standard. Any non-urgent workload should use batch endpoints.
What are prompt caching costs?
OpenAI charges 10% of standard input costs for cached tokens. GPT-5.2 cached input costs $0.175 versus $1.75 regular. Anthropic offers 90% discounts on cache hits but charges for cache writes. Claude Opus 4.6 cache writes cost $6.25-$10.00 per million tokens depending on duration, while cache hits run $0.50 versus $5.00 base input.
How do I calculate token usage for my application?
Use provider-specific tokenizer tools. OpenAI offers tiktoken library. Generally, one token equals roughly four characters or 0.75 words. A 1,000-word document contains approximately 1,333 tokens. Test your actual prompts and responses with tokenizers to get precise counts before estimating costs.
Does Claude cost more than GPT?
Depends on the models compared. Claude Opus 4.6 ($5.00 input) costs more than GPT-5.2 ($1.75 input) but less than GPT-5.2 Pro ($21.00 input). Output costs show bigger gaps — Claude Opus charges $25.00 output versus $14.00 for GPT-5.2. However, Claude’s aggressive caching discounts (90% off) can make it cheaper for applications with high context reuse.
What’s the most cost-effective model for chatbots?
For general customer service chatbots, GPT-4.1 Mini ($0.20 input / $0.80 output) or GPT-5 Mini ($0.25 input / $2.00 output) offer the best balance of quality and cost. For simpler FAQ bots, GPT-5 Nano ($0.025 input / $0.20 output) works well. Implement intelligent routing to use nano/mini models for simple queries and upgrade to flagship models only when complexity requires it.
Making Your LLM API Decision
Pricing shouldn’t be your only consideration. Model quality, latency, context window size, and integration ecosystem all matter.
But understanding cost structures helps you avoid the common trap of overspending on capability you don’t need. Most applications get 90% of the value from mid-tier models at 20% of flagship pricing.
Start with these steps:
First, profile your actual usage patterns. Track token counts, response lengths, and query complexity for your specific use case. Real data beats assumptions.
Second, test multiple providers on your actual workload. Performance benchmarks don’t always translate to your domain. Run A/B tests measuring both quality and cost.
Third, implement cost controls before scaling. Set budget alerts, enable caching, route queries intelligently. These optimizations deliver bigger savings than switching providers.
The LLM pricing landscape will keep shifting. New models launch monthly, prices fluctuate, and capabilities improve constantly. But the fundamentals remain consistent.
Understand token-based pricing. Monitor actual usage. Match model capability to task requirements. Optimize for cache reuse. Use batch processing when possible.
Organizations implementing cost optimization practices can potentially achieve significant savings through optimized model selection and usage patterns than those who just pick a provider and start calling APIs at full list prices. That’s the difference between sustainable AI adoption and budget-busting experiments that get shut down.
Ready to optimize your LLM spending? Start by auditing your current usage and implementing intelligent prompt routing. The savings compound quickly.