Quick Summary: Big data challenges include data volume explosion, quality issues, integration complexity, security risks, skill shortages, scalability bottlenecks, and governance gaps. Solutions span cloud infrastructure, automated quality tools, unified data platforms, encryption frameworks, training programs, and governance policies that enable organizations to transform raw data into actionable insights.
Data is everywhere. Every click, transaction, sensor reading, and social media post generates more of it. For example, Walmart alone collects more than 2.5 petabytes of data every hour from customer transactions—that’s 2.5 million gigabytes per hour. To put that in perspective, the Library of Congress held 235 terabytes of information in 2011, and one exabyte is roughly 4,255,319 times that amount.
But here’s the thing: having massive amounts of data doesn’t automatically translate to business value. Organizations face a gauntlet of obstacles when trying to collect, store, process, and analyze big data. Statista reports that 75% of businesses worldwide use data to drive innovation, and 50% report that data helps them compete in the market. Yet many struggle to bridge the gap between raw data and actionable insights.
This guide breaks down the most pressing big data challenges and the solutions that actually work. Real talk: some of these problems don’t have silver-bullet answers. But the strategies below—backed by research from NIST, IEEE, and enterprise case studies—offer proven paths forward.
Challenge #1: Data Volume Explosion
The sheer scale of data generation has outpaced traditional infrastructure. Companies now handle petabytes or exabytes of information, growing faster than their systems can support.
Storage costs can reach millions annually. Query performance degrades as datasets expand. Infrastructure becomes a bottleneck for analytics and machine learning initiatives. When data volume doubles every few years, yesterday’s solutions become tomorrow’s constraints.
Why Volume Matters
Back in 2010, it cost $600 to buy a disk drive that could store all of the world’s music, according to NIST. Storage has become cheaper, but data generation has accelerated even faster. Organizations generate structured data from transactions, unstructured data from documents and media, and semi-structured data from logs and sensors—all simultaneously.
Healthcare, financial services, and telecoms face particularly acute volume challenges. These sectors operate at adoption rates between 90% and 100% for big data and AI technologies, generating massive datasets that must be retained for compliance, analysis, and model training.
Solutions for Volume Management
- Cloud storage architectures provide elastic capacity that scales with demand. Services like Amazon S3, Google Cloud Storage, and Azure Blob Storage eliminate the need to provision hardware years in advance.
- Data compression reduces storage needs by 50–80%, depending on data type. Columnar formats like Parquet and ORC achieve high compression ratios while enabling fast query performance for analytics workloads.
- Automated lifecycle management moves cold data to cheaper storage tiers. Data accessed rarely can shift from hot SSD storage to archival tiers at a fraction of the cost, preserving budget for frequently accessed datasets.
- Data tiering strategies classify information by access patterns. Hot data stays on fast storage, warm data moves to balanced tiers, and cold data archives to low-cost object storage. This approach optimizes both performance and cost.
Challenge #2: Data Quality Issues
Garbage in, garbage out. Poor data quality undermines every downstream process—analytics, reporting, machine learning, and decision-making all suffer when source data contains errors, duplicates, or inconsistencies.
Data quality problems arise from multiple sources: manual entry errors, system integration bugs, inconsistent formatting across departments, missing values, and outdated records. When organizations merge data from dozens of systems, quality issues multiply.
The Real Cost of Bad Data
Bad data leads to bad decisions. Marketing campaigns target the wrong customers. Supply chain models make faulty predictions. Financial reports contain inaccuracies. Machine learning models trained on flawed data produce unreliable outputs.
Organizations waste time and resources cleaning data reactively rather than preventing quality issues proactively. Teams spend more time debugging data problems than generating insights.
Solutions for Data Quality
- Automated validation rules catch errors at ingestion time. Schema validation, format checks, range constraints, and referential integrity rules reject bad data before it pollutes downstream systems.
- Data profiling tools analyze datasets to identify patterns, anomalies, and quality issues. Profiling surfaces missing values, outliers, duplicates, and inconsistencies that manual review would miss.
- Master data management (MDM) creates a single source of truth for critical entities like customers, products, and locations. MDM systems resolve conflicts, deduplicate records, and maintain golden records.
- Data quality monitoring tracks metrics over time. Automated dashboards show completeness, accuracy, consistency, and timeliness scores, alerting teams when quality degrades.
| Data Quality Dimension | Common Problems | Solution Approach |
|---|---|---|
| Accuracy | Incorrect values, typos, outdated records | Validation rules, external verification, regular audits |
| Completeness | Missing fields, null values, partial records | Mandatory field enforcement, imputation, source system fixes |
| Consistency | Conflicting data across systems, format variations | Standardization, MDM, canonical data models |
| Timeliness | Stale data, delayed updates, batch lag | Real-time pipelines, CDC, automated refresh schedules |
| Uniqueness | Duplicate records, redundant entries | Deduplication algorithms, fuzzy matching, entity resolution |
Challenge #3: Data Integration Complexity
Modern organizations run dozens or hundreds of systems—CRM platforms, ERP systems, marketing automation tools, IoT devices, third-party APIs, legacy databases, and cloud applications. Each speaks its own data dialect.
Integrating disparate data sources is time-consuming, error-prone, and expensive. Different schemas, formats, update frequencies, and access methods make integration a perpetual challenge. One enterprise case study showed that development efficiency improved by 50% and codebase size shrank by 40% after implementing a unified data pipeline framework.
Why Integration Matters
Business questions rarely live within a single system. Understanding customer lifetime value requires joining CRM data, transaction records, support tickets, and marketing interactions. Supply chain optimization needs inventory data, supplier information, shipping logs, and demand forecasts.
Without integration, organizations operate on partial information. Siloed data creates conflicting reports, duplicated effort, and blind spots.
Solutions for Integration
- Unified data platforms provide a central hub for ingestion, transformation, and access. Modern data platforms support batch and streaming ingestion, schema evolution, and multiple query engines.
- ETL/ELT automation tools handle the mechanics of extraction, transformation, and loading. Cloud-native services like AWS Glue, Azure Data Factory, and Google Dataflow reduce custom coding.
- Change data capture (CDC) streams only modified records rather than full table scans. CDC reduces latency and infrastructure load while keeping downstream systems synchronized.
- API management layers standardize access to diverse systems. API gateways provide consistent interfaces, authentication, rate limiting, and monitoring across all data sources.
- Data virtualization creates logical views without physically moving data. Virtualization enables federated queries across systems while minimizing data replication and storage costs.
Challenge #4: Scalability and Performance Bottlenecks
Systems that work fine with gigabytes of data collapse under petabytes. Query performance degrades. Processing jobs time out. Real-time analytics become batch jobs that run overnight.
Scalability challenges appear as data volume grows, user concurrency increases, and query complexity rises. What worked at 100 users breaks at 10,000 users. Reports that ran in seconds now take hours.
The Performance Trap
Organizations often address scalability reactively—throwing more hardware at the problem or optimizing queries case-by-case. These approaches provide temporary relief but don’t solve the underlying architectural limitations.
According to research on distributed big data frameworks, 70% of Hadoop installations will fall short of their cost savings and revenue generation goals due to a combination of inadequate skills. The right technology matters, but so does the right design.
Solutions for Scalability
- Distributed processing frameworks like Apache Spark and Apache Flink parallelize computation across clusters. These frameworks handle petabyte-scale datasets by distributing work across hundreds or thousands of nodes.
- Columnar storage formats optimize analytical queries. Parquet, ORC, and similar formats store data by column rather than row, enabling efficient filtering and aggregation on large datasets.
- Partitioning strategies divide large tables into manageable chunks. Date-based partitioning, for example, lets queries scan only relevant partitions rather than entire tables.
- Caching and materialized views precompute expensive queries. Frequently accessed aggregations and joins get cached in memory or stored as materialized views, serving results in milliseconds rather than minutes.
- Query optimization rewrites inefficient queries. Modern query engines apply predicate pushdown, join reordering, and cost-based optimization to minimize data scanned and computation required.
One enterprise case study documented in arXiv research showed performance improved by 500x in scalability and by 10x in throughput after implementing a declarative data pipeline framework. Academic experiments showed 5.7x faster throughput compared to non-framework approaches, with 99% CPU utilization.
Challenge #5: Data Security and Privacy
Big data means big risk. The more data organizations collect, the larger the target for cyberattacks. Data breaches expose customer information, trigger regulatory penalties, and damage reputations.
Healthcare data breaches cost $10.93 million on average. GDPR fines can reach 4% of annual revenue. Security isn’t optional—it’s a business imperative.
Security Threats in Big Data
Traditional security perimeters have dissolved. Data moves between on-premises systems, cloud platforms, partner networks, and mobile devices. Each endpoint and data transfer creates potential vulnerabilities.
Insider threats pose particular challenges. Employees with legitimate access can exfiltrate sensitive data. Overly broad permissions grant users access to information they don’t need. Audit trails are often incomplete or ignored.
Solutions for Security and Privacy
- Encryption everywhere protects data at rest and in transit. Modern encryption standards like AES-256 secure stored data, while TLS protects data moving across networks. Encryption keys must be rotated regularly and stored separately from encrypted data.
- Access control and authentication enforce least-privilege principles. Role-based access control (RBAC) grants permissions by job function. Multi-factor authentication (MFA) prevents credential theft. Just-in-time access provisions temporary permissions that expire automatically.
- Data masking and anonymization protect sensitive information in non-production environments. Masking replaces real values with realistic fake data. Anonymization removes personally identifiable information (PII) while preserving analytical utility.
- Audit logging and monitoring track who accesses what data when. Security information and event management (SIEM) systems aggregate logs, detect anomalies, and alert security teams to suspicious activity.
- Data loss prevention (DLP) tools monitor data movement and block unauthorized transfers. DLP policies prevent sensitive data from leaving approved systems via email, file transfer, or removable media.
Challenge #6: Shortage of Skilled Professionals
Technology is only part of the equation. Organizations need people who understand data architecture, distributed systems, statistical modeling, and domain-specific analytics. Those people are scarce.
Demand for data engineers, data scientists, and machine learning engineers far exceeds supply. Competition for talent is fierce. Salaries rise, yet positions remain unfilled for months.
The Skills Gap
Big data requires a blend of skills rarely found in a single person. Engineers who build scalable pipelines may lack statistical expertise. Data scientists skilled in modeling may struggle with production deployment. Domain experts understand the business but not the technology.
Training takes time. Technologies evolve rapidly. What developers learned two years ago may already be obsolete. Continuous learning isn’t optional—it’s the only way to stay relevant.
Solutions for Skill Shortages
- Training and upskilling programs develop internal talent. Organizations that invest in education create career paths and reduce turnover. Online courses, certifications, and hands-on projects build practical skills.
- Specialized recruitment targets niche skill sets. Rather than seeking unicorns who do everything, build teams with complementary strengths—data engineers, analysts, scientists, and domain experts working together.
- Managed services and consulting fill gaps temporarily. Cloud providers offer managed big data services that handle infrastructure complexity. Consulting firms provide expertise for architecture design and initial implementation.
- Low-code and no-code tools democratize data work. Modern platforms enable business analysts to build dashboards, create reports, and perform basic analytics without writing code. This frees specialized talent for complex problems.
- Knowledge sharing and documentation preserve institutional knowledge. Well-documented architectures, runbooks, and best practices help new team members ramp up faster and reduce dependency on specific individuals.
Challenge #7: Lack of Data Governance
Without governance, data chaos reigns. Multiple versions of the same metric produce conflicting reports. Sensitive data proliferates without controls. Regulatory compliance becomes impossible to verify.
Data governance establishes policies, processes, and responsibilities for data management. It defines who owns which data, how data quality is measured, who can access what, and how compliance is ensured.
Why Governance Matters
Governance isn’t about bureaucracy—it’s about making data trustworthy and usable. When business users can’t find the data they need, or don’t trust the data they find, investments in big data infrastructure deliver no value.
Regulatory requirements like GDPR, CCPA, HIPAA, and SOX mandate governance controls. Organizations that can’t demonstrate compliance face fines, lawsuits, and operational restrictions.
Solutions for Data Governance
- Data catalogs create searchable inventories of available datasets. Modern catalogs include metadata, lineage, quality scores, and usage statistics. Users can discover relevant data without emailing colleagues or guessing.
- Data stewardship programs assign ownership and accountability. Data stewards define standards, resolve quality issues, and approve access requests for their domains. Clear ownership prevents the tragedy of the commons.
- Policy automation enforces rules consistently. Rather than relying on manual processes, automated systems apply classification tags, encryption, retention policies, and access controls based on data attributes.
- Lineage tracking shows data origins and transformations. Lineage helps debug quality issues, assess change impact, and satisfy audit requirements by documenting exactly how reports and models derive their inputs.
- Compliance frameworks structure governance efforts. Frameworks like DAMA-DMBOK and DCAM provide blueprints for governance programs, helping organizations build capabilities systematically rather than ad hoc.
| Governance Component | Purpose | Key Tools |
|---|---|---|
| Data Catalog | Inventory and discovery | Alation, Collibra, Azure Purview, AWS Glue Data Catalog |
| Data Quality | Monitoring and improvement | Great Expectations, Talend Data Quality, Informatica DQ |
| Access Control | Security and compliance | Apache Ranger, AWS IAM, Azure RBAC |
| Lineage | Traceability and impact analysis | Lineage tools in Alation, Collibra, Manta |
| Policy Management | Automated enforcement | Immuta, BigID, OneTrust |

Solve Big Data Problems With AI Superior
Big data projects often slow down because the data is scattered, inconsistent, hard to interpret, or disconnected from real business decisions. AI Superior can support companies through AI consulting, AI and data strategy, business intelligence, data analytics, machine learning, predictive analytics, and custom AI software development. For big data challenges, this can help with use case discovery, data preparation, analytics workflows, model development, and turning complex datasets into practical tools.
AI Superior’s support may include:
- Reviewing big data use cases and business goals
- Preparing data for analytics or machine learning
- Building predictive analytics and BI solutions
- Developing custom AI tools around business data
- Integrating analytics outputs into existing workflows
Contact AI Superior to discuss how your big data challenges can be turned into practical AI or analytics solutions.
Real-World Success Stories
Theory is one thing. Implementation is another. Here’s what organizations have achieved when tackling these challenges head-on.
An enterprise case study documented in arXiv research showed remarkable results from implementing a declarative data pipeline framework. Development efficiency improved by 50%. Collaboration and troubleshooting efforts compressed from weeks to days. Most dramatically, performance improved by 500x in scalability and 10x in throughput.
The codebase shrank by 40%, reducing maintenance burden and making the system easier to understand. These aren’t incremental improvements—they represent fundamental shifts in capability.
Academic experiments demonstrated similar patterns. One study achieved 5.7x faster throughput compared to non-framework implementations while maintaining 99% CPU utilization. Proper architecture and tooling choices matter enormously.
Cloud vs. On-Premises Deployment
Where should big data infrastructure live? The answer depends on specific requirements, but the trend is clear: cloud adoption continues to accelerate.
Cloud platforms offer elastic scalability, managed services, and consumption-based pricing. Organizations can provision massive compute resources for peak workloads and scale down during quiet periods. Managed services handle infrastructure complexity, patching, and upgrades.
But on-premises deployments retain advantages for specific scenarios. Latency-sensitive applications, highly regulated data, and existing infrastructure investments can favor on-premises or hybrid architectures.
Hybrid approaches combine both worlds. Organizations keep sensitive data on-premises while leveraging cloud resources for burst capacity and analytics. Data replication, secure connectivity, and unified management tools enable seamless hybrid operation.
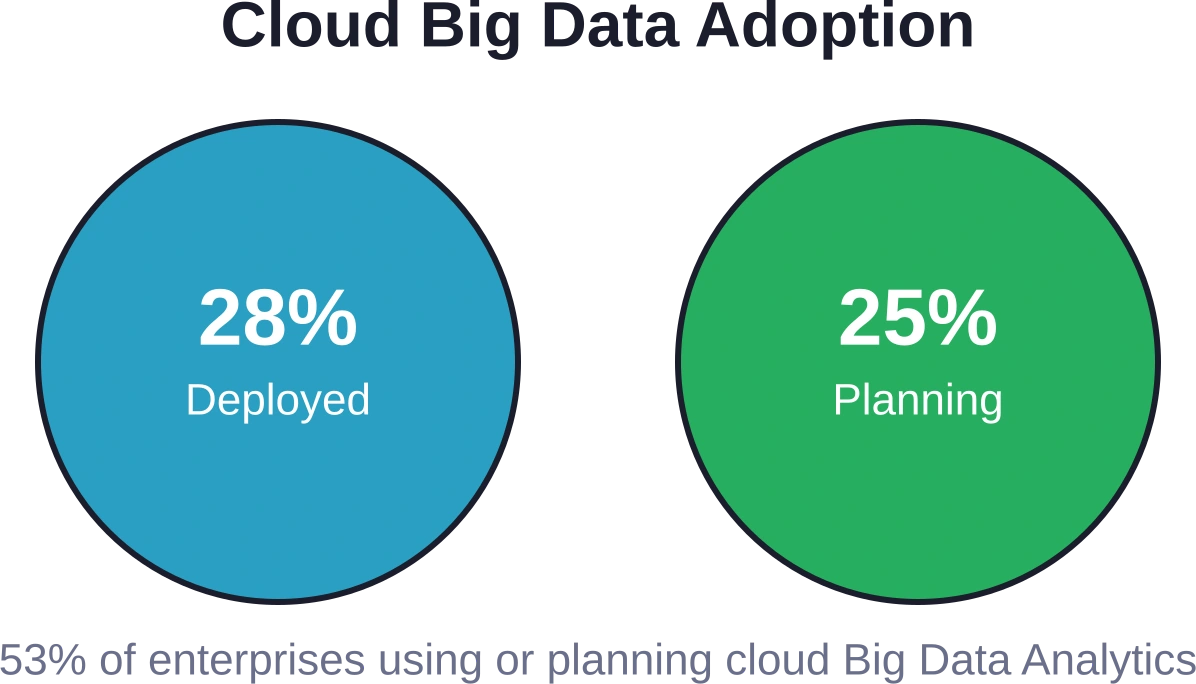
Frequently Asked Questions
What is the biggest challenge in big data?
Data volume explosion ranks as the most fundamental challenge. Organizations generate and collect data faster than traditional infrastructure can store, process, or analyze it. This challenge cascades into storage costs, query performance degradation, and infrastructure bottlenecks. Solving volume challenges often requires cloud architectures, distributed processing frameworks, and compression strategies.
How do you solve data quality problems in big data?
Automated validation rules catch errors at ingestion time before bad data pollutes downstream systems. Data profiling tools analyze datasets to identify anomalies and quality issues. Master data management creates single sources of truth for critical entities. Data quality monitoring tracks metrics over time and alerts teams when quality degrades. Combining these approaches prevents quality problems rather than fixing them reactively.
Why is big data security so difficult?
Big data security challenges stem from scale, distribution, and complexity. Data moves between on-premises systems, cloud platforms, and partner networks, creating numerous potential vulnerabilities. The sheer volume makes comprehensive monitoring difficult. Multiple access points and legitimate users complicate access control. Healthcare data breaches cost $10.93 million on average, while GDPR fines can reach 4% of annual revenue, making security failures extremely costly.
What skills are needed for big data roles?
Big data professionals need technical skills in distributed systems, programming languages like Python and SQL, and frameworks like Apache Spark. Data engineers focus on building pipelines and infrastructure. Data scientists require statistics, machine learning, and domain expertise. Both roles benefit from understanding cloud platforms, data modeling, and system design. Continuous learning is essential as technologies evolve rapidly.
How much does big data infrastructure cost?
Costs vary enormously based on scale and architecture. Businesses spent $595.7 billion on computing and storage infrastructure in 2024 (per Datamation). Cloud platforms offer consumption-based pricing that scales with usage. Data compression reduces storage needs by 50–80%, directly cutting costs. Managed services reduce operational overhead but charge premium prices. On-premises infrastructure requires upfront capital investment but lower per-unit costs at scale.
Is cloud or on-premises better for big data?
Cloud platforms dominate new deployments. Cloud offers elastic scalability, managed services, and consumption-based pricing. On-premises deployments make sense for latency-sensitive applications, highly regulated data, and organizations with existing infrastructure investments. Hybrid approaches combine both, keeping sensitive data on-premises while leveraging cloud resources for burst capacity.
What is data governance and why does it matter?
Data governance establishes policies, processes, and responsibilities for data management. It defines data ownership, quality standards, access controls, and compliance procedures. Without governance, organizations face conflicting reports, uncontrolled sensitive data proliferation, and regulatory compliance gaps. Governance makes data trustworthy and usable through data catalogs, stewardship programs, policy automation, lineage tracking, and compliance frameworks.
Conclusion
Big data challenges are real, but so are the solutions. Data volume continues to grow exponentially—Walmart’s 2.5 petabytes per hour stands as a vivid reminder. But cloud infrastructure, compression strategies, and distributed processing frameworks provide proven paths to manage that growth.
Data quality, integration complexity, scalability bottlenecks, security risks, skill shortages, and governance gaps each pose obstacles. Yet organizations that systematically address these challenges achieve remarkable results: 500x scalability improvements, 50% development efficiency gains, and 10x throughput boosts.
The key is moving from reactive problem-solving to proactive architecture. Automated quality validation beats manual cleanup. Unified data platforms eliminate integration spaghetti. Encryption and access controls prevent breaches rather than responding to them. Training programs build internal capability instead of endlessly recruiting.
That potential exists across industries. The question isn’t whether big data delivers value. The question is whether organizations will tackle the challenges required to capture it.
Start with one challenge. Pick the biggest pain point in the current environment. Implement one solution. Measure results. Build momentum. Big data transformation doesn’t happen overnight, but systematic progress compounds over time.
Ready to tackle your biggest big data challenge? Assess current state, prioritize solutions, and begin implementation today.