Korte samenvatting: De uitdagingen van big data omvatten onder andere de explosieve groei van datavolumes, kwaliteitsproblemen, complexe integratie, beveiligingsrisico's, tekorten aan gekwalificeerd personeel, knelpunten in schaalbaarheid en lacunes in governance. Oplossingen variëren van cloudinfrastructuur en geautomatiseerde kwaliteitscontroletools tot uniforme dataplatformen, encryptiekaders, trainingsprogramma's en governancebeleid, waarmee organisaties ruwe data kunnen omzetten in bruikbare inzichten.
Data is overal. Elke klik, transactie, sensormeting en socialmediapost genereert er meer van. Walmart verzamelt bijvoorbeeld alleen al meer dan 2,5 petabyte aan data per uur via klanttransacties – dat is 2,5 miljoen gigabyte per uur. Ter vergelijking: de Library of Congress bezat in 2011 235 terabyte aan informatie, en één exabyte is ongeveer 4.255.319 keer zoveel.
Maar er is een probleem: enorme hoeveelheden data leiden niet automatisch tot zakelijke waarde. Organisaties stuiten op talloze obstakels bij het verzamelen, opslaan, verwerken en analyseren van big data. Volgens Statista gebruikt 751.300.000 bedrijven wereldwijd data om innovatie te stimuleren, en 501.300.000 bedrijven geven aan dat data hen helpt te concurreren op de markt. Toch worstelen velen met de kloof tussen ruwe data en bruikbare inzichten.
Deze gids behandelt de meest urgente uitdagingen op het gebied van big data en de oplossingen die daadwerkelijk werken. Eerlijk gezegd: voor sommige van deze problemen bestaat geen wondermiddel. Maar de onderstaande strategieën – onderbouwd door onderzoek van NIST, IEEE en praktijkvoorbeelden uit het bedrijfsleven – bieden bewezen wegen vooruit.
Uitdaging #1: Explosie van datavolume
De enorme schaal waarop data wordt gegenereerd, heeft de traditionele infrastructuur overtroffen. Bedrijven verwerken nu petabytes of exabytes aan informatie, en deze hoeveelheid groeit sneller dan hun systemen aankunnen.
Opslagkosten kunnen oplopen tot miljoenen per jaar. De queryprestaties verslechteren naarmate datasets groter worden. De infrastructuur wordt een knelpunt voor analyses en machine learning-initiatieven. Wanneer het datavolume elke paar jaar verdubbelt, worden de oplossingen van gisteren de beperkingen van morgen.
Waarom volume ertoe doet
Volgens het NIST kostte het in 2010 $600 om een harde schijf te kopen die alle muziek ter wereld kon opslaan. Opslag is goedkoper geworden, maar de dataproductie is nog sneller toegenomen. Organisaties genereren gestructureerde data uit transacties, ongestructureerde data uit documenten en media, en semi-gestructureerde data uit logbestanden en sensoren – allemaal tegelijkertijd.
De sectoren gezondheidszorg, financiële dienstverlening en telecommunicatie staan voor bijzonder grote uitdagingen op het gebied van datavolume. Deze sectoren hanteren adoptiesnelheden tussen 901 TP3T en 1001 TP3T voor big data en AI-technologieën, wat resulteert in enorme datasets die bewaard moeten worden voor naleving van regelgeving, analyse en modeltraining.
Oplossingen voor volumebeheer
- Cloudopslagarchitecturen bieden elastische capaciteit die meegroeit met de vraag. Diensten zoals Amazon S3, Google Cloud Storage en Azure Blob Storage maken het overbodig om jaren van tevoren hardware te reserveren.
- Datacompressie vermindert de opslagbehoefte met 50 tot 801 TP3T, afhankelijk van het gegevenstype. Kolomgeoriënteerde formaten zoals Parquet en ORC bereiken hoge compressieverhoudingen en zorgen tegelijkertijd voor snelle queryprestaties voor analytische workloads.
- Geautomatiseerd lifecyclemanagement verplaatst inactieve data naar goedkopere opslaglagen. Data die zelden worden geraadpleegd, kunnen tegen een fractie van de kosten van actieve SSD-opslag naar archiefopslag worden verplaatst, waardoor budget vrijkomt voor datasets die veelvuldig worden gebruikt.
- Datatieringstrategieën classificeren informatie op basis van toegangspatronen. Veelgebruikte data blijft op snelle opslag, minder gebruikte data wordt verplaatst naar gebalanceerde opslaglagen en minder gebruikte data wordt gearchiveerd in goedkope objectopslag. Deze aanpak optimaliseert zowel de prestaties als de kosten.
Uitdaging #2: Problemen met de datakwaliteit
Wat erin gaat, komt er ook weer uit. Slechte datakwaliteit ondermijnt elk vervolgproces: analyses, rapportages, machine learning en besluitvorming lijden er allemaal onder wanneer brondata fouten, duplicaten of inconsistenties bevatten.
Problemen met de datakwaliteit kunnen verschillende oorzaken hebben: handmatige invoerfouten, systeemintegratiefouten, inconsistente opmaak tussen afdelingen, ontbrekende waarden en verouderde records. Wanneer organisaties gegevens uit tientallen systemen samenvoegen, nemen de kwaliteitsproblemen toe.
De werkelijke kosten van slechte data
Slechte data leiden tot slechte beslissingen. Marketingcampagnes richten zich op de verkeerde klanten. Supply chain-modellen doen onjuiste voorspellingen. Financiële rapporten bevatten onnauwkeurigheden. Machine learning-modellen die getraind zijn op gebrekkige data produceren onbetrouwbare resultaten.
Organisaties verspillen tijd en middelen aan het reactief opschonen van data in plaats van kwaliteitsissues proactief te voorkomen. Teams besteden meer tijd aan het oplossen van dataproblemen dan aan het genereren van inzichten.
Oplossingen voor datakwaliteit
- Geautomatiseerde validatieregels sporen fouten op tijdens het importeren. Schemavalidatie, formaatcontroles, bereikbeperkingen en referentiële integriteitsregels weren onjuiste gegevens af voordat ze downstream-systemen vervuilen.
- Data-profileringstools analyseren datasets om patronen, afwijkingen en kwaliteitsproblemen te identificeren. Profilering brengt ontbrekende waarden, uitschieters, duplicaten en inconsistenties aan het licht die bij handmatige controle over het hoofd zouden worden gezien.
- Master data management (MDM) creëert één betrouwbare bron voor cruciale gegevens zoals klanten, producten en locaties. MDM-systemen lossen conflicten op, verwijderen dubbele records en bewaren referentiegegevens.
- Datakwaliteitsmonitoring volgt de meetwaarden over tijd. Geautomatiseerde dashboards tonen scores voor volledigheid, nauwkeurigheid, consistentie en actualiteit, en waarschuwen teams wanneer de kwaliteit afneemt.
| Dimensie van de datakwaliteit | Veelvoorkomende problemen | Oplossingsaanpak |
|---|---|---|
| Nauwkeurigheid | Onjuiste waarden, typefouten, verouderde gegevens | Validatieregels, externe verificatie, regelmatige audits |
| Volledigheid | Ontbrekende velden, null-waarden, gedeeltelijke records | Verplichte veldhandhaving, imputatie, correcties van bronsystemen |
| Samenhang | Tegenstrijdige gegevens tussen systemen, variaties in opmaak | Standaardisatie, MDM, canonieke datamodellen |
| Tijdigheid | Verouderde gegevens, vertraagde updates, batchvertraging | Realtime pipelines, CDC, geautomatiseerde vernieuwingsschema's |
| Uniekheid | Dubbele records, overbodige invoer | Deduplicatiealgoritmen, fuzzy matching, entiteitsresolutie |
Uitdaging #3: Complexiteit van data-integratie
Moderne organisaties gebruiken tientallen of zelfs honderden systemen: CRM-platforms, ERP-systemen, marketingautomatiseringstools, IoT-apparaten, API's van derden, legacy-databases en cloudapplicaties. Elk systeem spreekt zijn eigen datataal.
Het integreren van uiteenlopende gegevensbronnen is tijdrovend, foutgevoelig en kostbaar. Verschillende schema's, formaten, updatefrequenties en toegangsmethoden maken integratie tot een voortdurende uitdaging. Een casestudy bij een bedrijf toonde aan dat de ontwikkelingsefficiëntie met 501 TP3T verbeterde en de codebasegrootte met 401 TP3T afnam na de implementatie van een uniform datapipeline-framework.
Waarom integratie belangrijk is
Zakelijke vraagstukken blijven zelden binnen één systeem bestaan. Om de klantwaarde op lange termijn te begrijpen, is het nodig om CRM-gegevens, transactiegegevens, supporttickets en marketinginteracties te combineren. Voor de optimalisatie van de toeleveringsketen zijn voorraadgegevens, leveranciersinformatie, verzendlogboeken en vraagvoorspellingen nodig.
Zonder integratie werken organisaties met onvolledige informatie. Gefragmenteerde data leidt tot tegenstrijdige rapporten, dubbel werk en blinde vlekken.
Oplossingen voor integratie
- Geïntegreerde dataplatformen bieden een centrale hub voor data-invoer, -transformatie en -toegang. Moderne dataplatformen ondersteunen batch- en streaming-data-invoer, schema-evolutie en meerdere query-engines.
- ETL/ELT-automatiseringstools verzorgen de extractie, transformatie en het laden van gegevens. Cloudgebaseerde services zoals AWS Glue, Azure Data Factory en Google Dataflow verminderen de behoefte aan maatwerkprogrammering.
- Change Data Capture (CDC) streamt alleen gewijzigde records in plaats van volledige tabelscans. CDC vermindert de latentie en de belasting van de infrastructuur, terwijl de systemen stroomafwaarts gesynchroniseerd blijven.
- API-beheerlagen standaardiseren de toegang tot diverse systemen. API-gateways bieden consistente interfaces, authenticatie, snelheidsbeperking en monitoring voor alle gegevensbronnen.
- Datavirtualisatie creëert logische weergaven zonder fysieke dataverplaatsing. Virtualisatie maakt gefedereerde query's over verschillende systemen mogelijk, terwijl de kosten voor datareplicatie en -opslag tot een minimum worden beperkt.
Uitdaging #4: Schaalbaarheid en prestatieknelpunten
Systemen die prima werken met gigabytes aan data, begeven het onder petabytes. De queryprestaties verslechteren. Verwerkingstaken lopen vast. Realtime analyses worden batchtaken die 's nachts draaien.
Schaalbaarheidsproblemen ontstaan naarmate het datavolume groeit, het aantal gelijktijdige gebruikers toeneemt en de complexiteit van query's stijgt. Wat werkte bij 100 gebruikers, werkt niet meer bij 10.000 gebruikers. Rapporten die voorheen in seconden werden uitgevoerd, duren nu uren.
De prestatieval
Organisaties pakken schaalbaarheidsproblemen vaak reactief aan: ze zetten meer hardware in of optimaliseren query's geval voor geval. Deze benaderingen bieden tijdelijke verlichting, maar lossen de onderliggende architectonische beperkingen niet op.
Volgens onderzoek naar gedistribueerde big data-frameworks zullen 701 TP3T aan Hadoop-installaties hun doelstellingen op het gebied van kostenbesparing en omzetgeneratie niet halen vanwege een combinatie van onvoldoende expertise. De juiste technologie is belangrijk, maar het juiste ontwerp is dat ook.
Oplossingen voor schaalbaarheid
- Gedistribueerde verwerkingsframeworks zoals Apache Spark en Apache Flink paralleliseren berekeningen over clusters. Deze frameworks verwerken datasets van petabyte-formaat door het werk te verdelen over honderden of duizenden knooppunten.
- Kolomgeoriënteerde opslagformaten optimaliseren analytische query's. Parquet, ORC en vergelijkbare formaten slaan gegevens op per kolom in plaats van per rij, waardoor efficiënte filtering en aggregatie op grote datasets mogelijk is.
- Partitioneringsstrategieën verdelen grote tabellen in beheersbare delen. Datumgebaseerde partitionering zorgt er bijvoorbeeld voor dat query's alleen de relevante partities doorzoeken in plaats van de hele tabel.
- Caching en gematerialiseerde weergaven zorgen ervoor dat kostbare query's vooraf worden berekend. Veelgebruikte aggregaties en joins worden in het geheugen gecached of als gematerialiseerde weergaven opgeslagen, waardoor de resultaten binnen milliseconden in plaats van minuten beschikbaar zijn.
- Query-optimalisatie herschrijft inefficiënte query's. Moderne query-engines passen predicaat-pushdown, join-herordening en kostengebaseerde optimalisatie toe om de hoeveelheid gescande data en de benodigde rekenkracht te minimaliseren.
Een casestudy van een bedrijf, gedocumenteerd in arXiv-onderzoek, toonde aan dat de prestaties met een factor 500 verbeterden op het gebied van schaalbaarheid en met een factor 10 in doorvoer na de implementatie van een declaratief datapipeline-framework. Academische experimenten lieten een 5,7 keer snellere doorvoer zien in vergelijking met benaderingen zonder framework, met een CPU-gebruik van 99%.
Uitdaging #5: Gegevensbeveiliging en privacy
Big data betekent grote risico's. Hoe meer data organisaties verzamelen, hoe groter het doelwit voor cyberaanvallen. Datalekken leggen klantgegevens bloot, leiden tot sancties van toezichthouders en schaden de reputatie.
Datalekken in de gezondheidszorg kosten gemiddeld 10,93 miljoen dollar. GDPR-boetes kunnen oplopen tot 41,3 biljoen dollar aan jaarlijkse inkomsten. Beveiliging is geen optie, maar een zakelijke noodzaak.
Beveiligingsrisico's in big data
Traditionele beveiligingsgrenzen zijn vervaagd. Gegevens worden verplaatst tussen lokale systemen, cloudplatforms, partnernetwerken en mobiele apparaten. Elk eindpunt en elke gegevensoverdracht creëert potentiële kwetsbaarheden.
Bedreigingen van binnenuit vormen een bijzondere uitdaging. Werknemers met legitieme toegang kunnen gevoelige gegevens stelen. Te ruime machtigingen geven gebruikers toegang tot informatie die ze niet nodig hebben. Auditsporen zijn vaak onvolledig of worden genegeerd.
Oplossingen voor beveiliging en privacy
- Versleuteling beschermt data, zowel in rust als tijdens transport. Moderne versleutelingsstandaarden zoals AES-256 beveiligen opgeslagen data, terwijl TLS data beschermt die via netwerken wordt verzonden. Versleutelingssleutels moeten regelmatig worden gewijzigd en apart van de versleutelde data worden opgeslagen.
- Toegangscontrole en authenticatie handhaven het principe van minimale bevoegdheden. Op rollen gebaseerde toegangscontrole (RBAC) verleent machtigingen op basis van functie. Multifactorauthenticatie (MFA) voorkomt diefstal van inloggegevens. Just-in-time toegang verleent tijdelijke machtigingen die automatisch verlopen.
- Gegevensmaskering en anonimisering beschermen gevoelige informatie in niet-productieomgevingen. Maskering vervangt echte waarden door realistische, fictieve gegevens. Anonimisering verwijdert persoonsgegevens (PII) met behoud van de analytische waarde.
- Auditlogboeken en monitoring registreren wie wanneer toegang heeft tot welke gegevens. Beveiligingsinformatie- en gebeurtenisbeheersystemen (SIEM) verzamelen logboeken, detecteren afwijkingen en waarschuwen beveiligingsteams voor verdachte activiteiten.
- Tools voor gegevensverliespreventie (DLP) bewaken gegevensverplaatsingen en blokkeren ongeautoriseerde overdrachten. DLP-beleid voorkomt dat gevoelige gegevens goedgekeurde systemen verlaten via e-mail, bestandsoverdracht of verwisselbare media.
Uitdaging #6: Tekort aan geschoolde professionals
Technologie is slechts een deel van de oplossing. Organisaties hebben mensen nodig die verstand hebben van data-architectuur, gedistribueerde systemen, statistische modellering en domeinspecifieke analyses. Zulke mensen zijn schaars.
De vraag naar data-engineers, datawetenschappers en machine learning-engineers is veel groter dan het aanbod. De concurrentie om talent is moordend. Salarissen stijgen, maar vacatures blijven maandenlang onvervuld.
Het tekort aan vaardigheden
Big data vereist een combinatie van vaardigheden die zelden in één persoon te vinden zijn. Ingenieurs die schaalbare pipelines bouwen, missen mogelijk statistische expertise. Datawetenschappers die bedreven zijn in modelleren, kunnen moeite hebben met de implementatie in een productieomgeving. Domeinexperts begrijpen de business, maar niet de technologie.
Training kost tijd. Technologieën ontwikkelen zich snel. Wat ontwikkelaars twee jaar geleden leerden, kan nu alweer achterhaald zijn. Continu leren is geen optie, maar de enige manier om relevant te blijven.
Oplossingen voor tekorten aan geschoolde arbeidskrachten
- Trainings- en bijscholingsprogramma's ontwikkelen intern talent. Organisaties die investeren in opleiding creëren carrièremogelijkheden en verminderen personeelsverloop. Online cursussen, certificeringen en praktijkprojecten ontwikkelen praktische vaardigheden.
- Gespecialiseerde werving richt zich op specifieke vaardigheden. In plaats van te zoeken naar alleskunners, kun je beter teams samenstellen met complementaire sterke punten: data-engineers, analisten, wetenschappers en domeinexperts die samenwerken.
- Managed services en consultancy vullen tijdelijk de gaten op. Cloudproviders bieden beheerde big data-diensten die de complexiteit van de infrastructuur afhandelen. Consultancybureaus leveren expertise voor architectuurontwerp en initiële implementatie.
- Low-code en no-code tools democratiseren dataverwerking. Moderne platforms stellen businessanalisten in staat dashboards te bouwen, rapporten te maken en basisanalyses uit te voeren zonder code te schrijven. Hierdoor komt specialistisch talent vrij voor complexe problemen.
- Kennisdeling en documentatie zorgen ervoor dat institutionele kennis behouden blijft. Goed gedocumenteerde architecturen, draaiboeken en best practices helpen nieuwe teamleden sneller ingewerkt te raken en verminderen de afhankelijkheid van specifieke personen.
Uitdaging #7: Gebrek aan gegevensbeheer
Zonder goed beheer heerst er datachaos. Meerdere versies van dezelfde meetwaarde leiden tot tegenstrijdige rapporten. Gevoelige gegevens verspreiden zich ongecontroleerd. Het wordt onmogelijk om de naleving van wet- en regelgeving te verifiëren.
Databeheer stelt beleid, processen en verantwoordelijkheden vast voor databeheer. Het definieert wie welke data bezit, hoe de datakwaliteit wordt gemeten, wie toegang heeft tot welke data en hoe naleving wordt gewaarborgd.
Waarom goed bestuur belangrijk is
Governance gaat niet over bureaucratie, maar over het betrouwbaar en bruikbaar maken van data. Wanneer zakelijke gebruikers de data die ze nodig hebben niet kunnen vinden, of de gevonden data niet vertrouwen, leveren investeringen in big data-infrastructuur geen waarde op.
Wettelijke voorschriften zoals GDPR, CCPA, HIPAA en SOX vereisen governance-controles. Organisaties die niet kunnen aantonen dat ze aan de regelgeving voldoen, riskeren boetes, rechtszaken en operationele beperkingen.
Oplossingen voor gegevensbeheer
- Datacatalogi creëren doorzoekbare inventarissen van beschikbare datasets. Moderne catalogi bevatten metadata, herkomstinformatie, kwaliteitsscores en gebruiksstatistieken. Gebruikers kunnen relevante gegevens vinden zonder collega's te hoeven mailen of te hoeven gissen.
- Programma's voor databeheer wijzen eigenaarschap en verantwoordelijkheid toe. Databeheerders definiëren standaarden, lossen kwaliteitskwesties op en keuren toegangsaanvragen voor hun domeinen goed. Duidelijk eigenaarschap voorkomt het probleem van de 'tragedie van de gemeenschappelijke bronnen'.
- Beleidsautomatisering zorgt voor consistente handhaving van regels. In plaats van te vertrouwen op handmatige processen, passen geautomatiseerde systemen classificatielabels, encryptie, bewaarbeleid en toegangscontroles toe op basis van data-attributen.
- Het traceren van de herkomst van gegevens laat de oorsprong en transformaties ervan zien. Het helpt bij het opsporen van kwaliteitskwesties, het beoordelen van de impact van wijzigingen en het voldoen aan auditvereisten door exact te documenteren hoe rapporten en modellen hun invoer verkrijgen.
- Compliancekaders structureren governance-inspanningen. Kaderwerken zoals DAMA-DMBOK en DCAM bieden blauwdrukken voor governanceprogramma's, waardoor organisaties systematisch in plaats van ad hoc capaciteiten kunnen opbouwen.
| Bestuurscomponent | Doel | Belangrijkste gereedschappen |
|---|---|---|
| Gegevenscatalogus | Inventarisatie en ontdekking | Alation, Collibra, Azure Purview, AWS Glue Data Catalog |
| Gegevenskwaliteit | Monitoring en verbetering | Great Expectations, Talend Data Quality, Informatica DQ |
| Toegangscontrole | Beveiliging en naleving | Apache Ranger, AWS IAM, Azure RBAC |
| Afstamming | Traceerbaarheid en impactanalyse | Afstammingstools in Alation, Collibra, Manta |
| Beleidsbeheer | Geautomatiseerde handhaving | Immuta, BigID, OneTrust |

Los big data-problemen op met superieure AI.
Big data-projecten lopen vaak vertraging op omdat de data verspreid, inconsistent, moeilijk te interpreteren of losgekoppeld is van daadwerkelijke zakelijke beslissingen. AI Superieur Wij kunnen bedrijven ondersteunen met AI-consultancy, AI- en datastrategie, business intelligence, data-analyse, machine learning, voorspellende analyses en de ontwikkeling van maatwerk AI-software. Bij big data-uitdagingen kunnen we helpen met het ontdekken van toepassingsmogelijkheden, datavoorbereiding, analyseworkflows, modelontwikkeling en het omzetten van complexe datasets in praktische tools.
De ondersteuning van AI Superior kan het volgende omvatten:
- Het beoordelen van toepassingsvoorbeelden van big data en bedrijfsdoelen.
- Gegevens voorbereiden voor analyses of machine learning.
- Het ontwikkelen van voorspellende analyses en BI-oplossingen.
- Het ontwikkelen van op maat gemaakte AI-tools op basis van bedrijfsgegevens.
- Het integreren van analyseresultaten in bestaande workflows
Neem contact op met AI Superior Om te bespreken hoe uw big data-uitdagingen kunnen worden omgezet in praktische AI- of analyseoplossingen.
Succesverhalen uit de praktijk
Theorie is één ding, implementatie is iets heel anders. Hieronder lees je wat organisaties hebben bereikt door deze uitdagingen rechtstreeks aan te pakken.
Een casestudy van een bedrijf, gedocumenteerd in arXiv Research, toonde opmerkelijke resultaten aan van de implementatie van een declaratief datapipeline-framework. De ontwikkelingsefficiëntie verbeterde met 501 TP3T. Samenwerking en het oplossen van problemen werden teruggebracht van weken naar dagen. Het meest opvallend was de prestatieverbetering: een factor 500 in schaalbaarheid en een factor 10 in doorvoer.
De codebasis is met 40% verkleind, waardoor de onderhoudslast is verminderd en het systeem gemakkelijker te begrijpen is. Dit zijn geen incrementele verbeteringen, maar fundamentele verschuivingen in de mogelijkheden.
Academische experimenten lieten vergelijkbare patronen zien. Eén onderzoek behaalde een 5,7 keer snellere doorvoer in vergelijking met implementaties zonder framework, terwijl het CPU-gebruik gelijk bleef aan dat van 99%. De juiste architectuur en toolkeuze zijn van enorm belang.
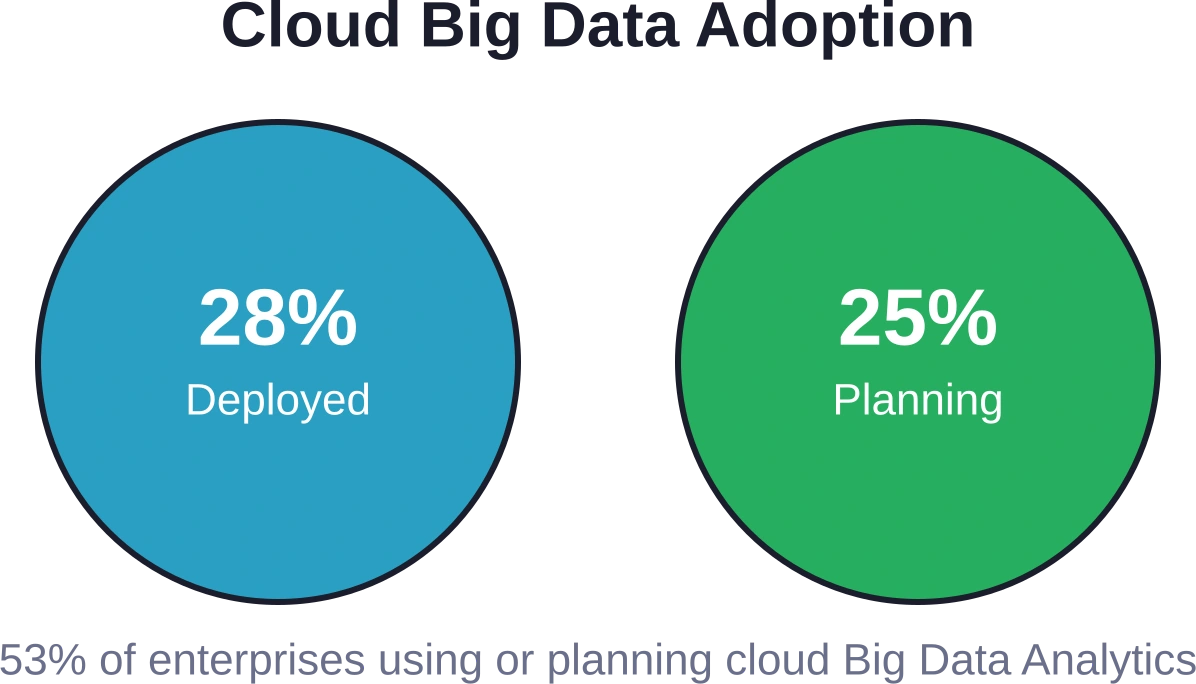
Cloudimplementatie versus implementatie op locatie.
Waar moet big data-infrastructuur gehuisvest worden? Het antwoord hangt af van de specifieke behoeften, maar de trend is duidelijk: de adoptie van de cloud blijft versnellen.
Cloudplatforms bieden flexibele schaalbaarheid, beheerde services en prijsstelling op basis van verbruik. Organisaties kunnen enorme rekenkracht inzetten voor piekbelastingen en deze terugschalen tijdens rustigere perioden. Beheerde services nemen de complexiteit van de infrastructuur, patches en upgrades voor hun rekening.
Maar on-premises implementaties behouden voordelen voor specifieke scenario's. Applicaties die gevoelig zijn voor latency, sterk gereguleerde data en bestaande investeringen in infrastructuur kunnen de voorkeur geven aan on-premises of hybride architecturen.
Hybride benaderingen combineren het beste van twee werelden. Organisaties bewaren gevoelige gegevens lokaal, terwijl ze cloudbronnen benutten voor extra capaciteit en analyses. Gegevensreplicatie, veilige verbindingen en uniforme beheertools maken een naadloze hybride werking mogelijk.
Veelgestelde vragen
Wat is de grootste uitdaging in big data?
De explosieve groei van het datavolume is de meest fundamentele uitdaging. Organisaties genereren en verzamelen data sneller dan traditionele infrastructuren deze kunnen opslaan, verwerken of analyseren. Deze uitdaging leidt tot hogere opslagkosten, een afname van de queryprestaties en knelpunten in de infrastructuur. Het oplossen van volumeproblemen vereist vaak cloudarchitecturen, gedistribueerde verwerkingsframeworks en compressiestrategieën.
Hoe los je problemen met de datakwaliteit in big data op?
Geautomatiseerde validatieregels sporen fouten op tijdens de data-invoer, voordat slechte data downstream-systemen vervuilt. Data-profileringstools analyseren datasets om afwijkingen en kwaliteitsproblemen te identificeren. Master data management creëert één betrouwbare bron voor kritieke entiteiten. Datakwaliteitsmonitoring volgt statistieken over tijd en waarschuwt teams wanneer de kwaliteit verslechtert. Door deze benaderingen te combineren, worden kwaliteitsproblemen voorkomen in plaats van ze reactief op te lossen.
Waarom is de beveiliging van big data zo moeilijk?
De beveiligingsuitdagingen van big data komen voort uit de schaal, de verspreiding en de complexiteit. Data verplaatst zich tussen on-premises systemen, cloudplatforms en partnernetwerken, waardoor talloze potentiële kwetsbaarheden ontstaan. Het enorme volume maakt uitgebreide monitoring moeilijk. Meerdere toegangspunten en legitieme gebruikers compliceren de toegangscontrole. Datalekken in de gezondheidszorg kosten gemiddeld 10,93 miljoen dollar, terwijl GDPR-boetes kunnen oplopen tot 41,3 biljoen dollar aan jaarlijkse inkomsten, waardoor beveiligingsfouten extreem kostbaar zijn.
Welke vaardigheden zijn nodig voor functies in de big data-sector?
Professionals in big data hebben technische vaardigheden nodig op het gebied van gedistribueerde systemen, programmeertalen zoals Python en SQL, en frameworks zoals Apache Spark. Data-engineers richten zich op het bouwen van pipelines en infrastructuur. Data scientists hebben kennis van statistiek, machine learning en domeinexpertise nodig. Beide rollen profiteren van inzicht in cloudplatformen, datamodellering en systeemontwerp. Continu leren is essentieel, aangezien technologieën zich snel ontwikkelen.
Wat zijn de kosten van een big data-infrastructuur?
De kosten variëren enorm, afhankelijk van de schaal en architectuur. Bedrijven gaven in 2024 1 TP4 T595,7 miljard uit aan computer- en opslaginfrastructuur (volgens Datamation). Cloudplatforms bieden prijsmodellen op basis van verbruik die meeschalen met het gebruik. Datacompressie vermindert de opslagbehoefte met 50 tot 801 TP3 T, wat direct leidt tot kostenbesparingen. Managed services verlagen de operationele overhead, maar rekenen daarvoor wel hogere prijzen. On-premises infrastructuur vereist een initiële kapitaalinvestering, maar resulteert in lagere kosten per eenheid bij schaalvergroting.
Is de cloud of een on-premises oplossing beter voor big data?
Cloudplatforms domineren nieuwe implementaties. De cloud biedt elastische schaalbaarheid, beheerde services en prijsstelling op basis van verbruik. On-premises implementaties zijn zinvol voor latency-gevoelige applicaties, sterk gereguleerde data en organisaties met bestaande infrastructuurinvesteringen. Hybride benaderingen combineren beide, waarbij gevoelige data on-premises wordt bewaard en cloudresources worden benut voor piekbelasting.
Wat is databeheer en waarom is het belangrijk?
Databeheer stelt beleid, processen en verantwoordelijkheden vast voor datamanagement. Het definieert data-eigendom, kwaliteitsnormen, toegangscontroles en complianceprocedures. Zonder governance worden organisaties geconfronteerd met tegenstrijdige rapporten, ongecontroleerde verspreiding van gevoelige data en lacunes in de naleving van wet- en regelgeving. Governance maakt data betrouwbaar en bruikbaar door middel van datacatalogi, beheerprogramma's, automatisering van beleid, traceerbaarheid van dataherkomst en compliancekaders.
Conclusie
De uitdagingen van big data zijn reëel, maar de oplossingen ook. Het datavolume blijft exponentieel groeien – de 2,5 petabytes per uur van Walmart zijn daar een treffend voorbeeld van. Maar cloudinfrastructuur, compressiestrategieën en frameworks voor gedistribueerde verwerking bieden bewezen manieren om die groei te beheersen.
Datakwaliteit, complexiteit van integratie, knelpunten in schaalbaarheid, beveiligingsrisico's, tekorten aan gekwalificeerd personeel en lacunes in governance vormen allemaal obstakels. Organisaties die deze uitdagingen systematisch aanpakken, behalen echter opmerkelijke resultaten: een 500x verbetering van de schaalbaarheid, een 50% efficiëntiewinst in de ontwikkeling en een 10x hogere doorvoer.
De sleutel ligt in de overgang van reactieve probleemoplossing naar proactieve architectuur. Geautomatiseerde kwaliteitsvalidatie is beter dan handmatige correctie. Uniforme dataplatformen elimineren een wirwar aan integraties. Versleuteling en toegangscontrole voorkomen datalekken in plaats van er achteraf op te reageren. Trainingsprogramma's bouwen interne expertise op in plaats van eindeloos nieuwe medewerkers te werven.
Dat potentieel bestaat in alle sectoren. De vraag is niet of big data waarde oplevert, maar of organisaties de uitdagingen aangaan die nodig zijn om die waarde te benutten.
Begin met één uitdaging. Kies het grootste pijnpunt in de huidige omgeving. Implementeer één oplossing. Meet de resultaten. Bouw momentum op. De transformatie naar big data gebeurt niet van de ene dag op de andere, maar systematische vooruitgang stapelt zich op in de loop van de tijd.
Klaar om uw grootste big data-uitdaging aan te pakken? Analyseer de huidige situatie, prioriteer oplossingen en begin vandaag nog met de implementatie.