Korte samenvatting: Voorspellende analyses maken gebruik van historische gegevens, machine learning en statistische algoritmen om toekomstige uitkomsten te voorspellen. Dit biedt grote voordelen, zoals betere besluitvorming, kostenbesparing en risicobeperking. Er zijn echter ook uitdagingen, waaronder eisen aan de datakwaliteit, implementatiekosten, risico's op vertekening en de behoefte aan specialistische expertise.
Elke dag genereren mensen zo'n 2,5 triljoen bytes aan data. Dat is een onvoorstelbare hoeveelheid informatie die door bedrijven, ziekenhuizen, financiële systemen en online platforms stroomt. Maar het probleem is dat het grootste deel van die data ongebruikt blijft liggen.
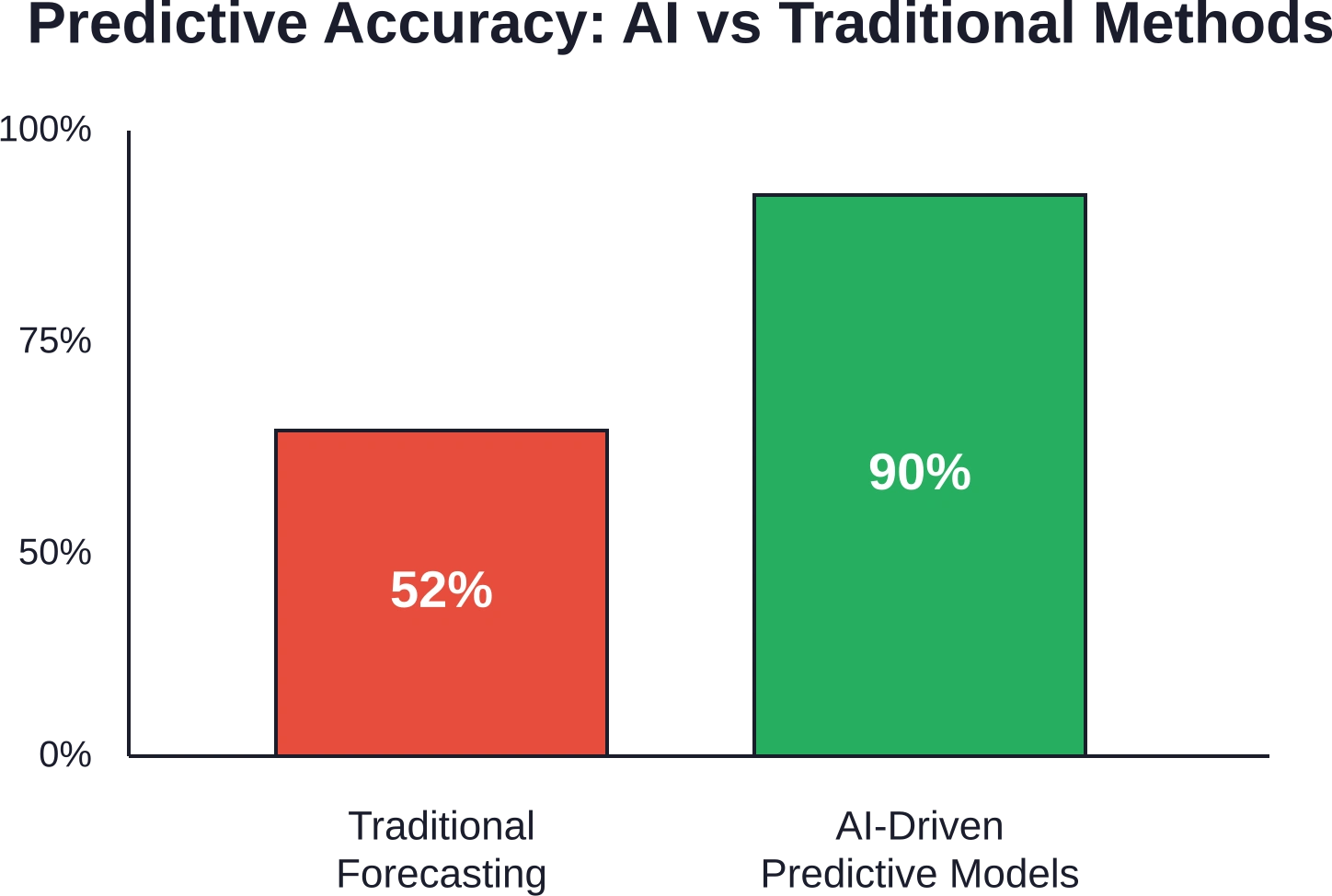
Voorspellende analyses veranderen die vergelijking. Door statistische methoden en machine learning-technieken toe te passen op historische gegevens, kunnen organisaties toekomstige gebeurtenissen, gedragingen en trends met opmerkelijke nauwkeurigheid voorspellen. Volgens een academische studie uit 2026 over AI en de voorspelling van consumentengedrag behaalde AI-gestuurde voorspellingen in de financiële sector een hogere nauwkeurigheid dan traditionele methoden.
Die prestatiekloof verklaart waarom de adoptie zo explosief is gestegen. Alleen al in de financiële handelssector is de implementatie van AI gestegen van 301 TP3T in 2018 naar 761 TP3T in 2024 – meer dan een verdubbeling in slechts zes jaar.
Maar maakt voorspellende analyse de belofte wel waar? En welke compromissen zijn er verbonden aan de implementatie van deze systemen?
Deze gids analyseert de werkelijke voor- en nadelen van voorspellende analyses, gebaseerd op gezaghebbend onderzoek, branchegegevens en praktische toepassingen in diverse sectoren.
Wat is voorspellende analyse?
Voorspellende analyses vormen een geavanceerde tak van data-analyse die actuele en historische gegevens onderzoekt om gefundeerde voorspellingen te doen over toekomstige uitkomsten. De discipline combineert verschillende technieken: statistische modellering, machine learning-algoritmen, data mining en patroonherkenning.
In tegenstelling tot beschrijvende analyses – die vertellen wat er is gebeurd – of diagnostische analyses – die verklaren waarom het is gebeurd – richten voorspellende analyses zich op wat er waarschijnlijk vervolgens gaat gebeuren.
Het proces volgt doorgaans dit patroon:
- Verzamel en prepareer historische gegevens uit relevante bronnen.
- Identificeer patronen, correlaties en trends binnen die gegevens.
- Bouw statistische modellen of machine learning-modellen die getraind zijn op die patronen.
- Pas de modellen toe op de huidige gegevens om voorspellingen te genereren.
- Modellen continu verfijnen naarmate er nieuwe gegevens beschikbaar komen.
Organisaties in alle sectoren zetten tegenwoordig voorspellende modellen in voor allerlei zaken, van vraagvoorspelling en klantverloopvoorspelling tot fraudedetectie en het plannen van onderhoud aan apparatuur.
Belangrijkste voordelen van voorspellende analyses
De voordelen die organisaties ertoe aanzetten om voorspellende analyses te gebruiken, zijn talrijk. Laten we de belangrijkste voordelen eens nader bekijken.
Verbeterde besluitvormingscapaciteiten
Een van de belangrijkste voordelen van voorspellende analyses is het vermogen om de besluitvorming op alle organisatieniveaus te verfijnen. In plaats van te vertrouwen op intuïtie of beperkte steekproeven, kunnen bedrijven strategische keuzes baseren op een uitgebreide data-analyse.
Voorspellende modellen laten zien welke acties de grootste kans hebben om de gewenste resultaten te behalen. Marketingteams kunnen bepalen welke klantsegmenten het beste zullen reageren op specifieke campagnes. Supply chain managers kunnen vraagfluctuaties weken of maanden van tevoren voorspellen. Zorgverleners kunnen patiënten met een verhoogd risico op bepaalde aandoeningen signaleren voordat de symptomen zich manifesteren.
Deze verschuiving van een reactieve naar een proactieve strategie vormt een fundamenteel concurrentievoordeel.
Kostenreductie en optimalisatie van middelen
Voorspellende analyses hebben een directe impact op de winstgevendheid doordat organisaties hun middelen efficiënter kunnen inzetten. Wanneer bedrijven de vraag nauwkeurig voorspellen, voorkomen ze zowel overproductie als voorraadtekorten.
Onderhoud is een duidelijk voorbeeld. Traditioneel gepland onderhoud vervangt onderdelen met vaste tussenpozen, ongeacht of ze aan vervanging toe zijn of niet. Voorspellend onderhoud bewaakt de conditie van apparatuur in realtime en voorspelt storingen voordat ze zich voordoen. Deze aanpak vermindert onnodig onderhoud en voorkomt kostbare ongeplande stilstand.
In de gezondheidszorg worden door middel van voorspellende analyses patiënten met een hoog risico geïdentificeerd die interventie nodig hebben, waardoor middelen worden geconcentreerd waar ze de grootste impact hebben in plaats van ze gelijkmatig te verspreiden.
Risicobeheer en fraudedetectie
Financiële instellingen zijn bijzonder bedreven geraakt in het gebruik van voorspellende modellen om kredietrisico's te beoordelen en frauduleuze transacties op te sporen. Machine learning-algoritmen kunnen duizenden variabelen tegelijk analyseren en verdachte patronen identificeren die voor mensen onopgemerkt zouden blijven.
Onderzoek naar machine learning-modellen voor kredietrisicobeoordeling heeft aangetoond dat problemen met de datakwaliteit een aanzienlijke invloed hebben op de voorspellende prestaties. Studies hebben ook prestatieverschillen tussen demografische groepen gedocumenteerd voor leners uit minderheidsgroepen en leners met een laag inkomen. Dit benadrukt zowel de kracht als de valkuilen van voorspellende systemen.
Verzekeringsmaatschappijen gebruiken eveneens voorspellende analyses om polissen nauwkeuriger te prijzen, risico's binnen hun portefeuilles in evenwicht te brengen en mogelijk frauduleuze claims te identificeren.
Personalisatie op grote schaal
Moderne aanbevelingssystemen tonen aan dat voorspellende analyses in staat zijn om ervaringen te personaliseren voor miljoenen gebruikers tegelijk. Analyse van verkeersbronnen laat zien dat AI-gestuurde aanbevelingssystemen nu ongeveer 351 TP3T aan verkeer genereren, vergeleken met 401 TP3T van directe zoekopdrachten en 101 TP3T van andere bronnen.
E-commerceplatforms voorspellen welke producten individuele klanten waarschijnlijk zullen kopen. Streamingdiensten voorspellen welke content abonnees geboeid zal houden. Zorgverleners kunnen behandelplannen afstemmen op basis van voorspellende modellen die zijn getraind op vergelijkbare patiëntuitkomsten.
Deze massale personalisatie was simpelweg onmogelijk voordat voorspellende analyses zich verder ontwikkelden.
Concurrentieanalyse en marktpositionering
Organisaties die voorspellende inzichten effectief benutten, verwerven vaak een positie die concurrenten moeilijk kunnen evenaren. Door opkomende trends vroegtijdig te signaleren, kunnen bedrijven producten aanpassen, prijzen bijstellen of nieuwe markten betreden vóór hun concurrenten.
Eerlijk gezegd: voorspellende analyses zijn in veel sectoren een absolute noodzaak geworden. Bedrijven die deze mogelijkheden niet omarmen, reageren steeds vaker op de acties van concurrenten in plaats van zelf de markt te beïnvloeden.

Overweeg de superioriteit van voorspellende analyses met AI voordat u opschaalt.
Voorspellende analyses kunnen nuttig zijn, maar vereisen wel de juiste gegevens, een duidelijk bedrijfsdoel en een realistisch inzicht in de beperkingen ervan. AI Superieur Ze bieden AI-consultancy, voorspellende analyses, machine learning, business intelligence, data-analyse en maatwerk AI-softwareontwikkeling. Hun werk kan bedrijven helpen beoordelen of voorspellende modellen geschikt zijn voor taken zoals forecasting, churn-analyse, vraagplanning, risicodetectie, operationele analyses of besluitvormingsondersteuning.
De ondersteuning van AI Superior op het gebied van voorspellende analyses kan het volgende omvatten:
- Beoordelen of voorspellende analyses geschikt zijn voor het beoogde gebruik.
- Het beoordelen van de gereedheid van de gegevens en de zakelijke vereisten.
- Het bouwen van machine learning- en voorspellingsmodellen
- Het ontwikkelen van BI- of analysetools op basis van modeluitkomsten.
- Het integreren van voorspellende inzichten in bedrijfsprocessen.
👉Neem contact op met AI Superior om te bespreken of voorspellende analyses geschikt zijn voor uw data, planningsproces of bedrijfsdoelen.
Belangrijke nadelen van voorspellende analyses
Nu wordt het interessant. Voorspellende analyses zijn geen tovermiddel, en verschillende aanzienlijke uitdagingen beperken de effectiviteit ervan.
Vereisten voor gegevenskwaliteit
Voorspellende modellen zijn slechts zo goed als de data waarop ze getraind zijn. Slechte datakwaliteit – ontbrekende waarden, ruis in attributen, uitschieters, onjuiste labels – vermindert de nauwkeurigheid van het model aanzienlijk.
Onderzoek naar machine learning-modellen voor kredietrisicobeoordeling heeft aangetoond dat problemen met de datakwaliteit de voorspellende prestaties aanzienlijk beïnvloeden. Opvallend is dat bepaalde soorten fouten, in tegenstelling tot wat je zou verwachten, specifieke meetwaarden kunnen verbeteren. Studies tonen verbeteringen aan, gemeten aan de hand van de F1-score, maar deze verbetering weerspiegelt eerder overfitting dan daadwerkelijke voorspellende kracht.
Onderzoek naar end-to-end frameworks voor datakwaliteit in machine learning-productieomgevingen heeft aangetoond dat er aanzienlijke datafiltering plaatsvindt bij het toepassen van kwaliteitsdrempels. Dit benadrukt de uitdaging om voldoende datavolume te behouden en tegelijkertijd kwaliteitsnormen te waarborgen.
Organisaties moeten fors investeren in het opschonen, valideren en beheren van data voordat voorspellende analyses rendabel worden.
Implementatie- en onderhoudskosten
Het opbouwen van effectieve voorspellende analyses vereist aanzienlijke investeringen. Bedrijven hebben gespecialiseerde softwareplatforms, computerinfrastructuur en – het allerbelangrijkste – bekwaam personeel nodig dat zowel de technische als de zakelijke aspecten begrijpt.
Datawetenschappers, machine learning-ingenieurs en analysespecialisten verdienen topsalarissen. De tools zelf brengen vaak aanzienlijke licentiekosten met zich mee. Cloudcomputing voor het trainen van complexe modellen zorgt voor terugkerende kosten.
Maar wacht even. De kosten stoppen niet na de initiële implementatie. Modellen verslechteren na verloop van tijd doordat onderliggende patronen veranderen. Continue monitoring, hertraining en verfijning worden doorlopende operationele vereisten.
Vooroordelen en zorgen over eerlijkheid
Machine learning-modellen die getraind zijn op historische data nemen onvermijdelijk de vooroordelen in die data over. Als eerdere kredietbeslissingen bepaalde bevolkingsgroepen discrimineerden, leren voorspellende modellen die discriminatie in stand te houden, tenzij ze expliciet worden gecorrigeerd.
Onderzoek van IEEE naar het verminderen van bias in machine learning benadrukt dit als een fundamentele uitdaging. Voorspellende modellen kunnen systematisch minderheidsgroepen, plattelandsbewoners of mensen met een laag inkomen tekortdoen – vaak op manieren die niet direct duidelijk zijn.
Kredietscores vormen een treffend voorbeeld, met aantoonbare prestatieverschillen tussen demografische groepen voor leners uit minderheidsgroepen en met een laag inkomen. Voorspellende modellen in de gezondheidszorg vertonen vergelijkbare vooroordelen, waarbij soms minder agressieve behandelingen worden aanbevolen voor patiënten uit minderheidsgroepen met identieke klinische profielen.
Het aanpakken van deze problemen vereist gespecialiseerde technieken, diverse trainingsgegevens en constante alertheid, wat de complexiteit en de kosten van initiatieven voor voorspellende analyses verhoogt.
Uitdagingen op het gebied van complexiteit en interpreteerbaarheid
Geavanceerde machine learning-modellen – met name diepe neurale netwerken – functioneren vaak als 'black boxes'. Ze genereren accurate voorspellingen, maar bieden weinig inzicht in de redenen achter die specifieke voorspellingen.
Deze ondoorzichtigheid zorgt voor problemen in gereguleerde sectoren waar organisaties hun beslissingen moeten toelichten. Een bank kan een leningaanvrager niet zomaar vertellen: "Het algoritme zei nee", zonder de redenering daarachter uit te leggen. Zorgverleners moeten begrijpen waarom een model een bepaalde behandeling aanbeveelt.
Onderzoek naar contrafeitelijke verklaringen voor de validatie van machine learning-modellen pakt deze uitdaging aan, maar interpreteerbaarheid blijft een belangrijke beperking. Eenvoudigere, transparantere modellen offeren vaak nauwkeurigheid op voor verklaarbaarheid.
Risico op overfitting en datalekken
Modellen kunnen zo nauwkeurig afgestemd raken op historische gegevens dat ze falen wanneer ze met nieuwe situaties worden geconfronteerd. Deze overfitting levert indrukwekkende resultaten op testdatasets op, maar slechte prestaties in een productieomgeving.
Datalekken vormen een ander cruciaal probleem. Onderzoek naar datakwaliteit benadrukt het belang van het minimaliseren van overlappingen tussen test-/validatie- en trainingsdatasets om kunstmatig opgeblazen prestatiecijfers te voorkomen. Overmatige overlapping leidt tot opgeblazen prestatiecijfers die de werkelijke mogelijkheden niet weerspiegelen.
Organisaties zonder sterke data science-praktijken zetten vaak modellen in die er op papier goed uitzien, maar in de praktijk falen.
Privacy- en beveiligingsaspecten
Voorspellende analyses vereisen het verzamelen, opslaan en analyseren van enorme hoeveelheden data, vaak inclusief gevoelige persoonlijke informatie. Dit brengt diverse risico's met zich mee.
Datalekken kunnen vertrouwelijke informatie over klanten, patiënten of bedrijfsactiviteiten blootleggen. Regelgeving zoals de AVG stelt strenge eisen aan de verwerking van gegevens en algoritmische besluitvorming. Bedrijven moeten een evenwicht vinden tussen voorspellende mogelijkheden en privacybescherming.
In sommige rechtsgebieden zijn organisaties nu verplicht om geautomatiseerde beslissingen toe te lichten en kunnen individuen deze aanvechten, wat de juridische en operationele complexiteit vergroot.
| Voordeel | Nadeel | Mitigatiestrategie |
|---|---|---|
| Verbeterde nauwkeurigheid van besluitvorming | Vereist gegevens van hoge kwaliteit. | Investeer in databeheer en -validatie. |
| Kosten- en resourceoptimalisatie | Hoge implementatiekosten | Begin met gerichte pilotprojecten. |
| Beter risicomanagement | Mogelijkheid tot vooringenomenheid en discriminatie | Pas technieken toe voor het opsporen en verminderen van vooringenomenheid. |
| Gepersonaliseerde ervaringen | Privacy- en beveiligingsrisico's | Implementeer sterke maatregelen voor gegevensbescherming. |
| Concurrentievoordeel | Vereist specialistische expertise. | Ontwikkel intern talent en werk samen met experts. |
| Proactief problemen oplossen | Interpretatieproblemen van de black box | Gebruik waar nodig verklaarbare AI-technieken. |
Praktische toepassingen en prestaties
Inzicht in hoe voorspellende analyses in de praktijk presteren, biedt cruciale context om de voordelen ervan af te wegen tegen de beperkingen.
Voorspellende analyses voor de gezondheidszorg
In de medische wereld komen zowel de mogelijkheden als de valkuilen van voorspellende systemen aan het licht. Ziekenhuizen gebruiken voorspellende modellen om patiënten met een hoog risico op heropname te identificeren, waardoor vroegtijdige interventie mogelijk is die de resultaten verbetert en de kosten verlaagt.
Modellen voor ziektevoorspelling helpen zorgsystemen bij het toewijzen van middelen tijdens het griepseizoen of andere voorspelbare gezondheidsgebeurtenissen. Behandelingsaanbevelingen gebaseerd op vergelijkbare patiëntuitkomsten kunnen klinische beslissingen sturen.
Voorspellende analyses in de gezondheidszorg staan echter voor aanzienlijke uitdagingen op het gebied van datakwaliteit, interoperabiliteit tussen systemen en problemen met vooringenomenheid. Medische data zijn notoir onoverzichtelijk, inconsistent tussen instellingen en weerspiegelen vaak historische verschillen in de kwaliteit van de zorg.
Financiële dienstverlening en kredietbeoordeling
Banken en financiële instellingen vertrouwen sterk op voorspellende modellen voor kredietbeoordeling, fraudedetectie en risico-inschatting. Deze applicaties verwerken dagelijks miljoenen transacties, waardoor handmatige controle onpraktisch is.
Onderzoek toont aan dat problemen met de datakwaliteit met name van invloed zijn op kredietrisicomodellen. Ontbrekende waarden, ruis in de data en fouten in labels verminderen allemaal de prestaties. Nog zorgwekkender is dat modellen een verschil in nauwkeurigheid vertonen tussen verschillende demografische groepen – precies het soort vertekening dat toezichthouders en belangenorganisaties onder de loep nemen.
De financiële sector blijft investeren in technieken om vooroordelen te verminderen en in verklaarbare AI om deze uitdagingen aan te pakken en tegelijkertijd de efficiëntievoordelen van voorspellende analyses te behouden.
Optimalisatie van detailhandel en e-commerce
Online retailers gebruiken voorspellende analyses voor vraagvoorspelling, voorraadbeheer, dynamische prijsstelling en aanbevelingssystemen. De concurrentiedruk is hevig: bedrijven die de voorkeuren van klanten nauwkeurig voorspellen, realiseren meer omzet.
Aanbevelingssystemen genereren tegenwoordig aanzienlijk veel verkeer en zijn verantwoordelijk voor ongeveer 351.000.300 bezoeken aan e-commerceplatforms. Deze systemen analyseren browsegeschiedenis, aankoopgedrag en gedragssignalen om te voorspellen welke producten individuele klanten willen zien.
De uitdaging zit hem in de rekenkosten en de noodzaak van realtime verwerking. Modellen moeten continu worden bijgewerkt naarmate er nieuwe gegevens binnenkomen, wat een geavanceerde infrastructuur vereist.
Kritische succesfactoren voor de implementatie
Organisaties die succesvol voorspellende analyses inzetten, hebben een aantal gemeenschappelijke kenmerken. Inzicht in deze factoren helpt bij het formuleren van realistische verwachtingen.
Data-infrastructuur en -governance
Een solide datafundament is essentieel. Dit omvat systemen voor dataverzameling, -opslag, -opschoning en -validatie. Organisaties hebben duidelijke beleidsregels voor databeheer nodig, waarin eigendom, toegangscontrole en kwaliteitsnormen zijn vastgelegd.
Onderzoek naar end-to-end frameworks voor datakwaliteit in machine learning legt de nadruk op het direct integreren van kwaliteitsbeoordeling in productiepipelines. Realtime monitoring detecteert kwaliteitsverslechtering van de data voordat dit de modelprestaties beïnvloedt.
Crossfunctionele samenwerking
Projecten voor voorspellende analyses mislukken wanneer datawetenschappers geïsoleerd van de zakelijke belanghebbenden werken. Succesvolle implementaties vereisen nauwe samenwerking tussen technische teams en domeinexperts die de zakelijke context begrijpen.
De zakelijke kant moet duidelijk de problemen formuleren die de moeite waard zijn om op te lossen, evenals de meetbare succesfactoren. De technische kant moet die eisen vertalen naar geschikte modelleringsmethoden en de beperkingen eerlijk communiceren.
Regelgevings- en ethische kaders
Overheidsbeleid geeft steeds meer vorm aan de inzet van voorspellende analyses. Het presidentieel decreet van het Witte Huis over beleidskaders voor AI benadrukt het leiderschap van de Verenigde Staten op het gebied van kunstmatige intelligentie en stelt tegelijkertijd eisen aan de governance.
Organisaties moeten op de hoogte blijven van de steeds veranderende regelgeving rondom algoritmische besluitvorming, gegevensbescherming en eerlijkheid. Het integreren van ethische toetsingsprocessen in de ontwikkelingscyclus voorkomt kostbare problemen achteraf.
Continue monitoring en verbetering
Het implementeren van een model is slechts het begin. Productiesystemen vereisen continue monitoring om prestatievermindering, data-afwijkingen of opkomende vertekeningen te detecteren.
Onderzoek naar governancekaders voor de validatie en monitoring van machine learning benadrukt het belang van systematische benaderingen voor het beheer van de levenscyclus van modellen. Modellen die niet actief worden onderhouden, worden een last in plaats van een aanwinst.
Wanneer voorspellende analyses zinvol zijn
Niet elke organisatie heeft voorspellende analyses nodig, en niet elk bedrijfsprobleem rechtvaardigt de investering. Discussies onder datawetenschappers suggereren dat voorspellende analyses het beste werken wanneer:
- Er zijn voldoende historische gegevens beschikbaar om betrouwbare modellen te trainen.
- Het bedrijfsprobleem heeft duidelijke, meetbare resultaten.
- Voorspellingen bieden bruikbare inzichten die beslissingen onderbouwen.
- De verwachte waarde van verbeterde besluitvorming overstijgt de implementatiekosten.
- De organisatie beschikt over de benodigde technische capaciteiten of kan deze ontwikkelen.
Kleine bedrijven met beperkte data en middelen kunnen wellicht voldoende hebben aan traditionele analyses. De vraag is niet of voorspellende analyses in absolute zin goed of slecht zijn, maar of de voordelen opwegen tegen de nadelen voor een specifieke toepassing.
Veelgestelde vragen
Wat zijn de belangrijkste voordelen van voorspellende analyses?
De belangrijkste voordelen zijn onder meer betere besluitvorming dankzij datagestuurde inzichten, kostenbesparing door geoptimaliseerde toewijzing van middelen, verbeterd risicomanagement en fraudedetectie, gepersonaliseerde klantervaringen op grote schaal en concurrentievoordelen door vroegtijdige trendherkenning. Onderzoek toont aan dat AI-gestuurde voorspellingsmodellen een hogere nauwkeurigheid behalen dan traditionele voorspellingsmethoden.
Wat zijn de grootste uitdagingen bij voorspellende analyses?
Belangrijke uitdagingen zijn onder meer strenge eisen aan de datakwaliteit, hoge implementatie- en onderhoudskosten, mogelijke algoritmische vooringenomenheid die discriminatie in stand kan houden, complexiteit en interpreteerbaarheidsproblemen bij geavanceerde modellen, risico's op overfitting en datalekken, en privacy- en beveiligingsproblemen rond gevoelige gegevens. Organisaties moeten deze systematisch aanpakken voor een succesvolle implementatie.
Hoe nauwkeurig zijn voorspellende analysemodellen?
De nauwkeurigheid varieert aanzienlijk, afhankelijk van het probleemgebied, de datakwaliteit en de modelleringsaanpak. Wetenschappelijk onderzoek toont aan dat AI-gestuurde voorspellingen een hoge nauwkeurigheid bereiken bij goed gestructureerde problemen. Kredietrisicomodellen presteren echter minder goed voor bepaalde demografische groepen, wat aantoont dat de nauwkeurigheid niet uniform is voor alle bevolkingsgroepen. De prestaties in de praktijk zijn sterk afhankelijk van de kwaliteit van de implementatie.
Welke sectoren profiteren het meest van voorspellende analyses?
De financiële sector maakt veelvuldig gebruik van voorspellende analyses voor kredietbeoordeling en fraudedetectie. De gezondheidszorg past het toe voor risicostratificatie van patiënten en ziektevoorspelling. De detailhandel en e-commerce gebruiken voorspellende modellen voor vraagvoorspelling en aanbevelingssystemen. De maakindustrie gebruikt voorspellend onderhoud om stilstand te verminderen. Ook de verzekerings-, telecommunicatie- en logistieke sector profiteren er aanzienlijk van. De toepassing ervan in de financiële sector is gestegen van 301 TP3T in 2018 naar 761 TP3T in 2024.
Welke invloed heeft de datakwaliteit op voorspellende analyses?
De kwaliteit van de data bepaalt direct de betrouwbaarheid van een model. Studies naar machine learning voor kredietrisico hebben aangetoond dat ontbrekende waarden, ruis in attributen, uitschieters en labelfouten de voorspellende nauwkeurigheid aanzienlijk verminderen. Onderzoek naar raamwerken voor datakwaliteit documenteerde aanzienlijke datafiltering bij het toepassen van kwaliteitsdrempels. Organisaties moeten investeren in databeheer, validatie en opschoning voordat voorspellende analyses haalbaar worden.
Kunnen voorspellende analyses bevooroordeeld zijn?
Ja, voorspellende modellen die getraind zijn op historische data absorberen de vooroordelen die in die data besloten liggen. Onderzoek van de IEEE naar het verminderen van vooroordelen benadrukt dit als een fundamentele uitdaging in machine learning. Kredietscoremodellen laten prestatieverschillen zien voor leners uit minderheidsgroepen en met een laag inkomen. Modellen in de gezondheidszorg hebben vergelijkbare verschillen aangetoond. Organisaties moeten gespecialiseerde technieken voor het detecteren en verminderen van vooroordelen toepassen gedurende de gehele levenscyclus van het model.
Wat is het verschil tussen voorspellende en prescriptieve analyses?
Voorspellende analyses voorspellen wat er waarschijnlijk gaat gebeuren op basis van historische patronen en huidige omstandigheden. Prescriptieve analyses gaan verder en bevelen specifieke acties aan om de gewenste resultaten te bereiken. Voorspellende modellen kunnen bijvoorbeeld het risico op klantverlies voorspellen, terwijl prescriptieve systemen suggesties doen voor retentiestrategieën voor elk klantsegment. Prescriptieve analyses bouwen voort op voorspellende mogelijkheden door optimalisatie- en beslissingslogica toe te voegen.
Conclusie over de afwegingen bij voorspellende analyses
Voorspellende analyses vormen een krachtige technologie die de manier waarop organisaties opereren fundamenteel verandert. De voordelen – betere besluitvorming, kostenbesparingen, risicovermindering, personalisatie en een sterkere concurrentiepositie – verklaren waarom de toepassing ervan de afgelopen tien jaar zo sterk is toegenomen.
Maar de nadelen zijn eveneens reëel. Eisen aan de datakwaliteit, implementatiekosten, risico's op vertekening, uitdagingen op het gebied van interpreteerbaarheid en privacykwesties vormen aanzienlijke obstakels. Organisaties die deze uitdagingen onderschatten, behalen vaak teleurstellende resultaten.
Uit onderzoek blijkt dat voorspellende analyses het beste werken wanneer organisaties ze strategisch benaderen in plaats van als een universele oplossing. Succes vereist een sterke datafundament, samenwerking tussen verschillende afdelingen, passende governancekaders en continue investeringen in onderhoud en verbetering.
Klinkt dit bekend? Dat komt omdat voorspellende analyses het patroon volgen van de meeste baanbrekende technologieën. De mogelijkheden zijn reëel, maar om ze te benutten is meer nodig dan alleen de technologie adopteren – het vereist een organisatorische inzet om het lastige werk van de implementatie correct uit te voeren.
Voor organisaties die bereid zijn die investering te doen, levert voorspellende analyses meetbare waarde op. Wie echter hoopt op snelle resultaten zonder aandacht te besteden aan fundamentele zaken zoals datakwaliteit en het tegengaan van vertekeningen, zal waarschijnlijk teleurgesteld zijn.
De vraag is niet of voorspellende analyses op zich de moeite waard zijn. Het gaat erom of uw organisatie beschikt over de data, middelen, expertise en toewijding om ze effectief in te zetten en tegelijkertijd de beperkingen ervan op een verantwoorde manier te beheren.