Quick Summary: Predictive analytics uses historical data, statistical modeling, and machine learning to forecast future outcomes across industries. From manufacturing equipment maintenance to banking churn prediction, predictive models help organizations reduce risks, optimize operations, and make data-driven decisions. Implementation involves data collection, model training, validation, and deployment—transforming reactive industries into proactive, autonomous systems.
Manufacturing lines don’t break on schedule. Customers don’t announce they’re leaving. Supply chains don’t send early warnings before they collapse.
But patterns exist in the data—hidden signals that something’s about to go wrong. Predictive analytics finds those signals before problems happen.
Predictive analytics is a branch of advanced analytics that makes predictions about future outcomes by using historical data combined with statistical modeling, data mining techniques, and machine learning. Companies employ predictive analytics tools to find patterns in data that help identify risks and opportunities.
The shift from reactive to proactive decision-making represents a fundamental transformation. Instead of fixing equipment after it fails, organizations predict failures weeks in advance. Instead of reacting to customer departures, banks identify at-risk accounts before churn occurs.
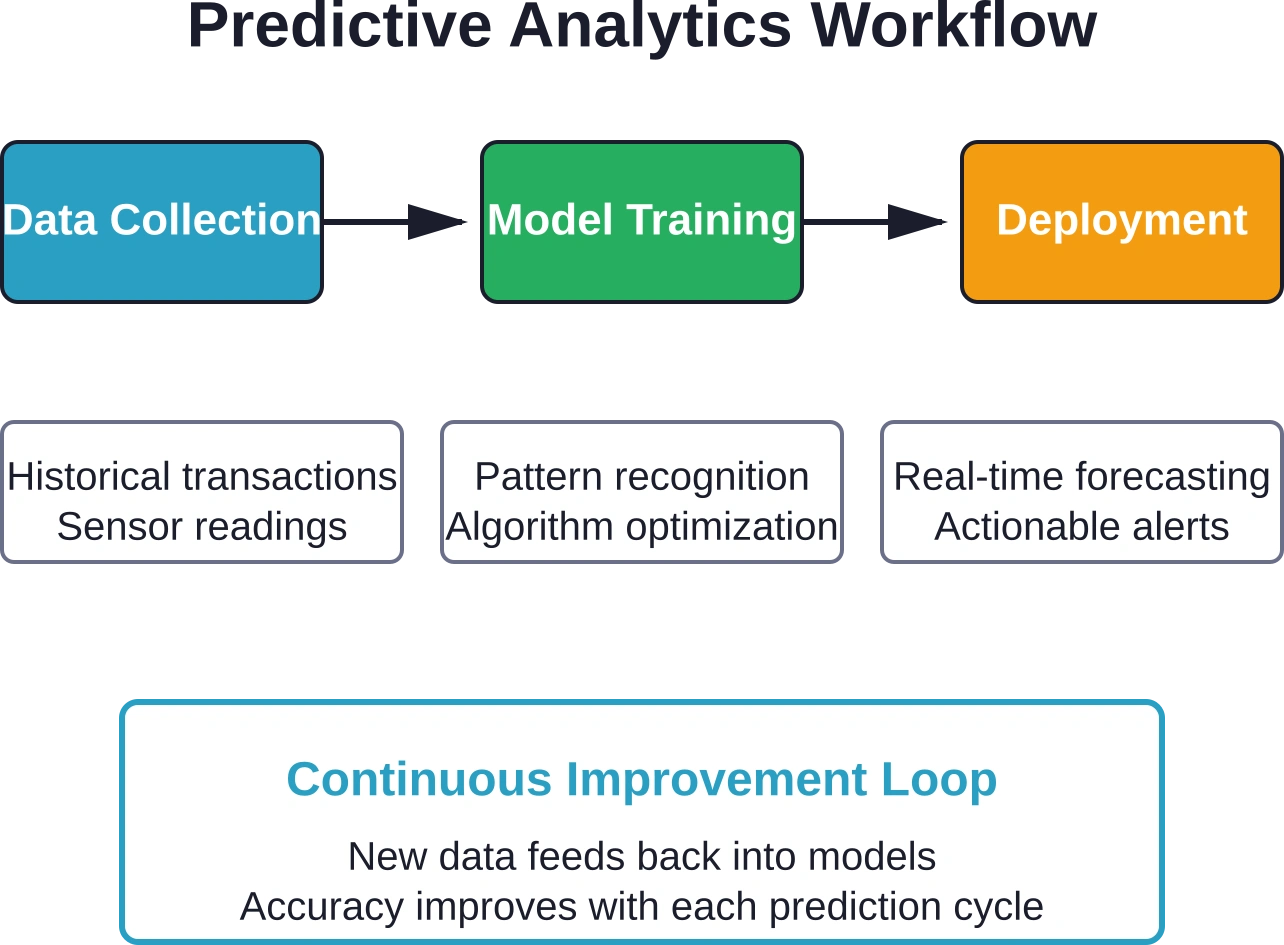
How Predictive Analytics Actually Works
The process starts with historical data. Lots of it.
Organizations collect transaction records, sensor readings, customer interactions, production metrics—any data that captures what happened in the past. This historical foundation feeds statistical models that learn to recognize patterns.
Machine learning algorithms analyze these patterns. They identify which variables correlate with specific outcomes. Temperature spikes before equipment failures. Transaction patterns before account closures. Inventory levels before supply disruptions.
The models don’t just spot correlations. They quantify probability. A specific machine configuration carries a 78% failure risk within two weeks. An account showing three behavioral flags has an 82% churn probability within 90 days.
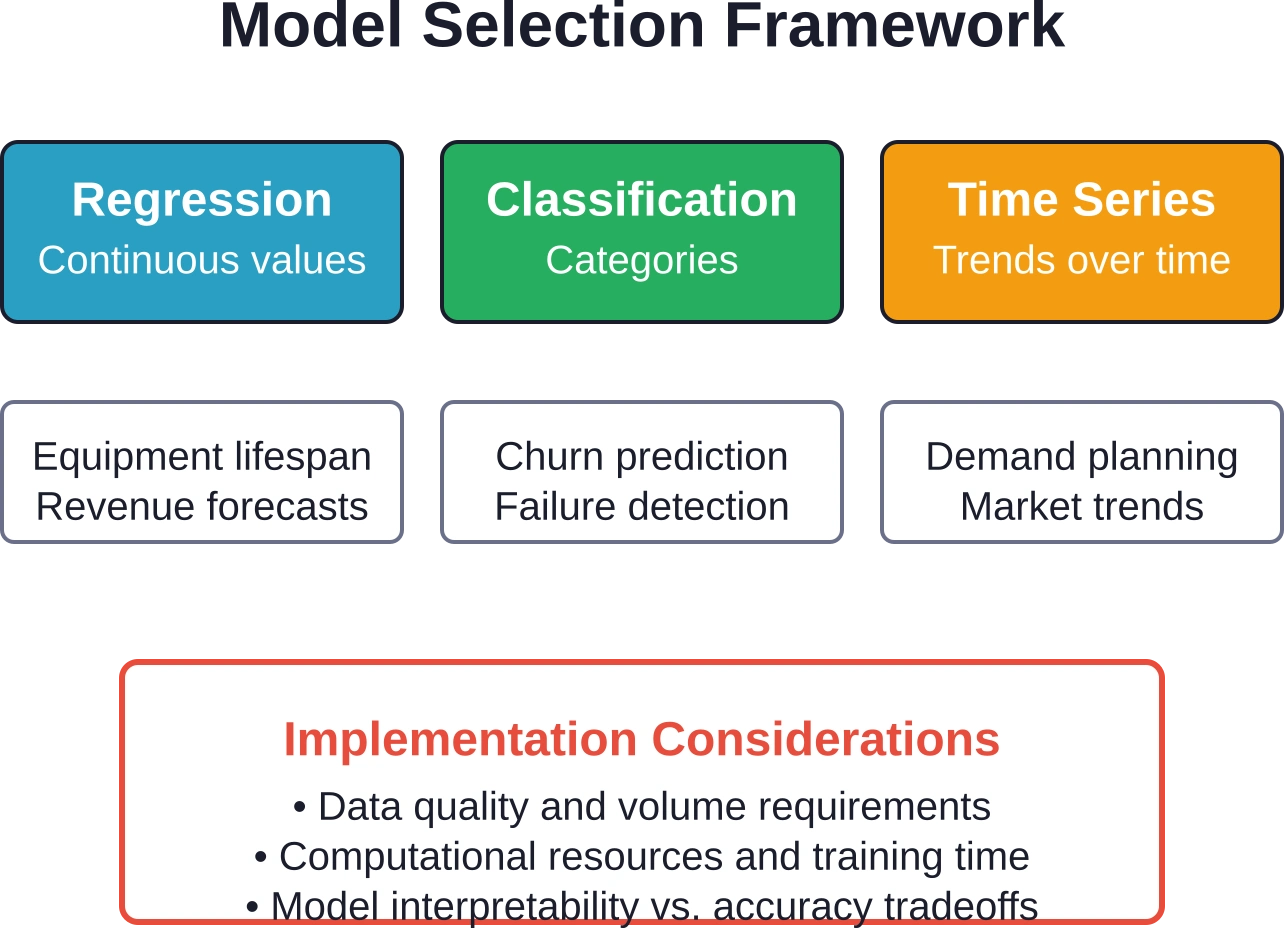
Statistical modeling techniques vary by use case. Regression models predict continuous values like equipment lifespan or revenue. Classification models predict categorical outcomes like pass/fail or stay/leave. Time series models forecast trends over specific periods.
Data mining techniques extract these patterns from massive datasets. Neural networks with multiple hidden layers identify non-linear relationships humans would miss. Decision trees map out branching logic paths that lead to different outcomes.
Industrial Predictive Maintenance Applications
Manufacturing facilities generate enormous volumes of sensor data. Temperature readings, vibration measurements, pressure levels, electrical current—all logged continuously from production equipment.
Predictive maintenance models analyze this sensor stream to forecast equipment failures before they happen. The IEEE technical literature documents implementations that improve availability of manufacturing equipment in automotive firms by predicting maintenance needs.
Industrial IoT applications now integrate predictive analytics for proactive maintenance. Sensors embedded in motors, pumps, conveyors, and assembly robots transmit real-time operational data. Machine learning algorithms process this data to identify degradation patterns.
| Maintenance Approach | Strategy | Downtime Impact | Cost Efficiency |
|---|---|---|---|
| Reactive | Fix after failure | High—unplanned outages | Low—emergency repairs expensive |
| Preventive | Scheduled maintenance | Medium—planned downtime | Medium—some unnecessary work |
| Predictive | Forecast-driven intervention | Low—targeted maintenance | High—optimal timing |
The manufacturing industry faces complex challenges with raw material shortages and supply chain disruptions. Predictive models help reduce operational risks by forecasting these disruptions before they impact production.
Automotive manufacturers use predictive analytics to optimize production schedules around anticipated equipment maintenance windows. Instead of shutting down entire lines for routine checks, maintenance occurs precisely when sensors indicate actual need.
Banking and Financial Services Use Cases
Customer retention drives profitability in financial services. Retaining existing customers costs less than acquiring new ones.
Neural networks significantly enhance predictive accuracy for customer churn in banking. Research using a dataset of 10,000 records with 14 features demonstrates how machine learning forecasts which customers will close accounts.

Logistic regression achieved 89.6% accuracy with a recall rate of 96.8% and an AUC score of 0.91 for discriminative power. Naive Bayes reached 86.7% accuracy with 92.0% precision and 92.2% recall, plus an AUC score of 0.83.
These models don’t just identify at-risk customers. They rank them by probability and suggest intervention strategies. High-value accounts showing early warning signs trigger personalized retention offers before customers make leaving decisions.
Banks use multilayer perceptron architectures with varying neuron configurations optimized for their specific churn prediction tasks. These neural networks process transaction patterns, account balance trends, customer service interactions, and demographic factors.
Financial institutions apply predictive analytics to fraud detection, credit risk assessment, and investment portfolio optimization. Each application follows the same core principle—historical patterns predict future behavior.
Supply Chain and Logistics Forecasting
Supply chains operate across multiple variables. Demand fluctuations, transportation delays, inventory levels, supplier reliability, seasonal patterns—all interconnected.
Predictive analytics models process this complexity to forecast demand, optimize inventory, and prevent disruptions. Data and predictive analytics use for logistics helps organizations move from reactive scrambling to planned responses.
Demand forecasting models analyze historical sales data alongside external factors like weather, economic indicators, and market trends. Retailers predict product demand weeks in advance, adjusting inventory before shortages or overstock situations develop.
Transportation and route optimization use predictive models to forecast delivery times accounting for traffic patterns, weather conditions, and historical delay data. Logistics companies reduce fuel costs and improve delivery accuracy.
But supply chain predictive analytics goes deeper. Models identify supplier risk by analyzing delivery consistency, quality metrics, and external factors like geopolitical instability or natural disaster probability in supplier regions.
Model Architecture and Technical Implementation
Building effective predictive models requires careful architecture decisions.
Neural networks offer powerful pattern recognition but need substantial training data and computational resources. Simpler models like logistic regression work well for binary classification problems with clear feature relationships.
The choice depends on data characteristics and prediction complexity. Linear models handle straightforward relationships. Non-linear models capture complex interactions but risk overfitting if training data is limited.
Data preprocessing consumes significant implementation time. Raw data contains inconsistencies, missing values, and outliers. Cleaning and normalizing data before model training dramatically impacts prediction accuracy.
Feature engineering transforms raw variables into meaningful predictors. Transaction frequency becomes a more useful feature than raw transaction timestamps. Temperature change rate often predicts failures better than absolute temperature.
Model validation prevents overfitting. Training data teaches patterns. Validation data tests whether those patterns generalize to new cases. Test data provides final performance metrics on completely unseen examples.
Cross-validation techniques partition data multiple ways to ensure models perform consistently across different subsets. K-fold validation splits data into segments, training on most segments while testing on the remainder, then rotating which segment serves as the test set.

Apply Predictive Analytics to Industry Workflows
Predictive analytics can support industrial companies when it is connected to planning, operations, equipment, production, quality, or resource management. AI Superior works with AI consulting, machine learning, predictive analytics, business intelligence, computer vision, and custom AI software development. Their team can help define the right prediction tasks, prepare business or operational data, build models, and connect results with existing systems. This is useful for companies that want to use data to notice risks earlier, plan with more confidence, or reduce avoidable inefficiencies.
Turn to AI Superior for:
- Defining predictive analytics use cases
- Building forecasting and anomaly detection models
- Supporting predictive maintenance and quality analysis
- Creating BI tools around operational data
- Integrating predictive insights into business workflows
Reach out to AI Superior to explore predictive analytics use cases for your industrial data, operations, or planning processes.
Deployment and Continuous Improvement
Trained models need integration into operational systems.
Deployment architecture determines how predictions reach decision-makers. Batch processing generates forecasts on schedule—nightly demand predictions or weekly maintenance risk reports. Real-time processing scores transactions as they occur—fraud detection or immediate quality control alerts.
API endpoints allow multiple systems to request predictions. A CRM system queries the churn model when customer service interacts with an account. An inventory system requests demand forecasts when planning restocks.
Monitoring deployed models prevents accuracy degradation. Business conditions change. Patterns that held true last year might not apply next quarter. Model performance metrics track prediction accuracy on ongoing outcomes.
Retraining schedules refresh models with recent data. Some organizations retrain monthly. Others trigger retraining when accuracy drops below thresholds. Critical applications may retrain continuously as new labeled data arrives.
The concept of autonomous data to AI platforms represents the next evolution. Organizations move beyond simple forecasting to create intelligent agents that act on predictions. Systems automatically adjust inventory based on demand forecasts or schedule maintenance based on equipment risk scores.
Industry-Specific Implementation Challenges
Each industry faces unique predictive analytics hurdles.
Manufacturing deals with sensor data quality. Industrial environments create electrical noise, temperature extremes, and vibration that corrupt readings. Models must distinguish actual degradation signals from environmental interference.
Financial services navigate regulatory requirements. Model decisions that affect lending or insurance often require explainability. Complex neural networks that act as black boxes face compliance challenges even when they deliver superior accuracy.
Healthcare predictive models handle sensitive patient data under strict privacy regulations. Model training on protected health information requires careful anonymization. Deployment must prevent re-identification risks.
Retail forecasting contends with rapid trend shifts and external disruptions. Demand patterns that held for years can shift overnight due to viral social media posts or unexpected events.
| Industry | Primary Application | Key Challenge | Success Metric |
|---|---|---|---|
| Manufacturing | Equipment maintenance | Sensor data quality | Downtime reduction |
| Banking | Churn prediction | Model explainability | Retention improvement |
| Retail | Demand forecasting | Rapid trend changes | Inventory optimization |
| Logistics | Route optimization | Real-time adaptation | Delivery accuracy |
Energy sector predictive models forecast consumption patterns and equipment failures in power generation and distribution. Grid operators use predictions to balance supply and demand, preventing blackouts while optimizing energy source utilization.
Construction applies predictive analytics to project timelines, cost overruns, and safety incidents. Models trained on historical project data identify risk factors that typically lead to delays or budget increases.
Measuring Predictive Model Success
Model accuracy alone doesn’t define success.
Classification models use precision, recall, and F1 scores. Precision measures what percentage of positive predictions are correct. Recall captures what percentage of actual positives the model identifies. F1 balances both metrics.
Regression models rely on mean absolute error or root mean squared error. These metrics quantify how far predictions deviate from actual values on average.
But business impact matters most. A churn model with 90% accuracy delivers zero value if the organization doesn’t act on its predictions. Conversely, a maintenance model with 75% accuracy might save millions if it prevents even a few critical failures.
Return on investment calculation compares model implementation costs against operational improvements. Reduced downtime, lower inventory carrying costs, improved customer retention—all convert to financial impact.
The real test happens in production. Predictions get validated when forecasted events occur or don’t occur. Continuous tracking of prediction versus reality reveals whether models maintain accuracy as conditions evolve.
Future Directions in Industrial Predictive Analytics
Predictive capabilities continue advancing as data volumes grow and algorithms improve.
Edge computing brings predictive models directly to industrial equipment. Instead of sending sensor data to cloud servers for analysis, models run on local processors embedded in machinery. This reduces latency and enables immediate response to predicted failures.
Automated machine learning platforms simplify model development. Systems automatically test multiple algorithms, optimize hyperparameters, and select the best-performing approach. Data scientists focus on business problems rather than manual model tuning.
Federated learning allows model training across distributed datasets without centralizing sensitive data. Organizations collaborate to improve prediction accuracy while maintaining data privacy.
Explainable AI techniques make complex models more interpretable. SHAP values and LIME analysis reveal which features drive specific predictions, helping organizations understand and trust model decisions.
The transition from predictive to prescriptive analytics represents the next frontier. Models won’t just forecast what will happen—they’ll recommend what actions to take. Prescriptive systems optimize decisions across multiple objectives and constraints.
Getting Started With Predictive Analytics
Organizations beginning their predictive analytics journey should start step by step:
- Identify a specific business problem with clear success metrics: Attempting to predict everything at once guarantees failure. Pick one use case—equipment failure prediction for a critical production line or churn prediction for high-value customer segments.
- Assess data availability and quality: Predictive models need historical examples that include the outcome being predicted. If equipment failure data wasn’t tracked systematically, building a failure prediction model requires establishing tracking first.
- Start simple: Logistic regression or decision trees often provide surprising accuracy with minimal complexity. Prove value with straightforward models before investing in sophisticated neural network architectures.
- Establish feedback loops: Deploy models in shadow mode initially, generating predictions alongside existing processes without acting on them. Compare predictions to actual outcomes. Refine before giving models decision authority.
- Build organizational capabilities: Predictive analytics success requires data engineering, statistical expertise, domain knowledge, and change management. No single person possesses all skills—assemble cross-functional teams.
Frequently Asked Questions
What’s the difference between predictive analytics and traditional business intelligence?
Traditional business intelligence analyzes historical data to understand what happened and why. Dashboards, reports, and descriptive statistics answer questions about past performance. Predictive analytics uses that historical data to forecast future outcomes. Instead of reporting last quarter’s churn rate, predictive models identify which current customers will likely churn next quarter.
How much historical data do I need to build accurate predictive models?
The required data volume depends on prediction complexity and feature count. Simple problems with few variables might produce useful models from hundreds of examples. Complex problems with many interacting features typically need thousands to tens of thousands of examples. The customer churn dataset that achieved 89.6% accuracy contained 10,000 records with 14 features. Generally speaking, more data improves accuracy, but data quality matters more than quantity.
Can small businesses implement predictive analytics without data science teams?
Yes, though expectations should match resources. Cloud platforms now offer automated machine learning tools that handle much of the technical complexity. Small businesses can start with focused applications like customer lifetime value prediction or inventory optimization using these platforms. The key is starting with clean data and a well-defined business problem. Consider partnering with analytics consultants for initial implementation while building internal capabilities.
How often should predictive models be retrained with new data?
Retraining frequency depends on how quickly patterns change in the underlying business environment. Retail demand models might need monthly retraining to capture seasonal shifts and trend changes. Industrial equipment failure models might remain accurate for quarters if operating conditions stay stable. Monitor model performance metrics continuously—when accuracy drops below acceptable thresholds, retrain. Many organizations establish quarterly retraining schedules as a baseline.
What happens when predictions are wrong?
No predictive model achieves perfect accuracy. Organizations must design processes that account for prediction errors. False positives—predicting an event that doesn’t occur—might waste resources on unnecessary interventions. False negatives—missing events that do occur—mean missed opportunities to prevent problems. The acceptable error rate depends on the cost of each error type. Predicting equipment failure when none occurs costs a maintenance visit. Missing an actual failure costs an entire production line shutdown.
Do I need real-time predictions or are batch forecasts sufficient?
This depends on decision timing requirements. Fraud detection needs real-time scoring because transactions must be approved or declined immediately. Demand forecasting for inventory planning works fine with nightly batch processing since purchasing decisions happen on longer time scales. Real-time systems add complexity and cost—only implement them when immediate action on predictions creates meaningful business value.
How do I convince management to invest in predictive analytics?
Start with a pilot project that addresses a visible, costly business problem. Calculate the potential ROI based on conservative assumptions. If preventing just three equipment failures saves more than the model implementation cost, the business case becomes clear. Use the pilot results to demonstrate value before requesting larger investments. Focus on business outcomes rather than technical capabilities—management cares about reduced costs and increased revenue, not algorithm sophistication.
Making Predictions Work for Your Industry
Predictive analytics transforms reactive organizations into proactive ones. Equipment breaks less often because maintenance happens before failures occur. Customers stay longer because interventions address issues before dissatisfaction leads to churn. Supply chains flow smoothly because disruptions get forecasted and mitigated.
The technology continues advancing, but core principles remain constant. Clean historical data combined with appropriate statistical techniques enables forecasting future outcomes. Model accuracy matters, but business impact determines success.
Industries that implement predictive analytics effectively gain competitive advantages. They optimize operations others can’t. They prevent problems competitors only react to. They make data-driven decisions while others rely on intuition.
The question isn’t whether predictive analytics provides value—documented implementations across manufacturing, finance, retail, and logistics prove it does. The question is whether organizations will invest in the data infrastructure, analytical capabilities, and cultural changes required to capture that value.
Start focused. Prove value on specific use cases. Build capabilities incrementally. The organizations that master predictive analytics today position themselves to lead their industries tomorrow.