Resumen rápido: El análisis predictivo utiliza datos históricos, modelos estadísticos y aprendizaje automático para pronosticar resultados futuros en diversos sectores. Desde el mantenimiento de equipos de fabricación hasta la predicción de la rotación de clientes en el sector bancario, los modelos predictivos ayudan a las organizaciones a reducir riesgos, optimizar operaciones y tomar decisiones basadas en datos. La implementación abarca la recopilación de datos, el entrenamiento, la validación y el despliegue del modelo, transformando así las industrias reactivas en sistemas proactivos y autónomos.
Las líneas de producción no se averían según lo previsto. Los clientes no anuncian que se van. Las cadenas de suministro no dan avisos con antelación antes de colapsar.
Pero en los datos existen patrones: señales ocultas que indican que algo está a punto de salir mal. El análisis predictivo detecta esas señales antes de que surjan los problemas.
El análisis predictivo es una rama del análisis avanzado que realiza predicciones sobre resultados futuros mediante el uso de datos históricos combinados con modelos estadísticos, técnicas de minería de datos y aprendizaje automático. Las empresas emplean herramientas de análisis predictivo para encontrar patrones en los datos que les ayuden a identificar riesgos y oportunidades.
El cambio de una toma de decisiones reactiva a una proactiva representa una transformación fundamental. En lugar de reparar los equipos después de que fallan, las organizaciones predicen las fallas con semanas de anticipación. En lugar de reaccionar ante la pérdida de clientes, los bancos identifican las cuentas en riesgo antes de que se produzca la deserción.
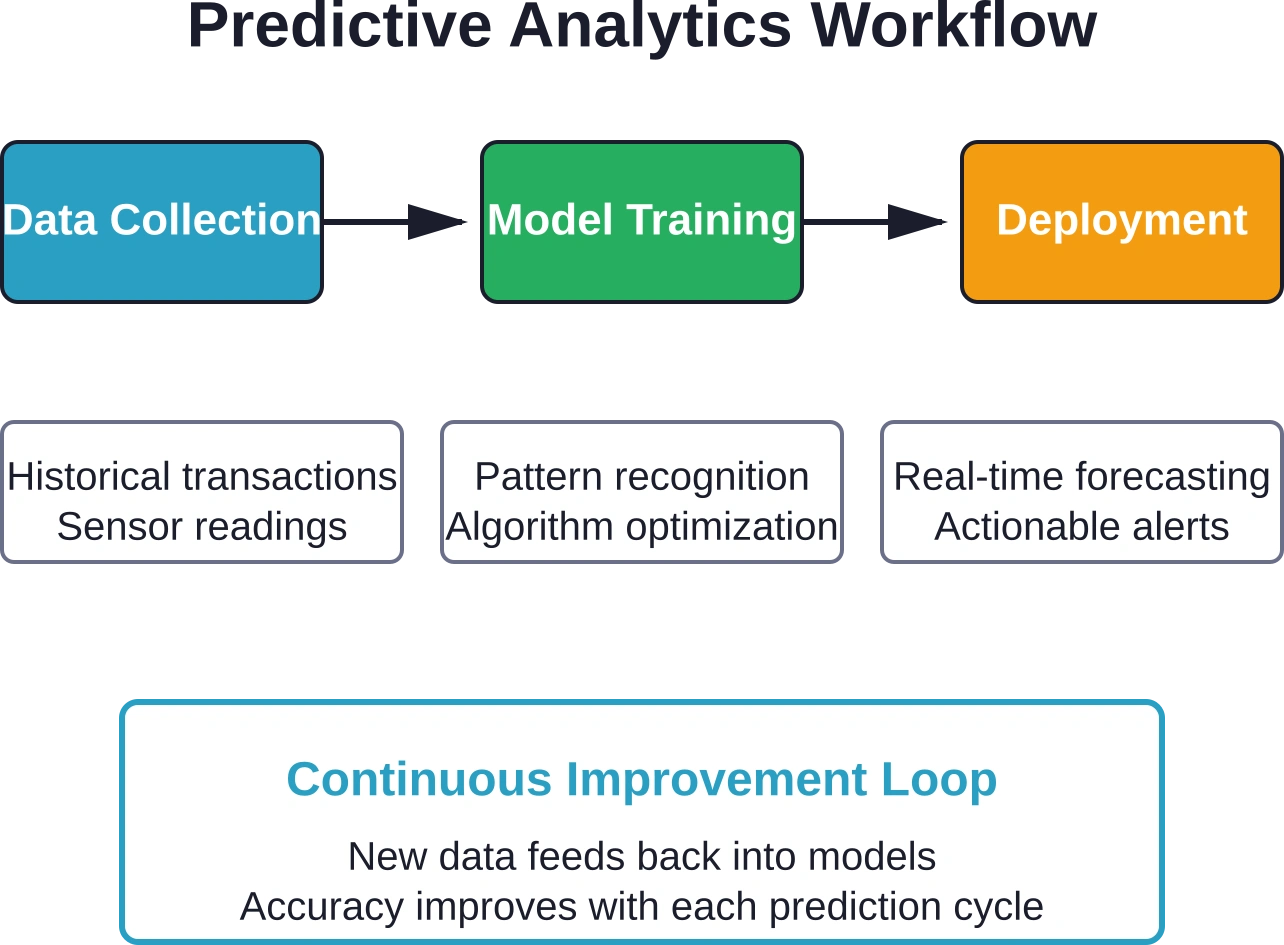
Cómo funciona realmente el análisis predictivo
El proceso comienza con datos históricos. Muchos datos históricos.
Las organizaciones recopilan registros de transacciones, lecturas de sensores, interacciones con clientes, métricas de producción: cualquier dato que capture lo sucedido en el pasado. Esta base histórica alimenta modelos estadísticos que aprenden a reconocer patrones.
Los algoritmos de aprendizaje automático analizan estos patrones. Identifican qué variables se correlacionan con resultados específicos: picos de temperatura antes de fallas en los equipos, patrones de transacciones antes del cierre de cuentas, niveles de inventario antes de interrupciones en el suministro.
Los modelos no solo detectan correlaciones, sino que cuantifican la probabilidad. Una configuración específica de la máquina conlleva un riesgo de fallo de 78% en dos semanas. Una cuenta que muestra tres indicadores de comportamiento tiene una probabilidad de abandono de 82% en 90 días.
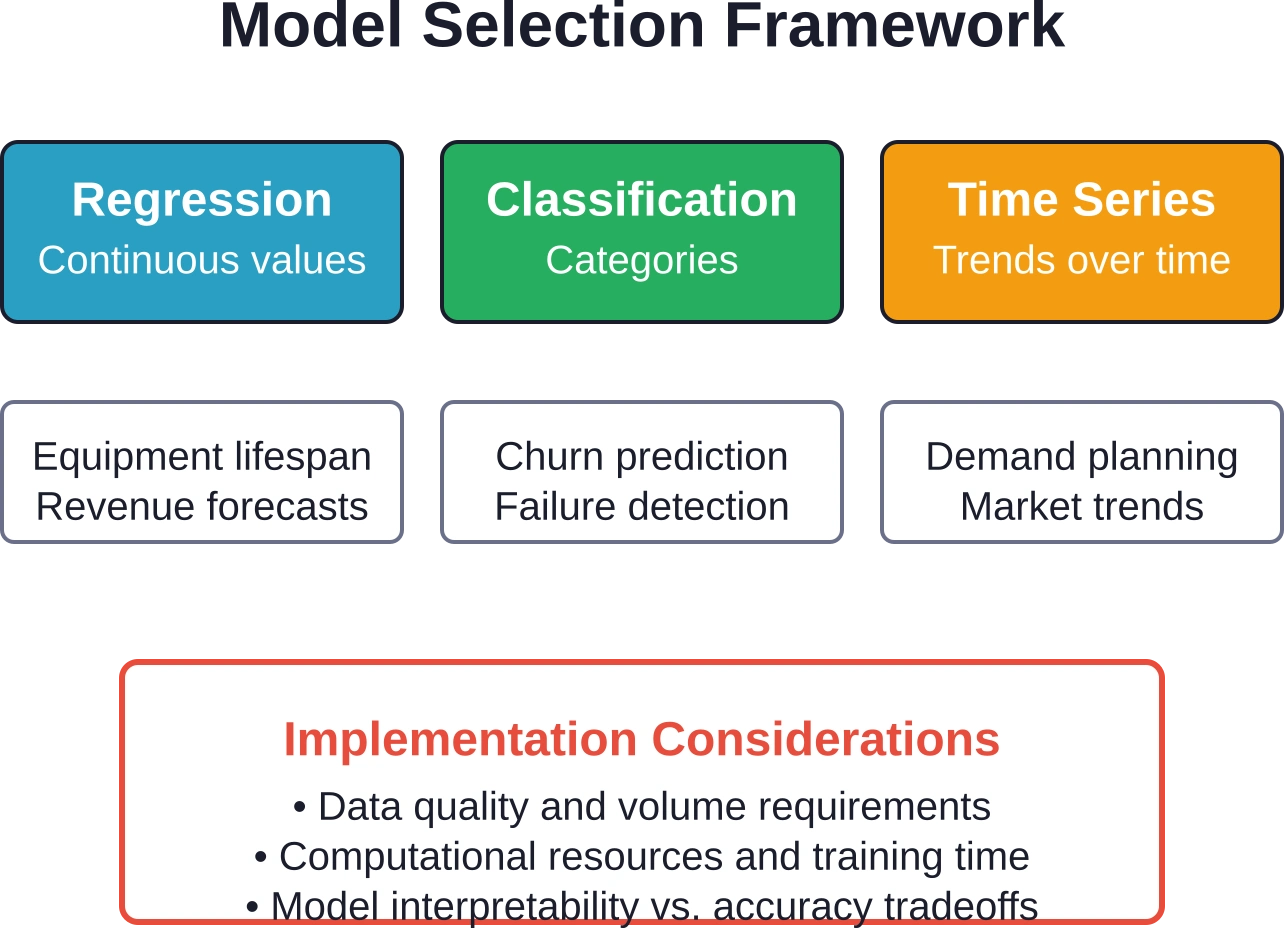
Las técnicas de modelado estadístico varían según el caso de uso. Los modelos de regresión predicen valores continuos como la vida útil del equipo o los ingresos. Los modelos de clasificación predicen resultados categóricos como aprobado/suspenso o permanencia/abandono. Los modelos de series temporales pronostican tendencias durante períodos específicos.
Las técnicas de minería de datos extraen estos patrones de conjuntos de datos masivos. Las redes neuronales con múltiples capas ocultas identifican relaciones no lineales que los humanos pasarían por alto. Los árboles de decisión trazan rutas lógicas ramificadas que conducen a diferentes resultados.
Aplicaciones de mantenimiento predictivo industrial
Las instalaciones de fabricación generan enormes volúmenes de datos de sensores. Lecturas de temperatura, mediciones de vibración, niveles de presión, corriente eléctrica: todo se registra continuamente desde los equipos de producción.
Los modelos de mantenimiento predictivo analizan este flujo de datos de los sensores para pronosticar fallas en los equipos antes de que ocurran. La literatura técnica del IEEE documenta implementaciones que mejoran la disponibilidad de los equipos de fabricación en las empresas automotrices mediante la predicción de las necesidades de mantenimiento.
Las aplicaciones de IoT industrial ahora integran análisis predictivos para un mantenimiento proactivo. Los sensores integrados en motores, bombas, cintas transportadoras y robots de ensamblaje transmiten datos operativos en tiempo real. Los algoritmos de aprendizaje automático procesan estos datos para identificar patrones de degradación.
| Enfoque de mantenimiento | Estrategia | Impacto del tiempo de inactividad | Eficiencia de costos |
|---|---|---|---|
| Reactivo | Reparar después de un fallo | Alto: interrupciones no planificadas | Bajo: las reparaciones de emergencia son costosas. |
| Preventivo | Mantenimiento programado | Medio: tiempo de inactividad planificado | Medio: algo de trabajo innecesario |
| Profético | Intervención basada en pronósticos | Mantenimiento dirigido de bajo nivel | Alto: momento óptimo |
La industria manufacturera se enfrenta a desafíos complejos debido a la escasez de materias primas y las interrupciones en la cadena de suministro. Los modelos predictivos ayudan a reducir los riesgos operativos al pronosticar estas interrupciones antes de que afecten la producción.
Los fabricantes de automóviles utilizan análisis predictivos para optimizar los programas de producción en función de los periodos de mantenimiento previstos para los equipos. En lugar de detener líneas de producción enteras para revisiones rutinarias, el mantenimiento se realiza precisamente cuando los sensores indican que es necesario.
Casos de uso de servicios bancarios y financieros
La fidelización de clientes impulsa la rentabilidad en los servicios financieros. Retener a los clientes existentes cuesta menos que adquirir nuevos.
Las redes neuronales mejoran significativamente la precisión predictiva de la deserción de clientes en el sector bancario. Una investigación que utiliza un conjunto de datos de 10 000 registros con 14 características demuestra cómo el aprendizaje automático predice qué clientes cerrarán sus cuentas.

La regresión logística alcanzó una precisión del 89,61% (TP3T), una tasa de recuperación del 96,81% (TP3T) y un valor AUC de 0,91 para el poder discriminatorio. El clasificador Naive Bayes alcanzó una precisión del 86,71% (TP3T), una exactitud del 92,01% (TP3T) y una recuperación del 92,21% (TP3T), además de un valor AUC de 0,83.
Estos modelos no solo identifican a los clientes en riesgo, sino que los clasifican según su probabilidad y sugieren estrategias de intervención. Las cuentas de alto valor que muestran señales de alerta temprana activan ofertas de retención personalizadas antes de que los clientes tomen la decisión de irse.
Los bancos utilizan arquitecturas de perceptrón multicapa con distintas configuraciones neuronales optimizadas para sus tareas específicas de predicción de abandono de clientes. Estas redes neuronales procesan patrones de transacciones, tendencias de saldos de cuentas, interacciones con el servicio al cliente y factores demográficos.
Las instituciones financieras aplican análisis predictivos para la detección de fraudes, la evaluación del riesgo crediticio y la optimización de carteras de inversión. Cada aplicación se basa en el mismo principio fundamental: los patrones históricos predicen el comportamiento futuro.
Previsión de la cadena de suministro y la logística
Las cadenas de suministro operan en función de múltiples variables. Las fluctuaciones de la demanda, los retrasos en el transporte, los niveles de inventario, la fiabilidad de los proveedores y los patrones estacionales están interconectados.
Los modelos de análisis predictivo procesan esta complejidad para pronosticar la demanda, optimizar el inventario y prevenir interrupciones. El uso de datos y análisis predictivo en logística ayuda a las organizaciones a pasar de la improvisación reactiva a respuestas planificadas.
Los modelos de previsión de la demanda analizan datos históricos de ventas junto con factores externos como el clima, los indicadores económicos y las tendencias del mercado. Los minoristas predicen la demanda de productos con semanas de antelación, ajustando el inventario antes de que se produzcan situaciones de escasez o exceso de existencias.
La optimización del transporte y las rutas utiliza modelos predictivos para pronosticar los tiempos de entrega, teniendo en cuenta los patrones de tráfico, las condiciones climáticas y los datos históricos de retrasos. Las empresas de logística reducen los costos de combustible y mejoran la precisión de las entregas.
Pero el análisis predictivo de la cadena de suministro va más allá. Los modelos identifican el riesgo de los proveedores analizando la consistencia en las entregas, las métricas de calidad y factores externos como la inestabilidad geopolítica o la probabilidad de desastres naturales en las regiones de los proveedores.
Arquitectura del modelo e implementación técnica
La creación de modelos predictivos eficaces requiere decisiones arquitectónicas cuidadosas.
Las redes neuronales ofrecen un potente reconocimiento de patrones, pero requieren una gran cantidad de datos de entrenamiento y recursos computacionales. Los modelos más sencillos, como la regresión logística, funcionan bien para problemas de clasificación binaria con relaciones claras entre las características.
La elección depende de las características de los datos y de la complejidad de la predicción. Los modelos lineales manejan relaciones sencillas. Los modelos no lineales capturan interacciones complejas, pero corren el riesgo de sobreajuste si los datos de entrenamiento son limitados.
El preprocesamiento de datos consume un tiempo de implementación considerable. Los datos brutos contienen inconsistencias, valores faltantes y valores atípicos. La limpieza y normalización de los datos antes del entrenamiento del modelo influye drásticamente en la precisión de la predicción.
La ingeniería de características transforma las variables sin procesar en predictores significativos. La frecuencia de las transacciones se convierte en una característica más útil que las marcas de tiempo de las transacciones sin procesar. La tasa de cambio de temperatura a menudo predice mejor las fallas que la temperatura absoluta.
La validación del modelo evita el sobreajuste. Los datos de entrenamiento enseñan patrones. Los datos de validación comprueban si esos patrones se generalizan a nuevos casos. Los datos de prueba proporcionan métricas de rendimiento finales en ejemplos completamente nuevos.
Las técnicas de validación cruzada dividen los datos de múltiples maneras para garantizar que los modelos tengan un rendimiento consistente en diferentes subconjuntos. La validación cruzada K-fold divide los datos en segmentos, entrenando con la mayoría de ellos y probando con el resto, para luego rotar qué segmento se utiliza como conjunto de prueba.

Aplicar análisis predictivos a los flujos de trabajo de la industria
El análisis predictivo puede ser de gran ayuda para las empresas industriales cuando se relaciona con la planificación, las operaciones, los equipos, la producción, la calidad o la gestión de recursos. IA superior Trabajan con consultoría en IA, aprendizaje automático, análisis predictivo, inteligencia empresarial, visión artificial y desarrollo de software de IA a medida. Su equipo puede ayudar a definir las tareas de predicción adecuadas, preparar datos empresariales u operativos, crear modelos y conectar los resultados con los sistemas existentes. Esto resulta útil para las empresas que desean utilizar los datos para detectar riesgos con antelación, planificar con mayor confianza o reducir ineficiencias evitables.
Recurre a AI Superior para:
- Definición de casos de uso de análisis predictivo
- Creación de modelos de pronóstico y detección de anomalías
- Apoyo al mantenimiento predictivo y al análisis de calidad.
- Creación de herramientas de BI en torno a los datos operativos
- Integración de información predictiva en los flujos de trabajo empresariales
Contacta con AI Superior para explorar casos de uso de análisis predictivo para sus datos industriales, operaciones o procesos de planificación.
Despliegue y mejora continua
Los modelos entrenados necesitan integrarse en los sistemas operativos.
La arquitectura de implementación determina cómo llegan las predicciones a quienes toman las decisiones. El procesamiento por lotes genera pronósticos según un cronograma: predicciones de demanda diarias o informes semanales de riesgo de mantenimiento. El procesamiento en tiempo real califica las transacciones a medida que ocurren: detección de fraude o alertas inmediatas de control de calidad.
Los puntos finales de la API permiten que varios sistemas soliciten predicciones. Un sistema CRM consulta el modelo de abandono de clientes cuando el servicio de atención al cliente interactúa con una cuenta. Un sistema de inventario solicita pronósticos de demanda al planificar las reposiciones.
El monitoreo de los modelos implementados evita la degradación de la precisión. Las condiciones del mercado cambian. Los patrones que se mantuvieron vigentes el año pasado podrían no aplicarse el próximo trimestre. Las métricas de rendimiento del modelo permiten realizar un seguimiento de la precisión de las predicciones en función de los resultados actuales.
Los programas de reentrenamiento actualizan los modelos con datos recientes. Algunas organizaciones realizan el reentrenamiento mensualmente. Otras lo activan cuando la precisión cae por debajo de ciertos umbrales. Las aplicaciones críticas pueden reentrenarse continuamente a medida que llegan nuevos datos etiquetados.
El concepto de plataformas de IA con datos autónomos representa la siguiente evolución. Las organizaciones van más allá de la simple previsión para crear agentes inteligentes que actúan en función de las predicciones. Los sistemas ajustan automáticamente el inventario según las previsiones de demanda o programan el mantenimiento según las puntuaciones de riesgo de los equipos.
Desafíos de implementación específicos de la industria
Cada sector industrial se enfrenta a desafíos únicos en materia de análisis predictivo.
La fabricación se ocupa de la calidad de los datos de los sensores. Los entornos industriales generan ruido eléctrico, temperaturas extremas y vibraciones que distorsionan las lecturas. Los modelos deben distinguir las señales de degradación reales de las interferencias ambientales.
Los servicios financieros deben cumplir con los requisitos regulatorios. Las decisiones basadas en modelos que afectan a los préstamos o los seguros a menudo requieren explicabilidad. Las redes neuronales complejas, que funcionan como cajas negras, se enfrentan a desafíos de cumplimiento normativo incluso cuando ofrecen una precisión superior.
Los modelos predictivos en el sector sanitario manejan datos confidenciales de pacientes bajo estrictas normativas de privacidad. El entrenamiento de los modelos con información sanitaria protegida requiere una anonimización rigurosa. Su implementación debe prevenir los riesgos de reidentificación.
La previsión en el sector minorista se enfrenta a rápidos cambios de tendencias y perturbaciones externas. Los patrones de demanda que se mantuvieron durante años pueden cambiar de la noche a la mañana debido a publicaciones virales en redes sociales o eventos inesperados.
| Industria | Aplicación principal | Desafío clave | Métrica de éxito |
|---|---|---|---|
| Fabricación | Mantenimiento de equipos | calidad de los datos del sensor | reducción del tiempo de inactividad |
| Bancario | Predicción de abandono | Explicabilidad del modelo | Mejora de la retención |
| Minorista | Previsión de la demanda | Cambios de tendencia rápidos | Optimización de inventario |
| Logística | Optimización de ruta | Adaptación en tiempo real | Precisión en la entrega |
Los modelos predictivos del sector energético pronostican los patrones de consumo y las fallas de los equipos en la generación y distribución de energía. Los operadores de la red utilizan estas predicciones para equilibrar la oferta y la demanda, evitando apagones y optimizando la utilización de las fuentes de energía.
En el sector de la construcción, se aplican análisis predictivos a los plazos de los proyectos, los sobrecostes y los incidentes de seguridad. Los modelos, entrenados con datos históricos de proyectos, identifican los factores de riesgo que suelen provocar retrasos o aumentos presupuestarios.
Medición del éxito de los modelos predictivos
La precisión del modelo por sí sola no define el éxito.
Los modelos de clasificación utilizan la precisión, la exhaustividad y la puntuación F1. La precisión mide el porcentaje de predicciones positivas correctas. La exhaustividad indica el porcentaje de positivos reales que identifica el modelo. La puntuación F1 equilibra ambas métricas.
Los modelos de regresión se basan en el error absoluto medio o en el error cuadrático medio. Estas métricas cuantifican cuánto se desvían las predicciones de los valores reales en promedio.
Pero lo que más importa es el impacto en el negocio. Un modelo de predicción de abandono con una precisión del 901% no aporta ningún valor si la organización no actúa en función de sus predicciones. Por el contrario, un modelo de mantenimiento con una precisión del 75% podría ahorrar millones si evita incluso unos pocos fallos críticos.
El cálculo del retorno de la inversión compara los costos de implementación del modelo con las mejoras operativas. La reducción del tiempo de inactividad, la disminución de los costos de mantenimiento de inventario y la mejora de la retención de clientes se traducen en un impacto financiero.
La verdadera prueba se produce en la producción. Las predicciones se validan cuando los eventos pronosticados ocurren o no. El seguimiento continuo de la predicción frente a la realidad revela si los modelos mantienen su precisión a medida que evolucionan las condiciones.
Direcciones futuras en el análisis predictivo industrial
Las capacidades predictivas siguen avanzando a medida que aumenta el volumen de datos y mejoran los algoritmos.
La computación perimetral lleva los modelos predictivos directamente a los equipos industriales. En lugar de enviar datos de sensores a servidores en la nube para su análisis, los modelos se ejecutan en procesadores locales integrados en la maquinaria. Esto reduce la latencia y permite una respuesta inmediata ante fallos previstos.
Las plataformas automatizadas de aprendizaje automático simplifican el desarrollo de modelos. Los sistemas prueban automáticamente múltiples algoritmos, optimizan los hiperparámetros y seleccionan el enfoque de mejor rendimiento. Los científicos de datos se centran en los problemas de negocio en lugar de en el ajuste manual de los modelos.
El aprendizaje federado permite entrenar modelos con conjuntos de datos distribuidos sin centralizar datos confidenciales. Las organizaciones colaboran para mejorar la precisión de las predicciones manteniendo la privacidad de los datos.
Las técnicas de IA explicable hacen que los modelos complejos sean más interpretables. Los valores SHAP y el análisis LIME revelan qué características impulsan predicciones específicas, lo que ayuda a las organizaciones a comprender y confiar en las decisiones del modelo.
La transición de la analítica predictiva a la prescriptiva representa la próxima frontera. Los modelos no solo pronosticarán lo que sucederá, sino que también recomendarán las acciones a seguir. Los sistemas prescriptivos optimizan las decisiones considerando múltiples objetivos y restricciones.
Introducción al análisis predictivo
Las organizaciones que inician su andadura en el análisis predictivo deben comenzar paso a paso:
- Identifique un problema empresarial específico con métricas de éxito claras: Intentar predecir todo a la vez garantiza el fracaso. Elija un caso práctico: predicción de fallos en equipos para una línea de producción crítica o predicción de la deserción de clientes en segmentos de alto valor.
- Evaluar la disponibilidad y la calidad de los datos: Los modelos predictivos necesitan ejemplos históricos que incluyan el resultado que se predice. Si no se ha realizado un seguimiento sistemático de los datos de fallos de los equipos, para crear un modelo de predicción de fallos es necesario establecer primero dicho seguimiento.
- Empieza por lo sencillo: La regresión logística o los árboles de decisión suelen ofrecer una precisión sorprendente con una complejidad mínima. Compruebe su eficacia con modelos sencillos antes de invertir en arquitecturas de redes neuronales sofisticadas.
- Establecer mecanismos de retroalimentación: Implemente inicialmente los modelos en modo de prueba, generando predicciones junto con los procesos existentes sin modificarlos. Compare las predicciones con los resultados reales. Refine los modelos antes de otorgarles autoridad para tomar decisiones.
- Desarrollar capacidades organizativas: El éxito en el análisis predictivo requiere ingeniería de datos, experiencia estadística, conocimiento del sector y gestión del cambio. Nadie posee todas las habilidades por sí solo; lo ideal es formar equipos multidisciplinarios.
Preguntas frecuentes
¿Cuál es la diferencia entre el análisis predictivo y la inteligencia empresarial tradicional?
La inteligencia empresarial tradicional analiza datos históricos para comprender qué sucedió y por qué. Los paneles de control, los informes y las estadísticas descriptivas responden preguntas sobre el rendimiento pasado. El análisis predictivo utiliza esos datos históricos para pronosticar resultados futuros. En lugar de informar la tasa de abandono del trimestre anterior, los modelos predictivos identifican qué clientes actuales tienen más probabilidades de abandonar el servicio el próximo trimestre.
¿Cuántos datos históricos necesito para construir modelos predictivos precisos?
El volumen de datos necesario depende de la complejidad de la predicción y del número de características. Los problemas sencillos con pocas variables pueden generar modelos útiles a partir de cientos de ejemplos. Los problemas complejos con muchas características que interactúan entre sí suelen requerir entre miles y decenas de miles de ejemplos. El conjunto de datos de abandono de clientes que alcanzó una precisión del 89,61 % (TP3T) contenía 10 000 registros con 14 características. En general, cuantos más datos haya, mayor será la precisión, pero la calidad de los datos es más importante que la cantidad.
¿Pueden las pequeñas empresas implementar análisis predictivos sin equipos de ciencia de datos?
Sí, aunque las expectativas deben ajustarse a los recursos. Las plataformas en la nube ofrecen ahora herramientas de aprendizaje automático automatizadas que gestionan gran parte de la complejidad técnica. Las pequeñas empresas pueden empezar con aplicaciones específicas, como la predicción del valor de vida del cliente o la optimización del inventario, utilizando estas plataformas. La clave está en comenzar con datos limpios y un problema de negocio bien definido. Considere la posibilidad de colaborar con consultores de análisis para la implementación inicial mientras desarrolla capacidades internas.
¿Con qué frecuencia se deben reentrenar los modelos predictivos con datos nuevos?
La frecuencia de reentrenamiento depende de la rapidez con que cambien los patrones en el entorno empresarial subyacente. Los modelos de demanda minorista podrían requerir reentrenamiento mensual para reflejar los cambios estacionales y las tendencias. Los modelos de fallas de equipos industriales podrían mantener su precisión durante trimestres si las condiciones operativas se mantienen estables. Supervise continuamente las métricas de rendimiento del modelo: cuando la precisión caiga por debajo de los umbrales aceptables, realice un reentrenamiento. Muchas organizaciones establecen cronogramas de reentrenamiento trimestrales como referencia.
¿Qué ocurre cuando las predicciones son erróneas?
Ningún modelo predictivo alcanza una precisión perfecta. Las organizaciones deben diseñar procesos que tengan en cuenta los errores de predicción. Los falsos positivos (predecir un evento que no ocurre) pueden suponer un desperdicio de recursos en intervenciones innecesarias. Los falsos negativos (no detectar eventos que sí ocurren) implican la pérdida de oportunidades para prevenir problemas. La tasa de error aceptable depende del coste de cada tipo de error. Predecir un fallo en un equipo cuando no se produce ninguno conlleva el coste de una visita de mantenimiento. No detectar un fallo real conlleva el cierre de toda la línea de producción.
¿Necesito predicciones en tiempo real o me bastan las previsiones por lotes?
Esto depende de los requisitos de tiempo de decisión. La detección de fraude requiere una puntuación en tiempo real, ya que las transacciones deben aprobarse o rechazarse de inmediato. La previsión de la demanda para la planificación de inventario funciona bien con el procesamiento por lotes nocturno, dado que las decisiones de compra se toman en plazos más largos. Los sistemas en tiempo real añaden complejidad y coste; solo deben implementarse cuando la acción inmediata basada en predicciones genere un valor empresarial significativo.
¿Cómo puedo convencer a la dirección para que invierta en análisis predictivo?
Comience con un proyecto piloto que aborde un problema empresarial visible y costoso. Calcule el retorno de la inversión potencial basándose en supuestos conservadores. Si prevenir tan solo tres fallas de equipos genera ahorros superiores al costo de implementación del modelo, la viabilidad del proyecto se vuelve evidente. Utilice los resultados del piloto para demostrar su valor antes de solicitar inversiones mayores. Céntrese en los resultados empresariales, no en las capacidades técnicas: a la gerencia le importan la reducción de costos y el aumento de los ingresos, no la sofisticación del algoritmo.
Cómo hacer que las predicciones funcionen para su industria.
El análisis predictivo transforma las organizaciones reactivas en proactivas. Los equipos se averían con menos frecuencia porque el mantenimiento se realiza antes de que se produzcan fallos. Los clientes permanecen más tiempo porque las intervenciones abordan los problemas antes de que la insatisfacción provoque la pérdida de clientes. Las cadenas de suministro fluyen sin problemas porque las interrupciones se pronostican y se mitigan.
La tecnología sigue avanzando, pero los principios fundamentales permanecen inalterables. La combinación de datos históricos precisos con técnicas estadísticas adecuadas permite predecir resultados futuros. La precisión del modelo es importante, pero el impacto en el negocio determina el éxito.
Las industrias que implementan eficazmente el análisis predictivo obtienen ventajas competitivas. Optimizan operaciones que otras no pueden. Previenen problemas ante los que sus competidores solo reaccionan. Toman decisiones basadas en datos, mientras que otras se guían por la intuición.
La cuestión no es si el análisis predictivo aporta valor —las implementaciones documentadas en los sectores de manufactura, finanzas, comercio minorista y logística demuestran que sí—. La cuestión es si las organizaciones invertirán en la infraestructura de datos, las capacidades analíticas y los cambios culturales necesarios para aprovechar ese valor.
Comience con un enfoque claro. Demuestre su valor en casos de uso específicos. Desarrolle capacidades de forma gradual. Las organizaciones que dominan el análisis predictivo hoy se posicionan para liderar sus sectores mañana.