Quick Summary: AI data collection is the systematic process of gathering, preparing, and curating datasets to train and validate artificial intelligence models. Success requires balancing data quality, diversity, privacy compliance, and ethical considerations while implementing proper governance frameworks. Organizations that master real-time, high-quality data collection—coupled with responsible AI practices—position themselves to build more accurate, fair, and trustworthy AI systems.
Artificial intelligence systems live or die by the data they consume. Every chatbot response, every facial recognition match, every predictive recommendation traces back to one fundamental ingredient: data.
Without high-quality, properly collected data, even the most sophisticated algorithms produce unreliable results. Industry experts emphasize that in an AI model, it’s 100% garbage in, garbage out.
The challenge? Data collection for AI isn’t simply about amassing large volumes of information. It demands strategic planning, ethical consideration, regulatory compliance, and continuous quality control.
This guide walks through the complete data collection lifecycle—from understanding core concepts to implementing collection methods, ensuring quality, navigating privacy regulations, and adopting best practices that align with 2026 standards.
What Is AI Data Collection?
AI data collection encompasses the methods, processes, and technologies used to gather information that trains, tests, and validates machine learning models. This data becomes the foundation upon which algorithms learn patterns, make predictions, and generate outputs.
Unlike traditional data collection for analytics or reporting, AI-focused collection serves a specific purpose: creating datasets that represent the problem space comprehensively enough for a model to generalize from examples to new, unseen scenarios.
The process involves several distinct phases. First comes identification—determining what data the model needs based on the problem domain. Next is acquisition, where raw data gets collected from various sources. Then preparation and annotation, transforming raw data into structured, labeled formats that algorithms can process. Finally, validation ensures the dataset meets quality and representativeness standards.
Types of Data for AI Systems
Different AI applications require fundamentally different data types:
- Structured data: Organized information in databases, spreadsheets, or tables with clearly defined fields—customer records, transaction logs, sensor readings.
- Unstructured data: Text documents, emails, social media posts, audio recordings, video files that lack predefined organization.
- Image data: Photographs, medical scans, satellite imagery, product images used for computer vision tasks.
- Time-series data: Sequential measurements over time—stock prices, weather patterns, IoT sensor streams.
- Behavioral data: User interactions, clickstreams, navigation patterns, engagement metrics.
Each type demands specialized collection approaches, annotation standards, and storage infrastructure.

Get Your Data Ready for AI With AI Superior
AI Superior helps companies define AI opportunities, assess available datasets, and check whether machine learning is the right fit before development starts. Their process covers discovery, data review, MVP development, scaling, integration, and result evaluation.
For AI data collection work, this can help teams understand what data they have, what is missing, and how to prepare it for a practical AI system.
Need Help Reviewing Your AI Data?
AI Superior can help with:
- assessing available datasets
- defining AI and ML use cases
- planning PoC or MVP development
- preparing workflows for AI integration
👉 Contact AI Superior to discuss your project.
Why Data Collection Is Critical for AI Success
The quality and characteristics of training data directly determine model performance. Several factors make data collection the linchpin of AI development:
- Model accuracy depends on data representativeness. If training data fails to capture the full diversity of real-world scenarios, the model develops blind spots. An AI trained primarily on data from one demographic group will underperform when encountering others.
- Bias stems from collection choices. Systematic gaps or overrepresentation in datasets create biased models that perpetuate or amplify existing inequities. The Federal Trade Commission has taken enforcement action against companies making deceptive AI claims, including cases where inadequate data led to misleading performance promises.
- Continuous improvement requires fresh data. AI models trained on static datasets grow stale as real-world conditions evolve. Real-time data collection mechanisms keep models current and responsive to emerging patterns.
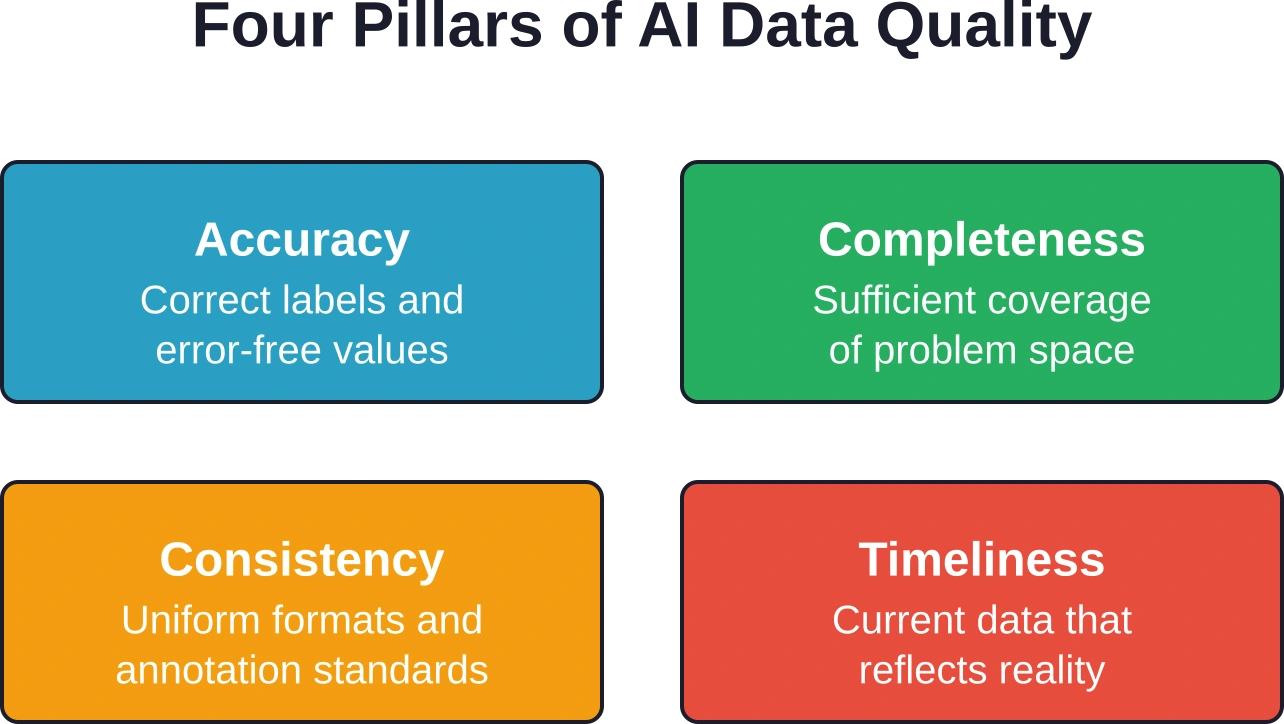
Core Data Collection Methods for AI
Organizations employ multiple collection strategies depending on data requirements, resource constraints, and application domains.
Primary Data Collection
Primary collection involves generating new data specifically for the AI project at hand. This approach offers maximum control over quality and relevance but typically requires more time and resources.
- Surveys and questionnaires gather self-reported information directly from target populations. Well-designed surveys can capture attitudes, preferences, and behaviors that other methods miss. The key challenge lies in designing questions that elicit accurate, unbiased responses and achieving representative sample coverage.
- Sensor and IoT data streams provide continuous, real-time measurements from physical environments. Manufacturing facilities deploy sensors to collect equipment performance data. Smart cities gather traffic, air quality, and infrastructure data. These streams generate massive volumes that require robust ingestion pipelines and storage infrastructure.
- Controlled experiments systematically vary conditions to collect data under known parameters. This approach works particularly well for training models where ground truth needs precise definition—A/B testing interfaces, clinical trials, or laboratory measurements.
- User interaction logging captures how people engage with systems—clicks, navigation paths, search queries, time spent on pages. This behavioral data reveals patterns that stated preferences often obscure. Privacy considerations become paramount when collecting interaction data, requiring clear consent mechanisms and careful anonymization.
Secondary Data Collection
Secondary collection leverages existing datasets created for other purposes. This approach accelerates project timelines and reduces costs but introduces less control over data characteristics.
- Public datasets and repositories offer pre-collected, often pre-annotated data for common AI tasks. Government agencies, research institutions, and industry consortia maintain repositories covering domains from natural language to medical imaging. Organizations including the National Institute of Standards and Technology (NIST) provide standardized datasets that support AI development while enabling performance benchmarking across systems.
- Web scraping automatically extracts information from websites and online platforms. This technique can rapidly accumulate large text corpora, product information, or social media content. However, legal and ethical considerations matter—website terms of service, copyright protections, and privacy regulations impose constraints on what can be scraped and how that data can be used.
- Third-party data providers specialize in collecting, curating, and licensing datasets for commercial use. These vendors offer access to proprietary datasets across industries—consumer behavior, financial markets, healthcare records. Due diligence becomes critical to verify data provenance, collection methods, and compliance with applicable regulations.
- Internal organizational data represents potentially the most valuable secondary source—customer databases, transaction histories, operational logs, support tickets. This data directly reflects the contexts where AI will operate, though it often requires substantial cleaning and restructuring before use in model training.
Synthetic Data Generation
Synthetic data creation uses algorithms to generate artificial datasets that mimic real-world data distributions without containing actual individual records. This approach addresses privacy concerns, data scarcity for rare scenarios, and the need for perfectly balanced training sets.
Generative models can create realistic images, text, or numerical data based on patterns learned from smaller real datasets. Simulation environments generate training data for autonomous systems—self-driving cars trained in virtual environments before real-world deployment, robots learning manipulation tasks in physics simulators.
The tradeoff? Synthetic data might not capture all the complexity and edge cases present in reality. Models trained purely on synthetic data sometimes struggle when encountering real-world messiness. Best practice often combines synthetic data for initial training and augmentation with real data for refinement and validation.
Data Collection Tools and Platforms
The technology landscape offers numerous tools addressing different collection needs:
| Tool Category | Primary Use Cases | Key Capabilities |
|---|---|---|
| Data integration platforms | Aggregating data from multiple sources | API connectors, ETL pipelines, real-time streaming, data transformation |
| Annotation tools | Labeling images, text, video for supervised learning | Collaborative labeling, quality control workflows, active learning integration |
| Web scraping frameworks | Extracting data from websites | HTML parsing, JavaScript rendering, anti-blocking mechanisms, scheduling |
| Survey platforms | Collecting questionnaire responses | Form builders, logic branching, response analytics, panel management |
| Data warehouses | Centralized storage and management | Scalable storage, SQL querying, access control, versioning |
| Feature stores | Managing ML features across pipelines | Feature versioning, serving infrastructure, monitoring, reuse across models |
Platform selection depends on technical requirements, existing infrastructure, team expertise, and budget constraints. Organizations often combine multiple tools into integrated data collection architectures rather than relying on single solutions.
Ensuring Data Quality and Validation
Collection represents only the first step. Raw data invariably contains errors, inconsistencies, and gaps that undermine model training. Systematic quality assurance transforms collected data into reliable training assets.
Data Cleaning and Preprocessing
Cleaning removes or corrects problematic records before they contaminate training sets:
- Duplicate detection identifies and eliminates redundant records that would give certain patterns disproportionate weight during training.
- Missing value handling addresses incomplete records through deletion, imputation, or flagging, depending on the extent and pattern of missingness.
- Outlier analysis distinguishes genuine edge cases worth preserving from data entry errors or sensor malfunctions requiring removal.
- Format standardization ensures consistency in units, date formats, text encoding, and categorical values across the dataset.
- Noise reduction filters measurement errors and random variations that obscure true patterns without removing legitimate variability.
Preprocessing transforms cleaned data into formats optimized for model consumption—normalization, feature engineering, dimensionality reduction, and tokenization.
Validation and Testing Protocols
Validation confirms that collected data actually serves its intended purpose. Several complementary approaches provide confidence:
- Statistical profiling examines distributions, correlations, and summary statistics to detect unexpected patterns suggesting collection problems. Comparing profiles between new batches and established baselines flags potential issues.
- Schema validation verifies that data conforms to expected structures—required fields present, data types correct, values within acceptable ranges, referential integrity maintained.
- Sample audits involve manual inspection of random subsets to catch errors that automated checks miss. Human reviewers assess annotation quality, identify ambiguous cases, and surface systematic issues.
- Holdout testing reserves portions of collected data exclusively for model evaluation. These holdout sets provide unbiased performance estimates since models never see them during training. Maintaining strict separation between training and test data prevents overfitting and ensures models genuinely generalize.
Privacy, Compliance, and Ethical Considerations
Data collection for AI operates within complex regulatory and ethical frameworks that have grown increasingly stringent. Organizations that fail to navigate these requirements face legal consequences, reputational damage, and loss of public trust.
Regulatory Frameworks and Compliance Standards
Organizations collecting, processing, or storing data for AI must follow rules that vary by country, industry, and data type.
NIST has developed AI guidance focused on trustworthiness, transparency, and risk management, including its AI Risk Management Framework and ongoing standards work. The FTC has also increased attention on AI data practices, especially around transparency, consent, accountability, and the use of customer data for model training.
Industry rules add another layer. Healthcare data may fall under HIPAA, financial data under consumer protection and security regulations, and educational records under FERPA. Companies working internationally also need to account for GDPR in Europe and other emerging data governance frameworks worldwide.
Consent and Transparency Requirements
Meaningful consent forms the ethical foundation for responsible data collection. Several principles guide consent practices:
- Informed consent requires clearly explaining what data gets collected, how it will be used, who will access it, and how long it will be retained. Technical jargon and legal complexity shouldn’t obscure these fundamentals—explanations must be comprehensible to typical users.
- Specific purpose limitation means collecting data only for explicitly stated purposes and not repurposing it for unrelated AI projects without additional consent. The temptation to extract additional value from collected data must be balanced against consent boundaries.
- Opt-in versus opt-out architectures have different ethical implications. Opt-in approaches—requiring active consent before collection—respect autonomy more than opt-out systems that collect by default unless users take action to prevent it.
- Revocable consent allows individuals to withdraw permission and request data deletion. Systems should provide straightforward mechanisms for consent withdrawal rather than creating friction that discourages exercise of this right.
Bias Mitigation and Fairness
Data collection choices directly influence whether AI systems perpetuate or reduce societal biases. Several strategies help promote fairness:
- Representative sampling ensures training data includes adequate representation across relevant demographic groups, geographic regions, and use contexts. Convenience sampling that overrepresents easily accessible populations introduces bias.
- Bias auditing examines collected datasets for systematic gaps or skews before training begins. Statistical analysis can reveal imbalances requiring correction through additional targeted collection or reweighting strategies.
- Inclusive data collection actively seeks perspectives and examples from marginalized or underrepresented groups rather than settling for whatever data proves easiest to obtain.
- Fairness metrics quantify whether datasets and resulting models treat different groups equitably across dimensions like accuracy, false positive rates, and false negative rates. These metrics guide decisions about whether additional data collection is needed to address disparities.
Academic and Research Guidelines
Research institutions have developed specific guidance for responsible AI data collection in academic contexts. Virginia Tech’s Considerations for the Responsible and Ethical Use of AI, published in November 2025 and revised in February 2026, translates the university’s Responsible and Ethical AI Framework (2025) into practical research lifecycle steps.
These guidelines emphasize that researchers should not enter confidential or proprietary information—including grant concepts, unpublished data, or inventions—into AI tools not approved by the institution. The framework addresses data provenance, proper attribution, and maintaining research integrity when using AI for data collection and analysis.
Northeastern University and the University of Illinois System have similarly published standards for AI use in research, emphasizing responsible conduct principles including honesty, accuracy, efficiency, and objectivity.
Real-World Data Collection Challenges
Theory and practice diverge when organizations attempt to implement data collection at scale. Several recurring challenges emerge:
Volume and Velocity Management
Modern AI applications often require enormous datasets. Computer vision models train on millions of images. Large language models consume billions of text tokens. Time-series models for anomaly detection process continuous sensor streams.
The infrastructure needed to ingest, process, and store these volumes strains budgets and technical capabilities. Streaming data pipelines must handle thousands or millions of events per second without data loss. Storage systems must balance access speed, redundancy, and cost across petabytes of information.
But wait—more data doesn’t automatically mean better models. Beyond certain thresholds, additional volume provides diminishing returns unless it adds genuinely new information. Strategic collection that prioritizes diversity and quality over pure quantity often produces superior results with lower resource requirements.
Data Labeling Bottlenecks
Supervised learning—still the dominant AI paradigm—requires labeled training examples. Humans must annotate images, transcribe audio, classify text, or mark entities. This annotation work becomes the rate-limiting step in many AI projects.
Labeling costs scale linearly with dataset size, creating budget pressure. Quality control adds complexity—multiple annotators must label subsets to measure agreement, and disagreements require resolution processes. Domain expertise requirements further constrain annotator pools for specialized applications.
Several strategies help address labeling bottlenecks:
- Active learning has models identify the most informative examples for human labeling, reducing total annotation needs.
- Semi-supervised learning leverages large unlabeled datasets alongside smaller labeled sets, extracting signal from both.
- Crowdsourcing platforms distribute labeling tasks across large annotator pools, accelerating throughput though introducing quality management challenges.
- Transfer learning uses models pre-trained on general datasets, requiring less labeled data for specialization to specific tasks.
Data Drift and Concept Drift
Real-world environments change over time. Customer preferences shift. Market conditions evolve. Adversaries adapt their tactics. Product catalogs update. Regulatory requirements change.
Models trained on historical data gradually lose relevance as the distributions they learned drift away from current reality. Performance degrades silently unless monitoring systems detect the divergence.
Addressing drift requires continuous data collection that captures current conditions, monitoring systems that flag performance degradation, and retraining pipelines that update models with fresh data. The cadence depends on how quickly the domain evolves—some applications need daily updates, others remain stable for months.
Privacy-Utility Tradeoffs
Strong privacy protections that preserve individual confidentiality sometimes conflict with data utility for model training. Techniques like differential privacy add mathematical noise that protects individuals but reduces signal available for learning.
Aggregation and anonymization provide privacy benefits but eliminate granular patterns that models might leverage. Synthetic data generation preserves privacy but may not capture all real-world complexity.
Organizations must navigate these tradeoffs based on application requirements, risk tolerance, and regulatory obligations. Use cases where privacy risks are high but utility requirements are modest might favor aggressive protection. Applications where model performance directly impacts safety or critical functions might accept narrower privacy margins within legal boundaries.
Best Practices for AI Data Collection in 2026
Successful data collection programs incorporate lessons learned from early AI deployments and emerging standards:
Establish Data Governance Frameworks
Formal governance structures define roles, responsibilities, and processes around data collection and management. Key components include:
- Data stewardship assigns ownership and accountability for data quality, security, and compliance.
- Access controls restrict who can view, modify, or export different data types based on role and need.
- Audit trails log data access and transformations to support compliance verification and incident investigation.
- Retention policies specify how long data should be kept and when it should be deleted, balancing utility against storage costs and privacy principles.
- Documentation standards require metadata describing data provenance, collection methods, known limitations, and intended uses.
Implement Data Quality Monitoring
Quality assurance shouldn’t be a one-time validation at collection. Ongoing monitoring catches degradation before it impacts models:
- Automated profiling generates statistical summaries of incoming data batches and compares them against baselines.
- Anomaly detection flags unusual patterns that might indicate collection problems or upstream changes.
- Completeness checks verify that expected data volumes arrive on schedule without unexplained gaps.
- Freshness monitoring ensures data pipelines deliver recent information rather than stale snapshots.
Prioritize Real-Time Collection Capabilities
Batch processing of historical data serves some use cases, but many modern AI applications demand real-time responsiveness. Streaming architectures that process data as it arrives enable:
- Immediate model updates reflecting current conditions
- Real-time personalization based on recent behavior
- Fraud detection systems that catch threats before damage accumulates
- Operational monitoring that alerts on anomalies within seconds
Building real-time collection requires investment in streaming infrastructure, but the competitive advantages often justify the costs in fast-moving domains.
Design for Explainability and Auditability
When AI systems make decisions affecting people—credit approvals, medical diagnoses, hiring recommendations—stakeholders rightfully demand explanations. Data collection practices should support explainability:
- Maintain provenance records tracing training data back to original sources
- Document data transformations and preprocessing steps
- Preserve metadata that contextualizes why certain data was included or excluded
- Enable reconstruction of the exact datasets used to train deployed models
Auditors, regulators, and researchers may need to examine data collection practices years after the fact. Documentation that seems excessive in the moment often proves invaluable during investigations.
Build Cross-Functional Collaboration
Data collection shouldn’t be relegated to data engineering teams alone. Effective programs involve:
- Domain experts who understand what data truly matters and what edge cases exist
- Data scientists who know model requirements and data format preferences
- Legal counsel who identify compliance obligations and risk areas
- Ethics reviewers who assess fairness and societal implications
- Security teams who protect data from unauthorized access or breaches
- Product managers who connect data needs to business objectives and user value
Regular cross-functional reviews catch problems that might escape notice within functional silos.
| Best Practice | Primary Benefit | Implementation Complexity |
|---|---|---|
| Data governance framework | Compliance and accountability | Medium—requires policy development and training |
| Real-time collection pipelines | Current data for responsive models | High—demands streaming infrastructure investment |
| Automated quality monitoring | Early problem detection | Medium—requires tooling and baseline establishment |
| Comprehensive documentation | Auditability and reproducibility | Low—mainly process discipline |
| Cross-functional collaboration | Holistic risk assessment | Low—organizational coordination |
| Privacy-preserving techniques | Regulatory compliance and trust | Medium to high—depends on technique |
Looking Ahead: Future Trends in AI Data Collection
Several emerging trends will shape data collection practices in coming years:
Federated Learning and Decentralized Collection
Traditional approaches centralize data in repositories where models train. Federated learning inverts this—models travel to where data resides, training locally and sharing only learned parameters rather than raw data.
This architecture addresses privacy concerns by keeping sensitive data within organizational or device boundaries. Medical institutions can collaborate on model development without sharing patient records. Mobile devices can improve personalization without uploading user behavior.
Challenges remain around coordination complexity, communication overhead, and ensuring security of the aggregation process. But the privacy benefits make federated approaches increasingly attractive as regulations tighten.
Self-Supervised and Unsupervised Methods
Reducing dependence on labeled data represents a major research frontier. Self-supervised learning creates training signals from data structure itself—predicting masked words in text, reconstructing corrupted images, forecasting next frames in video sequences.
These approaches dramatically reduce labeling costs while leveraging massive unlabeled datasets. As self-supervised techniques mature, collection strategies will shift emphasis from exhaustive labeling to gathering diverse raw data at scale.
Multimodal Data Integration
Real-world understanding often requires combining information across modalities—images with captions, video with audio, sensor readings with contextual metadata. Models that process multimodal inputs can develop richer representations than single-modality systems.
Collection strategies increasingly focus on gathering aligned multimodal datasets where different data types correspond to the same entities or events. The infrastructure complexity increases, but model capabilities advance correspondingly.
Continuous Learning Systems
Static training-deployment cycles give way to continuous learning where models update perpetually as new data arrives. This approach keeps models current but introduces challenges around stability, catastrophic forgetting, and quality control.
Data collection for continuous learning emphasizes streaming ingestion, rapid validation, and mechanisms for detecting when new data degrades rather than improves model performance.
Frequently Asked Questions
What’s the difference between data collection for AI versus traditional analytics?
Traditional analytics data collection focuses on capturing information for human analysis, reporting, and business intelligence. AI data collection serves a different purpose: creating training sets that teach algorithms to recognize patterns and make predictions. AI datasets require different characteristics—larger volumes, more diverse examples covering edge cases, careful labeling for supervised learning, and representativeness across the problem space. Traditional analytics might accept sampling that captures central tendencies; AI training needs comprehensive coverage including rare scenarios the model might encounter.
How much data do I actually need to train an AI model?
No universal answer exists—requirements vary dramatically by problem complexity, model architecture, and performance targets. Simple classification tasks with clear decision boundaries might achieve good results with hundreds of labeled examples. Computer vision models typically need thousands to millions of images. Large language models train on billions of text tokens. Generally speaking, more complex problems with higher-dimensional input spaces and more nuanced decision boundaries require larger datasets. Transfer learning and pre-trained models can dramatically reduce data needs for specific applications by leveraging learning from general datasets.
What are the biggest mistakes organizations make in AI data collection?
Common pitfalls include: prioritizing quantity over quality and collecting massive datasets without ensuring accuracy and relevance; neglecting diversity and gathering data from narrow sources that don’t represent the full problem space; ignoring privacy and compliance requirements until legal issues emerge; treating data collection as a one-time project rather than an ongoing process; poor documentation that leaves future teams unable to understand data provenance and limitations; and inadequate validation that allows problematic data into training pipelines. Organizations also frequently underestimate the time and cost required for data labeling, creating project delays when annotation becomes a bottleneck.
Can I use publicly available datasets or do I need to collect my own data?
Both approaches have merits depending on circumstances. Public datasets offer faster project starts, lower costs, and sometimes better quality from specialized curation efforts. Academic benchmarks enable performance comparisons across different modeling approaches. However, public data may not match the specific distribution, edge cases, or proprietary aspects of a particular application domain. Custom collection provides data tailored precisely to the problem but requires more resources and time. Many successful projects combine approaches—starting with public datasets for initial development then adding proprietary data to specialize models for specific deployment contexts.
How do I balance data quality with collection speed and cost?
This tradeoff requires strategic thinking about minimum viable quality thresholds. Start by defining what quality dimensions matter most for the specific application—some use cases demand near-perfect accuracy while others tolerate noisier data if volume compensates. Implement tiered collection where a subset receives intensive validation while bulk collection uses cheaper methods with spot-check audits. Leverage techniques like active learning to focus expensive labeling effort on the most informative examples. Consider phased approaches where initial models train on smaller high-quality datasets, then expand to larger noisier datasets once baseline performance is established. Monitor model performance metrics to determine when quality issues actually impact results versus when they remain theoretical concerns.
What role does synthetic data play in AI training?
Synthetic data serves several valuable purposes in the collection toolkit. It addresses privacy concerns by generating artificial records that preserve statistical properties without containing actual individual information. Synthetic generation helps handle class imbalance by creating additional examples of rare scenarios. Simulation environments produce synthetic training data for autonomous systems where real-world collection would be dangerous, expensive, or time-consuming. The limitations? Synthetic data might not capture all real-world complexity, and models trained purely on synthetic data can struggle with distribution shifts when deployed. Best practices typically combine synthetic data for initial training, data augmentation, or balancing with real-world data for validation and fine-tuning.
How should I handle data collection for AI in regulated industries?
Regulated industries—healthcare, finance, education, government—face additional compliance layers beyond general privacy laws. Start by identifying all applicable regulations for the specific data types and jurisdictions involved. Engage legal counsel and compliance specialists early in project planning rather than as an afterthought. Implement technical controls including encryption, access restrictions, audit logging, and data minimization. Obtain proper consent with clear explanations of AI uses. Consider privacy-preserving techniques like differential privacy, federated learning, or synthetic data generation that reduce regulatory risk. Document all collection processes, data flows, and compliance measures thoroughly. Regulatory frameworks continue evolving—NIST standards, FTC guidance, and agency-specific rules—so build monitoring processes that track relevant updates affecting data collection practices.
Building AI Systems on Solid Data Foundations
Data collection might seem like mere infrastructure work—technical plumbing that supports the exciting model development happening downstream. That perspective misses the fundamental truth: no amount of algorithmic sophistication compensates for inadequate training data.
The organizations building the most capable and trustworthy AI systems recognize that data collection demands strategic attention, substantial resources, and ongoing refinement. They establish governance frameworks that balance innovation with responsibility. They invest in quality assurance that catches problems early. They design collection architectures for adaptability as requirements evolve.
Success in this environment requires treating data collection as a core competency rather than a commodity task. The technical aspects matter—choosing appropriate collection methods, implementing robust pipelines, validating quality systematically. But so do the organizational and ethical dimensions—cross-functional collaboration, transparent practices, privacy protection, bias mitigation, and compliance diligence.
The AI models dominating headlines represent the visible outputs. The data collection processes supporting those models remain largely invisible to end users. Yet those unseen collection practices ultimately determine whether AI systems deliver value or create problems—whether they extend capabilities or amplify biases, whether they respect privacy or exploit it, whether they earn trust or erode it.
Organizations embarking on AI initiatives should invest as much strategic planning in data collection as in model architecture selection. Build collection capabilities that scale. Establish quality standards that hold. Create governance that protects. Document practices that withstand scrutiny.
Start with data. Do it right. Everything else follows from there.