ملخص سريع: انخفضت تكاليف استدلال نماذج التعلم الموجه بالذكاء الاصطناعي (LLM) بمقدار عشرة أضعاف سنويًا منذ عام 2021، حيث بلغت تكلفة أداء بمستوى GPT-4 الآن $0.40 لكل مليون رمز مميز، مقارنةً بـ $30 لكل مليون رمز مميز مُدخل و$60 لكل مليون رمز مميز مُخرج في مارس 2023. مع ذلك، قد تستهلك نماذج الاستدلال داخليًا ما يزيد عن 100 ضعف ما تُخرجه من رموز مميزة، مما يُؤدي إلى مفارقة في التكلفة حيث يُؤدي انخفاض سعر الرمز المميز إلى ارتفاع إجمالي الفواتير. يُعد فهم التكاليف الحقيقية للبنية التحتية، وتقنيات التحسين، والاختيار بين خدمات واجهة برمجة التطبيقات (API) وعمليات النشر ذاتية الاستضافة أمرًا بالغ الأهمية لاقتصاديات الذكاء الاصطناعي المستدامة.
دخل اقتصاد الذكاء الاصطناعي مرحلةً تتحدى المنطق التقليدي. فبينما تتصدر عناوين الأخبار احتفالات انخفاض أسعار العملات الرقمية، تكتشف شركات الذكاء الاصطناعي حقيقةً مزعجة: فواتيرها في ازدياد مستمر.
ما كان يكلف 1 تريليون/4 تريليون/60 لكل مليون رمز في نوفمبر 2021، أصبح يكلف الآن ما بين 1 تريليون/4 تريليون/0.06 و0.40 لكل مليون رمز لتحقيق أداء مماثل لنموذج GPT-4، ما يمثل انخفاضًا يتراوح بين 150 و1000 ضعف حسب النموذج. ومع ذلك، تُشير العديد من الشركات الناشئة التي تعتمد على نماذج لغوية ضخمة إلى أن تكاليف البنية التحتية تستنزف ما بين 40 و60 تريليون/3 تريليون من إيراداتها.
ما هو السبب؟ تحول جذري في كيفية توليد نماذج الذكاء الاصطناعي الحديثة للاستجابات - ونمط استهلاك الرموز الذي لم يتوقعه أحد.
الانخفاض الحاد في تسعير الاستدلال في نماذج LLM
انخفضت تكاليف الاستدلال في نماذج التعلم الآلي (LLM) بوتيرة أسرع من أي سلعة حاسوبية أخرى تقريبًا في التاريخ. ووفقًا لبحثٍ يُحلل اتجاهات التسعير، يتفاوت معدل انخفاض التكلفة بشكلٍ كبير تبعًا لمستوى الأداء، حيث يتراوح بين 9 أضعاف و900 ضعف سنويًا.
يختلف معدل الانخفاض اختلافًا كبيرًا باختلاف المهمة. ففي بعض المعايير، انخفضت الأسعار بمقدار 9 أضعاف سنويًا. وفي معايير أخرى، وصل الانخفاض إلى 900 ضعف سنويًا، مع العلم أن هذه الانخفاضات الحادة حدثت بشكل رئيسي في عام 2024 وقد لا تستمر.
إليكم كيف يبدو ذلك عمليًا. عندما أصبح GPT-3 متاحًا للجمهور في نوفمبر 2021، كان النموذج الوحيد الذي حقق درجة MMLU بلغت 42. التكلفة؟ $60 لكل مليون رمز. بحلول مارس 2026، تجاوزت نماذج متعددة هذا المعيار بتكلفة $0.06 لكل مليون رمز أو أقل.
يتصدر برنامج Gemini Flash-Lite 3.1 من جوجل قائمة البرامج ذات الأسعار الاقتصادية، حيث يبلغ سعره $0.25 لكل مليون رمز إدخال و$1.50 لكل مليون رمز إخراج. أما النماذج مفتوحة المصدر، التي يقدمها مزودون مثل Together.ai، فتُقدم أسعارًا أقل، حيث يعمل برنامج Llama 3.2 3B بسعر $0.06 لكل مليون رمز إدخال.
لماذا انخفضت الأسعار بهذه السرعة؟
تساهم عدة عوامل في خفض التكاليف هذه. فالنماذج أصبحت أصغر حجماً مع الحفاظ على الأداء، بفضل تقنيات التدريب المحسّنة. يمكن لنموذج ذي 13 مليار مُعامل أن يحقق الآن 95% من درجة MMLU لنموذج GPT-3 مع حجم استدلال أصغر بكثير.
تستمر تكاليف الأجهزة لكل وحدة حوسبة في الانخفاض. استقرت أسعار Cloud H100 عند $2.85-$3.50 دولارًا أمريكيًا في الساعة بعد انخفاضها من ذروتها في عام 2023. ووفقًا لبحث arXiv، فإن التكلفة الأساسية للساعة لكل بطاقة A800 80G تبلغ حوالي $0.79 دولارًا أمريكيًا، وتقع عمومًا ضمن نطاق $0.51-$0.99 دولارًا أمريكيًا في الساعة.
لقد أحدثت تقنيات التحسين مثل التكميم والتجميع المستمر وتقنية PagedAttention نقلة نوعية في قدرات الإنتاجية. وقد تحسنت الأنظمة في معيار MLPerf Inference v5.1 بما يصل إلى 50% مقارنةً بأفضل نظام في الإصدار 5.0 قبل ستة أشهر (سبتمبر 2025).
لكن هناك شرط.
مفارقة استهلاك الرموز
لا يمثل انخفاض سعر الرمز الواحد سوى نصف الحقيقة. أما النصف الآخر فيتعلق بعدد الرموز التي تستهلكها النماذج الحديثة فعلياً.
تُنتج نماذج اللغة التقليدية الاستجابات بشكل خطي. اطرح سؤالاً، واحصل على إجابة. يتناسب استهلاك الرموز تقريبًا مع طول الناتج. تستهلك الاستجابة المكونة من 200 كلمة ما يقارب 250-300 رمز.
تختلف نماذج الاستدلال في طريقة عملها. فهي "تفكر" في المشكلات داخلياً قبل إنتاج المخرجات. وتستهلك عملية الاستدلال الداخلية هذه الكثير من الرموز.
تُظهر الأمثلة الواقعية حجم هذا التحول. قد يستخدم سؤال بسيط 10000 رمز استدلال داخليًا بينما يُعيد إجابةً لا تتجاوز 200 رمز. هذا يزيد 50 ضعفًا عن عدد الرموز التي يُشير إليها الناتج الظاهر.
في حالات استثنائية موثقة من قبل المستخدمين، استهلكت بعض نماذج الاستدلال أكثر من 600 رمز لإنتاج كلمتين فقط. ويمكن أن يتضخم استعلام بسيط، كان سيستخدم 50 رمزًا فقط مع نموذج قياسي، ليصل إلى أكثر من 30,000 رمز عند تفعيل الاستدلال المتقدم.
الأثر التجاري
يُؤدي هذا إلى ما يُطلق عليه البعض "مفارقة تكلفة إدارة دورة حياة المنتج". انخفض سعر الرمز المميز الواحد عشرة أضعاف، بينما زاد استهلاك الرموز المميزة مئة ضعف لبعض أحمال العمل. لا تُبشّر هذه الحسابات بالخير لشركات الذكاء الاصطناعي.
تواجه الشركات الناشئة التي بنت نماذج التسعير على أساس اقتصاديات الرموز التقليدية انخفاضًا في هوامش الربح. فعلى سبيل المثال، قد يُكبّد العميل الذي يدفع $20 شهريًا تكاليف استدلال تتراوح بين $18 و$25 خلال مهام الاستدلال المعقدة. ببساطة، لا يُجدي نموذج اقتصاديات الوحدة نفعًا.
استجاب بعض مزودي الخدمة بوضع حد أقصى لعدد رموز الاستدلال، مما يحد من قدرة النموذج على إجراء عمليات التفكير الداخلية. بينما طبق آخرون نظام تسعير متدرج حيث تكلف الطلبات التي تتطلب استدلالًا مكثفًا تكلفة أعلى. إلا أن هذه الحلول تخلق تعقيدات ومشاكل.
فهم التكاليف الحقيقية للبنية التحتية
إلى جانب تسعير واجهات برمجة التطبيقات، تحتاج الفرق التي تفكر في نشر تطبيقاتها ذاتيًا إلى فهم هيكل التكلفة بالكامل. تكشف الأرقام متى يكون النشر الذاتي مجديًا اقتصاديًا، ومتى لا يكون كذلك.
اقتصاديات البنية التحتية لوحدات معالجة الرسومات
وفقًا لإرشادات قياس الأداء الصادرة عن NVIDIA في يونيو 2025، فإن حساب تكاليف الاستدلال الحقيقية يتطلب مراعاة اقتناء الأجهزة، واستهلاك الطاقة، والتبريد، وعرض النطاق الترددي للشبكة، والنفقات التشغيلية العامة.
تتراوح تكلفة مثيلات H100 السحابية بين 2.85 و3.50 جنيه إسترليني في الساعة، وذلك حسب مزود الخدمة ومدة الاشتراك. تتطلب مثيلات H100 المُستضافة ذاتيًا نفقات رأسمالية بالإضافة إلى تكاليف تشغيلية مستمرة. ويعتمد حساب نقطة التعادل على معدلات الاستخدام.
تشير الأبحاث إلى أن البنية التحتية ذاتية الاستضافة تصبح مجدية عندما يتجاوز استخدام وحدة معالجة الرسومات 50% بشكل مستدام. أما دون هذا الحد، فعادةً ما توفر خدمات واجهة برمجة التطبيقات (API) جدوى اقتصادية أفضل.
| عنصر التكلفة | موفر الخدمات السحابية | الاستضافة الذاتية |
|---|---|---|
| تكلفة وحدة معالجة الرسومات | $2.85-3.50/ساعة | $30,000-40,000 (H100) |
| الطاقة (لكل وحدة معالجة رسومية) | مشمول | $0.40-0.60/ساعة |
| تبريد | مشمول | $0.15-0.25/ساعة |
| شبكة | $0.08-0.12/GB صادر | قسط شهري ثابت |
| العمليات | الحد الأدنى | مهندس واحد أو اثنان بدوام كامل |
| نقطة التعادل | — | استخدام 50%+ |
معادلة الاستخدام
يُحدد معدل الاستخدام كل شيء. فتكلفة وحدة معالجة الرسومات التي تعمل بمعدل استخدام 30% تزيد بمقدار 3.3 أضعاف لكل عملية استدلال مقارنةً بتلك التي تعمل بمعدل 100%. ولكن تحقيق معدل استخدام عالٍ يتطلب حجم عمل ثابت واستراتيجيات تجميع متطورة.
يمكن للمعالجة الدفعية أن تقلل تكلفة كل رمز إخراج بما يصل إلى 30% مقارنةً بالمعالجة الفردية. وتعمل تقنيات مثل التجميع المستمر، حيث يقوم محرك الاستدلال بدمج الطلبات ديناميكيًا عند وصولها، على زيادة الإنتاجية إلى أقصى حد.
يمكن أن تُحسّن كفاءة النموذج من خلال التكميم، وهياكل مزيج الخبراء، وتنقيح البيانات، الجدوى الاقتصادية بمقدار 2-5 أضعاف دون المساس بالجودة. ووفقًا لمعلومات مزود Together.ai، فإن بنية مزيج الخبراء في DeepSeek مُهيأة لتقديم أداء يُضاهي GPT-4 بكفاءة عالية من حيث التكلفة.
هيكل التكلفة عبر أحجام النماذج
يؤثر حجم النموذج بشكل مباشر على تكاليف الاستدلال، لكن العلاقة ليست خطية. فالنماذج الأصغر لا تعني بالضرورة تكاليف أقل نسبياً، وقد توفر النماذج الأكبر قيمة أفضل في بعض الأحيان للمهام المعقدة.
النماذج الصغيرة (معاملات من 3B إلى 7B)
تتميز النماذج في هذا النطاق بكفاءتها العالية من حيث التكلفة في المهام البسيطة. تبلغ تكلفة Llama 3.2 3B حوالي $0.06 لكل مليون رمز. وتتعامل هذه النماذج بكفاءة مع التصنيف، والإجابة على الأسئلة البسيطة، واستخراج البيانات المنظمة.
يكمن المقابل في القدرة. فالنماذج الصغيرة تواجه صعوبة في التعامل مع الاستدلال المعقد، وفهم اللغة الدقيق، والمهام التي تتطلب معرفة واسعة بالعالم. وهذا مقبول بالنسبة للعديد من أحمال العمل الإنتاجية.
النماذج المتوسطة (المعلمات من 13B إلى 70B)
يمثل هذا النطاق النطاق الأمثل للعديد من التطبيقات. قد يكلف نموذج بحجم 13 مليار نقطة يحقق 95% من درجة MMLU لنموذج GPT-3، $0.25 لكل مليون رمز مميز - وهو أعلى من النماذج الصغيرة، ولكنه يتمتع بقدرات استدلال أفضل بكثير.
تُقدّم نماذج فئة 70B، مثل Llama 3.1 70B، أداءً متميزًا يُقارب أداء أحدث التقنيات، حيث تبلغ تكلفتها حوالي $0.80 لكل مليون رمز. بالنسبة للتطبيقات التي تتطلب قدرة استدلالية قوية دون الحاجة إلى إمكانيات متطورة للغاية، تُوفّر هذه النماذج اقتصاديات وحدة ممتازة.
النماذج الكبيرة (أكثر من 175 مليار معلمة)
تتراوح تكلفة النماذج الرائدة مثل GPT-4 وClaude وGemini Ultra بين $2 و15 لكل مليون رمز، وذلك حسب النموذج المحدد ومزود الخدمة. وتتميز هذه النماذج بقدرتها الفائقة على الاستدلال المعقد، والمهام الإبداعية، وحل المشكلات التي تتطلب معرفة متعمقة بالمجال.
تصبح التكلفة الأعلى لكل رمز اقتصاديًا عندما يكمل النموذج المهام في عدد أقل من التكرارات، أو يقدم استجابات أكثر دقة، أو يمكّن حالات الاستخدام التي لا تستطيع النماذج الأصغر التعامل معها ببساطة.

هل تحتاج إلى مساعدة في تصميم ونشر نظام إدارة دورة حياة القانون؟
إذا كنت تخطط لتشغيل نموذج لغوي كبير في بيئة الإنتاج، فمن المفيد العمل مع فريق يقوم ببناء ونشر أنظمة الذكاء الاصطناعي كل يوم. متفوقة الذكاء الاصطناعي تُطوّر الشركة تطبيقات ذكاء اصطناعي مُخصصة بالاعتماد على نماذج التعلّم الآلي ونماذج التعلم اللغوي، بدءًا من دراسة الجدوى الأولية وصولًا إلى النشر والتكامل. يعمل فريقها من علماء البيانات والمهندسين على تطوير النماذج، وأنظمة معالجة اللغة الطبيعية، وخطوط نقل البيانات، والنشر في بيئة الإنتاج. كما يُساعدون في تقييم ما إذا كانت حالة الاستخدام تتطلب بالفعل نموذجًا للتعلم اللغوي، وكيفية هيكلة النظام لضمان تشغيله بكفاءة.
هل أنت مستعد للتخطيط لتنفيذ برنامج الماجستير في القانون؟
تحدث مع الذكاء الاصطناعي المتفوق على:
- قم بتقييم حالة استخدام برنامج الماجستير في القانون والمتطلبات التقنية الخاصة بك
- تصميم وبناء أنظمة الذكاء الاصطناعي أو معالجة اللغة الطبيعية المخصصة
- نشر النماذج ودمجها في البرامج الحالية
👈 اطلب استشارة الذكاء الاصطناعي مع متفوقة الذكاء الاصطناعي لمناقشة مشروعك في برنامج الماجستير في القانون.
خدمات واجهة برمجة التطبيقات مقابل اقتصاديات الاستضافة الذاتية
يعتمد الاختيار بين خدمات واجهة برمجة التطبيقات (API) والبنية التحتية المستضافة ذاتيًا على الحجم وأنماط الاستخدام والقدرات التقنية. ولا يوجد خيار واحد مهيمن بشكل مطلق.
عندما تفوز خدمات واجهة برمجة التطبيقات
توفر خدمات واجهة برمجة التطبيقات (API) من OpenAI وAnthropic وGoogle ومزودين مثل Together.ai حلولاً اقتصادية جذابة للعديد من السيناريوهات. عدم الحاجة لإدارة البنية التحتية يعني أن الفرق ستركز على منطق التطبيق بدلاً من إدارة وحدة معالجة الرسومات (GPU).
تتناسب التكاليف طرديًا مع الاستخدام. وتكون تكلفة الأشهر ذات الاستخدام المنخفض أقل نسبيًا من تكلفة الأشهر ذات الاستخدام المرتفع. لا توجد نفقات رأسمالية، ولا طاقة فائضة خلال فترات انخفاض الطلب، ولا تكاليف تشغيلية إضافية للبنية التحتية لخدمة النموذج.
بالنسبة للتطبيقات ذات أنماط حركة المرور المتغيرة، أو الطلب الموسمي، أو مسارات النمو غير المتوقعة، فإن واجهات برمجة التطبيقات (APIs) توفر عادةً اقتصاديات أفضل ما لم يتجاوز معدل النقل المستدام عتبة عالية إلى حد ما.
متى يكون الاستضافة الذاتية منطقية
يصبح الاستضافة الذاتية مجدية اقتصاديًا عندما يتجاوز استخدام وحدة معالجة الرسومات (GPU) بشكل مستدام 50%. ووفقًا لبيانات قياس الأداء، يتطلب ذلك حجم عمل ثابتًا - ما يقرب من 10 ملايين رمز مميز يوميًا لإعداد وحدة معالجة رسومات واحدة.
إلى جانب الاعتبارات الاقتصادية البحتة، تلجأ بعض المؤسسات إلى الاستضافة الذاتية لضمان خصوصية البيانات، أو لتلبية متطلبات التخصيص، أو لتلبية احتياجات محددة تتعلق بزمن الاستجابة. في كثير من الأحيان، لا تستطيع تطبيقات الخدمات المالية والرعاية الصحية والتطبيقات الحكومية إرسال البيانات إلى واجهات برمجة التطبيقات الخارجية بغض النظر عن مزايا التكلفة.
تُمكّن محركات الاستدلال مفتوحة المصدر مثل vLLM من عمليات نشر عالية الأداء ومستضافة ذاتيًا. تعمل تقنيات PagedAttention والتجميع المستمر في vLLM على زيادة استخدام وحدة معالجة الرسومات إلى أقصى حد، مما يجعل الاستضافة الذاتية أكثر تنافسية من الناحية الاقتصادية.
| عامل | واجهات برمجة التطبيقات المفضلة | يفضل الاستضافة الذاتية |
|---|---|---|
| مقدار | أقل من 10 ملايين رمز مميز يوميًا | أكثر من 50 مليون رمز مميز يوميًا |
| نمط حركة المرور | متغير/شائك | متسق/قابل للتنبؤ |
| احتياجات زمن الاستجابة | مرن | متطلبات منخفضة للغاية |
| حساسية البيانات | معيار | حساسية عالية |
| التخصيص | النماذج القياسية جيدة | هل تحتاج إلى نماذج مخصصة؟ |
| القدرة التقنية | عمليات التعلم الآلي المحدودة | فريق عمليات قوي في مجال التعلم الآلي |
تقنيات التحسين التي تُحدث تحولاً في الاقتصاد
يمكن لعدة تقنيات أن تقلل تكاليف الاستدلال بمقدار يتراوح بين ضعفين إلى عشرة أضعاف دون المساس بالجودة. وتعمل هذه التحسينات سواء باستخدام واجهات برمجة التطبيقات أو الاستضافة الذاتية.
التكميم
يؤدي التكميم إلى تقليل دقة النموذج من 16 بت أو 32 بت للفاصلة العائمة إلى 8 بت أو حتى 4 بت للأعداد الصحيحة. وهذا يقلل من حجم الذاكرة المستخدمة ويسرع عملية الاستدلال.
تحافظ أساليب التكميم الحديثة على الجودة بشكل ملحوظ. ووفقًا لأبحاث حول تدريب FP8، يمكن استخدام تنسيقات منخفضة الدقة لمعظم المتغيرات في تدريب نماذج التعلم الخطي واستنتاجها دون المساس بالدقة. وتقدم شركات مثل Together.ai نماذج مُكمّمة بأسعار مخفضة مع ضمان الحفاظ على الجودة.
التحسين الفوري
يؤثر طول الرسالة بشكل مباشر على التكاليف. فرسالة مكونة من 5000 رمز، تتم معالجتها 1000 مرة، تكلف نفس تكلفة 5 ملايين رمز من الاستدلال. ويؤدي تحسين الرسائل لتكون موجزة مع الحفاظ على فعاليتها إلى خفض التكاليف بشكل فوري.
تُظهر الأبحاث أن تحسين التوجيهات يُحسّن دقة المهام مع تقليل استهلاك الرموز في الوقت نفسه. فالتوجيهات المنظمة جيدًا تُوجّه النماذج بكفاءة أكبر، مما يُقلل من رموز الاستدلال اللازمة للوصول إلى الإجابات الصحيحة.
تخزين الاستجابة مؤقتًا
تُجري العديد من التطبيقات طلبات متشابهة أو متطابقة بشكل متكرر. ويؤدي تخزين الاستجابات للاستعلامات الشائعة إلى التخلص تمامًا من تكاليف الاستدلال الزائدة.
تعتمد استراتيجيات التخزين المؤقت الذكية على التشابه في الاستجابة، وليس فقط على التطابق التام. يقارن التخزين المؤقت الدلالي معنى الطلبات ويعيد الاستجابات المخزنة مؤقتًا للاستعلامات المتشابهة بدرجة كافية، حتى عندما تختلف الصياغة.
توجيه النماذج
لا يتطلب كل طلب استخدام أقوى نموذج. إن توجيه الاستعلامات البسيطة إلى نماذج صغيرة وسريعة، والاستعلامات المعقدة إلى نماذج أكبر، يُحسّن المفاضلة بين التكلفة والجودة.
يتطلب هذا منطقًا مسبقًا لتصنيف تعقيد الطلبات، لكن الجدوى الاقتصادية غالبًا ما تبرر الاستثمار. توجيه 70% من حركة البيانات إلى نموذج $0.10/مليون رمز، و30% إلى نموذج $3/مليون رمز، ينتج عنه تكلفة إجمالية قدرها $0.97/مليون، وهي أقل بكثير من استخدام النموذج المكلف لكل شيء.
المشهد الخدمي في عام 2026
لقد تطور سوق مزودي خدمات الاستدلال بشكل كبير. وتلبي الآن عدة فئات من المزودين احتياجات مختلفة.
واجهات برمجة تطبيقات نموذج الحدود
تُقدّم OpenAI وAnthropic وGoogle إمكانيات متطورة بأسعار مرتفعة. تتراوح تكلفة نماذج GPT-4 بين $2 و15 لكل مليون رمز، وذلك حسب نوع النموذج. يستثمر هؤلاء المزودون بكثافة في السلامة والموثوقية والقدرات المتطورة.
يمثل نموذجا o3 و o4-mini من OpenAI، اللذان تم إصدارهما عام 2025، تطوراً ملحوظاً في قدرات الاستدلال. ووفقاً لتقييمات OpenAI، يرتكب o3 أخطاءً جسيمة أقل بكثير من o1 في المهام الصعبة التي تتطلب مهارات واقعية، ويتفوق بشكل خاص في تطبيقات البرمجة والاستشارات التجارية.
منصات نموذج المصادر المفتوحة
توفر شركات مثل Together.ai وFireworks وReplicate نماذج مفتوحة المصدر بأسعار أقل بكثير. توفر نماذج DeepSeek على منصة Together.ai وفورات في التكاليف تتراوح بين 70 و901 تيرابايت مقارنةً بالبدائل مغلقة المصدر، مع تقديم أداء فائق.
تجمع هذه المنصات بين نماذج مفتوحة المصدر شائعة الاستخدام وبنية تحتية خاصة بالخدمة. والنتيجة: أداء ممتاز بأسعار أقل بكثير، وإن كان ذلك أحيانًا مع مستوى أقل من تصفية الأمان ومراقبة المحتوى.
خدمات الذكاء الاصطناعي لمزودي الخدمات السحابية
تُقدّم كلٌّ من AWS وAzure وGoogle Cloud نماذجها الخاصة ونماذج الجهات الخارجية عبر واجهات برمجة تطبيقات موحدة. وتختلف الأسعار، ولكن عادةً ما يضيف مزودو الخدمات السحابية هامش ربح على الوصول المباشر إلى واجهة برمجة التطبيقات، مع توفير ميزات خاصة بالمؤسسات مثل اتفاقيات مستوى الخدمة، وشهادات الامتثال، والتكامل مع البنية التحتية السحابية الحالية.
مزودو الاستدلال المتخصصون
تركز شركات مثل Groq تحديدًا على تحسين الاستدلال. وتركز Groq على تحسين الاستدلال من خلال استخدام رقائق سيليكون مخصصة لتحقيق أداء منخفض زمن الاستجابة.
مسار التكلفة المستقبلية
إلى أين تتجه تكاليف الاستدلال من هنا؟ هناك عدة اتجاهات تشكل التوقعات.
من غير المرجح أن تستمر معدلات خفض التكاليف التي بلغت عشرة أضعاف سنويًا خلال الفترة من 2021 إلى 2025 بنفس الوتيرة. فقد تم استغلال فرص التحسين السهلة. وتستمر تحسينات الأجهزة، ولكن بوتيرة أبطأ. ولا تزال ابتكارات بنية النماذج تحدث، ولكن بوتيرة أقل مما كانت عليه خلال الفترة المزدهرة من 2022 إلى 2024.
يتضمن التوقع الأكثر واقعية تخفيضات سنوية تتراوح بين 3 و5 أضعاف حتى عام 2027، ثم تتضاءل تدريجياً إلى 1.5 إلى 2 ضعف سنوياً. وهذا يمثل تحسناً ملحوظاً، وإن لم يكن بالوتيرة الاستثنائية التي شهدتها السنوات الأخيرة.
سيُحفز تحدي استهلاك رموز الاستدلال الابتكارات المعمارية. وستستحوذ النماذج التي تُحقق استدلالًا قويًا مع تقليل استهلاك الرموز على حصة سوقية كبيرة. ومن المتوقع استمرار الأبحاث في آليات الاستدلال الفعّالة.
لا تزال المنافسة شرسة. وقد أحدث دخول شركة DeepSeek تغييراً جذرياً في أسعار السوق، مما أجبر الشركات القائمة على خفض أسعارها أو التميّز في جوانب أخرى. ومن المرجح أن يأتي المزيد من التغيير من مصادر غير متوقعة، مثل الشركات الناشئة ذات البنى المبتكرة أو الشركات الإقليمية ذات الهياكل الاقتصادية المختلفة.
بناء اقتصاديات الذكاء الاصطناعي المستدامة
تحتاج المنظمات التي تبني على نماذج التعلم الممتد إلى استراتيجيات فعّالة بغض النظر عن تقلبات الأسعار. وتُمكّن عدة مبادئ من تحقيق اقتصاديات مستدامة.
- أولاً، صمم النظام ليكون مرناً. تجنب تضمين تبعيات ثابتة على مزودين أو نماذج محددة. استخدم الاستدلال المجرد خلف الواجهات التي تسمح بتغيير المزودين مع تغير الظروف الاقتصادية.
- ثانيًا، قم بقياس كل شيء. قِس استهلاك الرموز، وتكلفة كل طلب، وتكلفة كل نتيجة عمل. تكتشف العديد من المؤسسات أن 20% من حالات الاستخدام تستهلك 80% من التكاليف - وبعض حالات الاستخدام عالية التكلفة لا تقدم قيمة تُذكر.
- ثالثًا، استثمر في التحسين. التقنيات التي نوقشت سابقًا - التكميم، والتخزين المؤقت، والتوجيه، والتحسين الفوري - تتراكم فوائدها بمرور الوقت. قد يبدو التحسين بمقدار الضعف متواضعًا حتى تدرك أنه يعني خفضًا في التكاليف بمقدار 50% شهريًا بعد ذلك.
- رابعًا، يجب مطابقة قدرات النموذج مع متطلبات المهمة. استخدام نماذج متقدمة لكل مهمة يُعدّ إهدارًا للمال. بينما بناء منطق تصنيفي يوجّه الطلبات بشكل مناسب يُؤتي ثماره.
- وأخيرًا، خطط لضمان شفافية استهلاك الرموز. فمشكلة الرموز المنطقية تُفاجئ الفرق عندما لا تراقب استهلاك الرموز داخليًا. ويُقدم مزودو الخدمات بشكل متزايد بيانات عن بُعد تُظهر استخدام الرموز الخفي - فاستفد منها.
الأسئلة الشائعة
كم تبلغ تكلفة الاستدلال باستخدام نموذج LLM لكل طلب؟
تتفاوت تكاليف الاستدلال في نماذج LLM بشكل كبير بناءً على حجم النموذج وتعقيد الطلب. تكلف الطلبات البسيطة للنماذج الصغيرة (من 3 إلى 7 مليارات مُعامل) أجزاءً من السنت - أي ما يقارب $0.01-0.05 لكل 1000 طلب. أما النماذج المتوسطة (من 13 إلى 70 مليار مُعامل) فتكلف $0.10-0.80 لكل 1000 طلب. بينما تكلف النماذج الكبيرة (أكثر من 175 مليار مُعامل) $2-15 لكل 1000 طلب. مع ذلك، قد تستهلك نماذج الاستدلال من 50 إلى 100 ضعف عدد الرموز المميزة التي يُشير إليها طول المُخرجات، مما يزيد التكاليف الفعلية بشكل كبير.
هل الاستضافة الذاتية أرخص من استخدام خدمات واجهة برمجة التطبيقات (API)؟
يصبح الاستضافة الذاتية أرخص من واجهات برمجة التطبيقات (APIs) عندما يتجاوز استخدام وحدة معالجة الرسومات (GPU) حوالي 50% بشكل مستمر. يتطلب هذا عادةً معالجة أكثر من 10 ملايين رمز مميز يوميًا لكل وحدة معالجة رسومات. أما دون هذا الحد، فتوفر واجهات برمجة التطبيقات عادةً جدوى اقتصادية أفضل لأنها تتجنب النفقات الرأسمالية ولا تدفع مقابل السعة غير المستخدمة. كما تتطلب الاستضافة الذاتية خبرة في عمليات التعلم الآلي وتكاليف إضافية لإدارة البنية التحتية.
لماذا تُعتبر نماذج الاستدلال باهظة الثمن؟
تُنتج نماذج الاستدلال عددًا كبيرًا من الرموز الداخلية "للتفكير" قبل إخراج النتائج. قد يستهلك ردٌّ يحتوي على 200 رمز مرئي ما بين 10,000 و30,000 رمز إجمالًا أثناء عملية الاستدلال. يُحتسب هذا الاستهلاك الداخلي للرموز ضمن التكلفة، ولكنه يبقى غير مرئي في النتائج، مما يخلق حالات تبدو فيها تكلفة الرمز الواحد منخفضة، بينما تكون التكاليف الإجمالية مرتفعة. تستهلك بعض استعلامات الاستدلال أكثر من 600 رمز لإنتاج إجابات من كلمتين.
كيف يمكنني تقليل تكاليف الاستدلال في نموذج LLM؟
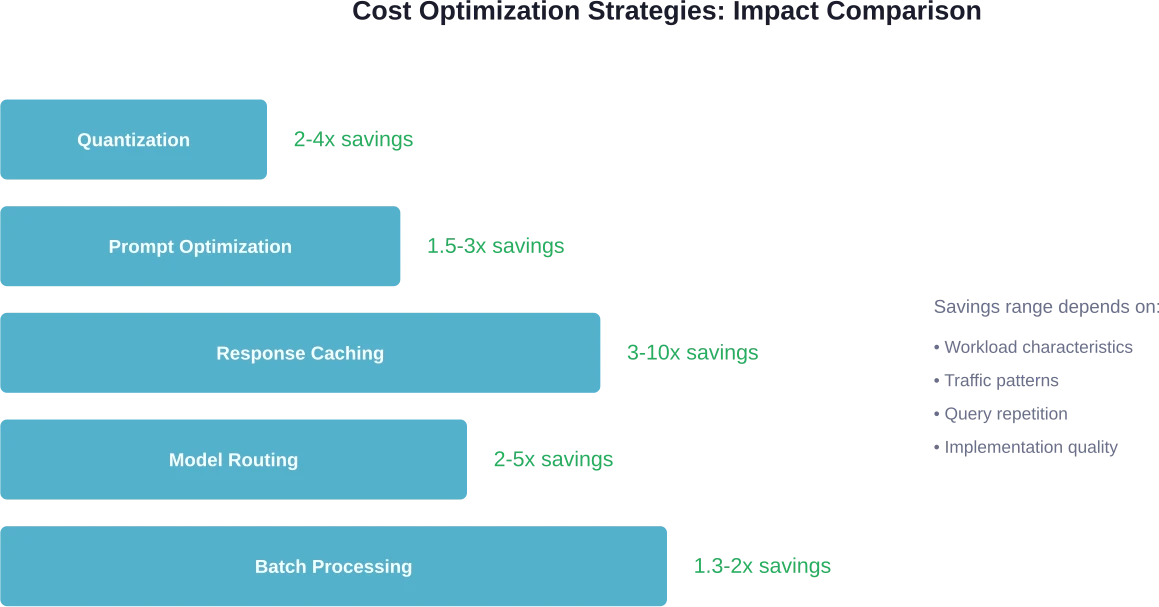
تُساهم خمس استراتيجيات رئيسية في خفض تكاليف الاستدلال: التكميم (توفير من 2 إلى 4 أضعاف)، وتخزين الاستجابات مؤقتًا للاستعلامات المتكررة (توفير من 3 إلى 10 أضعاف)، وتحسين الاستجابة الفورية لتقليل استخدام الرموز (توفير من 1.5 إلى 3 أضعاف)، وتوجيه النماذج لاستخدام نماذج أصغر للمهام البسيطة (توفير من 2 إلى 5 أضعاف)، والمعالجة الدفعية لأحمال العمل التي تتطلب إنتاجية عالية (توفير من 1.3 إلى ضعفين). وتتضاعف هذه التقنيات عند دمجها بفعالية.
ما هي التكلفة الحالية لأداء بمستوى GPT-4؟
اعتبارًا من مارس 2026، بلغت تكلفة تحقيق أداء مماثل لنموذج GPT-4 ما يقارب $0.40-0.80 لكل مليون رمز باستخدام بدائل منافسة مثل DeepSeek V3 أو نماذج متوسطة المستوى من مزودين رئيسيين. أما تكلفة GPT-4 الفعلية من OpenAI فتتراوح بين $2 و$15 لكل مليون رمز، وذلك حسب الإصدار المحدد. ويمثل هذا انخفاضًا كبيرًا مقارنةً بأواخر عام 2022، عندما كانت تكلفة الأداء المكافئ تتجاوز $20 لكل مليون رمز.
كيف تتم مقارنة تكاليف وحدات معالجة الرسومات السحابية بين مختلف مزودي الخدمة؟
استقرت أسعار وحدات معالجة الرسومات السحابية H100 عند $2.85-3.50 دولارًا أمريكيًا في الساعة لدى كبرى شركات الحوسبة السحابية اعتبارًا من أوائل عام 2026. وتقدم بعض شركات الحوسبة السحابية الإقليمية أسعارًا أقل ($2.20-2.60 دولارًا أمريكيًا في الساعة) مع اتفاقيات مستوى خدمة مخفّضة. وتُكلّف بطاقات A800، الشائعة في بعض المناطق، حوالي $0.79 دولارًا أمريكيًا في الساعة بناءً على اقتصاديات البنية التحتية. وتُقدّم تكوينات وحدات معالجة الرسومات المتعددة عادةً خصومات على الكميات تتراوح بين 10 و20%.
هل ستستمر تكاليف الاستدلال في نموذج LLM في الانخفاض؟
من المرجح أن تستمر تكاليف الاستدلال في الانخفاض، ولكن بوتيرة أبطأ من الانخفاض السنوي الذي بلغ عشرة أضعاف خلال الفترة من 2021 إلى 2025. وتشير التوقعات الواقعية إلى انخفاض سنوي يتراوح بين ثلاثة وخمسة أضعاف حتى عام 2027، ثم يتراجع إلى ما بين ضعف ونصف إلى ضعفين سنويًا مع تضاؤل فرص التحسين. وستساهم تحسينات الأجهزة والابتكارات المعمارية في استمرار هذا الانخفاض، إلا أن الوتيرة الاستثنائية التي شهدتها السنوات الأخيرة لن تستمر على الأرجح إلى أجل غير مسمى.
أهم النقاط الاستراتيجية لتطبيقات الذكاء الاصطناعي
يُعدّ فهم اقتصاديات الاستدلال في نماذج الانحدار الخطي الموجه (LLM) أكثر أهمية من أي وقت مضى. فقد تصل الفجوة بين التنفيذ البسيط والنشر الأمثل إلى 5-10 أضعاف في التكلفة، وهو ما يكفي لتحديد جدوى اقتصاديات الوحدة من الأساس.
لا يُظهر تسعير الرموز سوى جزء من الحقيقة. فإجمالي استهلاك الرموز، بما في ذلك رموز الاستدلال المخفية، هو ما يُحدد التكاليف الفعلية. لذا، يُعد رصد هذا الاستهلاك والتحكم فيه أمرًا بالغ الأهمية لضمان استدامة العمليات.
يعتمد الاختيار بين خدمات واجهة برمجة التطبيقات (API) والاستضافة الذاتية على حجم المشروع، وأنماط الاستخدام، والقدرات التنظيمية. لا يوجد خيار مثالي بشكل مطلق. لذا، حلل وضعك الخاص بدلاً من اتباع اتجاهات السوق بشكل أعمى.
تتراكم تقنيات التحسين. فالتكميم والتخزين المؤقت والهندسة الفورية وتوجيه النماذج معًا يمكن أن يقلل التكاليف بمقدار عشرة أضعاف أو أكثر مقارنةً بالتطبيقات الأساسية. ويؤدي الاستثمار في هذه التحسينات إلى عوائد مستدامة.
يستمر السوق في التطور بوتيرة متسارعة، حيث تظهر باستمرار شركات جديدة ونماذج وهياكل تسعير مبتكرة. إن بناء بنى تحتية مرنة قادرة على التكيف مع المتغيرات الاقتصادية يحمي من تضخم التكاليف وضياع الفرص المتاحة بفضل البدائل الأفضل.
بصراحة، انخفضت تكاليف الاستدلال في نماذج التعلم الآلي بشكل كبير، لكن هذا لا يعني أن البنية التحتية للذكاء الاصطناعي رخيصة. بل يعني أن الوضع الاقتصادي قد تحول من "باهظ التكلفة" إلى "قابل للإدارة مع التحسين الدقيق". الفرق التي تفهم هذا الوضع الاقتصادي وتصمم البنية التحتية وفقًا له ستتمكن من بناء شركات ذكاء اصطناعي مستدامة. أما تلك التي تتعامل مع الاستدلال كسلعة دون فهم العوامل الأساسية التي تحدد التكلفة فستواجه صعوبات.
هل أنت مستعد لتحسين تكاليف استدلال نموذج التعلم القائم على اللغة (LLM)؟ ابدأ بقياس أنماط استهلاك الرموز الحالية، بما في ذلك أي رموز استدلال مخفية. حدد حالات الاستخدام ذات التكلفة الأعلى، وقيم ما إذا كان توجيه النموذج أو تحسين المطالبات يمكن أن يقلل النفقات. قارن حجمك الحالي بعتبة التعادل للاستضافة الذاتية لتحديد ما إذا كانت ملكية البنية التحتية مجدية. ستؤثر الرؤى التي تكتسبها بشكل مباشر على أرباحك النهائية.