Résumé rapide : La collecte de données pour l'IA est le processus systématique de rassemblement, de préparation et d'organisation des ensembles de données destinés à l'entraînement et à la validation des modèles d'intelligence artificielle. Sa réussite repose sur un équilibre entre la qualité et la diversité des données, le respect de la vie privée et les considérations éthiques, tout en mettant en œuvre des cadres de gouvernance appropriés. Les organisations qui maîtrisent la collecte de données en temps réel et de haute qualité, associée à des pratiques d'IA responsables, sont en mesure de concevoir des systèmes d'IA plus précis, équitables et fiables.
Les systèmes d'intelligence artificielle dépendent entièrement des données qu'ils exploitent. Chaque réponse de chatbot, chaque correspondance de reconnaissance faciale, chaque recommandation prédictive repose sur un ingrédient fondamental : les données.
Sans données de haute qualité et correctement collectées, même les algorithmes les plus sophistiqués produisent des résultats peu fiables. Les experts du secteur insistent sur le fait que, dans un modèle d'IA, la règle est simple : si les données d'entrée sont mauvaises, les résultats le seront aussi.
Le défi ? La collecte de données pour l’IA ne se résume pas à accumuler de grands volumes d’informations. Elle exige une planification stratégique, une réflexion éthique, le respect des réglementations et un contrôle qualité continu.
Ce guide décrit l'intégralité du cycle de vie de la collecte de données, depuis la compréhension des concepts fondamentaux jusqu'à la mise en œuvre des méthodes de collecte, en passant par l'assurance qualité, la gestion des réglementations en matière de confidentialité et l'adoption des meilleures pratiques conformes aux normes de 2026.
Qu’est-ce que la collecte de données par l’IA ?
La collecte de données en intelligence artificielle englobe les méthodes, les processus et les technologies utilisés pour recueillir les informations nécessaires à l'entraînement, au test et à la validation des modèles d'apprentissage automatique. Ces données constituent le fondement sur lequel les algorithmes apprennent des schémas, font des prédictions et génèrent des résultats.
Contrairement à la collecte de données traditionnelle à des fins d'analyse ou de reporting, la collecte axée sur l'IA sert un objectif précis : créer des ensembles de données qui représentent l'espace du problème de manière suffisamment exhaustive pour qu'un modèle puisse généraliser à partir d'exemples à de nouveaux scénarios inédits.
Le processus comprend plusieurs phases distinctes. La première est l'identification : il s'agit de déterminer les données nécessaires au modèle en fonction du domaine d'application. Vient ensuite l'acquisition, où les données brutes sont collectées auprès de diverses sources. Puis, la préparation et l'annotation transforment les données brutes en formats structurés et étiquetés, exploitables par les algorithmes. Enfin, la validation garantit que l'ensemble de données répond aux normes de qualité et de représentativité.
Types de données pour les systèmes d'IA
Les différentes applications d'IA nécessitent des types de données fondamentalement différents :
- Données structuréesInformations organisées dans des bases de données, des feuilles de calcul ou des tableaux avec des champs clairement définis — enregistrements clients, journaux de transactions, relevés de capteurs.
- Données non structuréesDocuments texte, courriels, publications sur les réseaux sociaux, enregistrements audio, fichiers vidéo sans organisation prédéfinie.
- Données d'imagePhotographies, scans médicaux, images satellites, images de produits utilisées pour des tâches de vision par ordinateur.
- Données de séries chronologiquesMesures séquentielles dans le temps : cours des actions, tendances météorologiques, flux de données de capteurs IoT.
- Données comportementalesInteractions des utilisateurs, flux de clics, schémas de navigation, indicateurs d'engagement.
Chaque type requiert des approches de collecte, des normes d'annotation et une infrastructure de stockage spécifiques.

Préparez vos données à l'IA avec AI Superior
IA supérieure Cette entreprise aide les sociétés à identifier les opportunités offertes par l'IA, à évaluer les ensembles de données disponibles et à vérifier la pertinence de l'apprentissage automatique avant le début du développement. Son processus comprend la phase de découverte, l'analyse des données, le développement d'un MVP, la mise à l'échelle, l'intégration et l'évaluation des résultats.
Pour les travaux de collecte de données en IA, cela peut aider les équipes à comprendre quelles données elles possèdent, quelles données manquent et comment les préparer pour un système d'IA pratique.
Besoin d'aide pour analyser vos données d'IA ?
AI Superior peut vous aider avec :
- évaluer les ensembles de données disponibles
- définition des cas d'utilisation de l'IA et du ML
- planification du développement d'une preuve de concept ou d'un MVP
- Préparation des flux de travail pour l'intégration de l'IA
👉 Contactez l'IA supérieure pour discuter de votre projet.
Pourquoi la collecte de données est essentielle à la réussite de l'IA
La qualité et les caractéristiques des données d'entraînement déterminent directement les performances du modèle. Plusieurs facteurs font de la collecte de données la pierre angulaire du développement de l'IA :
- La précision du modèle dépend de la représentativité des données. Si les données d'entraînement ne reflètent pas toute la diversité des situations réelles, le modèle présente des angles morts. Une IA entraînée principalement sur des données issues d'un seul groupe démographique sera moins performante face à d'autres groupes.
- Les biais découlent des choix de collecte des données. Des lacunes systématiques ou une surreprésentation dans les ensembles de données créent des modèles biaisés qui perpétuent ou amplifient les inégalités existantes. La Federal Trade Commission a engagé des poursuites contre des entreprises faisant des déclarations trompeuses concernant l'IA, notamment dans des cas où des données insuffisantes ont conduit à des promesses de performance mensongères.
- L'amélioration continue exige des données actualisées. Les modèles d'IA entraînés sur des ensembles de données statiques deviennent obsolètes face à l'évolution des conditions réelles. Les mécanismes de collecte de données en temps réel permettent de maintenir les modèles à jour et de les adapter aux nouvelles tendances.
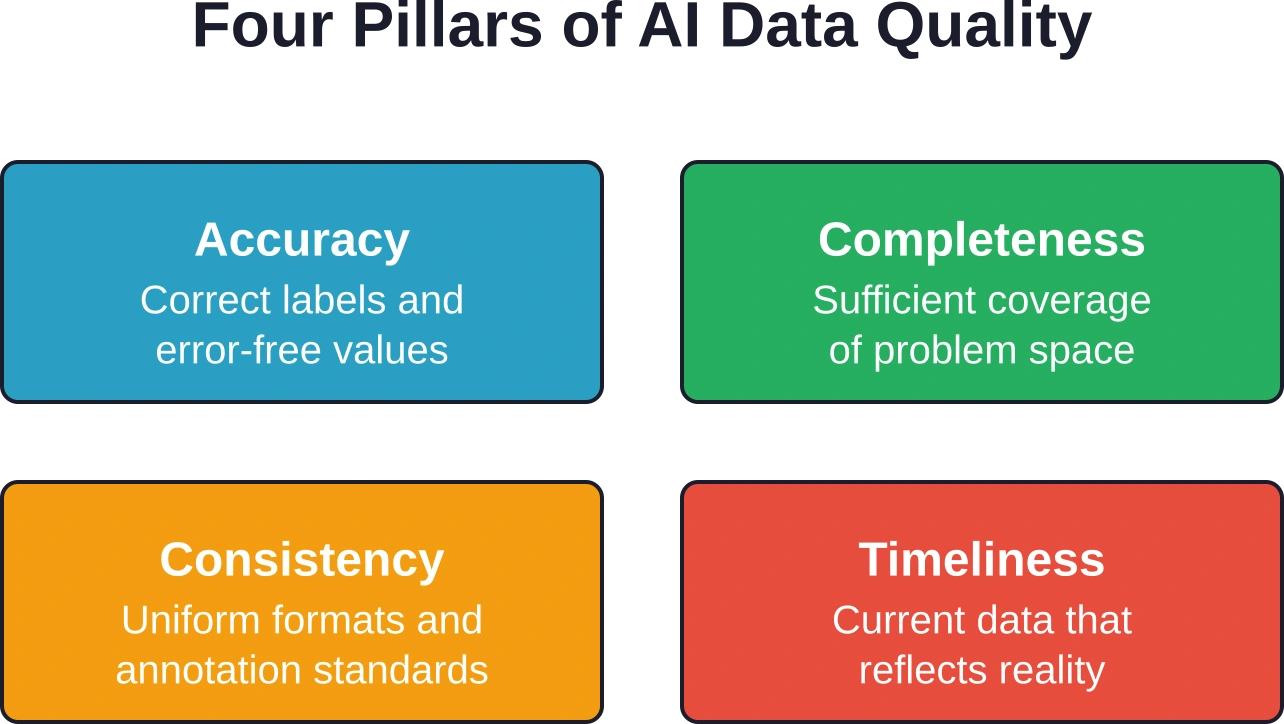
Méthodes fondamentales de collecte de données pour l'IA
Les organisations utilisent plusieurs stratégies de collecte en fonction des besoins en données, des contraintes de ressources et des domaines d'application.
Collecte de données primaires
La collecte primaire consiste à générer de nouvelles données spécifiquement pour le projet d'IA concerné. Cette approche offre un contrôle maximal sur la qualité et la pertinence des données, mais elle exige généralement plus de temps et de ressources.
- Les enquêtes et les questionnaires permettent de recueillir des informations autodéclarées directement auprès des populations cibles. Des enquêtes bien conçues peuvent révéler des attitudes, des préférences et des comportements que d'autres méthodes ne permettent pas de saisir. La principale difficulté réside dans la conception de questions qui suscitent des réponses précises et objectives, ainsi que dans l'obtention d'un échantillon représentatif.
- Les flux de données issus des capteurs et de l'Internet des objets (IoT) fournissent des mesures continues et en temps réel de l'environnement physique. Les usines déploient des capteurs pour collecter des données sur les performances de leurs équipements. Les villes intelligentes collectent des données sur le trafic, la qualité de l'air et les infrastructures. Ces flux génèrent des volumes massifs qui nécessitent des infrastructures d'ingestion et de stockage robustes.
- Les expériences contrôlées font varier systématiquement les conditions afin de recueillir des données selon des paramètres connus. Cette approche est particulièrement efficace pour l'entraînement de modèles où la vérité de terrain nécessite une définition précise : tests A/B d'interfaces, essais cliniques ou mesures de laboratoire.
- L'enregistrement des interactions utilisateur permet de visualiser comment les personnes interagissent avec les systèmes : clics, parcours de navigation, requêtes de recherche, temps passé sur les pages. Ces données comportementales révèlent des tendances souvent masquées par les préférences déclarées. Le respect de la vie privée est primordial lors de la collecte de ces données, ce qui exige des mécanismes de consentement clairs et une anonymisation rigoureuse.
Collecte de données secondaires
La collecte secondaire exploite des ensembles de données existants créés à d'autres fins. Cette approche accélère le calendrier des projets et réduit les coûts, mais offre moins de contrôle sur les caractéristiques des données.
- Les bases de données publiques offrent des données pré-collectées, souvent pré-annotées, pour les tâches d'IA courantes. Les agences gouvernementales, les instituts de recherche et les consortiums industriels gèrent des bases de données couvrant des domaines allant du traitement automatique du langage naturel à l'imagerie médicale. Des organisations comme le National Institute of Standards and Technology (NIST) fournissent des jeux de données standardisés qui facilitent le développement de l'IA et permettent l'évaluation comparative des performances des différents systèmes.
- Le web scraping extrait automatiquement des informations de sites web et de plateformes en ligne. Cette technique permet de constituer rapidement d'importants corpus de textes, d'informations sur des produits ou de contenus issus des réseaux sociaux. Toutefois, des considérations juridiques et éthiques s'imposent : les conditions d'utilisation des sites web, les protections du droit d'auteur et les réglementations relatives à la protection de la vie privée encadrent les données pouvant être extraites et leur utilisation.
- Les fournisseurs de données tiers se spécialisent dans la collecte, l'organisation et la commercialisation de jeux de données. Ils offrent un accès à des données propriétaires issues de divers secteurs : comportement des consommateurs, marchés financiers, dossiers médicaux, etc. Une vérification préalable rigoureuse est donc essentielle pour garantir la provenance des données, les méthodes de collecte et la conformité aux réglementations en vigueur.
- Les données internes de l'organisation représentent potentiellement la source secondaire la plus précieuse : bases de données clients, historiques de transactions, journaux d'exploitation, tickets d'assistance. Ces données reflètent directement les contextes d'intervention de l'IA, même si elles nécessitent souvent un nettoyage et une restructuration importants avant d'être utilisées pour l'entraînement des modèles.
Génération de données synthétiques
La création de données synthétiques utilise des algorithmes pour générer des ensembles de données artificiels qui imitent les distributions de données réelles sans contenir d'enregistrements individuels. Cette approche répond aux préoccupations en matière de confidentialité, à la rareté des données dans certains cas particuliers et au besoin d'ensembles d'entraînement parfaitement équilibrés.
Les modèles génératifs peuvent créer des images, des textes ou des données numériques réalistes à partir de modèles appris sur des ensembles de données réelles plus restreints. Les environnements de simulation génèrent des données d'entraînement pour les systèmes autonomes : voitures autonomes entraînées dans des environnements virtuels avant leur déploiement dans le monde réel, robots apprenant des tâches de manipulation dans des simulateurs physiques.
Le compromis ? Les données synthétiques risquent de ne pas refléter toute la complexité et les cas particuliers du monde réel. Les modèles entraînés exclusivement sur des données synthétiques peuvent rencontrer des difficultés face aux aléas du monde réel. Il est donc recommandé de combiner des données synthétiques pour l’entraînement initial et l’augmentation des données avec des données réelles pour l’affinage et la validation.
Outils et plateformes de collecte de données
Le paysage technologique offre de nombreux outils répondant à différents besoins en matière de collecte :
| Catégorie d'outils | Principaux cas d'utilisation | Capacités clés |
|---|---|---|
| plateformes d'intégration de données | Agrégation de données provenant de sources multiples | Connecteurs API, pipelines ETL, flux de données en temps réel, transformation des données |
| Outils d'annotation | Étiquetage d'images, de textes et de vidéos pour l'apprentissage supervisé | Intégration de l'étiquetage collaboratif, des flux de travail de contrôle qualité et de l'apprentissage actif |
| frameworks de web scraping | Extraction de données à partir de sites web | Analyse HTML, rendu JavaScript, mécanismes anti-blocage, planification |
| Plateformes d'enquête | Collecte des réponses au questionnaire | Création de formulaires, logique conditionnelle, analyse des réponses, gestion de panels |
| entrepôts de données | Stockage et gestion centralisés | Stockage évolutif, requêtes SQL, contrôle d'accès, gestion des versions |
| Magasins vedettes | Gestion des fonctionnalités d'apprentissage automatique à travers les pipelines | Gestion des versions des fonctionnalités, infrastructure de service, surveillance, réutilisation entre les modèles |
Le choix de la plateforme dépend des exigences techniques, de l'infrastructure existante, de l'expertise de l'équipe et des contraintes budgétaires. Les organisations combinent souvent plusieurs outils au sein d'architectures intégrées de collecte de données plutôt que de s'appuyer sur des solutions uniques.
Garantir la qualité et la validation des données
La collecte ne représente que la première étape. Les données brutes contiennent inévitablement des erreurs, des incohérences et des lacunes qui nuisent à l'entraînement du modèle. Un contrôle qualité systématique transforme les données collectées en ressources d'entraînement fiables.
Nettoyage et prétraitement des données
Le nettoyage permet d'éliminer ou de corriger les enregistrements problématiques avant qu'ils ne contaminent les ensembles d'entraînement :
- La détection des doublons identifie et élimine les enregistrements redondants qui donneraient à certains modèles un poids disproportionné lors de l'entraînement.
- La gestion des valeurs manquantes permet de traiter les enregistrements incomplets par suppression, imputation ou signalement, selon l'étendue et le type de données manquantes.
- L'analyse des valeurs aberrantes permet de distinguer les cas limites authentiques qu'il convient de préserver des erreurs de saisie de données ou des dysfonctionnements de capteurs nécessitant leur suppression.
- La normalisation des formats garantit la cohérence des unités, des formats de date, de l'encodage du texte et des valeurs catégorielles dans l'ensemble des données.
- La réduction du bruit filtre les erreurs de mesure et les variations aléatoires qui masquent les véritables tendances sans supprimer la variabilité légitime.
Le prétraitement transforme les données nettoyées en formats optimisés pour la consommation par le modèle : normalisation, ingénierie des caractéristiques, réduction de dimensionnalité et tokenisation.
Protocoles de validation et de test
La validation confirme que les données collectées servent bien l'objectif visé. Plusieurs approches complémentaires permettent d'en avoir confiance :
- L'analyse statistique examine les distributions, les corrélations et les statistiques descriptives afin de détecter les tendances inattendues pouvant indiquer des problèmes de collecte. La comparaison des profils entre les nouveaux lots et les données de référence établies permet de repérer les problèmes potentiels.
- La validation du schéma vérifie que les données sont conformes aux structures attendues : champs obligatoires présents, types de données corrects, valeurs comprises dans des plages acceptables, intégrité référentielle maintenue.
- Les audits par échantillonnage consistent en une inspection manuelle de sous-ensembles aléatoires afin de déceler les erreurs que les contrôles automatisés ne détectent pas. Des examinateurs humains évaluent la qualité des annotations, identifient les cas ambigus et mettent en évidence les problèmes systématiques.
- Test de maintieng Une partie des données collectées est réservée exclusivement à l'évaluation du modèle. Ces ensembles de test permettent d'obtenir des estimations de performance objectives, car les modèles ne les utilisent jamais lors de l'entraînement. Le maintien d'une séparation stricte entre les données d'entraînement et de test empêche le surapprentissage et garantit une véritable capacité de généralisation des modèles.
Considérations relatives à la confidentialité, à la conformité et à l'éthique
La collecte de données pour l'IA s'inscrit dans des cadres réglementaires et éthiques complexes et de plus en plus stricts. Les organisations qui ne parviennent pas à s'y conformer s'exposent à des conséquences juridiques, à une atteinte à leur réputation et à une perte de confiance du public.
Cadres réglementaires et normes de conformité
Les organisations qui collectent, traitent ou stockent des données pour l'IA doivent respecter des règles qui varient selon le pays, le secteur d'activité et le type de données.
Le NIST a élaboré des recommandations en matière d'IA axées sur la fiabilité, la transparence et la gestion des risques, notamment son cadre de gestion des risques liés à l'IA et ses travaux de normalisation en cours. La FTC a également renforcé son attention sur les pratiques relatives aux données d'IA, en particulier en matière de transparence, de consentement, de responsabilité et d'utilisation des données clients pour l'entraînement des modèles.
Les réglementations sectorielles ajoutent une couche supplémentaire. Les données de santé peuvent relever de la loi HIPAA, les données financières des réglementations relatives à la protection et à la sécurité des consommateurs, et les dossiers scolaires de la loi FERPA. Les entreprises opérant à l'international doivent également se conformer au RGPD en Europe et aux autres cadres de gouvernance des données émergents dans le monde.
Exigences en matière de consentement et de transparence
Le consentement éclairé constitue le fondement éthique d'une collecte de données responsable. Plusieurs principes guident les pratiques de consentement :
- Le consentement éclairé exige d'expliquer clairement quelles données sont collectées, comment elles seront utilisées, qui y aura accès et pendant combien de temps elles seront conservées. Le jargon technique et la complexité juridique ne doivent pas masquer ces principes fondamentaux : les explications doivent être compréhensibles par tous.
- La limitation des finalités spécifiques implique de ne collecter des données que pour des finalités explicitement énoncées et de ne pas les réutiliser pour des projets d'IA sans lien avec ces finalités, sans consentement supplémentaire. La tentation d'exploiter davantage les données collectées doit être mise en balance avec les limites du consentement.
- Les architectures d'adhésion volontaire (opt-in) et d'exclusion volontaire (opt-out) ont des implications éthiques différentes. Les approches d'adhésion volontaire, qui exigent un consentement explicite avant la collecte de données, respectent davantage l'autonomie que les systèmes d'exclusion volontaire qui collectent les données par défaut, sauf si l'utilisateur prend des mesures pour l'empêcher.
- Le consentement révocable permet aux individus de retirer leur autorisation et de demander la suppression de leurs données. Les systèmes doivent proposer des mécanismes simples pour retirer ce consentement, plutôt que de créer des obstacles qui décourageraient l'exercice de ce droit.
Atténuation des préjugés et équité
Les choix en matière de collecte de données influencent directement la capacité des systèmes d'IA à perpétuer ou à réduire les biais sociétaux. Plusieurs stratégies contribuent à promouvoir l'équité :
- Un échantillonnage représentatif garantit que les données d'entraînement comprennent une représentation adéquate des groupes démographiques, des régions géographiques et des contextes d'utilisation pertinents. Un échantillonnage de commodité qui surreprésente les populations facilement accessibles introduit un biais.
- L’audit des biais examine les ensembles de données collectés afin de déceler les lacunes ou les distorsions systématiques avant le début de la formation. L’analyse statistique peut révéler des déséquilibres nécessitant une correction par le biais de collectes ciblées supplémentaires ou de stratégies de pondération.
- La collecte de données inclusive recherche activement les perspectives et les exemples des groupes marginalisés ou sous-représentés plutôt que de se contenter des données les plus faciles à obtenir.
- Les indicateurs d'équité permettent de quantifier si les ensembles de données et les modèles qui en résultent traitent équitablement les différents groupes selon des critères tels que la précision, les taux de faux positifs et les taux de faux négatifs. Ces indicateurs orientent les décisions quant à la nécessité de collecter des données supplémentaires pour corriger les disparités.
Directives académiques et de recherche
Les institutions de recherche ont élaboré des lignes directrices spécifiques pour une collecte responsable des données d'IA dans les contextes académiques. Le document « Considérations pour une utilisation responsable et éthique de l'IA » de Virginia Tech, publié en novembre 2025 et révisé en février 2026, traduit le cadre de référence de l'université pour une IA responsable et éthique (2025) en étapes pratiques du cycle de vie de la recherche.
Ces lignes directrices soulignent que les chercheurs ne doivent pas saisir d'informations confidentielles ou exclusives — notamment des projets de subvention, des données non publiées ou des inventions — dans des outils d'IA non approuvés par leur établissement. Ce cadre de référence aborde la provenance des données, l'attribution correcte des sources et le maintien de l'intégrité de la recherche lors de l'utilisation de l'IA pour la collecte et l'analyse des données.
L'Université Northeastern et le système universitaire de l'Illinois ont également publié des normes pour l'utilisation de l'IA dans la recherche, mettant l'accent sur les principes de conduite responsable, notamment l'honnêteté, l'exactitude, l'efficacité et l'objectivité.
Défis liés à la collecte de données en situation réelle
La théorie et la pratique divergent lorsque les organisations tentent de mettre en œuvre la collecte de données à grande échelle. Plusieurs défis récurrents se dégagent :
Gestion du volume et de la vitesse
Les applications d'IA modernes nécessitent souvent d'énormes ensembles de données. Les modèles de vision par ordinateur s'entraînent sur des millions d'images. Les grands modèles de langage consomment des milliards de mots. Les modèles de séries temporelles pour la détection d'anomalies traitent des flux continus de données de capteurs.
L'infrastructure nécessaire à l'ingestion, au traitement et au stockage de ces volumes importants met à rude épreuve les budgets et les capacités techniques. Les pipelines de données en flux continu doivent gérer des milliers, voire des millions d'événements par seconde sans perte de données. Les systèmes de stockage doivent trouver un équilibre entre vitesse d'accès, redondance et coût pour des pétaoctets d'informations.
Mais attention : plus de données ne signifie pas automatiquement de meilleurs modèles. Au-delà d’un certain seuil, l’augmentation du volume de données n’apporte que des gains de plus en plus faibles, sauf si elle contient des informations véritablement nouvelles. Une collecte stratégique qui privilégie la diversité et la qualité à la quantité pure donne souvent de meilleurs résultats avec des besoins en ressources moindres.
Goulots d'étranglement de l'étiquetage des données
L’apprentissage supervisé, qui demeure le paradigme dominant en IA, nécessite des exemples d’entraînement étiquetés. L’intervention humaine est indispensable pour annoter des images, transcrire des fichiers audio, classifier des textes ou identifier des entités. Ce travail d’annotation constitue souvent le facteur limitant dans de nombreux projets d’IA.
Les coûts d'annotation augmentent proportionnellement à la taille des jeux de données, ce qui exerce une pression budgétaire. Le contrôle qualité complexifie encore la tâche : plusieurs annotateurs doivent annoter des sous-ensembles pour évaluer le degré de concordance, et les désaccords nécessitent des procédures de résolution. Les exigences en matière d'expertise du domaine restreignent davantage le nombre d'annotateurs disponibles pour les applications spécialisées.
Plusieurs stratégies permettent de remédier aux problèmes d'étiquetage :
- L'apprentissage actif permet aux modèles d'identifier les exemples les plus informatifs pour l'étiquetage humain, réduisant ainsi les besoins totaux d'annotation.
- L'apprentissage semi-supervisé exploite de grands ensembles de données non étiquetés parallèlement à des ensembles étiquetés plus petits, en extrayant des informations des deux.
- Les plateformes de crowdsourcing répartissent les tâches d'annotation entre de vastes groupes d'annotateurs, accélérant ainsi le débit mais introduisant des défis en matière de gestion de la qualité.
- L'apprentissage par transfert utilise des modèles pré-entraînés sur des ensembles de données généraux, ce qui réduit le besoin de données étiquetées pour la spécialisation à des tâches spécifiques.
Dérive des données et dérive des concepts
L’environnement réel évolue avec le temps. Les préférences des clients changent. Les conditions du marché évoluent. Les concurrents adaptent leurs tactiques. Les catalogues de produits sont mis à jour. Les exigences réglementaires changent.
Les modèles entraînés sur des données historiques perdent progressivement de leur pertinence à mesure que les distributions qu'ils ont apprises s'éloignent de la réalité actuelle. Leurs performances se dégradent silencieusement, sauf si les systèmes de surveillance détectent cette divergence.
Pour corriger la dérive, il est nécessaire de collecter en continu des données reflétant les conditions actuelles, de mettre en place des systèmes de surveillance signalant les dégradations de performance et de réentraîner les modèles avec des données actualisées. La fréquence de ces opérations dépend de la vitesse d'évolution du domaine : certaines applications nécessitent des mises à jour quotidiennes, tandis que d'autres restent stables pendant des mois.
Compromis entre confidentialité et utilité
Les protections strictes de la vie privée, qui préservent la confidentialité des individus, peuvent parfois entrer en conflit avec l'utilité des données pour l'entraînement des modèles. Des techniques comme la confidentialité différentielle introduisent un bruit mathématique qui protège les individus, mais réduit le signal disponible pour l'apprentissage.
L'agrégation et l'anonymisation offrent des avantages en matière de protection de la vie privée, mais éliminent les structures fines que les modèles pourraient exploiter. La génération de données synthétiques préserve la confidentialité, mais peut ne pas refléter toute la complexité du monde réel.
Les organisations doivent gérer ces compromis en fonction des exigences de l'application, de leur tolérance au risque et de leurs obligations réglementaires. Dans certains cas, où les risques pour la protection de la vie privée sont élevés mais les exigences d'utilité modestes, une protection renforcée pourrait être préférable. Dans d'autres cas, où les performances du modèle ont un impact direct sur la sécurité ou les fonctions critiques, des marges de confidentialité plus restreintes pourraient être acceptées dans le respect du cadre légal.
Meilleures pratiques pour la collecte de données d'IA en 2026
Les programmes de collecte de données réussis intègrent les enseignements tirés des premiers déploiements de l'IA et des normes émergentes :
Établir des cadres de gouvernance des données
Les structures de gouvernance formelles définissent les rôles, les responsabilités et les processus liés à la collecte et à la gestion des données. Leurs principaux composants sont les suivants :
- La gestion des données attribue la propriété et la responsabilité de la qualité, de la sécurité et de la conformité des données.
- Les contrôles d'accès limitent les personnes autorisées à consulter, modifier ou exporter différents types de données en fonction de leur rôle et de leurs besoins.
- Les journaux d'audit enregistrent les accès aux données et leurs transformations afin de faciliter la vérification de la conformité et les enquêtes sur les incidents.
- Les politiques de conservation des données précisent la durée de conservation des données et le moment de leur suppression, en équilibrant l'utilité, les coûts de stockage et les principes de confidentialité.
- Les normes de documentation exigent des métadonnées décrivant la provenance des données, les méthodes de collecte, les limitations connues et les utilisations prévues.
Mettre en œuvre la surveillance de la qualité des données
L’assurance qualité ne doit pas se limiter à une validation ponctuelle lors de la collecte. Un suivi continu permet de détecter la dégradation avant qu’elle n’affecte les modèles.
- Le profilage automatisé génère des résumés statistiques des lots de données entrants et les compare à des valeurs de référence.
- La détection d'anomalies signale les schémas inhabituels pouvant indiquer des problèmes de collecte ou des changements en amont.
- Les contrôles d'exhaustivité vérifient que les volumes de données attendus arrivent dans les délais prévus, sans lacunes inexpliquées.
- La surveillance de la fraîcheur des données garantit que les flux de données fournissent des informations récentes plutôt que des instantanés obsolètes.
Prioriser les capacités de collecte en temps réel
Le traitement par lots des données historiques répond à certains besoins, mais de nombreuses applications d'IA modernes exigent une réactivité en temps réel. Les architectures de flux qui traitent les données à mesure qu'elles arrivent permettent :
- Mises à jour immédiates du modèle reflétant les conditions actuelles
- Personnalisation en temps réel basée sur le comportement récent
- Des systèmes de détection de la fraude qui repèrent les menaces avant que les dommages ne s'accumulent.
- Surveillance opérationnelle qui alerte en cas d'anomalies en quelques secondes
La mise en place d'une collecte en temps réel nécessite des investissements dans l'infrastructure de streaming, mais les avantages concurrentiels justifient souvent les coûts dans les domaines en constante évolution.
Conception pour l'explicabilité et l'auditabilité
Lorsque les systèmes d'IA prennent des décisions qui affectent les personnes (octroi de crédit, diagnostics médicaux, recommandations d'embauche), les parties prenantes exigent légitimement des explications. Les pratiques de collecte de données doivent favoriser cette explicabilité.
- Conserver des enregistrements de provenance permettant de retracer les données de formation jusqu'à leurs sources originales.
- Étapes de transformation et de prétraitement des données documentaires
- Conserver les métadonnées qui contextualisent les raisons pour lesquelles certaines données ont été incluses ou exclues.
- Permettre la reconstruction des ensembles de données exacts utilisés pour entraîner les modèles déployés
Les auditeurs, les organismes de réglementation et les chercheurs peuvent avoir besoin d'examiner les pratiques de collecte de données des années après les faits. Une documentation qui semble excessive sur le moment s'avère souvent inestimable lors des enquêtes.
Développer la collaboration interfonctionnelle
La collecte de données ne doit pas être laissée aux seules équipes d'ingénierie des données. Les programmes efficaces impliquent :
- Des experts du domaine qui comprennent quelles données sont vraiment importantes et quels cas particuliers existent
- Les data scientists qui connaissent les exigences des modèles et les préférences en matière de format de données
- Conseillers juridiques chargés d'identifier les obligations de conformité et les zones à risque
- Les examinateurs en matière d'éthique évaluent l'équité et les implications sociétales
- Les équipes de sécurité protègent les données contre les accès non autorisés ou les violations de données.
- Les chefs de produit qui relient les besoins en données aux objectifs commerciaux et à la valeur utilisateur
Des revues transversales régulières permettent de déceler les problèmes qui pourraient passer inaperçus au sein des services cloisonnés.
| Meilleures pratiques | Avantage principal | Complexité de la mise en œuvre |
|---|---|---|
| cadre de gouvernance des données | Conformité et responsabilité | Niveau moyen — nécessite l’élaboration de politiques et la formation |
| pipelines de collecte en temps réel | Données actuelles pour les modèles réactifs | Investissements importants dans les infrastructures de streaming – forte demande |
| Surveillance automatisée de la qualité | Détection précoce des problèmes | Niveau moyen — nécessite un outillage et l'établissement d'une base de référence |
| Documentation complète | Auditabilité et reproductibilité | Faible – principalement discipline de processus |
| Collaboration interfonctionnelle | Évaluation holistique des risques | Faible coordination organisationnelle |
| Techniques de préservation de la vie privée | Conformité réglementaire et confiance | Moyen à élevé — cela dépend de la technique |
Perspectives d'avenir : Tendances futures en matière de collecte de données d'IA
Plusieurs tendances émergentes façonneront les pratiques de collecte de données dans les années à venir :
Apprentissage fédéré et collection décentralisée
Les approches traditionnelles centralisent les données dans des référentiels où les modèles sont entraînés. L'apprentissage fédéré inverse ce principe : les modèles se déplacent vers l'emplacement des données, s'entraînent localement et ne partagent que les paramètres appris plutôt que les données brutes.
Cette architecture répond aux préoccupations en matière de confidentialité en maintenant les données sensibles au sein de l'organisation ou de l'appareil. Les établissements médicaux peuvent collaborer au développement de modèles sans partager les dossiers des patients. Les appareils mobiles peuvent améliorer la personnalisation sans télécharger les données comportementales des utilisateurs.
Des défis subsistent quant à la complexité de la coordination, aux coûts de communication et à la sécurité du processus d'agrégation. Toutefois, les avantages en matière de protection de la vie privée rendent les approches fédérées de plus en plus attrayantes à mesure que la réglementation se durcit.
Méthodes d'auto-supervision et de non-supervision
Réduire la dépendance aux données étiquetées représente un axe de recherche majeur. L'apprentissage auto-supervisé génère des signaux d'entraînement à partir de la structure même des données : prédiction de mots masqués dans un texte, reconstruction d'images corrompues, prévision des images suivantes dans des séquences vidéo.
Ces approches réduisent considérablement les coûts d'étiquetage tout en exploitant d'immenses ensembles de données non étiquetées. À mesure que les techniques d'apprentissage auto-supervisé se perfectionnent, les stratégies de collecte privilégieront la collecte à grande échelle de données brutes et diversifiées plutôt qu'un étiquetage exhaustif.
Intégration de données multimodales
La compréhension du monde réel nécessite souvent de combiner des informations issues de différentes modalités : images et légendes, vidéo et audio, données de capteurs et métadonnées contextuelles. Les modèles qui traitent des entrées multimodales peuvent élaborer des représentations plus riches que les systèmes unimodaux.
Les stratégies de collecte privilégient de plus en plus le regroupement d'ensembles de données multimodaux cohérents, où différents types de données correspondent aux mêmes entités ou événements. La complexité de l'infrastructure augmente, mais les capacités des modèles progressent en conséquence.
Systèmes d'apprentissage continu
Les cycles statiques d'entraînement et de déploiement cèdent la place à l'apprentissage continu, où les modèles se mettent à jour en permanence au fur et à mesure de l'arrivée de nouvelles données. Cette approche garantit la mise à jour des modèles, mais soulève des problèmes de stabilité, d'oubli catastrophique et de contrôle qualité.
La collecte de données pour l'apprentissage continu met l'accent sur l'ingestion en flux continu, la validation rapide et les mécanismes permettant de détecter quand les nouvelles données dégradent plutôt qu'elles n'améliorent les performances du modèle.
Questions fréquemment posées
Quelle est la différence entre la collecte de données pour l'IA et l'analyse traditionnelle ?
La collecte de données analytiques traditionnelles vise à recueillir des informations destinées à l'analyse humaine, à la production de rapports et à l'informatique décisionnelle. La collecte de données pour l'IA poursuit un objectif différent : créer des ensembles d'entraînement permettant aux algorithmes de reconnaître des tendances et d'effectuer des prédictions. Les ensembles de données pour l'IA requièrent des caractéristiques spécifiques : des volumes plus importants, une plus grande diversité d'exemples couvrant les cas limites, un étiquetage précis pour l'apprentissage supervisé et une représentativité de l'ensemble du problème. L'analyse traditionnelle peut se contenter d'un échantillonnage permettant de saisir les tendances centrales ; l'entraînement des algorithmes d'IA exige une couverture exhaustive, incluant les scénarios rares que le modèle pourrait rencontrer.
De combien de données ai-je réellement besoin pour entraîner un modèle d'IA ?
Il n'existe pas de solution universelle : les besoins varient considérablement selon la complexité du problème, l'architecture du modèle et les objectifs de performance. Des tâches de classification simples, avec des frontières de décision claires, peuvent donner de bons résultats avec quelques centaines d'exemples étiquetés. Les modèles de vision par ordinateur nécessitent généralement des milliers, voire des millions d'images. Les grands modèles de langage sont entraînés sur des milliards de jetons textuels. De manière générale, les problèmes plus complexes, avec des espaces d'entrée de plus grande dimension et des frontières de décision plus nuancées, requièrent des ensembles de données plus importants. L'apprentissage par transfert et les modèles pré-entraînés peuvent réduire considérablement les besoins en données pour des applications spécifiques en tirant parti de l'apprentissage à partir d'ensembles de données généraux.
Quelles sont les principales erreurs commises par les organisations en matière de collecte de données pour l'IA ?
Les pièges courants incluent : privilégier la quantité à la qualité et collecter des ensembles de données massifs sans en garantir l’exactitude ni la pertinence ; négliger la diversité et collecter des données provenant de sources restreintes qui ne représentent pas l’ensemble du problème ; ignorer les exigences en matière de confidentialité et de conformité jusqu’à l’apparition de problèmes juridiques ; considérer la collecte de données comme un projet ponctuel plutôt que comme un processus continu ; une documentation insuffisante qui empêche les équipes futures de comprendre la provenance et les limites des données ; et une validation inadéquate qui permet l’intégration de données problématiques dans les chaînes de formation. Les organisations sous-estiment également fréquemment le temps et le coût nécessaires à l’étiquetage des données, ce qui entraîne des retards de projet lorsque l’annotation devient un goulot d’étranglement.
Puis-je utiliser des ensembles de données accessibles au public ou dois-je collecter mes propres données ?
Les deux approches présentent des avantages selon les circonstances. Les jeux de données publics permettent un démarrage de projet plus rapide, des coûts moindres et, parfois, une meilleure qualité grâce à un travail de curation spécialisé. Les référentiels académiques permettent de comparer les performances de différentes approches de modélisation. Cependant, les données publiques peuvent ne pas correspondre à la distribution spécifique, aux cas particuliers ou aux aspects propriétaires d'un domaine d'application donné. La collecte personnalisée fournit des données parfaitement adaptées au problème, mais exige davantage de ressources et de temps. De nombreux projets réussis combinent ces approches : ils commencent par utiliser des jeux de données publics pour le développement initial, puis ajoutent des données propriétaires afin de spécialiser les modèles pour des contextes de déploiement spécifiques.
Comment concilier la qualité des données, la rapidité de leur collecte et leur coût ?
Ce compromis exige une réflexion stratégique sur les seuils de qualité minimaux viables. Commencez par définir les dimensions de qualité les plus importantes pour l'application spécifique : certains cas d'utilisation requièrent une précision quasi parfaite, tandis que d'autres tolèrent des données plus bruitées si le volume compense. Mettez en œuvre une collecte par étapes, où un sous-ensemble fait l'objet d'une validation approfondie, tandis que la collecte en masse utilise des méthodes moins coûteuses avec des audits ponctuels. Tirez parti de techniques comme l'apprentissage actif pour concentrer les efforts d'étiquetage coûteux sur les exemples les plus informatifs. Envisagez des approches progressives, où les modèles initiaux sont entraînés sur des ensembles de données plus petits et de haute qualité, puis étendus à des ensembles plus grands et plus bruités une fois les performances de base établies. Surveillez les indicateurs de performance du modèle pour déterminer quand les problèmes de qualité ont un impact réel sur les résultats et quand ils restent des préoccupations théoriques.
Quel rôle jouent les données synthétiques dans l'entraînement de l'IA ?
Les données synthétiques remplissent plusieurs fonctions essentielles dans la collecte de données. Elles répondent aux préoccupations relatives à la protection de la vie privée en générant des enregistrements artificiels qui préservent les propriétés statistiques sans contenir d'informations individuelles réelles. La génération synthétique contribue à gérer le déséquilibre des classes en créant des exemples supplémentaires de scénarios rares. Les environnements de simulation produisent des données d'entraînement synthétiques pour les systèmes autonomes, pour lesquels la collecte de données réelles serait dangereuse, coûteuse ou trop longue. Leurs limites ? Les données synthétiques peuvent ne pas refléter toute la complexité du monde réel, et les modèles entraînés uniquement sur des données synthétiques peuvent avoir des difficultés à s'adapter aux variations de distribution lors de leur déploiement. Les bonnes pratiques combinent généralement les données synthétiques pour l'entraînement initial, l'augmentation des données ou l'équilibrage, avec des données réelles pour la validation et l'ajustement fin.
Comment gérer la collecte de données pour l'IA dans les secteurs réglementés ?
Les secteurs réglementés (santé, finance, éducation, administration publique) sont soumis à des exigences de conformité supplémentaires, au-delà des lois générales sur la protection des données. Commencez par identifier toutes les réglementations applicables aux types de données et aux juridictions concernées. Faites appel à des conseillers juridiques et des spécialistes de la conformité dès le début de la planification du projet, et non après coup. Mettez en œuvre des contrôles techniques tels que le chiffrement, les restrictions d'accès, la journalisation des audits et la minimisation des données. Obtenez un consentement éclairé, accompagné d'explications claires sur l'utilisation de l'IA. Envisagez des techniques de protection de la vie privée comme la confidentialité différentielle, l'apprentissage fédéré ou la génération de données synthétiques, afin de réduire les risques réglementaires. Documentez rigoureusement tous les processus de collecte, les flux de données et les mesures de conformité. Les cadres réglementaires évoluent constamment (normes NIST, recommandations de la FTC et réglementations spécifiques aux agences) ; il est donc essentiel de mettre en place des processus de surveillance permettant de suivre les mises à jour pertinentes ayant une incidence sur les pratiques de collecte de données.
Concevoir des systèmes d'IA sur des bases de données solides
La collecte de données pourrait sembler se limiter à un simple travail d'infrastructure, une simple installation technique qui soutient le développement passionnant du modèle en aval. Cette vision occulte une vérité fondamentale : aucune sophistication algorithmique ne saurait compenser des données d'entraînement insuffisantes.
Les organisations qui conçoivent les systèmes d'IA les plus performants et les plus fiables savent que la collecte de données exige une approche stratégique, des ressources considérables et une amélioration continue. Elles mettent en place des cadres de gouvernance qui concilient innovation et responsabilité. Elles investissent dans l'assurance qualité afin de détecter les problèmes au plus tôt. Elles conçoivent des architectures de collecte adaptables à l'évolution des besoins.
Dans ce contexte, la réussite repose sur la valorisation de la collecte de données comme une compétence fondamentale et non comme une simple tâche. Les aspects techniques sont essentiels : choix des méthodes de collecte appropriées, mise en place de processus robustes et validation systématique de la qualité. Mais les dimensions organisationnelles et éthiques le sont tout autant : collaboration interfonctionnelle, transparence des pratiques, protection de la vie privée, atténuation des biais et rigueur en matière de conformité.
Les modèles d'IA qui font la une des journaux représentent les résultats visibles. Les processus de collecte de données qui sous-tendent ces modèles restent largement invisibles pour les utilisateurs finaux. Pourtant, ces pratiques de collecte occultes déterminent en fin de compte si les systèmes d'IA apportent une réelle valeur ajoutée ou créent des problèmes : s'ils développent les capacités ou amplifient les biais, s'ils respectent la vie privée ou l'exploitent, s'ils inspirent confiance ou l'érodent.
Les organisations qui se lancent dans des initiatives d'IA devraient investir autant dans la planification stratégique de la collecte de données que dans le choix de l'architecture du modèle. Il est essentiel de développer des capacités de collecte évolutives, d'établir des normes de qualité rigoureuses, de mettre en place une gouvernance protectrice et de documenter les pratiques afin qu'elles résistent à tout examen critique.
Commencez par les données. Faites-le correctement. Tout le reste en découlera.