Résumé rapide : Les cas d'utilisation du Big Data s'étendent à des secteurs aussi variés que la santé, la finance, le commerce de détail, l'industrie et l'administration publique. Ils permettent aux organisations de détecter les fraudes, de personnaliser l'expérience client, d'optimiser leurs chaînes d'approvisionnement et d'améliorer leur prise de décision. En analysant d'immenses volumes de données en temps réel, les entreprises acquièrent un avantage concurrentiel grâce à l'analyse prédictive, à la compréhension des comportements et à des gains d'efficacité opérationnelle que les systèmes de données traditionnels ne peuvent offrir.
Le big data n'est plus un simple mot à la mode. C'est le moteur des décisions prises par les organisations qui surpassent constamment leurs concurrents.
Les chiffres le confirment. Selon une étude citée dans de nombreuses analyses sectorielles, les entreprises qui prennent des décisions fondées sur les données ont plus de chances d'atteindre leurs objectifs de chiffre d'affaires que celles qui ne le font pas. Les organisations axées sur les données génèrent, en moyenne, une croissance de plus de 300 000 $ par an.
Mais concrètement, à quoi cela ressemble-t-il ?
C’est précisément le sujet de cet article : des mises en œuvre concrètes, des cas d’usage spécifiques et des résultats mesurables obtenus par des organisations qui ont transformé des ensembles de données massifs et complexes en atouts stratégiques.
Comprendre les cas d'utilisation du Big Data
Les cas d'usage du Big Data désignent des situations spécifiques où les organisations collectent, traitent et analysent d'importants volumes de données pour accomplir des tâches et atteindre des objectifs. Il ne s'agit pas d'exercices théoriques, mais d'applications concrètes permettant de résoudre de véritables problèmes d'entreprise.
Selon le National Institute of Standards and Technology (NIST), le terme « big data » désigne l'immense quantité de données présentes dans un monde interconnecté, numérisé, hyperconnecté et axé sur l'information. Le volume seul ne suffit pas à le définir. Ce qui importe, c'est l'usage que les organisations font de ces données.
Les caractéristiques déterminantes se retrouvent dans ce que les professionnels du secteur appellent les « V » du big data : volume, vélocité, variété, véracité et valeur. Certains cadres d’analyse ajoutent la variabilité comme sixième dimension.
Le hic, c'est que ces caractéristiques créent à la fois des opportunités et des défis. La même rapidité qui permet la détection des fraudes en temps réel exige également une infrastructure capable de traiter des millions de transactions par seconde. La diversité qui enrichit les profils clients nécessite quant à elle des systèmes capables de gérer à la fois des bases de données structurées et des publications non structurées sur les réseaux sociaux.
Les organisations qui réussissent avec le big data se concentrent sur des cas d'usage spécifiques plutôt que de tenter de tout analyser en profondeur. Elles identifient les problèmes commerciaux pour lesquels l'analyse de données à grande échelle apporte une valeur ajoutée mesurable, puis développent les capacités techniques et organisationnelles nécessaires à sa mise en œuvre.
Cas d'utilisation du Big Data dans le secteur de la santé
Le secteur de la santé génère quotidiennement une quantité massive de données : dossiers médicaux électroniques, imagerie médicale, demandes de remboursement d’assurance, enquêtes auprès des patients, dispositifs portables, données génomiques et recherche pharmaceutique. Le défi a toujours consisté à transformer ce flot d’informations en de meilleurs résultats pour les patients.
Cela change rapidement.
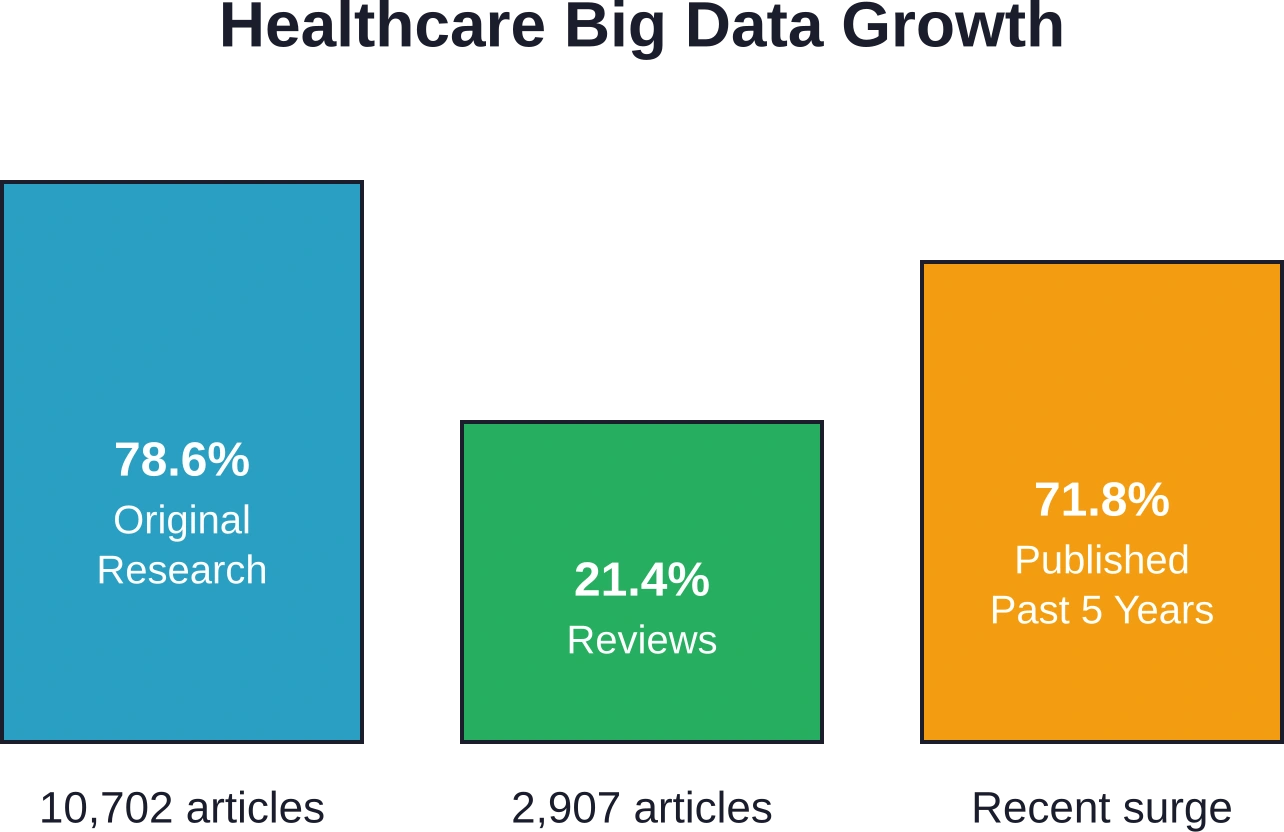
Une analyse bibliométrique publiée dans des bases de données de recherche médicale a examiné 13 609 articles sur les applications du big data dans le secteur médical. Cette étude a révélé que 10 702 articles (78,61 %) étaient des recherches originales, tandis que 2 907 (21,41 %) étaient des revues de la littérature. Il est à noter que 71,81 % de ces publications ont été réalisées au cours des cinq dernières années, témoignant d'une croissance exponentielle récente de l'adoption de l'analyse des données de santé.
Des articles scientifiques sur les applications des technologies du big data dans le secteur médical ont été publiés depuis 2009, mais leur développement s'est accéléré beaucoup plus récemment. Les États-Unis arrivent en tête avec 4 053 publications, suivis par la Chine avec 3 184 articles.
Analyse prédictive pour les soins aux patients
Les professionnels de santé utilisent l'analyse des mégadonnées pour prédire l'aggravation de l'état des patients avant qu'elle ne devienne critique. En analysant les signes vitaux, les résultats de laboratoire, les dossiers médicamenteux et les antécédents de milliers de patients, les modèles prédictifs identifient les signes avant-coureurs qui pourraient échapper aux cliniciens.
Cette approche favorise une prise de décision fondée sur des données probantes et axée sur les résultats dans la pratique clinique. L'analyse des données en santé permet d'identifier des tendances, d'améliorer la prise en charge des patients et d'accroître l'efficacité du système.
Gestion des opérations et des ressources en soins de santé
Une étude menée par le Centre de recherche et d'expertise de l'Université d'économie de Katowice a examiné l'adoption du big data par les établissements de santé. Il en ressort que 23,51 milliards de livres sterling des établissements interrogés étaient financés par des fonds publics (Fonds national de santé), 11,51 milliards de livres sterling fonctionnaient de manière commerciale et 64,91 milliards de livres sterling bénéficiaient d'un financement hybride, public et commercial.
La répartition par taille des entités a révélé que 34% étaient des entreprises de taille moyenne (10 à 50 employés) et 27% des grandes entreprises (51 à 250 employés). Ces organisations utilisent le Big Data pour optimiser leurs effectifs, réduire les temps d'attente et améliorer l'allocation des ressources entre leurs différents sites.
Recherche médicale et développement de médicaments
Les entreprises pharmaceutiques analysent les données génomiques, les résultats des essais cliniques et les données cliniques réelles afin d'accélérer la découverte et le développement de médicaments. Ce qui prenait auparavant des années peut désormais se faire en quelques mois grâce à l'identification de tendances parmi des millions de points de données.
Le Big Data permet aux chercheurs d'identifier les populations de patients les plus susceptibles de bénéficier de traitements spécifiques, de prédire les interactions médicamenteuses indésirables et d'optimiser la conception des essais cliniques avant d'investir des millions dans leur développement.
Cas d'utilisation du Big Data dans les services financiers
Les institutions financières ont été parmi les premières à adopter l'analyse des mégadonnées, et ce à juste titre. Les enjeux sont considérables, les volumes de données sont massifs et les avantages concurrentiels sont tangibles.
Soyons clairs : une seule journée de transactions sur les principales places boursières génère des téraoctets de données. Les sociétés de cartes de crédit traitent des milliards de transactions par an. Les banques conservent des décennies d’historique financier de leurs clients. C’est précisément ce volume, cette vitesse et cette variété de données qui font la force du Big Data.
Détection et prévention de la fraude
La fraude financière coûte des milliards chaque année. L'analyse des mégadonnées permet une détection instantanée en analysant les tendances de millions de transactions en temps réel.
L'analyse permet de repérer rapidement les comportements inhabituels des clients, susceptibles de révéler une fraude à la carte bancaire, un vol d'identité ou toute autre activité frauduleuse. La détection instantanée permet une intervention rapide : la société de services financiers internationale JP Morgan Chase a développé un système de détection de la fraude en temps réel qui analyse simultanément les schémas de transaction de l'ensemble de sa clientèle.
Les systèmes traditionnels basés sur des règles détectent les schémas de fraude connus. Les modèles d'apprentissage automatique entraînés sur des données massives détectent les nouveaux schémas de fraude en identifiant des anomalies subtiles que les règles ne permettent pas de repérer.
Gestion des risques et notation de crédit
Les banques utilisent le big data pour évaluer le risque de crédit avec une plus grande précision que les modèles de notation traditionnels. En analysant des milliers de variables (historique des transactions, habitudes de paiement, relations sociales, stabilité de l'emploi, voire habitudes d'utilisation des smartphones), les prêteurs peuvent mieux prédire le risque de défaut de paiement.
Cela profite à la fois aux institutions et aux consommateurs. Les banques réduisent leurs pertes liées aux défauts de paiement. Les clients solvables qui auraient pu être refusés par les systèmes d'évaluation traditionnels obtiennent un prêt.
Trading algorithmique
Les sociétés d'investissement analysent en temps réel les données de marché, les flux d'actualités, les sentiments exprimés sur les réseaux sociaux et les indicateurs économiques afin d'exécuter des transactions en quelques millisecondes. Leur avantage ne réside pas seulement dans la rapidité, mais aussi dans leur capacité à traiter simultanément des milliers de signaux et à identifier des tendances invisibles pour les traders humains.
Les sociétés de trading haute fréquence traitent les données de marché à une échelle où chaque microseconde compte. L'investissement dans l'infrastructure est considérable, mais l'avantage concurrentiel est tangible.
Personnalisation du client
Les banques analysent les données transactionnelles de leurs clients afin de personnaliser les recommandations de produits, d'optimiser la prestation de services et d'améliorer la satisfaction client. En comprenant les habitudes de consommation, les événements marquants de la vie et les objectifs financiers, les établissements peuvent proposer des produits adaptés au moment opportun.
Ce n'est pas seulement un service de qualité, c'est aussi rentable. Les offres personnalisées convertissent à des taux nettement supérieurs aux campagnes marketing génériques.
Cas d'utilisation du Big Data dans le commerce de détail
Le commerce de détail génère des données comportementales parmi les plus riches qui soient. Chaque clic, chaque achat, chaque panier abandonné raconte une histoire. Les détaillants qui savent décrypter ces histoires remportent la mise.
La transformation est manifeste. Les détaillants traditionnels peinaient à rivaliser avec les entreprises nées du numérique, précisément parce qu'ils ne pouvaient égaler la personnalisation basée sur les données offerte par les plateformes en ligne. Désormais, l'écart se réduit à mesure que les commerces physiques déploient l'analyse des mégadonnées dans l'ensemble de leurs opérations.
Analyse comportementale et connaissance client
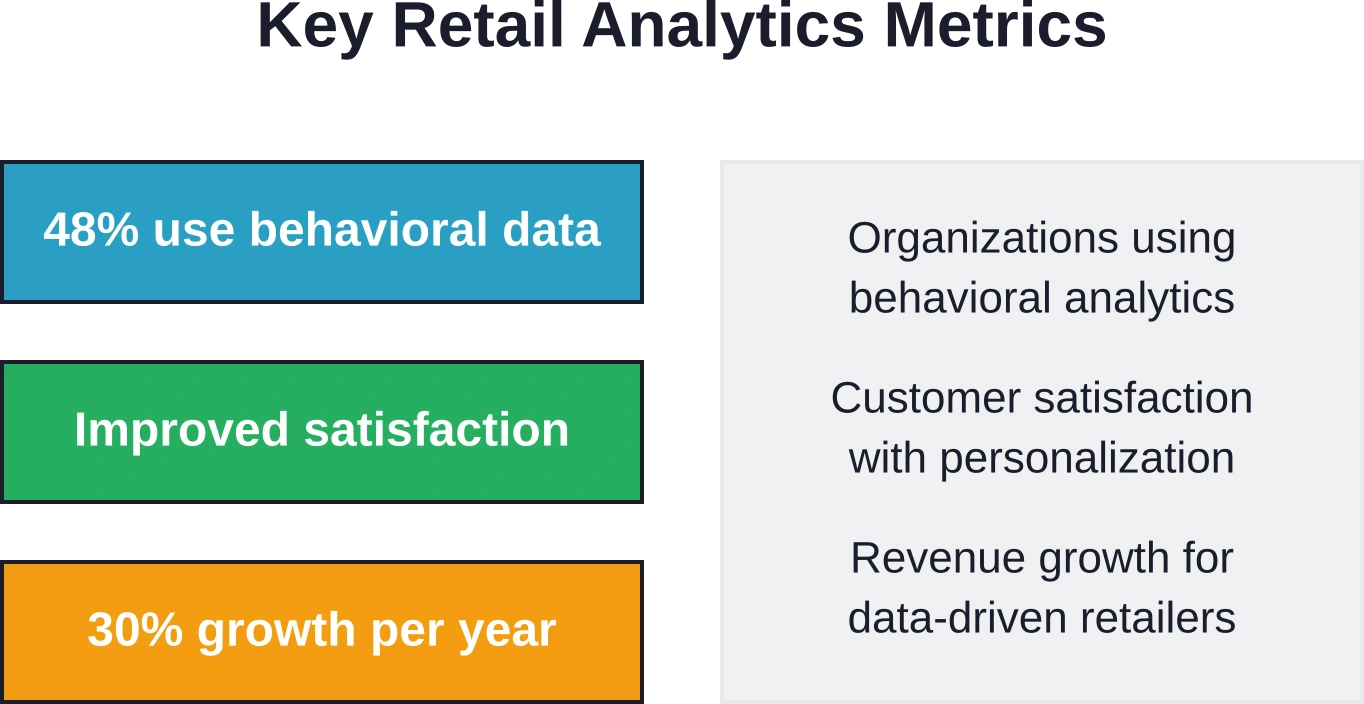
L'analyse révèle que 481 millions d'organisations utilisent le Big Data pour extraire des informations pertinentes des données comportementales de leurs clients. Ces organisations exploitent l'analyse comportementale pour générer une valeur ajoutée significative pour leurs activités.
Nordstrom constate une amélioration de la satisfaction client grâce à des expériences personnalisées basées sur l'analyse des données comportementales. Le système recommande des produits susceptibles d'intéresser les clients avant même qu'ils ne les recherchent.
Optimisation des stocks et de la chaîne d'approvisionnement
Les détaillants utilisent l'analyse prédictive pour optimiser leurs niveaux de stock sur des milliers de références et des centaines de points de vente. En analysant les données de ventes historiques, les tendances saisonnières, les prévisions météorologiques, les événements locaux et les signaux de tendance, ces systèmes prévoient la demande avec une précision remarquable.
Les avantages sont considérables. Des niveaux de stock optimaux permettent de réduire les coûts de stockage tout en minimisant les ruptures de stock qui pénalisent les ventes. L'optimisation de la chaîne d'approvisionnement étend ce principe à l'ensemble du réseau de distribution.
Tarification dynamique
Le Big Data permet aux détaillants d'ajuster leurs prix en temps réel en fonction de la demande, des prix de la concurrence, des niveaux de stock et des segments de clientèle. Les compagnies aériennes ont été pionnières dans ce domaine il y a plusieurs décennies. Aujourd'hui, cette approche se généralise à tous les secteurs du commerce de détail.
Ces systèmes analysent des millions de données pour déterminer le prix qui maximise les revenus de chaque produit à chaque instant. Bien mise en œuvre, la tarification dynamique accroît la rentabilité sans mécontenter les clients.
Agencement du magasin et marchandisage
Les détaillants analysent les flux de clients en magasin grâce à des capteurs et des caméras afin d'optimiser l'agencement de leurs points de vente. Quelles allées sont les plus fréquentées ? Où les clients s'arrêtent-ils ? Quel emplacement favorise les achats impulsifs ?
Cette approche du merchandising fondée sur les données remplace l'intuition par des preuves. Tester, mesurer, optimiser, recommencer.
Cas d'utilisation du Big Data dans le secteur manufacturier
Le secteur manufacturier génère des flux continus de données provenant de capteurs, de machines, de systèmes de contrôle qualité et de chaînes d'approvisionnement. L'Internet industriel des objets (IIoT) a considérablement amplifié cette tendance.
La transformation de General Electric illustre cette opportunité. Comme le documentent les études de cas de la MIT Sloan Management Review, GE a lancé une initiative majeure pour devenir un leader de l'Internet industriel, misant des milliards sur les données et les capacités d'analyse.
La promesse : utiliser les données pour optimiser les opérations à une échelle impossible à atteindre par les approches traditionnelles.
Maintenance prédictive
Les capteurs installés sur les équipements de production génèrent en continu des données opérationnelles : température, vibrations, pression, qualité de la production, consommation d’énergie. En analysant les tendances observées sur des milliers de machines pendant des années de fonctionnement, des modèles prédictifs identifient des signes avant-coureurs de pannes.
La proposition de valeur est simple : les arrêts de production imprévus coûtent des millions aux fabricants. La maintenance prédictive permet de passer des réparations réactives (coûteuses et perturbatrices) à une maintenance planifiée (programmée et optimisée). Il s’agit de remplacer les pièces avant qu’elles ne tombent en panne, pendant les arrêts programmés, lorsque les pièces de rechange sont disponibles.
Contrôle qualité et détection des défauts
Les systèmes de vision par ordinateur analysent les produits avec une rapidité et une précision supérieures à celles des inspecteurs humains. Les modèles d'apprentissage automatique, entraînés sur des millions d'images, détectent des défauts que les systèmes automatisés traditionnels ne parviennent pas à identifier.
Les systèmes s'améliorent en continu. Chaque défaut détecté alimente les données d'apprentissage, ce qui rend le modèle plus précis. Il en résulte des produits de meilleure qualité à moindres coûts d'inspection.
Optimisation de la chaîne d'approvisionnement et de la production
Les fabricants analysent les données de l'ensemble de leur chaîne d'approvisionnement afin d'optimiser les calendriers de production, de minimiser les stocks et de réduire les coûts. En comprenant les tendances de la demande, la fiabilité des fournisseurs, la logistique du transport et les contraintes de capacité de production, les systèmes optimisent les décisions impliquant des milliers de variables.
Ce qui nécessitait auparavant des armées d'analystes et des semaines de travail se fait désormais automatiquement, en continu, sur la base de données en temps réel.
Gestion de l'énergie
Le secteur manufacturier est énergivore. L'analyse des mégadonnées permet d'identifier les possibilités de réduire la consommation d'énergie sans compromettre la production. En analysant les profils de consommation énergétique des équipements, les calendriers de production et les conditions opérationnelles, les systèmes repèrent les inefficacités et les axes d'optimisation.
Les économies s'accumulent. Une réduction de 51 TP3T des coûts énergétiques dans une grande usine de fabrication se traduit par des millions par an.
Cas d'utilisation du Big Data dans le divertissement et les médias
Les entreprises du divertissement ont été pionnières en matière de personnalisation à grande échelle. Les algorithmes de recommandation qui suggèrent quoi regarder, quoi écouter, quoi lire – ces systèmes analysent des milliards d'interactions d'utilisateurs pour prédire leurs préférences avec une précision étonnante.
Recommandations de contenu
Les plateformes de streaming analysent les habitudes de visionnage de millions d'utilisateurs pour leur recommander du contenu. Ces systèmes ne se contentent pas de proposer des contenus par genre ; ils identifient des préférences subtiles en fonction du temps de visionnage, du taux d'achèvement, du comportement de revisionnage et de centaines d'autres indicateurs.
Il ne s'agit pas seulement d'une meilleure expérience utilisateur. Les systèmes de recommandation ont un impact direct sur la fidélisation des abonnements et la consommation de contenu, ce qui génère des revenus.
Décisions relatives à la production de contenu
Les entreprises de médias exploitent le big data pour orienter leurs décisions en matière de production de contenu. Quels genres sont en vogue ? Quels acteurs ou réalisateurs attirent le plus de téléspectateurs ? Quels éléments narratifs trouvent un écho auprès de segments spécifiques du public ?
En analysant les données de visionnage, le buzz sur les réseaux sociaux et les tendances du marché, les studios prennent des décisions plus éclairées quant aux projets à valider et à la manière de les commercialiser.
Optimisation publicitaire
Les plateformes médias analysent les données des utilisateurs pour diffuser des publicités ciblées à grande échelle. La même technologie qui recommande du contenu permet également de proposer aux utilisateurs des publicités pertinentes, ce qui accroît l'efficacité des publicités et améliore l'expérience utilisateur en affichant des publicités plus adaptées.
Les annonceurs paient des tarifs premium pour cette capacité de ciblage car elle offre des résultats nettement supérieurs à la publicité traditionnelle.
Cas d’utilisation du Big Data dans le secteur public et gouvernemental
Les organismes gouvernementaux gèrent d'immenses ensembles de données : données de recensement, dossiers fiscaux, informations sur la santé, systèmes de transport, données sur la sécurité publique, etc. Le défi a toujours consisté à transformer ces données en améliorations concrètes pour les citoyens.
Cela est en train de changer à mesure que les organisations du secteur public adoptent l'analyse des mégadonnées.
Sécurité publique et prévention du crime
Les forces de l'ordre utilisent l'analyse prédictive pour optimiser l'allocation de leurs ressources. En analysant les tendances criminelles, les variations saisonnières, le calendrier des événements et les facteurs environnementaux, ces systèmes permettent de prédire les zones à risque.
Cela permet une police proactive, en plaçant les agents aux bons endroits et aux bons moments pour prévenir les crimes plutôt que de simplement réagir après qu'ils se soient produits.
Planification des transports et de l'urbanisme
Les villes analysent les données relatives au trafic, à l'utilisation des transports en commun et aux infrastructures afin d'optimiser leurs systèmes de transport. Des capteurs installés sur les routes et les véhicules génèrent des données en temps réel qui permettent de contrôler la synchronisation des feux de circulation, la planification des itinéraires et les décisions d'investissement dans les infrastructures.
Il en résulte une réduction des embouteillages, des temps de trajet plus courts et des systèmes de transport public plus efficaces.
Surveillance de la santé publique
Les agences de santé analysent les données de santé publique pour identifier les épidémies, suivre les tendances en matière de santé publique et allouer les ressources de soins. La pandémie de COVID-19 a mis en évidence à la fois le potentiel et les défis de l'analyse des mégadonnées en santé publique.
En analysant les données de dépistage, les taux d'hospitalisation, la couverture vaccinale et les schémas de mobilité, les agences prennent des décisions plus éclairées concernant les interventions de santé publique.
Optimisation des services sociaux
Les organismes gouvernementaux utilisent l'analyse de données pour identifier les citoyens ayant besoin de services, détecter les fraudes aux programmes d'aide sociale et optimiser la prestation de ces services. En analysant les tendances issues de multiples sources de données, ils peuvent cibler plus efficacement leurs interventions et réduire le gaspillage.
| Industrie | Cas d'utilisation principal | Avantage clé | Défi de mise en œuvre |
|---|---|---|---|
| Soins de santé | Soins prédictifs aux patients | Amélioration des résultats | réglementation sur la protection des données |
| Services financiers | Détection de fraude | Prévention en temps réel | exigences de latence du système |
| Vente au détail | Analyse comportementale | Expérience personnalisée | Complexité de l'intégration des données |
| Fabrication | Maintenance prédictive | Temps d'arrêt réduit | coûts d'infrastructure des capteurs |
| Divertissement | Recommandations de contenu | Engagement accru | Transparence des algorithmes |
| Gouvernement | analyses de sécurité publique | prévention du crime | Préoccupations relatives aux préjugés et à l'équité |
Analyse marketing et ciblage client
L'analyse des mégadonnées a transformé le marketing. La possibilité de mesurer l'efficacité des campagnes, de cibler des segments de clientèle spécifiques et d'optimiser les dépenses en temps réel a modifié l'approche marketing des entreprises.
Une étude publiée par la Stanford Graduate School of Business a examiné le big data et l'analyse marketing dans le secteur des jeux. Cette étude décrit les efforts déployés pour développer, mettre en œuvre et évaluer un cadre d'analyse marketing chez MGM Resorts International à partir de données transactionnelles individuelles.
Ce cadre d'analyse s'appuie sur des modèles empiriques de la réaction des consommateurs aux actions marketing afin d'optimiser la segmentation et le ciblage. Ces modèles intègrent l'hétérogénéité des consommateurs et la dépendance à l'état du comportement dans la modélisation des choix, tout en contrôlant l'endogénéité des règles de ciblage historiques.
La recherche a démontré des améliorations substantielles de l'efficacité marketing grâce à des approches analytiques basées sur les données appliquées aux opérations réelles des casinos.
Cette étude de cas souligne l'importance d'utiliser des solutions d'analyse marketing empiriquement pertinentes pour améliorer les résultats dans des contextes réels.
Segmentation de la clientèle
Le Big Data permet une segmentation client très fine, basée sur des centaines de variables : données démographiques, historique d’achats, comportement de navigation, activité sur les réseaux sociaux, etc. Au lieu de catégories générales comme “ femmes de la génération Y ”, les entreprises peuvent identifier des micro-segments aux préférences et comportements spécifiques.
Cette précision permet un marketing personnalisé à grande échelle. Des messages, des offres et des canaux différents pour chaque segment, le tout optimisé grâce aux données et non à l'intuition.
Modélisation de l'attribution
L'attribution multi-touch analyse les parcours clients à travers des dizaines de points de contact (publicités, e-mails, réseaux sociaux, visites de sites web, visites en magasin) afin de comprendre quelles activités marketing génèrent réellement des conversions.
L'attribution traditionnelle attribuait tout le mérite au dernier clic avant l'achat. L'analyse des mégadonnées révèle une réalité plus complexe : les clients interagissent avec les marques via de multiples canaux et au fil du temps avant d'effectuer un achat. Comprendre ce parcours permet une allocation budgétaire plus judicieuse.
Optimisation de la campagne
Les spécialistes du marketing utilisent les tests A/B et les tests multivariés à grande échelle pour optimiser leurs campagnes en continu. Ils testent différents messages, images, offres et paramètres de ciblage. Ils mesurent les résultats en temps réel et misent davantage sur les stratégies performantes.
Le cycle de campagne est passé de plusieurs mois à quelques jours, voire quelques heures. Les campagnes s'améliorent en continu grâce aux données de performance, sans attendre l'analyse post-campagne.

Transformer les cas d'utilisation du Big Data en solutions d'IA opérationnelles
Le Big Data prend plus de valeur lorsque les entreprises savent ce qu'elles veulent prédire, optimiser, automatiser ou comprendre. IA supérieure Nous proposons des services de conseil en IA, des stratégies de données et d'IA, des solutions de veille stratégique, des technologies d'apprentissage automatique, des analyses prédictives et le développement de logiciels d'IA sur mesure. Dans le secteur industriel, cela peut concerner l'analyse client, le reporting opérationnel, les prévisions, la détection d'anomalies, l'analyse des processus et l'aide à la décision à partir de grands ensembles de données.
Pour les projets de mégadonnées, AI Superior peut apporter son soutien :
- Identifier les cas d'utilisation pratiques de l'IA et de l'analyse
- Élaboration de modèles prédictifs à partir de données d'entreprise
- Développement d'outils de veille stratégique et d'analyse de données
- Création de logiciels d'IA à partir d'ensembles de données volumineux ou complexes
- Connexion des résultats analytiques aux systèmes existants
👉Contactez l'IA supérieure explorer comment les cas d'utilisation du big data peuvent être transformés en solutions pratiques d'IA ou d'analyse.
Défis et considérations liés à la mise en œuvre du Big Data
Le Big Data génère une valeur mesurable. Mais sa mise en œuvre est complexe. Les organisations sont confrontées à des défis techniques, organisationnels et éthiques.
Qualité et intégration des données
Les mégadonnées ne sont utiles que si elles sont exactes. Les problèmes de qualité des données (enregistrements incomplets, formats incohérents, doublons, informations obsolètes) nuisent à l'analyse.
L'intégration complexifie encore la situation. Les organisations doivent généralement combiner des données provenant de dizaines de sources, chacune avec ses propres schémas, formats et normes de qualité. La mise en place de pipelines permettant de nettoyer, transformer et intégrer les données de manière fiable exige un investissement technique considérable.
Infrastructure technique
Le traitement des mégadonnées exige une infrastructure spécialisée. Les systèmes de bases de données traditionnels n'ont pas été conçus pour le volume, la vitesse et la variété des mégadonnées. Les organisations ont besoin de systèmes informatiques distribués, d'une infrastructure cloud, de solutions de stockage spécialisées et de plateformes d'analyse.
Le coût peut être considérable. Mais l'alternative — tenter d'effectuer des analyses de données massives sur une infrastructure traditionnelle — est vouée à l'échec.
Compétences et talents
Le Big Data exige des compétences spécialisées. Les ingénieurs de données conçoivent les pipelines. Les data scientists développent des modèles. Les analystes interprètent les résultats. Les décideurs métiers transforment les informations recueillies en décisions.
La pénurie de talents est bien réelle. Les entreprises rivalisent pour attirer des professionnels capables de maîtriser à la fois les aspects techniques du big data et le contexte commercial où il crée de la valeur.
Confidentialité et sécurité
Le Big Data contient souvent des informations sensibles : dossiers médicaux, transactions financières, comportements personnels. Les organisations doivent protéger ces données lorsqu’elles les utilisent à des fins d’analyse.
Des réglementations comme le RGPD et la loi HIPAA imposent des exigences strictes. Les violations sont passibles de sanctions importantes. Les failles de sécurité nuisent à la réputation et à la confiance des clients.
Les organisations ont besoin de contrôles techniques, de processus de gouvernance et d'une culture organisationnelle qui privilégient la confidentialité et la sécurité.
Biais et équité
Les modèles d'apprentissage automatique entraînés sur des données historiques peuvent perpétuer ou amplifier les biais existants. Si les données historiques sur les prêts révèlent des pratiques discriminatoires, les modèles entraînés sur ces données apprendront à discriminer.
Il ne s'agit pas seulement d'un problème éthique, mais aussi d'un risque commercial et juridique. Les organisations ont besoin de processus pour identifier et atténuer les biais dans leurs données et leurs modèles.
Changement organisationnel
Devenir une organisation axée sur les données exige un changement culturel. Les décisions autrefois fondées sur l'intuition, l'expérience ou des considérations politiques doivent désormais s'appuyer sur des preuves. Cela représente un bouleversement pour les organisations habituées aux processus décisionnels traditionnels.
Le soutien de la direction est essentiel. Mais l'éducation, les incitations et les processus qui intègrent la prise de décision fondée sur les données dans les opérations quotidiennes le sont tout autant.
| Défi | Impact | Stratégie d'atténuation |
|---|---|---|
| Problèmes de qualité des données | Informations inexactes | Pipelines automatisés de validation et de nettoyage |
| coûts d'infrastructure | Investissement initial élevé | Plateformes cloud avec tarification à l'usage |
| Pénurie de talents | retards de mise en œuvre | programmes de formation et services gérés |
| Règlement sur la protection de la vie privée | Risque de non-conformité | Protection de la vie privée dès la conception et cadres de gouvernance |
| Biais algorithmique | Résultats injustes | Tests de biais et données d'entraînement diversifiées |
| résistance culturelle | Faible adoption | Parrainage exécutif et gestion du changement |
Premiers pas avec le Big Data
Les organisations n'ont pas besoin de se lancer dans des projets pharaoniques. Les initiatives Big Data les plus réussies commencent modestement, prouvent leur valeur, puis s'étendent à grande échelle.
Identifier les cas d'utilisation à forte valeur ajoutée
Commencez par identifier les problèmes commerciaux pour lesquels l'analyse des données peut apporter une valeur ajoutée mesurable. Privilégiez les problèmes pour lesquels l'organisation collecte déjà des données pertinentes ou peut les collecter facilement.
Les meilleurs projets initiaux se caractérisent par des indicateurs de réussite clairs, un périmètre maîtrisable et le soutien de la direction. Mieux vaut d'abord obtenir ces résultats, puis s'attaquer aux problèmes plus complexes.
Évaluer la disponibilité des données
De quelles données l'organisation dispose-t-elle déjà ? Dans quel état sont-elles ? Quelles sont les lacunes ? L'inventaire et l'évaluation de la qualité des données permettent d'éviter les mauvaises surprises.
Les organisations découvrent souvent qu'elles possèdent plus de données qu'elles ne le pensaient. Le défi consiste à les rendre accessibles et exploitables.
Développer ou acquérir des compétences
Les organisations peuvent développer en interne leurs capacités en matière de mégadonnées, recourir à des services gérés ou adopter des approches hybrides. Le choix le plus approprié dépend de leur maturité technique, de leur budget et de l'importance stratégique du traitement.
De nombreuses organisations optent pour des plateformes cloud qui fournissent l'infrastructure et les outils nécessaires sans exiger d'investissement initial important. Cela facilite l'accès au marché et permet une expérimentation plus rapide.
Commencez par des projets pilotes
Les projets pilotes permettent de tester des hypothèses et de démontrer leur intérêt avant de s'engager dans une mise en œuvre à grande échelle. Choisissez un problème bien délimité, appliquez des méthodes d'analyse et mesurez les résultats.
Tirez les leçons des projets pilotes. Qu'est-ce qui a fonctionné ? Qu'est-ce qui n'a pas fonctionné ? Qu'est-ce qui vous a surpris ? Utilisez ces enseignements pour affiner votre approche avant de passer à l'échelle supérieure.
Développez ce qui fonctionne
Une fois que les projets pilotes auront démontré leur efficacité, il faudra généraliser les approches qui ont fait leurs preuves. Il convient de mettre en place l'infrastructure, les processus et les capacités organisationnelles nécessaires pour que la prise de décision fondée sur les données devienne une pratique courante et non exceptionnelle.
C’est là que la valeur cumulative se révèle. Un seul projet d’analyse réussi apporte de la valeur. Une douzaine en apportent davantage. Une organisation où les décisions fondées sur les données sont la norme transforme ses performances.
Tendances futures du Big Data
Le Big Data continue d'évoluer rapidement. Plusieurs tendances façonnent la prochaine génération de cas d'utilisation.
Analyse en temps réel
Le délai entre la collecte des données et leur interprétation ne cesse de se réduire. L'analyse en temps réel permet des réponses immédiates : détection des fraudes en quelques millisecondes, tarification dynamique mise à jour en continu, alertes de maintenance prédictive pour prévenir les pannes.
Les infrastructures et les algorithmes qui prennent en charge le traitement en temps réel à grande échelle permettent de réaliser des cas d'utilisation impossibles avec le traitement par lots.
Informatique de pointe
Le traitement des données au plus près de leur lieu de production réduit la latence et les coûts de bande passante. Au lieu d'envoyer toutes les données des capteurs vers des systèmes cloud centralisés, les dispositifs périphériques effectuent un prétraitement et n'envoient que les informations pertinentes.
Cela a son importance pour les cas d'utilisation où les millisecondes comptent : véhicules autonomes, automatisation industrielle, dispositifs médicaux.
Intégration de l'IA et de l'apprentissage automatique
Les modèles d'apprentissage automatique deviennent des composantes essentielles des systèmes de mégadonnées. Leur combinaison est puissante : les mégadonnées fournissent les données d'entraînement et les entrées en temps réel nécessaires à l'apprentissage automatique, tandis que ce dernier extrait des informations pertinentes à des échelles inaccessibles aux analystes humains.
À mesure que les capacités de l'IA progressent, la frontière entre l'analyse des mégadonnées et l'intelligence artificielle s'estompe. Elles deviennent des compétences intégrées plutôt que des disciplines distinctes.
Analyses respectueuses de la vie privée
Des techniques comme la confidentialité différentielle, l'apprentissage fédéré et le calcul multipartite sécurisé permettent d'analyser des données sensibles sans exposer les enregistrements individuels. Cela ouvre la voie à des cas d'utilisation auparavant bloqués par des préoccupations liées à la protection de la vie privée.
Les secteurs de la santé, des services financiers et gouvernemental bénéficient particulièrement des approches analytiques qui préservent la confidentialité tout en extrayant des informations pertinentes.
Questions fréquemment posées
Quels sont les cas d'utilisation les plus courants du big data ?
Les cas d'utilisation les plus courants du Big Data incluent la détection des fraudes dans les services financiers, la maintenance prédictive dans l'industrie manufacturière, l'analyse du comportement client dans le commerce de détail, les recommandations personnalisées dans le divertissement et l'optimisation des soins aux patients dans le secteur de la santé. Ces cas d'utilisation ont en commun des caractéristiques importantes : des volumes de données considérables, la nécessité d'un traitement en temps réel ou quasi réel et une valeur ajoutée mesurable pour l'entreprise grâce à une meilleure prise de décision.
Comment les entreprises mesurent-elles le retour sur investissement de leurs initiatives en matière de mégadonnées ?
Les entreprises mesurent le retour sur investissement du Big Data grâce à des indicateurs liés à des résultats commerciaux précis. Les services financiers suivent les pertes dues à la fraude évitées et la réduction des faux positifs. Les détaillants mesurent l'augmentation des taux de conversion et la valeur vie client. Les fabricants suivent la réduction des temps d'arrêt et des coûts de maintenance. Une étude menée chez MGM Resorts a démontré des améliorations substantielles de l'efficacité marketing grâce à des approches analytiques basées sur les données.
Quelle est la différence entre l'analyse des mégadonnées et l'analyse traditionnelle ?
L'analyse traditionnelle traite généralement des données structurées provenant de sources limitées à l'aide d'outils de bases de données et de méthodes statistiques standard. L'analyse du Big Data, quant à elle, gère des volumes massifs de données structurées et non structurées issues de sources diverses, souvent en temps réel, grâce à des systèmes informatiques distribués et des algorithmes d'apprentissage automatique avancés. L'échelle, la vitesse et la variété des données traitées diffèrent fondamentalement, permettant ainsi d'obtenir des informations impossibles à exploiter avec les approches traditionnelles.
Quels sont les secteurs qui tirent le plus profit du big data ?
Les secteurs de la santé, des services financiers, du commerce de détail, de l'industrie et du divertissement tirent des avantages considérables du big data. Des études montrent que 13 609 articles ont été publiés sur le big data dans le seul secteur médical, dont 71,81 milliards de publications au cours des cinq dernières années. Les services financiers utilisent le big data pour la détection des fraudes et la gestion des risques. Le commerce de détail l'applique à la personnalisation et à l'optimisation de la chaîne d'approvisionnement. L'industrie manufacturière l'utilise pour la maintenance prédictive. Le secteur du divertissement s'en sert pour les recommandations de contenu.
Quels sont les principaux défis liés à la mise en œuvre du big data ?
Les organisations sont confrontées à plusieurs défis majeurs : problèmes de qualité et d’intégration des données provenant de sources disparates, coûts d’infrastructure importants pour les systèmes informatiques et de stockage spécialisés, pénurie de talents dans les domaines de la science et de l’ingénierie des données, préoccupations liées à la confidentialité et à la sécurité des données sensibles, biais algorithmiques susceptibles de perpétuer la discrimination et résistance organisationnelle à la prise de décision fondée sur les données. Les mises en œuvre réussies permettent de surmonter ces difficultés grâce à une planification, une gouvernance et une gestion du changement appropriées.
Les petites entreprises ont-elles besoin du big data ?
Les petites entreprises peuvent tirer profit des principes de l'analyse de données, même sans infrastructure de grande envergure dédiée au “ big data ”. L'important n'est pas le volume de données, mais plutôt la capacité des informations issues de ces données à créer un avantage concurrentiel. Des études montrent que 581 000 entreprises qui prennent des décisions basées sur les données ont plus de chances d'atteindre leurs objectifs de chiffre d'affaires. Les petites entreprises peuvent commencer par des plateformes d'analyse dans le cloud, qui ne nécessitent pas d'investissements massifs, et se concentrer sur des cas d'usage à forte valeur ajoutée, comme la segmentation client ou l'optimisation des stocks.
Quelles sont les compétences techniques nécessaires pour les projets de big data ?
Les projets de mégadonnées requièrent des compétences techniques variées, notamment en ingénierie des données (construction de pipelines, gestion de l'infrastructure), en science des données (analyse statistique, développement de modèles d'apprentissage automatique), en administration de bases de données (gestion des systèmes distribués) et en génie logiciel (intégration de l'analyse dans les applications). Les compétences en analyse métier permettent de transformer les connaissances techniques en recommandations concrètes. La plupart des projets réussis privilégient le travail en équipes pluridisciplinaires plutôt que d'attendre d'une seule personne la maîtrise de toutes les compétences.
Conclusion
Les cas d'utilisation du Big Data sont présents dans tous les grands secteurs d'activité, offrant des avantages concurrentiels mesurables aux organisations qui les mettent en œuvre efficacement. De l'analyse des données de santé améliorant les résultats pour les patients aux services financiers détectant les fraudes en temps réel, des détaillants personnalisant l'expérience client aux fabricants prévenant les pannes d'équipement, ces applications ont fait leurs preuves et leurs résultats sont quantifiables.
Les données confirment les tendances. Les entreprises qui prennent des décisions basées sur les données ont 581 % de chances supplémentaires d'atteindre leurs objectifs de chiffre d'affaires. Les organisations axées sur les données génèrent en moyenne une croissance de plus de 301 % par an. Des exemples concrets, comme l'analyse marketing de MGM Resorts, ont démontré des améliorations substantielles de l'efficacité marketing grâce à des approches fondées sur les données.
Mais voilà le hic : le succès n'est pas automatique.
Les organisations qui réussissent grâce au big data commencent par des cas d'utilisation à forte valeur ajoutée, développent les capacités techniques nécessaires, traitent de manière proactive les problèmes de confidentialité et de sécurité, et impulsent un changement organisationnel qui intègre la prise de décision fondée sur les données dans les opérations quotidiennes.
Les organisations qui s'appuient encore uniquement sur l'intuition et l'expérience sont distancées par leurs concurrents qui fondent leurs décisions sur des données probantes issues d'ensembles de données massifs. Cet écart se creuse chaque trimestre.
Commencez modestement. Choisissez un problème bien délimité où l'analyse de données peut apporter une valeur ajoutée mesurable. Validez le concept. Développez ensuite votre stratégie. L'avantage cumulatif de dizaines d'améliorations fondées sur les données se transforme progressivement en un avantage concurrentiel durable.
La question n'est pas de savoir si le big data crée de la valeur – les preuves sont accablantes. La question est de savoir si votre organisation saura capter cette valeur avant vos concurrents.