Résumé rapide : En 2026, le développement de l'IA s'articule autour des systèmes agentiques, des modèles de langage à grande échelle atteignant 1 600 milliards de paramètres et du déploiement concret en entreprise. Parmi les tendances clés figurent les systèmes d'IA agentiques affichant d'excellentes performances pour les tâches de codage et de raisonnement, les transformateurs de diffusion qui alimentent les outils créatifs de nouvelle génération et les cadres gouvernementaux qui redéfinissent les normes de cybersécurité. Cette année marque le passage d'une IA expérimentale à des systèmes opérationnels intégrés aux secteurs de la santé, du codage et des processus métier.
Le paysage de l'IA a connu des bouleversements majeurs depuis fin 2025. Là où l'expérimentation dominait autrefois, des systèmes de production prennent désormais en charge des flux de travail critiques. Des modèles à mille milliards de paramètres fonctionnent sur du matériel grand public. Des agents autonomes planifient des réunions, analysent des données et gèrent l'infrastructure sans intervention humaine.
Mais qu'est-ce qui change réellement la donne ? Au-delà des engouements et des lancements de produits, des avancées techniques spécifiques redéfinissent la manière dont les entreprises et les développeurs interagissent avec l'intelligence artificielle. Les tendances qui se dessinent en 2026 ne sont pas théoriques : elles s'appuient sur des gains de performance mesurables, des changements de politiques gouvernementales et des données d'adoption en entreprise.
Cette analyse approfondie examine les huit développements les plus significatifs en IA qui marqueront l'année 2026, des innovations architecturales dans les modèles de diffusion aux données de l'enquête mondiale de l'IEEE sur l'adoption des agents. Soyons francs : certaines prédictions de 2024 se sont complètement révélées erronées. D'autres ont même dépassé les projections les plus optimistes.
L'IA agentique atteint l'adoption par le grand public
L'enquête mondiale de l'IEEE, publiée en janvier 2026, a révélé un fait remarquable : 521 000 experts en technologies s'attendent désormais à ce que les assistants personnels et les planificateurs IA soient massivement adoptés d'ici la fin de l'année. Il ne s'agit plus d'une technologie marginale, mais d'une infrastructure courante.
L'IA agentique se distingue fondamentalement des chatbots ou des outils de recherche. Ces systèmes n'attendent pas d'instructions. Ils analysent le contexte, prennent des décisions autonomes et exécutent des flux de travail complexes. Imaginez un logiciel de planification qui lit vos e-mails, consulte les agendas des participants, négocie les horaires de réunion, réserve les salles de conférence et envoie les documents préparatoires, le tout sans aucune intervention manuelle.
La même enquête a révélé que 91% des répondants prévoient une utilisation accrue de l'IA agentive pour l'analyse des données en 2026. Cette augmentation reflète un changement plus large : l'IA passe de la réponse aux questions à la résolution proactive des problèmes.
Qu'est-ce qui motive ces progrès ? Des fenêtres de contexte plus performantes, des capacités de raisonnement améliorées et une réduction des coûts. Des modèles comme DeepSeek-V4-Pro traitent désormais un million de jetons dans une seule fenêtre de contexte, soit environ 750 000 mots, de quoi analyser des bases de code entières ou des échanges d'e-mails sur plusieurs mois en une seule passe.
Le problème est le suivant : l’adoption par les entreprises est plus lente que l’enthousiasme des consommateurs. Les préoccupations liées à la sécurité, aux exigences de conformité et à la complexité de l’intégration freinent le déploiement. Accenture indique que 871 030 clients se détourneront d’une marque après une seule expérience négative, ce qui renforce l’importance des agents de service client autonomes.
Les modèles à mille milliards de paramètres redéfinissent l'échelle
Début 2026, la taille des modèles a atteint un nouveau seuil. DeepSeek-V4-Pro a été lancé avec 1 600 milliards de paramètres, soit 49 milliards par inférence. C'est dix fois plus important que les modèles de pointe de 2023, et pourtant, les coûts d'inférence ont considérablement diminué grâce à l'architecture de type ’ mixing-of-experts » (MoE).
L'avancée technique majeure ? Des mécanismes d'attention hybrides. DeepSeek-V4 combine une attention dense pour les jetons critiques avec une attention parcimonieuse pour le contexte, réduisant ainsi la charge de calcul tout en maintenant les performances. Sur les benchmarks MMLU, DeepSeek-V4-Pro-Base obtient un score de 90,1% lors d'une évaluation en 5 exemples, soit un niveau proche de celui d'un expert humain pour des tâches de connaissances de niveau universitaire.
| Modèle | Paramètres totaux | Paramètres activés | Longueur du contexte | Innovation clé |
|---|---|---|---|---|
| DeepSeek-V4-Pro | 1,6T | 49B | 1 million de jetons | attention hybride |
| DeepSeek-V4-Flash | 284B | 13B | 1 million de jetons | Précision mixte FP4/FP8 |
| Mistral Medium 3.5 | 128B | 128B (dense) | 256 000 jetons | Instruction/code unifié |
| Qwen3.6-27B | 27B | 27B (dense) | 128 000 jetons | Concentration sur l'utilité dans le monde réel |
Mais c'est là que ça devient intéressant. Les modèles plus petits réduisent l'écart. Qwen3.6-27B d'Alibaba offre des performances compétitives pour les tâches de codage et de raisonnement, malgré sa taille 60 fois inférieure. L'équipe a privilégié la stabilité et l'utilité concrète plutôt que le nombre brut de paramètres, et cela se voit : les développeurs constatent moins d'hallucinations et des résultats plus cohérents.
Mistral Medium 3.5, un modèle dense de 128 milliards de paramètres, a atteint 91,41 TP3T sur τ³-Telecom et 77,61 TP3T sur SWE-Bench Verified. Ce dernier chiffre est important : SWE-Bench teste des tâches concrètes d’ingénierie logicielle, comme la résolution de problèmes GitHub à partir de descriptions en langage naturel. Des performances supérieures à 751 TP3T indiquent que ces modèles peuvent gérer de manière autonome les flux de travail de développement en production.
Les transformateurs de diffusion transforment l'IA créative
La génération d'images à partir de texte a évolué au-delà des simples flux de travail d'affichage d'images. Les derniers transformateurs de diffusion combinent contrôle de la mise en page, cohérence du style et conditionnement multimodal dans des architectures unifiées.
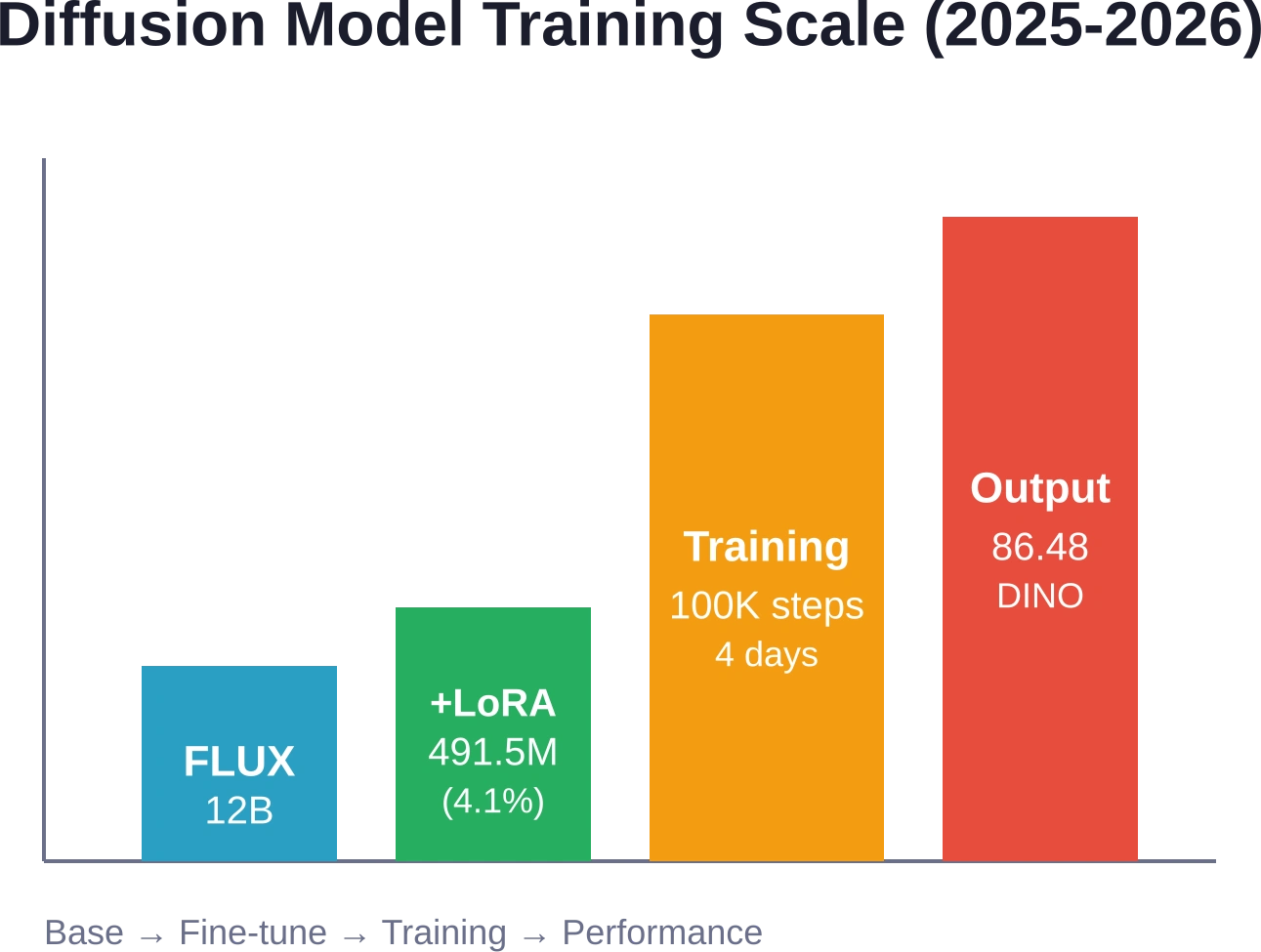
CreatiDesign, un projet de recherche de ByteDance et de l'université Fudan, a optimisé FLUX.1-dev (un modèle de base à 12 milliards de paramètres) grâce à LoRa avec un rang de 256. Cette optimisation n'a introduit que 491,5 millions de paramètres supplémentaires (soit une surcharge de 4,11 Tp3T), tout en permettant un contrôle précis des mises en page graphiques. Le système accepte simultanément les invites textuelles, les agencements spatiaux, les références de style et les contraintes de cohérence thématique.
L'entraînement a duré quatre jours sur huit GPU H20-96G, avec 100 000 itérations et un taux d'apprentissage fixe de 1e-4. Les résultats ? Un score DINO de 86,48 pour la préservation du sujet et de 78,30 pour la précision sémantique des éléments textuels. En d'autres termes : les conceptions générées conservent une cohérence visuelle malgré les variations et rendent fidèlement les mises en page de texte complexes, deux points faibles des modèles précédents.
Les auto-encodeurs de représentation (RAE) constituent un autre changement architectural majeur. Les modèles de diffusion traditionnels utilisent des encodeurs VAE datant de 2021 — des architectures obsolètes qui nuisent à l'efficacité. Les RAE entraînent des transformateurs de vision spécifiquement pour l'espace latent, produisant 256 jetons pour des images de 224 × 224 avec une reconstruction améliorée. Les modèles ImageNet affichent une erreur de reconstruction de 0,288, nettement inférieure à celle de l'encodeur FLUX traditionnel.
Les données d'entraînement sont également importantes. Le passage de 1,28 million d'images ImageNet à 73 millions d'échantillons web, synthétiques et textuels a permis d'améliorer les scores GenEval, passant d'une valeur de référence à 76,8 sur DPG-Bench. Des données d'entraînement plus diversifiées produisent des modèles qui généralisent mieux aux cas limites et aux requêtes inhabituelles.
Les cadres gouvernementaux redéfinissent la cybersécurité de l'IA
Les mesures politiques prises fin 2025 et début 2026 ont établi de nouvelles normes en matière de sécurité et de gouvernance de l'IA. L'Institut national des normes et de la technologie (NIST) a publié en décembre 2025 un projet de lignes directrices intitulé “ Repenser la cybersécurité à l'ère de l'IA ”.”
Ces lignes directrices abordent une tension fondamentale : si les systèmes d’IA automatisent la surveillance de la sécurité et la réponse aux menaces, ils créent également de nouvelles surfaces d’attaque. Les entrées adverses, l’extraction de modèles et les données d’entraînement corrompues n’étaient pas des préoccupations dans les cadres de cybersécurité antérieurs à l’IA. L’approche actualisée du NIST considère les modèles d’IA comme des infrastructures critiques nécessitant une protection dédiée.
Parallèlement, le décret présidentiel de décembre 2025 du président Trump, intitulé “ Garantir un cadre politique national pour l’intelligence artificielle ”, chargeait le procureur général de créer un groupe de travail sur les litiges en matière d’IA. L’objectif ? Contester les réglementations étatiques en matière d’IA jugées inconstitutionnelles ou relevant de la compétence fédérale. Ceci crée un cadre de conformité unifié – controversé parmi les autorités de réglementation étatiques, mais bien accueilli par les entreprises présentes dans plusieurs États et confrontées à des exigences disparates.
Un décret distinct de juillet 2025, intitulé “ Prévenir l’IA woke au sein du gouvernement fédéral ”, impose aux systèmes d’IA fédéraux d’éviter tout biais idéologique. Les agences doivent documenter les sources des données d’entraînement, vérifier la neutralité des résultats et mettre en place des procédures d’examen avant leur déploiement. L’impact de ces mesures sur la fiabilité de l’IA et leur impact sur les obligations de conformité font encore débat.
Le plan d'action américain pour l'IA, intitulé “ Gagner la course à l'IA ” (publié en juillet 2025) de la Maison-Blanche, recense plus de 90 mesures politiques fédérales articulées autour de trois axes : l'accélération du développement des infrastructures, la suppression des obstacles réglementaires et la protection des intérêts de sécurité nationale. Parmi les mesures concrètes figurent la simplification des autorisations pour les centres de données, l'augmentation des financements alloués à la recherche en IA et la restriction de certaines exportations de modèles.
L'IA dans le secteur de la santé réduit l'écart mondial
L’Organisation mondiale de la santé prévoit une pénurie de 11 millions de professionnels de santé d’ici 2030, privant ainsi 4,5 milliards de personnes de services de santé essentiels. Les systèmes de diagnostic assistés par l’IA et la télémédecine offrent une solution partielle, non pas en remplaçant les cliniciens, mais en étendant leur champ d’action.
L'outil d'orchestration de diagnostic par IA de Microsoft (MAI-DxO) a atteint une précision de 85,51 TP3T dans la résolution de cas médicaux complexes, contre une moyenne de 201 TP3T pour les médecins expérimentés. Cela ne signifie pas que l'IA diagnostique mieux que les médecins. Cela signifie que les systèmes d'IA, en analysant des données patient exhaustives, la littérature médicale et l'imagerie, peuvent faire émerger des informations que les praticiens humains ne parviennent pas à identifier, faute de temps ou en raison d'une surcharge d'informations.
Les systèmes d'IA assistent les cliniciens dans le triage et l'aide à la décision, ces derniers examinant ensuite les recommandations. Le gain d'efficacité provient de la prise en charge par l'IA de l'agrégation des données, de l'analyse de la littérature et de l'établissement des diagnostics différentiels – des tâches qui mobilisent des heures de travail médical.
Les modèles de soins hybrides, combinant consultations en présentiel et télésurveillance par intelligence artificielle, connaissent une expansion rapide. Les dispositifs portables transmettent des données vitales à des systèmes d'IA qui détectent les anomalies, prédisent les complications et recommandent des interventions. Pour les maladies chroniques comme le diabète ou les maladies cardiaques, la surveillance continue permet de déceler précocement les aggravations, réduisant ainsi le nombre d'interventions d'urgence.
D'après l'enquête mondiale de l'IEEE, 41% prévoient une adoption massive, voire quasi massive, des systèmes d'IA de surveillance de la santé d'ici 2026. Cette prévision concorde avec l'intégration par Apple, Google et Samsung de technologies de suivi de santé avancées dans leurs appareils grand public. L'infrastructure est déjà en place : les couches d'IA permettent d'exploiter les données.
L'IA devient un élément central des flux de travail de recherche
La recherche scientifique génère des données plus rapidement que les humains ne peuvent les analyser. La génomique produit des téraoctets par expérience. Les détecteurs de physique des particules enregistrent des milliards d'événements de collision. Les modèles climatiques fonctionnent pendant des semaines, générant des pétaoctets de simulations atmosphériques.
Les outils d'IA s'intègrent désormais directement aux processus de recherche. Les modèles de langage synthétisent la littérature, proposent des protocoles expérimentaux et identifient les lacunes des études existantes. Les modèles de vision par ordinateur analysent les images microscopiques, les données satellitaires et les observations télescopiques. L'apprentissage par renforcement optimise les paramètres expérimentaux et l'allocation des ressources.
arXiv, le serveur de prépublication pour la physique, les mathématiques et l'informatique, a hébergé plus de 200 000 soumissions en 2025. Une part croissante d'entre elles reconnaît l'utilité de l'IA pour la revue de la littérature, la formulation d'hypothèses ou l'analyse des données. Les chercheurs ne sous-traitent pas la réflexion ; ils automatisent les tâches fastidieuses de la méthode scientifique.
L'IA soulève toutefois de nouveaux défis. Les modèles entraînés sur des recherches publiées héritent d'un biais de publication, privilégiant les résultats positifs. Sans apprentissage spécifique, ils ne peuvent distinguer les études rigoureuses de celles présentant des failles méthodologiques. Les chercheurs doivent donc valider les suggestions de l'IA en les confrontant à leur expertise du domaine, une compétence qui n'est pas systématiquement enseignée dans les cursus universitaires.
Le rapport du NIST de juin 2025 intitulé “ L’impact de l’intelligence artificielle sur les effectifs en cybersécurité ” met en lumière une préoccupation similaire : à mesure que l’IA automatise les tâches routinières, les compétences des professionnels doivent évoluer vers la supervision, la validation et la gestion des cas particuliers. Ce même constat s’applique à toutes les disciplines : l’automatisation ne supprime pas l’expertise ; elle rehausse le niveau d’exigence de ce qui constitue un travail d’expert.
Les infrastructures deviennent plus intelligentes et plus efficaces
L'entraînement de DeepSeek-V4-Pro nécessitait des centres de données, et pas seulement des GPU. L'infrastructure énergétique et de refroidissement nécessaire pour supporter des entraînements à grande échelle avec des milliards de paramètres représente un goulot d'étranglement aussi important que la disponibilité de la puissance de calcul.
En 2026, l'infrastructure d'IA privilégiera autant l'efficacité que la capacité brute. Les systèmes de refroidissement liquide réduiront la consommation d'énergie de 30 à 400 Tk par rapport au refroidissement par air. L'allocation dynamique des charges de travail déplacera l'entraînement vers les heures creuses ou les régions disposant d'un surplus d'énergie renouvelable. Les techniques de compression de modèles, comme l'entraînement en précision mixte (FP4 et FP8), réduiront les besoins en bande passante mémoire, permettant ainsi de traiter des lots plus importants par GPU.
DeepSeek-V4-Flash illustre cette tendance : 284 milliards de paramètres, dont seulement 13 milliards sont activés par jeton, grâce à l’utilisation d’une précision mixte FP4 et FP8. Cela réduit le coût d’inférence d’environ 751 TP3T par rapport aux équivalents en pleine précision, rendant ainsi les modèles à l’échelle du billion économiquement viables pour une utilisation en production.
L'IA embarquée représente une autre frontière. L'exécution des modèles directement sur l'appareil élimine la latence et les risques liés à la confidentialité associés aux allers-retours vers le cloud. Des modèles quantifiés de moins de 10 milliards de paramètres fonctionnent désormais sur smartphones et objets connectés, permettant la vision par ordinateur, le traitement vocal et l'analyse de données de capteurs en temps réel, sans connexion réseau.
Les cas d'usage de l'IA en périphérie restent principalement axés sur le contrôle qualité en production, le suivi des stocks en magasin, la maintenance prédictive des équipements industriels et l'analyse de données de capteurs. Ces applications n'ont pas besoin de capacités de modélisation de pointe ; elles privilégient la fiabilité, une faible latence et un fonctionnement hors ligne.
L'IA de codage apprend le contexte, pas seulement la syntaxe
Les anciens modèles de génération de code traitaient la programmation comme une simple prédiction de texte. Il suffisait de leur fournir la signature d'une fonction et sa documentation pour qu'ils en complètent l'implémentation. Or, le véritable génie logiciel implique de comprendre l'architecture du système, les contrats d'API, les contraintes de performance et les conventions de l'équipe.
Les performances de Mistral Medium 3.5 sur SWE-Bench Verified (77,6%) témoignent d'une meilleure compréhension du contexte. Ce benchmark présente des tickets GitHub issus de dépôts réels : rapports de bogues, demandes de fonctionnalités et cas limites. Les modèles doivent analyser le ticket, localiser le code pertinent dans plusieurs fichiers, implémenter une correction et s'assurer de la réussite des tests. Il s'agit d'ingénierie logicielle complète, et non de génération de simples extraits de code.
Kimi K2.6, un modèle agentique multimodal à pondération ouverte, publié en avril 2026, améliore les capacités de programmation à long terme. Ce modèle gère des tâches de programmation complexes de bout en bout en Rust, Go et Python, et s'applique aux domaines du développement front-end, du DevOps et de l'optimisation des performances. Il obtient un score de 54,0 sur HLE-Full (avec outils), un benchmark évaluant l'exécution de tâches en plusieurs étapes nécessitant planification, utilisation d'outils et gestion des erreurs.
La conception pilotée par le code s'impose comme une compétence à part entière. Les développeurs définissent les exigences produit de haut niveau ; l'IA génère des maquettes d'interface utilisateur, des schémas d'API, des migrations de base de données et des implémentations initiales. Les développeurs humains examinent et affinent l'architecture, et gèrent les cas particuliers. La répartition des tâches évolue : l'IA prend en charge le code standard et les premières implémentations, tandis que les humains garantissent la robustesse et la maintenabilité.
Mais voilà le hic : la qualité du code est variable. Les modèles produisent un code syntaxiquement correct qui, parfois, enfreint les bonnes pratiques, introduit des failles de sécurité ou échoue avec des données non testées. La revue de code demeure essentielle. Les organisations qui déploient des assistants de codage IA constatent des gains de productivité de 20 à 400 000 £ sur les tâches routinières, mais soulignent que les développeurs juniors ont toujours besoin d’encadrement et de supervision.
Les responsables des données voient leurs mandats élargis
Les enquêtes révèlent une conviction croissante que le rôle du directeur des données (CDO) doit englober l'analyse de données et l'intelligence artificielle, avec une croissance annuelle significative. Cela témoigne du caractère indissociable de l'IA et de l'infrastructure de données.
L'entraînement de modèles complexes nécessite des ensembles de données structurés, des contrôles qualité et des cadres de gouvernance. Le déploiement de systèmes d'IA exige une surveillance des dérives, des biais et de la conformité. Ces deux fonctions relèvent naturellement de la responsabilité des données, mais de nombreux responsables de la gestion des données (CDO) manquent d'expertise en IA ou de l'autorité suffisante pour piloter la stratégie en la matière.
L'enquête de l'IEEE a révélé que les pratiques éthiques en IA connaîtront une croissance de la demande de 441 000 postes en 2026, soit une hausse de 9 points de pourcentage par rapport à l'année précédente. Les organisations recherchent des professionnels possédant une expertise en matière de pratiques éthiques en IA, d'évaluation de l'équité et de conformité — des rôles qui font le lien entre l'ingénierie des données, le droit et les connaissances du domaine.
Soyons francs : la plupart des entreprises fonctionnent encore en silos. Les équipes de données gèrent le stockage et les pipelines. Les ingénieurs en apprentissage automatique conçoivent les modèles. Le service juridique vérifie la conformité. Les équipes produit définissent les exigences. Les responsables des données, dotés d’une autorité transversale, pourraient unifier ces efforts, mais les jeux politiques internes font souvent obstacle.

Transformez les tendances de l'IA en projets concrets grâce à AI Superior
Les nouvelles tendances en matière d'IA n'ont d'importance que lorsqu'une entreprise peut les relier à un produit, un processus ou un problème commercial réel. IA supérieure Nous accompagnons les entreprises à travers des services de conseil en IA, l'identification de cas d'usage, la R&D, le développement d'IA générative, le conseil en master de droit (LLM), la vision par ordinateur, le traitement automatique du langage naturel (NLP), l'apprentissage automatique et le développement de logiciels d'IA sur mesure. Cette offre s'adresse aux entreprises souhaitant explorer les possibilités de l'IA avec une approche pragmatique avant de se lancer dans le développement.
AI Superior peut aider les équipes à :
- Évaluation des cas d'utilisation de l'IA en fonction des besoins de l'entreprise
- Explorer les opportunités en IA générative, LLM, NLP ou vision par ordinateur
- Soutenir la recherche et le développement en IA
- Conception d'un logiciel d'IA personnalisé répondant à des exigences réalistes
- Intégrer des solutions d'IA dans les produits ou flux de travail existants
👉Contactez l'IA supérieure pour discuter des développements en IA qui méritent d'être explorés pour votre entreprise, votre produit ou vos opérations internes.
Que signifie 2026 pour la stratégie en matière d'IA
Les tendances qui convergeront en 2026 ont un point commun : l’IA passera du stade de prototype à celui d’infrastructure de production. Les systèmes d’agents automatiseront les flux de travail. Les modèles à mille milliards de paramètres offriront des performances quasi expertes. Les transformateurs de diffusion généreront des créations prêtes à être publiées. Les cadres gouvernementaux établiront des normes de conformité.
Pour les entreprises, cela implique deux choses. Premièrement, les projets pilotes doivent impérativement mettre en place des plans de transition. “ Nous expérimentons l'IA ” n'est plus une stratégie viable : nos concurrents déploient déjà des solutions à grande échelle. Deuxièmement, l'infrastructure est tout aussi importante que les algorithmes. Même le meilleur modèle est inutile sans flux de données, surveillance et processus de conformité.
Les discussions au sein de la communauté reflètent des préoccupations pragmatiques. Les développeurs débattent des compromis matériels liés à l'IA en périphérie, de la reproductibilité des performances et des conditions de licence des modèles. Le phénomène de l'engouement médiatique persiste, mais il coexiste désormais avec les discussions sur le déploiement en production, ce qui constitue un équilibre plus sain.
D’ici 2028, le marché des logiciels d’IA devrait atteindre 1 400 580 milliards de dollars, selon les projections du secteur. Cette croissance finance non seulement le développement de modèles, mais aussi les outils, l’infrastructure et les services permettant aux organisations de mettre l’IA en œuvre. Le principal obstacle n’est plus de savoir “ pouvons-nous le construire ? ” mais “ pouvons-nous le déployer de manière responsable à grande échelle ? ”
Questions fréquemment posées
Qu’est-ce que l’IA agentique et en quoi diffère-t-elle des chatbots ?
Les systèmes d'IA agentiques fonctionnent de manière autonome, surveillant le contexte et exécutant des flux de travail complexes sans intervention humaine. Contrairement aux chatbots qui répondent aux requêtes, les agents planifient des réunions, analysent les flux de données et gèrent l'infrastructure de manière proactive. Selon une enquête mondiale de l'IEEE, 911 millions de technologues prévoient une utilisation accrue de l'IA agentique pour l'analyse des données en 2026, ce qui témoigne du passage d'une automatisation réactive à une automatisation proactive.
Quelle sera la taille des plus grands modèles d'IA en 2026 ?
DeepSeek-V4-Pro a atteint 1 600 milliards de paramètres, dont 49 milliards activés par inférence, grâce à une architecture de type « mix of experts ». Mistral Medium 3.5 est un modèle dense de 128 milliards de paramètres. Les fenêtres de contexte atteignent désormais 1 million de jetons (DeepSeek-V4) ou 256 000 jetons (Mistral Medium 3.5), permettant ainsi l’analyse de bases de code entières ou de collections de documents en une seule passe.
Les modèles à mille milliards de paramètres sont-ils pratiques pour une utilisation en production ?
Oui, grâce aux innovations en matière d'efficacité. L'entraînement en précision mixte (FP4/FP8) réduit les coûts d'inférence d'environ 751 Tp3 par rapport à la précision maximale. L'architecture de type « mixte d'experts » n'active qu'une fraction des paramètres par jeton : DeepSeek-V4-Pro utilise 49 milliards de ses 1,6 Tp de paramètres par inférence. Ces optimisations rendent les modèles massifs économiquement viables pour un déploiement en entreprise, quelle que soit leur taille.
Quelles seront les compétences en IA les plus recherchées en 2026 ?
Les pratiques éthiques en matière d'IA ont connu une croissance de la demande de 441 000 personnes en 2026, soit une hausse de 9 points de pourcentage par rapport à l'année précédente, selon les données de l'IEEE. Les organisations ont besoin de professionnels capables de faire le lien entre l'ingénierie des données, la conformité juridique et l'équité en matière d'IA. L'enquête du MIT Sloan a révélé que 70 000 personnes estiment que le rôle du directeur des données devrait englober la stratégie en matière d'IA, ce qui témoigne d'une forte demande pour des leaders qui intègrent la gouvernance des données au déploiement de l'IA.
Comment l'IA transforme-t-elle la prestation des soins de santé ?
L'outil de diagnostic IA de Microsoft a atteint une précision de 85,51 % (TP3T) sur des cas médicaux complexes, contre 201 % (TP3T) pour des médecins expérimentés sur le même ensemble de tests. L'IA ne remplace pas les médecins, mais étend leur champ d'action grâce au triage, à l'aide à la décision et à la télésurveillance continue. L'OMS prévoit une pénurie de 11 millions de travailleurs d'ici 2030 ; les systèmes d'IA contribuent à combler ce manque en automatisant l'analyse des données et la revue de la littérature, libérant ainsi les cliniciens pour les soins aux patients.
Quels sont les principaux défis en matière d'infrastructure d'IA en 2026 ?
La consommation d'énergie, les besoins en refroidissement et la disponibilité des ressources de calcul limitent l'échelle d'entraînement. Le refroidissement liquide réduit la consommation d'énergie de 30 à 40 Tk³ par rapport au refroidissement par air. L'entraînement en précision mixte et l'activation parcimonieuse MoE permettent d'économiser de 60 à 70 Tk³. Les organisations doivent trouver un équilibre entre les performances du modèle et les coûts opérationnels, en privilégiant souvent des modèles plus petits et finement paramétrés plutôt que des systèmes de grande envergure pour des tâches spécifiques où l'efficacité prime sur la puissance brute.
Les réglementations gouvernementales en matière d'IA vont-elles ralentir l'innovation ?
Les cadres fédéraux visent à harmoniser la conformité, remplaçant ainsi la disparité des réglementations étatiques qui engendrent des coûts supplémentaires. Les lignes directrices du NIST sur la cybersécurité de décembre 2025 et le plan d'action de la Maison-Blanche intitulé “ Gagner la course à l'IA ” recensent plus de 90 mesures politiques visant à accélérer le développement des infrastructures tout en établissant des normes de sécurité minimales. Leur impact sur l'innovation dépendra de leur mise en œuvre : la simplification des autorisations pour les centres de données est un atout, mais les litiges relatifs à la préemption des États créent une incertitude.
La voie à suivre
L'IA en 2026 n'est plus une question de spéculation. Les indicateurs de performance, les données d'adoption en entreprise et les évolutions des politiques gouvernementales témoignent concrètement de l'état actuel de cette technologie. Les systèmes multi-agents, les modèles à mille milliards de paramètres et les transformateurs de diffusion représentent des avancées techniques majeures, et non de simples arguments marketing.
Mais les problèmes les plus épineux restent d'ordre organisationnel. Intégrer l'IA aux systèmes existants, former le personnel aux nouveaux processus et garantir un déploiement responsable exigent un leadership et des investissements qui vont au-delà du simple développement d'algorithmes. La technologie fonctionne ; la question est de savoir si les organisations peuvent s'adapter suffisamment vite pour en tirer pleinement parti.
L'indice Stanford AI et les enquêtes de l'IEEE fourniront des données actualisées d'ici mi-2026. Il convient de les suivre pour obtenir des données quantitatives sur les taux d'adoption, les tendances en matière de calcul et l'évolution du marché du travail. Pour l'heure, la tendance est claire : l'IA est une infrastructure, et les décisions relatives à cette infrastructure façonnent l'avantage concurrentiel pour les années à venir.
Restez informé. Testez avec soin. Déployez de manière responsable. Les avancées majeures en IA de 2026 ne sont pas théoriques : ce sont des systèmes opérationnels qui transforment déjà des secteurs entiers.