Résumé rapide : En 2026, les prix des API LLM varient considérablement d'un fournisseur à l'autre, allant de 0,28 Tk par million de jetons pour l'offre économique de DeepSeek à 21 Tk par million de jetons pour GPT-5.2 Pro d'OpenAI. Comprendre les modèles de tarification par jeton, les coûts cachés comme la mise en cache et les plongements lexicaux, ainsi que les stratégies d'optimisation, permet de réduire les dépenses de 30 à 90 Tk tout en maintenant les performances.
Le marché des API de modèles de langage a connu une croissance exponentielle. Plus de 300 modèles se disputent désormais l'attention des développeurs, chacun avec des structures tarifaires très différentes.
Choisir le mauvais fournisseur peut entraîner des dépenses excessives de plusieurs milliers d'euros par mois. Certaines sources indiquent que les entreprises surpaient les API LLM, mais les pourcentages exacts de surpaiement varient selon les cas d'utilisation, car elles n'ont pas optimisé leur sélection de modèles ni leurs habitudes d'utilisation.
Ce comparatif détaille les tarifs actuels des principaux fournisseurs, révèle les coûts cachés qui prennent les équipes au dépourvu et montre exactement où va votre argent lorsque vous utilisez une API LLM.
Comprendre les modèles de tarification de l'API LLM
La plupart des API LLM facturent au jeton. Mais quel impact cela a-t-il concrètement sur votre budget ?
Un jeton représente environ quatre caractères. Le mot “ compréhension ” contient environ trois jetons. Vos appels d'API sont facturés séparément pour les jetons d'entrée (ce que vous envoyez) et les jetons de sortie (ce que le modèle génère).
Les jetons de sortie coûtent généralement 3 à 6 fois plus cher que les jetons d'entrée. Cette asymétrie est importante lors de la génération de réponses longues.
Les trois principaux niveaux de prix
Les fournisseurs structurent leurs prix autour de trois modèles de consommation :
- À la demande (standard) : Paiement à l'unité sans engagement. Coût unitaire le plus élevé, mais flexibilité maximale. Idéal pour le prototypage ou les charges de travail imprévisibles.
- Traitement par lots : Soumettez des requêtes traitées de manière asynchrone sous 24 heures. Amazon Bedrock et OpenAI proposent tous deux des remises de 50% pour les requêtes par lots par rapport aux tarifs à la demande. Idéal pour les tâches non urgentes telles que l'analyse de données ou la génération de contenu.
- Débit provisionné : Réservez une capacité dédiée avec des temps de réponse garantis. Facturation horaire ou mensuelle. Idéal pour le traitement de volumes importants et constants nécessitant une latence prévisible.
OpenAI a introduit de nouveaux niveaux dans sa dernière grille tarifaire. Le niveau “ Flex ” offre des remises modérées, tandis que le niveau “ Priorité ” garantit un traitement plus rapide pendant les périodes de forte utilisation.
Ventilation des prix des principaux fournisseurs
Laissons de côté le marketing et examinons les chiffres réels des pages de prix officielles.
Tarification de l'API OpenAI (2026)
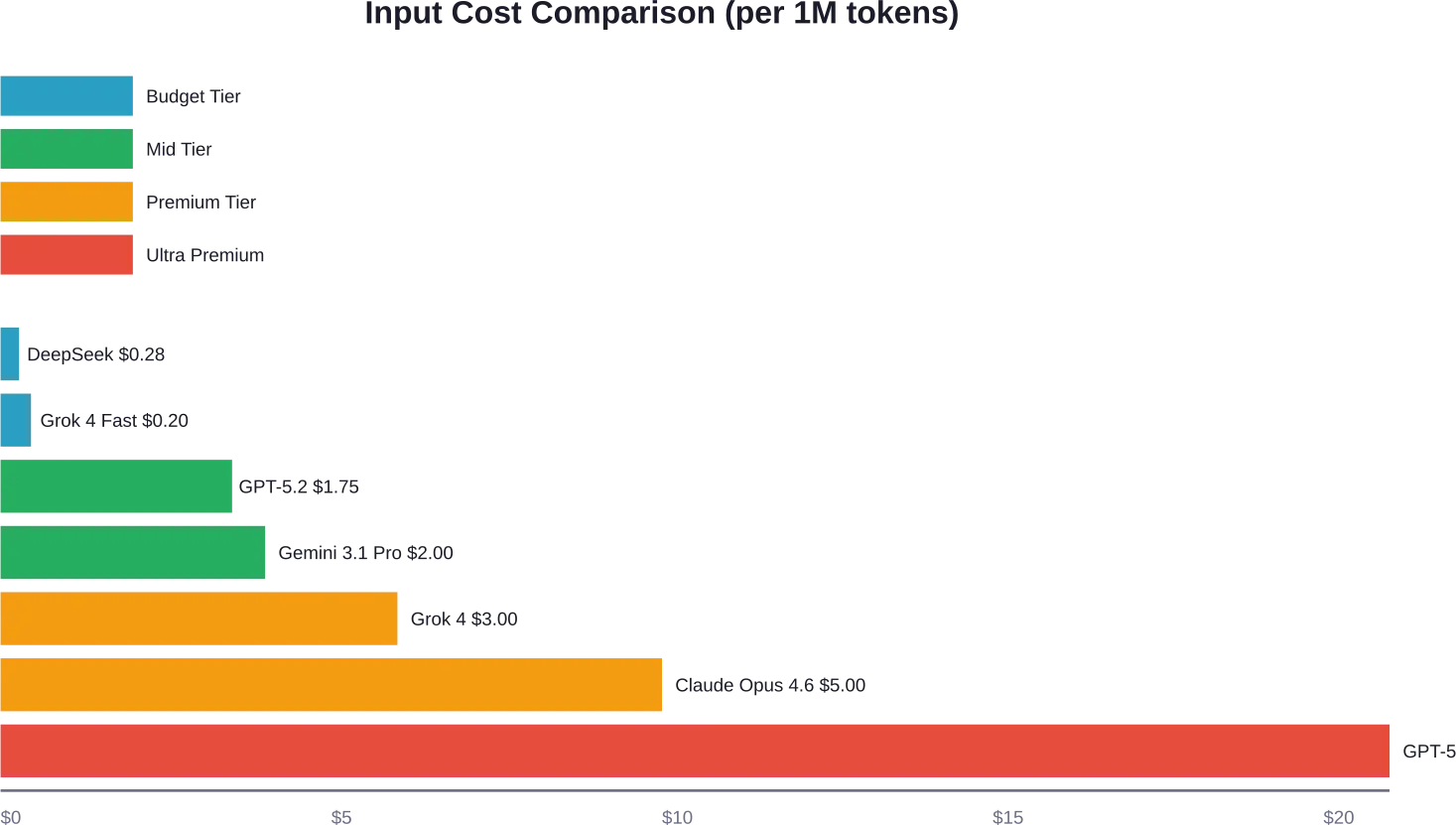
L'offre d'OpenAI s'est considérablement élargie. Voici les tarifs par million de jetons, selon la page officielle d'OpenAI :
| Modèle | Coût des intrants | Entrée mise en cache | Coût de production |
|---|---|---|---|
| GPT-5.2 Pro | $21.00 | N / A | $168.00 |
| GPT-5.2 | $1.75 | $0.175 | $14.00 |
| GPT-5 Mini | $0.25 | $0.025 | $2.00 |
| Nano GPT-5 | $0.025 | $0.0025 | $0.20 |
| GPT-4.1 | $1.00 | N / A | $4.00 |
| GPT-4o | $1.25 | N / A | $5.00 |
Le modèle phare GPT-5.2 est conçu pour le raisonnement complexe et les flux de travail automatisés. GPT-5 Nano offre l'option la plus abordable de la gamme actuelle d'OpenAI, adaptée aux tâches simples de classification ou d'extraction.
Leur API par lots divise ces prix par deux. Le traitement par lots de GPT-5.2 coûte $0,875 en entrée et $7,00 en sortie par million de jetons, soit une réduction de 50% par rapport au tarif standard.
Prix de Claude l'anthropomorphe
Les modèles Claude d'Anthropic adoptent une architecture différente, avec des capacités de mise en cache du contexte particulièrement performantes. Extrait de leur documentation officielle :
| Modèle | Entrée de base | Résultats du cache | Sortir |
|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.5 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.1 | $15.00 | $1.50 | $75.00 |
Le système de cache de Claude offre une réduction de 90% lorsque vous réutilisez le contexte. Si vous développez un chatbot qui consulte régulièrement la même base de connaissances, le coût du cache ($0,50 par million de jetons contre $5,00 pour une nouvelle entrée) représente des économies considérables.
Anthropic propose également un traitement par lots à 50% de réduction sur les tarifs standard, correspondant à la structure de réduction d'OpenAI.
Google Vertex AI (Modèles Gemini)
La plateforme Vertex AI de Google héberge sa famille de modèles Gemini ainsi que des modèles tiers. Les tarifs indiqués sur la page officielle de Vertex AI sont les suivants :
| Modèle | Saisie ≤ 200 000 jetons | Entrée > 200K | Sortir |
|---|---|---|---|
| Aperçu de Gemini 3.1 Pro | $2.00 | $4.00 | $12.00 |
| Gemini 3.1 Flash | Tarifs des niveaux inférieurs | Consultez les documents officiels. | Consultez les documents officiels. |
Google applique des seuils de tarification pour les requêtes de longue durée. Les requêtes dépassant 200 000 jetons sont facturées à un tarif plus élevé pour l'ensemble des jetons de la requête. Gemini 2.5 Pro inclut 10 000 requêtes intégrées (intégration de recherche Web) par jour gratuitement, puis facture $35 par tranche de 1 000 requêtes intégrées supplémentaires.
Leur service de mise à la terre de sites web pour entreprises coûte $45 pour 1 000 invites mises à la terre. Ces fonctionnalités d'amélioration de la recherche peuvent rapidement faire grimper la facture si vous ne surveillez pas leur utilisation.
Plateforme multi-modèles Amazon Bedrock
AWS Bedrock regroupe les modèles de plusieurs fournisseurs sous une facturation unifiée. Voici ce qu'indique leur mise à jour tarifaire de février 2026 :
- Claude 3.5 Sonnet commence à $3 en entrée / $15 en sortie par million de jetons
- Gemma 3 4B coûte $0,04 en entrée / $0,08 en sortie
- Gemma 3 12B fonctionne avec une entrée $0.09 et une sortie $0.18.
Bedrock propose l'inférence par lots à 501 TP3T, avec des tarifs à la demande. Son modèle de débit provisionné facture par unité de modèle et par heure plutôt qu'en jetons, avec des remises pour les contrats d'un ou six mois.
Amazon propose également ses modèles Nova à des prix compétitifs, bien que les tarifs spécifiques varient selon les régions.
Options économiques : DeepSeek et xAI
La société chinoise DeepSeek a bouleversé le marché avec une politique tarifaire agressive pour ses modèles V3.2-Exp. Ces modèles sont proposés à $0,60 par million de jetons d'entrée (avec défaut de cache) et à $0,40 par million de jetons de sortie de raisonnement, selon les données tarifaires disponibles avec défaut de cache.
xAI a lancé Grok 4 à $3 en entrée et $15 en sortie par million de jetons. Sa variante plus rapide, Grok 4.1 Fast, coûte $0,20 en entrée et $0,50 en sortie, et s'adresse aux développeurs qui privilégient la vitesse à la capacité maximale.
Des frais cachés qui font grimper votre facture
Les frais symboliques font souvent la une. Mais plusieurs frais moins évidents peuvent doubler vos dépenses réelles.
Mise en cache des invites et fenêtres de contexte
Les fenêtres de contexte étendues semblent idéales jusqu'à ce qu'on réalise qu'elles engendrent un coût par jeton. OpenAI et Anthropic proposent tous deux une mise en cache rapide pour réduire les coûts liés aux contextes répétés.
D'après la documentation d'OpenAI, les jetons d'entrée mis en cache coûtent 90% de moins que les jetons d'entrée standard. Pour GPT-5.2, le coût est de $0,175 pour les jetons mis en cache contre $1,75 pour les jetons non mis en cache.
Le hic ? Les écritures dans le cache ont un coût. La tarification d'Anthropic indique des tarifs d'écriture variables selon la durée : $6,25 par million de jetons pour une écriture de 5 minutes et $10 par million pour une écriture d'une heure avec Claude Opus 4.6.
Si vous ne réutilisez pas le contexte assez fréquemment, la mise en cache coûte plus cher qu'elle n'est économique.
Plongements et recherche vectorielle
La construction d'un système RAG (génération augmentée par la récupération) nécessite la génération d'embeddings. Ces coûts sont indépendants de la tarification principale de l'inférence.
D'après la documentation AWS, Amazon Titan Text Embeddings V2 coûte $0,00002 $ par tranche de 1 000 jetons d'entrée. Cela paraît bon marché, sauf lorsqu'il s'agit d'intégrer des millions de documents.
Vous payez également pour le stockage vectoriel. Le moteur RAG de Vertex AI de Google inclut des frais pour l'ingestion des données, l'analyse LLM pour le découpage en segments et les opérations de recherche vectorielle, en plus des coûts d'inférence du modèle.
Mise à la terre et utilisation des outils
Google facture $35 pour 1 000 requêtes Web (recherche Web) sur Gemini après épuisement du quota journalier gratuit. Selon la documentation tarifaire officielle d'Anthropic pour Vertex AI, la recherche Web avec Claude coûte $10 pour 1 000 recherches.
Ces fonctionnalités améliorent considérablement la précision des informations en temps réel. Cependant, leur utilisation fréquente entraîne également une augmentation des coûts habituels (10-15%).
Limites de débit et limitation de bande passante
Les offres gratuites et les offres à faible utilisation imposent des limites de débit strictes. Le système de niveaux d'OpenAI indique que les utilisateurs du niveau 1 bénéficient de 500 requêtes par minute et de 500 000 jetons par minute sur GPT-5.2. Les utilisateurs du niveau 5 accèdent à 40 millions de jetons par minute.
Le non-respect des limites de requêtes entraîne des échecs et la mise en place d'une logique de nouvelle tentative, ce qui gaspille des jetons et du temps de développement. La mise à niveau vers un niveau supérieur nécessite un investissement mensuel minimum, mais élimine les goulots d'étranglement.

Concevez l'architecture LLM idéale grâce à l'IA supérieure
Le choix entre différentes API LLM ne se résume pas au prix des jetons. Les exigences de performance, la conception rapide, l'architecture système et la stratégie de mise à l'échelle influent également sur le coût total d'une application.
IA supérieure aide les entreprises à concevoir des systèmes LLM prêts pour la production et à choisir l'architecture la plus adaptée à leur cas d'utilisation.
Leur équipe peut vous aider pour :
- choisir les bons fournisseurs de LLM
- conception d'architectures LLM évolutives
- optimisation des invites et de l'utilisation des jetons
- intégration des LLM dans les systèmes existants
Si vous envisagez de lancer un produit basé sur la technologie LLM, IA supérieure peut aider à concevoir l'architecture technique et à mettre en œuvre la solution.
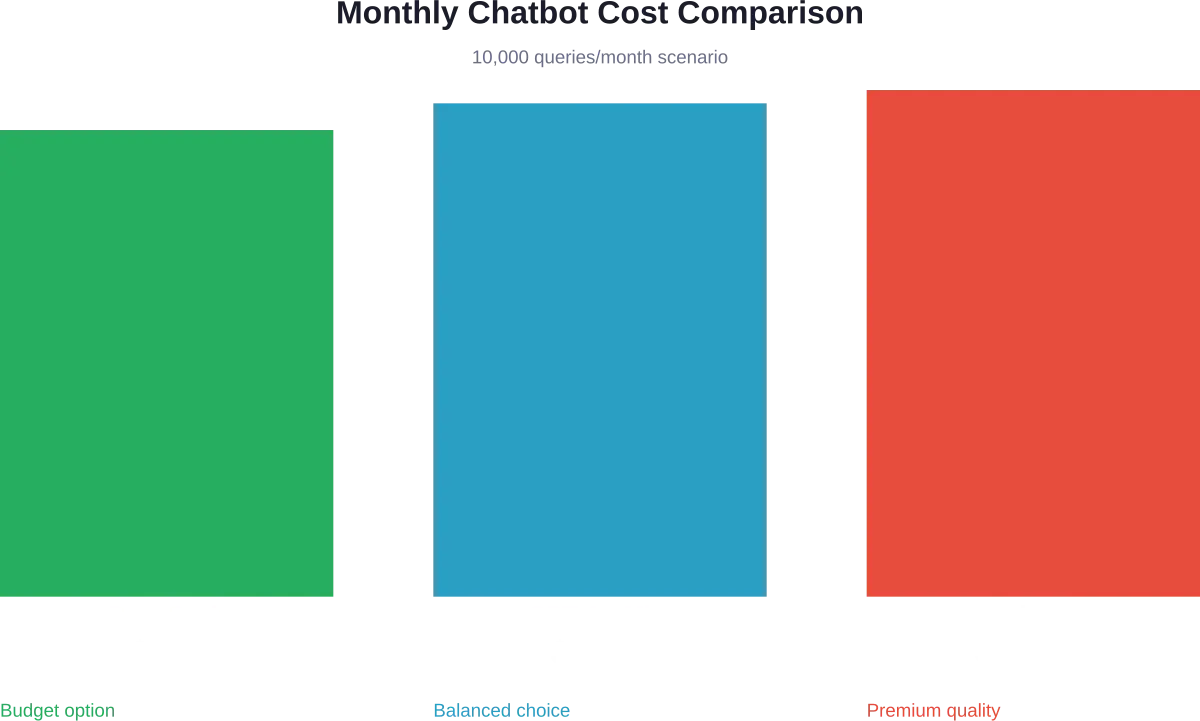
Analyse des coûts en situation réelle : exemple d’un chatbot
Modélisons les coûts réels d'un chatbot de service client traitant 10 000 requêtes par mois.
Hypothèses basées sur les modèles typiques des centres d'appels issus de la documentation AWS :
- 5 millions de jetons pour la base de connaissances (achat unique + mises à jour)
- 50 000 plongements lexicaux pour la recherche sémantique
- En moyenne, 100 jetons par requête utilisateur
- 100 jetons en moyenne par réponse
- Total : 2 millions de jetons par mois (1 million en entrée, 1 million en sortie)
OpenAI GPT-4.1 Mini
- Entrée : 1M de jetons × $0,20 = $200
- Résultat : 1M de jetons × $0,80 = $800
- Intégrations : 50K × $0,00002 = $1
- Total mensuel : ~$1 001
Claude Opus 4.6 avec mise en cache
- Base de connaissances en cache : 901 résultats TP3T
- Entrée en cache : 900 Ko × $0,50 = $450
- Nouvelle entrée : 100K × $5.00 = $500
- Résultat : 1M × $25,00 = $25 000
- Total mensuel : ~$25 950
Attendez, c'est 26 fois plus cher ! Mais voilà : Claude Opus offre une qualité nettement supérieure pour les tâches de raisonnement complexes. Ce surcoût se justifie pour les applications critiques où la précision prime sur le coût.
Option économique DeepSeek V3.2
- Entrée : 1M × $0,28 = $280
- Sortie : 1M × $0,40 = $400
- Intégrations : $1
- Total mensuel : ~$681
DeepSeek est l'option la plus économique, mais sa fiabilité est moins éprouvée pour les applications en entreprise. Les tests de performance montrent qu'elle obtient des scores similaires aux meilleurs modèles commerciaux (à 20% près) lors des tests standard, ce qui la rend intéressante pour les applications sensibles au coût.
Stratégies d'optimisation des coûts qui fonctionnent réellement
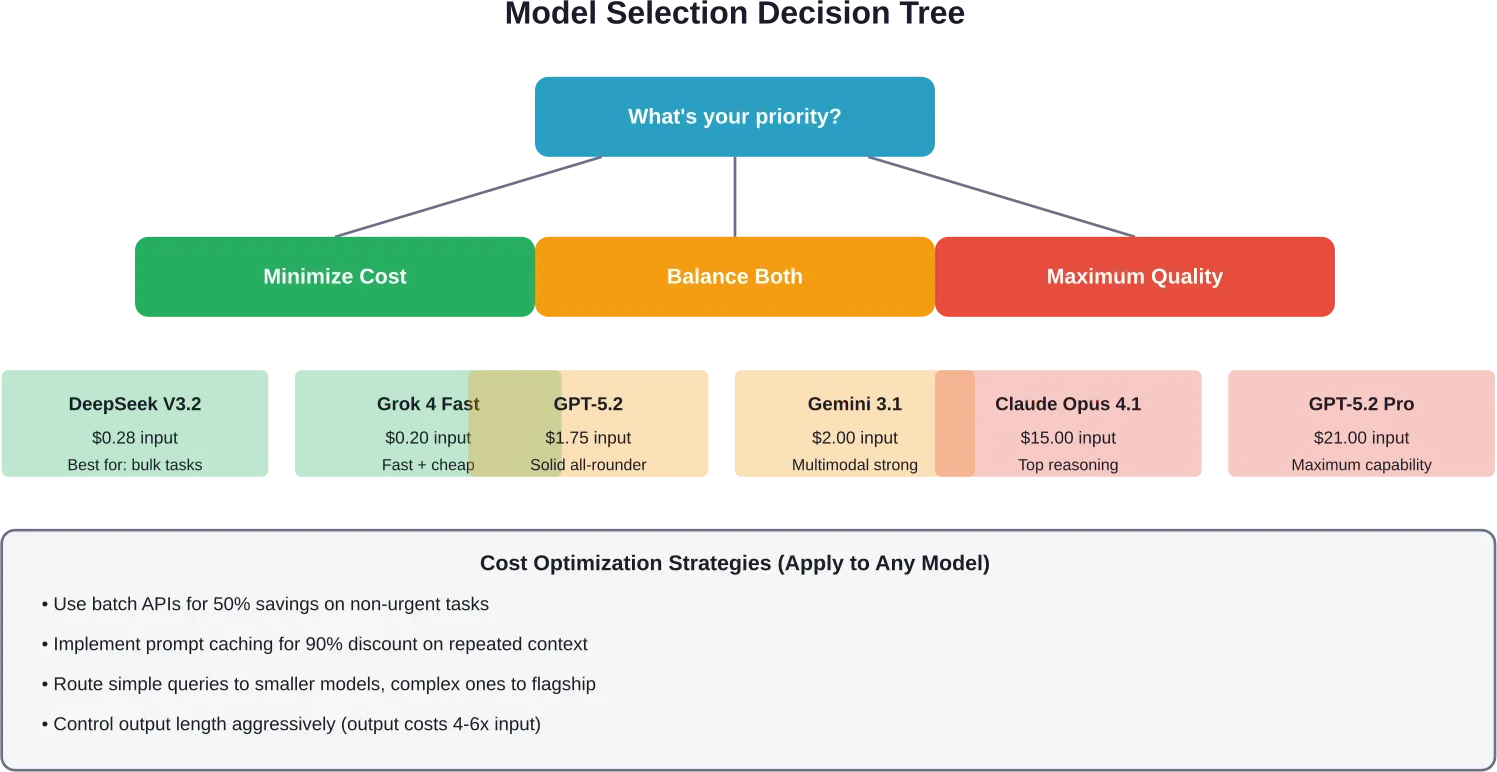
Les équipes qui gèrent efficacement les coûts des programmes LLM suivent plusieurs modèles éprouvés.
Routage intelligent des invites
Toutes les requêtes ne nécessitent pas votre modèle le plus puissant. Attribuez les modèles plus légers aux questions simples et les raisonnements complexes aux modèles les plus performants.
La documentation AWS indique que le routage intelligent des requêtes peut réduire les coûts jusqu'à 301 TP3T sans compromettre la précision. Mettez en œuvre une logique de classification qui attribue les requêtes aux modèles appropriés en fonction de leur complexité.
Amazon Bedrock prend en charge cette fonctionnalité grâce à son système de routage intelligent des requêtes, qui sélectionne automatiquement les modèles optimaux pour chaque requête.
Mise en cache agressive des prompts
Structurez vos invites pour optimiser la réutilisation du cache. Placez le contexte stable (instructions système, extraits de la base de connaissances) au début, là où il peut être mis en cache.
Le système de cache d'Anthropic permet de réduire les coûts jusqu'à 901 TP3T sur les jetons mis en cache par rapport à la tarification standard. Pour les applications qui utilisent un contexte cohérent, cette simple optimisation peut diviser les dépenses par deux.
Traitement par lots pour les tâches non urgentes
OpenAI et Amazon Bedrock proposent tous deux des remises 50% pour les requêtes API par lots. Tout traitement pouvant être effectué sous 24 heures devrait passer par les points de terminaison de traitement par lots.
La génération de contenu, l'analyse des données et la création de données d'entraînement fonctionnent parfaitement en mode batch. Les entreprises peuvent ainsi réaliser d'importantes économies grâce au traitement par lots, qui offre généralement des remises (50%) par rapport à la tarification à la demande.
Gestion des jetons de sortie
Les jetons de sortie coûtent 4 à 6 fois plus cher que les jetons d'entrée. Contrôlez rigoureusement la longueur des réponses grâce aux paramètres max_tokens et à une ingénierie des invites optimisée.
Demander des réponses de 500 jetons alors que 200 suffisent engendre des coûts inutiles à chaque requête. Il est recommandé de définir des limites de sortie prudentes et de les augmenter uniquement pour les requêtes qui nécessitent réellement des réponses plus longues.
Sélection du modèle par type de tâche
Adapter les capacités du modèle aux exigences :
- Classification/extraction simple : Utilisez les modèles nano/mini (GPT-5 Nano avec une entrée $0.025 et une sortie $0.20).
- Réponses générales des chatbots : Modèles de milieu de gamme (GPT-4.1 Mini, variantes Claude Sonnet)
- Raisonnement/codage complexe : Modèles phares (GPT-5.2, Claude Opus)
- Traitement en vrac : Utilisez toujours les API par lots pour réaliser des économies (50%).
Une analyse coûts-avantages suggère que les organisations peuvent atteindre le seuil de rentabilité avec un déploiement LLM sur site, en fonction des niveaux d'utilisation, des besoins de performance, du volume d'utilisation et des coûts d'infrastructure. Cependant, pour la plupart des équipes, l'optimisation de l'utilisation des API cloud offre un meilleur retour sur investissement que l'auto-hébergement.
Outils de suivi et de gestion des coûts
On ne peut optimiser ce qu'on ne mesure pas. Plusieurs méthodes permettent de suivre les dépenses liées aux masters en droit :
Tableaux de bord natifs du fournisseur
OpenAI, Anthropic et Google proposent tous des tableaux de bord d'utilisation affichant la consommation de jetons par modèle, projet et période. Ces outils sont fonctionnels, mais ne permettent pas de comparaison entre fournisseurs.
L'API Usage & Cost d'Anthropic vous permet d'accéder par programmation aux données de consommation avec une granularité allant de la minute à la journée. Tous les coûts sont exprimés en dollars américains (USD) sous forme de chaînes décimales en cents.
Plateformes de surveillance tierces
Helicone et les services similaires agrègent l'utilisation auprès de plusieurs fournisseurs de services de gestion de bibliothèques (LLM). Ils suivent les coûts par requête, identifient les requêtes coûteuses et envoient des alertes en cas de dépassement des seuils budgétaires.
Ces plateformes facturent généralement entre 1 et 21 TP3T de dépenses LLM ou des frais mensuels fixes. Elles sont avantageuses pour les équipes utilisant plusieurs prestataires ou nécessitant une attribution détaillée par utilisateur/projet.
Configurer les alertes budgétaires
La plupart des fournisseurs prennent en charge les limites de dépenses et les alertes. Configurez-les avant la mise en production :
- Définir des limites strictes pour les environnements de développement/test
- Configurer les alertes aux seuils budgétaires 50%, 75% et 90%
- Mettez en place des disjoncteurs qui suspendent les requêtes lorsque les limites sont atteintes.
AWS Cost Explorer permet le suivi budgétaire de l'utilisation de Bedrock. Google Cloud propose une fonctionnalité similaire pour les dépenses liées à Vertex AI.
Tendances émergentes en matière de tarification des LLM
Le paysage concurrentiel continue d'évoluer rapidement.
Course au moins-disant en matière de tâches liées aux produits de base
Le prix de la génération et de la classification de texte de base a baissé de 80 à 90% depuis 2023. Des modèles comme GPT-5 Nano ($0,025 entrée) et DeepSeek ($0,28 entrée) font baisser les prix à presque zéro pour les tâches simples.
Cette banalisation signifie que la différenciation s'opère sur des capacités spécialisées — raisonnement, compréhension multimodale, utilisation d'outils — plutôt que sur la simple génération de texte.
Tarification premium pour les modèles de raisonnement
La tendance inverse s'observe pour le raisonnement avancé. Le GPT-5.2 Pro, avec une entrée $21 et une sortie $168, est nettement plus cher que les modèles standard.
Ces modèles à “ pensée lente ” consacrent plus de temps de calcul au raisonnement avant de répondre, justifiant ainsi des prix plus élevés pour les problèmes complexes où la précision prime sur la rapidité.
Économie de la fenêtre contextuelle
Les fournisseurs appliquent des tarifs majorés pour les requêtes nécessitant un contexte long. Le seuil de plus de 200 000 jetons de Google entraîne une hausse des prix pour tous les jetons de cette requête.
À mesure que les fenêtres de contexte s'étendent (GPT-5.2 d'OpenAI prend en charge 400 000 jetons), il faut s'attendre à ce qu'une tarification à plusieurs niveaux basée sur l'utilisation du contexte devienne la norme. Une gestion efficace du contexte grâce à la synthèse et à la mise en cache prendra une importance accrue.
Tarification des modèles spécialisés
Les modèles spécialisés (médical, juridique, financier) affichent des prix plus élevés en raison de la formation spécialisée requise. Il faut s'attendre à une expansion continue des modèles de niche, dont les prix sont 2 à 3 fois supérieurs à ceux des modèles généralistes équivalents.
Quel fournisseur choisir ?
Il n'existe pas de réponse universelle, mais voici un cadre de décision basé sur les priorités :
Pour les petits budgets
DeepSeek V3.2 propose les coûts par jeton les plus bas tout en conservant une qualité acceptable. Grok 4 Fast constitue une autre option économique avec une infrastructure de support améliorée.
Combinez les modèles économiques pour les tâches simples avec une utilisation stratégique des modèles premium pour les requêtes critiques. Acheminez le trafic 80% vers les modèles économiques et le trafic 20% vers les modèles coûteux.
Pour une qualité maximale
Les modèles GPT-5.2 Pro et Claude Opus 4.1 d'OpenAI représentent actuellement le summum en matière de qualité. Prévoyez un budget 10 à 30 fois supérieur à celui des solutions de milieu de gamme.
Justifiée uniquement lorsque la précision a un impact direct sur les revenus ou les risques (analyse juridique, applications médicales, infrastructures critiques).
Pour des performances équilibrées
Les processeurs GPT-5.2 (entrée $1.75) et Claude Opus 4.6 (entrée $5.00) offrent un excellent compromis pour la plupart des applications de production : des performances élevées à un coût raisonnable.
Le Gemini 3.1 Pro de Google, compatible avec l'entrée $2.00, offre un prix compétitif et d'excellentes capacités multimodales.
Pour les utilisateurs de Google Cloud
Vertex AI offre un accès unifié à Gemini et aux modèles tiers. Son écosystème intégré simplifie le déploiement si vous utilisez déjà l'infrastructure GCP.
Profitez des 10 000 suggestions de recherche gratuites et quotidiennes de Gemini 2.5 Pro pour les applications à recherche augmentée.
Pour les environnements AWS
Bedrock propose le plus large choix de modèles avec une facturation unifiée. C'est un excellent choix pour les organisations utilisant AWS et souhaitant accéder à Anthropic, Meta et d'autres fournisseurs via une interface unique.
Questions fréquemment posées
Quelle est l'API LLM la moins chère en 2026 ?
DeepSeek V3.2 propose actuellement le tarif le plus bas par jeton, à environ $0,28 par million de jetons d'entrée et $0,40 pour le calcul des résultats. Grok 4 Fast de xAI coûte $0,20 en entrée et $0,50 en sortie. Pour les utilisateurs d'OpenAI, GPT-5 Nano coûte $0,025 en entrée et $0,20 en sortie par million de jetons.
Quel est le prix de GPT-5 par rapport à GPT-4 ?
D'après les tarifs officiels d'OpenAI, GPT-5.2 coûte $1,75 en entrée et $14,00 en sortie par million de jetons. L'ancien GPT-4 consomme $30,00 en entrée et $60,00 en sortie. GPT-5.2 est nettement moins cher (94% de réduction sur l'entrée et 77% sur la sortie) tout en offrant de meilleures performances.
Les API par lots sont-elles vraiment moins chères que les API 50% ?
Oui. OpenAI et Amazon Bedrock proposent tous deux des remises de 50% pour le traitement par lots avec un délai de 24 heures. Chez OpenAI, le coût du traitement par lots pour GPT-5.2 passe à $0,875 en entrée et $7,00 en sortie, contre $1,75 et $14,00 en standard. Il est recommandé d'utiliser le traitement par lots pour toute charge de travail non urgente.
Quels sont les coûts de mise en cache rapide ?
OpenAI facture 101 TP3 T de coûts d'entrée standard pour les jetons mis en cache. L'entrée mise en cache pour GPT-5.2 coûte 1 TP4 T0,175 T contre 1 TP4 T1,75 T pour l'entrée standard. Anthropic offre une réduction de 901 TP3 T sur les accès au cache, mais facture les écritures en cache. Les écritures en cache pour Claude Opus 4.6 coûtent entre 1 TP4 T6,25 et 1 TP4 T10,00 T par million de jetons selon la durée, tandis que les accès au cache coûtent 1 TP4 T0,50 T contre 1 TP4 T5,00 T pour l'entrée standard.
Comment calculer l'utilisation des jetons pour mon application ?
Utilisez les outils de tokenisation spécifiques au fournisseur. OpenAI propose la bibliothèque tiktoken. En général, un token équivaut à environ quatre caractères, soit 0,75 mot. Un document de 1 000 mots contient approximativement 1 333 tokens. Testez vos questions et réponses avec des tokeniseurs pour obtenir un décompte précis avant d'estimer les coûts.
Claude coûte-t-il plus cher que GPT ?
Cela dépend des modèles comparés. Claude Opus 4.6 ($5.00 en entrée) coûte plus cher que GPT-5.2 ($1.75 en entrée) mais moins cher que GPT-5.2 Pro ($21.00 en entrée). Les écarts sont plus importants au niveau des coûts de sortie : Claude Opus facture $25.00 en sortie contre $14.00 pour GPT-5.2. Cependant, les remises importantes accordées par Claude pour la mise en cache (90% de réduction) peuvent le rendre plus avantageux pour les applications nécessitant une réutilisation fréquente du contexte.
Quel est le modèle le plus rentable pour les chatbots ?
Pour les chatbots de service client général, GPT-4.1 Mini (entrée $0.20 / sortie $0.80) ou GPT-5 Mini (entrée $0.25 / sortie $2.00) offrent le meilleur compromis entre qualité et coût. Pour les chatbots de FAQ plus simples, GPT-5 Nano (entrée $0.025 / sortie $0.20) est parfaitement adapté. Il est recommandé d'implémenter un routage intelligent afin d'utiliser les modèles Nano/Mini pour les requêtes simples et de passer aux modèles haut de gamme uniquement lorsque la complexité l'exige.
Prendre votre décision concernant l'API LLM
Le prix ne doit pas être votre seul critère de choix. La qualité du modèle, la latence, la taille de la fenêtre de contexte et l'écosystème d'intégration sont également importants.
Comprendre les structures de coûts vous permet d'éviter l'écueil fréquent de surpayer des fonctionnalités inutiles. La plupart des applications offrent 90 % du rapport qualité-prix des modèles de milieu de gamme, soit 20 % de celui des modèles haut de gamme.
Commencez par ces étapes :
Commencez par analyser vos habitudes d'utilisation réelles. Suivez le nombre de jetons, la longueur des réponses et la complexité des requêtes pour votre cas d'utilisation spécifique. Les données concrètes valent mieux que les suppositions.
Deuxièmement, testez plusieurs fournisseurs sur votre charge de travail réelle. Les indicateurs de performance ne sont pas toujours pertinents dans votre contexte. Effectuez des tests A/B en mesurant à la fois la qualité et le coût.
Troisièmement, mettez en place des mécanismes de contrôle des coûts avant toute mise à l'échelle. Configurez des alertes budgétaires, activez la mise en cache et optimisez le routage des requêtes. Ces optimisations permettent de réaliser des économies plus importantes qu'un changement de fournisseur.
Le marché des solutions LLM est en constante évolution. De nouveaux modèles sont lancés chaque mois, les prix fluctuent et les fonctionnalités s'améliorent continuellement. Mais les fondamentaux restent les mêmes.
Comprendre la tarification par jetons. Surveiller l'utilisation réelle. Adapter les capacités du modèle aux exigences de la tâche. Optimiser la réutilisation du cache. Utiliser le traitement par lots lorsque cela est possible.
Les organisations qui mettent en œuvre des pratiques d'optimisation des coûts peuvent réaliser des économies substantielles grâce à une sélection et une utilisation optimisées des modèles, contrairement à celles qui choisissent un fournisseur sans discernement et utilisent les API au tarif plein. C'est ce qui distingue une adoption durable de l'IA des expériences coûteuses vouées à l'échec.
Prêt à optimiser vos dépenses LLM ? Commencez par auditer votre consommation actuelle et mettre en place un routage intelligent des notifications. Les économies s’accumulent rapidement.